 夜雨聆风
夜雨聆风最近我在看 Anthropic 官方的 claude-code-setup 插件。
一开始我以为它只是一个“Claude Code 配置推荐器”:扫一下项目,然后告诉你应该装哪些 MCP、skills、hooks、subagents。看完它的 README、核心 claude-automation-recommender skill,以及几份 reference 之后,我觉得它真正有意思的地方不在“推荐了什么”,而在“它为什么这样推荐”。
它背后的思想其实很清楚:
不要先问 Claude Code 有什么能力,而要先看这个项目暴露出了什么自动化需求。
很多人配置 Agent 工具时,很容易进入“能力收藏夹”模式。听说 context7 很好,就装一个;听说 Playwright MCP 很强,也装一个;看到别人写了十几个 subagent,就也想给自己项目配一套。最后工具越来越多,但 Agent 真正做事时未必更稳定。
claude-code-setup 走的是另一条路。它先读项目结构、依赖、测试、CI、数据库、前端框架、安全敏感代码,再把这些信号映射到 Claude Code 的五类扩展能力:MCP Server、Skill、Hook、Subagent、Plugin。
换句话说,它不是从“我能装什么”出发,而是从“这个项目需要什么”出发。
读完这篇文章,你至少能带走三个东西:为什么 Claude Code 配置不能靠“插件收藏夹”;MCP、Skill、Hook、Subagent、Plugin 这五层能力到底各管什么;以及如果自己实现一个 setup 推荐器,应该如何从项目事实推导自动化配置。
它到底在做什么
官方对 claude-code-setup 的描述很直接:分析 codebase,然后推荐适合这个项目的 Claude Code automations,包括 hooks、skills、MCP servers、subagents 等。
它的核心 skill 叫 claude-automation-recommender。这个 skill 本身是只读的,不修改文件,只分析项目并输出建议。它的流程可以简化成三步:
1. Codebase Analysis
读取项目结构、依赖、测试、CI、文档和已有 Claude 配置。
2. Generate Recommendations
根据项目信号推荐 MCP、Skills、Hooks、Subagents、Plugins。
3. Output Report
每类只推荐 1-2 个最高价值选项,不把用户淹没。这里最值得注意的是第三点:它不追求推荐得多,而是推荐得准。
Agent 工程里有一个很常见的问题:一旦你知道有 MCP、hooks、skills、subagents,就会忍不住把所有东西都塞进去。但配置项越多,系统未必越强,反而可能变得更难预测。MCP 太多会增加工具选择噪声,hook 太多会拖慢反馈,skill 太多会降低触发精度,subagent 太多会制造审查疲劳。
所以 claude-code-setup 的克制很重要。它默认每一类只给 1-2 个最高价值建议,本质上是在做“自动化优先级排序”,而不是工具清单生成。
五类能力:从外部事实到团队分发
第一层:MCP 不是插件,是外部事实入口
在它的推荐体系里,MCP Server 对应的是“Claude 缺少外部上下文或外部操作能力”的场景。
比如项目用了 React、Vue、Next.js、Express、FastAPI、Prisma、Stripe、OpenAI SDK,它会倾向推荐 context7 这类实时文档工具。因为这类项目最怕模型凭训练记忆写过时 API。文档 MCP 的价值不是“多一个搜索功能”,而是把模型从静态记忆拉回当前事实。
如果项目是前端应用,它会推荐 Playwright MCP。因为前端质量不能只靠读代码判断,必须打开页面、点击按钮、截屏、看 console。浏览器 MCP 的价值是让 Agent 接触真实 UI 反馈。
如果项目使用 Supabase、Convex、Postgres、GitHub、Linear、Sentry、Docker,它也会分别推荐对应 MCP。这里的逻辑不是“这个 MCP 很热门”,而是:
项目里已经存在某类外部系统
↓
Agent 需要和这个系统交互或读取事实
↓
推荐对应 MCP所以 MCP 的本质不是“扩展插件”,而是 外部事实入口。
一个没有 MCP 的 Agent,很多时候只能靠代码和上下文猜测;一个接入合适 MCP 的 Agent,才有机会看见真实数据库、真实浏览器、真实 issue、真实错误日志。
第二层:Skill 是可复用的工作方法
Skills 对应的是另一类问题:团队有很多重复任务,但这些任务仍然靠人临时描述。
比如生成 API 文档、创建数据库迁移、生成测试、创建新组件、写 release notes、做 PR checklist。这些事情并不是一次性问题,而是会反复出现的工程动作。
如果每次都写 prompt:
请参考项目风格,为这个接口生成 OpenAPI 文档。
请创建一个数据库迁移,记得有 up/down。
请按照现有测试风格给这个文件补测试。那团队的经验仍然停留在人的口头提醒里。Skill 的作用,就是把这些提醒变成可调用的流程。
claude-code-setup 的 reference 里给了不少 custom skill 的例子:api-doc、create-migration、gen-test、new-component、pr-check、release-notes、setup-dev。这些例子背后有一个共同点:Skill 不是简单提示词,而是可以带模板、脚本、示例和验证步骤的“工作包”。
一个好的 Skill 至少应该回答四个问题:
什么时候触发?
