 夜雨聆风
夜雨聆风一个人就是一支产品团队
你之前一个人做过完整的产品吗?
大概是这样开始的——
打开 Claude,告诉它:"帮我做一个完整的 SaaS。"
然后等待。
等待 API 响应。等待代码生成。等跑起来。
报错。粘贴错误信息。再等待。
又报错。再等。
两小时后,你还在修同一个 Dashboard 的样式问题。
这不是在做产品。
这是在花钱玩"氛围编码"(Vibe Coding)。
而真正懂的人,已经不用一个模型干所有活了。
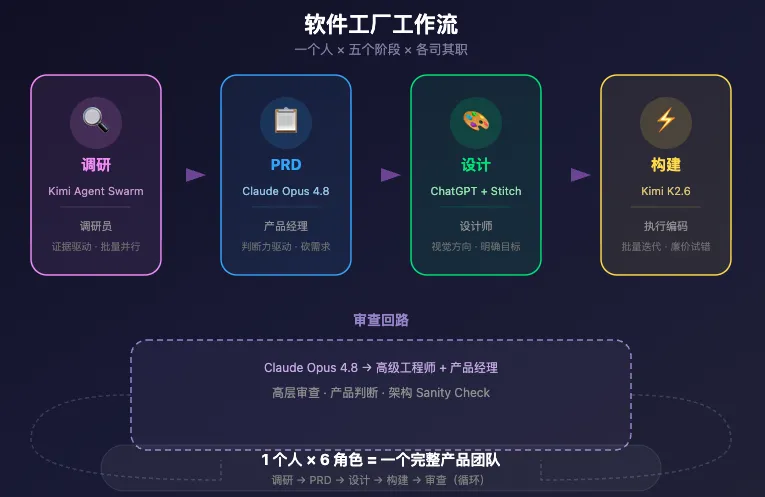
他们建了一个软件工厂。
一个人,多个 AI 模型,各司其职,两周搞定一个可上线的 MVP。
今天,我把这个完整工作流公开给你。
核心思维:别把 AI 当一个聊天机器人
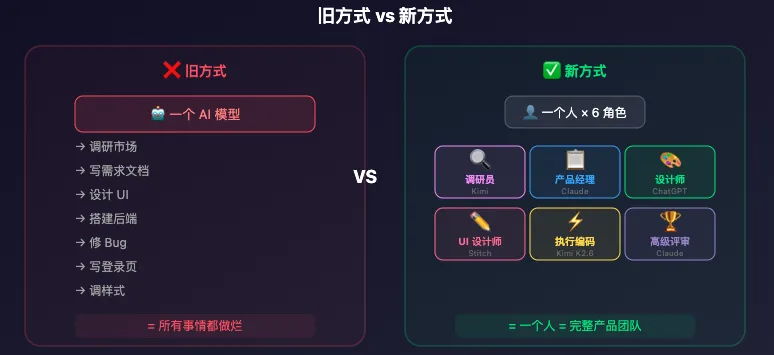
大多数独立开发者的错误,是从一开始就把 AI 当成全能助手。
"调研市场。写需求文档。设计 UI。生成图标。搭建后端。修 Bug。写登录页。"
听起来很美好。但很快就会崩。
因为每个任务的需求截然不同:
- 调研
需要广度,要同时看几十个来源 - 产品需求
需要判断力,要决定什么不该做 - 设计
需要视觉方向 - 编码
需要廉价的大批量试错 - 审查
需要深度推理
一个模型能做所有事。
但一个模型不应该做所有事。
软件工厂的本质,是一个路由系统——每个模型只干它最擅长的那件事。
为什么 Claude 不应该包揽一切
Claude Opus 4.8 是目前最强的深度推理模型之一。
用它来做这些:
→ 产品方向判断→ 架构决策→ PRD 撰写→ 边界情况分析→ 代码审查→ 战略制定
但绝不要用它来跑那两小时的"构建循环"。
构建是脏活。
你要改需求。要重新生成文件。要跑测试。要贴错误信息。要调样式。要改数据库字段。要同一个组件重写四次。
这就是为什么 Claude 的速率限制让你痛苦——不是因为 Claude 不好,而是你在用昂贵的"思考模型"干便宜的"重复执行活"。
Claude 应该是架构师。
不是那个一遍遍写同样表单的实习生。
价格差异决定了你的工作流
建产品的时候,Token 成本不是理论问题,是实际每一轮循环都在烧的钱。
Claude Opus 4.8 API 定价:
→ 输入 $5 / 1M tokens→ 输出 $25 / 1M tokens
Claude Opus 4.8 快速模式:
→ 输入 $10 / 1M tokens→ 输出 $50 / 1M tokens
Kimi K2.6 API 定价:
→ 输入约 $0.95 / 1M tokens→ 输出约 $4 / 1M tokens→ 缓存输入可以更低
Kimi Code:
→ 包含在 Kimi 会员中,可用于编码→ 在终端和 VS Code 中使用→ 支持第三方编码代理→ 使用共享会员额度→ 基于 Kimi K2.6 驱动
这就很清楚了:
一个模型适合昂贵决策,另一个适合大量迭代。
Claude 是你花钱的地方。Kimi 是你迭代的地方。
这才是真正的杠杆。
关键问题不是"哪个模型更好?"
