 夜雨聆风
夜雨聆风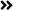 点击上方智能工厂前线 关注我们
点击上方智能工厂前线 关注我们
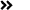 e-works鼓励原创,如需投稿请参看首页“原创投稿”说明。
e-works鼓励原创,如需投稿请参看首页“原创投稿”说明。
当一座数据中心的耗电量堪比一个小镇,当一枚顶级芯片的造价超过一辆豪车 ,当生成一张设计图的能耗足以让一台家用电脑连轴转上好几天 …… NVIDIA创始人黄仁勋在达沃斯世界经济论坛上提出的 “AI五层蛋糕”(AI is a 5-layer cake) 理论,正揭示一个被忽视的真相: AI早已不是人们印象中的某个软件或工具,而是如同电力与互联网般不可或缺的新型基础设施。
作者:e-works北京记者王聪
如果说传统软件是“人类写剧本、机器照着演”的确定性工程,那么AI则是一场“机器自己读剧本、还能即兴发挥”的范式革命。它不再等待人类把世界翻译成代码,而是直接从原始的信息混沌中提炼意义、生成洞察。这种跃迁不仅改写了人机协作的底层语法,更促使从能源到应用的整个五层架构发生根本性重构。黄仁勋的“五层蛋糕”理论,正是对这五层垂直工业体系的解码。本文将逐层拆解这一架构,透视每层的技术内核、创新趋势与生态博弈,揭示AI产业变革背后的市场逻辑与发展价值。
图1 黄仁勋的AI“五层蛋糕”架构(来源:NVIDIA)
万丈高楼平地起,在黄仁勋提出的AI“五层蛋糕”架构中,能源层是AI算力与智能生成的物理根基。黄仁勋明确表示,AI生成的每一个token,都是电子流动、热量管理以及能量转化为计算的结果,能源供给的规模与稳定性,直接决定系统能产出多少智能。
AI产业的爆发式增长,让全球数据中心的能源消耗迎来跨越式攀升。根据国际能源署(IEA)发布的《能源与人工智能》报告,全球数据中心用电量将从2024年的约415 TWh,攀升至2030年的约945 TWh,几乎翻倍。算力规模的持续扩张,从供需两端深刻重塑能源利用格局,催生出行业发展的三大核心特征。
图2 AI的推动下未来十年数据中心
的电力需求将大幅激增(来源:IEA)
相较于传统数据中心单机柜5-10kW 的功率水平,AI训练集群单机柜功率可达到100-300kW,百万卡级集群单设施更是需要1-5GW电力供应,功率密度的飞跃直接带动能源需求几何级增长。
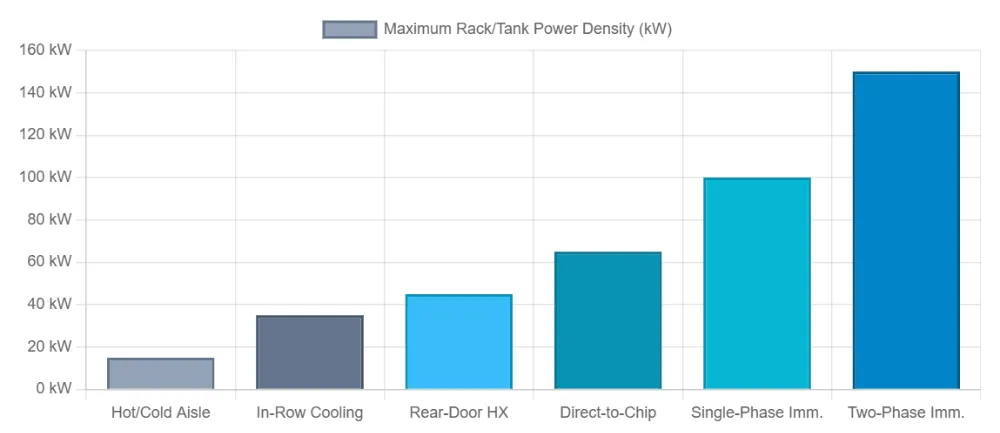
图3 不同冷却架构所能支撑的“最大可持续机架功率密度”(来源:Energy Solutions Intelligence《Liquid vs Air Cooling for Data Centers 2026》)
AI训练和推理依赖GPU集群长时间满负荷运转,任务特性决定其无法像传统数据中心一样灵活调度电力,必须保障7×24小时不间断的高功率供电,这种不可中断的刚性特征,对电网的稳定性与持续性提出了严苛标准。
