 夜雨聆风
夜雨聆风本体不一定要知识图谱;它真正的核心,是让那些不容出错的东西,进入一条受治理的轨道。
上一篇,我画了张地图:Palantir 本体、GraphRAG、语义层、Skill、MCP 这五派看着各说各话,其实在收敛成同一张分层的企业知识底座。但地图只告诉你有哪些楼层,没告诉你每层具体怎么盖、用什么料、怎么验收。这一篇,我想正面把这套方案讲清楚——概念、组成、技术选型,外加一段能真跑起来的骨架。
而真正让我把这套东西想透的,不是读了多少资料,是我自己当时一连串较真的疑问。就从这些疑问讲起。
一、我当时较真的几个问题
带着一连串问题,我反复研究了一段时间,也对照了业界主流的做法。真正卡住我、逼出后面这套理解的,是几个怎么也绕不过去的疙瘩。
第一个:Pydantic 到底有什么用? 调研里反复看到一种主流做法——用 Pydantic 给企业实体(借款人、贷款、抵押物)定义“形状”,当作本体的轻量落地。我也认真学了 Pydantic,知道它能定义实体、属性、关系,也明白它和普通 Python 类的区别。可我没懂——定义好一份 Pydantic 模型,它到底在哪儿发挥作用?是不是“Pydantic + RAG”就等于 GraphRAG?
第二个:语义层是不是只能查“死”指标? 结构化数据那条线,主流方案常落到一个“语义层”——通俗说,就是预先登记一批口径已审定的指标(所谓“受认证查询”)。这我同意有意义,Agent 要算财务指标时直接调,结果准、可验证。可它只能覆盖少量审定过的指标,没定义的怎么办?有人会说:没梳理的指标就算不准了,那还有啥意义?这好像不符合大家对大模型“什么都能智能处理”的期待。
第三个:“规则即代码”和普通规则引擎有什么区别? 还有一类做法叫“规则即代码”:把信贷政策里的硬约束(阈值、准入条件)写成带版本、可测试的函数或决策表。可我看那些示例,规则和溯源都是提前梳理好、写死的,LLM 好像根本没起关键作用。那这跟传统的规则引擎,到底有什么本质不同?
第四个,也是最要命的一个:这套做法,不就是把 LLM 能做的和不能做的分开吗? 把确定性的逻辑从 LLM 里搬出去,交给成熟的确定性技术,LLM 干 LLM 的——这听上去只是给模型框了条边界。可人们心目中的“本体”,不该是这样:它应该是给 LLM 的一份完整的企业知识说明书,让模型理解和操作一切。比如语义层,应该是个加强版的全量元数据描述,让模型读懂全部数据、自己推理出任何查询;再比如规则,根本无法穷举,最终应该是 LLM 从知识库里现场提炼出来。这才符合人们对“本体”和大模型能力的预期吧?把能做的和不能做的简单切开,算什么本体?
