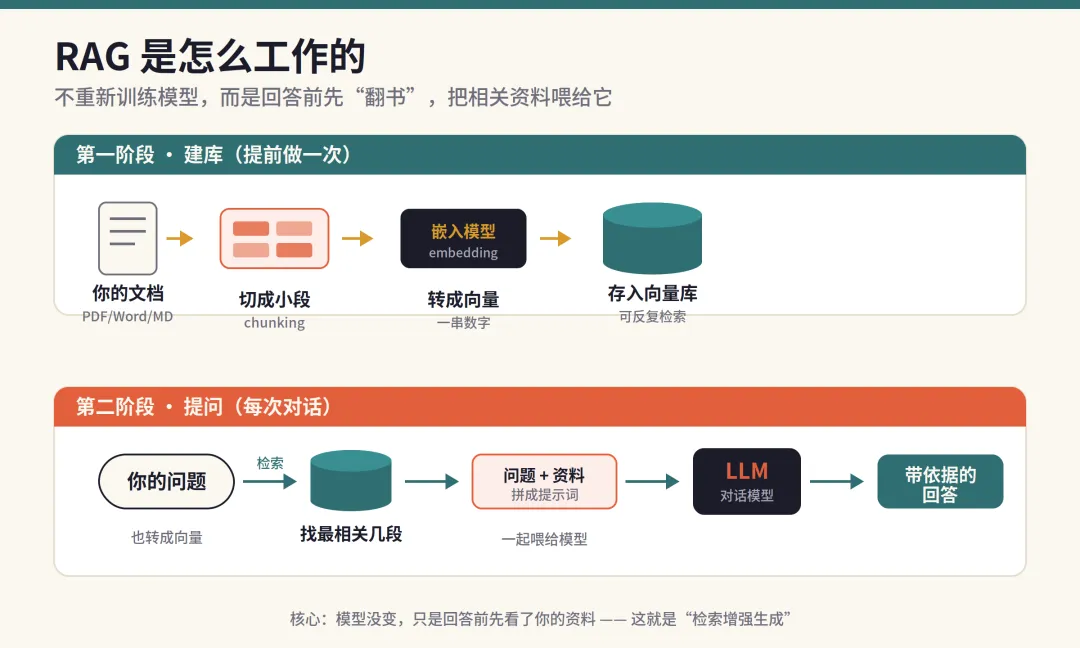
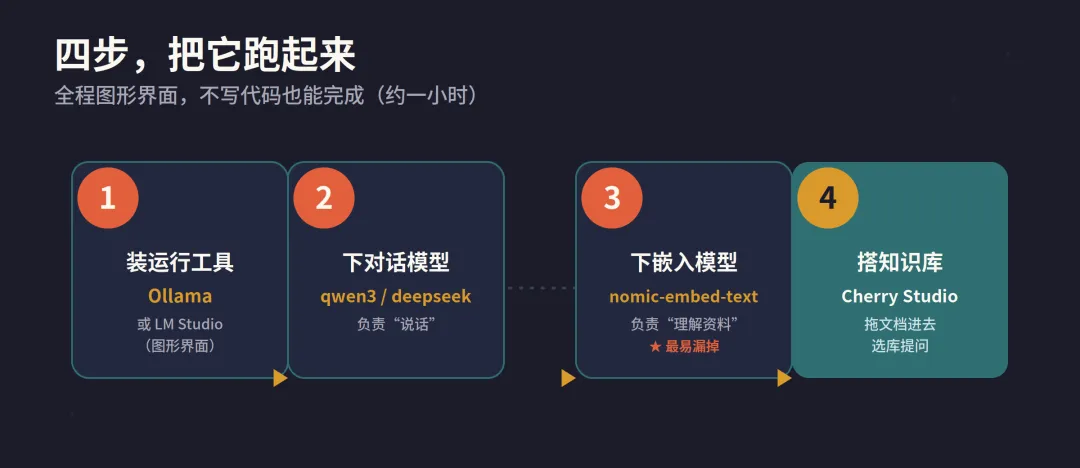
ChatGPT、Claude 用着很爽,但有三件事一直让人不踏实:一是隐私,公司合同、客户资料、个人笔记,每问一句都在往云端传;二是成本,几个会员订阅加 API 调用,一年下来不是小数目;三是离线,飞机上、内网里、信号差的地方,想用却连不上。 这篇教程就解决这三个痛点:把大模型装进自己的电脑,再喂给它你自己的资料,让它变成一个"读过你全部文档、还断网可用"的私人助手。整个过程不用写代码,跟着做,一小时就能跑起来。 先用一分钟搞懂 RAG 是什么 很多人以为"让 AI 读我的文档"就是把文件丢给它训练,其实不是。重新训练一个模型既贵又慢,普通人根本玩不起。真正实用的方案叫RAG(检索增强生成) ,思路特别朴素: 不改动模型本身,而是在它回答之前,先从你的资料库里"翻书",把最相关的几段内容找出来,连同你的问题一起递给模型,让它"看着资料回答"。 打个比方:模型是一个知识渊博但没读过你公司文件的专家,RAG 就是在他回答前,先帮他把相关那几页文件翻开摆在桌上。专家还是那个专家,但现在他能引用你的资料了。 它的完整流程是这样的:你的文档先被切成一小段一小段(chunking),每段用"嵌入模型"转成一串数字向量存进向量库;提问时,问题也被转成向量,系统在库里找出最相似的几段,拼进提示词喂给对话模型,最后生成带依据的回答。 准备工作:你的电脑够用吗 好消息是,2026 年的本地模型门槛已经很低,普通电脑也能跑。关键看内存(或显存): 8GB 内存:能跑 1B~3B 的小模型,回答速度尚可,适合做摘要、改写这类简单任务。 16GB 内存:能流畅跑 7B~8B 模型,这是体验和性能的甜点区,日常问答、知识库检索都够用。 32GB 及以上:可以挑战 14B~32B 模型,回答质量明显更好。 Apple Silicon(M 系列):统一内存架构对跑模型特别友好,同样内存下表现常常接近入门独显机器。 