 夜雨聆风
夜雨聆风论文: arXiv 2605.30907
GitHub: https://github.com/Longitude-Labs/bluefin
数据集: https://huggingface.co/datasets/Longitude-Labs/bluefin-release
一、一个Excel错误,60亿美元没了
2012年,摩根大通的伦敦鲸事件震惊全球金融圈。一个交易员在VaR模型表格里抄错了一个公式,导致风险敞口被严重低估,最终亏损超过60亿美元。这不是孤例。房利美2003年因为表格错误重述了11亿美元利润。一份对50个运营表格的审计发现了117处错误,其中一些错误的财务影响高达1亿美元。
你可能会说,这都是十几年前的事了。但问题是,到了2026年,全球还有近250万金融从业者每天花10个小时跟Excel搏斗。根据美国劳工统计局的数据,这群人产生的劳动价值以数千亿美元计。而他们手里的表格,犯错的概率是0.8%到1.8%。放在万亿级的资金规模上,这就是定时炸弹。
所以一个很自然的问题是:能不能让AI来做这些表格?大模型不是连代码都能写吗,填个Excel应该不难吧。
答案是:你想多了。
二、BlueFin:专治金融Excel的AI体检中心
2026年5月29日,Longitude Labs联合康奈尔大学和卡内基梅隆大学在arXiv上发了一篇论文,标题很直白:BlueFin,测试LLM Agent在金融电子表格上的能力基准。这个基准不是为了秀AI有多强,恰恰相反,它是为了告诉你AI现在有多弱。

BlueFin的三大任务类型:综合构建(Synthesis)、操作修改(Manipulation)、查询问答(Interrogation)
BlueFin的设计理念很讲究。之前的电子表格评测要么太浅,比如只是让模型猜一个公式,要么假设数据是干净的CSV而不是多标签页的真实工作簿。BlueFin不一样,它找了78位来自7个国家的金融专业人士做贡献者,覆盖了投行分析师、私募股权从业者、对冲基金研究员、管理咨询顾问,甚至包括CFO级别的资深人士。
这些人要做的不是凭空编造任务,而是把真实工作中的Excel需求写成测试题。每一个任务都带有细粒度的评分标准,总计3225个评分点,分成6个维度逐项打分。
这套系统的关键:20个工具组成的脚手架
很多人听到AI能做金融Excel的第一反应是:把Excel文件上传给ChatGPT,让它输出结果。这个想法完全不对。LLM本身无法直接操作Excel文件,它需要一个脚手架来桥接。这个脚手架才是决定AI能做什么的核心变量。
BlueFin自己搭了一套完全自定义的Harness,不基于任何现有框架,不是Cursor,不是OpenClaw,不是Claude Code。整套系统给LLM提供了20个工具,分成6个类别,覆盖电子表格操作的全生命周期:
读取类:get_cells预览工作表、read_range读取矩形范围、get_sheets获取所有标签页。写入类:set_cells批量写入值和公式、create_sheet新建工作表、insert_rows插入行。格式化类:set_cell_format设置字体数字格式对齐等。计算类:recalc_workbook驱动LibreOffice无头计算引擎重新计算公式,并开启迭代计算,让债务计划和LBO模型中的循环引用能正确收敛。代码执行类:execute_python在沙箱中用openpyxl批量操作,限制内置函数和白名单导入,禁文件IO禁网络。
有几个细节值得注意。第一,整个agent的系统提示词只有61个英文单词,极其简洁,没有工作流程指导,没有工具偏好,没有领域惯例。论文故意设计成这样,是为了把模型能力从指令遵循的干扰因素中剥离出来。第二,没有用SKILL.md这类技能文件系统,纯函数调用模式。第三,recalc_workbook这个工具很关键,它驱动的是LibreOffice的无头模式,而不是Excel本身,这是一个纯Python可控的技术选型。
这意味着什么?意味着BlueFin测的其实不是裸模型的能力,而是模型加脚手架这个组合体的能力。不同模型的工具使用策略截然不同。GPT-5.5在64%的操作任务中,第一个动作就是调用execute_python通过openpyxl批量检查和写入单元格,像一个先用代码理解表格结构的量化程序员。而Opus、Sonnet和Gemini只有不到25%会这样做。Opus更倾向于通过读取工具逐区域理解,然后用set_cells精准修改。这两种策略各有利弊:GPT-5.5的代码模式回合数更少,但输出验证更弱;Opus的逐区域模式更保守,但回合计多、成本更高。
这也是为什么奇哥说,评估一个AI做金融Excel的能力,不能只看模型本身的分数。工具的完备性、recalc的可靠性、沙箱的安全边界,这些都直接影响最终产出。你在实际工作中如果要用AI做表格,你的脚手架是什么,决定了你的上限在哪里。
三、三大任务:AI能做到什么程度?