这第四个问题,其实是前三个的共同根源。它也确实把我自己问住了。
二、关键的反转:不是一道墙,是一个旋钮
后来想明白了:我前面的困惑,卡在一个错误的图景上——我以为“受治理”是在 LLM 和确定性技术之间砌一道墙,墙这边归模型,墙那边归代码。
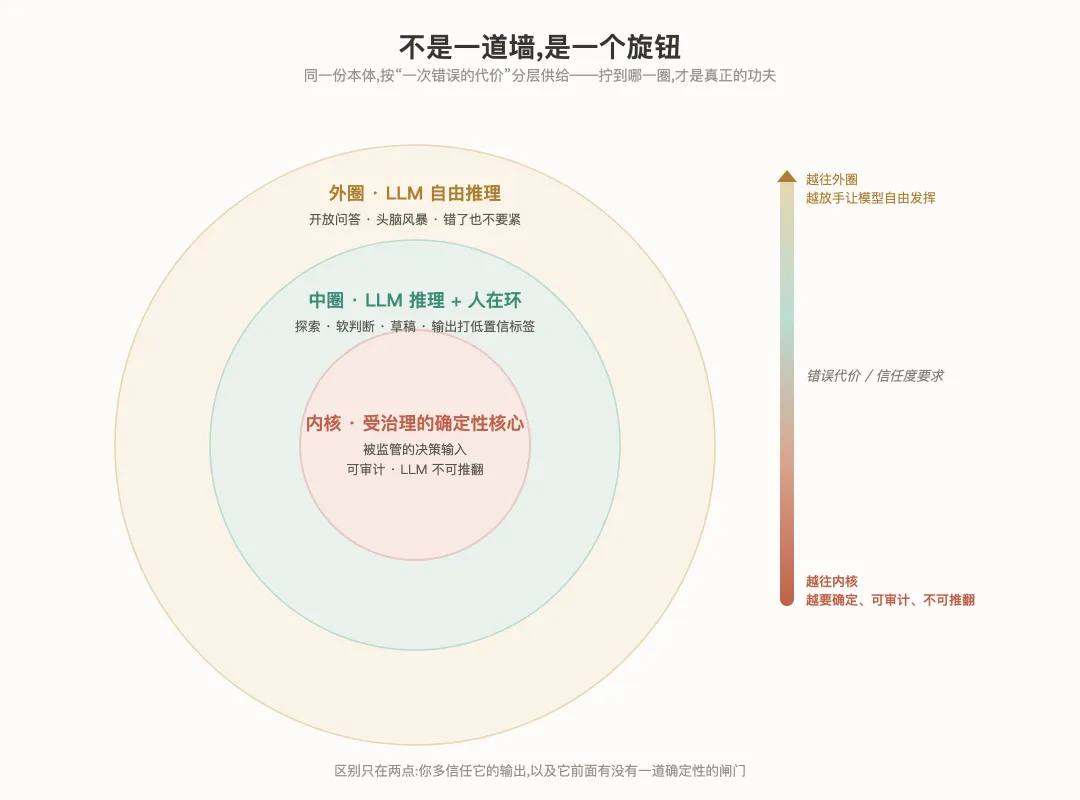
真实的图景不是一道墙,是一个旋钮。
把企业的知识,按“一次错误的代价”分层供给,就是三个同心圈。最内核,是受治理的确定性核心——被监管的决策输入,可审计,LLM 不能推翻;一笔信贷的负债收入比到底过没过线,走这里。中间圈,是 LLM 在丰富的知识模型上推理,但人在环、输出打低置信标签——探索、软判断、草稿走这里。最外圈,是 LLM 自由推理——开放问答、头脑风暴,错了也不要紧。
关键在于:同一份本体,喂所有圈层。区别只在两点——你多信任它的输出,以及它前面有没有一道确定性的闸门。同一个财务数,作为分析师探索用,坐在中圈,多放点兜底没关系,反正有人批判性地读结果;可同一个数,作为信贷决策的输入,必须坐进内核,走确定性的那条路。
我之前以为这两半是对立的:要么给 LLM 一份完整说明书、让它推理一切,要么把确定的逻辑锁进代码、给模型划条边界。想通了才发现,这两半不仅不对立,还相互增强。
那份“完整说明书”——把所有数据、术语、关系都用自然语言丰富地描述出来——不是为了让 LLM 在上面瞎推理,而是让它能把杂乱的现实,正确地映射成受治理层的输入,并且知道自己此刻在不在覆盖范围内:该信任内核给的确定答案时信任,够不着时主动标记或弃答。反过来,LLM 在这份说明书上推理时,会提议往受治理核心里加东西——从知识库里提炼出候选指标、候选规则——由人认证之后,确定性的覆盖范围就这样一点点长大。
所以我那个“规则无法穷举、最终靠 LLM 提炼”的直觉,是对的。错只错在角色:LLM 的角色是“提议者 / 顾问”和“生长机制”,而不是“裁决者”。它提炼出的东西,在变成有约束力的裁决之前,要先过人工认证。这条线不是我看低 LLM,是合规和审计自己在划——审计官问“哪条规则、哪个版本、怎么适用的”,“模型推理出来的”从来不是一个能交差的答案。
想通这个旋钮,前面那三个小疑问,顺手就解开了。
