 夜雨聆风
夜雨聆风🚀 2026年5月:AI编程的"诸神之战"
2026年4-5月,AI大模型行业迎来了史上最密集的升级周期。OpenAI、Anthropic、Google、DeepSeek 四大阵营集中发布旗舰模型,百万 Token 上下文、代码能力、多模态效果全面突破。
核心变化:不再是"能不能写代码",而是复杂工程重构、推理深度、端到端 Agent 自动化。Django 之父 Simon Willison 甚至预言:到2026年底,仍然认为AI代码都是垃圾的人将站不住脚。
今天这篇文章,结合自身实测和 SWE-bench、LiveCodeBench、ARC-AGI-2 等权威榜单,盘一盘程序员最常用的6款AI大模型,以及我的使用建议。本文对比数据截止2026年5月,可以放心参考。
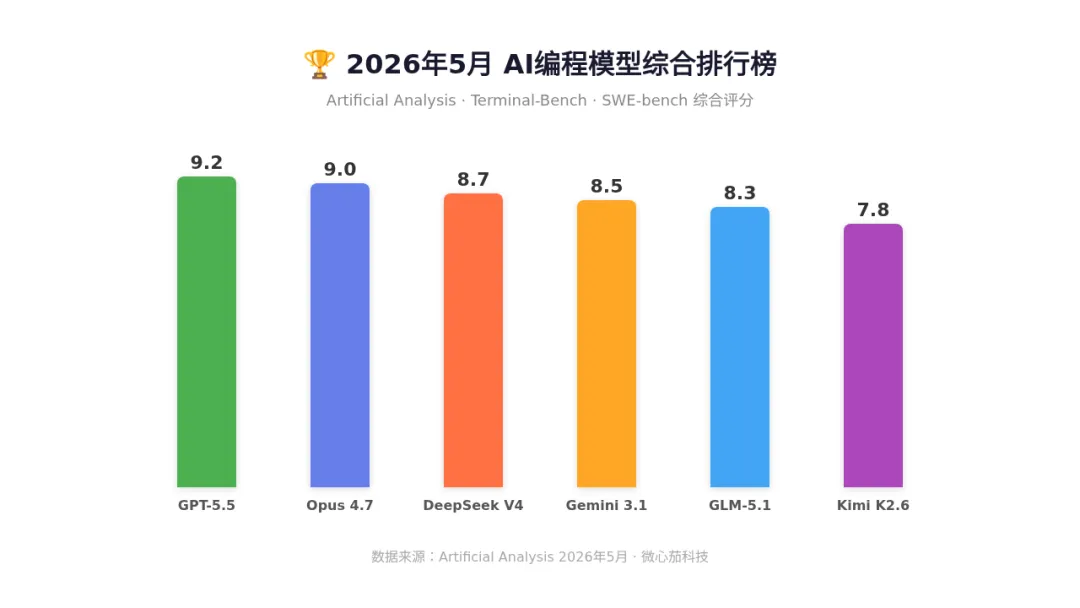
👑 Claude Opus 4.7:编程天花板,登顶全球
2026年4月16日发布,Anthropic 的 Opus 4.7 在全球 AI 综合排名中以 1503 分登顶。LMArena Coding Arena 盲测中以 1350 分位列第一,编程能力是目前的天花板。
|
💎 Claude Opus 4.7 关键数据 |
|
✅ SWE-bench Pro:64.3%(复杂编程任务冠军) |
新特性:Opus 4.7 新增了任务预算功能(API beta),可以给模型效率建议;新增 xhigh 推理档位,介于高与最大之间;视觉识别全面升级,能直接分析架构图和 UI 设计稿。
实测场景:用它重写一个3000行遗留系统的支付模块,一次通过单元测试。同任务 GPT-5.5 需要两轮调试,DeepSeek V4 三轮才过。Opus 4.7 在复杂架构设计、跨模块调试、长上下文分析方面目前没有对手。
适合人群:追求极致代码质量的团队,预算充足的情况下,用它做代码评审和复杂架构最合适。
🤖 GPT-5.5:Agent时代的全能战士
OpenAI 在4月24日发布 GPT-5.5(代号 Spud),5月5日推出 GPT-5.5 Instant 作为 ChatGPT 默认模型。它的野心不是"写代码",而是"替你完成整个工作流"。
|
⚡ GPT-5.5 关键数据 |
|
✅ Terminal-Bench:82.7%(Agent编程最高分) |
