 夜雨聆风
夜雨聆风2026年5月,AI芯片公司Cerebras登陆纳斯达克,募资55.5亿美元,首日收盘市值约670亿美元[4]。这家公司的核心产品只有一样——一颗和餐盘一样大的芯片。这颗名为WSE-3的晶圆级引擎集成了90万个计算核心、4万亿晶体管,面积达46,225平方毫米,约等于一整片12英寸晶圆。
与此同时,特斯拉的Dojo超级计算机正沿着另一条晶圆级路线演进——通过台积电InFO_SoW先进封装技术,将25颗自研D1芯片在载体晶圆上集成为一颗逻辑统一的处理器。而台积电披露的下一代CoW-SoW技术路线图,更计划将超过40个光罩面积的硅片与高达60颗HBM芯片垂直集成[1]。
将一颗常规尺寸的GPU放大到一整片晶圆的规模——这个看似疯狂的想法,正在从实验室走向工业化。它背后的技术逻辑是什么?工程上如何实现?效果到底如何?本文将围绕「晶圆级计算架构」这一主题,从技术演进、实现路线、工程挑战、架构设计和未来方向五个维度展开。
一、为什么需要晶圆级计算?
1.1 传统芯片架构的瓶颈:三堵墙
传统芯片制造的标准流程是:晶圆光刻→切割→挑选良品→封装→PCB板级互联。这套流程极其成熟,但它在一个根本问题上做出了妥协:数据在不同芯片之间的搬运,需要跨越越来越慢的物理边界。
这种妥协在AI大模型时代暴露为三堵墙:
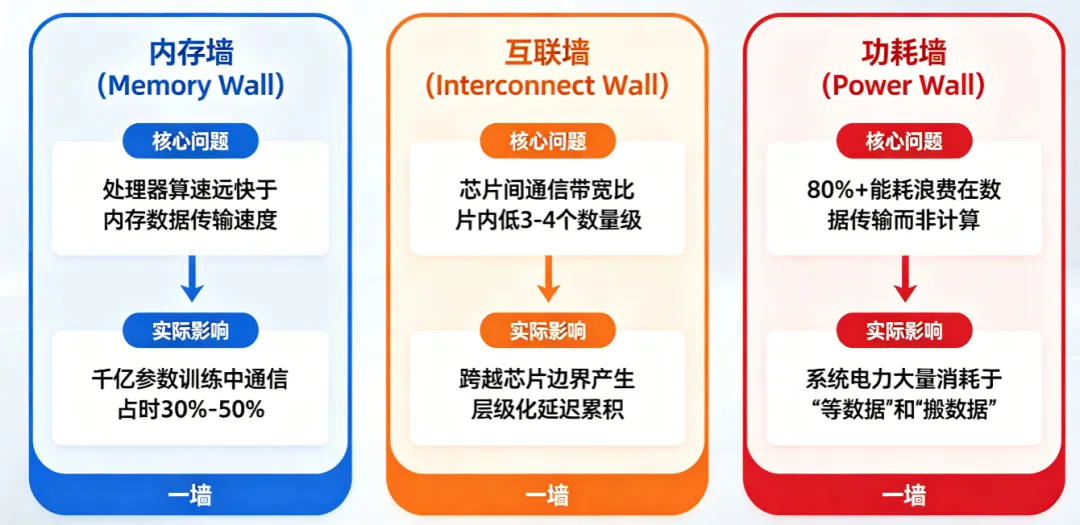
图1:传统芯片架构面临的「三堵墙」——内存墙、互联墙、功耗墙
内存墙:处理器计算速度远快于数据从内存传输到处理器的速度。
互联墙:当系统从单芯片扩展到多芯片集群时,即使采用最先进的NVLink或InfiniBand,芯片间通信带宽仍比片内通信低3-4个数量级。
通信层级 | 典型带宽密度 | 相对延迟 |
片内(on-chip) | TB/s级别 | 基准(1×) |
片间封装级(UCIe等) | 数百GB/s | ~10× |
板级(PCB走线) | 数十GB/s | ~100× |
机架级(NVLink/IB) | 数GB/s | ~1000× |
功耗墙:数据搬运不仅消耗时间,还消耗能量。在AI集群中,80%以上的能耗浪费在数据传输上,70%以上的成本花在数据存储上。系统的大部分电力不是花在「计算」上,而是花在「等数据」和「搬数据」上。
三堵墙指向同一个根源:芯片边界本身。每当你把晶圆切割成小芯片再通过封装和PCB把它们连起来,你就在人为地制造通信瓶颈的层级累积。