在双碳目标的约束下,数据中心PUE(能源使用效率)管控日趋严格,液冷等高效散热技术成为行业刚需。例如浸没式液冷可将PUE降至1.04左右,先进冷板液冷约1.15,远优于传统风冷1.5以上的水平,绿色高效成为AI能源利用的核心导向。
电力需求持续攀升,正沿着产业链向上游传导,间接引爆了变压器、配电柜、UPS(不间断电源)等多个细分领域的需求。例如高性能变压器作为核心电力配套产品,2025年国内变压器市场规模同比增长超20%,出口总值达646亿元,同比增幅36%,其中对欧洲出口暴涨138%,市场需求旺盛,国内多家头部企业订单已排至2027年底,产能持续处于满负荷状态。
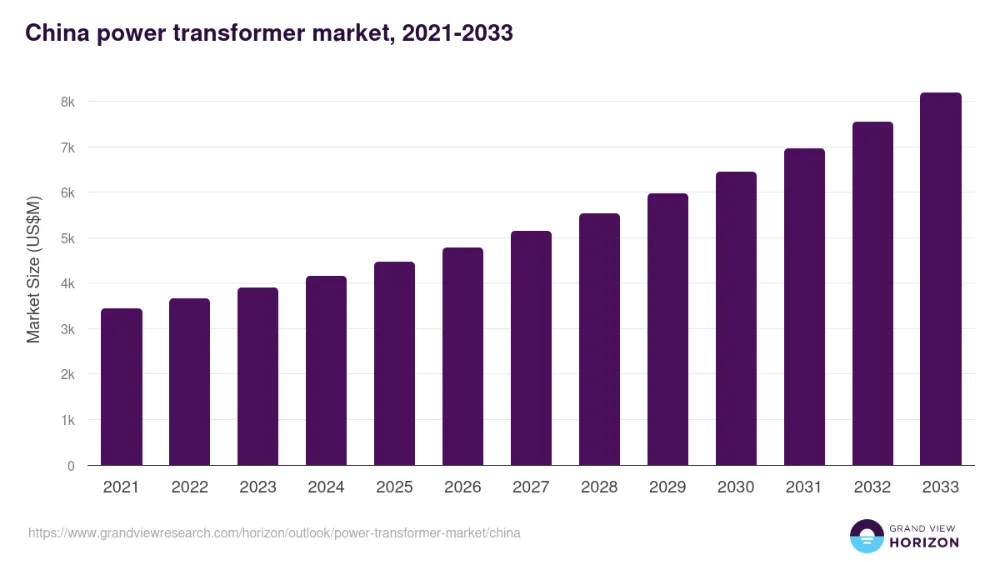
图4 中国变压器市场增长预测(来源:Grand View Research《China Power Transformer Market Size&Outlook, 2026-2033》)
作为国内变压器产能第一的龙头企业特变电工,2025年上半年,变压器产能利用率突破100%,国内输变电签单额高达273.34亿元;同期海外新签11.2亿美元,待执行合同超50亿美元,2025年8月特变电工中标沙特电力公司164亿元超高压设备采购项目,更是将订单体量推至全新高度。
当能源层的约束从云端数据中心延伸至工厂车间,生产管控的底层逻辑也在被同步改写。一方面,部分制造企业正优先推动能源管控系统的智能化升级,例如依托年初五部门联合印发的《工业绿色微电网建设与应用指南》,逐步部署“光伏+储能+微电网”的工业绿色电力体系。另一方面,零碳工厂正成为越来越多企业的战略必选项,像数据中心追求极致PUE一样,制造企业通过高能效技术迭代,降低单位产值能耗,为上层智能应用落地筑牢能源根基。
第二层芯片层是AI工业体系的核心大脑,承担着将能源高效转化为算力的关键职能。芯片的算力密度、能效比以及互联能力三大核心指标,直接决定了AI体系的扩展速度与智能适用性,也让这一层成为全球AI算力角逐的核心战场。
AI芯片的竞争,从来不是单一品类的跑分竞赛,而是围绕GPU、CPU与NPU(含ASIC)的“算力分工”。在模型训练与大规模推理的战场上,GPU凭借并行计算架构对海量矩阵运算的天然适配,相较CPU建立了不可替代的优势。但当大模型进入推理环节,全量参数加载对内存带宽的吞噬、多卡集群对高速互联的依赖,使HBM高带宽内存与片间高速互联成为高端AI芯片的“生死线”。与此同时,在智能制造产线、边缘终端等场景,NPU与专用ASIC芯片正以更低功耗、更高能效比承接实时算力需求。而CPU并未退场,它在AI系统中仍承担着通用控制与任务调度的底座职能。三者从“云端训练”到“端侧推理”、从“通用算力”到“专用加速”的层层递进,不仅定义了AI芯片的技术参数,也点燃了激烈的市场竞争与博弈。