没有独立显卡也别灰心,纯 CPU 模式下跑量化后的 7B 模型完全可用,只是速度慢一些。先从小模型起步,跑顺了再往上加。 第一步:安装 Ollama,跑起第一个模型 Ollama 是目前最省心的本地模型运行工具,可以理解成"大模型界的 Docker"——一条命令拉模型,自带一个标准接口供其他软件调用。它安装包很小,启动快,资源占用低。 到官网下载对应系统的安装包,双击安装。装好后打开终端,输入一行命令就能下载并运行模型,比如运行一个中文表现不错的 8B 模型: ollama run qwen3:8b
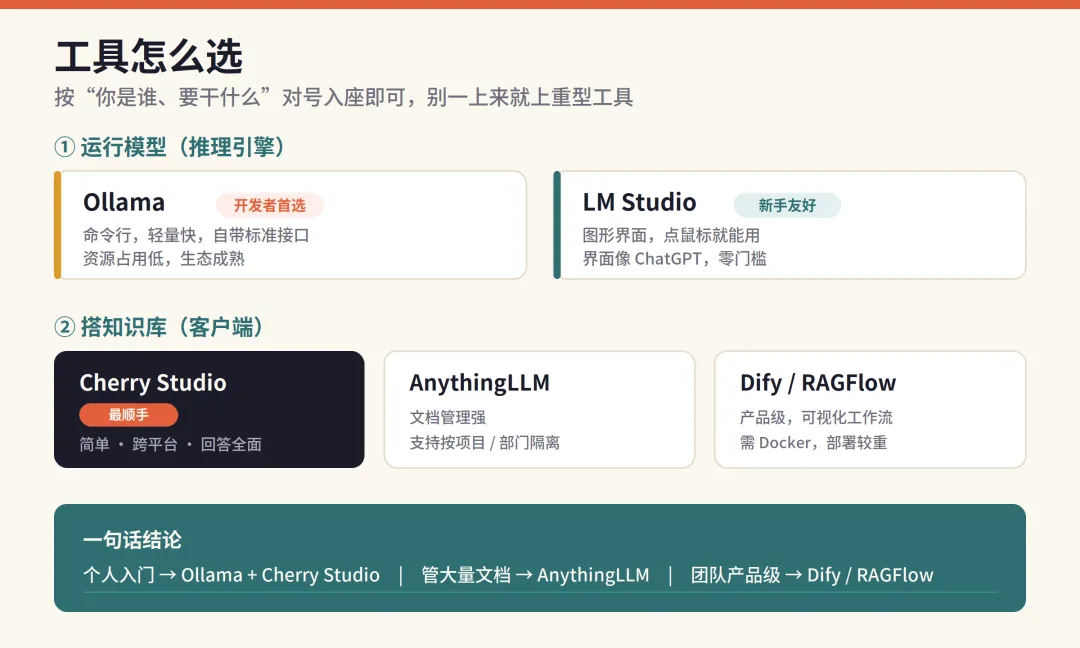
第一次会自动下载模型文件(几个 GB,取决于网速),下完之后直接进入对话,以后秒级启动。如果你完全不想碰命令行,可以换成LM Studio ——它是图形界面,搜索、下载、运行全靠点鼠标,界面和 ChatGPT 很像,对新手零门槛。两者引擎能力相近,区别只是命令行还是图形界面,按你的习惯选就行。 第二步:除了对话模型,还要装一个"嵌入模型" 这一步最容易被忽略,却是知识库能不能用好的关键。前面说过,RAG 要把文档转成向量,干这件事的是专门的嵌入模型(embedding model) ,它和聊天用的对话模型是两回事,必须单独下载。 ollama pull nomic-embed-text
记住这个搭配:一个对话模型负责"说话",一个嵌入模型负责"理解和检索文档" ,两个缺一不可。中文资料多的话,也可以选 bge 系列的中文嵌入模型,检索更准。 第三步:用客户端搭起知识库 模型就位后,需要一个"知识库客户端"把它们串起来。推荐两个免费、跨平台、纯界面操作的: Cherry Studio 是目前体验最顺手的一个,安装简单,Mac、Windows、Linux 都能用,知识库回答的全面性在实测里常常优于同类。AnythingLLM 则在文档管理和"工作区隔离"上更强,适合按项目、按部门把不同资料分开管理。