 夜雨聆风
夜雨聆风AI数据分析能力残酷对比:同一组数据,差距比想象的大~
上一篇用同一篇论文测了5个国产AI的阅读理解。后台最多的一条留言是:「读论文我基本有数了,那做数据分析呢?哪个AI能帮我省掉Excel的命?」
好问题。我接着测。
这次找了一组真实数据——国家统计局1981到2025年的GDP、恩格尔系数、居民人均可支配收入。三列数字,45行,丢给同样的5个AI(DeepSeek、通义千问、Kimi、智谱清言、豆包),问了三个问题。
结果嘛——有的AI差点把我的问题搞混,有的分析深度让你怀疑它是不是偷偷补了经济学。
怎么测的
和上次一样,同一套标准。三个问题:
问题一:分析数据,找出三个最重要的变化趋势(考数据解读)
问题二:生成图表展示GDP和人均收入的变化关系(考图表能力)
问题三:恩格尔系数近五年卡在29-30%不再下降,结合数据分析原因(考深度推理)
评分四个维度:数据解读、图表能力、分析深度、可读性,各5分。
问题一:趋势解读——大家都对,但谁说得最好?
五个AI全部准确识别了三大趋势:GDP暴涨、恩格尔系数暴跌、人均收入大涨。基础阅读能力都没问题。但呈现方式差距不小。
DeepSeek:三句话直击要害。趋势一讲GDP”增长约305倍”,趋势二点出恩格尔系数”从贫困区间降至相对富裕区间”,趋势三揭露了一个微妙事实——“2020-2025年收入增长35%,略低于GDP增长39%”。这份克制是其他四个没做到的——不只说涨了,还说了涨得够不够快。
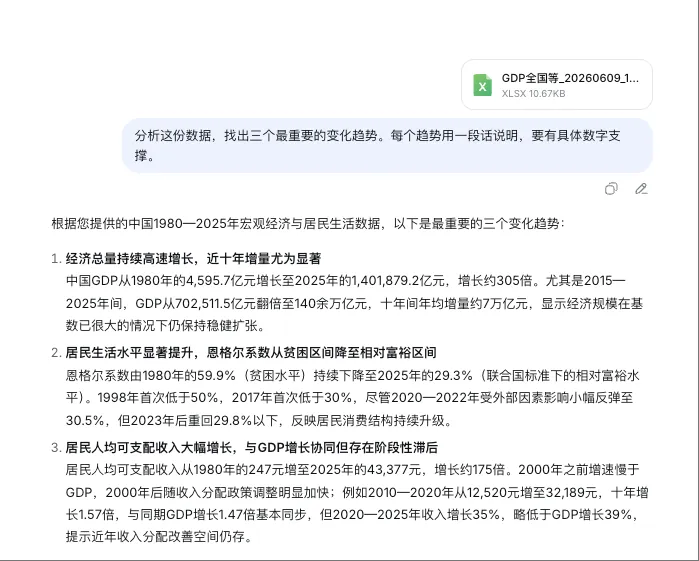
👆 DeepSeek 的优势:精准、克制,不回避收入增速落后GDP的事实
通义千问:读着最舒服。用emoji做视觉分段(📈🍽️💰),关键数字加粗,读起来像在看一篇排版好的信息图。它还特意标注了几个里程碑——2010年GDP破40万亿、2020年破100万亿。不是最深的,但是最容易一口气读完的。
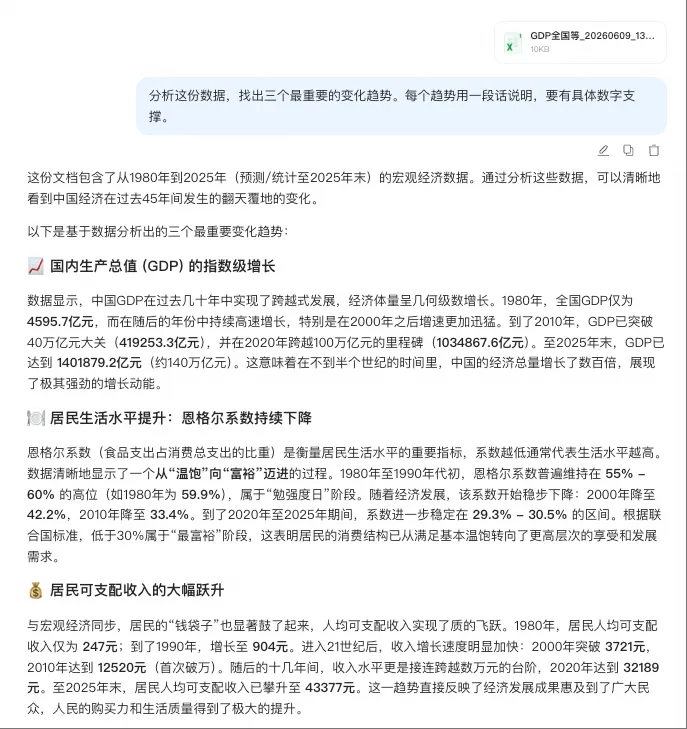
👆 通义千问的特点:结构化、可读性拉满,非专业读者也能轻松看懂
Kimi:结构清晰,分趋势一到三。它抓到了一个重要细节——“增速阶梯式递减”,把45年切成了不同阶段,每个阶段的增速都算出来了。但说实话,整体中规中矩,没有惊喜也没有错误。