2026年3月GTC大会上,黄仁勋预测AI芯片市场正迎来万亿美元级机遇,彰显了该赛道的爆发式增长潜力。目前NVIDIA在AI训练赛道牢牢占据主导地位,其“护城河”源于三重核心优势:一是深耕多年的CUDA软件生态,坐拥数百万注册开发者,成为全球绝大多数AI框架的原生适配选择;二是打造了芯片、互联、软件到系统的全栈垂直整合方案,形成闭环式产业竞争力;三是极高的客户迁移成本,企业基于CUDA搭建的定制化代码体系,形成了难以突破的技术绑定与生态锁定,进一步夯实其市场主导优势。
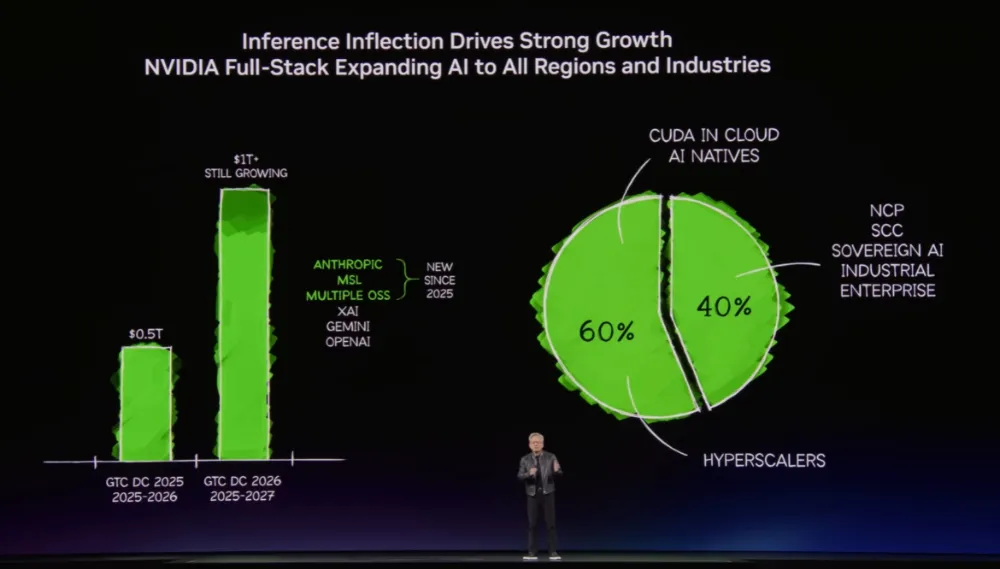
图5 黄仁勋在GTC 2026展示“万亿美元机遇”
(来源:NVIDIA)
在NVIDIA的领先格局下,行业竞争者正加速突围追赶。AMD凭借高性能算力产品快速抢占市场份额,2025年6月推出的MI350搭载288GB HBM3e内存,带宽高达8TB/s。此外,OpenAI已与AMD达成深度战略合作,通过认股权证布局未来最高10%持股权益,双方同步敲定了6GW量级的GPU算力长期规划。
与此同时,专用ASIC芯片迎来规模化崛起窗口期。博通为谷歌、Meta、OpenAI等科技巨头定制ASIC芯片,2026年第一季度AI营收达84亿美元,同比激增106%,并定下2027年AI芯片营收千亿美元的目标。相较于通用GPU,ASIC芯片在特定推理场景下能效比可提升数倍,但在场景灵活性上存在明显短板,由此形成了差异化的市场竞争格局。
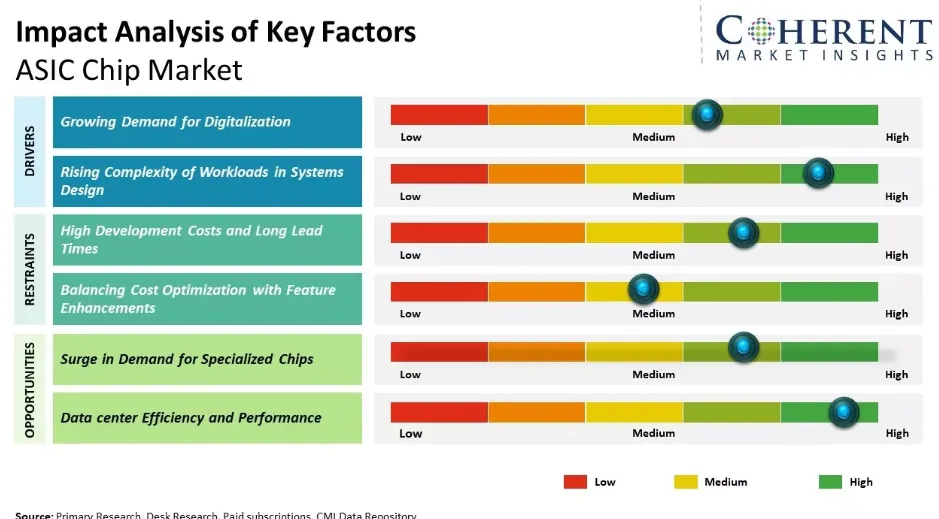
图6 ASIC芯片市场驱动因素分析
(来源:Coherent Market Insights)
国内市场,2025至2026年初迎来国产GPU厂商的上市热潮,多家企业通过IPO集结资本力量,进军芯片市场。摩尔线程、沐曦股份相继登陆科创板,分别募资75.76亿元、41.97亿元,聚焦自主AI训推一体芯片与对标国际主流的图形芯片研发;壁仞科技作为2026年港股首只新股登陆港交所,将八成以上募资投向智能计算解决方案;燧原科技也完成上市辅导,即将冲刺科创板,持续加码的资本投入为国产高端GPU突破提供了坚实支撑。
华为昇腾系列NPU凭借软硬件深度协同的独特优势,在AI推理及特定训练场景实现规模化商用,成为国产算力的重要支柱力量。但从行业整体发展来看,国产芯片仍面临核心发展瓶颈,软件生态差距是最突出的挑战。尽管华为昇腾以CANN+MindSpore搭建自主生态,海光信息通过兼容CUDA/ROCm降低迁移门槛,寒武纪则依托自研MLU架构与NeuWare软件栈提供代码迁移工具,但与NVIDIA成熟完善的生态体系相比,仍存在不小的成长空间。
需要注意的是,在智能制造核心场景里,机器视觉质检、工业机器人柔性作业、生产线数字孪生等,都高度依赖AI芯片在端侧输出低延迟、高稳定性的实时算力。这种需求逻辑,和数据中心芯片主打大规模并行运算的发展方向有着本质区别。与此同时,工厂现场高温、多粉尘、强电磁干扰等复杂工况,对芯片的工业级防护等级、环境耐受能力提出了严苛的标准。目前行业主流AI芯片大多面向数据中心与消费市场研发设计,难以适配工业特殊使用环境,成为国际巨头布局尚不充分的领域。