最大突破:GPT-5.5 提供多级推理强度(极高/高/中/低/无推理),这是能力与成本的权衡。更高推理带来更好结果,但消耗更多 Token。核心创新是"词元效率"——不只看单次调用成本,而是看完成任务的总成本。GPT-5.5 在多项任务上的 Total Cost 比 5.4 低 40%。
实测场景:让它搭建一个 API 数据采集 → 清洗 → 入库 → 可视化 Dashboard 的完整流水线,GPT-5.5 在 Codex 环境中自主完成了 80% 的工作,从写代码到部署一步到位。如果你在搭建 AI 自动化工作流,GPT-5.5 是目前的最佳引擎。
🧠 Gemini 3.1 Pro:推理之王
Google 的 Gemini 系列一直主打"推理",3.1 Pro 版本更是把这个优势发挥到了极致。在评估全新逻辑模式处理能力的 ARC-AGI-2 基准测试中,实测得分 77.1%,是上一代的两倍多。
|
🔬 Gemini 3.1 Pro 核心优势 |
|
✅ GPQA Diamond:94.3%(知识推理最高分) |
适用场景:如果你经常处理算法题、数据科学研究、数学建模,Gemini 3.1 Pro 是最佳选择。它能直接读取公式截图并给出完整推导过程,这在教育科研场景中非常实用。
💼 Claude Sonnet 4.6:日常主力均衡之选
如果 Opus 4.7 是法拉利,那 Sonnet 4.6 就是丰田凯美瑞——够快、够稳、够便宜。价格:输入$3/百万token,输出$15/百万token,综合性价比评分 7/10。在中等复杂度的编程任务上,Sonnet 4.6 的表现和 Opus 差距不到 15%,但价格只有 Opus 的 60%。
实际使用:我日常 80% 的中等复杂编码任务都用 Sonnet 4.6 完成,包括 CRUD 接口编写、单元测试补充、代码重构等。只有遇到极复杂架构设计时才切到 Opus 4.7。
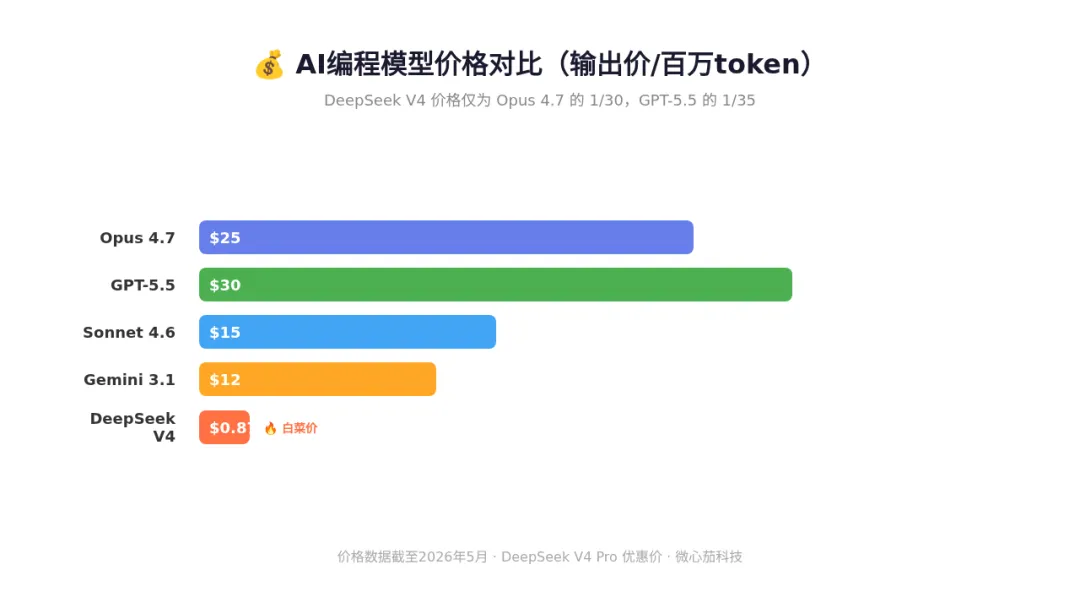
⚡ DeepSeek V4:价格屠夫,国产之光
4月24日发布的 DeepSeek V4,直接打出"1%成本实现90%能力"的王牌。有 V4 Pro(1.6T 参数/激活49B)和 V4 Flash(284B/13B)两个版本,支持 1M Token 上下文,开源权重和技术报告。
三大创新主打长上下文:Compressed Sparse Attention(CSA)、Heavily Compressed Attention(HCA)、Manifold-Constrained Hyper-Connections(mHC),KV 缓存降至传统方案的 10%。在 1M 上下文下,单词元推理 FLOPs 仅为 V3.2 的 27%。