按什么步骤做?
参考哪些模板或示例?
做完后怎么验证?这和普通 prompt 的差别很大。
Prompt 更像一次性沟通,Skill 更像团队流程资产。Prompt 告诉 Agent “这次怎么做”,Skill 告诉 Agent “以后遇到这类任务都怎么做”。
第三层:Hook 把规范塞进执行链路
Hooks 解决的是“规则写了,但执行不稳定”的问题。
项目有 Prettier,但 Agent 改完代码不一定会格式化;项目有 ESLint,但 Agent 不一定会主动跑 lint;项目有 .env,但 Agent 可能误改敏感文件;项目有 lock file,但 Agent 可能直接编辑锁文件。
这些问题如果只靠文档提醒,效果很有限。因为文档是被动的,Agent 不一定每次都想起。Hook 的价值在于把规则挂到事件上。
比如:
PostToolUse: Edit/Write 后自动格式化
PostToolUse: Edit/Write 后运行 lint 或 type-check
PreToolUse: 阻止编辑 .env、credentials、lock files
PostToolUse: 修改测试相关文件后运行相关测试这其实是 Agent 工程里很关键的一层:把“应该做”变成“必然发生”。
传统团队会靠 CI、pre-commit、lint-staged、review checklist 来守住工程质量。Agent 参与编码以后,这些机制仍然需要,只是触发点变了。Hook 就是在 Claude Code 的工具事件上重建这套约束。
如果说 Skill 是团队经验,Hook 就是团队纪律。
Skill 告诉 Agent “遇到这类任务可以这样做”,Hook 告诉 Agent “做完某类动作必须经过这道门”。
第四层:Subagent 是专业判断的并行化
Subagent 的价值,不是“多叫几个模型来热闹一下”,而是把不同性质的判断拆开。
主 Agent 在做一个功能时,已经要理解需求、读代码、修改文件、跑测试、解释结果。让它同时深度审安全、审性能、审 UI 可访问性、补测试、写文档,很容易变浅。
claude-code-setup 会根据代码信号推荐不同 subagent:
大型代码库 -> code-reviewer
认证 / 支付 / 用户数据 -> security-reviewer
API 项目 -> api-documenter
数据库和热点路径 -> performance-analyzer
前端组件多 -> ui-reviewer
测试覆盖不足 -> test-writer这背后的判断是:不同问题需要不同视角。
安全审查要看权限边界、输入校验、密钥泄漏、数据暴露。性能分析要看 N+1 查询、复杂度、缓存、内存占用。UI 审查要看可访问性、响应式、交互反馈和视觉层级。测试生成要理解现有测试风格和边界条件。
这些不是同一种思维负载。把它们拆成 subagent,等于把主 Agent 的“单线程判断”变成“多角色并行审查”。
这也是 Agent 工程和普通 Chatbot 的重要区别:普通 Chatbot 追求一个回答,Agent 系统追求一组可协作的角色。
第五层:Plugin 是团队级分发单元
Plugin 解决的是“如何把一组能力交给整个团队”的问题。
一个 skill 可以沉淀一个任务,一组 hooks 可以固化一批规则,一个 subagent 可以负责某类审查,一个 MCP 可以连接外部系统。但如果团队每个人都手动配置,这套能力就很难一致。
Plugin 把这些东西打包起来:
plugin/
├── .claude-plugin/plugin.json
├── skills/
├── agents/
├── hooks/
├── commands/
└── .mcp.json这意味着 Claude Code 的插件不是传统意义上的“安装一个功能按钮”,而更像一套团队工作方式的分发包。