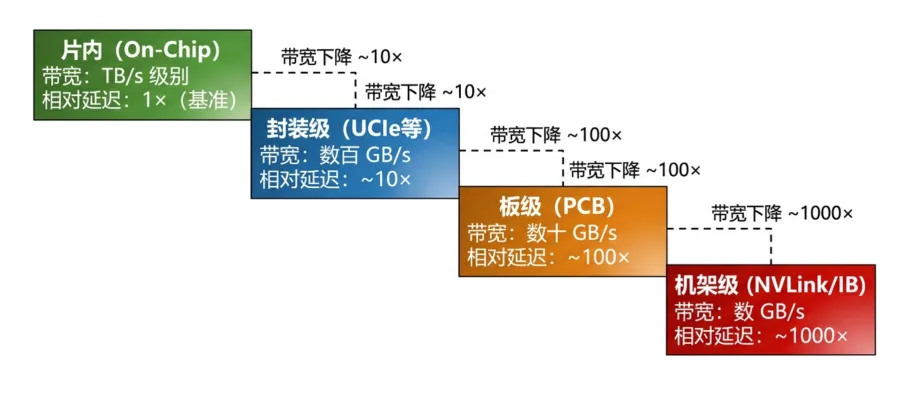
图2:不同通信层级的带宽衰减——片内到机架级相差3-4个数量级
τ定律的视角:2026年ISCAS会议上提出的τ定律框架,将上述三堵墙统一为「时间常数τ的累积」问题——信号跨越物理边界的时间远远超过了信号在器件内部切换的时间。τ定律由此提出范式转换:半导体优化的目标应从摩尔定律的「把晶体管做小」(几何缩微),转向「把信号传快」(时间缩微)。晶圆级计算,正是这一范式在物理层面最激进的实践。
1.2 Chiplet路线:折中方案
在讨论晶圆级计算之前,有必要先看另一种试图解决三堵墙的方案——Chiplet(芯粒)路线。
Chiplet不追求单一超大芯片,而是将不同功能模块分别制造成较小的芯粒,再通过先进封装技术(如硅桥、中介层)紧密互联。代表案例包括AMD MI300系列和Intel Ponte Vecchio。
Chiplet将「100×→1000×」的PCB/机架级延迟跳跃压缩到了「~10×」的芯粒间延迟——进步显著,但它并未消除「跨芯片」这个基本事实。芯粒间互联仍需要跨越die边界,协议栈开销和物理走线延迟仍然存在。
晶圆级计算走了一条更激进的路:从物理上消除芯片边界本身。
二、晶圆级计算的两条技术路线
晶圆级计算并非只有一种实现方式。当前业界存在两条差异显著的技术路线:单片集成和芯粒晶圆级集成。
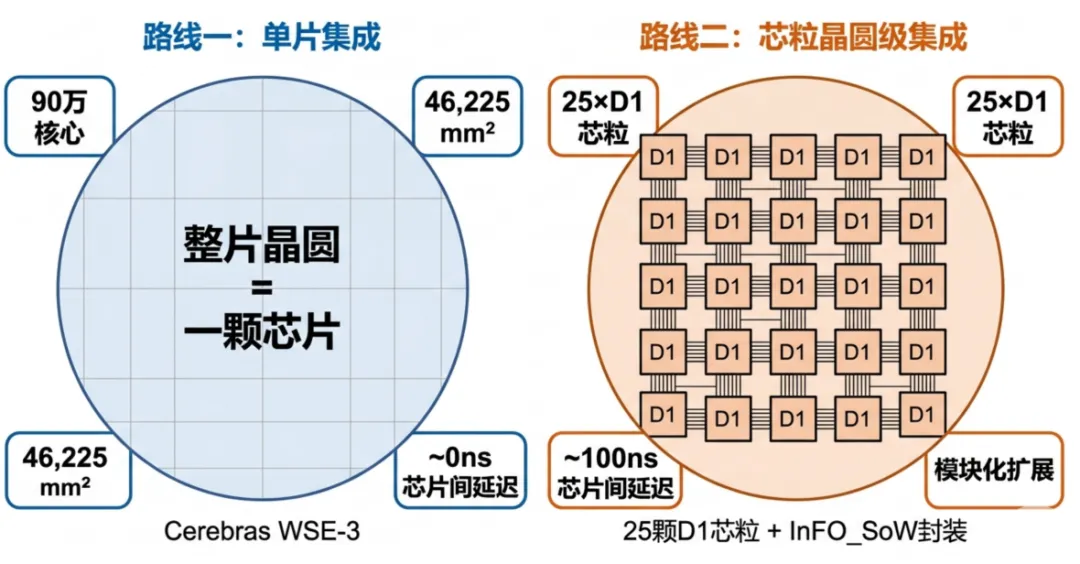
图3:晶圆级计算两条技术路线对比——单片集成vs芯粒晶圆级集成
2.1 路线一:单片集成—Cerebras WSE-3
Cerebras的方案最纯粹:将整片12英寸晶圆作为单一芯片进行设计和制造。
WSE-3核心参数:
参数 | 数值 |
制程工艺 | 台积电5nm |
芯片面积 | 46,225mm² |
晶体管数量 | 4万亿 |
物理核心数 | 97万个(含冗余) |
可用计算核心数 | 90万个 |
片上SRAM | 44GB,21PB/s带宽[1] |
AI算力 | 125PFLOPS@FP16[2] |
典型功耗 | 约23kW[3] |
片上互联总带宽 | 214Pb/s[3] |
Cerebras将这颗巨型芯片封装为CS-3系统——一个以完整机柜形式交付的AI推理/训练设备,单台售价约200-300万美元[1]。配合外部MemoryX内存扩展系统(最高1.2PB),单台CS-3可支持最高24万亿参数的AI模型而无需手动分区[1][2]。
