 夜雨聆风
夜雨聆风从底层认知到安装实战 · 一篇彻底搞懂 2026 年最火的开源 AI Agent
| 自进化原理 · 四层记忆架构 · 安装配置 · 使用技巧 · 进阶玩法 |
写在前面:你的 AI 助手,只是一个「金鱼脑」?
上个月,我做了一个让自己崩溃的实验。
我花了整整三天时间,手把手「教」Claude Code 我们项目的代码规范、架构偏好、部署流程。它学得很快,配合得也很默契。我以为我终于拥有了一个靠谱的 AI 搭档。
然后我关掉了终端。
第二天重新打开——它全忘了。
「你好!我是你的 AI 编程助手,有什么可以帮你的吗?」——就像我们从来没有合作过一样。三天的调教,全部蒸发。
我当时的感受是:这不就是在养一条金鱼吗?每次转一圈回来,它都觉得自己是第一次见你。
后来我发现,这不是我一个人的痛点。
2026 年,几乎所有用 AI Agent 做生产力工具的人,都在面对同一个问题:AI 很聪明,但它不「成长」。你每天都在教它同样的事情,它每天都在从零开始。你花在「教 AI」上的时间,可能比你自己做还多。
直到我遇到了 Hermes Agent。
它是 Nous Research 在 2026 年 2 月开源的一个 AI 智能体框架,GitHub 星标已经飙到了 47K——两个月翻了好几倍。而让它一骑绝尘的,不是什么花哨的功能,而是一个朴素但颠覆性的能力:
它会自己学习、自己记忆、自己进化。你教它一次的东西,它永远不会忘。而且越用越聪明。
这篇文章,我会从底层认知讲起,带你彻底搞懂 Hermes Agent 到底是什么、为什么它代表了 AI Agent 的进化方向、怎么安装配置、以及那些让它真正好用的技巧。不管你是开发者、AI 产品经理还是技术爱好者,看完这篇,你对 AI Agent 的认知会升一个维度。
一、底层认知:Hermes Agent 凭什么不一样?
1.1 先搞清楚一个概念:什么才是「真正的 Agent」
市面上自称「AI Agent」的产品满天飞,但大部分不过是套了一层壳的 ChatGPT。真正的 Agent 和聊天机器人之间,有一道明确的分界线:
普通聊天机器人 | 真正的 AI Agent |
你问一句,它答一句 | 你给一个目标,它自己拆解、规划、执行 |
关掉窗口,一切归零 | 跨会话记住你说过的话、做过的事 |
只能输出文字 | 能调用工具(搜索、写代码、操作数据库……) |
永远是出厂设置 | 越用越懂你,能力越来越强 |
被动等你提问 | 能主动执行定时任务、后台监控 |
看到最后一列的关键词了吗?「越用越强」——这正是 Hermes Agent 的核心卖点,也是它和绝大多数 Agent 框架最本质的区别。
1.2 Hermes Agent 是谁做的?
Hermes Agent 的开发方是 Nous Research——一家专注 AI 基础研究的实验室。你可能没听过这个名字,但大概率用过他们的模型:Hermes 系列微调模型在 Hugging Face 上长期霸榜,被业界称为「开源模型调教天花板」。
做模型的人来做 Agent,这个出身决定了 Hermes Agent 的基因——它不是从产品经理视角出发的「功能堆叠」,而是从 AI 研究者视角出发的「架构创新」。Nous Research 在设计这个框架时,回答的是一个更根本的问题:
「一个 AI 系统,如何在长期使用中真正变得更聪明?」
1.3 一句话定义 Hermes Agent
官方的定义是:Self-improving AI agent with built-in learning loop。翻译成人话就是:
一个内置了学习闭环的、能自我进化的 AI 智能体。
关键词拆解:
▸ 自我进化(Self-improving):不是你教它,而是它自己从实战经验中学习
▸ 学习闭环(Learning Loop):完成任务 → 提取经验 → 生成可复用技能 → 下次更快更好
▸ 内置(Built-in):这不是一个需要你额外开发的功能,开箱即用
这意味着什么?意味着 Hermes Agent 不是一个「工具」,而是一个「会成长的数字同事」。你和它合作的时间越长,它就越了解你的项目、你的习惯、你的偏好——而且这些理解会被永久保存,不会因为重启而丢失。
二、Agent 进化方向:Hermes 的自进化机制有多硬核?