这也为国产芯片提供了突围契机——聚焦工业场景的定制化需求,优化低延迟、抗恶劣环境等核心指标,同时联合制造企业共建适配工业软件的生态,有望在细分赛道实现差异化突破,而制造企业与国产芯片厂商的深度协同,也将推动芯片层从“通用化”走向“场景化”,真正适配智能制造的核心需求。
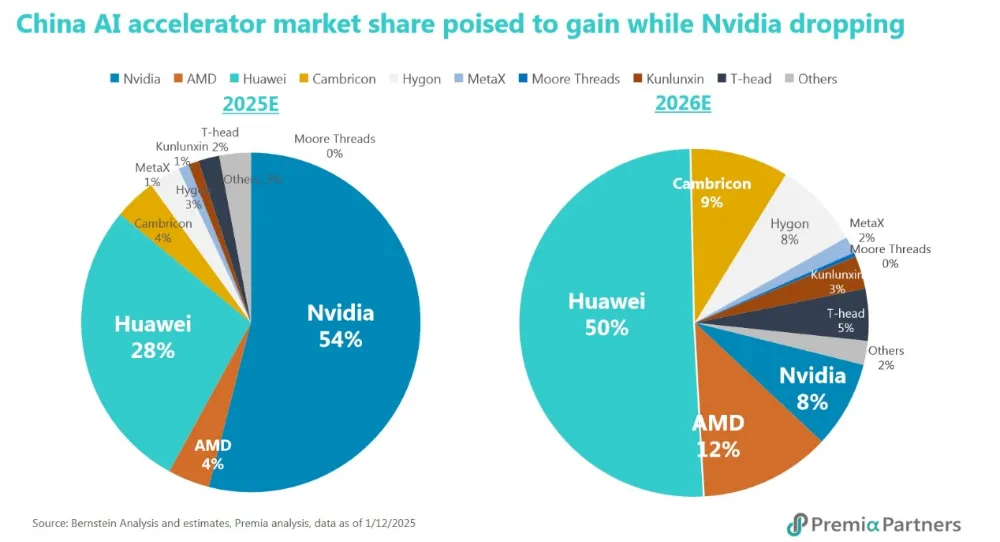
图7 中国AI加速器细分市场份额变化
(来源:Premia Partners)
第三层基础设施层是将芯片集群整合为智能生产载体的核心环节,涵盖数据中心建设与机电工程,包括土地、建筑、供配电系统、备用电源等。随着算力需求的日益旺盛,AI数据中心的建设周期已从传统的2-3年大幅压缩至12-18个月,技术迭代核心聚焦于散热方案升级与高速网络适配两大方向。
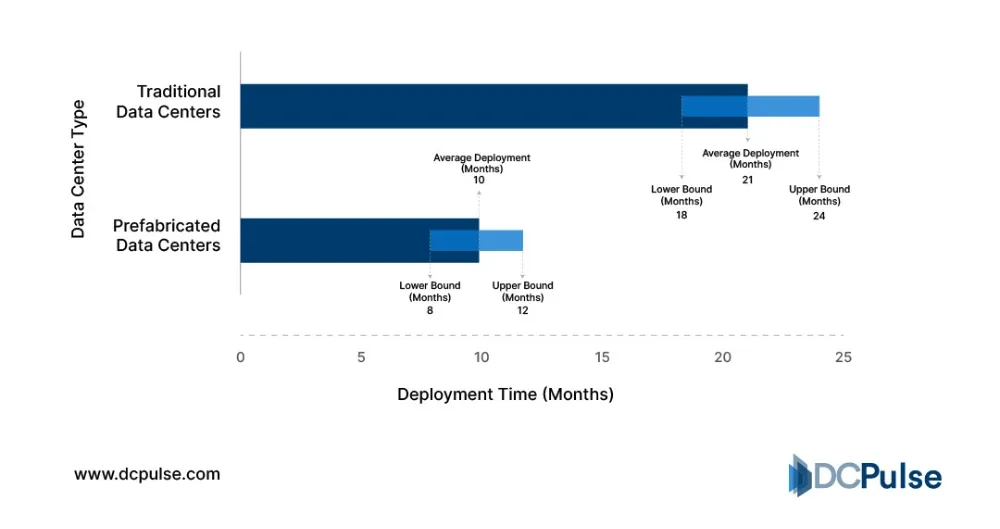
图8 数据中心(预制化)部署时间对比
(来源:DC Pulse)
AI芯片功耗的持续飙升,突破了传统风冷散热的承载上限,液冷技术成为适配高密算力的首选,不过较高的部署成本,也成为其大规模普及的主要制约因素。当前制造企业在不断探索风冷升级、冷热分流、混合散热等折中方案,力求在散热效能、建设投入与运维成本之间找到平衡点,推动散热体系走向多元化、分层化发展。
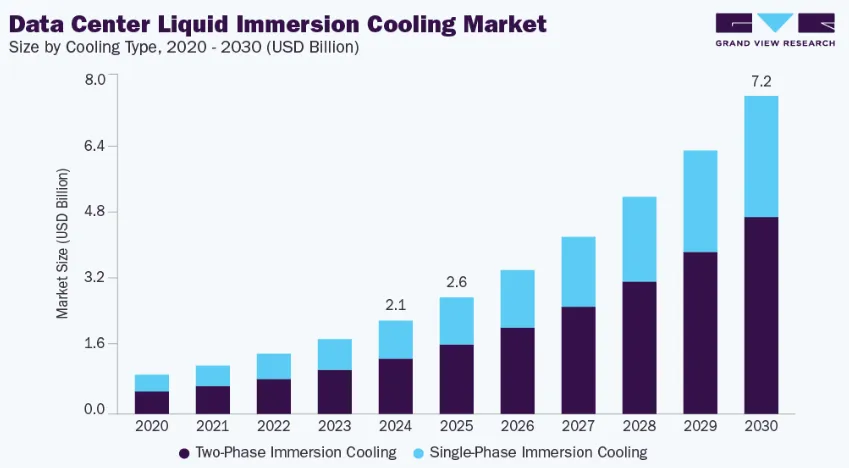
图9 数据中心液冷市场增长预测
(来源:Grand View Research)
与此同时,大规模AI集群开展并行训练与协同运算时,海量模型参数、训练数据流需要在服务器之间高速流转、实时同步,对网络传输的低时延、高带宽与无损转发能力提出了极致要求,也直接驱动高速网络硬件迎来快速迭代升级。目前400G、800G主流高速光模块已实现成熟量产,在各大算力中心完成批量组网部署。随着超大规模算力集群建设提速,业内普遍预计1.6T光模块将在2027年完成技术普及与成本下探,正式成为顶级AI算力集群组网的通用标准配置。
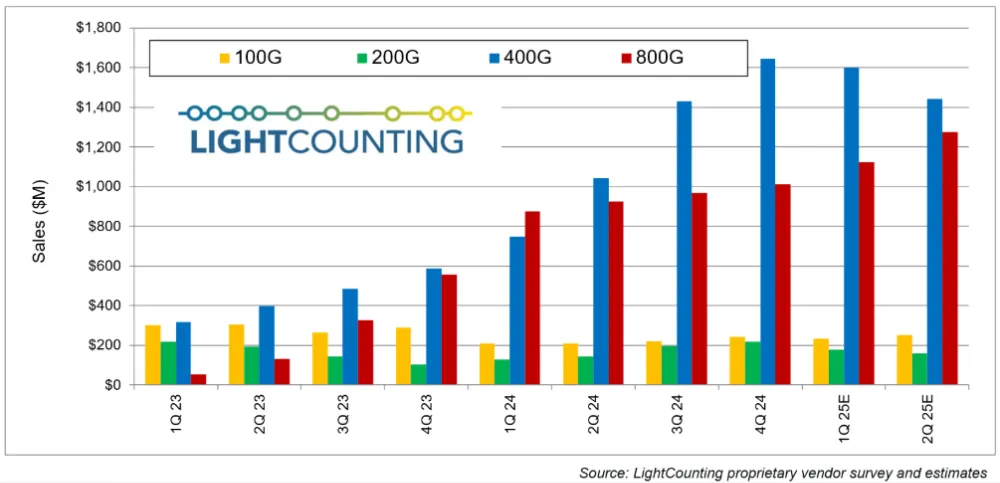
图10 2023Q1至2025Q2光模块(100G/200G/400G/800G)
市场增长(来源:LightCounting)
这一技术迭代直接引爆光模块与光连接器市场的爆发式增长。Choice数据显示,截至2026年4月22日,国内已有51家光模块概念公司披露2025年年报,其中46家实现盈利;已披露的2026年一季度财报的13家光模块板块公司全部实现盈利,其中10家公司实现业绩同步增长,光库科技、杭电股份、中际旭创等同比增长超1倍。