架构设计理念:Cerebras WSE-3的架构设计完全颠覆了传统GPU的思路,核心是数据流驱动和原生稀疏计算两大理念。它没有采用传统GPU中少量强大的通用核心,而是在整片晶圆上部署了90万个高度简化的计算单元——每个核心面积仅0.05mm²,约为H100 SM核心的1%[3],只保留了AI计算必需的算术逻辑和本地存储。这种设计的核心理念非常朴素却极其有效:与其让少数强大核心大部分时间都在等待数据,不如让海量简单核心随时待命,数据一到就立即处理。
2.2 路线二:芯粒晶圆级集成—TeslaDojo
特斯拉的Dojo超级计算机代表了另一条思路:不追求单颗芯片覆盖整片晶圆,而是通过先进封装将多颗常规尺寸的芯粒在晶圆尺度的基板上紧密集成,在电气特性上逼近单片集成的效果。
D1芯片:Dojo的基础芯粒
参数 | 数值 |
制程工艺 | 台积电7nm |
芯片面积 | 645mm²[5] |
晶体管数量 | 500亿(单芯粒)[1];每TrainingTile含25颗D1,合计1.25万亿 |
计算核心数 | 354个(18×20网格,6个冗余禁用)[5] |
单芯片算力 | 362TFLOPS(BF16/CFP8)[5] |
片上SRAM | 440MB(约1.25MB/核心)[1] |
单芯片功耗 | 约600W[1] |
与WSE-3中高度简化的计算核心不同,D1的每个核心是一个完整的可编程处理器——基于RISC-V指令集自定义扩展,具备完整的取指、译码、执行流水线。每个核心包含4个8×8×4矩阵乘法单元,支持FP32、FP16、BFP16和CFP8等多种数据精度[5]。
InFO_SoW:晶圆级的芯粒集成
特斯拉Dojo采用台积电的InFO_SoW封装技术,将25颗D1芯片以5×5阵列排布形式集成在一块完整的载体晶圆上,而非传统PCB板。通过填充虚拟芯片和高密度RDL层,25颗独立芯片在通信上如同一颗统一处理器,实现了100ns的超低延迟和2TB/s的超高带宽。最终单个Training Tile能提供9PFLOPS的AI训练算力,总功耗为15kW[1]。
从Training Tile到ExaPOD:层次化扩展
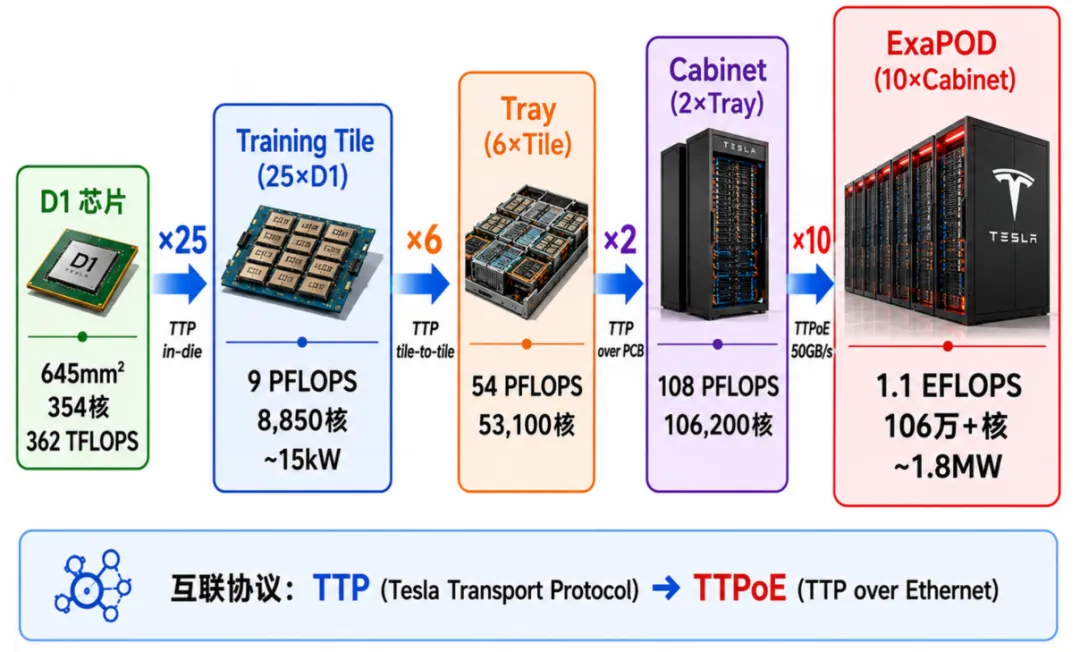
图4:Tesla Dojo层次化扩展架构——从D1芯片到ExaPOD