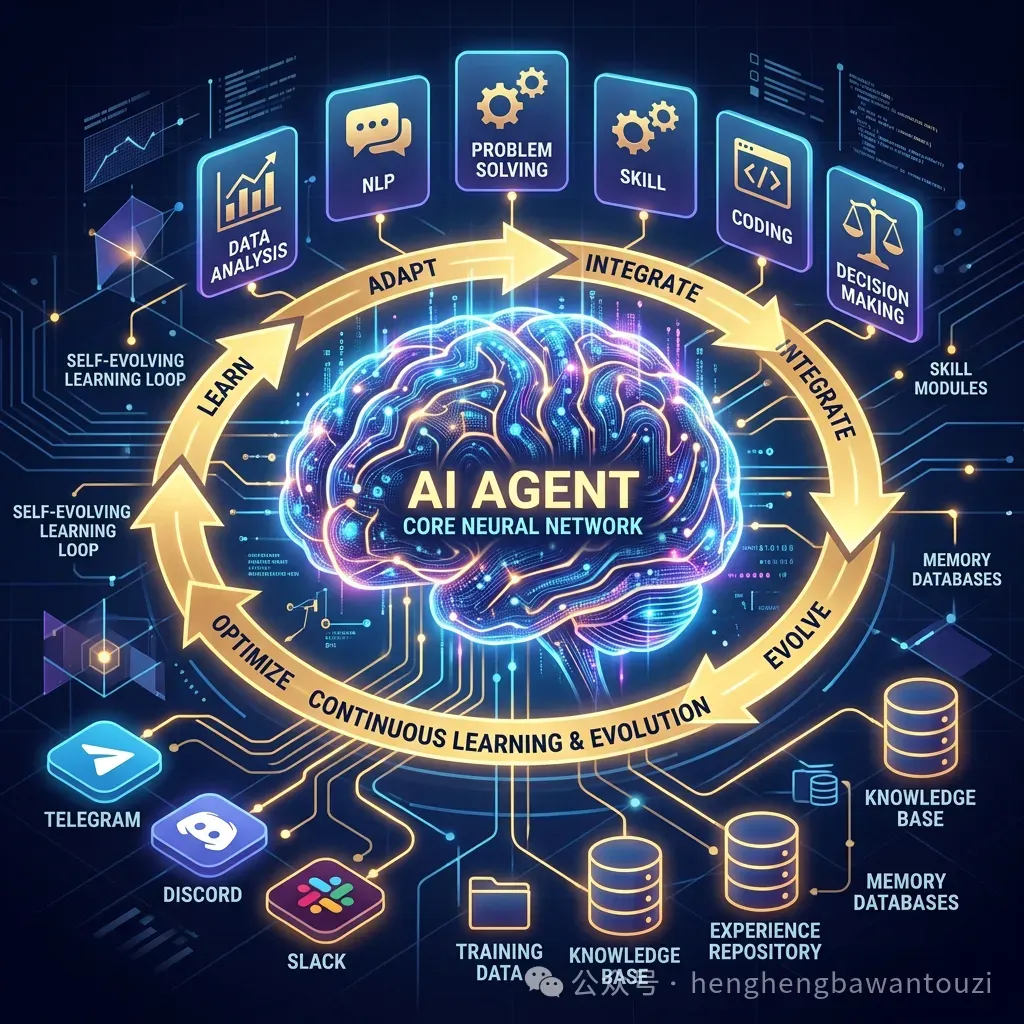
Hermes Agent 之所以能「越用越聪明」,靠的不是玄学,而是三套精密的工程化机制。让我逐个拆解。
2.1 核心引擎:学习闭环(Learning Loop)
学习闭环是 Hermes 的灵魂,也是它和市面上所有 Agent 最大的差异点。它的运行机制是这样的:
1. 你给 Hermes 一个复杂任务(比如「帮我部署一个 Node.js 项目到服务器」)
2. Hermes 一边执行,一边在内部记录:用了哪些工具、走了哪些弯路、哪些方法有效
3. 任务完成后,如果这次执行满足特定条件(调用了 5 个以上工具、从错误中恢复过、包含非显而易见的工作流),Hermes 会自动触发「技能提取」
4. 它会把这次成功的工作流提炼成一份结构化的技能文档(SKILL.md),存入技能库
5. 下次遇到类似任务,它直接加载这份技能,跳过摸索阶段——实测速度提升约 40%
类比:这就像一个新员工。第一次做某件事可能需要摸索半天,但他会把方法记在笔记本上。第二次再做,翻开笔记就能直接上手。区别是,Hermes 的「笔记本」是结构化的、可搜索的、会自动更新的。
更厉害的是,技能不是「写完就不动了」——Hermes 在后续使用中会持续优化已有技能。它默认使用 patch(补丁)模式而非全量重写,只修改需要改进的部分,既节省 Token 又保证不破坏已经正常工作的流程。