此外,AI训练对存储基础设施提出了前所未有的挑战。大模型预训练需吞吐PB级非结构化数据,Checkpoint高频读写对存储IOPS要求严苛,传统NAS架构已难以支撑。基于并行文件系统与全闪存阵列的高吞吐存储池,成为AI数据中心的标配,“算-网-存”协同优化成为基础设施层的新技术焦点。
在AI数据中心建设过程中,国内企业在模块化数据中心领域具备突出优势,部分项目可将部署周期压缩至数月,建设成本较传统模式显著降低。最近,国内头部云厂商与科技企业纷纷加码资本开支,全力布局AI数据中心建设。阿里巴巴宣布未来三年投入3,800亿元,聚焦云和AI硬件基础设施建设;腾讯近三个季度累计投入超831亿元,重点打造AI算力集群与边缘计算节点;字节跳动2026年规划投入约1,600亿元,持续完善AI基础设施布局。
然而,建设热潮背后亦暗藏隐忧。国内部分地市的智算中心出现“建成即闲置”的窘况,算力利用率不足30%的现象并非个例。这暴露出基础设施层与上层生态的深层脱节:注重“堆卡、盖楼”的硬件叙事时,AI模型开发工具链、行业数据集治理与商业化场景落地等“软实力”却没能跟上。这一现实也反向印证了“五层蛋糕”的深层逻辑——AI工业化不是单一层级的军备竞赛,而是基础设施、模型能力与商业场景垂直协同的系统工程。
总体来看,根据Gartner发布的数据显示,全球AI相关基础设施支出的强劲增长态势将在2026年延续,预计相关技术投资总额将升至2.5万亿美元,较2025年增长44%。2027年支出将进一步增长32%,达到3.34万亿美元。但这组数字的背后,资本流向正在发生结构性迁移——从单纯的数据中心土建与硬件采购,转向“算力底座+软件工具链+行业数据平台”的软硬一体化投资。基础设施层作为AI“五层蛋糕”中资本密度最高的环节,正从“跑马圈地”的粗放模式,迈向“聚木成林”的软硬协同新阶段。
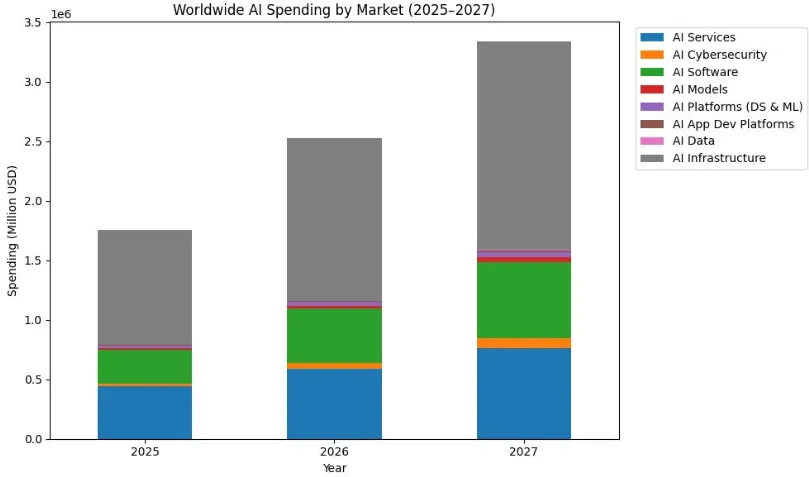
图11 全球AI支出按市场分层,AI基础设施(灰色)占比最大(来源:Sebastian Barros / Substack,基于Gartner数据绘制---Gartner《Worldwide AI Spending by Market, 2025–2027》)
第四层模型层是AI“五层蛋糕”中产业关注度与商业化潜力较高的层级,囊括大语言模型、多模态模型、科学AI模型等核心类型,是衔接底层算力与上层应用的关键纽带。2026年,全球AI模型技术迈入规模化成熟阶段,行业呈现出三大核心技术演进趋势。
推理能力跃升成为模型竞争的核心标尺。以OpenAIo系列、DeepSeek R1为代表的“慢思考”模型,依托强化学习技术深度优化逻辑推理链路,在数学演算、代码编写、科学问题求解等专业领域,性能表现逐步提升,让AI从“文本生成”向“逻辑思考”实现本质跨越,推进物理AI的全面应用。
MoE混合专家架构成为行业主流标配。该架构通过超大总参数量保障模型的知识容量,同时在推理环节仅激活少量参数运行,完美平衡了模型性能与计算效率。典型产品中,DeepSeek R1总参数达671B、活跃参数仅约37B,Llama 4 Maverick配备128个专家模块、活跃参数17B,GLM-4.5总参数355B、活跃参数32B,均通过这一架构实现了高效能落地。