|
💰 价格暴击对比(每百万token) |
|
🔥 V4 Flash:输入$0.0028,输出$0.28 — 日常首选 |
实测体感:我近一个月日常编码全用 DeepSeek V4 Flash,每月成本不到 50 元,效率完全没降。唯一的短板是极端复杂的架构设计稍逊于国际顶流,但日常场景完全够用。个人开发者和中小团队首选,没有之一。
🔥 GLM-5.1 & Kimi K2.6:国产双雄
GLM-5.1(智谱)——3月28日发布,距5.0仅一个月,编程能力冲到国产第一梯队。核心突破是从"单点强"到"全栈能打",SWE-bench 58.4%,GPQA Diamond 85.7%。适合政企系统、中文业务全栈开发,网络稳、沟通成本低。
Kimi K2.6(月之暗面)——200万 Token 上下文窗口(目前公开模型最长),开源生态完善,支持本地部署和微调。在跑分上不如 DeepSeek V4 亮眼,但胜在灵活可定制。如果你需要处理超长中文文档或在本地部署模型,Kimi K2.6 是最优选择之一。
国产模型的进步让我觉得,我们的模型不再是"凑数的",而是能真正解决本土开发者痛点的——网络稳、沟通成本低、适配国内生态,这些都是国际模型比不了的。
💡 实战选型:智能路由策略
没有一款模型能通吃所有场景。下面是实测最优的智能路由策略,成本节省85%,性能损失不到5%:
| 流量 | 模型 | 场景 | 月成本 |
| 70% | DeepSeek V4 Flash | 日常编码、简单任务 | ¥30 |
| 25% | Claude Sonnet 4.6 | 中等复杂度任务 | ¥200 |
| 5% | Claude Opus 4.7 | 复杂架构、极致质量 | ¥300 |
📌 写在最后:2026下半年AI编程还有哪些看点
2026年5月的AI编程战场已经进入白刃战阶段。但更值得关注的是接下来:GPT-6 预计2026年5-7月发布,Claude 5 也已在路上。下半年将是更激烈的竞争。
圈子里的共识是:2026年,人类程序员手写代码的比例将下降到个位数。这个数字听起来恐怖,但换个角度想——这意味着程序员的角色将从"写代码"升级为"做决策"。架构设计、业务抽象、AI调度、代码评审,这些才是未来的核心能力。
不迷信单一模型,灵活组合才是2026年程序员的正确姿势。选对工具,编程效率翻倍;灵活组合,才不被时代甩下。
|
👆 觉得有用?点个关注不迷路 关注【微心茄科技】,持续分享AI编程实战干货 🚀 |
