 夜雨聆风
夜雨聆风“ 鲸吞阅、精输出,内修外求,日拱一卒,慢慢变富。”——半亩云田
“普通的人改变结果,优秀的人改变原因,顶级高手改变模型”。各位同学,大家好,我是你们的老朋友Fisher。
昨晚狂风骤雨下了一晚,早起看天放晴,空气挺清新,继续带孩子去公园跑步3公里,这个习惯已经坚持了两个月,也一定会坚持下去的。
今天周六,放空一下,就不聊新话题了,回顾之前聊过的一篇旧文“什么是AI幻觉”。
想回顾,是因为这周在聊“AI型人才”时,我说:AI给的答案不可全信,因为它会犯错,会瞎说,会胡编,会一本正经地胡说八道。
为什么?
因为,AI的回答不是“理解”,是“猜测”。它根据概率猜下一个词应该是什么,猜对了,给你正确答案;猜错了,就编出一个看起来像那么回事的答案。
比如,你问它“北京冬天冷不冷”,它读过无数篇描述北京冬天的文章,知道“冷”、“零下”、“暖气”这些词经常一起出现,于是它告诉你“冷”。你会觉得,它说对了。
但是,如果你问它“我家楼下新开的那家包子铺好吃吗”,它没读过任何关于那家包子铺的信息,但它不会说“不知道”。它会根据“包子铺”、“皮薄”、“好吃”这些词的关联概率,给你编一个答案——“好吃,那家包子铺的包子皮薄馅大,口碑很好”。它不知道自己在编,它只是没有“我知道我不知道”这个能力。
这就是AI幻觉。
它不是故意骗你,而是它没有“对”和“错”的概念,它只是根据上文,猜下一个最可能出现的词是什么。猜对,猜错,满意,不满意,衡量的标准,其实在你自己。
所以,重发一下这篇旧文,是希望小伙伴们再次阅读后,能够明白:AI可以替你干活,但不能替你判断。你信它几分,你得自己负责。如果觉得旧文内容还不错,那就点个赞或者“在看”,谢谢啦 。
。

以下是这篇旧文的正文内容,希望大家喜欢 。
。

01 什么是人工智能幻觉?
现在,我们越来越多地将“决策权”交给了AI,但交给它之前,你有没有搞懂它的“脾气”呢?
脾气?啥意思?
来,我问你,你有没有遇到过下面这样的经历?
比如,用AI写一篇行业分析报告,里面引用的“权威数据”看起来逻辑闭环、格式标准,感觉无懈可击。可你去权威网站去查,根本没有这些“权威数据”。你疑惑,然后去问AI时,它可能会道歉说:“这样啊,对不起,我可能弄错了。”……。
你看,我们这么“信任”AI,它居然说“弄错了”,是不是有病啊!
没错!AI确实得了一种"病",这种病,就叫“人工智能幻觉”。
不过,你肯定会有一连串的问题:AI不是靠数据训练出来的吗?数据是真实存在的啊,它怎么会编造不存在的信息呢?这种“幻觉”,是偶然失误,还是技术有缺陷?咋分辨AI说的是“真话”,还是“胡话”?还怎么信任AI交给的任何结果?……
好,别急,问题咱们一个个回答。
什么是人工智能幻觉?
人工智能幻觉,是指AI在“处理信息、生成输出”时,出现与现实事实不符、逻辑混乱或违背用户意图的情况。
说白了,就是AI在处理信息或生成内容时,“睁着眼睛,说瞎话”。不但“胡说八道”,而且最要命的是,它在胡说八道的时候,不脸红,不支支吾吾,语气是那么的坚定,逻辑看起来是那么的自洽 。
。
这种不脸红,不支支吾吾的自信样儿,像是一个职场“老油条”,为了不让你失望,为了完成任务,哪怕是编,也要编得天衣无缝。
 |
AI的这种“幻觉”,有两个典型特征,你一眼就能识别:
1.“无中生有,张冠李戴”的事实性错误。
这是最常见的AI幻觉。
AI会“编造”完全不存在的信息,或者“把甲的事,安在乙身上”,“把过去的事,挪到未来”。最迷惑的是,它编造的信息细节,逼真到让你误以为是真的。
比如,你问AI:"清朝有个叫王文治的书法家,他的代表作是什么?"