而是"哪个模型干哪个活?"

第一步:用 Kimi Agent Swarm 做市场调研
不要一上来就写代码。
先用 Kimi 做调研。
打开 Kimi,使用 Agent Swarm / Deep Research 功能。同一个 Kimi 订阅,后面编码还能继续用。
不要问:"给我 10 个创业点子。"
那只会得到显而易见的废话。
要让 Kimi 启动多个独立调研代理,每个代理搜索不同方向的市场信号:
Reddit 上的抱怨帖 Quora 上的求助问题 G2 / Capterra 上的差评 App Store 的低分评论 YouTube 视频评论区 LinkedIn 行业讨论 招聘网站上的岗位需求 竞品定价页 垂直行业论坛
目标不是想象。
目标是证据。
你要找的是人们已经在讨论的痛点,已经在付费的产品,以及还没有被好好解决的断 Workflow。
什么样的机会最好?
通常是最无聊的。
不是"AI 约会 App"。不是"创始人社交网络"。不是"又一个 AI 写作工具"。
而是:
→ 重度依赖 Excel 的业务→ 靠 WhatsApp/微信运营的团队→ 手动做报表→ 合规工作→ 昂贵的人工→ 重复行政→ 又烂又贵的旧软件→ 没有技术团队的行业→ 还在用邮件做流程的场景→ 人们每周都恨之入骨的任务
诊所、房产中介、会计事务所、招聘公司、仓库、物流公司、室内设计师、学校、酒店、建筑公司……
这些企业不想要 AI 演示。
他们想要节省时间。减少错误。增加收入。
让 Kimi 杀死弱点子
大多数创业点子听起来不错,5 分钟后就不行了。
所以要让 Kimi 主动验证、主动拒绝:
→ 这个痛点够痛吗?→ 有人已经在为此付费吗?→ 为什么还没人被解决?→ 2 周能做出 MVP 吗?→ 我能触达前 10 个客户吗?→ 买家是谁?清楚吗?→ 工作流重复频率高吗?→ AI 能 10 倍改进吗?