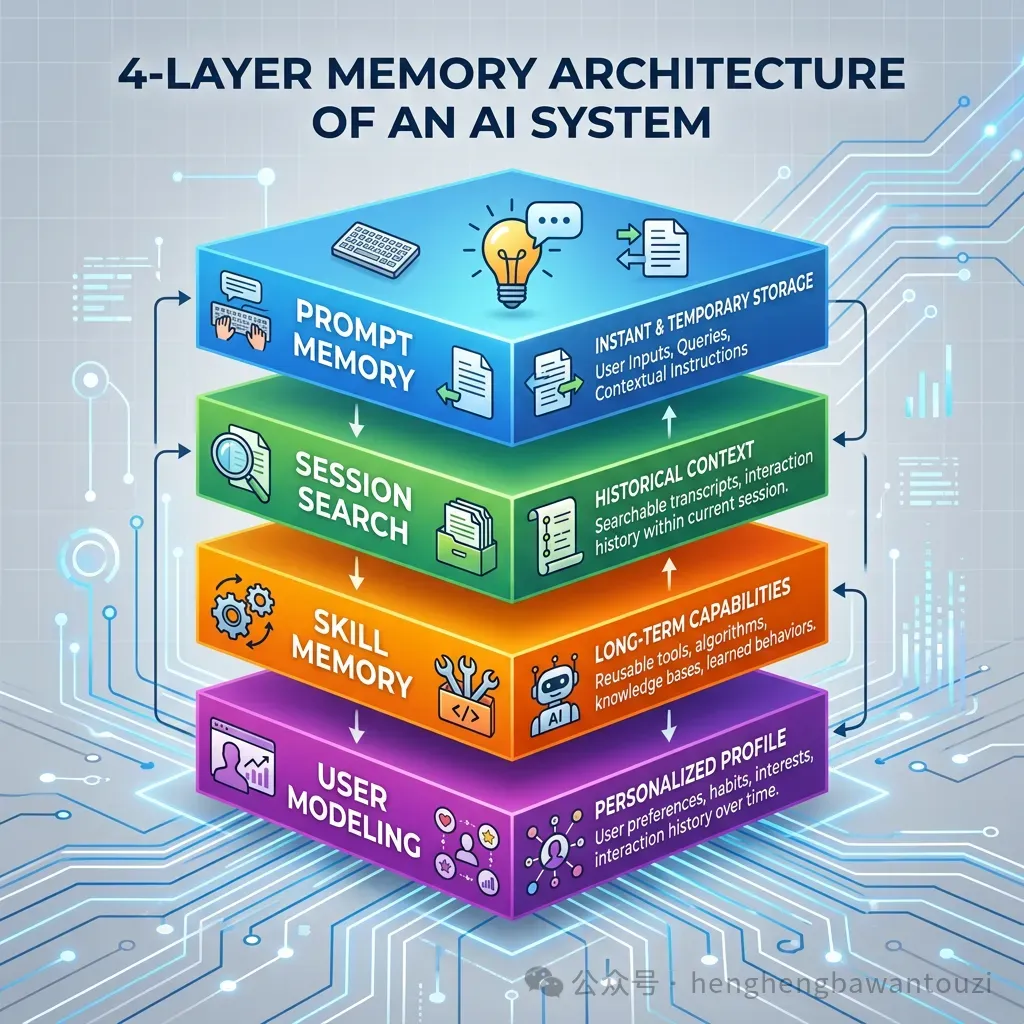
2.2 记忆中枢:四层内存架构
传统 Agent 的记忆方案要么太简单(只有短期对话历史),要么太混乱(什么都往一个数据库里塞)。Hermes 设计了一套四层分级的内存架构,每层解决一个特定问题:
记忆层级 | 存储位置 | 加载时机 | 解决什么问题 |
提示记忆 | MEMORY.md / USER.md | 每次会话自动加载 | 「你是谁、你喜欢什么」——用户画像和核心偏好 |
会话搜索 | SQLite + FTS5 | Agent主动检索 | 「上次我们怎么做的」——历史经验按需召回 |
技能记忆 | ~/.hermes/skills/ | 按需加载(名称+摘要) | 「这件事该怎么做」——可复用的工作流指南 |
用户建模 | Honcho 辩证建模 | 后台自动构建 | 「你在变、我也跟着变」——动态跟踪用户变化 |
几个设计亮点值得注意:
▸ 提示记忆有硬性上限(3,575 字符),强制你精选而非堆积——这避免了「记忆越多、越迟钝」的问题
▸ 技能库采用「渐进式披露」:系统提示中只加载技能名称和摘要,完整内容按需展开——无论存了多少技能,Token 成本不膨胀
▸ 会话搜索使用 SQLite + FTS5 全文检索,而非向量数据库——本地优先、零依赖、部署极简