AI可能会告诉你:"王文治是清代著名书法家,乾隆年间进士,官至吏部尚书,代表作有《快雨堂题跋》……"
听起来很专业,对吧?但问题来了,王文治根本没当过吏部尚书。AI把另一个人的履历"张冠李戴"了。这种“逼真”的错误,对普通用户来说,几乎无法辨别。
 |
2.“前后打脸,自圆其说”的逻辑性矛盾。
如果说事实错误是“记错了”,那逻辑矛盾就是“想错了”。
AI在推理过程中,有时候会得出和前提条件,完全相悖的结论,违背基本的逻辑思维。
比如,你让AI写“如何提高客户复购率”,它噼里啪啦说了一通,前面说“~复购率的核心是客户满意度,要重视售后跟进”,后面却说“无需投入售后成本,只要降价就能吸引客户再次购买~”,前言不搭后语,逻辑混乱……。
这种逻辑上的“自我打脸”,本质是AI对内容的深层逻辑,缺乏理解,只是在表面上拼接语句,导致前后无法自洽。
 |
这里,AI幻觉,它不是“错别字”、“语法错误”,也不是“答非所问”。它的输出,在形式上是“正确”的,甚至比很多人类的回答更流畅、更专业。但是,其核心内容是错误的、虚构的或矛盾的。这也是,它最危险的地方:用专业的外壳,包裹错误的内核。
 |

02 那么,AI为什么会产生“幻觉”?
要回答这个问题,首先要纠正一个误解。
很多人认为,AI是一个加强版的“百科全书”或“搜索引擎”。当我们提问时,它会去数据库里翻箱倒柜,找到正确答案,然后抄给你。
其实,不是这样的。目前主流的大模型,它们的底层逻辑:不是“搜索”,而是“预测”。这一点,我在““大模型”到底是个啥?”一文中聊过。
 |
AI大模型训练时,阅读了人类历史上几乎所有的文本数据,学习了字与字、词与词之间出现的概率关系。
比如,当你问它:“秦始皇死于哪一年?” 它并不是去查历史书,而是在计算:在“秦始皇”、“死于”这两个词后面,接哪个数字的概率最高?
在它的训练数据里,概率最高的,是“公元前210年”。于是,它便输出了这个答案。
因此,AI回答问题,靠“猜”,不是“搜”,明白了吧。
 |
另外,我们还要明白:幻觉的产生,并不是AI的“故障”,而是目前主流AI技术架构、训练数据、语义理解等多方面因素,共同作用的结果,是几乎无法避免的“特性”。
为什么这么说?
1.首先,技术架构层面存在“先天局限性”。
前面我们说:当前主流的AI大模型,本质上是基于“概率统计”和“深度学习”的语言模型。说白了,AI并不理解什么是“真理”,它只理解什么是“概率”。它在数据处理和生成过程中,倾向于选择“出现概率较高”的词汇和语句组合,而非真正理解。这就意味着,它的“选择”并不一定代表真实。
比如,前面的那个栗子。你继续问:“秦始皇使用iPhone15的时候,最喜欢哪个APP?”
如果是人类,会直接告诉你:“别扯了,秦始皇那时候没手机。”
但是,AI模型的技术架构决定了,它必须预测下一个词。它不能“不说话”。于是,它开始在数据库中寻找概率最大的词、组合。它可能会想:“秦始皇”通常和“治理国家”联系在一起,“iPhone”通常和“微信”、“抖音”联系在一起……。于是,经过一番复杂的权重计算,它可能会“一本正经”一本正经地告诉你:“如果非要选一个,地图类APP 或许最符合他“胸怀天下”的掌控欲,但更可能是他会让人开发一个 “大秦帝国定制版OS”,把所有功能集成进去,并禁止六国遗民使用加密聊天软件(比如诏令禁止“Telegram”)……”。