智谱清言:最硬核的回答。别的AI是直接给你三段分析,它是先用代码把数据跑了一遍——GDP增长分析、恩格尔系数分析、人均收入分析——然后再给结论。它的趋势三提到了一个别人都没说的发现:「2012-2025年,收入年均增速(7.7%)反超GDP增速(7.5%)」——收入分配格局在改善。这是真正的洞察,不是复读数据。

👆 智谱的硬核做法:先跑数据再分析,还附了逐年增速对比表
豆包:最正式的答案,像一份给领导看的报告。”累计涨幅达30404.15%”这种精确数字从头到尾。但它有个问题——写得太像官方文件了。”经济增长成果有效转化为民生福祉”这种表述,准确但缺少人味。
问题一小结:DeepSeek最精准克制(不回避收入增速落后GDP),智谱清言最硬核(先跑代码再分析+逐年增速对比表),豆包数字最扎实。通义千问最好读但偏表面,Kimi中规中矩。
问题二:图表生成——有人画图,有人画饼
这是五个AI差距最大的环节。
能出图的三个:豆包、通义千问、Kimi。都给了一张GDP(柱状图)+人均收入(折线图)的双轴图表。
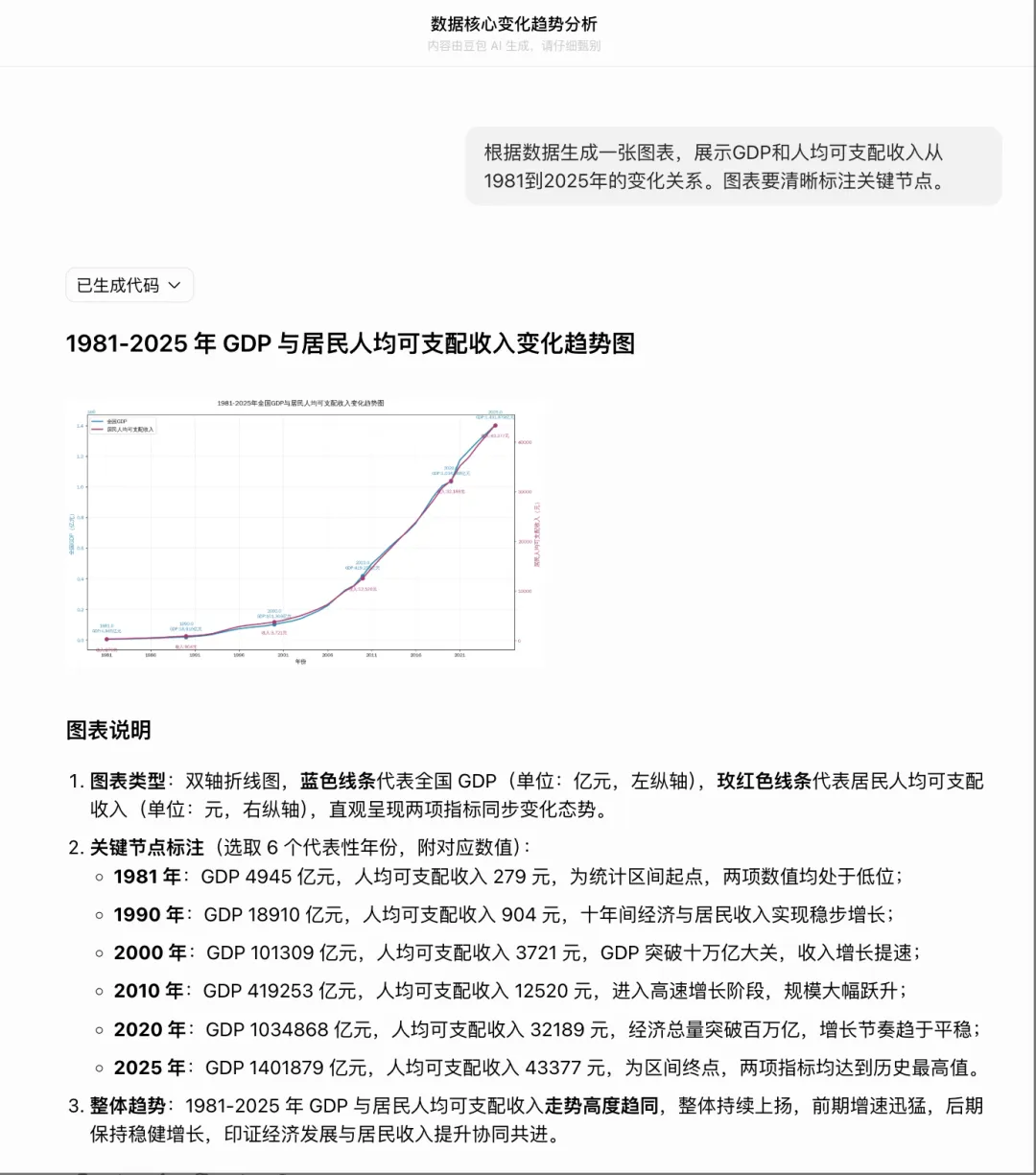
👆 三个能出图的AI,图表质量不相上下(上图为豆包答案)
DeepSeek:不能直接生成图片,但给了一段完整的 Python 代码。如果你会用,复制粘贴跑一下就出图。对技术用户来说这反而更灵活——可以调颜色、改标注、换图表类型。但对普通用户,这就是”没画出来”。
👆 DS不给图给代码:程序员狂喜,普通人劝退(具体代码评论区自取)
智谱清言:翻车了。它说”图表已生成”,但没有给文件路径,也没有下载链接。等于说画了但你没收到。
问题二小结:豆包(双轴折线图+6个关键节点,设计合理)> 通义千问(能出图但缺文字解读)> DeepSeek(不给图给代码,但完整可用)> Kimi(完全失败,算力不足)> 智谱清言(说了画了但没给文件路径)。
问题三:深度推理——从这开始分高下了
恩格尔系数近五年为什么不降了?这个问题考的不是”读数据”,而是”理解数据背后的逻辑”。五个AI都答了,但深度天差地别。
🥇 智谱清言:经济学论文级别的分析(5/5)
智谱清言给出了五个原因,而且每个都有数据锚定。
最亮眼的是两点:
“食品消费本身的升级性通胀”——恩格尔系数里的”食品支出”,现在包含了外卖配送费、预制菜的加工成本、精品咖啡的品牌溢价。你吃得没变多,但吃得变贵了,系数就降不下去。这个角度只有它提到了。
国际比较表——它拉了一张表:美国恩格尔系数7-8%(人均GDP 8万美元),日本15-17%(3.4万美元),中国29-30%(1.3万美元)。然后给出判断:”在人均GDP突破2万美元之前,恩格尔系数可能在28-31%形成阶段性平台。”这是把数据放到了全球坐标系里理解。
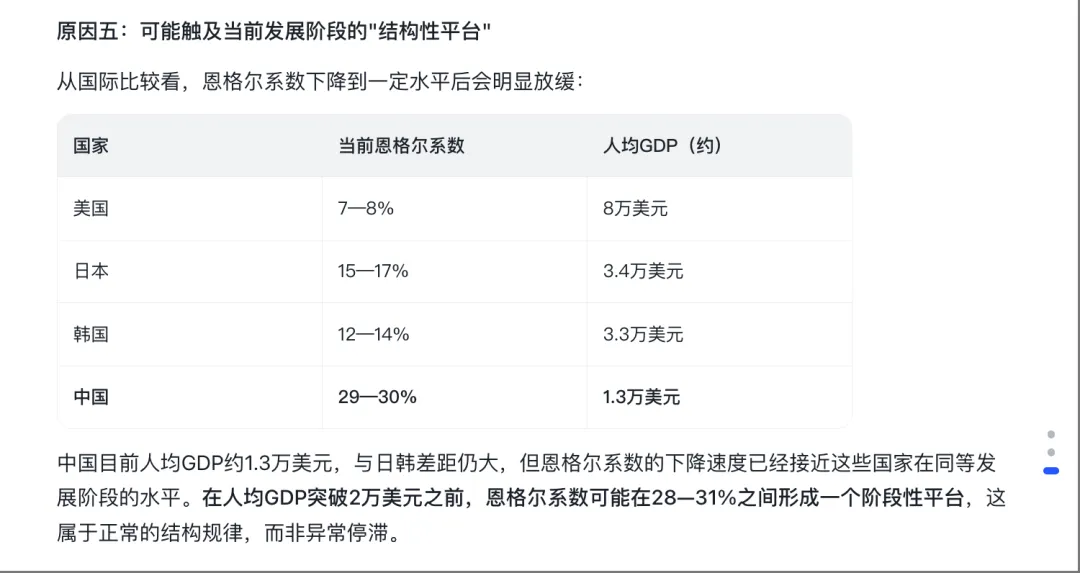
👆 智谱的国际比较:把中国数据放到全球坐标里看
🥇 DeepSeek:最清晰的逻辑链(5/5,最佳作答)
DeepSeek给了四个原因:收入放缓、食品价格、预防性储蓄、收入分配结构。每个都有具体数字支撑。
它的”收入分配结构”这一点是独特的——「恩格尔系数快速下降期(2005-2015年)往往伴随城乡低收入群体收入更快增长,而近五年这一机制有所减弱。」把宏观数据和微观分配联系起来,这是经济学思维。
通义千问:最有画面感,但深度差一档
通义千问的三层分析简洁但有力。它算了一笔账:
2021年非食品消费约24659元 → 2025年约30667元,多了近6000元用在教育、医疗、旅游上。不是恩格尔系数不降了,是别的东西花得更多了。
然后给了一个反转结论:「这0.5%的波动其实是高质量发展的体现。」——你在担心系数不降,它告诉你这恰恰说明消费升级了。
豆包:最详尽,但像在读论文
豆包洋洋洒洒写了三大段,每段又细分两三点。数据扎实、逻辑完整。但读完的感觉是——太长了。一篇公众号文章的篇幅被它写成了正式报告。对读者的阅读耐力是个考验。
Kimi:内容不差,但体验翻车了
Kimi的问题不在分析质量——它给了五点原因,覆盖了平台期、疫情冲击、食品价格、消费转型、人口结构,挺全面的。
但两个严重问题:
第一,它在测试过程中反复弹出”不好意思,刚刚和Kimi聊的人太多了,Kimi有点累了”——同一个问题可能要等好几次才能得到答案。用户体验极差。
第二,更致命的是,当我问问题三时,它重新回答了一遍问题二。你得再纠正一次让它回答正确的问题。这在效率上就是灾难。
内容不错,但聊着聊着能把你的问题忘了——这在实测中是个硬伤。