aggressively 拒绝弱点子。
你不需要 100 个点子。
你需要1 个有证据支撑的点子。
第二步:用 Claude Opus 4.8 写 PRD
Kimi 找到方向之后,暂停调研,把结果交给 Claude。
这才是 Claude 最值回票价的地方。
给 Claude 的东西:
→ Kimi 调研结果→ 痛点证据→ 目标客户画像(ICP)→ 竞品缺口→ 工作流细节→ 定价思路→ 2 周 MVP 范围→ 前 10 个客户获取策略
然后让它写一份完整的 PRD(产品需求文档)。
Claude 应该把杂乱的调研变成结构化的产品规格。
一份好的 PRD 包含:
- 产品总结
——做什么、给谁做、解决什么痛点、为什么有人付费 - 目标客户(ICP)
——角色、公司规模、现有工具、购买触发条件 - 痛点分析
——多痛、多频繁、花多少钱、不解决的后果 - 现有替代方案
——软件、表格、WhatsApp、邮件、人工,以及各自为什么不行 - 产品定位
——一句话定位、首页标语、核心承诺 - 核心工作流
——用户从注册到完成价值的每一步 - MVP 功能范围
——必须做的、应该做的、不做的(这个最重要) - 用户故事
——As a [user], I want to [action], so that [outcome] - 数据模型
——表结构、字段、关系、索引 - 页面清单
——每个页面的功能、组件、主操作、空状态 - API / 后端需求
——接口、定时任务、第三方服务 - AI 功能定义
——输入、输出、Prompt 行为、兜底方案 - 定价策略
——免费版要不要、付费档位、价值指标 - 2 周构建计划
——每天的目标和验收标准 - 上线计划
——前 10 个客户怎么触达、演示什么、什么优惠 - 风险评估
——产品、技术、分发、付费意愿 - 成功指标
——激活、使用、留存、收入
重点强调"不做什么"。
MVP 死于多写功能,比死于少写功能的概率高得多。
Claude 擅长说:"这个第一版不需要。"
这就是你用它的理由——不是因为它的按钮写得好,而是因为它想得更好。
第三步:设计先行,再编码
PRD 定下来之后,不要急着写代码。
先用 ChatGPT 生成视觉素材。
App 图标、Dashboard 插图、空状态图形、引导页视觉、落地页图片、小图标……
大多数独立开发者上线丑产品,不是因为审美差,而是因为他们觉得"设计会拖慢进度"。
但你需要的是一个视觉方向,不是完美设计。
视觉素材让产品在后端还没写完时就感觉真实。
同时也能帮助后面的编码模型理解产品调性——
这是一个诊所工具?一个房产 Dashboard?一个仓库操作系统?还是一个获客机器?
视觉方向会改变 AI 的编码输出。
再用 Google Stitch 设计 UI 界面。
把 PRD 给它,让它设计:
→ Dashboard→ 引导流程→ 核心工作流页面→ 设置页→ 定价页→ 空状态→ 移动端响应式
然后把这些交给 Kimi。
如果你告诉 AI 编码模型:"做一个好看的 Dashboard。"
它会给你每个人都在用的那种通用 SaaS 界面。
但如果你给它:PRD + UI 设计稿 + 视觉素材 + 明确工作流
它就能构建出一个接近真实产品的东西。
设计先行,构建在后。
第四步:用 Kimi K2.6 低成本构建
现在 Kimi 回来了——这次是作为执行者。
给它:
→ Claude 写的 PRD→ Stitch 的 UI 设计→ ChatGPT 的视觉素材→ 技术栈选择→ 文件夹结构→ 数据库 schema→ 实施计划
然后让它开始构建。
Kimi 用来做:
→ 项目脚手架→ CRUD 操作→ 用户认证→ Dashboard 页面→ API 接口→ 数据库模型→ 后台任务→ 样式调整→ 重构→ 测试
这就是廉价 Token 真正发挥价值的地方。
构建从来不是一次 Prompt 就能搞定的。
构建是这样的循环:
Prompt → 运行 → 报错 → 修复 → 再运行 → 改需求 → 调样式 → 重构 → 测试 → 上线
你不想用 Claude 的配额跑这个循环。
用 Kimi 干这个脏活累活。
第五步:Claude 回来做最终审查
Kimi 构建完成之后,再请 Claude 回来。
不是让它重写整个应用。
让它审查。
问它:
→ 这个产品符合 PRD 吗?→ 还缺什么?→ 什么会让用户困惑?→ 什么应该砍掉?→ 有什么风险?→ 什么上了线会崩?→ 上线前应该修什么?
Claude 这时候的角色是高级工程师 + 产品经理。
高层审查。产品判断。架构 sanity check。
不是当代码生成器用。
完整工作流一览
把上面所有步骤串起来:
一个人。
六个角色。
每个模型干它最擅长的事。
旧方式:一个 AI 模型,把所有事情都做烂。
新方式:调研员 + 产品经理 + 设计师 + UI 设计师 + 执行编码 + 审查员。全在一个工作流里。
大多数人还在问 AI:
"帮我做一个 App。"
而能赢的人问的是:
"哪个模型干哪个活?"
