 夜雨聆风
夜雨聆风AutoPilot:AI 驱动的移动端自动化测试平台
一、背景:为什么要做这件事
工具生态零散,是移动端测试的第一痛点
做移动端测试的同学一定深有体会——工具太多、太散、不成体系。
日常工作中,我们要在十几种工具间反复切换:用 Appium/UIAutomator2 做 UI 自动化,用 adb/idevice 连设备,用 scrcpy 投屏,用 Monkey/Fastbot 做稳定性测试,用 Charles/mitmproxy 抓包,用 PerfDog 看性能,用 ffmpeg 拆帧算启动耗时……每个工具解决一个垂直问题,但彼此之间毫无关联。
结果就是:
• 环境配置碎片化 — 每个工具一套依赖,Python、Node、Java 混着装,版本冲突频发 • 数据不互通 — 性能数据在这里,执行日志在那里,测试报告又在另一个地方 • 学习成本高 — 新人入职要学一整套工具链,上手周期长 • 流程断裂 — 写完用例、执行测试、查看报告,每一步都是手动衔接
市面上缺少一个将移动端测试工具链整合在一起的统一平台。
AI 时代带来的新可能
2024-2025 年,大模型能力的爆发给测试领域带来了两个关键变化:
第一,多模态模型(VLM)让"看图操作手机"成为现实。 当 AI 能看懂一张手机截图、理解当前页面状态并决策下一步操作时,UI 自动化不再需要依赖脆弱的控件 ID 和 XPath。
第二,文本大模型让"需求文档直接生成测试用例"成为可能。 通过多 Agent 协作的工作流,AI 可以完成需求解析、测试点提取、用例设计、覆盖率评审的完整链路。
AutoPilot 的定位

基于以上两个背景,我们构建了 AutoPilot——一个将移动端测试工具生态整合到一起的 AI 测试平台。
核心思路:
