 夜雨聆风
夜雨聆风目录
1、2026年AI推理芯片演进背景:内存墙与资本开支拐点
2、NVIDIA Groq:SRAM片上内存路线与确定性架构
3、Taalas:基于模型硬连线架构的定制化AI推理芯片
4、Cerebras Systems:晶圆级单芯片架构推理方案
5、Etched:Transformer专用推理ASIC芯片Sohu
6、d-Matrix:基于存内计算架构的AI推理芯片
7、Untether AI:近内存计算架构探索与融合
8、Axelera AI:数字内存内计算平台
9、Tenstorrent:基于RISC-V架构的AI推理芯片及系统布局
10、SambaNova:聚焦可重构数据流与三级内存的AI推理方案
11、MatX:聚焦大语言模型专属加速的MatX One芯片
12、Hepzibah AI:存内计算IP核
13、Positron AI推理芯片与系统架构
14、FuriosaAI:AI推理芯片与架构演进
15、AI推理芯片核心参数对比表
一、2026年AI推理芯片演进背景:内存墙与资本开支拐点
在2026年,生成式AI已经全面迈入智能体(Agentic AI)与长上下文检索增强生成(RAG)时代。这一应用端的范式转变,使得AI系统对底层硬件的要求从单纯的算力堆砌,彻底转向超高带宽、超大容量和极低延迟的内存系统。
2026年全球半导体领域迎来了一场前所未有的内存超级周期。由于HBM3e、HBM4以及服务器DRAM价格的高速上涨,内存采购在超大规模云服务商(CSP)的硬件资本性支出(CapEx)中占比已飙升至30%左右,而这一数字在2023至2024年间仅为8%左右。内存不仅成为了数据中心构建的核心瓶颈,也成为了总体拥有成本(TCO)的最主要驱动因素。
从计算架构理论来看,由于AI芯片的算力增长极快,而内存带宽的提升速度相对滞后,导致算力与带宽平衡的拐点不断向右上方移动。这意味着,绝大多数实际的AI推理负载都已经深陷在“内存受限”区域内。在这种背景下,单纯增加计算单元(FLOPS)无法带来同比例的性能提升,反而会导致硅片利用率低下和能耗剧增。
因此,2026年AI推理芯片的创新主战场已经发生转移:如何打破内存墙、优化数据移动路径以及重构内存层级,成为了决定推理芯片成败的核心。以NVIDIA Groq为代表的片上SRAM确定性路线、以d-Matrix和Positron为代表的LPDDR5x商用内存路线、以Cerebras为代表的晶圆级大片片上存储路线、以SambaNova和Tenstorrent为代表的混合多级耦合路线,以及以Etched为代表的ASIC硬编码路线,正展开激烈的技术路线竞争。
二、NVIDIA Groq:SRAM片上内存路线与确定性架构
在2026年的AI推理芯片演进中,基于片上SRAM(静态随机存取存储器)与确定性架构的路线成为一个重要的技术分支。这一路线的主要代表是美国企业Groq(成立于2016年),其核心技术已于2025年底被NVIDIA以约200亿美元的规模授权整合。在2026年的GTC大会上,英伟达正式发布了NVIDIA Groq 3 LPU(Language Processing Unit,语言处理单元)及LPX机架系统,将其纳入Rubin计算平台,形成混合推理架构。

NVIDIA Groq 3 LPX计算托盘(8颗LPU + 互连)来源:NVIDIA技术博客
1.核心架构:张量流处理器(TSP)与确定性执行
在微架构层面,Groq LPU采用了张量流处理器(TSP)架构,其设计思路与传统计算芯片具有显著差异。该架构摒弃了硬件缓存、分支预测和上下文切换模块,采用“确定性执行”策略,即完全依赖软件编译器在编译阶段预先安排并静态调度所有的数据流水线与操作。
芯片内部被划分为专用的功能切片,包括矩阵乘法(MXM)、向量运算(VXM)、内存(MEM)和数据交换(SXM)单元。这种完全软件定义的数据流水线设计主要目的是消除动态调度过程中的延迟抖动,为大语言模型推理的Decode阶段提供高度可预测的低延迟输出。
2.内存配置与晶圆制造规格:以片上SRAM为主存储
在物理硬件配置上,NVIDIA Groq 3放弃了外部高带宽内存(HBM),转而使用大规模的片上SRAM作为主要的工作内存,用于存放模型权重、激活值以及KV Cache,从而最大化每瓦词元数(tokens/watt)并降低片外数据搬运的延迟。
芯片级与制造规格:单颗NVIDIA Groq 3 LPU集成了约500MB的高速SRAM,内存带宽达到150TB/s。根据TrendForce披露,由于高容量SRAM的物理集成需求,Groq 3芯片的物理Die(裸片)面积超过了700平方毫米,单片12寸晶圆仅能切割约64颗芯片。其芯片面积的70%至80%被SRAM存储单元占用,这使得该方案在提供高带宽的同时也面临着较高的制造难度。
机架级规格:采用液冷设计的LPX计算集群(机架)包含256颗LPU,机架级SRAM总容量为128GB,聚合带宽达到40PB/s(扩展带宽为640TB/s)。在互联方面,芯片间通过96条112Gbps链路连接,单芯片提供2.5TB/s的互联带宽,多个芯片可通过特定协议像“单核”一样协同运行。
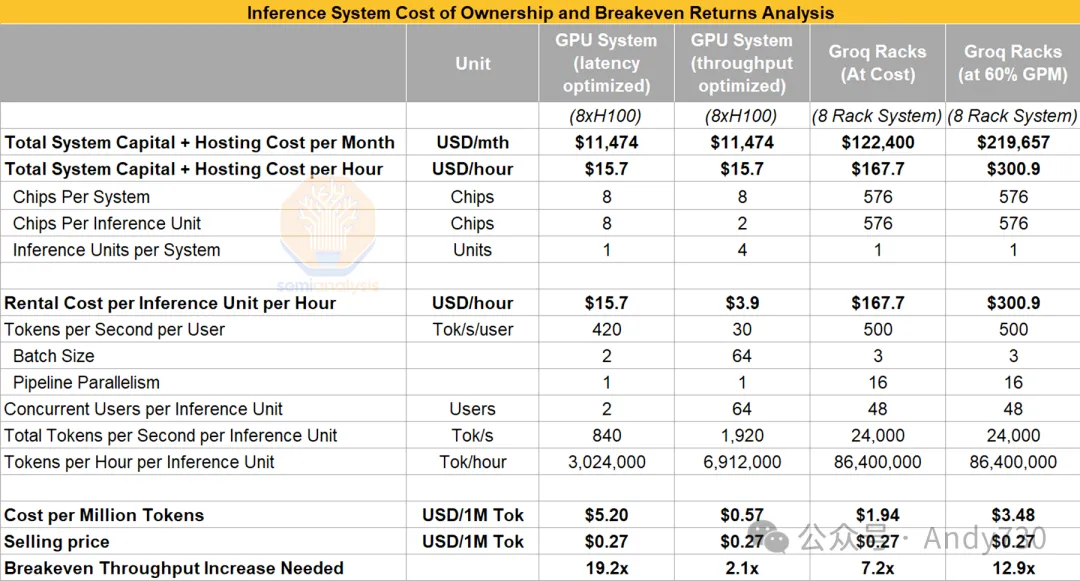
Groq vs NVIDIA GPU推理性能对比(token/s与成本表) 来源:SemiAnalysis
3.异构计算模式与性能表现
由于SRAM具有极高的带宽但物理容量存在限制,目前该技术主要以“GPU+LPU”的异构计算模式进行部署。在实际应用流程中,由配备大容量存储的传统GPU负责处理依赖较高通用性的Prefill阶段,而由LPU专注于生成词元的Decode阶段。
在运行表现上,LPX机架能够提供315PFLOPS的AI算力。基于Llama 3或Llama 3.1 70B模型的测试数据显示,该方案下单用户的处理速度约为750至800词元/秒,首字延迟(TTFT)维持在18至50毫秒的区间。在能耗表现方面,结合了Rubin平台与LPX机架的混合推理架构,其每兆瓦的推理吞吐量较前代系统提升了约35倍。
三、Taalas:基于模型硬连线架构的定制化AI推理芯片
1.企业背景与技术路线
Taalas是一家位于加拿大多伦多的AI芯片初创企业,成立于2023年,由具备AMD、NVIDIA等厂商工作经验的前Tenstorrent联合创始人Ljubisa Bajic担任首席执行官。2026年2月19日,Taalas正式发布其首款AI推理产品HC1,并宣布完成1.69亿美元融资,累计融资额超过2.19亿美元。



