 夜雨聆风
夜雨聆风
Gemma 4 12B 由Google DeepMind 在 2026.6.3 正式开源发布。这是一款120亿参数的统一多模态模型,最大的特点是:只需16GB内存的消费级笔记本电脑,就能本地运行完整的多模态AI能力——文本、图像、音频全部支持,还能处理复杂的推理任务和智能体工作流。
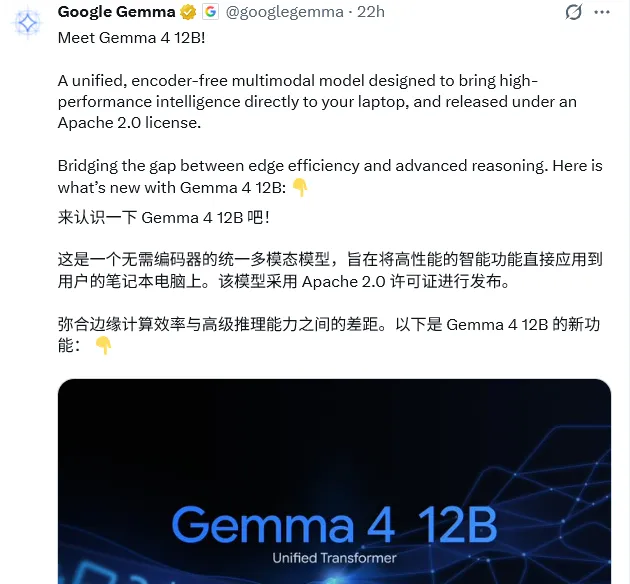
它的性能几乎与我们较大的 Gemma 26B型号相当,但所需的总内存却少得多。此外,它体积小巧,只需 16GB 的 VRAM 即可运行。采用宽松的 Apache 2.0 许可证发布,任何人在16M显存或统一运行内存以上,都可以使用它。
今天,小编带大家分享用Ollama安装Gemma4 12B的过程,希望起到抛砖引玉作用:
首先,从Ollama.com/download下载最新版本的Ollama(目前支持Mac/Linux/Windows),如果不是最新版,会提示无法拉取(下载)Gemma4 12B。
下载好最新版的Ollama后,直接安装,会提示Ollama正在使用中,这也是困扰了小编一阵的一个问题,原来,Ollama关闭后,Ollama的后台仍在运行,需要把服务手工停止。

在运行窗口,输入:ps aux | grep -i ollama,列出 ollama 的 PID:

然后执行kill将所有的端口都删除。
到了这个时候,再运行新版ollama的安装,就不会提示ollama服务正在使用中了。
目前最新版是:Version 0.30.5:

在运行窗口拉取Gemma4 12B:


当看到以下信息时,就大功告成了:

运行ollama,选择:gemma4:12b,可以自由的在本机跑起来了:
Gemma4 12B 的发布,就像是普罗米修斯将火种带到了人间。
它不再是被锁在云端机房里、按次计费的奢侈品;它是你笔记本里那个永远不会断网、永远保护你隐私、永远不知疲倦的数字搭档。
它不是最强的Gemma 4模型,但可能是最多人用得上的Gemma 4模型。

欢迎收听环境生态网微信:eeduorgcn。