为什么这个工作流有效
因为它匹配了每个模型的真正优势:
Claude Opus 4.8 是你的架构师。
它贵,因为它擅长判断。用它在关键的决策点上。
Kimi 不只是 Claude 的替代品。
它是你的调研集群 + 构建引擎。便宜、快速、量大。
ChatGPT 是你的视觉素材生成器。
让编码模型有视觉方向,输出质量天差地别。
Google Stitch 是你的 UI 设计师。
给 AI 编码一个明确的视觉目标。
它们组合在一起,形成了一个闭环:
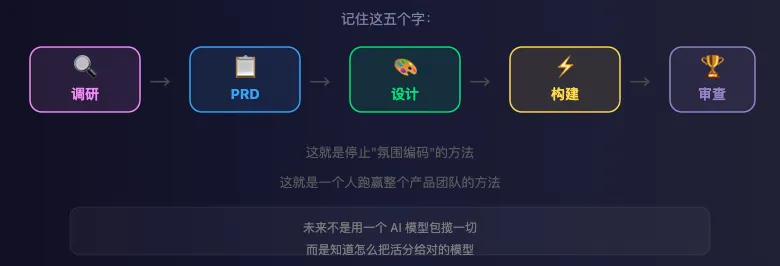
调研 → PRD → 设计 → 构建 → 审查
这就是停止"氛围编码"的方法。
这就是一个人跑赢整个产品团队的方法。
这个未来不是用一个 AI 模型包揽一切。
这个未来是知道怎么把活分给对的模型。
国产模型:现在不够,但进步值得鼓励
这里有一个绕不开的问题:国产模型在这个工作流里算什么角色?
Kimi 是国内产品,确实进来了。但更广泛的国产大模型——比如通义千问、文心、智谱、月之暗面 Moonshot——在深度推理和编码能力上,目前和 Claude Opus 4.8 这样的顶级模型之间,还有肉眼可见的差距。
这一点不必回避。
现阶段,国产模型在以下场景还不太够用:
- 复杂推理
:架构决策、边界情况排查、PRD 中的"不做什么"判断——这类需要深度思考的工作,国产模型的推理链还容易断 - 长文档理解
:一份 200 页的技术文档加 50 个代码文件,同时理解它们之间的关系并做出决策——这是顶级模型的强项 - 代码质量上限
:在生成可运行的脚手架和 CRUD 时没问题,但在复杂系统设计和边界处理上,错误率明显更高 - 指令遵循精度
:在严格的格式要求下(比如 JSON schema 校验、特定的输出结构),国产模型更容易"自作聪明"
但是,国产模型不是没地方用。
恰恰相反,它们在这个工作流的某些环节有天然优势:
- 中文内容创作
:写公众号、写落地页中文文案、写用户评论回复——国产模型的中文语感天然优于国外模型 - 中文调研
:搜索国内论坛、小红书、知乎、B站评论——国产模型更懂中文互联网的表达方式 - 简单编码任务
:写样式、写单元测试、写文档、重构代码——这类任务的天花板不高,国产模型完全够用 - 日常对话交互
:问答、翻译、摘要、润色——这些是高频低门槛需求,用便宜的国产模型跑,成本可以压到极低 - 本地化部署
:数据隐私敏感的场景,国产模型支持本地部署,不需要过墙
更关键的是:它们在进步。
过去一年,国产模型在推理能力上的进步速度是惊人的。通义千问从千问 2.0 到现在的版本,代码能力提升了不止一个量级。智谱、月之暗面、MiniMax 都在快速迭代。
今天的差距不代表明天的差距。
所以我的建议是:
现在: 关键决策用 Claude Opus,执行用 Kimi,视觉用 ChatGPT。各司其职,先把工作流跑通。
未来: 当国产模型在推理和编码能力上追上来,它们完全可以替代 Claude 的角色——甚至在中文场景下做得更好。而你现在搭建的这套"路由系统",切换起来只需要改一两行 Prompt。
核心不是绑定某个模型,而是建立一套工作流思维。
模型会迭代、会被替代、会涨价。但"知道哪个活该给哪个模型干"这个能力,是任何模型都拿不走的。
总结:各司其职,才是真正的杠杆
回到开头的问题——你之前一个人做过完整的产品吗?
现在你多了一个选项:
不要打开 Claude,说"帮我做一个完整的 SaaS。"
打开你的软件工厂,让每个模型干它最擅长的事。
Claude Opus 4.8 想问题。Kimi 干活。ChatGPT 做图。Stitch 画界面。国产模型——做它们现在能做的,等它们变得更强。
一个人。多模型。各司其职。
这才是 2026 年独立开发者的终极杠杆。
建议收藏。你的下一个 MVP,会从这开始不一样。