比如一个前端团队可以有自己的 frontend plugin:包含 UI review agent、component generator skill、Playwright 验收命令、自动格式化 hook。一个后端团队可以有 API plugin:包含 API 文档 skill、安全审查 agent、数据库 migration skill、接口测试 hook。
插件的价值不只是复用代码,而是复用工程习惯。
真正的设计:从项目信号到能力配置
把这五层放在一起看,claude-code-setup 的结构就很清楚了。
它不是在回答:
Claude Code 有哪些好用功能?它在回答:
这个项目的哪些摩擦点,应该被 Claude Code 自动化?我会把它抽象成一个推荐器模型:
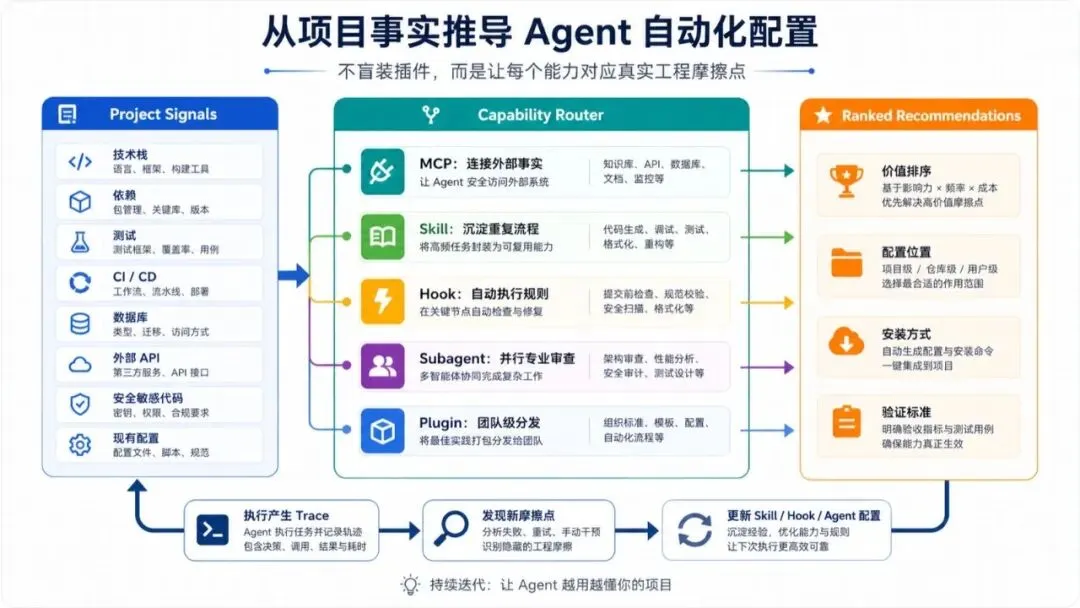
Project Signals
- language / framework
- dependencies
- test setup
- CI/CD
- database
- external APIs
- security-sensitive files
- existing Claude config
↓
Capability Router
- MCP: 需要外部事实和工具
- Skill: 高频重复工作流
- Hook: 必须稳定执行的规则
- Subagent: 需要专业判断的审查
- Plugin: 需要团队分发的一组能力
↓
Ranked Recommendations
- why this project needs it
- where to configure it
- how to install or create it
- what value it brings如果自己实现一个类似的工具,我会把它拆成四个模块。
第一是 Scanner,负责收集事实。它只读文件,不做修改。读取 package.json、pyproject.toml、go.mod、Cargo.toml、测试目录、CI 文件、Docker 配置、Claude 配置、目录结构和关键依赖。
第二是 Signal Model,把事实转成结构化信号。例如:
{
「frontend」: 「nextjs」,
「typescript」: true,
「tests」: [「vitest」, 「playwright」],
「database」: 「postgres」,
「externalApis」: [「stripe」, 「openai」],
「securitySensitive」: true,
「existingClaudeConfig」: false
}第三是 Recommendation Engine,把信号映射到能力。比如:
frontend + playwright config -> Playwright MCP / ui-reviewer
typescript -> type-check hook
stripe/auth/user data -> security-reviewer
openai sdk -> context7
tests exist -> related-test hook / test-writer第四是 Ranker,决定推荐顺序。这里不能只看“匹配到了什么”,还要看价值、风险、落地成本和团队成熟度。
一个推荐可以这样打分:
score = impact + frequency + confidence - setup_cost - runtime_noise高价值推荐通常有三个特征:项目证据明确、重复发生频率高、自动化后能减少真实风险。
它为什么坚持 read-only
claude-code-setup 的一个细节很重要:它是 read-only。它分析项目,但不直接改配置。