以 Cherry Studio 为例,搭建过程就三件事:在设置里把模型来源指向本地 Ollama(地址填本机回环地址即可);分别选好对话模型和嵌入模型;然后新建一个知识库,把你的 PDF、Word、Markdown 拖进去等它处理完。之后在对话框选中这个知识库提问,AI 就会"看着你的资料"回答了。 工具怎么选,一张图说清 入门和个人用,Ollama + Cherry Studio 是最省心的组合。如果你要管理大量文档、做长期知识体系,用AnythingLLM 。如果是团队要做产品级应用、需要可视化工作流,再考虑部署更重的Dify 或RAGFlow ——但它们要 Docker、配置复杂,个人玩没必要上来就碰。 几个让效果立刻变好的实战技巧 很多人搭完发现"AI 答得不准",往往不是模型差,而是细节没调好: :每段太长会塞进无关信息,太短又会切碎语义。中文资料一般每段 300~500 字、相邻段落留一点重叠,效果比较稳。 嵌入模型选对:中文为主就用中文嵌入模型,别用纯英文模型硬扛,检索准确率差很多。 资料先清洗:扫描版 PDF 要先做文字识别(OCR),否则 AI"看不见"里面的字。表格、目录这类噪声尽量去掉。 提问要具体:知识库不是搜索引擎,问"第三季度华东区退货政策是什么"远比问"退货"得到的答案精准。 小模型起步:先用 7B/8B 跑通整个流程,确认搭法没问题,再换更大的模型提升质量,避免一上来就被硬件卡住。 几个常见的坑 模型下载卡住,多半是网络问题,可以配置国内镜像源或换时间段重试。回答驴唇不对马嘴,先检查是不是漏装了嵌入模型,或者知识库还没处理完。回答速度慢,要么是模型相对硬件偏大,要么是没用上 GPU,换小一号的量化模型通常立竿见影。 写在最后 本地大模型 + RAG,本质上是把"通用 AI"变成"懂你的 AI"。它不追求最强性能,而是把隐私、成本、可控性这三件事一次性解决。对个人来说,它是一个永远在线、读过你全部笔记的助理;对小团队来说,它是一个数据不出内网的知识中枢。 工具和模型每隔几个月就会更新,但这套"运行工具 + 对话模型 + 嵌入模型 + 知识库客户端"的骨架是稳定的。今天先把流程跑通,比等一个"完美时机"重要得多。
 夜雨聆风
夜雨聆风