在技术路线上,Taalas未采用传统图形处理器(GPU)或通用人工智能加速器的设计,而是专注于特定用途集成电路(ASIC)的极端定制化。其核心策略是将特定AI模型的架构、参数和权重在物理层面上“硬连线”(hardwire)到硅片电路中。该公司开发了Taalas Foundry平台,用于将AI模型转化为电路设计,并利用结构化ASIC工艺修改最后两层金属层来完成生产。在配合中国台湾的台积电(TSMC)代工的情况下,这一转换和制造流程通常需要约两个月时间。
2.硬件架构与内存配置
针对传统AI推理芯片在计算单元与外部存储(如HBM或DRAM)之间频繁进行数据传输所面临的功耗和延迟瓶颈,Taalas的架构将存储与计算融合在单一芯片上。
在HC1芯片的设计中,外部高带宽内存和DRAM被完全剔除。其模型权重通过Mask-ROM(掩膜只读存储器)的形式,在制造阶段直接蚀刻进晶体管及金属层中,运行时无需再次加载。同时,芯片内部配备了少量静态随机存取存储器(SRAM)用于处理KV Cache、激活值,并支持一定程度的上下文窗口配置和通过LoRA适配器进行的有限模型微调。
3.首款产品HC1规格与表现
Taalas的首款芯片HC1专为Meta Llama 3.1 8B模型定制。该芯片采用台积电6纳米(N6)工艺制造,单颗芯片面积约为815至880平方毫米,集成约530亿个晶体管。HC1通常以PCIe扩展卡的形式部署,单芯片热设计功耗(TDP)约250W。在硬件组装上,单个标准服务器可容纳10张HC1计算卡,整机功耗约2.5千瓦,可使用传统风冷散热,降低了对液冷或高级封装方案的依赖。
在性能测试中,首代HC1采用了3-bit基础搭配6-bit选择性的自定义权重混合量化方案。根据Llama 3.1 8B模型(1k输入/1k输出序列)的实测数据,其单用户吞吐量约为16000至17000词元/秒。作为参考对比,在运行相同模型时,NVIDIA的H200/B200芯片吞吐量约为230至594词元/秒;Groq LPU约为594至600词元/秒;SambaNova约为932词元/秒;Cerebras的系统约为1981至2000词元/秒。由于硬件层面的精简,Taalas表示该方案的Llama 3.1 8B推理成本可降至每百万词元0.0075美元,并在整机功耗与构建成本上低于传统的GPU数据中心方案。
4.应用局限与后续规划
Taalas的硬件架构虽然在特定模型的吞吐量和成本控制上表现出优势,但主要代价是大幅削弱了设备的灵活性。由于模型已被物理固化在芯片内部,用户无法在同一硬件上随意切换或升级到全新的模型架构;若需更换底层模型,则必须重新设计掩膜并制造新的芯片。
此外,首代产品由于采用激进的自定义量化方案,可能存在模型输出质量方面的折损。为应对这一问题并提升兼容性,Taalas计划在预计于2026年冬季推出的下一代平台(HC2)中采用标准的4-bit浮点量化技术,并计划支持规模更大的前沿AI模型。
四、Cerebras Systems:晶圆级单芯片架构推理方案
Cerebras Systems是一家位于美国加州的AI芯片研发企业,其技术路线主要聚焦于高性能AI推理场景,重点涵盖大模型的低延迟与高吞吐推理、实时交互以及智能体应用。不同于依赖多芯片互连的传统GPU集群架构,Cerebras采用了独特的晶圆级单芯片架构,以应对万亿参数模型部署过程中的计算与内存瓶颈。
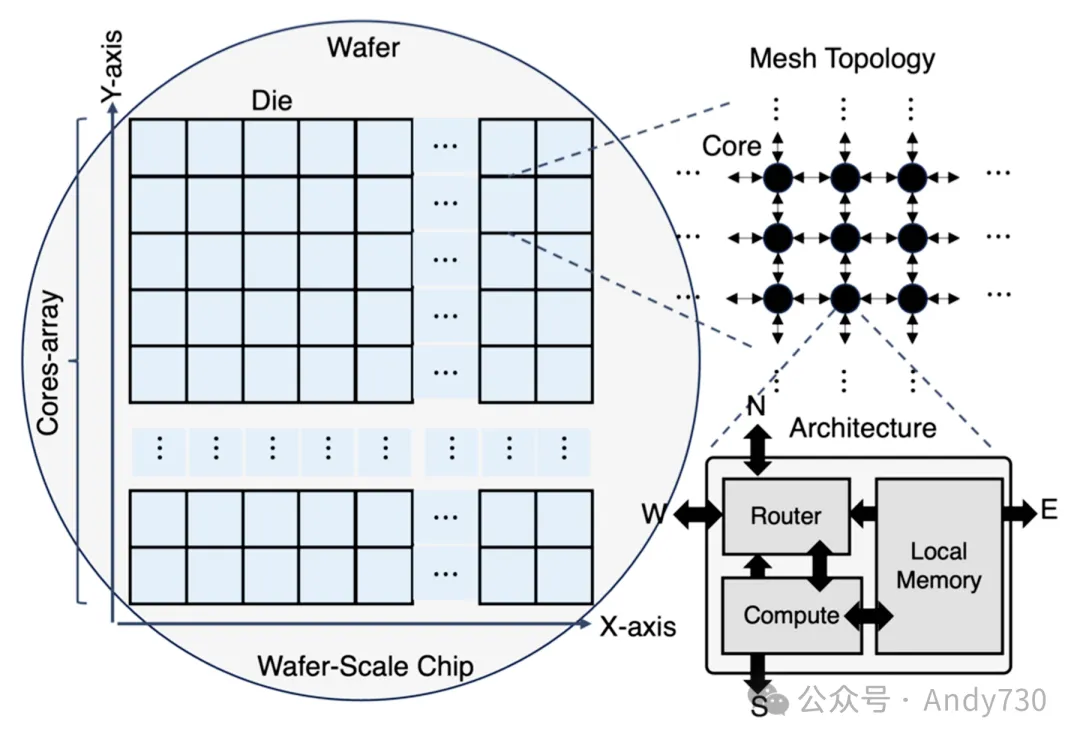
Cerebras晶圆级芯片架构。来源:Wafer-Scale AI Compute: A System Software Perspective
1.核心产品与硬件规格
Cerebras当前的主力芯片产品为2024年发布的第三代晶圆级引擎WSE-3(Wafer Scale Engine 3)。该芯片采用台积电(TSMC)的5nm工艺,将整片300mm晶圆制造为单一物理芯片,核心面积达46225平方毫米。在硬件规格上,WSE-3内部集成了4万亿个晶体管与90万个AI优化核心,峰值AI算力约为125PetaFLOPS(基于FP16等精度计算)。
基于WSE-3,该公司推出了CS-3系统作为完整的数据中心部署节点。CS-3采用15U或16RU机架式水冷设计,单节点搭载一颗WSE-3芯片,整机运行功率约为23至25kW。该系统既支持独立部署,也支持集群扩展,最高可构建2048个节点的集群系统。
2.技术架构与内存配置
大语言模型推理通常受限于内存带宽(Memory-bound)。Cerebras的架构设计主要通过硬件级的本地化计算与内存来减少芯片外(Off-chip)数据读写,从而缓解所谓的“内存墙”问题。
晶圆级互连(Wafer-Scale Integration):WSE-3将所有的计算核心、内存和网络直接集成在同一块硅片上。片上核心通过2D网络架构相连,内部互连带宽达到214Pb/s,这避免了传统多卡节点间跨芯片互连(如NVLink或InfiniBand)产生的延迟和带宽损耗。
片上高速SRAM:芯片内部集成了总计44GB的高速SRAM,且SRAM与计算单元物理位置相邻,无需复杂的缓存层级设计。其片上内存总带宽达到21PB/s,访问延迟处于纳秒级别,这在一定程度上满足了模型权重与KV Cache的高速读取需求。此外,架构支持权重流式处理(Weight Streaming)与稀疏计算,兼容4-bit权重与16-bit计算的量化推理。
外部存储扩展:为支持显存占用超过44GB的超大模型,系统可连接名为MemoryX的外部扩展存储单元。单系统支持从12TB扩展至最高1.2PB(1200TB),这使得单逻辑设备能够支持最高达24万亿参数的模型。推理时,权重数据从MemoryX以流式加载的方式传输至片内计算。
3.性能表现与应用场景
在独立第三方(如Artificial Analysis)的基准测试中,基于CS-3系统的推理服务在处理多种规模的语言模型时展现出了较高的数据吞吐能力。
运行Llama 3.1/3.2 70B模型:处理速度约为2100至2500词元/秒。
运行Llama 4 Maverick(400B级别)模型:处理速度超过2500词元/秒。
运行GPT-OSS-120B模型:处理速度超过2700词元/秒。
同时,该架构也具备运行万亿参数模型的能力。以支持月之暗面(Moonshot)的Kimi K2.6万亿参数模型为例,系统可维持近1000词元/秒的输出速度。在面向终端用户的应用中,这种高带宽本地内存架构能够支持高并发下的低延迟响应(Time to First Token较短),适用于要求实时性的语音交互、视频生成以及复杂长链推理任务。
4.商业化与行业动态
从商业落地来看,Cerebras的商业模式主要包括系统硬件销售与基于CS-3的云推理服务接入。在2024至2025年期间,Cerebras与亚马逊云科技(AWS)达成合作,共同推出了结合AWS Trainium与CS-3的混合部署方案。相关商业报道显示,Cerebras计划于2026年进行首次公开募股(IPO)。