Dojo的扩展策略严格层级化:
- 25颗D1→1个Training Tile(训练瓦,9PFLOPS)
- 6个Training Tile→1个Tray(托盘)
- 2个Tray→1个Cabinet(机柜)
- 10个Cabinet→1套ExaPOD(1.1EFLOPS,106万+核心,3000颗D1,全系统功耗约1.8MW[1])
Training Tile之间通过特斯拉自研的TTP协议(Tesla Transport Protocol)互联,单链路900GB/s;跨机柜则通过TTPoE(TTP overEthernet)承载,单链路50GB/s。
2.3 两条路线的对比
维度 | 单片集成(Cerebras WSE-3) | 芯粒集成(Tesla Dojo) |
集成方式 | 整片晶圆光刻,跨光罩拼接 | 常规芯片制造+InFO_SoW封装集成 |
核心设计 | 高度简化(90万核) | 完整可编程处理器(354核/片) |
芯片间延迟 | 趋近于零(全片内) | ~100ns,仍远优于传统互联 |
良率策略 | 片上冗余+缺陷绕行 | 小芯片高良率,缺陷芯片直接替换 |
工艺依赖 | 必须依赖最先进制程(5nm) | 可用成熟制程(7nm) |
扩展方式 | 单芯片固定规模 | 模块化「铺地砖」式横向扩展 |
核心总数 | 90万(单芯片) | 8,850(单Training Tile)/106万+(ExaPOD) |
成本 | ~$200-300万/系统[1] | 特斯拉自用,不对外销售 |
两条路线的本质分歧在于对芯片间通信延迟的不同权衡:
单片路线:用极高的工程复杂度(跨光罩拼接、缺陷绕行、全片散热)换取芯片间延迟趋近于零
芯粒路线:接受~100ns的轻度跨die延迟,换取良率可控、制程灵活、模块化扩展的工程优势
比喻:单片晶圆级相当于把所有人搬到一栋巨型建筑里——内部通勤时间趋近于零,但这栋楼的设计、建造和维护成本极高。芯粒晶圆级相当于用封闭天桥把几栋楼连起来——走天桥比过大马路快得多,但毕竟不如在同一栋楼里。
应用场景决定了路线选择:Cerebras面向通用AI推理市场,用户对响应延迟极度敏感,单片路线的极致低延迟是核心卖点。Dojo专为特斯拉自身的FSD(全自动驾驶)模型训练定制,算法相对固定,对超低延迟的需求弱于对可扩展性的需求,芯粒路线的模块化优势更加匹配。
三、工程挑战:把晶圆做成一颗芯片有多难?