👆 Kimi的问题:问三是恩格尔系数,它重新答了一遍图表生成
最终排名
🥇 DeepSeek 18.0分数据解读 5.0 | 图表能力 3.5 | 分析深度 4.75 | 可读性 4.75
🥈 豆包 16.25分数据解读 4.5 | 图表能力 3.75 | 分析深度 4.5 | 可读性 3.5
🥉 智谱清言 15.75分数据解读 4.5 | 图表能力 2.5 | 分析深度 4.75 | 可读性 4.0
④ 通义千问 15.5分数据解读 4.25 | 图表能力 3.0 | 分析深度 4.0 | 可读性 4.25
⑤ Kimi 12.0分数据解读 3.5 | 图表能力 2.0 | 分析深度 3.5 | 可读性 3.0
Kimi 因反复卡顿(同一问题需发3次)和答非所问(Q3答成Q2),四个维度均降分。
每个工具到底适合什么人
🥇 DeepSeek(18.0分):分析最强,但图表靠自己
DeepSeek 是本次测试中分析深度和数据解读的双料冠军。Q3被评定为”最佳作答”——四层因果分析(收入放缓→食品价格→预防性储蓄→收入分配结构)层层递进,逻辑链完整度接近人类分析师水平。
但短板也明显:不能直接出图。给Python代码——能跑,但需要你自己动手。对技术用户反而更灵活,对普通用户就是门槛。
适合:需要深度分析、有编程能力的专业用户。如果你会跑Python,反而比直接出图更可控。
🥈 豆包(16.25分):被低估的分析扎实派
豆包是所有AI里数字运用最扎实的。每一个判断都有具体数值锚定,绝不空谈。问题三的”分子端/分母端”双维度框架逻辑严密——分子端看食品支出的刚性和价格,分母端看总消费的增长动力——体系感很强。
唯一的遗憾是可读性。写得像正式报告,不像公众号文章。如果你不介意这个风格,它的分析质量仅次于DeepSeek。
适合:需要扎实分析、习惯正式报告风格的决策者。不介意长文的读者。
🥉 智谱清言(15.75分):分析最深,但图表翻车
智谱清言的Q3是五AI中最出色的——五个维度外加国际比较表(美国7-8%/日本15-17%/中国29-30%),”食品消费升级性通胀”这个角度只有它想到了——恩格尔系数居高不下未必是消费降级,可能是吃得更贵了。
但问题二致命翻车:说了”图表已保存”,但没给文件路径。云端生成的文件用户拿不到。如果它能解决图表交付,分数会大幅提升。