客观而言,Cerebras提供的晶圆级方案在部分细分的高吞吐推理场景具备性能上的单点优势,并在总拥有成本(TCO)上提出了相应的竞争力。但作为一种高度定制化的硬件架构,其在市场推广中仍需应对生态软件栈的完善、特殊供电与散热(液冷)需求,以及行业整体供应链能力的考验。
五、Etched:Transformer专用推理ASIC芯片Sohu
Etched是一家位于美国加州的芯片公司,成立于2022年。该公司的核心产品Sohu是一款专门针对Transformer架构设计的专用集成电路(ASIC)推理芯片。截至2026年1月,Etched完成了约5亿美元的融资,公司估值达到50亿美元,资金计划用于加速芯片的量产与生态构建。
1.核心架构与物理配置
Sohu芯片采用台积电(TSMC)的4nm工艺制造。在架构设计上,Sohu与采用通用架构的GPU不同,选择将Transformer的完整组件(如注意力机制Attention、QKV投影和前馈网络FFN等)直接硬编码为固定功能电路。这种设计省去了通用计算芯片在内核启动、调度和分支等方面的开销,其浮点运算(FLOPS)有效利用率宣称可达90%以上。该架构专为batch-1自回归解码这一真实的推理场景进行了优化,以提升KV Cache访问效率与数据生成速度。
在内存硬件方面,单颗Sohu芯片搭载了144GB的HBM3E内存,提供约4.8TB/s的带宽。该硬件方案采用了标准的HBM堆叠架构,能够通过多芯片互连扩展,以满足大型语言模型(如70B以上规模)推理时对权重和KV Cache的大容量需求。
2.性能声明与当前状态
在性能表现方面,根据Etched官方公布的数据,单台搭载8颗Sohu芯片的服务器在运行Llama 70B模型时,吞吐量可达500000词元/秒。官方宣称,该方案在特定应用场景下能够替代上百个通用GPU,并在能效和成本上具备显著优势。
需要注意的是,截至2026年5月,Sohu芯片仍处于预生产阶段,仅向投资者进行了演示并拥有内部基准数据。上述性能声明尚未经过独立第三方的公开验证,产品也未进行大规模的商业发售和部署。该芯片的实际量产与应用验证预计需等待至2026年下半年。
3.技术局限性与潜在风险
Sohu采用的极致专用硬件路径伴随着明显的局限性。由于硬件设计完全绑定了Transformer架构,该芯片无法运行卷积神经网络(CNN)、循环神经网络(RNN、LSTM)等非Transformer架构的模型。此外,Sohu并不兼容主流的CUDA生态,需要依赖高度定制化的软件栈。从商业和技术发展角度来看,如果未来AI领域的主流模型架构发生重大演进并取代Transformer,这家高度依赖单一架构的公司及其专用芯片将面临较高的技术淘汰风险。
六、d-Matrix:基于存内计算架构的AI推理芯片
1.企业背景与市场定位
d-Matrix成立于2019年,总部位于美国加利福尼亚州,是一家专注于数据中心AI推理芯片的初创企业。2025年11月,公司完成了2.75亿美元的C轮融资,投资方包括微软M12和淡马锡等。为进一步强化数据中心的机架级部署能力,d-Matrix于2026年4月收购了GigaIO的数据中心业务。
在市场定位上,d-Matrix主要针对生成式AI(如大语言模型推理、智能体AI等)的低延迟需求。与侧重于通用计算和训练的传统GPU芯片不同,d-Matrix专注于解决AI推理场景中的“内存墙”瓶颈,提供独立于传统GPU和HBM的主流替代方案。
2.核心技术架构与三维堆叠探索
d-Matrix的底层核心技术为数字内存计算(Digital In-Memory Compute,简称DIMC)。在传统AI芯片中,乘累加运算需要将数据从内存搬运至计算单元;而DIMC技术通过将乘法运算逻辑直接嵌入SRAM内存单元中,减少了数据搬运带来的延迟与能耗。
在物理结构上,该方案采用小芯片(Chiplet)架构,基于台积电(TSMC)6纳米工艺制造。每个封装内包含4个小芯片,并通过基于OCP Bunch-of-Wires标准的自研DMX Link实现全互联。控制方面,芯片集成了SIMD向量单元与RISC-V控制核心,并支持MXINT4、MXINT8和MXINT16等块浮点数据格式。
此外,d-Matrix正在研发下一代3D堆叠数字内存计算技术(3DIMC)。公司于2025年11月宣布与Alchip合作,计划采用面朝面(Face-to-Face)工艺将DRAM直接垂直堆叠在逻辑芯片上。目前,该技术已在名为Pavehawk的测试硅片上完成了各项验证。
3.内存分层设计
为控制成本和功耗,避开极其紧缺的HBM,d-Matrix采用了“性能内存”与“容量内存”相结合的分层配置方案:
性能内存(Performance Memory):采用片上SRAM设计。单卡配置2GB至4GB容量,带宽达150TB/s至300TB/s(8卡服务器配置下可提供16GB容量与1200TB/s带宽)。该层主要用于驻留模型权重和KV Cache,以应对低延迟的交互式生成任务。
容量内存(Capacity Memory):采用板外LPDDR5内存。单卡最高支持256GB至512GB容量(服务器级最高可达2TB),带宽约为400GB/s。该层主要满足大模型离线批处理的容量需求。
4.主要产品线
Corsair平台:作为2024-2025年的主力产品,Corsair采用标准的PCIe Gen5 x16扩展卡形式,便于在现有数据中心服务器中部署。产品提供单卡与双卡配置,双卡版本的硅片面积为6400平方毫米,包含超过2500亿个晶体管。在算力方面,单卡MXINT8峰值算力约为2400TFLOPS,双卡配置下MXINT8峰值达4800TFLOPS,MXINT4可达19200TFLOPS。多卡系统可通过DMX Bridge(512GB/s)进行互连,并配有Aviator软件栈(兼容PyTorch与Triton等框架)及SquadRack机架参考架构。
Raptor平台:规划于2026年商用的下一代加速器产品。该平台将引入3DIMC技术并集成3D DRAM,旨在支持参数量更大的模型及更为复杂的智能体计算流。
5.性能表现与应用生态
根据d-Matrix官方公布的初步测试数据,在自然语言处理任务中:
运行Llama3-8B模型时,单台服务器的生成速度可达60000词元/秒(约1ms/词元)。
运行Llama3-70B模型时,基于64卡的单机架系统生成速度约为30000词元/秒(约2ms/词元)。
在生态合作方面,d-Matrix的硬件支持与现有GPU异构数据流水线混合部署。2026年3月,Gimlet Cloud成功集成了Corsair加速卡,通过推测解码技术在智能体AI(Agentic AI)工作负载的测试中实现了明显的加速效果。