1. 工具整合 — 把 UI 自动化、Monkey 测试、性能监控、网络抓包、启动耗时等能力统一到一个桌面应用中,开箱即用 2. AI 加持 — 在整合的基础上,用 AI 重塑两个最耗人力的环节:用例编写(AI 生成)和用例执行(AI 驱动) 3. 全链路闭环 — 从需求文档输入 → AI 生成用例 → AI 执行测试 → 查看报告,一站式完成
二、整体规划
产品目标
一句话描述需求,AI 帮你完成测试。
AutoPilot 的核心理念是降低测试的"编程门槛"。测试工程师不再需要写代码、学习框架、维护定位器,而是用自然语言描述测试意图,由 AI 完成执行和验证。
功能覆盖
| 功能测试 | |
| 回归测试 | |
| 稳定性测试 | |
| 性能监控 | |
| 网络分析 | |
| 启动耗时 |
支持平台
• Android — 通过 ADB 连接,支持模拟器与真机 • iOS — 通过 WebDriverAgent (WDA) 连接 • HarmonyOS — 通过 HDC 连接
三端共用同一套用例描述和执行引擎,真正做到"写一次,三端跑"。
三、核心功能介绍
3.1 AI 测试用例生成
这是 AutoPilot 最具差异化的功能之一:从需求文档直接生成结构化测试用例。
多源输入
支持多种需求来源,覆盖主流协作平台:
• 飞书文档 — 支持普通文档、知识库、多维表格(通过 lark-cli 扫码授权,无需配置 App) • Confluence — REST API 直接拉取页面内容 • 语雀 — Token 授权读取文档 • PDF / Markdown / 纯文本 — 直接上传或粘贴
7 节点 AI 工作流
用例生成不是简单的"丢给 GPT 一句话",而是一条精心设计的 DAG 工作流,由 7 个专业 Agent 协作完成:
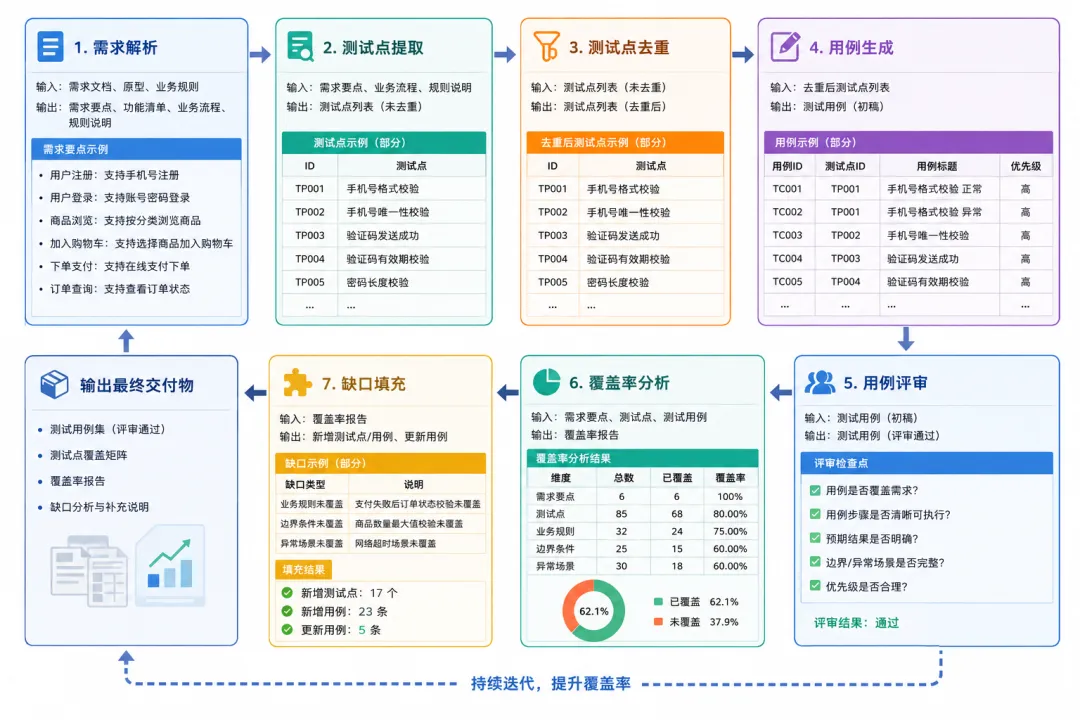
每个节点都有独立的 Prompt、Schema 校验和重试策略:
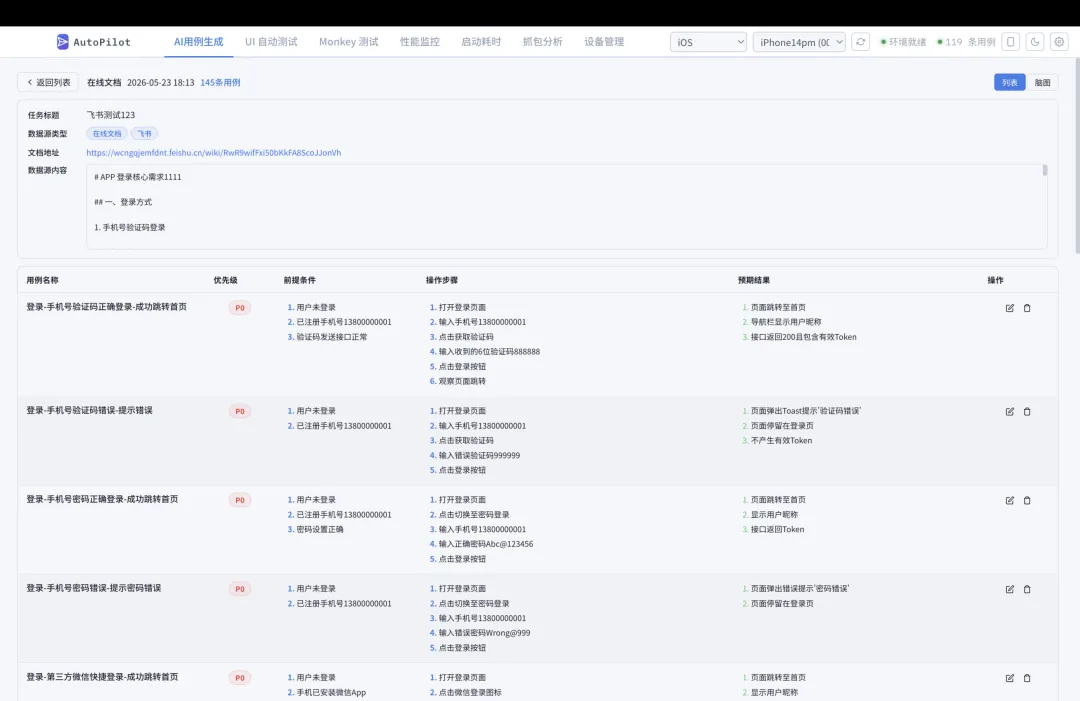
1. 需求解析 — 从非结构化文档中提取功能点、业务规则、约束条件 2. 测试点提取 — 基于需求生成测试点(正向/反向/边界/异常) 3. 去重 — 合并语义重复的测试点 4. 用例生成 — 为每个测试点生成完整用例(含优先级 P0/P1/P2、前置条件、步骤、断言) 5. 评审 — 模拟资深测试工程师评审,标记问题并给出修改建议 6. 覆盖率分析 — 评估用例对需求的覆盖情况,标识遗漏风险 7. 缺口填充 — 对高风险遗漏自动补充用例(仅在发现明确缺口时触发)
关键特性:
• 断点恢复 — 中途失败可从最后完成的节点继续,不必重头来过 • Token 统计 — 每个节点的 Token 消耗清晰可见 • 一键导入 — 生成的用例可直接导入用例库,由 AI Agent 执行
3.2 AI 驱动的 UI 自动测试
这是平台的核心引擎——让 AI 像真实用户一样操作手机。
工作原理
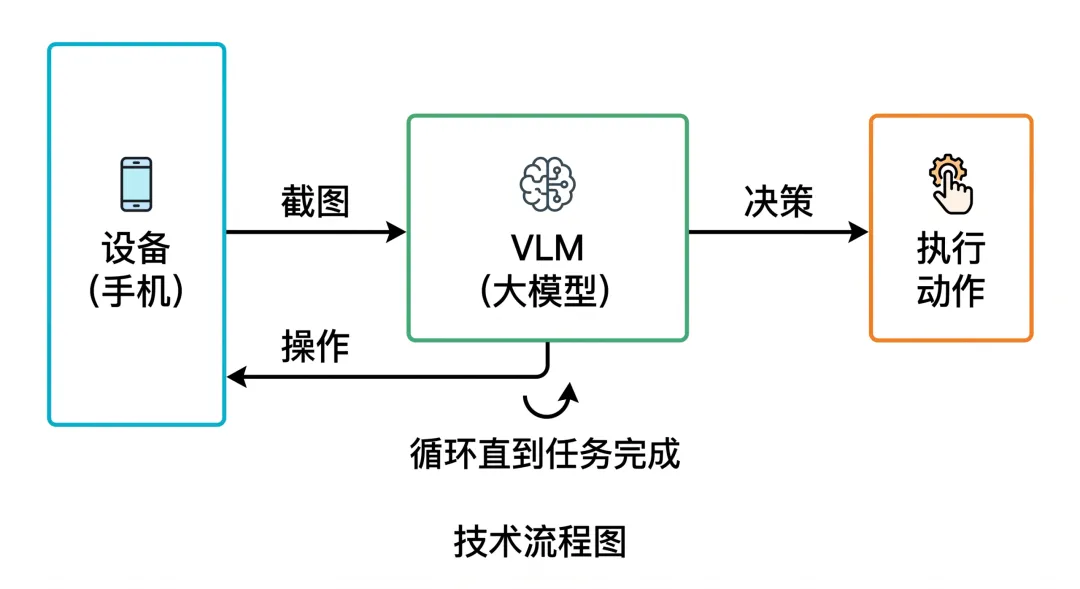
1. 截取当前屏幕 — 获取手机实时画面 2. 发送给多模态模型 — 模型"看到"截图 + 任务描述 + 历史操作 3. 模型输出结构化指令 — 如 Tap(500, 300)/Swipe(500, 800, 500, 200)/Type("hello")4. 在设备上执行操作 — 通过 ADB/WDA/HDC 发送触控事件 5. 判断是否完成 — 模型输出 finish表示任务达成
智能任务预处理