BlueFin一共有131个任务,分成三类:
Synthesis 综合构建(10个任务)
给一个自然语言需求,从头创建一个完整的Excel工作簿。比如:帮我构建Take Two Interactive的DCF估值模型,包括假设页、运营模型、债务安排和合并模型。这种任务一个有经验的投行分析师要花好几个小时。
Manipulation 操作修改(82个任务)
给一个已有的工作簿,按照自然语言指令进行修改。这是最大的类别,也是IB和PE分析师最日常的工作。每个任务分析师至少需要45分钟才能完成。覆盖了5个金融建模类别和16个行业,房地产、科技、能源、消费服务和医疗占60%。
Interrogation 查询问答(39个任务)
给一个输入工作簿,回答问题。但不是简单的看一眼就答,很多问题要求先修改假设、重新计算多层依赖关系,然后才能正确回答。
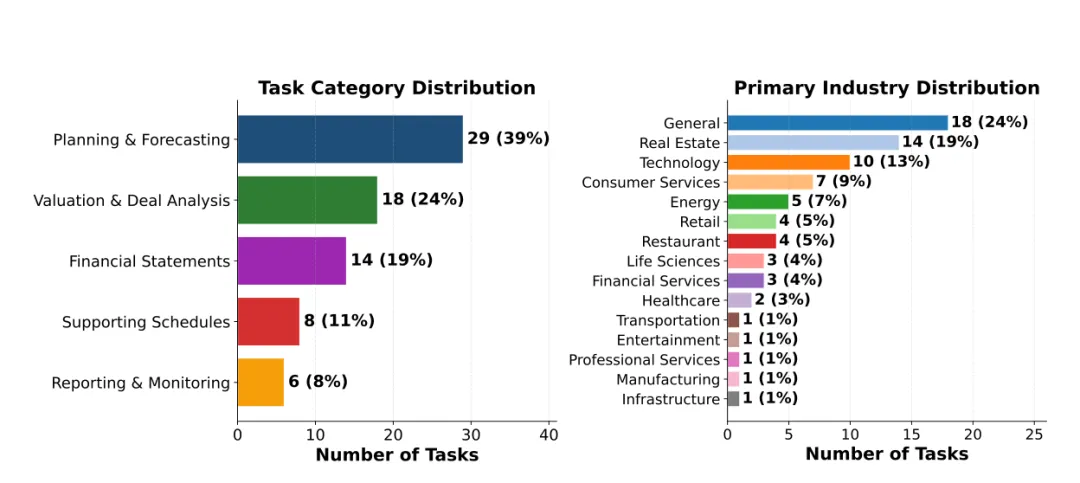
Manipulation任务保留集的构成:5个金融建模类别和16个行业分布
四、核心结果:全军覆没,无一超过50%