七、Untether AI:近内存计算架构探索与融合
Untether AI是一家成立于2018年的加拿大初创公司(总部位于多伦多),主要针对人工智能(AI)推理场景开发专用加速芯片。在AI芯片行业探索降低功耗和提升计算密度的过程中,该公司的技术路线提供了与传统GPU不同的设计思路,其发展历程也反映了AI推理芯片市场的技术迭代与行业整合趋势。
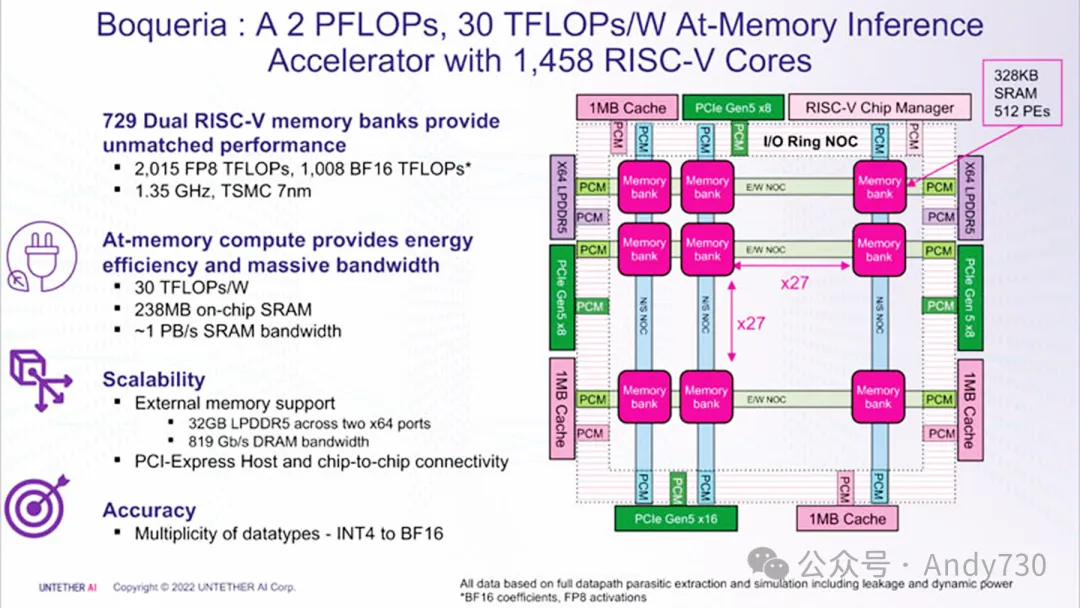
Untether AI Boqueria(speedAI架构)芯片结构。来源:ServeTheHome
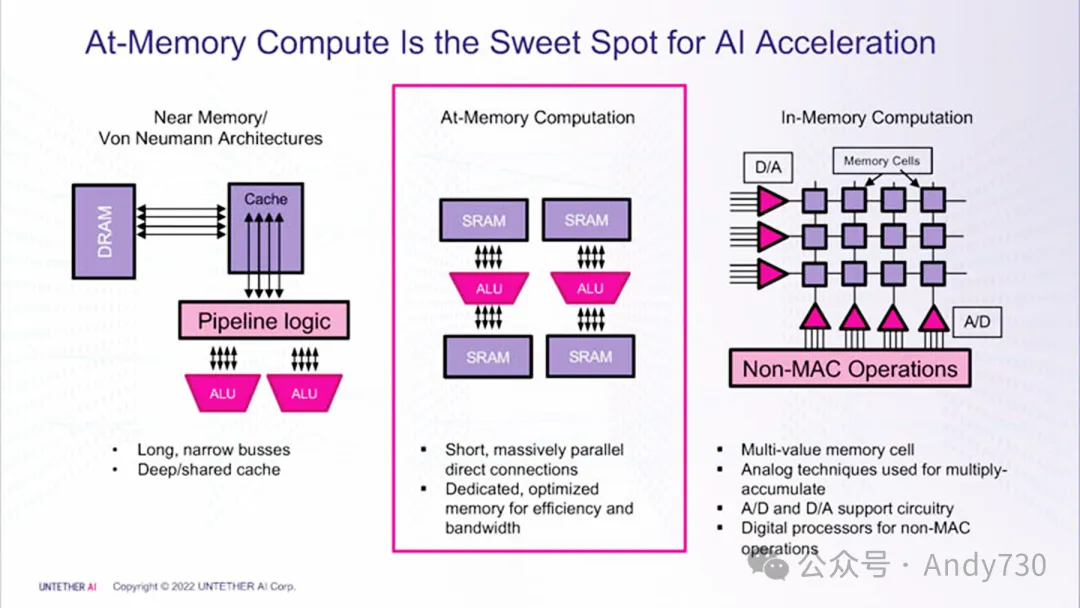
At-Memory Computing vs 传统Von Neumann和In-Memory架构。来源:ServeTheHome
1.核心技术路线:近内存计算(At-Memory Computing)
在传统的冯·诺依曼架构中,AI推理任务面临的主要瓶颈是数据搬运。据统计,在传统架构中约90%的能耗被用于将数据从动态随机存取存储器(DRAM)经过缓存移动到计算单元。针对这一痛点,不同厂商采取了不同的解决方案,例如通过高带宽内存(如HBM/HBM3e)提升数据传输速率,或是采用专用片上静态随机存取存储器(SRAM)架构。
Untether AI采用了近内存计算(At-Memory Computing)架构。其核心设计理念是将处理元件(Processing Elements,PE)直接嵌入并附加到片上SRAM存储库(Memory Banks)中,实现“计算紧贴数据”。这种分布式内存与计算紧耦合的物理硬件配置,使得数据可以通过极短的内部连线进行并行处理,从而在不高度依赖外部DRAM搬运数据的情况下,有效降低了系统的整体延迟和功耗。此外,该架构结合了定制的优化RISC-V内核与空间编译优化软件SDK(imAIgine),以适应固定的AI推理模型和高效的数据流水线调度。
2.产品演进与性能表现
在其独立运营期间,Untether AI主要推出了两代具有代表性的产品:
第一代产品(runAI200芯片与tsunAImi加速卡):推出于2020至2022年间,主要面向INT8精度的推理任务。单颗runAI200芯片配置了约200MB(204MB)的片上SRAM,划分为511个存储库,可提供502TOPS的算力,SRAM内部带宽达到260TB/s,典型热设计功耗(TDP)在50-75W之间。由四颗芯片组成的tsunAImi加速卡在ResNet-50图像识别任务(batch=1)中展现了约8万帧/秒的吞吐量。
第二代产品(speedAI240芯片,代号Boqueria):于2022年发布,并于2024年投入商用及基准测试。该代产品采用台积电(TSMC)7nm工艺制造,主频为1.35GHz。其物理配置大幅扩展,单芯片包含238MB专用SRAM and 729个双RISC-V存储库(总计1458个优化RISC-V核心)。在数据类型上,不仅支持INT8,还扩展至FP8和BF16,FP8下的峰值算力可达2PFLOPS。此外,该芯片还提供了PCIe Gen5接口和32GB LPDDR5外部内存支持,以应对更大模型或多芯片堆叠扩展的需求。
在2024年的MLPerf Inference 4.1基准测试中,speedAI240架构在边缘(Edge Closed)和数据中心(Datacenter Closed)场景的图像识别任务中提供了客观的数据参考。在边缘场景下,其单流延迟为0.12毫秒;与功耗约350W的传统GPU(如NVIDIA L40S)相比,功耗为150W的speedAI在延迟和吞吐量指标上呈现出一定优势,展现了该架构在功耗受限场景下的能效潜力。
3.目标应用场景与市场定位
由于其高计算密度和低功耗的特性,Untether AI的技术主要面向边缘视觉网络、数据中心固定模型推理以及自动驾驶等对吞吐率和能效比要求较高的应用领域。公司曾与汽车平台(如Arm)集成,并与梅赛德斯-奔驰在高级驾驶辅助系统(ADAS)领域展开合作。
在AI推理市场中,Untether AI的“海量SRAM+计算紧耦合”方案,与市场上其他主打超大SRAM的专用加速器(如Groq、Cerebras)、存内计算方案(如d-Matrix),以及采用HBM方案的通用GPU及中国厂商(如寒武纪、华为昇腾)形成了技术路线上的差异化竞争。其优势在于极高的能效(第二代产品标称达30TFLOPS/W) and 低延迟,但局限性在于针对特定推理负载的通用性不如传统GPU。
4.团队动向与行业整合
2025年,AI推理芯片市场加速整合。2025年6月,AMD宣布以“人才收购”(acqui-hire)的方式吸纳了Untether AI的全部工程团队。随后,Untether AI停止了独立运营,其原有的speedAI产品线及相关软件SDK停止供应和支持,并于同年10月正式申请破产。
目前,Untether AI的技术遗产已被整合进AMD的AI推理路线图中。原团队成员正在协助AMD进行AI编译器优化、内核开发以及SoC(系统级芯片)设计,以期进一步增强AMD产品在AI推理领域的能效竞争力。这一事件也侧面印证了芯片巨头对于低功耗推理技术及近内存架构理念的重视。
八、Axelera AI:数字内存内计算平台
1.企业背景与市场定位
Axelera AI是一家专注于边缘人工智能推理硬件与软件平台的初创公司,于2021年从比利时微电子研究中心(imec)孵化成立,总部位于荷兰埃因霍温(Eindhoven)。该公司的产品主要面向计算机视觉、机器人、无人机以及边缘大语言模型(LLM)和多模态AI推理等应用场景,旨在为工业、安防、零售等领域提供专用的AI推理硬件。
目前,Axelera AI的员工规模超过200人,并在欧洲多个国家设立了研发中心。2026年2月,该公司完成了约2.5亿美元(约2.1亿欧元)的融资;同年5月,公司与ServerDirect达成合作,共同推动欧洲本土的AI计算基础设施建设。
Axelera AI Metis AIPU架构。来源:Axelera AI
2.核心技术架构
Axelera AI芯片的核心技术是基于SRAM(静态随机存取存储器)的数字内存内计算(Digital In-Memory Computing,简称D-IMC)。
计算机制:在传统架构中,数据需要在处理器和独立存储单元之间反复搬运,而D-IMC技术使SRAM内存单元同时承担存储和计算功能,直接在内存中执行矩阵-向量乘法(MAC操作)。这种设计大幅减少了数据传输,从而降低了延迟和功耗。