并非所有操作都需要调用大模型。AutoPilot 内置了任务预处理器,对系统级指令(如"返回主页"、“打开设置”)直接走规则引擎执行,响应延迟从秒级降到毫秒级。只有真正需要视觉理解的复杂交互才进入 LLM 循环。
双模型断言机制
测试的关键是验证。AutoPilot 采用双模型架构:
• 主模型 — 负责理解界面、执行操作(如 autoglm-phone) • 断言模型 — 独立验证最终结果是否符合预期(如 glm-4v-flash)
两个模型独立运行,避免"自己验证自己"的偏差问题。断言模型接收最终截图 + 断言描述,输出 {result: true/false, reason: "..."}。
用例编写示例
一条典型的测试用例:
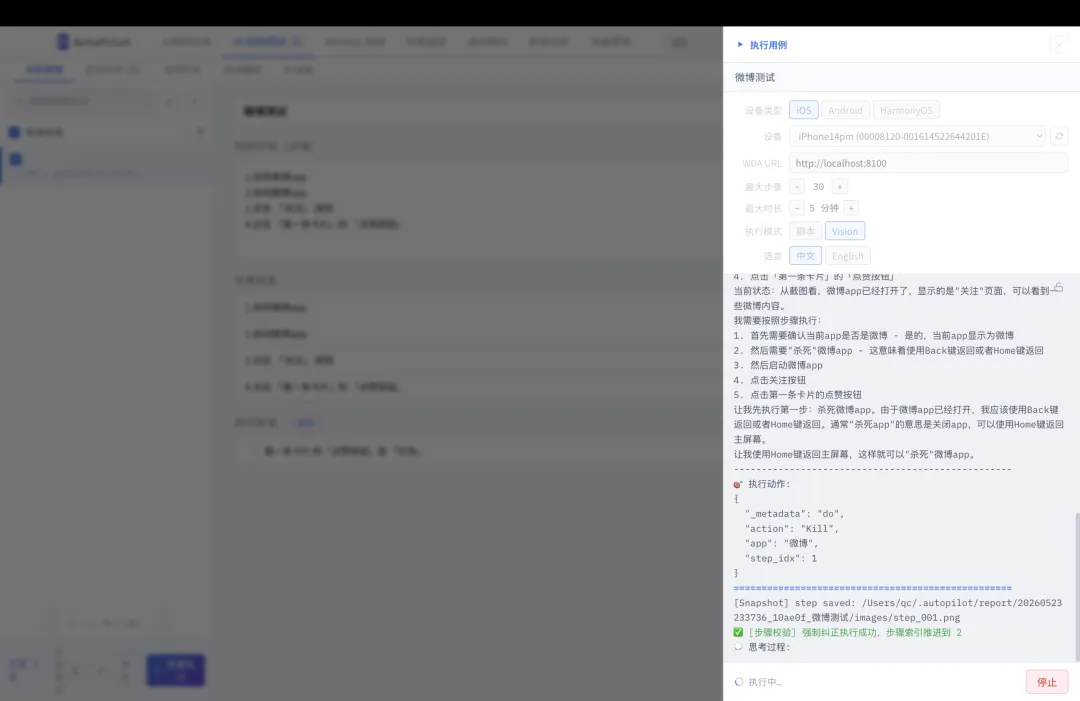
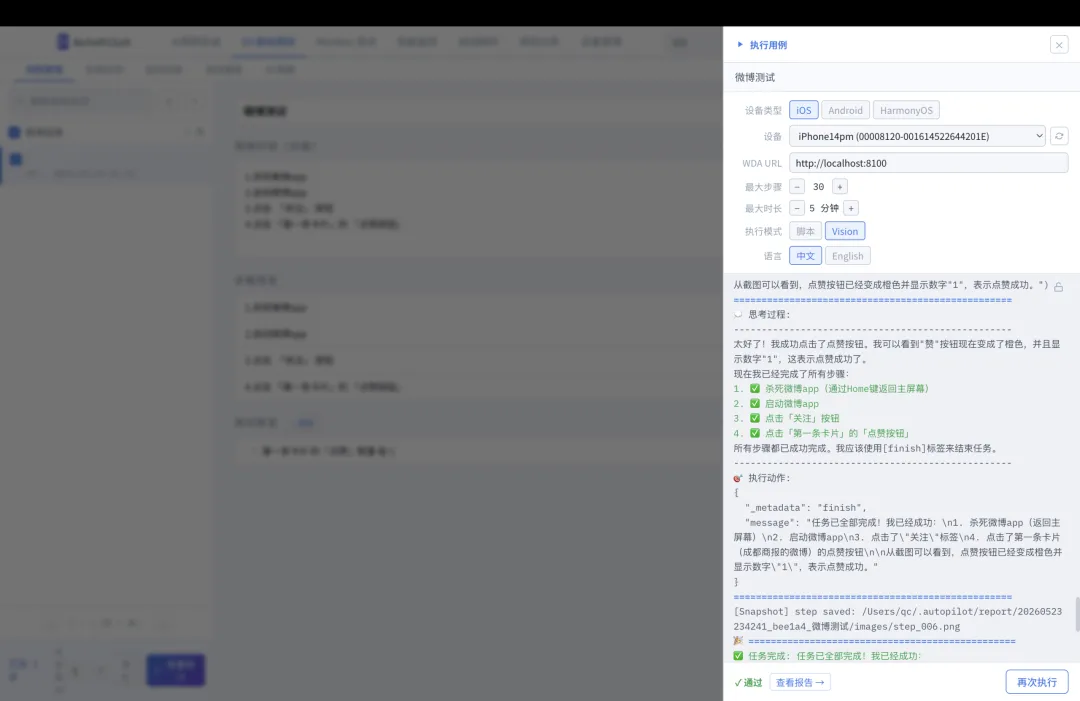
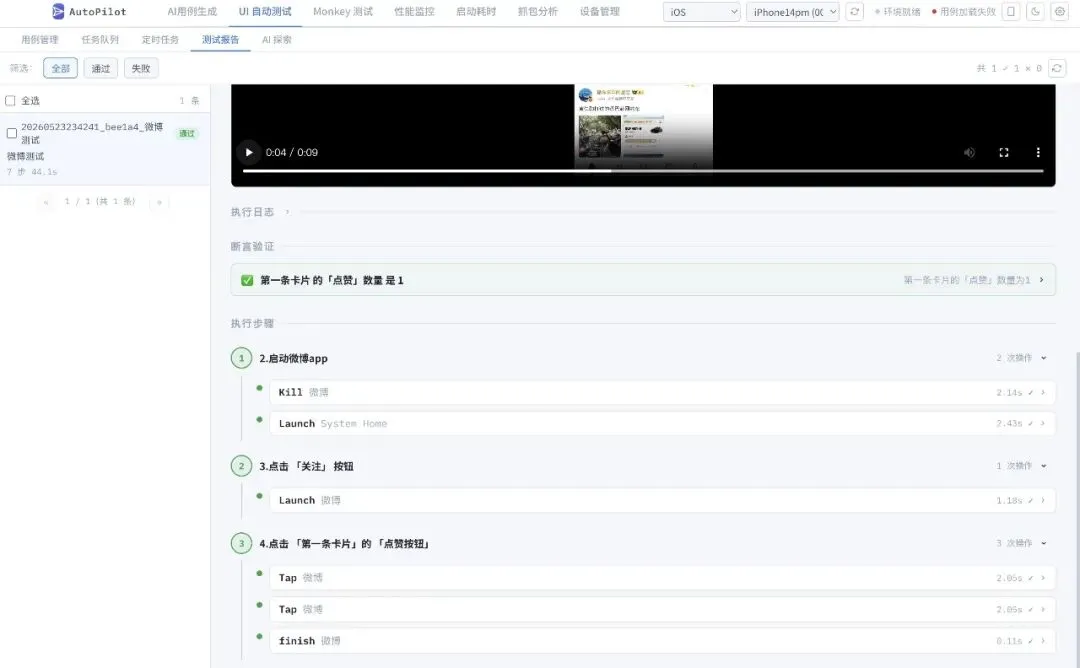
用例名称:微博点赞功能测试步骤: 1. 杀死微博app 2. 启动微博app 3. 点击「关注」 按钮 4. 点击 「第一条卡片」的 「点赞按钮」断言: 1. 第一条卡片 的「点赞」数量 是 1不需要任何控件 ID、XPath、accessibility ID。纯自然语言,AI 看图操作。
3.3 Monkey 稳定性测试
针对 App 稳定性场景,AutoPilot 集成了多种 Monkey 工具:
| System Monkey | ||
| Fastbot | ||
| WuKong | ||
| Random Touch |
支持:
• 多设备并行执行 • 崩溃日志自动收集(logcat / iOS crash log) • 内存快照分析(hprof dump + 泄漏检测) • 自定义执行时长、事件间隔、包名过滤 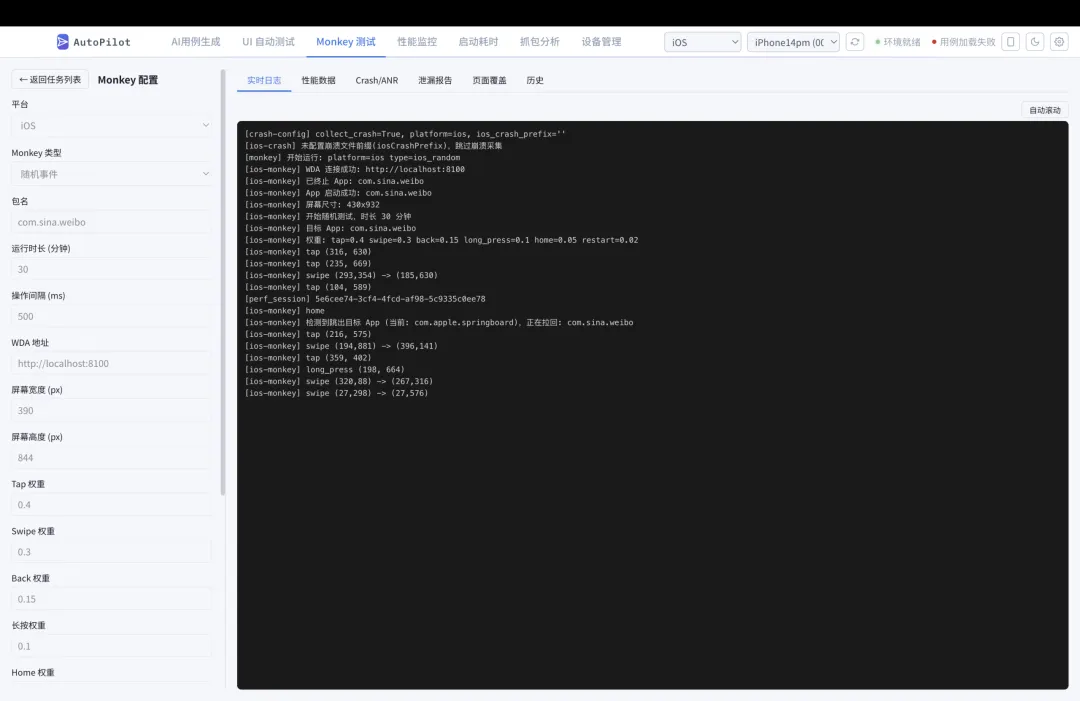