将整片晶圆作为单一芯片来制造,碰到的工程挑战与传统芯片完全不同。这里聚焦三个最具代表性的领域。
3.1 良率:缺陷管理的范式转换
传统芯片制造中,一片12英寸晶圆上可能有几十到上百个随机缺陷。切割成数百颗小芯片后,只需淘汰有缺陷的芯片即可,良率可控。
但晶圆级芯片不能这样做——任何一个缺陷都会在芯片上制造一个「死区」。当芯片面积从常规的数百mm²暴增到46,225mm²(WSE-3),完全不出现缺陷的概率几乎为零。
核心解法:冗余架构+缺陷绕行。WSE-3实际制造了约97万个物理核心,量产版本启用90万个,冗余率约7%[3]。出厂前通过测试定位所有缺陷位置,将缺陷区域的电路永久禁用,数据流自动绕开。这类似于互联网中路由器的「绕行」机制——一条路断了,数据包自动走另一条路。
由于WSE-3单个核心面积仅约0.05mm²,每个缺陷只损失极小的硅面积,而GPU的SM核心面积约5-6mm²,单个缺陷的损失约为WSE-3的100倍以上[3]。在台积电5nm工艺约0.001个/mm²的缺陷密度下,WSE-3的硅面积利用率仍可达93%[3]。
芯粒路线的取巧:Tesla Dojo从根源上绕开了这一难题。D1芯片面积仅645mm²,属于常规尺寸,良率可控;25片D1在集成前被逐个测试、筛选,坏芯片直接替换。代价是接受~100ns的跨die延迟——用微小的延迟增加换取巨大的良率优势。
3.2 散热:功率密度的极限挑战
当90万个核心集成在一片晶圆上全速运转,功耗密度远超传统芯片。WSE-3典型功耗约23kW,Training Tile约15kW——分别相当于约10台和7台家用空调同时运转,但热量集中在餐盘大小的面积上。
核心解法:系统级直接液冷。Cerebras CS-3系统采用冷却液直接流经芯片表面的设计方案,以完整机柜形式交付,集成了冗余电源、泵组和冷却分配单元。Tesla Dojo同样采用水冷方案,Training Tile的供电电流高达18,000安培[6],对供电和散热系统的设计要求极高。
3.3 光刻:跨越光罩边界的拼图
光刻机单次曝光的最大面积受限于光罩尺寸(reticle limit),通常不超过约858mm²。WSE-3的46,225mm²意味着需要数十次曝光才能覆盖。
核心挑战在于:如何在多次独立曝光之间实现无缝衔接。跨光罩边界的金属连线必须在宽度和对准精度上完美匹配,否则会导致信号完整性问题和延迟跳变。
核心解法:跨光罩拼接(Cross-Reticle Stitching)。台积电为Cerebras专门开发了这项技术——在相邻曝光区域之间设计精密的互联结构,使得数十次独立曝光的电路在电气特性上表现为一个连续的整体。
四、架构设计精髓
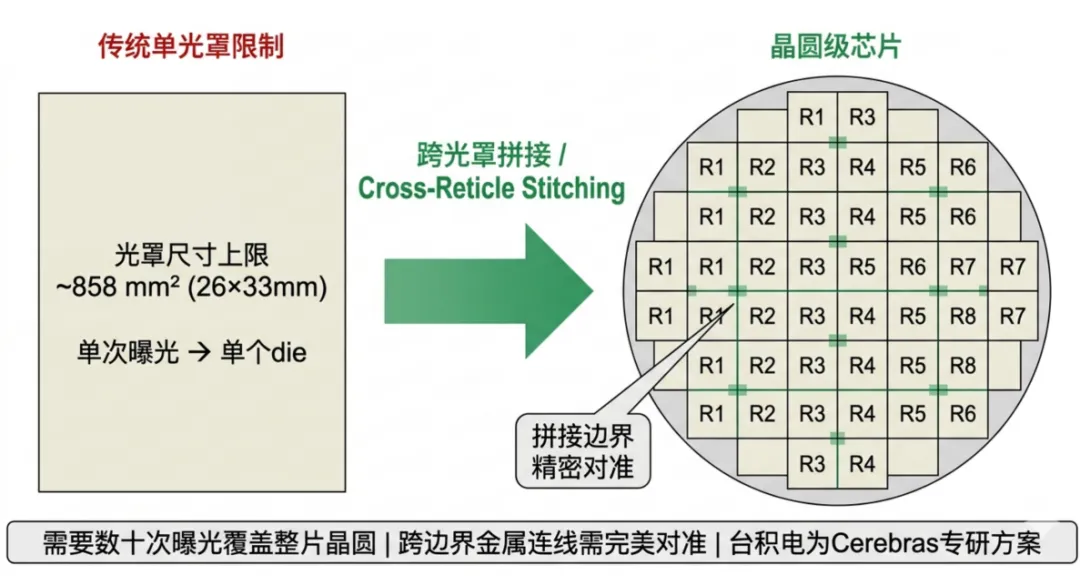
图5:跨光罩拼接(Cross-Reticle Stitching)技术原理示意