精度与能效:该技术采用数字电路计算,避免了模拟计算可能产生的噪声问题。在INT8精度下,该架构能够实现与FP32等效的准确率(例如在无需重训的ResNet-50模型中实现99.9%的相对准确率)。其核心架构的整体标称能效可达15TOPS/W。
辅助架构与工艺:配合D-IMC核心,芯片内部集成了基于RISC-V架构的向量处理器(VPU),用于处理视频解码及传感器数据等非AI的预处理和后处理任务。芯片采用标准CMOS工艺(如12nm节点)制造,配备Voyager SDK软件栈,支持TensorFlow Lite、ONNX和PyTorch等主流框架的模型部署。
3.内存配置策略
为了配合内存内计算,Axelera AI的硬件高度依赖大容量的片上缓存。以其主力产品为例,单片芯片内置32MB或128MB的L2 SRAM,聚合带宽达200GB/s。在片外内存方面,芯片辅以特定容量的DRAM/LPDDR内存(从1GB到64GB不等),以平衡功耗与大参数模型/多路视频流的显存需求。
4.产品线规划与性能表现

Axelera AI Metis PCIe AI加速卡。来源:Axelera AI
根据目前的硬件发展,Axelera AI拥有两代主要量产/准量产架构及一款研发中产品:
Metis AIPU系列(第一代主力产品):该系列已实现大规模出货,主要针对边缘计算机视觉场景。单颗AIPU的峰值算力为214TOPS(INT8混合精度),典型功耗介于3.5W至9W之间。
o硬件形态:包括标准M.2扩展卡(配备 1GB DRAM)、PCIe加速卡(最高集成四核AIPU,算力达856TOPS),以及集成CPU的计算板。
o针对大模型的优化版本:2025年9月推出了Metis M.2 Max版本,将片外内存最高提升至16GB,使其能够在边缘端支持大语言模型(LLM/VLM)的推理吞吐。
o性能数据:在基准测试中,单颗芯片运行ResNet-50可达3200FPS;处理YOLOv5s模型时,可支持16路全高清视频流达到480FPS。
Europa AIPU系列(第二代产品):该系列于2025年10月发布,预计于2026年上半年出货,定位从重度边缘设备延伸至企业级服务器,侧重于生成式AI和多模态推理。
o硬件规格:单芯片算力提升至629TOPS(INT8),热设计功耗(TDP)约为45W。芯片内部集成了8个第二代D-IMC核心与16个RISC-V向量核,内置H.264/265解码器。
o内存扩展:配备128MB片上L2 SRAM和带宽为200GB/s的LPDDR5接口,单芯片最高支持64GB DRAM,多芯片级联可满足更大参数规模的生成式AI运行需求。
Titania芯片(研发阶段):这是一款针对高性能计算(HPC)和超大规模数据中心推理设计的Chiplet(芯粒)产品。目前,该项目已获得欧盟EuroHPC DARE计划6160万欧元的资金支持,具体性能指标尚未公布。
九、Tenstorrent:基于RISC-V架构的AI推理芯片及系统布局
Tenstorrent是一家由Jim Keller领导、总部位于美国(原注册于加拿大)的芯片企业,主要研发基于RISC-V架构的AI加速器。该公司的硬件设计主要针对AI推理场景进行优化(同时支持模型训练),其应用方向涵盖大语言模型(LLM)的预填充与解码任务、AI视频生成以及智能体工作负载。
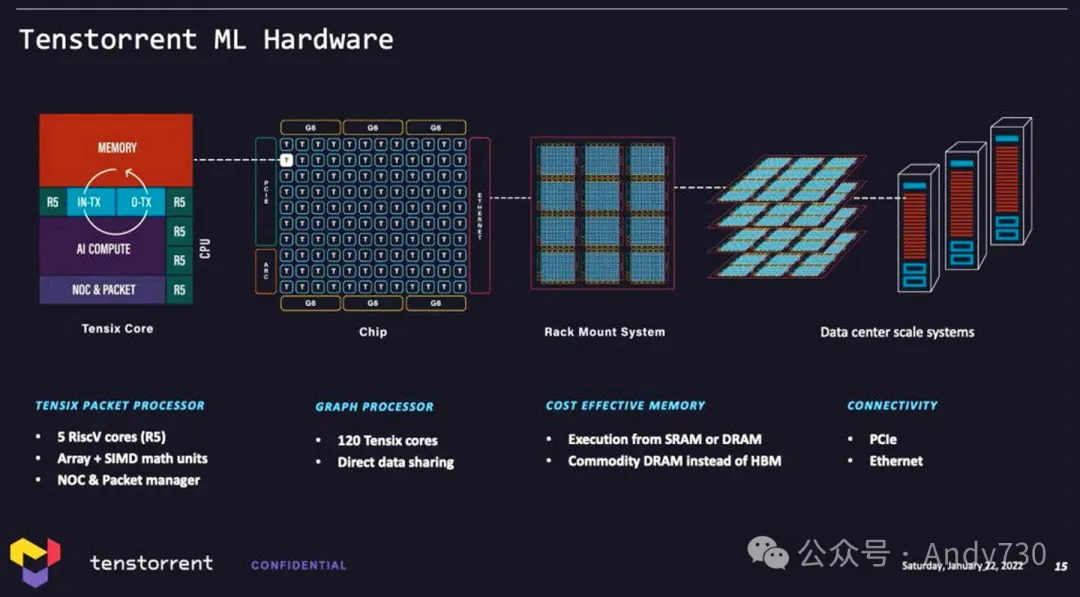
Tenstorrent Blackhole硬件扩展架构示意图。来源:SemiAnalysis
1.核心架构与技术路线
Tenstorrent的技术基础围绕Tensix核心与Networked AI(网络化AI)架构展开,并配套开源软件生态:
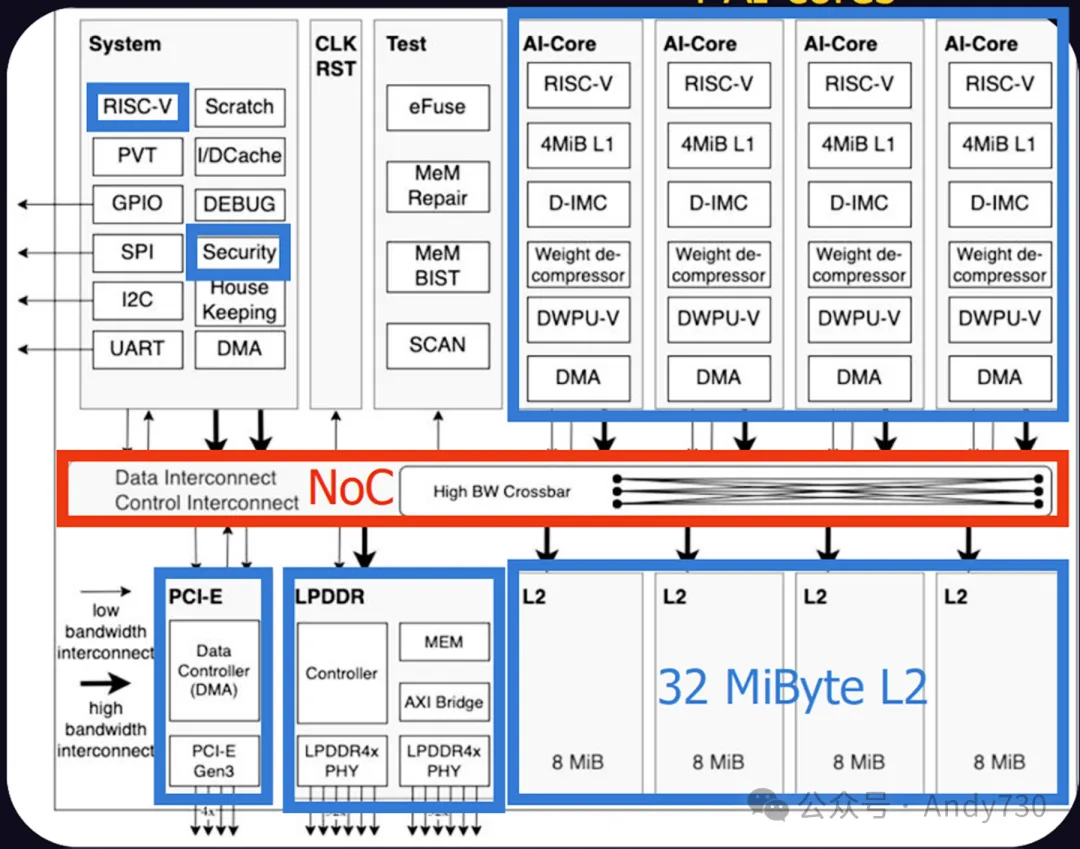
Tensix核心设计与片上RISC-V异构:其芯片底层采用Tensix数据流核心,每个核心内部集成了计算单元、矩阵单元(Matrix FPU)、向量单元(Vector SFPU)、1.5MB本地SRAM、用于控制数据移动的小型RISC-V核心以及片上网络(NoC)。在最新的Blackhole架构中,单芯片配备了120个Tensix核心以及16个可运行Linux操作系统的SiFive x280大型RISC-V核心。TrendForce的研究指出,随着智能体AI的崛起,推理系统需要高度频繁地进行串行条件判断和工具调度。Blackhole片上直接集成的高性能RISC-V核心正好充当了智能体工具流控制器的角色,从而极大减少了对外部主机CPU的依赖。该架构采用显式数据流执行模型,支持Block FP8、FP16及BF16等多种计算精度。
Networked AI架构:在硬件互连方面,Tenstorrent采用标准以太网(如800G QSFP-DD)进行直接Scale-Out扩展,而非使用专有互连技术。这种设计将计算、内存和网络统一为单一的互连网络,支持预填充和解码任务在同一硬件设备上运行,单芯片到多服务器集群均采用统一的编程模型。
软件生态:公司提供全开源的软件栈,包括TT-Metalium(低阶内核)、TT-Forge(编译器)和TT-Lang等,支持PyTorch与Hugging Face框架,兼容超过90%的Hugging Face模型。
2.内存配置策略
在物理硬件配置上,Tenstorrent采用了高容量SRAM结合GDDR6及以太网扩展的混合内存层次结构,作为昂贵且供应受限的HBM方案的替代选项:
片上SRAM:单颗Blackhole芯片配备180MB片上SRAM,推理时系统优先将活跃模型或KV Cache置于SRAM中运行,以控制数据访问延迟。在32芯片的Galaxy服务器级别,SRAM总容量达6.2GB,聚合带宽为2.9PB/s。
片外DRAM:采用成本相对更低、基于6nm工艺制造的GDDR6内存。单颗Blackhole芯片外接28GB至32GB的GDDR6,单卡带宽介于448至512GB/s之间;Galaxy服务器的总DRAM容量为1TB,聚合带宽达16TB/s。
网络池化:通过系统的标准以太网接口(Galaxy服务器最高提供56个800G端口,扩展带宽11.2TB/s),实现跨节点的内存共享与数据调度,适配长上下文模型的推理需求。
3.主要产品线与规格
Tenstorrent的产品线覆盖了从开发板、工作站到数据中心服务器的多个层级,截至2026年的主要产品状态如下:
早期产品(Grayskull与Wormhole):Grayskull为12nm工艺的早期基础开发板,正逐步被替代。第二代Wormhole系列包含n150(单处理器)、n300(双处理器,24GB GDDR6)以及TT-LoudBox液冷工作站(支持四卡,可本地运行120B参数模型),主要面向开发者与小型服务器测试。