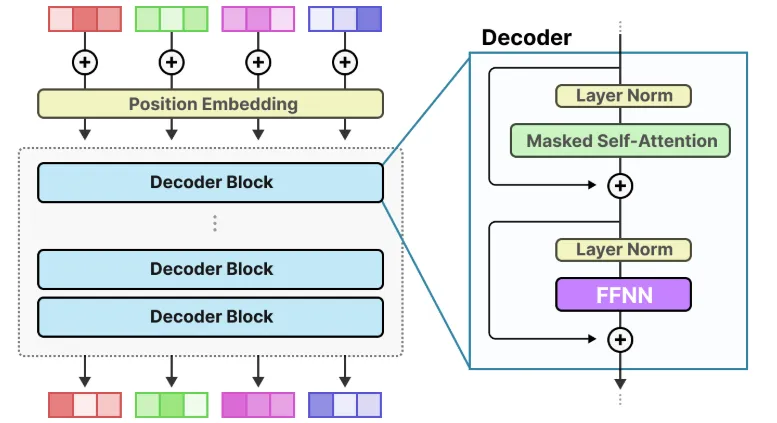
图12 MoE Decoder内部结构图
(来源:Maarten Grootendorst)
开源模型与闭源模型的性能差距持续收窄。DeepSeek R1、阿里Qwen3、Meta Llama 4 等开源先锋模型,在多项权威基准测试中,与 GPT-5.4、Claude Opus 4.6等头部闭源模型的性能差距正持续收窄,部分测试项已难分伯仲。
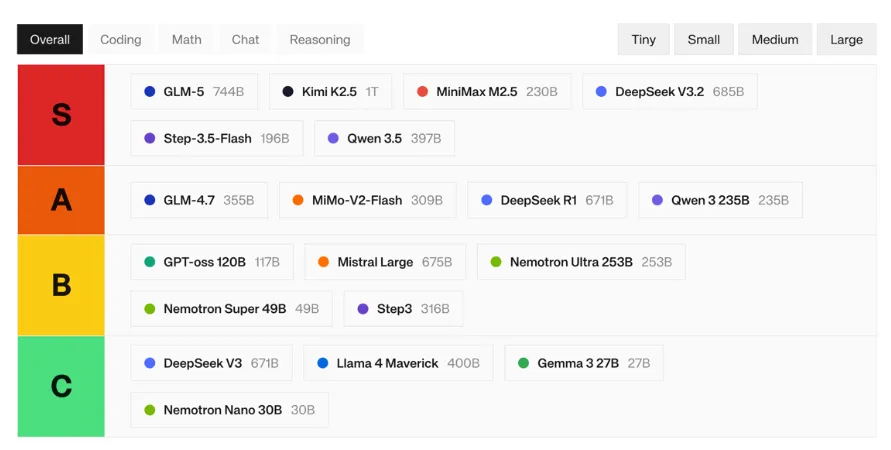
图13 2026年(Q1季度)开源/闭源大模型性能排行榜
(来源:Onyx AI/OpenRouter)
在工业现场,模型的落地逻辑与消费级场景截然不同。产线质量检测、设备预测性维护等场景要求毫秒级响应与数据不出厂,直接催生了“大小模型协同”的主从架构。云端大模型(百亿/千亿参数)承担工艺知识蒸馏、排产优化与跨工厂协同;边缘端轻量化模型(数亿至数十亿参数)则通过模型蒸馏、剪枝与量化技术,部署在工控机或边缘网关,负责实时质检、异常检测与设备控制。这种分层推理模式,既保留了大模型的知识密度,又满足了工业场景对低延迟、高可靠、强隐私的刚性要求,成为制造业部署AI的主流范式。
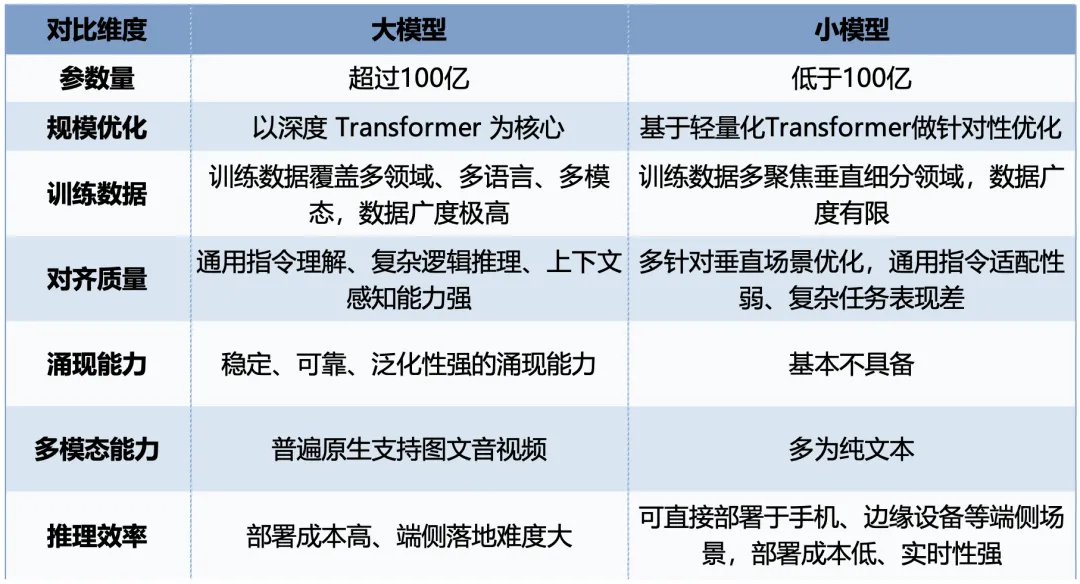
表1 大小模型不同维度对比
2026年全球大模型市场已呈现出鲜明的差异化竞争格局,各厂商围绕技术路线、商业模式与生态策略展开深度博弈,而非简单的性能排序。在旗舰赛道,OpenAI GPT-5.4 凭借综合推理能力占据领先地位,Anthropic Claude Opus 4.6打造了业界最优的安全对齐机制,Google Gemini 3.1 Pro则在原生多模态与科学计算能力上独具优势。与此同时,开源生态阵营正加速崛起,DeepSeek R1成为开源推理模型标杆,API调用成本约为OpenAI o1的1/27;阿里Qwen3.5依托活跃的开源生态快速扩张,Meta Llama 4凭借强大的社区支持实现便捷本地部署。此外,以百度文心、Kimi、智谱GLM等为代表,在垂直行业场景与区域市场中构建起差异化竞争优势。
黄仁勋特别强调,AI模型的价值边界远不止语言交互领域,物理模拟、机器人智能、蛋白质AI、化学AI等科学AI模型,同样是产业核心组成部分。在黄仁勋看来,目前模型层已跨越“足够好”的门槛,可以支撑上层应用的爆发,作为AI产业链的中枢,目前模型层在工业场景中正体现为“工业Know-how的代码化”之争。