▸ 用户建模是被动构建的,不需要你手动配置——它在 12 个维度上同时跟踪你的变化
2.3 模型无关:今天用 Claude,明天切 DeepSeek
这一点非常重要,但很容易被忽略。
Hermes Agent 采用「模型无关架构」——它不绑定任何一家模型厂商。你可以随时通过 hermes model 命令一键切换:
▸ Nous Portal(官方推荐)
▸ OpenRouter(200+ 模型随便选)
▸ OpenAI / Anthropic / Google 官方 API
▸ DeepSeek / Kimi / GLM 等国产模型
▸ Ollama / vLLM 本地部署(数据完全不出机器)
▸ 任何 OpenAI 兼容的自定义端点
这意味着什么?意味着你的工作流和技能积累不会被任何一家模型厂商绑架。今天 Claude 效果好就用 Claude,明天 DeepSeek 便宜就切 DeepSeek——你换的只是「大脑」,你的技能、记忆、配置全部保留。这对开发者来说是真正的自由。如果你需要一个支持多模型切换的 API 接入方案,LingTrue(www.lingtrue.com)是个不错的选择——一个 Key 统一管理 Claude、GPT、DeepSeek 等几十种模型的 API,省去注册多个账号的麻烦,还能享受比官方更优的价格。
2.4 为什么说 Hermes 代表了 Agent 的进化方向?