第三代主力产品(Blackhole PCIe加速卡):2026年的主打芯片,单芯片计算能力峰值达664TFLOPS(BlockFP8),TDP约为300W。其PCIe产品包括p100a(配备28GB GDDR6,起售价999美元)以及p150a/p150b系列(配备32GB GDDR6)。其中,p150系列卡身带有4个800G以太网端口,支持多卡直连扩展。
Galaxy Blackhole数据中心服务器:于2026年4月正式发布(GA)的6U风冷服务器,单台设备集成32颗Blackhole芯片,提供23PFLOPS的计算能力(Block FP8)。单台服务器起售价约为11万美元;由4台服务器组成的超级集群起售价为44万美元,并支持扩展至36个机架及以上规模。
4.应用表现与基准测试(2026年数据)
根据公开的测试信息,Tenstorrent产品在长上下文、批量推理和实时生成任务中呈现出特定的运行特征:
大语言模型推理:在运行DeepSeek-R1-0528 671B模型时,基于128k上下文及8-64批次的设定,其解码速度达到350+词元/秒/用户;在100k上下文条件下,首个词元生成时间(TTFT)在4秒以内。
多模态与视频生成:在结合网络扩展的超级集群环境下,生成一段720p分辨率、共81帧的视频,耗时为2.4秒,该耗时数据相较于部分主流GPU系统有较明显的缩短。
商业应用情况:其设备支持MoE架构模型(如Qwen、DeepSeek等),在TTS(文本转语音)等特定任务的部署成本低于NVIDIA L40S等部分常规选项。目前,相关硬件产品已实现量产交付,并在Cirrascale云平台上线,私有化部署案例包括Virtu Financial、ai&等企业。
十、SambaNova:聚焦可重构数据流与三级内存的AI推理方案
SambaNova Systems是一家位于美国硅谷的AI芯片公司,其业务主要聚焦于AI推理领域,特别是针对智能体AI(Agentic AI)场景的底层硬件优化。在AI推理芯片市场中,有别于以NVIDIA为代表的GPU架构、以Groq为代表的超大SRAM架构以及Cerebras的晶圆级芯片,SambaNova的技术路线主要围绕“可重构数据流架构(RDA)”与“三层耦合内存配置”展开。
SambaNova SN40L vs SN50三级内存规格对比
SambaNova RDU数据流架构。来源:SambaNova
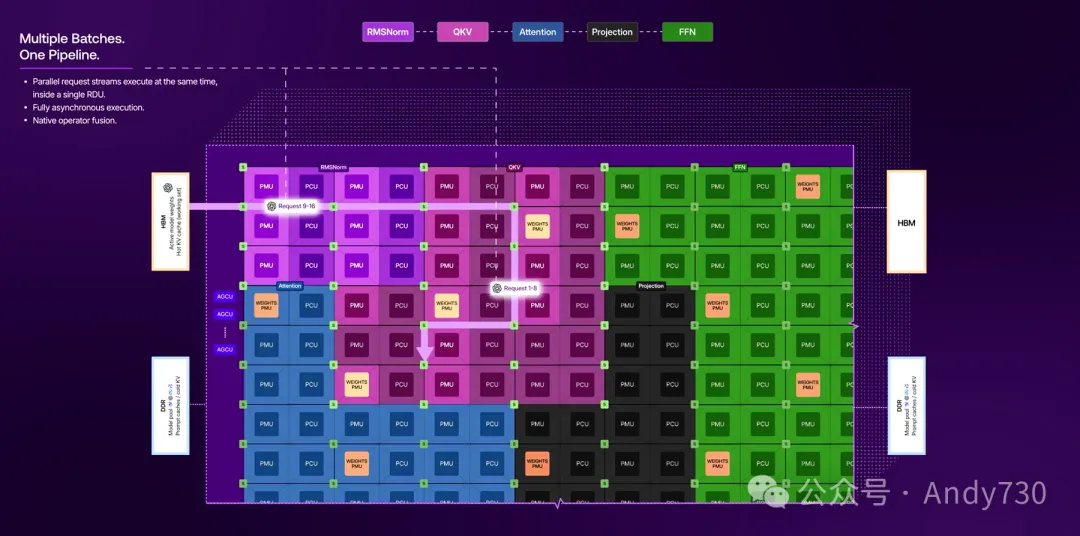
1.核心技术:可重构数据流架构(RDA)
SambaNova的核心处理器被称为可重构数据流单元(Reconfigurable Dataflow Unit,简称RDU)。该架构的物理基础是由模式计算单元(PCU)和模式内存单元(PMU)组成的网格,各单元之间通过可编程的开关网络进行连接。
在软件层面,其专有的SambaFlow编译器负责将整个神经网络的计算图静态映射 to 硬件上,形成空间与时间上的执行数据流水线。这种设计的核心在于实现操作融合(operator fusion)和数据的就地计算,从而减少传统GPU执行中常见的逐内核(kernel-by-kernel)调用,降低数据在内存间的往返移动开销。在实际应用中,该架构主要针对推理的Decode阶段进行设计,并支持智能体AI应用中常见的多模型切换、工具调用和长上下文处理。
2.内存配置:三层紧密耦合架构与异构CPU协作
在物理内存设计上,SambaNova采用了一种三层内存架构,旨在平衡系统的存储容量、访问带宽与数据延迟,以缓解AI推理中的“内存墙”现象。这三层内存分别包括:
片上SRAM:每颗芯片配备约432MB至520MB的分布式SRAM,作为可编程存储暂存器,提供数百TB/s的聚合带宽,主要用于处理热点数据、中间结果及融合内核的极速计算。
高带宽内存(HBM):每颗芯片搭载64GB的HBM(采用HBM2E或HBM3),带宽约为1.8至2TB/s,负责存放当前活跃运行的模型权重、混合专家模型(MoE)的专家层数据和KV Cache。
大容量DDR内存:每颗芯片支持256GB至2TB的DDR(支持DDR5)内存配置。在16颗芯片组建的单节点系统中,DDR总容量可达12TB以上。该层主要用于存储完整的超大规模模型(达百万亿参数级)、大量的模型检查点及提示词缓存,使得数百个多模型能够驻留在内存中,并实现微秒至毫秒级的模型热切换。
3.主要产品迭代与系统部署
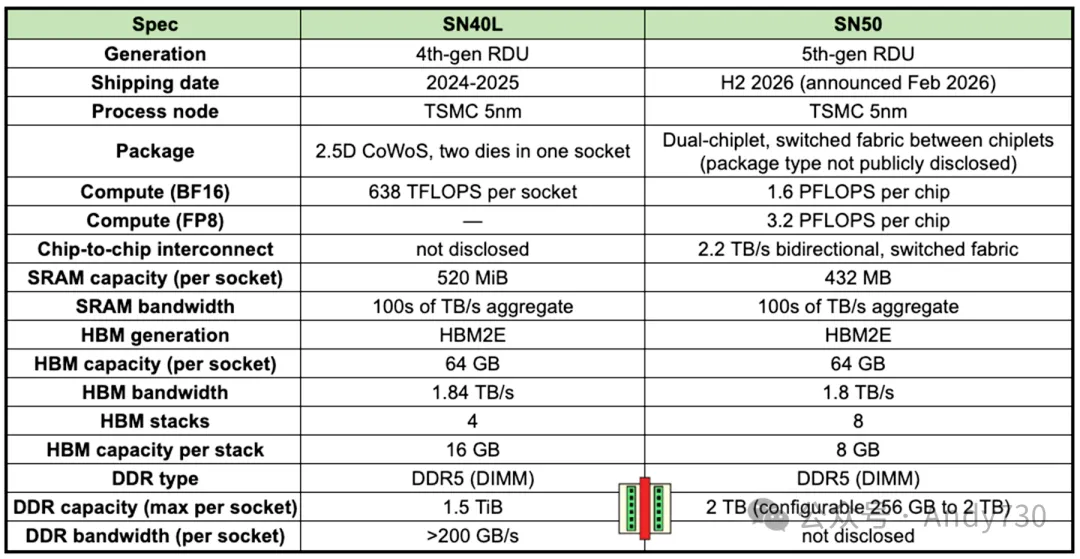
SambaNova目前的商用和即将交付的主力产品为第四代与第五代RDU芯片:
SN40L(第四代):于2024年发布并已投入商用,采用台积电5nm工艺和双die CoWoS封装。该芯片包含1040个RDU核心,单芯片峰值算力标称为638BF16 TFLOPS。
SN50(第五代):于2026年2月发布,计划于同年下半年出货。该芯片采用双Chiplet封装,官方数据显示,其计算性能为SN40L的5倍,网络带宽提升4倍,主要定位于新一代的智能体AI推理任务。
在系统硬件层面,SambaNova提供基于空气冷却的SambaRack机架方案。以搭载SN50的机架为例,系统平均功耗约为20kW至30kW,通过集群配置,单机架可直接运行DeepSeek R1 671B和Llama 4等大规模模型,规避了跨机架的模型切片(sharding)需求。
4.性能表现与近期市场动态
在性能指标方面,根据第三方(如Artificial Analysis)的基准测试,SN40L在处理DeepSeek等模型的高并发测试中展现了稳定的吞吐量表现。针对智能体AI和多模型MoE场景,SambaNova官方信息显示,相较于同期的GPU产品(如H100、B200等),SN50在模型切换速度、输出吞吐量以及每瓦词元数(tokens/watt)上具有更高的效率,整体拥有成本(TCO)更低。
在市场和企业动态方面:
融资与部署:SambaNova于2026年2月宣布完成3.5亿美元的E轮融资,其设备已被软银(SoftBank)及澳大利亚、欧洲和英国等地的主权AI项目采购部署。
异构生态合作:根据TrendForce针对异构系统协作的最新报道,2026年4月,SambaNova与Intel联合发布了一项异构推理系统蓝图。该方案采用“分工协作”模式:利用GPU处理Prefill阶段,SambaNova RDU负责Decode阶段,并由Intel Xeon 6 CPU负责智能体工具的编排与协调。这一蓝图深刻印证了智能体AI时代主机CPU在硬件流水线中承担逻辑与工具编排核心任务的全新定位。
十一、MatX:聚焦大语言模型专属加速的MatX One芯片