Pydantic 的疑问,卡在一个混淆上。一个知识系统其实有三个层:类型层(有哪些种类的东西、什么属性、什么关系、能做什么操作),这是一份契约、一份词汇表;实例层(真正的事实:这个借款人、这笔贷款),这是被存储的东西;检索层(运行时怎么把对的那一片取出来)。Pydantic 纯活在类型层,它既不存事实、也不做检索;GraphRAG 横跨的是实例层加检索层。所以“Pydantic + RAG”压根不等于 GraphRAG——它们在不同的层上。Pydantic 真正的用处,是当 LLM 的“非结构化世界”和确定性代码之间的翻译契约加质检关卡:它把模型从杂乱文档里抽出的东西,钉成可验证的类型,再安全地往下游传。
语义层的疑问,卡在把它想成“一批写死的 SQL”了。它其实是个模型——实体、度量、维度、连接、术语表——LLM 在这个模型上做组合(挑度量、挑维度、加过滤),由语义层编译成正确的 SQL。可回答的空间,是“所有建模过的度量 × 维度 × 过滤”的组合,大得很,远不止 N 个固定指标。够不着的部分,再退到带护栏的 text-to-SQL 兜底,但必须配校验、打上“未经口径审定、仅供参考”的标签。意义就在于:该有保证的地方有保证,其余地方是带标签的、优雅的尽力而为,而不是全盘都不可信。
至于“规则即代码”跟普通规则引擎没本质区别——老实说,对“裁决”这一步,是的,它就是个受治理、带版本的规则引擎。而这种“没区别”恰恰是它的特性,不是缺陷:可审计的东西,就必须长成这样。LLM 也没缺席,它做的是规则引擎做不了的事——把银行流水 PDF 里的数字抽出来、判断行业代码、从股权图里认定关联方,以及协助起草和维护规则本身。它只是不碰最后那一下裁决。
三、本体由功能定义,不由技术定义
绕回最根上的问题:本体到底是什么。
我现在的定义是:本体由功能定义,不由技术定义。判断一份东西是不是好本体,标准只有一个——它有没有把这个 Agent 完成任务所需的企业知识,刻画清楚。
这一条想清楚,很多纠结会自动消失。知识问答这种简单场景,一个组织良好的 RAG 知识库,就可以是本体;信贷预审这种复杂场景,本体才是语义层加文档检索加关系图加规则层加 skill 的合体。知识图谱 / GraphRAG 不是本体的必需品——只有当“关系”本身需要被当作关系来遍历、推理(多跳)时才需要;Pydantic 也不是必需品,它只是一种好的契约,用了更好,不用也不能说就不是本体。技术栈是手段,“清晰刻画 Agent 所需知识”才是目的。
有个常见的失败模式,正是把“把文档塞进向量库”误当成“好的本体”。本体的质量,来自向量库周围那层描述性骨架——元数据、术语表、结构保留、范围界定、治理——而不是向量库本身。
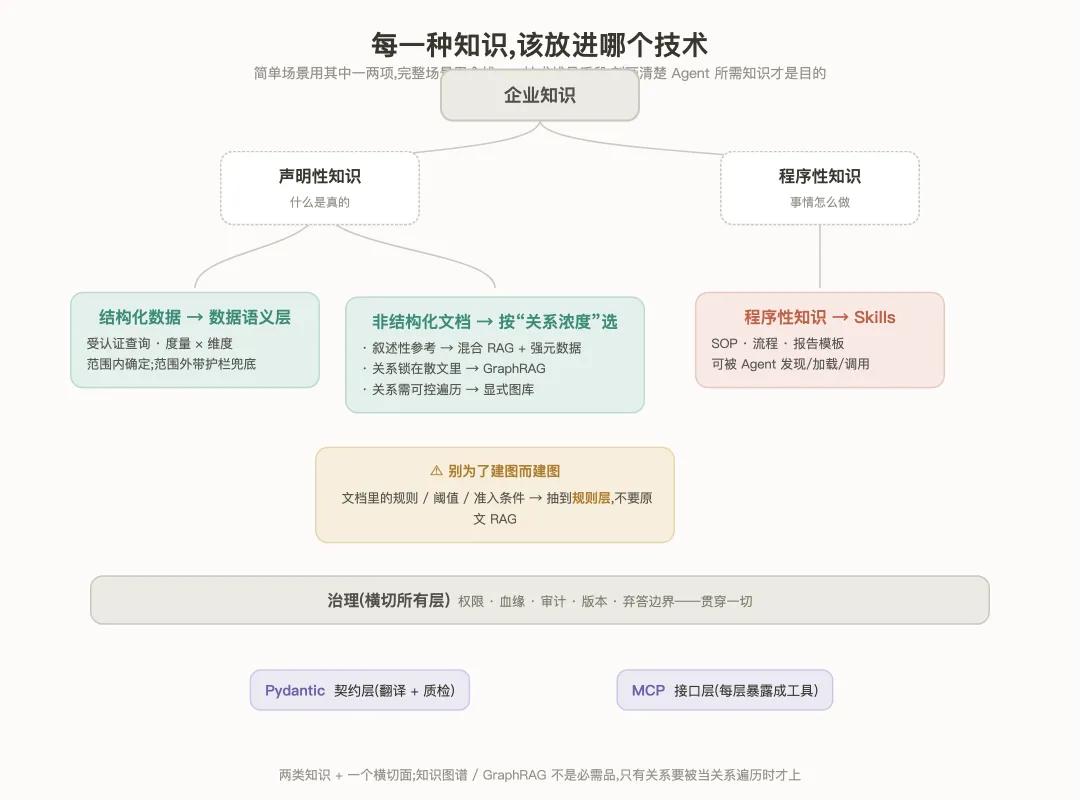
把这层想清楚,本体的组成就是按知识种类来铺:简单场景用其中一两项,完整场景用全栈。