回到芯片架构本身,晶圆级芯片在设计层面与传统GPU存在根本性差异,主要体现在三个维度。
4.1 片上互联:从协议栈到物理走线
WSE-3的Swarm通信架构采用二维网格(2DMesh)拓扑,所有90万核心通过片上网络直接互联,总聚合带宽达214Pb/s[3]。作为对比,NVIDIA H100的NVLink 4.0片间互联带宽为900GB/s(约7.2Tb/s)——WSE-3的片内通信带宽约为其约3万倍。
更关键的差异在于通信路径的复杂度:
传统多GPU通信:计算核→片上网络→PCIe/NVLink控制器→物理层→线缆→对端物理层→控制器→片上网络→计算核
晶圆级芯片通信:计算核→片上网络→计算核
传统方案需要穿越多级协议栈和物理层转换,每一环都在增加延迟。晶圆级的做法是把互联协议变成物理走线——因为不需跨芯片,所以不需要协议栈。延迟从微秒级直接降到了纳秒级,压缩了约三个数量级。
4.2 内存层次:用面积换带宽
WSE-3与GPU最大的架构差异之一在于存储层次:
WSE-3 | NVIDIA H100 | |
片上SRAM | 44GB,21PB/s带宽[1] | 50MB L2 Cache |
外部高带宽内存 | 外挂MemoryX DRAM(权重流) | 80GB HBM3 |
内存模型 | 计算核心直接访问全片上SRAM | 多级缓存+显存层次 |
WSE-3选择「巨大统一片上SRAM」路线的本质是用面积换带宽。44GB SRAM虽然小于H100的80GB HBM3,但所有核心访问任意SRAM地址的延迟是统一且极低的——不存在GPU中L1 miss→L2 miss→HBM访问的多级延迟惩罚。
配合权重流(Weight Streaming)架构:模型权重参数存储在外部MemoryX DRAM中,按需以流的方式加载到片上SRAM进行计算。权重搬运的延迟与计算的延迟实现流水线化重叠,使得内存访问延迟在宏观上被隐藏。
4.3 编程模型:硬件的复杂度由编译器承担
传统多GPU编程需要开发者处理数据并行、模型并行、流水线并行等复杂的分布策略——本质上,开发者需要手动管理数据的物理位置和通信时机。
晶圆级芯片将物理上的90万核心抽象为一个逻辑统一的编程空间。开发者在Cerebras软件栈中无需显式管理核心间通信或数据分布——编译器自动将计算图映射到二维网格上,分析数据依赖关系,优化路由。从传统GPU集群迁移到WSE的程序,代码量可减少到原来的1/10甚至更少。
这种设计理念的关键在于:将架构的复杂性从程序员的手动负担,变成了编译器的自动优化。它降低了晶圆级芯片的使用门槛,也部分弥补了其软件生态相对CUDA不够丰富的问题。
五、实际效果与适用边界
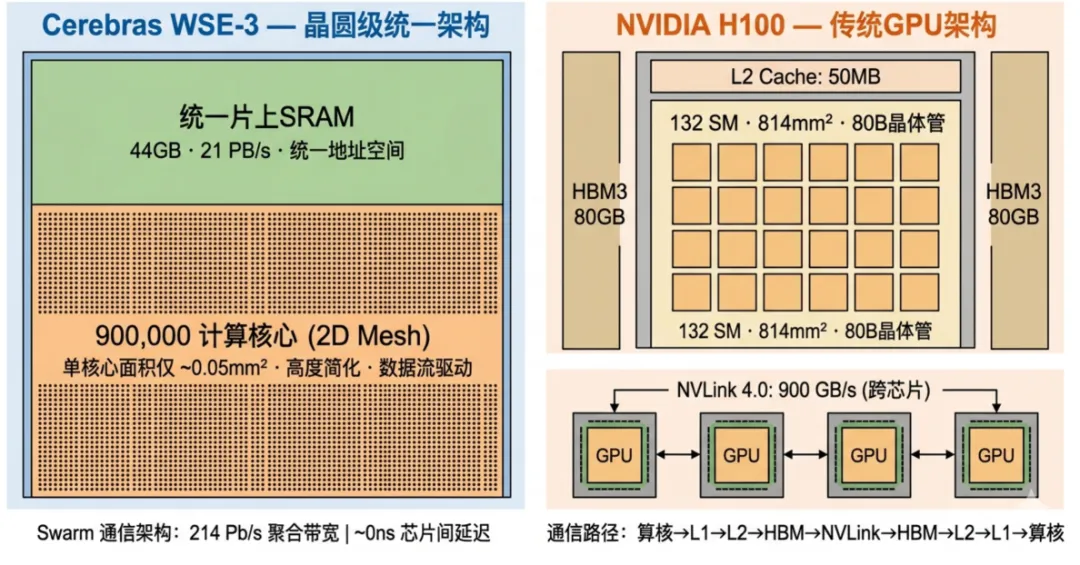
图6:WSE-3晶圆级架构vsH100传统GPU架构对比
架构设计上的优势能否转化为真实应用场景中的性能提升?晶圆级计算的局限又在哪里?