回看 AI Agent 的发展轨迹,可以清晰地看到三个阶段:
阶段 | 代表 | 核心能力 | 局限 |
Agent 1.0 | AutoGPT / BabyAGI | 能自主拆解任务 | 没有记忆,每次从零开始 |
Agent 2.0 | OpenClaw / Claude Code | 能调用工具、能编程 | 不会学习,能力不增长 |
Agent 3.0 | Hermes Agent | 能学习、能记忆、能自我进化 | 生态仍在发展中 |
Hermes 的路径很清晰:它不试图做「功能最多」的 Agent,而是做「最会学习」的 Agent。在 Nous Research 看来,Agent 的终极形态不是一个无所不能的超级工具,而是一个能持续积累经验、不断自我完善的「数字生命」。
一个不会学习的 Agent,本质上只是一个用 Prompt 驱动的脚本。真正的 Agent,应该越用越强。这就是 Hermes 回答的根本问题。
三、安装指南:10 分钟拥有一个会进化的 AI 助手

Hermes Agent 的安装过程非常丝滑——一行命令搞定。但安装之前,先确认你的环境满足要求。
3.1 系统要求
操作系统 | 支持情况 | 备注 |
Linux | ✅ 完整支持 | 推荐 Ubuntu 22.04+ |
macOS | ✅ 完整支持 | Intel 和 Apple Silicon 均可 |
WSL2 | ✅ 完整支持 | 推荐 Ubuntu 22.04 |
Windows 原生 | ❌ 不支持 | 必须使用 WSL2 |
唯一需要手动提前安装的依赖是 Git。其他依赖(Python 3.11、Node.js v22、ripgrep、ffmpeg 等)都会被安装脚本自动处理。
3.2 一键安装(推荐)
打开终端,粘贴以下命令:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash安装脚本会自动完成以下事情:
▸ 检测并安装 Python 3.11、Node.js v22、uv 包管理器
▸ 克隆 Hermes Agent 仓库并安装依赖
▸ 创建 ~/.hermes/ 配置目录
▸ 设置全局 hermes 命令
安装完成后,让环境变量生效:
source ~/.zshrc # macOS 用户# 或者source ~/.bashrc # Linux 用户
验证安装是否成功:
hermes doctor如果所有检查项都是绿色的 ✅,恭喜你,安装成功了。
3.3 配置模型(重要!)
安装完 Hermes 本身还不能用——你还需要给它一个「大脑」,也就是配置 LLM 提供商。
方式一:交互式配置(推荐新手)
hermes setup这会启动一个配置向导,引导你完成模型选择、API Key 填写等所有设置。
方式二:手动配置
编辑 ~/.hermes/.env 文件,填入你的 API Key:
# 选择一个填就行,不需要全部都有# Nous Portal(官方推荐)NOUS_API_KEY=your_key_here# OpenRouter(200+ 模型可选)OPENROUTER_API_KEY=your_key_here# OpenAIOPENAI_API_KEY=your_key_here# AnthropicANTHROPIC_API_KEY=your_key_here# 自定义 OpenAI 兼容端点(如中转站)OPENAI_BASE_URL=https://www.lingtrue.com/v1OPENAI_API_KEY=your_lingtrue_key
💡 省钱技巧:如果你不想为每个模型分别注册账号和充值,可以直接用 LingTrue(www.lingtrue.com)这类模型中转站。一个 Key 就能调用 Claude、GPT、DeepSeek 等几十种模型,在 Hermes 里通过 OPENAI_BASE_URL 指向中转站地址即可——配置简单,价格也比官方更优惠,特别适合开发阶段需要频繁切换模型的场景。
3.4 选择模型
hermes model根据你的需求选择不同的模型:
使用场景 | 推荐模型 | 理由 |
隐私优先 / 离线使用 | Ollama + Llama 3.3 | 数据不出本机,完全免费 |
日常使用(性价比) | OpenRouter + Hermes 405B | 按量付费,200+ 模型可选 |
