夜雨聆风
夜雨聆风
将水木上岸设为“星标⭐”
掌握第一手top院校信息

水木上岸自2017年开始辅导清华347应用心理,近年上岸率高达67%-88%,团队的讲师均来自清华大学,本硕博都有,覆盖考研体系中所有课程,我们是心理学领域唯一专业人工智能的团队。
2026考研中,水木上岸21位学员被录取(共29人),占总录取人数72.4%,前五名均为水木上岸学员。
2025考研中,水木上岸21位学员被录取(共录取 24人),占总录取人数88%,前五名均为水木上岸学员(包含总分第一和专业第一)。2024考研中,水木上岸学员录取率67%,其中包含专业第一。

监督学习,又称有监督学习、监督式学习,是机器学习的一种方法。监督学习可以从训练数据(由输入对象和预期输出组成)中学习到或建立一个学习模型 (learning model) 来反映给定输入和给定输出之间的关系,并依此模型推测新的实例。模型的输出可以是一个连续的值 (称为回归问题),或是一个离散的分类标签 (称作分类问题)。目前,监督学习已广泛应用于各个领域,如金融预测 (信用评分)、医疗诊断 (疾病预测)、图像识别 (人脸识别) 等。
线性模型的基本形式
对于由n个属性描述的示例,线性模型 (linear model) 试图学习一个通过属性值的线性组合来进行预测的函数,即
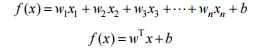
式中,w=(w1,w2,w3,⋯,wn)和b是待学习的参数,当二者学得之后,模型就可以确定。线性模型的形式简单,建模容易,通过在线性模型的基础上引入层级结构或高维度映射,可以构建功能更为强大的非线性模型 (nonlinear model)。
线性回归
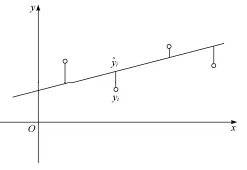
对于给定的数据集,线性回归尝试去学习一个线性模型,使得预测值尽可能接近真实值。模型的预测值和真实值应当尽可能接近,因此可以将预测值与真实值的差距作为评价模型的指标。目前,均方误差是回归任务中最常用的性能度量指标,因为它有着简单易懂、对大误差敏感和便于计算导数等优点。
逻辑回归
以基本的二分类问题为例,需要将模型输出的真实值转变为输出标记{0,1}。根据之前提出的广义线性模型,需要找到一个单调可微函数将二者联系起来。逻辑斯蒂函数 (logistic function) 正是常用的替代函数:
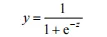
在二分类问题中,上式也可以这样表示:
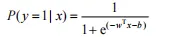
这样模型的输出值就被转换为在给定输入特征的条件下,对应样本被分类为正类的概率大小,通过设定决策边界 (输出概率大于该边界时为正类) 即可通过模型来预测输入数据的类别。
多分类学习
现实中遇到的分类任务大多是多分类任务,针对这类问题,部分二分类学习方法可以直接推广到多分类。但一般情况下,是根据一些策略,将多分类问题拆解为二分类问题。经典的拆分策略有三种:一对一 (one-vs-one,OvO)、一对其余 (one-vs-rest,OvR) 和多对多 (many-vs-many,MvM)。
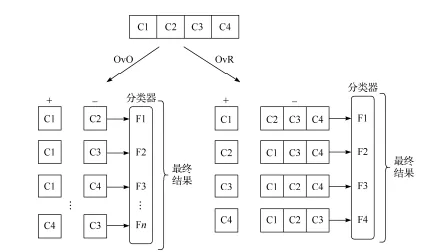
对于含有N个类别的数据集,OvO 策略是将N个类别进行两两配对,一共训练N(N−1)/2个二分类器,任意一个新数据,会被传入所有的二分类器中,最后对所有的分类结果进行统计,选择票数最高的作为最终结果。
OvR 策略则是每次将一类的样例作为正例,其余作为反例来训练N个分类器,在预测时,若仅有一个分类器的结果为正,那么代表输入就属于这一类,若有多个分类器结果为正,则根据这些分类器的预测置信度,选择置信度最大的那一个作为最终结果。
显然,OvR 策略需要的分类器数目要少于 OvO 策略,因此 OvO 分类器所需的存储开销和测试时间一般比 OvR 更大。但是,OvR 策略中,每个训练器都需要使用全部的数据进行训练,所以当数据集中类别较多的时候,OvO 策略的训练开销要更小。二者的预测性能在多数情况下是相近的。
MvM 策略是一次取多个类作为正类,其余作为负类,显然 OvR 策略是 MvM 策略的一种特殊情况。MvM 的正负类构造不能随意选取,目前常用 “纠错输出码”(error correcting output codes,ECOC) 来构造。其主要过程分四步。
编码
为每个类别分配一个独特的二进制码字。假设有K个类别,则可以构建一个K×M的编码矩阵,其中M是二分类器的数量。每一行代表一个类别,每一列代表一个二分类器的输出。
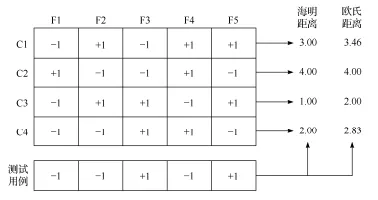
训练分类器
针对每一列 (每个二分类器) 进行训练。每个分类器的任务是区分对应的码字中是 “+1” 还是 “-1”。例如,图中第一列的分类器需要识别类别 2 (C2)(输出 “+1”) 与类别 1 (C1)、类别 3 (C3)、类别 4 (C4)(输出 “-1”) 之间的差异。
预测
对于新的输入样本,将其输入到所有训练好的分类器中,得到每个分类器的输出。
解码
将得到的输出与编码矩阵中每个类别的码字进行比较,返回其中距离最小的类别作为预测结果。ECOC 码对分类器的错误存在一定的容忍和修正能力。一般来说,ECOC 编码越长,纠错能力就越强,但随之而来的计算、存储开销都会上升。此外,对于有限类别的分类问题,组合数目也是有限的,所以 ECOC 码过长就失去了意义。
类别不平衡问题
上述的分类学习方法都基于一个共同的基本假设:不同类别的训练样例数目相近,但现实问题中不同类别的样例数目差别可能会非常大,这样模型在训练时很有可能忽视少数类样本,使得模型不具有解决实际问题的能力。