这不是保守,而是边界设计。
因为推荐自动化和实施自动化是两件不同的事。推荐阶段需要广泛观察,实施阶段会产生副作用:安装 MCP、写 hooks、创建 skills、引入 subagents、修改团队配置。这些都会改变 Agent 的行为边界。
如果一个 setup 工具一边扫描一边自动写配置,很容易造成两个问题:
第一,用户不知道系统为什么变了。 第二,后续 Agent 行为变复杂时,团队很难追溯来源。
所以更好的流程是:
先诊断
再解释
再选择
最后实施这对团队尤其重要。Agent 配置不是个人偏好,而是工程系统的一部分。它应该像架构决策一样,有理由、有边界、有回滚路径。
对我们有什么启发
我觉得 claude-code-setup 最值得借鉴的,不是它推荐了哪些具体工具,而是它提供了一种“Agent 配置观”。
过去我们很容易把 Agent 配置理解成提示词工程:
写好 AGENTS.md
写好规则
告诉模型怎么做但 Claude Code 的插件体系说明,真正成熟的配置应该分层:
AGENTS.md / CLAUDE.md 管总体边界
MCP 管外部事实
Skill 管可复用流程
Hook 管自动约束
Subagent 管专业判断
Plugin 管团队分发
Trace 管持续改进这几层合在一起,才像一个真正的 Agent 工程系统。
如果只有 AGENTS.md,很多规则仍然停留在文本里。如果只有 MCP,Agent 可能有工具但缺少流程。如果只有 Skill,流程可以复用但缺少强制约束。如果只有 Hook,系统有纪律但没有经验沉淀。如果只有 Subagent,审查变多但不一定能进入下一次默认行为。
所以关键不是“装哪个插件”,而是看你的项目现在缺哪一层。
一个实用判断框架
如果你想给自己的项目做一次 Claude Code setup,我建议不要从插件市场开始,而是先问五个问题。
第一,Agent 经常因为缺少外部事实而猜错吗? 如果是,优先考虑 MCP,比如文档、浏览器、数据库、GitHub、Sentry。
第二,团队是否有反复出现的任务? 如果是,把它写成 Skill。比如生成测试、写迁移、做发布说明、创建组件、写 API 文档。
第三,哪些规则每次都必须执行? 如果是,把它写成 Hook。比如格式化、lint、type-check、阻止敏感文件编辑、运行相关测试。
第四,哪些判断需要专家视角? 如果是,设计 Subagent。比如安全审查、性能分析、UI 可访问性、测试补全、API 文档。
第五,这套能力是否要给整个团队复用? 如果是,把它打包成 Plugin,而不是让每个人复制配置。
这五个问题,比“推荐几个好用插件”更有价值。因为它们会逼你回到项目本身。
最后的判断
claude-code-setup 表面上是一个官方插件,实际上是在展示 Claude Code 作为工程系统的思路。
它把项目结构看成信号,把自动化能力看成响应,把插件配置看成架构,而不是把 Agent 当成一个会写代码的聊天窗口。
这也是我觉得它值得学习的地方。
未来团队的 Agent 配置,不应该靠个人经验堆出来,而应该能从项目事实里推导出来。项目用了什么技术栈,哪里经常出错,哪些动作重复,哪些规则必须执行,哪些审查需要专业判断,这些都应该反过来决定 Agent 系统怎么长。
所以,别再盲装插件。
真正高质量的 Claude Code setup,不是把所有能力都打开,而是让每一个能力都对应一个真实的工程摩擦点。
参考资料:
- Claude Code Setup 官方插件页
- claude-code-setup GitHub
- claude-automation-recommender/SKILL.md
- Claude Code Plugins README
- Claude Code Plugins Reference
#AI #ClaudeCode #Agent #MCP #Skill