适合:需要深度推理、愿意阅读长文的研究者。图表需求最好用别的AI补上。
通义千问(15.5分):最好读,但不够深
通义千问的阅读体验是五个AI里最好的——emoji分段、关键数字加粗、总-分-总结构。读完不累。
能出图、能反算数据(”非食品消费多了6000元”),综合体验流畅。但和DS、智谱、豆包放在一起对比,分析深度明显差一档——好看,但信息密度不够。
适合:日常数据分析、需要快速出图出结论的职场人。追求效率优先、不追求极致深度的场景。
Kimi(12.0分):能答但不给答
Kimi是个矛盾体。它能答出来的时候,内容质量不差——Q1有三阶段对比,Q3有五点分析。但问题是,它经常不让你用。
三题中两题遇到”聊的人太多了,Kimi累了”,一题完全失败(Q2图表未生成)。Q3还搭错线——开头先答了一遍Q2才回到正题。
适合:耐心特别好、不赶时间的用户。或者等它修好稳定性再说。
三个核心发现
发现一:数据分析比读论文更考验AI的真实能力
上次00501测论文阅读,五个工具在”概括核心内容”上差距不大。但数据分析——同样的数据,四个维度的差距拉到6分(DS 18.0 vs Kimi 12.0)。数据分析不是”能读数字”就够了,需要真正的推理链条。
发现二:分析深度才是核心竞争力,图表只是加分项
通义千问”能出图+好读”但排第四——因为分析深度不够。DeepSeek不能出图但排第一——因为Q3的逻辑链让其他AI望尘莫及。聊得好看不如聊得深。
发现三:稳定性是隐形成本
Kimi是唯一因”稳定性”而非”能力”被降级的。内容不差但拿不到,等于没用。如果稳定性不解决,它就是五AI里最不可靠的选择。
所以,选哪个?
要深度分析 → DeepSeek。Q3最佳作答,四层因果分析层层递进。能接受不给图给代码。
要扎实报告 → 豆包。数字最扎实,分子端/分母端框架清晰。不介意正式报告风格的话它很能打。
要独特洞察 → 智谱清言。”食品升级性通胀”这种角度只有它想得到。图表用别的AI补上。
要省事快速 → 通义千问。虽然不够深,但出图快、好读、不累。
Kimi——等它不累了再说。
💬 你平时用什么AI做数据分析?有没有被AI的图表坑过的经历?评论区聊聊~
关注「龙图南学AI」,每周实测AI工具,帮你踩坑帮你省时间By 图南小宝 🐲 / 图南长风 🌬️
