 夜雨聆风
夜雨聆风
一台转手绢的机器人
2025年春晚,当宇树科技的人形机器人「福兮」穿着花袂转手绢的时候,台下观众惊呼连连。但很多人可能没意识到,那个转手绢的动作,比ChatGPT写一首诗要难一万倍。
为什么?因为ChatGPT只需要处理文字,而转手绢需要指尖感知力度、手腕控制角度、全身协调发力——这是完全不同维度的智能。
一个只会聊天的AI,和另一个能动、能看、能触碰世界的AI,差距就像「纸上谈兵的军师」和「身经百战的将军」。
这就是具身智能的核心问题: AI什么时候才能不只会说,还会做?
什么是具身智能
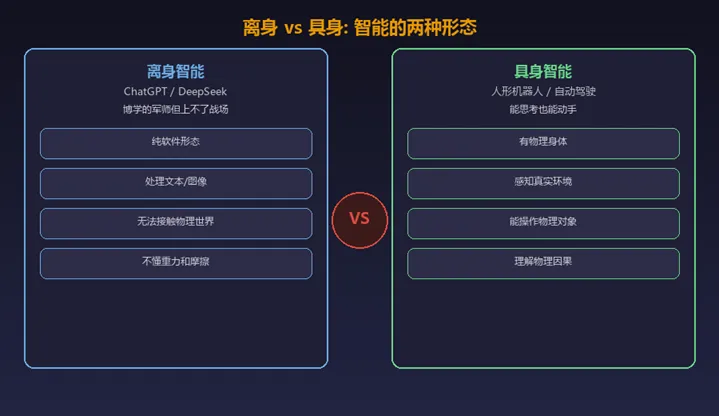
要想理解具身智能,最直接的方式是和它「反着来」的离身智能做个对比。
你平时用的ChatGPT、DeepSeek,都属于离身智能——它们没有身体,纯靠处理数据来生成内容。就像一个博学但手无缚鸡之力的军师,能给你出谋划策,却连一杯水都端不起来。
而具身智能,是「长着身体的AI」。它不再满足于在数字世界里打转,而是要走进真实世界,用传感器当眼睛,用机械臂当双手,用轮子或双腿当脚,去感知、去触摸、去操作。
举个生活里的小例子: 你让ChatGPT「帮我倒杯水」,它只能给你写一段倒水的步骤说明;但你让一台具身智能机器人倒水,它能走到厨房、找到杯子、打开水龙头、接水、稳稳端到你面前。
一个是「会说」,一个是「会做」。这就是最根本的区别。
76年进化之路
具身智能这个概念并不新,它比互联网还老。
早在1950年,图灵在《计算机器与智能》那篇开创性论文中,就提出过一种设想: 真正的智能不只是符号运算,还需要与物理世界交互。但当时连计算机都才刚诞生,这个想法太超前了。
接下来的几十年,学界一直在「要不要给AI一个身体」这个问题上争论不休。主张「不需要」的一方,做出了今天的ChatGPT;主张「需要」的一方,走了另一条路。
1986年,MIT的罗德尼·布鲁克斯提出「行为式机器人」——他认为智能不需要复杂的内部表征,而是通过身体与环境的互动自然涌现。说白了,就是你不需要预先告诉机器人「杯子是什么」,让它自己摸、摔、试,它自然会理解。
1991年,瓦雷拉等人正式提出了「具身认知」理论,从哲学和认知科学层面论证: 认知不是大脑的独角戏,而是大脑、身体、环境三者的合奏。
但理论归理论,真正让具身智能从学术概念变成产业热点的,是2023年大模型的爆发。当GPT-4这样的模型能给机器人当「大脑」的时候,技术拐点来了——一个能理解自然语言的大脑,配上一个能动的身体,具身智能终于从科幻走进了现实。
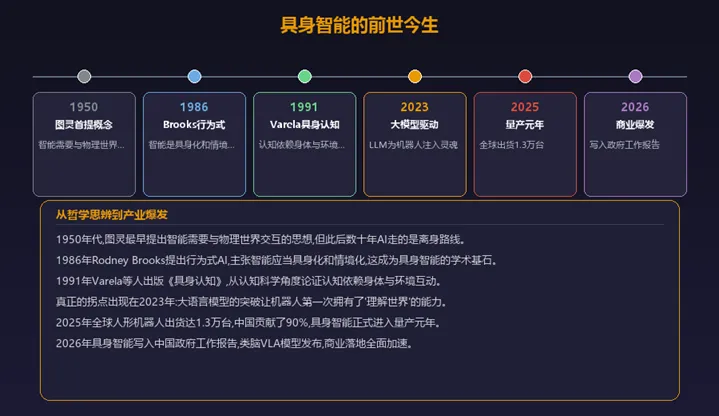
2025年,全球人形机器人出货量约1.3万台,中国制造占了90%。2026年3月,具身智能首次写入《政府工作报告》。从图灵的论文到国家战略,这条路走了76年。
三层架构: 大脑、小脑、肢体
搞具身智能,技术架构长什么样?最主流的说法是「三层架构」:

大脑层: 负责感知、认知和决策。这就是大模型的领地——VLA(视觉-语言-动作)模型、世界模型都在这一层。它要「看懂」场景、「听懂」指令、「想清楚」该怎么做。相当于人的大脑皮层。
小脑层: 负责运动协调和实时控制。再聪明的脑袋,手不听使唤也白搭。强化学习在这里发挥关键作用——通过大量试错训练,让机器人学会平稳走路、灵巧抓取、精准操控。相当于人的小脑。
肢体层: 负责物理执行。传感器(眼睛)、关节模组(肌肉)、灵巧手(手指)——这些是机器人真正「动手干活」的部分。没有好的肢体,再厉害的大脑也出不了手。
一个关键趋势: 2024年起,「大脑层」专利首次超过「肢体层」,整个行业从「把机器造出来」转向「让机器变聪明」。到2025年,大脑+小脑层占比已经接近77%。
两大核心技术: VLA与世界模型
2026年具身智能最热的两大技术话题,是VLA和世界模型。

VLA(Visual-Language-Action),翻译过来就是「视觉-语言-动作」一体化模型。传统做法是分步走: 先用视觉模型看,再用语言模型理解,最后用动作模型控制——三步各自为战,信息在传递中大量丢失。VLA则是一步到位: 看着场景,听着指令,直接输出该做什么动作。
打个比方: 传统方法像传话游戏——「我看到一个杯子」传给「我理解你要我拿杯子」再传给「我来伸手」; VLA则是直接「看到杯子就伸手拿」,不用传话,少了中间环节,动作更自然流畅。
世界模型, 简单说就是让机器人在行动之前先「想象」一下会发生什么。就像你伸手去拿杯子之前,脑子里会预判杯子在哪个位置、手伸多远能碰到——这就是世界模型在起作用。
2026年4月,全球首个类脑架构VLA具身大模型正式发布,标志着从「端到端VLA」迈向「类脑VLA」的新阶段。类脑VLA把大脑和小脑的功能融合在一起,就像人的大脑和小脑通过神经紧密协作,而不是各干各的。
全球竞速: 谁在抢跑
全球具身智能赛道,正在形成「两超多强」的格局。

中国整机制造阵营, 目前是绝对的出货主力。智元机器人以5100台位居2025年全球出货第一,宇树科技以4200台紧随其后,优必选以1000台位列第三。三家加起来,占了全球出货量的近80%。更惊人的是,全球每10台人形机器人,有9台是中国造。
美国科技巨头阵营, 走的是另一条路。特斯拉Optimus把大模型推理能力注入机器人, Figure AI与OpenAI合作打造「会思考的工作者」,波士顿动力则在运动控制上独步全球。美国的优势在大模型和算法,中国的优势在制造能力和供应链。
中国互联网大厂阵营(百度、华为、小米),手握生态和场景优势。华为人才外溢催生了一批具身智能创业公司,百度在萝卜快跑自动驾驶上的积累也能迁移到人形机器人,小米则从消费级机器人入手跑马圈地。
商业化元年: 四大场景加速落地
2026年被称为具身智能的「商业化元年」,四大场景正在加速落地。

工业制造, 是商业化最明确的战场。优必选Walker S已经进入蔚来汽车工厂,负责装配和搬运; 3C电子领域对精密抓取需求旺盛;仓储物流是刚需场景。制造业的需求清晰、付费能力强,是第一个跑出商业闭环的赛道。
商业服务, 目前还在试水阶段。酒店接待、商场导购、送餐配送——这些场景对交互能力要求高,但客单价低,ROI模型还没完全跑通。宇树的机器人已经在多家酒店提供迎宾服务。
医疗健康, 门槛最高、潜力也最大。手术辅助的精度要求极高,康复护理需要与人体安全交互,药品配送则相对容易实现。达芬奇手术机器人已经证明了「AI+精密操作」的可行性。
特种作业, 是刚需中的刚需。核电站巡检、矿井作业、火灾救援——这些「人不能去、但必须有人去」的场景,天然适合机器人替代。云深处的四足机器人已经在矿井中执行巡检任务。
据预测, 2026年全球具身智能市场规模将突破900亿元,中国市场占比超过65%。到2035年,市场规模有望突破万亿元。
未来已来: 四大趋势与三大挑战

具身智能的未来,不仅仅是「机器人做得更像人」这么简单。四个趋势值得关注:
通用化: 从专机专用到一机多用。就像智能手机取代了相机、MP3、导航仪,未来的通用型机器人有望在同一个硬件平台上完成多种任务。
群体协作: 多机器人编队协同,是下一个技术前沿。想象一座工厂里几十台机器人像蜂群一样分工协作——有的搬运、有的检测、有的装配,彼此实时通信、动态调度。
认知进化: 从「你让我做我就做」到「我知道该做,不需要你告诉我」。当世界模型足够强,机器人不仅能执行指令,还能主动发现问题、提出解决方案。
人机共融: 从工具变成伙伴。未来的机器人不只是帮你干活,还能理解你的情绪、预判你的需求,成为真正的智能伙伴。
当然,挑战同样巨大: 数据稀缺(真实世界数据远比互联网数据难获取)、安全与伦理(机器人出了事故谁负责)、成本与规模化(一台几十万,何时走进千家万户)?这些问题,每一个都是硬仗。
但有一点是确定的: 当AI长出了身体,它就不再只是屏幕里的一段对话,而是和你一起走在路上的伙伴。这不是科幻,这是正在发生的现实。