声明性知识、结构化数据,走数据语义层——实体、度量、维度、连接、术语表,外加一批受认证查询。
声明性知识、非结构化文档,按“关系的浓度”选:叙述性的参考材料(背景、行业说明)走混合 RAG(向量加 BM25)加强元数据(生效日期、版本、文档类型);关系密集、而且关系锁在散文里取不出来,才上 GraphRAG;关系密集但需要可控遍历、关系又多来自结构化来源(股权穿透、担保链),用显式图库更划算。这里有个要紧的纪律:文档里的“结构化知识”——规则、阈值、准入条件、监管限额——不要原文 RAG,要抽取到规则层。别为了建图而建图。
程序性知识,走 Skills——把“怎么写贷前调查书”“预审 SOP”做成可被 Agent 发现、加载、调用的模块。
再加三样配套:Pydantic 当契约层(可选但推荐),MCP 当接口层(把每一层暴露成一个工具),治理横切所有层(权限、血缘、审计、版本、弃答边界)。
上一篇我提过三条判断轴,其中一条是“声明性知识和程序性知识要分开”。现在你能看到,它不是一句口号,是直接决定每种知识落到哪个技术上的那把尺。
四、一段能真跑的骨架
光有概念和选型,还是悬的。我把信贷预审这个场景里“必须正确”的那部分,落成一段最小骨架——本体即代码、语义层即代码、规则即代码,溯源和弃答都嵌进去。不上 OWL/RDF,纯 Python。
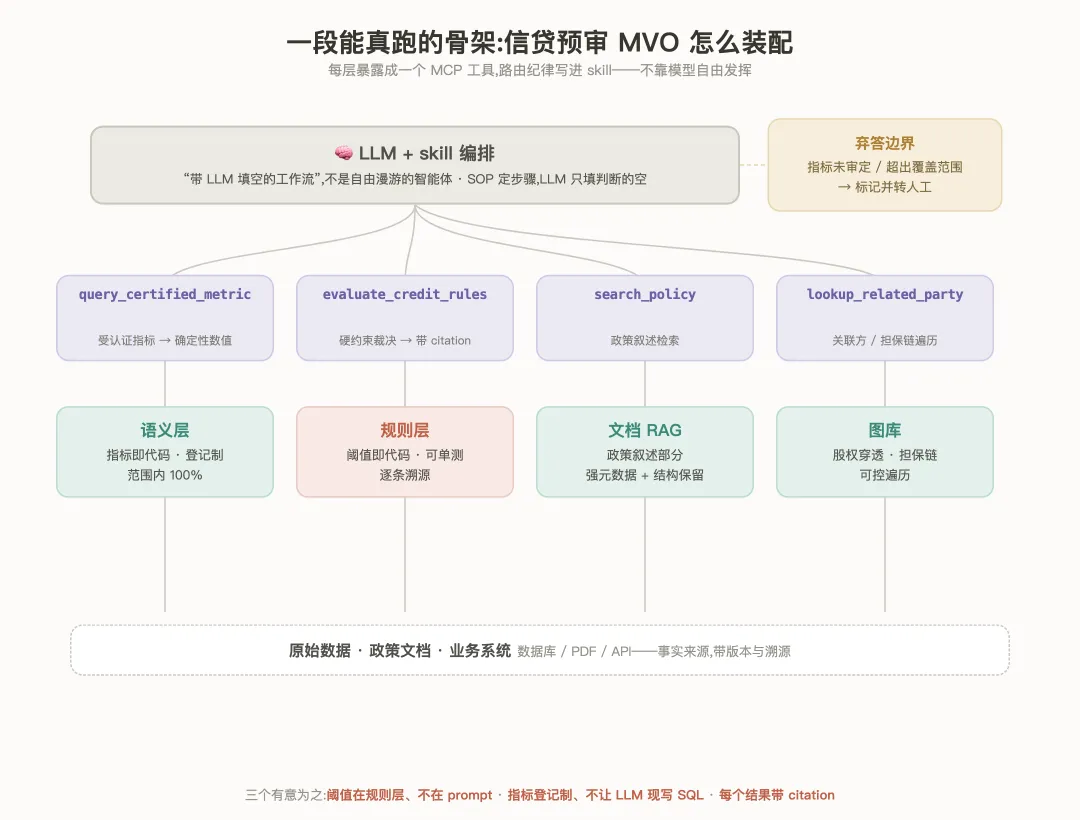
from pydantic import BaseModelfrom decimal import Decimal# ① 本体:实体即代码(轻量,Pydantic 即可,不上 OWL/RDF)classLoanApplication(BaseModel): application_id: str borrower_id: str amount: Decimal is_related_party: bool # 关联方 → 触发特定监管口径# ② 语义层:受认证的指标即代码 —— 不让 LLM 现写 SQL,# 而是登记一份口径已审定的参数化查询;范围内确定,范围外不生成CERTIFIED_METRICS = {"debt_to_income": {"desc": "负债收入比,口径见信贷政策 v3.2 §4.1","sql": "SELECT total_debt / NULLIF(annual_income, 0) ""FROM fin_profile WHERE borrower_id = :bid","owner": "风险管理部","version": "3.2", },}# ③ 规则即代码:硬约束确定性评估(绝不交给 