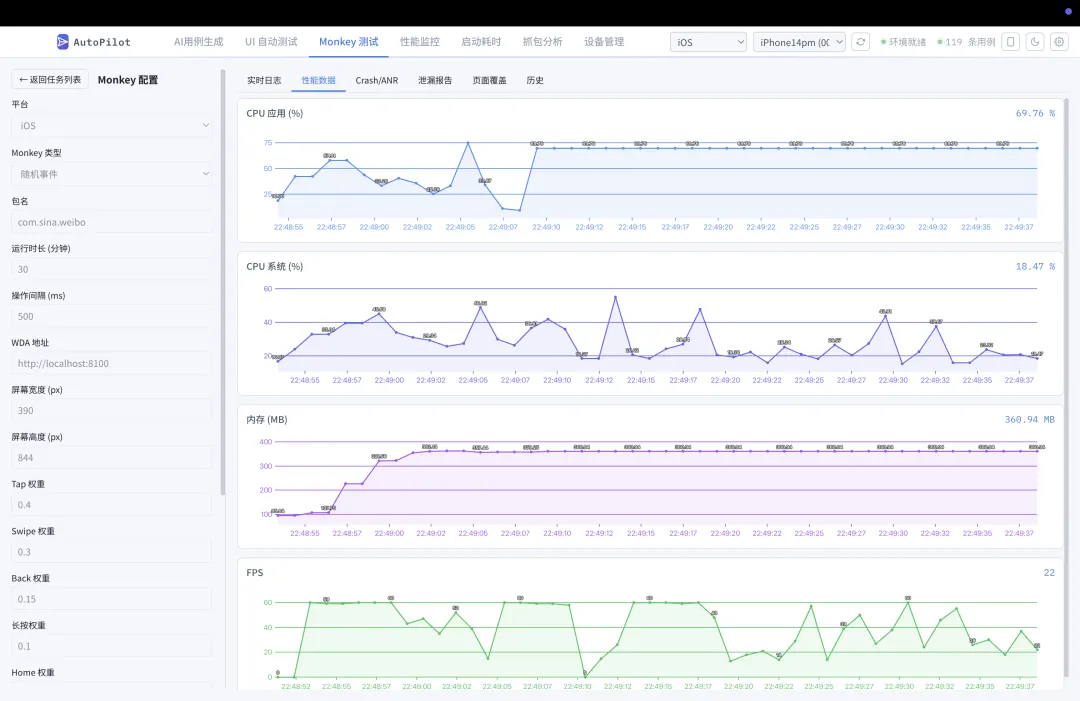
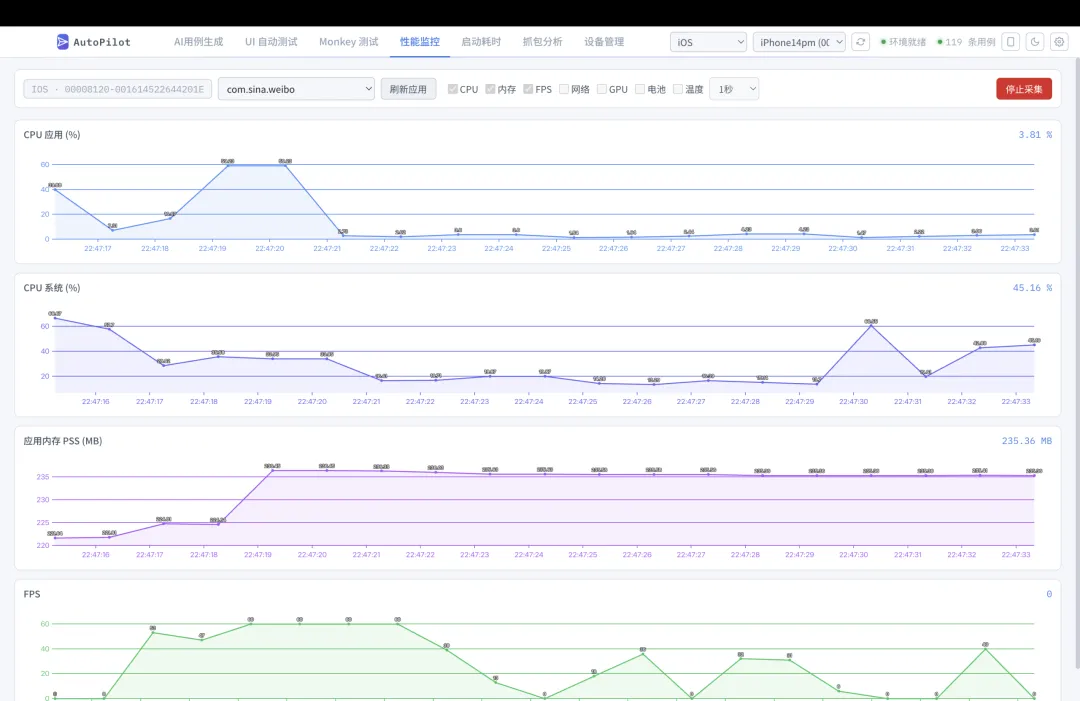
3.4 性能监控
实时采集 App 运行时性能数据:
• CPU 使用率 — 进程级 CPU 占比 • 内存占用 — PSS / RSS 内存趋势 • 帧率 (FPS) — 渲染流畅度监控
数据以时间轴图表实时展示,支持会话管理和历史对比。可在 UI 自动化执行期间同步采集,关联测试操作与性能表现。
解决了iOS17+设备无法采集性能数据的问题,在最新的iOS26也同样可以采集数据。
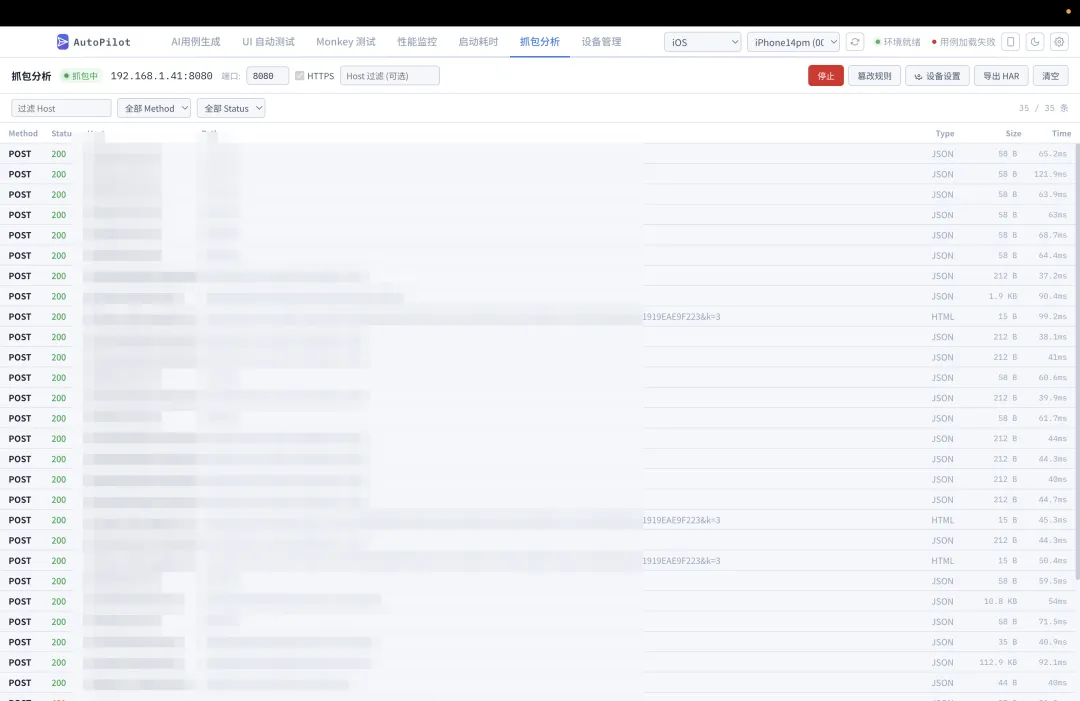
3.5 网络抓包分析
集成 MITM 代理,实现移动端 HTTPS 流量捕获:
核心能力:
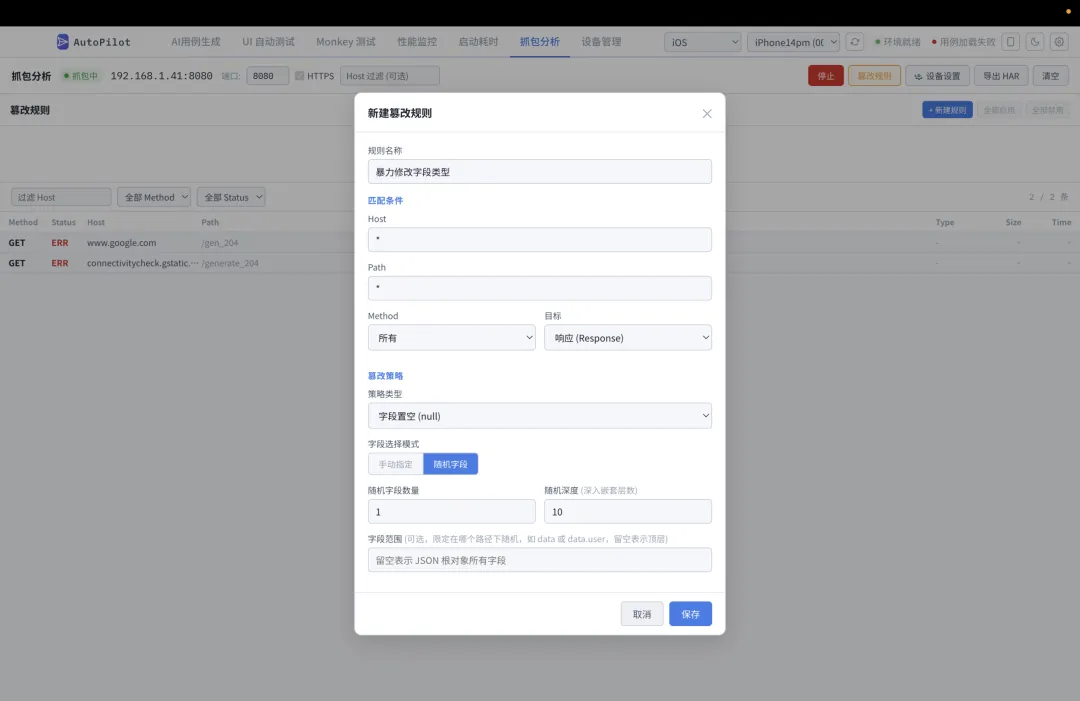
• HTTPS 解密 — 自动安装 CA 证书 + Frida SSL Pinning Bypass • 请求列表 — 按时间、域名、状态码筛选 • 请求/响应详情 — Headers、Body 完整展示 • 请求篡改 — 规则化 Mock(修改状态码、注入延迟、替换响应体)
典型场景:
• 接口返回异常数据时 App 的容错表现 • 弱网环境模拟(注入延迟) • 特定接口 Mock(返回边界值数据验证 UI 展示)
四、技术架构
4.1 整体架构
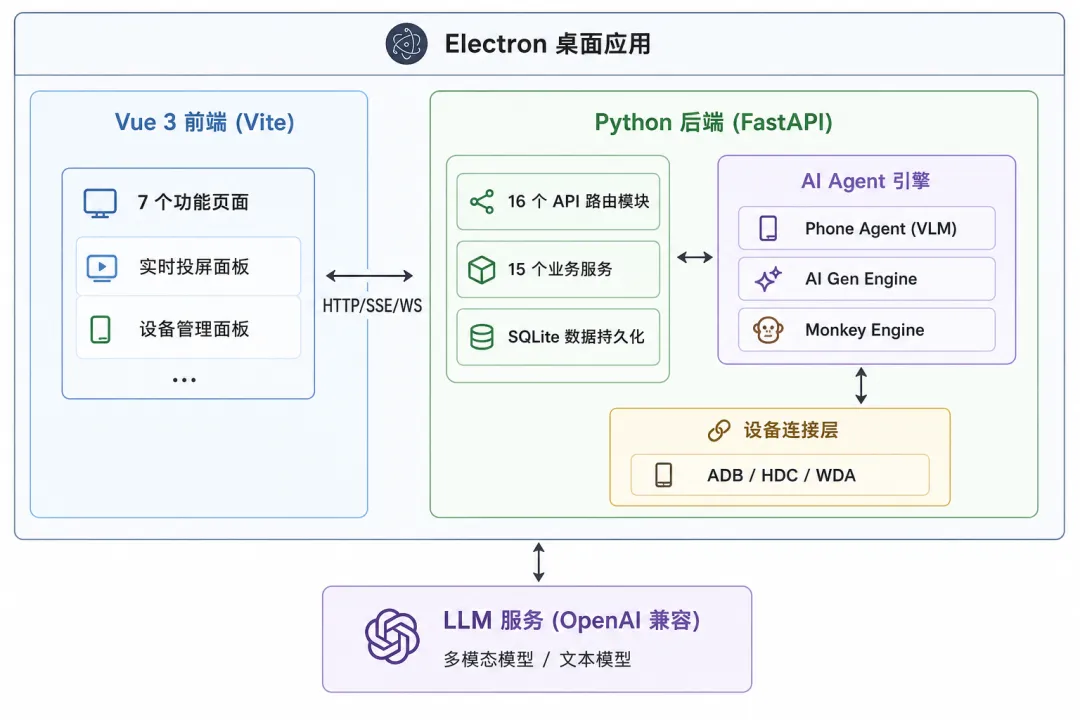
技术栈选型:
• 前端:Electron 31 + Vue 3 (Composition API) + Vite 5 • 后端:Python 3.12+ + FastAPI + uvicorn • 数据库:SQLite (aiosqlite 异步驱动) • AI 框架:OpenAI 兼容 API + 自研 Agent 框架 • 打包:PyInstaller (后端单文件) + electron-builder (跨平台安装包)
最终交付为独立桌面应用(.dmg / .exe / .AppImage),用户无需安装 Python 环境。
4.2 Agent 执行引擎
Agent 引擎是平台的大脑,核心设计:
设备抽象工厂
DeviceFactory.create(device_type="adb"|"hdc"|"ios", device_id="xxx")统一接口:screenshot() / tap(x, y) / swipe(...) / type_text(...) / get_ui_tree()。三平台差异封装在工厂内部,上层 Agent 代码完全平台无关。
归一化坐标系 (0-1000)
所有坐标操作使用 0-1000 的归一化空间。LLM 输出 Tap(500, 300) 表示"屏幕正中偏上",由 ActionHandler 根据实际分辨率换算像素坐标。好处:
• 模型不需要知道具体分辨率 • 同一用例可在不同尺寸设备上执行 • 训练数据标注更统一
线程安全的实时日志
Agent 执行在独立线程中运行。通过线程局部变量 + stdout 劫持 + asyncio.Queue,实现:
• 每个执行线程独立的日志流 • 200ms 缓冲合并(避免高频推送) • SSE 推送到前端实时展示
4.3 AI 用例生成引擎
基于自研的 DAG 工作流框架:
• 节点 (Node) — 每个节点封装一个 Agent(独立 System Prompt + 输出 Schema) • 工作流 (Workflow) — 定义节点间的依赖关系和数据流 • 上下文 (Context) — 在节点间传递中间结果 + Token 统计 • 持久化 — 每个节点执行完毕后状态写入 SQLite,支持断点恢复
节点失败时的策略:
1. 内置重试(最多 3 次,指数退避) 2. Schema 验证失败 → 自动修复 Prompt 重试 3. 最终失败 → 标记节点状态,用户可触发从该节点恢复
4.4 实时通信方案
| SSE | ||
| MJPEG | ||
| WebSocket | ||
| HTTP REST |
五、效果与价值
用例编写效率
| 传统手写 | ||
| AutoPilot AI 生成 |
效率提升约 5-10 倍,且生成的用例自带优先级、覆盖率分析,质量有保障。
执行稳定性
传统方案依赖控件属性,一次 UI 重构可能导致 70% 用例失效。AutoPilot 基于视觉理解:
• 按钮换了位置?AI 能"看到"新位置并正确点击 • 文案改了?只要语义相近,AI 仍能识别 • 新增了一个弹窗?AI 会根据上下文判断如何处理
三端统一
同一条用例"打开设置 → 进入 Wi-Fi":
• Android:通过 ADB 截图 + VLM 识别 + ADB tap 执行 • iOS:通过 WDA 截图 + VLM 识别 + WDA tap 执行 • HarmonyOS:通过 HDC 截图 + VLM 识别 + HDC tap 执行
用例层完全一致,差异封装在设备层。
六、关于开发方式:100% AI 编码
最后聊一个可能让你意外的事实:
AutoPilot 项目的所有代码,100% 由 Claude Code 生成。没有人工写过一行代码,没有人工改过一个字符。