5.1 推理性能:低延迟场景的结构性优势
在公开的benchmark评测中,WSE-3在LLM推理任务上的性能显著优于主流GPU方案。以Llama 3.1 8B模型(16位精度)为例,WSE-3可达1,800+tokens/s,而同等条件下H100的最高性能约242tokens/s——两者相差约7.4倍[1]。
这种优势的根源不是「算得更快」,而是「搬得更快」。推理过程中自回归生成的每一步都需要传递KV cache——在GPU集群中,每次KV cache访问可能需要跨越片内→HBM→NVLink→对端HBM→对端片内等多个层级;在WSE中,KV cache直接放在44GB统一SRAM中,任何核心的访问都处于同一延迟域。
这也解释了为什么OpenAI会与Cerebras签署超过200亿美元的多年推理算力合作协议[7]——大规模在线推理对响应延迟极为敏感,晶圆级架构在这个维度上有结构性优势,这种优势无法通过堆叠更多GPU来弥补。
5.2 训练性能:集合通信瓶颈的消除
对于大模型训练,传统GPU集群中集合通信(All-Reduce等)的开销可占整体时间的50%以上。WSE在单芯片范围内几乎不受此限制——所有数据搬运都属于片内通信。
一个具体的benchmark:由2,048台WSE-3系统组成的集群(总理论算力约256 EFLOPS)可在一天内完成Llama 2 70B模型的训练,比Meta原始训练集群快约30倍[1]。此外,论文[1]指出WSE-3在相同功耗下实现了两倍于前代WSE-2的训练吞吐量。单台CS-3系统配合MemoryX内存扩展,可支持最高24万亿参数的AI模型而无需手动分区[1][2]。
但需要指出:当模型规模超过单颗WSE的存储和算力容量时,跨WSE芯片的扩展仍需面对延迟重新累积的问题——晶圆级芯片的单片优势很强,多片扩展并非其强项。Dojo通过层次化架构(Training Tile→Tray→Cabinet)在一定程度上缓解了这一问题。
5.3 适用边界:不是万能解药
晶圆级计算的局限性同样值得正视:
成本门槛高:单台CS-3系统约200-300万美元[1],而单颗H100 GPU约2-4万美元。对于延迟敏感度不高的场景,GPU集群在TCO上更具优势。
灵活性受限:一整片晶圆意味着架构被全局统一优化,无法像GPU集群那样为不同任务配置不同的资源分布策略。晶圆级方案的架构优化是「全有或全无」的。
RAS能力不足:RAS(可靠性/可用性/可维护性)是服务器级系统的核心指标,晶圆级计算存在明显短板。其单片集成架构故障爆炸半径较大,单点物理故障可能会造成整片晶圆失效、设备整体下线,且无法像GPU集群那样灵活的实现故障模块隔离、热插拔替换,运维容错能力弱;现有冗余机制主要针对制造阶段静态缺陷,对运行中的动态故障防护能力有限。
迭代周期长:重新设计一整片晶圆级芯片的工程复杂度远高于设计常规尺寸芯片,每一步改动都需要重新考虑对全局互联和功耗分布的影响。
生态相对封闭:GPU的CUDA生态历经二十年沉淀,工具链、函数库与开发框架体系成熟、适配广泛。而晶圆级计算软件栈高度定制垂直,通用开发生态不完善,适配性与拓展性偏弱。
硬件供应链单一:传统GPU集群支持组件解耦,软硬件配件多厂商供应,供应链开放且迭代灵活。晶圆级计算采用整机集成架构,核心软硬件均由单一厂商定制,外部厂商介入空间极低,用户存在深度厂商锁定问题,议价能力弱、系统迁移成本高,制约规模化商用。
峰值能效并非全面领先:在峰值TFLOPS/W指标上,WSE-3约5.4 TFLOPS/W,H100约7.9 TFLOPS/W[1]。但论文[1]同时指出WSE-3实现了"2× perf/W vs WSE-2"的代际提升,且GPU集群中跨芯片通信消耗了大量额外能量,使得实际有效能效远低于峰值标称值。结合论文[1]提供的H100单并发请求延迟约12ms的数据(vs Dojo 100ns),可以看出通信效率对整体性能的决定性影响。此外,WSE-3的硅面积利用率达93%,而同等缺陷密度下多GPU方案的硅面积损失约为其164倍[3],从晶圆级到系统级的整体效率需要综合评估。
核心判断:晶圆级计算的核心价值在于应用场景适配性。其优势集中在延迟敏感度高、大规模并行计算场景,可牺牲部分可用性与供应链自由度换取极致性能;而延迟敏感度低、高可用刚需、需要灵活迭代与开放供应链的场景,传统GPU集群在综合成本与可靠性上更具优势。
──────────────────────────────────────────────────
六、技术演进方向
6.1 推理成为主战场
随着大模型从「训练军备竞赛」进入「推理规模部署」阶段,推理算力的需求增速已超过训练算力。推理对延迟的敏感度远高于训练——用户不会接受「请等待5秒钟,GPU正在搬运数据」。
这正是晶圆级计算最匹配的应用场景:延迟敏感度高、架构优势明显、能承受相应的工程成本。Cerebras与OpenAI的合作印证了这一趋势。
6.2 CoW-SoW:3D集成的纵向突破
台积电已披露的CoW-SoW(Chip-on-Wafer-on-Substrate-on-Wafer)路线图代表着晶圆级计算的下一个阶段:在InFO_SoW晶圆级平面的基础上,叠加CoWoS先进封装和SoIC 3D堆叠,将高带宽存储(HBM)与晶圆级计算平面垂直集成。下一代Dojo系统有望实现算力40倍以上提升,集成超过40个光罩面积的硅片和高达60颗HBM芯片[1]。