LLM 裁决)classRuleResult(BaseModel): rule_id: str passed: bool actual: Decimal | None threshold: Decimal | None citation: str # 逐条溯源到政策条款 + 版本,供审计defcheck_dti(dti: Decimal) -> RuleResult: threshold = Decimal("0.55") # 阈值来自政策,集中维护、可单测、可随版本演进return RuleResult( rule_id="CREDIT-DTI-001", passed=dti <= threshold, actual=dti, threshold=threshold, citation="信贷政策 v3.2 §4.1", )几个有意为之的地方:阈值写在规则层,不写在 prompt 里——它可单测、可随政策版本演进;指标是登记制,不是让 LLM 现写 SQL——范围外直接走弃答;每个规则结果都带 citation,因为审计要的就是这个。这三样加起来,就是把信贷里“必须正确”的部分,从模型的即兴发挥里彻底拿出来了。
然后是怎么把各层组装起来。最干净的说法:每一层都通过 MCP 暴露成一个工具,而路由的纪律,写在 skill 里,不靠模型自由发挥。
# 每层暴露为一个 MCP 工具;路由纪律写在 skill / 系统提示里,不靠模型自由发挥TOOLS = ["query_certified_metric", # 语义层:受认证指标 → 确定性数值"evaluate_credit_rules", # 规则层:硬约束裁决 → 带 citation 的结果"search_policy", # 文档 RAG:政策叙述检索"lookup_related_party", # 图库:关联方 / 担保链遍历]# skill 里的硬约束(节选):# · 任何信贷数值输入,必须调 query_certified_metric,绝不自己算# · 指标未经审定 → 标记并转人工(弃答)# · 需要规则判定 → 调 evaluate_credit_rules,不自行裁决# · 每句结论必须带溯源;超出覆盖范围 → 弃答对受监管的那条路径,它更像“带 LLM 填空的工作流”,而不是一个自由漫游的自主智能体。SOP 规定步骤,LLM 填判断的空。越是高风险,越要把编排收紧在 skill 里,而不是交给模型即兴。
五、怎么建,怎么养
方案画出来了,真要落地,还有两个绕不开的问题:第一次怎么建,以后怎么养。