从前端 Vue 组件到后端 FastAPI 路由,从 Agent 执行引擎到 DAG 工作流框架,从设备通信层到数据库设计——全部通过与 AI 对话完成。开发者的角色是产品设计者和架构决策者,而不是代码编写者。
这反映了 AI 时代一个重要的认知转变:
代码能力正在快速贬值,产品设计和产品思维才是核心竞争力。
当 AI 能够高质量地完成代码实现时,决定一个工具好不好用的关键不再是"代码写得多漂亮",而是:
• 你是否真正理解用户的痛点 • 你能否设计出流畅的交互流程 • 你是否做出了正确的技术选型和架构决策 • 你能否把碎片化的需求组织成一个完整的产品
AutoPilot 的存在本身就证明了这一点——一个有产品思维的测试工程师,借助 AI 编码工具,完全可以独立构建一个完整的工程化平台。
七、当前状态与获取方式
当前版本:Beta
AutoPilot 目前处于 Beta 阶段,核心功能已可用,仍在持续迭代中。
获取方式:
• 提供 macOS (Apple Silicon) DMG 安装包 • 下载即用,无需配置 Python 环境 • 暂不开源,目前beat版,后续放出来安装包
模型配置:
只有AI用例生成和UI自动化会用例,点击右上角设置进入配置页面
UI自动化:autoglm-phone 和 glm-4v-flash
AI用例生成:deepseek-v4-flash、qwen3-235b、gpt-4o-mini
未来规划:
• CI/CD 集成 — 支持命令行模式,对接 Jenkins / GitLab CI • 测试报告 AI 分析 — 自动总结失败原因、推荐修复方案 • 更智能的探索 — 基于应用结构图的系统性遍历 • 多设备协同 — 跨设备交互测试场景(如分享、投屏) • Windows 版本 — 扩展平台支持
如果你也在寻找一种更高效、更智能的移动端测试方案,欢迎交流和试用。