1.企业背景与发展规划
MatX是一家成立于2022年的美国初创公司,由前Google TPU与Brain团队工程师Reiner Pope和Mike Gunter创立,专注于为大语言模型(LLM)研发专用的高吞吐量芯片。2026年2月,MatX宣布完成5亿美元的B轮融资,投资方包括Jane Street、Situational Awareness等机构,以及部分科技界人士和供应链企业(如Alchip和Marvell)。此轮融资主要用于产品开发与规模化制造,公司计划于2026年内通过中国台湾的台积电(TSMC)启动流片(tape-out),并预计在2027年实现量产出货。
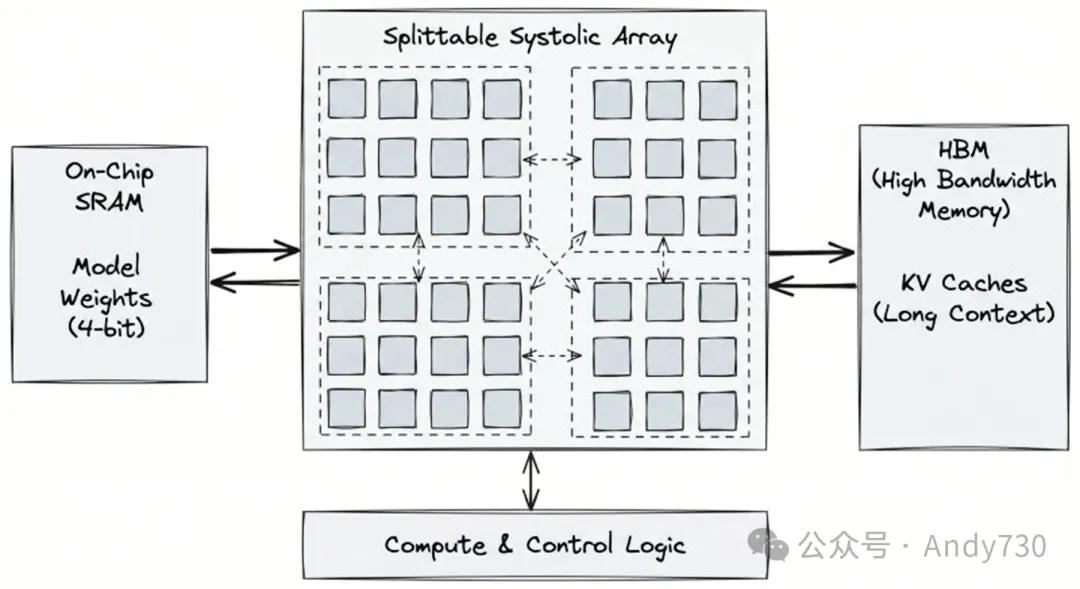
MatX One可分割脉动阵列架构
2.产品定位
MatX的首款产品为MatX One,这是一款集成了训练与推理功能的芯片,在设计上主要侧重于推理阶段的高吞吐和低延迟场景。与通用GPU不同,MatX One剥离了针对小型模型、卷积神经网络(CNN)或推荐系统等非大模型场景的支持,专攻100层以上的大型混合专家(MoE)模型与稠密模型。此外,该产品在设计上支持集群扩展,可组网至数十万个芯片的规模。
3.核心架构技术
在硬件架构方面,MatX One采用了“可拆分脉动阵列”(Splittable Systolic Array)设计。这种架构旨在兼顾大型脉动阵列的能效优势,并在处理大模型(如MoE模型的注意力层或Decode阶段的“skinny batch”)中较小、形状灵活的矩阵时,保持较高的计算利用率。芯片采用了新的数值计算方案,其编程模型兼容PyTorch,并允许对底层硬件进行直接控制,去除了通用GPU中针对非Transformer架构的冗余部分。
4.混合内存设计
为应对大模型推理中的数据读取瓶颈,MatX One在物理硬件配置上采用了SRAM(片上静态随机存取存储器)与HBM(高带宽内存)相结合的混合内存架构。根据官方的设计逻辑,模型权重(主要采用4-bit量化)被放置在SRAM中以实现低延迟访问;而KV Cache则存放在HBM中,以利用其大容量特性来支持超长上下文。这种分离机制旨在避免HBM带宽被权重加载占用,从而改善Decode阶段的内存限制问题。
5.性能预期
根据MatX公布的内部测试与模拟数据,在运行100层的大型MoE模型时,MatX One的输出速度可达2000词元/秒。在Prefill阶段和训练场景下,该芯片侧重于提供高计算密度(FLOPS/mm²);而在Decode和强化学习(RL)场景下,则通过内存与架构优化试图在低延迟、高计算量与长上下文支持之间取得平衡。由于MatX One目前仍处于预量产阶段,其实际性能表现与最终参数仍需等待流片完成后的硅验证。
十二、Hepzibah AI:存内计算IP核
Hepzibah AI是一家位于多伦多的初创企业,主要定位为人工智能计算领域的IP授权商。其核心团队包括首席执行官Martin Snelgrove、Raymond Chik、David Lynch和Taneem Ahmed,部分成员此前曾参与创立Untether AI。该公司于2025年获得Two Small Fish Ventures的投资,加入了加拿大半导体理事会(CSC),并先后参加了2025年在中国台湾举办的SEMICON Taiwan展会以及2026年的COMPUTEX展会。
1.产品模式与应用
Hepzibah AI主要向SoC(系统级芯片)设计厂商提供模块化的AI计算IP核,而非直接生产和销售完整芯片。其IP核采用了可扩展设计,客户可根据性能需求进行配置:最小配置可为单个Tile,适用于传感器、无人机和手机等边缘设备中的简单任务;在需要高吞吐量的数据中心或工业系统中,可通过自定义的片上网络(NoC)和Chiplet技术将规模扩展至单个芯片包含数千个Tile。
在商业交付上,该公司早期主要提供定制化的IP集成服务,后续计划推出标准化的IP库以简化部署。为了方便客户在实际集成前评估和验证应用代码,公司计划于2026年第四季度上线硬件仿真平台。
2.技术架构特征
针对AI推理过程中因数据搬运产生的能耗问题,Hepzibah AI采用了以内存为中心(At-Memory Compute)的Tile模块化架构。其主要技术特征如下:
片上SRAM布局:每个Tile内部集成了自定义的低功耗SRAM块,使数据处理能够在内存附近直接完成,降低了对外部存储的依赖以及跨区域的数据移动能耗。该架构也可在成本较低的成熟工艺节点上实现。
专用转置单元(Transpose Unit):硬件中加入了专门处理矩阵转置操作的单元,旨在减少AI计算中因该类操作引发的反复读写过程。
软件优先(Software-First)设计:硬件针对轻量级程序的运行进行了针对性优化,以保持芯片结构的精简。
除主要用于推理外,该架构内置的片上网络也支持模型蒸馏等轻量级的训练任务。
3.性能表现评估
Hepzibah AI的研发重点在于优化AI硬件的性能功耗比(Performance-per-Watt),以适应功耗敏感的边缘及本地部署场景。目前,由于公司产品仍处于IP预商用阶段,尚未公布诸如MLPerf等公开的行业基准测试数据。但根据该公司公开的内部建模信息显示,在处理雷达和信号处理等数据密集型工作负载时,该架构在能效上优于传统的GPU,同时在可编程性上具备比固定功能ASIC更高的灵活性。
十三、Positron AI推理芯片与系统架构
1.企业背景与技术路线
Positron AI成立于2023年,是一家专注于Transformer模型AI推理加速器的硬件初创企业。2026年2月,该公司完成了2.3亿美元的B轮融资。在供应链方面,其硬件产品的制造环节主要在美国本土进行,其中首代加速器由英特尔(Intel)代工。
针对大语言模型(LLM)在推理场景下因KV Cache、超长上下文及大参数量引发的内存带宽瓶颈,Positron AI提出了“内存优先”(Memory-First)的架构设计。该架构专为Transformer推理从零设计,通过平衡矩阵与向量运算,优化注意力机制及KV Cache的管理。在软件生态层面,其硬件支持Hugging Face模型的直接映射(无需重写代码),同时兼容OpenAI API接口。
2.存储设计特点与商业内存突围
在内存硬件的选择上,Positron AI未采用行业内广泛使用的HBM(高带宽内存)方案,而是转向商品化的LPDDR5x内存。通过Credo Weaver芯片粒(Chiplet)和CXL扩展技术,该方案在提升单芯片内存容量的同时,有效控制了硬件成本与功耗,并避开了2026年极其严峻的HBM供应链限制。根据公开数据,其架构设计可使系统内存带宽利用率(MBU)达到90%以上,大幅优于传统GPU,成为云端与本地异构部署高性价比的通用选择。