论文测试了5个最前沿的模型:Claude Opus 4.7、Claude Sonnet 4.6、GPT-5.5、Gemini 3.1 Pro Preview和Grok 4.20。所有模型都设为高推理模式。另外在公开集上还测试了两个开源模型:Kimi K2.6和MiniMax M2.5。
结果怎么说呢,最好模型GPT-5.5综合得分49.6%,Claude Opus 4.7紧随其后49.2%。没有模型超过50%。而SWE-bench这种代码评测早被刷到70%以上了。做表格比写代码难得多。
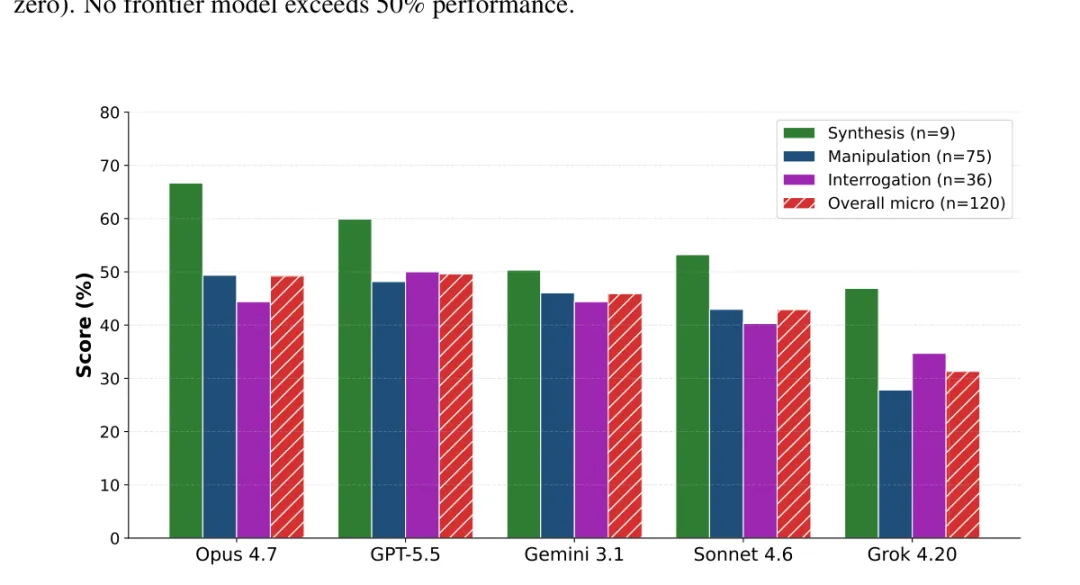
保留集120个任务的评测结果:所有模型都低于50%
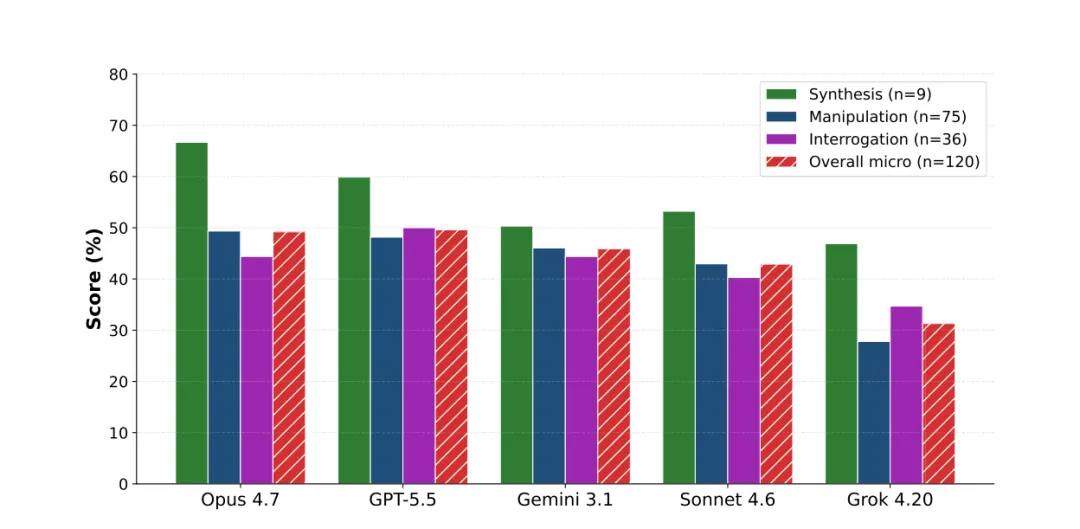
各类任务的模型表现:Synthesis最好(Opus 66.7%),Interrogation最差
分任务类型看,Synthesis任务表现最好,Opus达到66.7%。这其实很好理解,从零开始搭模型比改别人做好的模型要自由得多。Manipulation是最大的一类82个任务,最好也只有49.4%。Interrogation最差,因为很多问题需要理解复杂的计算依赖链。
五、AI擅长什么,不擅长什么?