对于制造企业而言,模型层的形态需求并非静态的“知识库”,而是具备自主规划与工具调用能力的工业AI Agent。这类Agent以工业大模型为大脑,通过调用接口与MES、ERP、SCADA、WMS等系统打通,能够自主完成“接收订单→排产优化→下发工单→监控执行→异常处置→生成报表”的全流程闭环。例如,西门子Industrial Copilot、施耐德EcoStruxure以及华为面向制造业的“盘古智能体”,都在大力推动“工业Know-how代码化”,使其成为可执行的智能体工程。
毕竟在生产实际场景中,真正创造价值的并非参数规模本身,而是融合了工艺参数、缺陷图谱、设备履历与专家经验的“专业智能”:谁掌握了更深厚的工艺知识,谁拥有更高质量的领域数据,谁更懂制造现场的隐性逻辑,谁就能在工业模型的构建中占据不可替代的生态位。
作为AI“五层蛋糕”的顶层环节,应用层是智能技术转化为商业价值与社会价值的最终出口,也是黄仁勋所强调的、AI产业经济效益的核心实现载体。进入2026年,AI应用摆脱单一工具属性,全面激活产业落地价值。
一方面,从辅助协作的Copilot模式,向自主决策与执行的Agent范式升级。Gartner预测至2026年末,将有近四成企业应用内嵌任务型AI智能体,实现流程自动化与业务自主化。这一趋势不仅发生在企业软件的后台,更以极具穿透力的方式进入个人桌面——年初掀起的OpenClaw“养龙虾”热潮便是缩影:用户通过自然语言指令,即可驱动AI智能体自主完成文件处理、报表生成、系统运维、跨平台协作等复杂任务,无需逐一手动操作。而当Agent能力从个人桌面延伸至工业现场,其价值便进一步放大。
例如在工业价值链的上游,AI正重塑产品诞生的方式。西门子Industrial Copilot已嵌入NX CAD与Simcenter CAE,工程师可用自然语言生成复杂曲面、自动完成网格划分与仿真求解;达索系统3DEXPERIENCE平台集成AI生成式设计,将材料力学约束转化为拓扑优化方案;Autodesk Fusion AI支持文本到3D模型的直接生成。这种“AI+工业软件”深度融合,不仅将设计周期从数周压缩至数小时,更将专家经验直接编码为可复用的设计模板,使中小制造企业也能获得前沿研发能力。
另一方面,AI应用的边界持续从数字空间向物理世界延伸,具身智能成为技术落地新热点。软件智能与硬件本体深度融合,让AI具备感知、移动、操作真实世界的能力。同时,AI加速向金融、医疗、制造、法律等知识密集型行业渗透,规模化落地路径日益清晰,投入产出比逐步验证,形成可复制的行业解决方案。
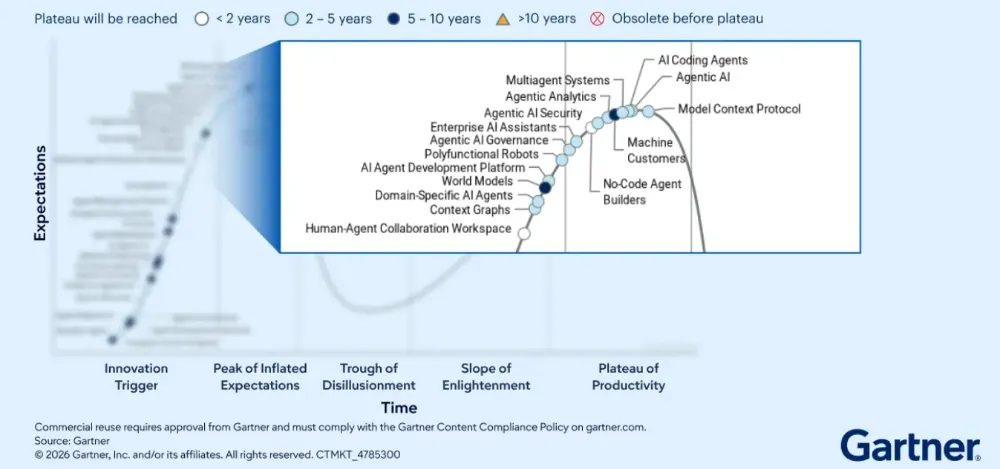
图14 2026 Agentic AI技术成熟度曲线
(来源:Gartner《2026 Hype Cycle for Agentic AI》)
以工业机器人与具身智能为例,Figure AI的Figure 03人形机器人可自主完成家务、洗碗、扫地、爬楼梯,特斯拉Optimus已进入特斯拉工厂执行电池分拣任务,优必选Walker S在新能源汽车工厂实现移动产线自适应行走,波士顿动力Atlas具备高动态运动能力。这些从实验室到产线的密集突破,标志着具身智能正从概念验证迈向规模化商用,物理世界与数字智能的融合已不可逆转。在黄仁勋看来,机器人技术是千载难逢的机遇,尤其对拥有强大工业基础的国家而言。