2026清华复试名单与所报水木上岸班型
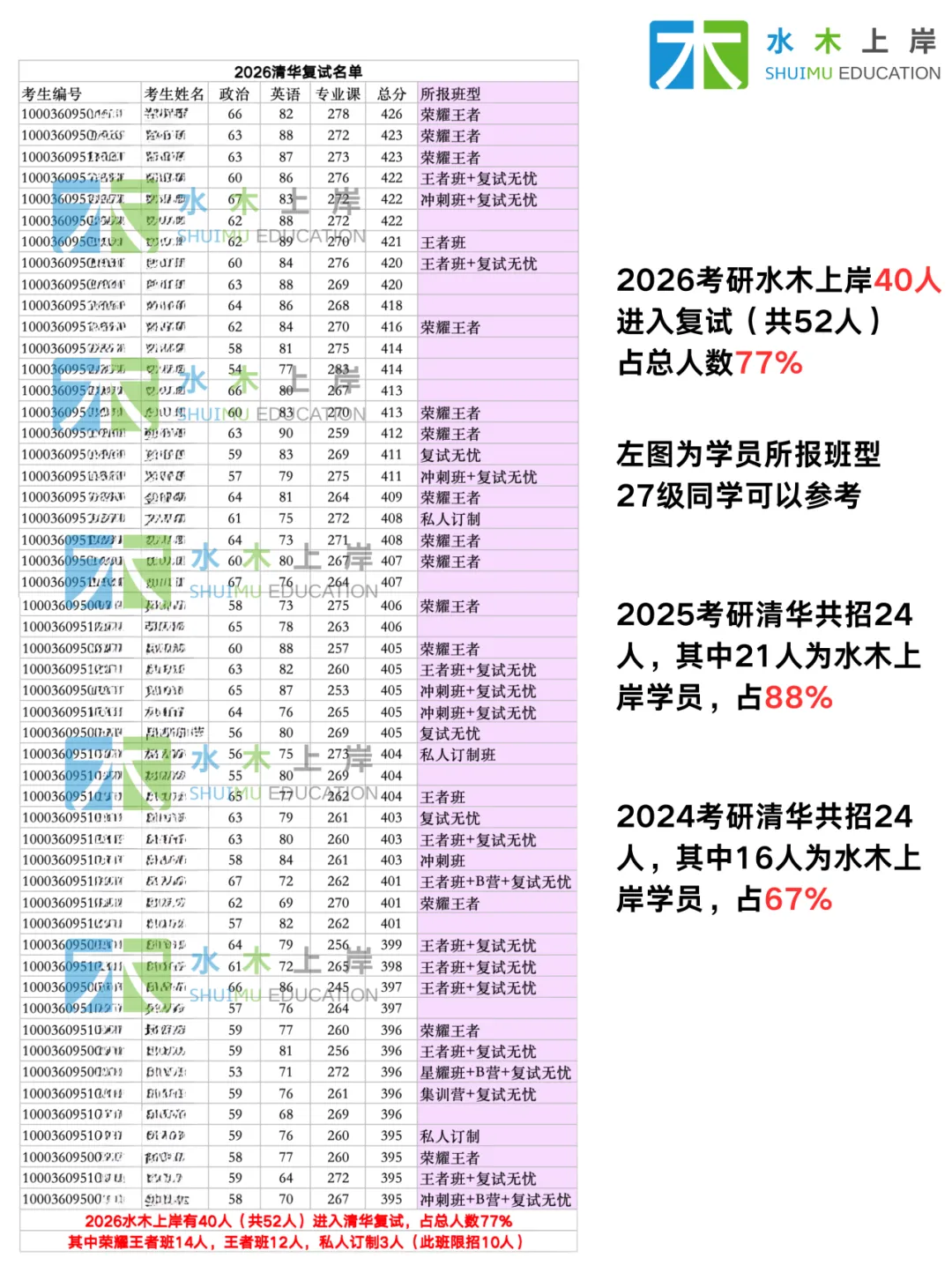
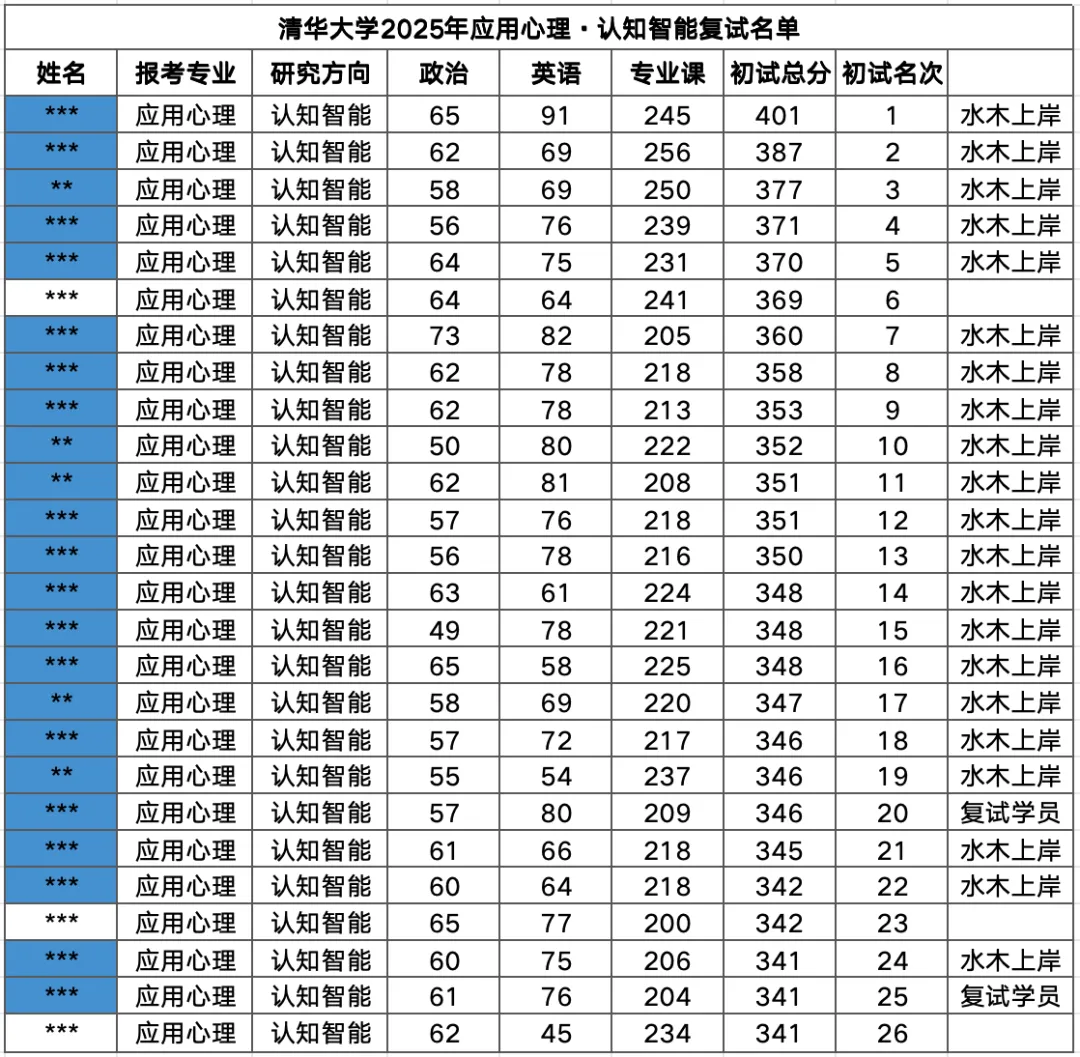
2025清华复试名单
往期精选

【26水木上岸40位学员进入清华复试】
【25上岸经验贴】
【清华录取通知书】
【26喜报】


公众号安利

水木上岸官方总号
由水木上岸学术团队打造的"智能心理测量"公众号,是心理学与人工智能深度交融的先锋平台。我们以"用算法解析心智,以科技赋能心灵"为使命,聚焦AI+心理学的跨学科创新,持续追踪全球顶尖实验室的科研动态,为读者搭建认知升级的智识桥梁。
水木上岸联合清华计算机系AI团队
推出了
心理学考研版 AI 助教
24 小时答疑