论文用6个维度评估每个任务的表现,结果揭示了一个非常反直觉的事实:AI写公式很强,但让它在输入变化时维持正确就崩了。
擅长的:公式正确性
各模型的公式正确性通过率在50%到68%之间。GPT-5.5尤其有意思,在64%的操作任务中,它的第一个动作是用Python代码通过openpyxl批量检查和写入单元格,像一个先用编程方式理解表格结构的策略交易员。
不擅长的:动态行为(扰动测试)
这是AI最大的短板。扰动测试的意思是:改变一个驱动输入,看所有依赖的输出是否正确更新。各模型的通过率只有15%到37%。公式正确性和扰动测试之间有约30个百分点的鸿沟。
举个例子:一个DCF模型,你把增长率从3%改成4%,最终的估值应该自动重新计算。但如果AI实现这个公式时出了问题,比如不是用Excel公式而是硬编码了数值,那修改增长率之后估值就不会变。这就是很多模型失败的原因。
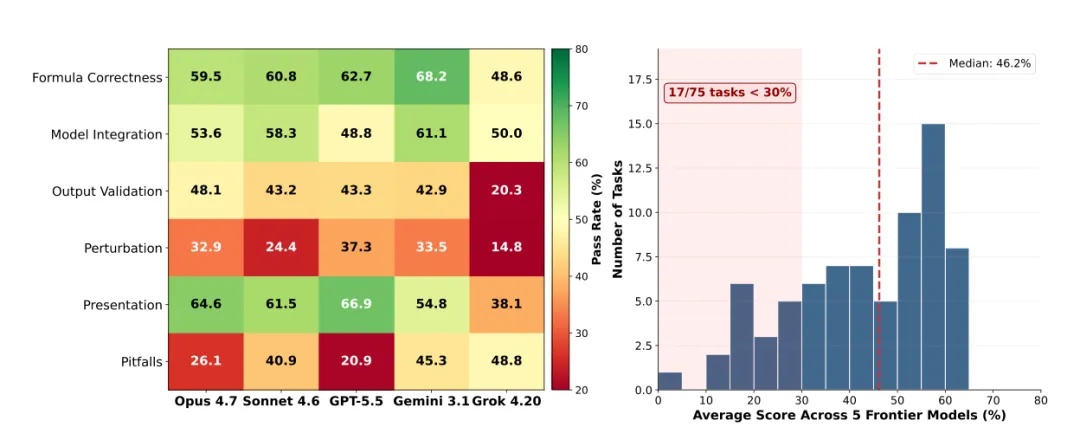
6个评分维度的通过率对比:公式正确性最高,扰动测试最低
另外,输出验证也是重灾区,通过率只有20%到48%。常见错误包括:现金流项目的正负号搞反、日期轴错位比如Q1-2024和Q1-2025偏移、利率和金额混淆比如5%写成了5.0而不是0.05、期末和期初折现搞混。这些都是金融从业者一眼就能看出来的低级错误,但LLM一犯再犯。
更有趣的是Sonnet的行为。在大约8%的操作任务中,Sonnet对输入工作簿做了大量读取操作,思考了半天,然后直接调用done,返回的工作簿跟输入一模一样。等于说它在漫长的探索之后,选择了放弃。
六、做同样的事,价格差了27.7倍
论文还做了一个很现实的分析:花多少钱能干多少活。
GPT-5.5平均每任务成本8.85美元,得分49.6%。Opus 4.7每任务成本49.21美元,得分49.2%。贵了5.6倍,分数还低了一点。Gemini 3.1 Pro更夸张,每任务5.78美元,比Opus便宜8.5倍,总分只差了不到7个百分点。
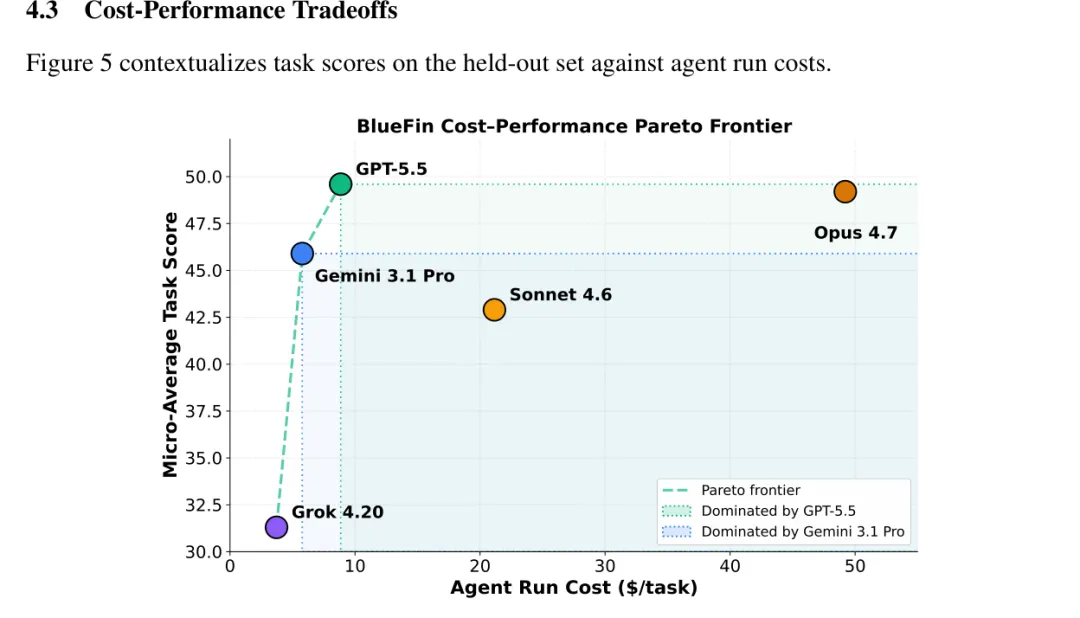
成本效率图:Pareto前沿由Grok到Gemini再到GPT-5.5构成