复杂推理任务 | Claude Sonnet / GPT-4.1 | 推理能力最强 |
批量任务 / 省钱 | DeepSeek / GPT-4.1-mini | 成本极低,效果够用 |
研究 / 训练 | vLLM 本地部署 | 完全可控,支持 RL 训练 |
3.5 第一次对话
一切就绪!输入 hermes 启动交互界面:
hermes 你会看到一个精致的 TUI(终端用户界面),支持多行编辑、命令补全和流式输出。试着给它一个任务:
> 帮我在当前目录创建一个 Python 项目,包含 .gitignore、README.md 和基本目录结构看着它自主思考、调用终端命令、创建文件——你会有一种「哇,这才是 AI 该有的样子」的感觉。
四、使用技巧:从入门到「真的好用」
安装只是起点。想要把 Hermes Agent 用到飞起,以下这些技巧是关键。
4.1 主动触发 Skill 沉淀——让它越来越聪明
Hermes 的自动技能创建有触发条件:任务需要涉及 5 次以上的工具调用,或者包含从错误中恢复的过程。所以,如果你只让它做「翻译一段话」这种简单任务,它永远不会生成技能。
正确的做法:
▸ 多给它复杂任务:「帮我分析这个项目的依赖,找出过期的包,生成升级方案」
▸ 故意制造一些「纠错」场景:如果它第一次方案不对,告诉它正确做法,它会把纠正后的流程记入技能
▸ 定期查看技能库:hermes 命令行中可以浏览已生成的 Skill,不合理的可以手动删除
经验之谈:新装的 Hermes 大概需要 1-2 周的「磨合期」。前期多花点时间给它分配有挑战性的任务,后期的效率提升是指数级的。就像带新人——前期多投入,后期省大力气。
4.2 善用多平台网关——把它变成 24 小时在线的助手
Hermes 最被低估的功能之一,是它的消息网关系统。你可以把 Hermes 接入几乎所有主流平台:
▸ Telegram / Discord / Slack / WhatsApp / Signal
▸ 飞书 / 企业微信 / 钉钉
▸ Email(SMTP)
▸ Home Assistant(智能家居)
配置方法非常简单:
# 启动网关配置向导hermes gateway setup# 选择平台,填入 Bot Token# 启动网关hermes gateway# 注册为系统服务(7×24 小时运行)hermes gateway install
关键亮点:上下文跨平台共享。你在 Telegram 上跟 Hermes 聊到一半,切到终端继续——它完全记得你之前说了什么。会话绑定的是你的 ID,不是平台。
4.3 定时自动化——让它在你睡觉时干活
Hermes 内置了 cron 调度器,可以设置定时任务。比如:
▸ 每天早上 8 点生成前一天的 GitHub 项目活动报告
▸ 每周一自动检查服务器状态并发送巡检报告到你的 Telegram
▸ 每 6 小时自动备份数据库
这些定时任务通过网关触发,输出也通过网关推送——你在手机上打开 Telegram 就能看到结果。Agent 不需要你在场也能持续工作,这才是「AI 助手」该有的样子。
4.4 安全使用的铁律——别让它翻车
Hermes 内置了五层安全防线,但有些配置需要你主动开启:
1. 开启 Docker 隔离:在配置中设置执行后端为 Docker,所有命令在容器中运行,不会影响宿主机
2. 开启手动审批:设置 approvals.mode: manual,高危操作(如删除文件、写入数据库)需要你确认才能执行
3. 不要开放全员访问:网关默认只响应授权用户,千万不要设置 GATEWAY_ALLOW_ALL_USERS=true
4. 定期清理记忆:使用 hermes memory 检查记忆内容,防止长期使用后出现记忆混淆或过时信息
5. 监控日志:定期查看 ~/.hermes/logs/ 中的运行日志,确认 Agent 的行为符合预期
⚠️ 生产环境部署铁律:永远不要给 Agent 不受限的 root 权限。把它当成一个实习生——能力很强,但需要监督。
4.5 常用命令速查表
命令 | 功能 |
hermes | 启动交互式 CLI 对话 |
hermes model | 选择/切换模型 |
hermes tools | 查看和配置工具集 |
hermes setup | 运行完整配置向导 |
hermes gateway | 启动消息网关 |
hermes gateway setup | 配置网关平台 |