本质上,这是两个维度同时推进:
水平方向(晶圆级扩展):扩大单芯片面积,消除更多横向的芯片边界
垂直方向(3D堆叠):通过逻辑-存储垂直堆叠缩短信号路径
6.3 光互联:突破多晶圆扩展瓶颈
跨晶圆扩展的根本瓶颈在于电互联的延迟和功耗累积。随着硅光子技术的发展,片间光互联可能成为突破多晶圆扩展的关键技术。据近期学术研究披露,近封装光互连引擎单模块带宽可达8 Tb/s,将信号传输距离从传统方案的约100厘米缩短至5厘米,通信距离可从1米拓展到100米。光互联不产生焦耳热,不受电磁干扰,延迟的物理极限远优于铜互联。
对于晶圆级计算而言,光互联意味着:当单片晶圆的互联延迟已被压到极致后,光互联是继续压缩晶圆间延迟的最有希望的手段。
6.4 可重构计算的融合
一种值得关注的技术趋势是,将可重构计算架构(如CGRA粗粒度可重构阵列)与晶圆级集成相结合。传统固定架构的芯片在出厂后数据流特性就已固化,但AI工作负载是多样化且快速演进的。可重构计算的核心思路是「软件定义硬件」——硬件电路可根据不同算法在纳秒级时间内动态重组。
如果在一整片晶圆上部署高度灵活的可重构计算单元,理论上可以实现运行时数据流优化——不仅互联延迟被压到很低,而且数据流路径可以根据当前任务自适应调整。这是晶圆级计算从「静态架构优化」走向「动态架构优化」的潜在方向。
结语
晶圆级计算的新颖性不在于「做得更大」,而在于它触及了一个此前被视为理所当然的假设:芯片的物理边界不是天经地义的——它只是一种制造便利性的妥协。而这种妥协的代价,在AI大模型时代变得不可承受。
从1980年代Gene Amdahl创立Trilogy Systems进行晶圆级集成的失败尝试,到2026年Cerebras以约670亿美元市值登陆纳斯达克[4]、特斯拉Dojo将芯粒晶圆级集成推向工业化——晶圆级计算跨越了近半个世纪。它证明了一件事:当半导体行业把注意力从「开关有多快」转向「信号有多快」,那些曾经被认为「过于激进」的架构设想,可能会重新定义计算的边界。
晶圆级计算不会替代GPU。但在AI推理成为算力主战场的时代,它代表了一个新的设计空间:在这个空间里,核心优化目标不再是「单位面积塞进多少晶体管」,而是「数据到达计算单元需要多少纳秒」。
参考文献:
[1] Ozkan, M. et al. "Performance, efficiency, and cost analysis of wafer-scale AI accelerators vs. single-chip GPUs." Device 3, 100834 (2025). https://doi.org/10.1016/j.device.2025.100834
[2] Cerebras Systems. "Cerebras Systems Unveils World's Fastest AI Chip with Whopping 4 Trillion Transistors." Press Release (2024). https://www.cerebras.ai/press-release/cerebras-announces-third-generation-wafer-scale-engine
[3] Cerebras Systems. "100x Defect Tolerance: How Cerebras Solved the Yield Problem." Cerebras Blog (2025). https://www.cerebras.ai/blog/100x-defect-tolerance-how-cerebras-solved-the-yield-problem
[4] TechStackIPO. "Cerebras IPO 2026: Nasdaq CBRS." (2026).https://www.techstackipo.com/ipo/cerebras
[5] Talpes, E. et al. "The Microarchitecture of DOJO, Tesla's Exa-Scale Computer." IEEE Micro 43(3), (2023). https://doi.org/10.1109/MM.2023.3258906
[6] Tom's Hardware. "Tesla's wafer-sized Dojo processor is in production." (2024). https://www.tomshardware.com/tech-industry/teslas-dojo-system-on-wafer-is-in-production-a-serious-processor-for-serious-ai-workloads
[7] The Information. "OpenAI Agrees to Pay Cerebras More Than $20 Billion Over Three Years." Reported by multiple Chinese financial media (2026).
──────────────────────────────────────────────────