先说建。最反直觉、却最重要的一条:用例优先,不是资产优先。不要一上来就盘点全企业的数据资产,而是从 Agent 要服务的那个决策倒推——贷中预审需要哪些事实、指标、规则、关系、SOP?这张清单,就是你的初始本体范围。上一篇说过别把海煮开,这里是它的具体做法:从最小可用本体起步,先回答一个高价值问题,跑起来、交付价值,再随新场景往外长。
建的过程里,有个反模式我想专门点出来:别先写一份 Word 规格、再人肉翻译成技术语言。这个翻译是有损的,而且会随时间漂移。正确的姿势是,让那份“人能读的目录”——实体目录、带定义和负责人和溯源的指标目录、带溯源的规则目录、术语表、关系模型——本身就是“机器能读的”那一份。业务人员在描述、定义、对应到哪条政策款项上签字,他们不需要学技术语言;LLM 加工程师,负责把它翻译成各层的工具。每个产物,都带负责人、版本、溯源。
再说养。本体永远不会“完工”,所以更新机制比第一次构建更决定生死。我的心智模型是:把本体当代码库管。源文档带版本;政策一变,让 LLM 去 diff 新旧、提出增量(哪些指标、规则、款项变了),人只认证这个增量。溯源链——规则对应到政策第几条第几版——让全程可追。改一个阈值,就是一行 PR 加一个单测,而不是重新建模一遍。文档 / RAG 层也只重建变更过的那几篇,增量、便宜。
让更新便宜的根本原则只有一条:把“事实来源”和“上线产物”之间的距离,压到最小,并保持可追溯的链接。这样每次更新,就退化成“重新推导受影响的那一小片,加认证增量”。反过来,一旦你把一切都人肉翻译进了一个独立的表示,每次更新都会很痛。
六、所以,本体到底是什么
绕了一大圈,回到那个被资本带火的词。
归根到底,本体不一定要知识图谱,也不一定要那套 OWL/RDF 加推理机的重家伙。它真正的核心,是让那些不容出错的东西,进入一条受治理的轨道——可溯源、可审计、可版本化、LLM 不能擅自推翻。剩下的,放心交给模型去理解、去编排、去解释。
所以本体不是一种特定技术,而是一种姿态:一种为风险分层、把企业知识恰当地喂给 AI 的姿态。语义层也好,GraphRAG 也好,Skill 也好,Pydantic 也好,都是这个姿态下的工具,而不是姿态本身。那个旋钮——什么进内核、什么放外圈——拧到哪里,才是真正的功夫。
到这里,概念、组成、骨架算是齐了。但里面还有两块,我后来又单独想得更深:一块是文档那条线,RAG 怎么靠强元数据和治理,从“能召回相关段落”变成“能交差的本体”;另一块是结构化数据那条线,智能问数到底该怎么搭语义层。这两块,留给后面两篇。
下篇见。