3.产品线规划及硬件规格
根据公布的产品路线图,Positron AI的产品涵盖了从加速服务器到定制芯片及大型系统的不同层级:
Atlas推理服务器:作为目前的在售主力产品(自2025年起出货),Atlas单机配备8个Archer加速器(作为过渡期的FPGA加速器),系统总加速器内存为256GB。其整机功耗约2000W,采用常规风冷散热,支持最高5000亿参数模型的推理。
Asimov芯片:定位为定制化ASIC加速器,预计于2026年底流片(Tape-out),2027年量产。该芯片采用512×128脉动阵列(Systolic Array)及本地权重内存设计以最小化数据搬运。其单芯片提供864GB至2.3TB的LPDDR5x内存容量,内存带宽为2.76TB/s,热设计功耗(TDP)约为400W,同样支持风冷部署。
Titan系统:计划于2027年发布,针对长上下文与超大规模参数模型设计。单台Titan系统由4颗Asimov芯片构成,配备8TB以上的加速器内存及3TB以上的主机内存。系统总带宽达11.8TB/s,外部芯片间带宽为32Tbit/s,整机功耗约4.5kW(风冷)。该系统支持最高16万亿参数模型及千万级词元的上下文窗口,并可横向扩展至最高4096个节点的系统集群。
4.性能表现与商业落地
在基准测试表现上,Atlas服务器在运行Llama 3.1 8B模型(BF16精度,无推测或分页注意力设置)时,单用户推理速度为280词元/秒。在系统能耗方面,Atlas单台系统的功耗(2000W)约为NVIDIA DGX H200(5900W)的三分之一。
在实际部署方面,Atlas目前已进入商业数据中心落地阶段,甲骨文(Oracle)已在生产环境中对其进行了规模化部署。此外,Cloudflare、Jump Trading等企业也是其现有的部署客户。
十四、FuriosaAI:AI推理芯片与架构演进
1.企业背景与市场定位
FuriosaAI是一家成立于2017年的韩国初创公司,总部位于首尔。该公司的创始人白俊浩(June Paik)曾是三星和AMD的工程师。与主导通用计算市场的NVIDIA等厂商不同,FuriosaAI专注于开发专用的AI推理(Inference)芯片。其产品的核心设计目标是针对数据中心、云计算和边缘计算场景,优化计算机视觉、大型语言模型(LLM)及多模态模型的推理过程,以期降低能耗和总拥有成本(TCO)。
2.核心技术与内存架构设计
在硬件架构层面,传统GPU通常以矩阵乘法(matmul)为核心算子,而FuriosaAI采用了一种名为张量收缩处理器(Tensor Contraction Processor,TCP)的专用架构。根据其在ISCA 2024学术会议上发表的论文,张量收缩是矩阵乘法的高维泛化,能够更直接地映射Transformer和LLM等深度学习模型的计算过程。该设计的目的是提高数据重用率和计算利用率,同时通过配套的全栈编译器(Furiosa SDK)自动优化张量映射并支持稀疏与动态形状,从而减少数据移动产生的能耗。
在内存物理配置上,FuriosaAI采取了优先满足内存带宽的硬件策略,以应对大模型推理场景中常见的内存带宽受限问题(如KV Cache和批处理计算)。其产品结合了高带宽内存(HBM)与大容量片上SRAM,通过本地化计算最大化每瓦词元数(tokens/watt),从而减少对片外DRAM的访问频率。
3.产品线演进
自成立以来,FuriosaAI规划并推出了三代不同定位的产品:
第一代Warboy(视觉专用NPU):于2021年起提供,定位为计算机视觉推理芯片,主要针对智能城市、视频分析等场景。该芯片采用三星14nm工艺制造,运行频率2.0GHz,峰值算力为64TOPS(INT8)。其配备16GB LPDDR4X系统内存(带宽66GB/s)和32MB片上SRAM,热设计功耗(TDP)约为40至60瓦。在MLPerf Inference基准测试中,该芯片在特定的图像分类和目标检测任务上优于部分同类GPU,目前已在韩国企业(如Kakao)的实际生产环境中商用部署。
第二代RNGD(数据中心推理加速器):在2024年Hot Chips会议上发布,定位为主攻LLM和多模态模型的高并发推理。RNGD采用台积电(TSMC)5nm工艺制造,集成约400亿个晶体管。在计算性能上,其FP8算力为512TFLOPS,INT4算力为1024TOPS。内存方面,单芯片集成了两颗HBM3(采用CoWoS-S 2.5D封装),总容量48GB,内存带宽达1.5TB/s;同时配备256MB片上SRAM。形态上为PCIe Gen5 x16双槽全高卡,TDP设定为180瓦(部分信息披露为150瓦),支持空气冷却。基于该芯片构建的NXT RNGD服务器(包含8张加速卡和双AMD EPYC处理器)可提供384GB HBM3内存、12TB/s总带宽及4PetaFLOPS的FP8算力,系统总功耗约3千瓦。截至2026年1月,该芯片已完成首批约4000片的量产交付。
第三代(规划中):2026年5月,FuriosaAI宣布与博通(Broadcom)达成价值约1.327亿美元的战略合作,共同开发第三代多Die(Chiplet)平台。该平台计划采用2nm计算晶片和专用IO晶片,集成博通的以太网网络(Ethernet fabric)技术和HBM4/4E内存,面向超大规模智能体AI(Agentic AI)推理场景,目标于2028年上半年提供样品。
4.性能测试与商业进展
在基准测试方面,根据韩国LG AI Research的验证结果,单台配备4张RNGD卡的服务器在运行EXAONE 3.5 32B模型时,4K上下文长度下吞吐量可达60词元/秒。在同等功耗条件下,其并发用户支持数量达到英伟达RTX Pro 6000的7.4倍,每瓦性能(perf/watt)约为传统GPU的2.25倍。在Llama 3.1 70B模型测试中,8卡配置的吞吐量可达957词元/秒。测试数据显示,其标准气冷机架部署可将数据中心总体拥有成本(TCO)降低约40%。
在商业与资本层面,RNGD量产后已向LG AI Research、Samsung SDS、OpenAI等企业提供测试和部署。据公开信息披露,FuriosaAI在拒绝Meta的收购提议后,当前估值接近7亿美元,并计划进行规模约3亿至5亿美元的D轮融资,同时规划于2027年实现首次公开募股(IPO)。
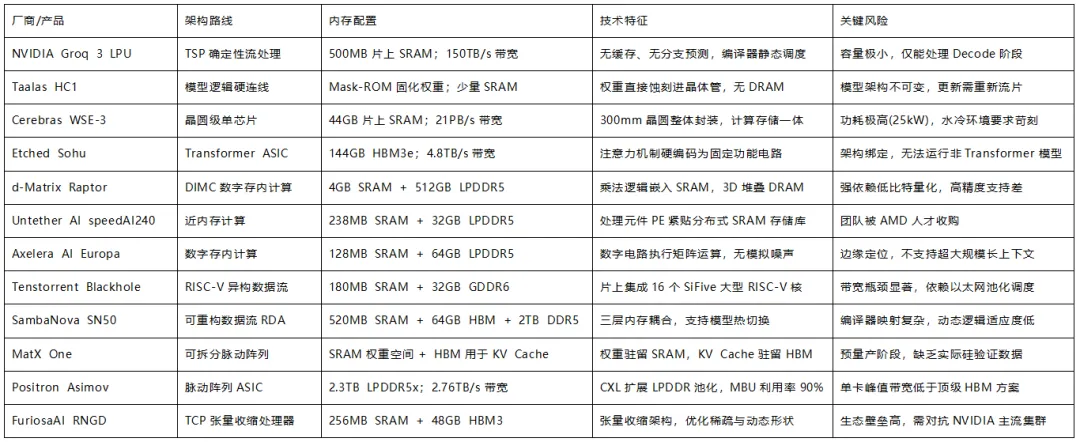
AI推理芯片核心参数对比表
免责声明:文章来源Andy730,转载仅供读者参考。
关注我们获取更多精彩内容
往期回顾