图15 基于NVIDIA Isaac Sim的机器臂抓取模拟演示(来源:《Advancing Robot Learning, Perception, and Manipulation with Latest NVIDIA Isaac Release》)
应用层位于AI产业链顶端,价值创造直接且多元,已在工业制造、金融服务、企业级软件与生产力工具等场景全面落地。在生产车间,AI视觉承担了表面缺陷检测,AI Agent接管了生产排程与物料调度,工艺工程师从繁琐的看屏盯表中解放出来,转而专注于新材料验证与核心工艺的突破。这一逻辑适用于所有知识密集型行业---AI自动化的是具体任务,而非替代岗位本身,最终以人机协同释放更大产业价值。
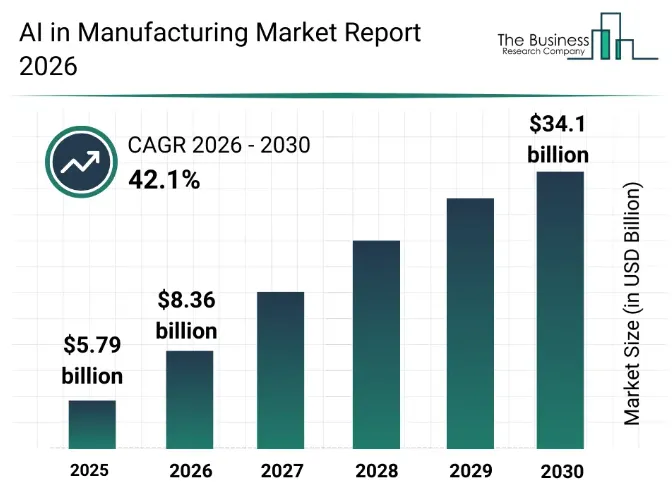
图16 制造业市场AI应用增长预测
(来源:The Business Research Company)
AI五层蛋糕各层级并非孤立存在,而是形成自上而下的强关联拉动机制。黄仁勋强调,每一款成功落地的AI应用,都会逐级带动下方每一层的需求扩张,最终传导至底层的能源供给环节,构建起完整的产业价值传导闭环。
从传导关系来看,应用层的规模化爆发直接驱动模型层快速迭代。2025年全球风险投资创下新高,大量资金涌向医疗、机器人、制造、金融等领域的AI原生企业,核心原因正是垂直行业模型的性能首次突破实用阈值,足以支撑上层应用的深度开发与落地。
模型层的普及则进一步带动基础设施层需求增长,以DeepSeekR1为代表的开源模型降低了应用开发门槛,在加速应用落地的同时,持续推高底层算力训练、数据中心、芯片与能源的整体需求。而基础设施层的巨额资本投入,又会反向拉动芯片与能源层的产能扩张与技术升级;当前全球已投入数千亿美元布局AI基础设施,这仅是产业起步阶段,未来数万亿美元级的投资规模将持续释放,台积电规划新建20座芯片工厂、美光启动2,000亿美元内存投资,正是这一趋势的直观体现。
可以看出,黄仁勋的AI“五层蛋糕”理论本质上是一场关于智能如何生产、分配、消费的工业革命蓝图,从能源到芯片,从基础设施到模型,再到最终的应用,每一层都相互依存、相互强化,构成了一个完整的工业体系。这一体系的核心特征在于物理世界的深度绑定,AI不再是纯粹的软件,而是需要消耗真实电力、占用真实土地、雇佣真实工人的实体产业,数千亿美元的投资只是开端,数万亿美元的建设狂潮正在路上。
可以断言的是,我们仍处于这场变革的早期阶段,大部分基础设施尚未建成,大部分劳动力尚未接受培训,大部分机遇尚未得到发掘,但方向已然明确,AI正在成为现代世界的基础设施,而我们此刻的选择、构建速度、参与度以及对它的应用方式,将最终决定这个时代走向何方。(本文完)