hermes doctor | 诊断环境和配置问题 |
hermes update | 更新到最新版本 |
hermes claw migrate | 从 OpenClaw 迁移数据 |
hermes config set KEY VALUE | 设置单项配置 |
五、进阶玩法:把 Hermes 的能力榨干
5.1 OpenClaw 用户无缝迁移
如果你之前用的是 OpenClaw,迁移到 Hermes 只需要一条命令:
hermes claw migrate 它会自动导入你在 OpenClaw 中的会话历史、配置和自定义设置。不需要从头开始。
5.2 接入浏览器自动化——让 Agent 上网
安装浏览器扩展包后,Hermes 可以操控浏览器:搜索信息、导航页面、点击按钮、截图分析、甚至填写表单。
pip install "hermes-agent[browser]"配合视觉分析能力,你可以让它「帮我看看竞品的最新版本有什么更新」,它会自己打开网页、截图、分析、给你总结。
5.3 MLOps 能力——给 AI 研究者的彩蛋
作为一家 AI 研究实验室的作品,Hermes 内置了一些对 AI 研究者极为友好的功能:
▸ 批量生成训练数据:基于现有会话自动生成用于微调的数据集
▸ 强化学习训练:集成 Atropos 框架,支持在线 RL 训练
▸ 轨迹导出:支持 ShareGPT 格式,方便导入各种训练框架
这些功能对普通用户来说用不到,但如果你是 AI 研究者或训练工程师,这简直是意外之喜。
5.4 Skill Hub——站在巨人的肩膀上
Hermes 有一个技能共享生态——agentskills.io。你可以:
▸ 浏览社区贡献的技能,一键安装到你的 Hermes
▸ 把你自创的好用技能分享给社区
▸ 技能文件遵循开放标准(agentskills.io),可以在不同 Agent 之间移植
目前 Hermes 已内置 40+ 技能,涵盖开发、运维、研究、内容创作等场景。随着社区的发展,这个数字会快速增长。
六、Hermes Agent 适合谁?不适合谁?
写了这么多,最后来做一个客观的评估。Hermes 不是万能药,明确知道它适合和不适合的场景,能帮你少踩很多坑。
✅ 强烈推荐
1. 长期个人 AI 助手——你需要一个越用越懂你的 Agent,而不是每天从零开始的陌生人
2. 开发者 / 技术团队——需要一个能记住项目架构、代码规范、部署流程的编程搭档
3. 自动化运维——Agent 能积累故障处理经验,下次遇到同类问题直接套用已有方案
4. AI 研究者——内置训练框架、RL 支持和数据生成能力,边用边做研究
5. 隐私敏感场景——全量本地部署、零遥测、MIT 开源、数据完全可控
❌ 不太适合
1. 一次性简单对话——问个天气、翻译个句子、聊聊天,直接用 ChatGPT 更方便
2. 完全零基础用户——虽然一键安装,但配置模型、网关、Docker 对纯小白仍有门槛
3. Windows 原生环境——必须用 WSL2,对不熟悉 Linux 的用户不太友好
总结一句话:如果你需要一个「长期搭档」而非「一次性工具」,Hermes Agent 目前是最佳选择。
写在最后:AI Agent 的下一步,是「成长」
2026 年初,AI Agent 领域正在经历一场范式转换。
过去两年,我们在追求「让 AI 做更多事」——更多工具、更多平台、更多模态。但 Hermes Agent 提出了一个不同的问题:让 AI 做得更多,不如让 AI 做得更好——让它记住经验、学会教训、积累智慧。
这个思路为什么重要?因为在企业落地场景中,一个「用了半年就很好用」的 Agent,远比一个「开箱即用但永远不进步」的 Agent 更有价值。前者的投资回报率是递增的,后者是恒定的。
Hermes Agent 当然不完美——它的生态还在发展中,Windows 支持有限,对新手的友好度还有提升空间。但它的架构方向是对的:学习闭环、分层记忆、模型无关、开源透明。这些基因,决定了它在长跑中会越来越强。
如果你对 AI Agent 感兴趣,我的建议很简单:
1. 今天就装一个 Hermes Agent——就是一行命令的事
2. 给它分配一个你日常重复做的任务——让它开始学习
3. 坚持用一到两周——感受它从「陌生人」变成「老同事」的过程
开始的第一步是拿到一个好用的模型 API。
如果这篇文章帮你搞懂了 Hermes Agent,
觉得有用的话,点赞收藏一键三连,就是对我最大的支持 😊