最极端的案例是一个资产负债表构建任务。Gemini 3.1 Pro得分100%,花了3美元。Opus 4.7得分95%,花了83.05美元。同样的活,价格差了27.7倍。如果你是一个金融团队,每天要做几十个表格分析,这个差距足以影响你的采购决策。
七、人类怎么看AI做的表格?
论文还邀请了两个专家评审员评估模型输出的实用性。两个评审员分别独立判断:这个AI生成的表格能不能直接作为一个工作起点来用。
结果:Opus以75%的可用率排第一,GPT-5.5以68.75%排第二,Gemini和Sonnet都是56.25%,Grok是0%。评审员的评价是:Opus在结构和公式方面最强,但格式是所有模型的通病,AI很难遵循已有工作簿的格式约定。
这个结果其实挺说明问题的。即使是最好的AI,只有四分之三的产出能被人类专家认为可以继续用。换句话说,至少四分之一的AI产出需要重做。如果任务难度再高一点,这个比例只会更低。
八、总结:AI做表格还早,但有意思
BlueFin告诉我们几件事。
第一,金融电子表格的复杂度远超代码。SWE-bench已经被刷爆了,但BlueFin连50%都没过。表格里的公式需要处理多层依赖、动态传播、格式一致性、跨标签页引用,这些都不是写一段Python能搞定的事。
第二,AI在静态任务上还行,在动态任务上很烂。能写出正确的公式是一回事,让公式在输入变化时自动重新计算是另一回事。这30个百分点的落差是当前LLM最大的软肋。
第三,便宜不一定差。GPT-5.5以不到五分之一的价格做到了和Opus几乎一样的分数,Gemini更便宜。实际决策时不能只看绝对分数。
第四,这个基准本身很重要。全球250万金融从业者,每天花10小时做表格。如果AI能把这个效率提升哪怕20%,释放的生产力远大于让AI写代码。但目前看来,这条路还很长。
最后说一句,BlueFin的难度设计是有意为之。作者故意找了投行和PE的分析师来做贡献者,任务难度对标的是华尔街精英。所以AI做到50%其实不丢人,换一个普通打工人来做,可能还不如Opus。况且论文里的模型都是2026年5月的版本,再过半年谁知道呢。
奇哥的建议是:现阶段别指望AI替你做完整个模型,但让它帮你搭框架、写公式、做初步检查是完全可行的。关键是人要做最后的审核,尤其是在数字符号、日期对齐、折现起点这些容易出错的地方。一个Excel错误能亏60亿美元,一个AI写的Excel错误可能亏更多。