 |
看,它幻觉了。
从它的角度看,这句话语法通顺,逻辑(在概率上)似乎也连得上。但在事实层面,这就是纯粹的胡扯。
所以,我们需要明白一个核心观点:AI并不理解什么是“真理”,它只理解什么是“概率”。
这就是技术架构层面存在“先天局限性”。
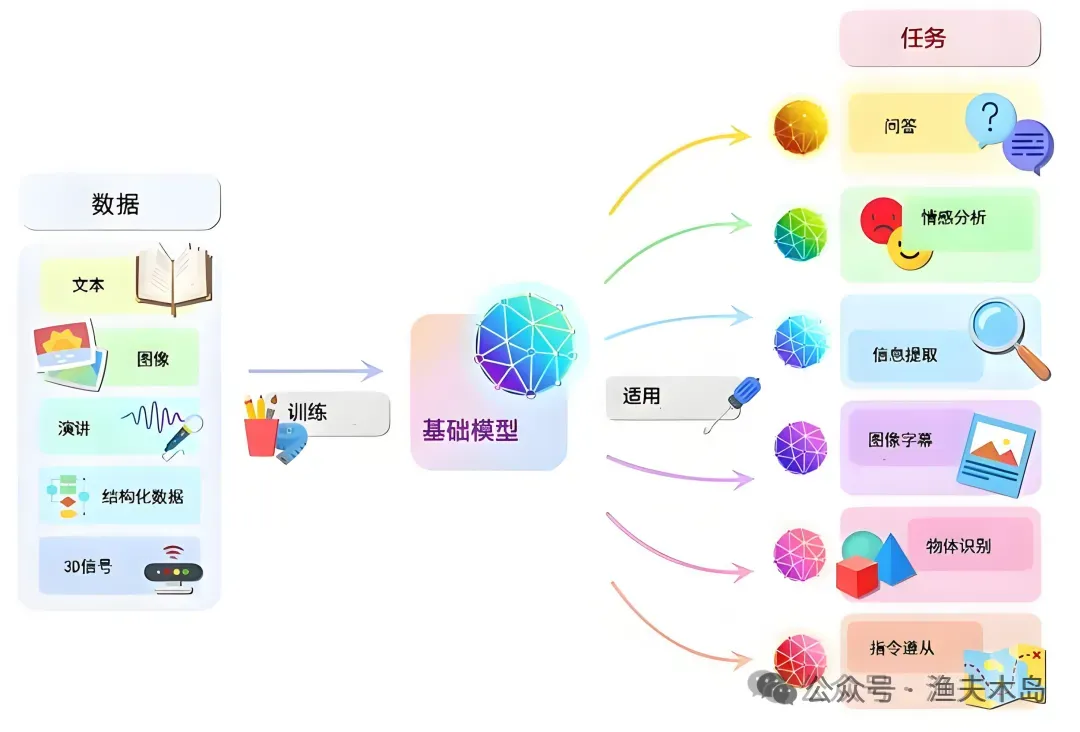
2.然后,AI学了“错误的知识”。
在““大模型”到底是个啥?”一文中,我说:“大模型就是一个读完了互联网上几乎所有书、脑容量巨大、靠“猜”来回答问题的超级学霸。”
它的“认知水平”,完全取决于它学过的训练数据。如果训练的数据(如文本、图像、视频、声音等)存在问题,AI自然会“学坏”,产生幻觉。
 |
那,训练的数据问题,主要有以下几种:
①数据存在错误或偏差。
AI的训练数据,主要来自互联网、书籍、文献等。这些数据中,本身就有可能包含大量的错误信息。比如,网上的虚假新闻、论坛里的错误观点、书籍中的印刷错误等。
AI在训练(学习)过程中,会把这些错误信息当成“正确知识”吸收,然后在生成回答时,“复述”这些错误。
 |
②训练的数据,缺失或陈旧。
对于一些新兴领域、冷门话题、久远资料……,AI的训练数据可能很匮乏。在没有足够的“正确知识”来支撑回答时,AI只能靠“编造”来回答。
还有,有的训练数据,是几年前的陈旧数据,无法反映最新的情况。用“过时”、“陈旧”的数据来训练,AI的回答自然会得出“过时、错误”的结论。
③训练的数据,存在“偏见”。
什么是“偏见数据”?
偏见数据,说白了,就是反映社会中的一些偏见的数据。比如,性别偏见、种族偏见等。
AI训练时,“学习”了这些偏见数据,那么它在生成回答时,有可能会把这些偏见放大,产生“带有偏见”的幻觉。比如,AI可能会编造“女性不适合做科技行业”,“某地区的人,更爱撒谎”等错误观点。
 |
你看,AI就像一块“海绵”,不管是给的是清水,还是污水,它都会全盘吸收。如果它吸收的污水太多,自然会“吐”出“污”(错误)的信息。
 |
3.最后,AI读不懂“深层含义”,语义理解有“短板”。
别看AI能流畅地翻译,写文章,生成图片、视频等,但它对语言的“理解能力”,其实很有限。也就是说,它能读懂“字面意思”,却读不懂“深层含义”,更无法理解复杂的逻辑、抽象的概念和特定的文化背景。更不能像人类一样,通过感官体验去理解世界。
比如,当你说"难过",AI知道这是一个负面情绪的词。但它不知道"难过"到底是一种什么感觉,是胸口发闷,还是鼻子发酸,还是想哭却哭不出来。
再比如,一些依赖文化背景的问题:“为什么中国人过年要吃饺子?” AI可能会给出“因为饺子象征团圆,财富与吉祥”的标准答案。但是,如果追问:“这种习俗是从什么时候开始的?有什么历史渊源?,怎么理解饺子赋予中国人的情感意义?”,AI可能会编造一个虚假的历史故事。因为,它无法真正理解饺子背后的传统文化、历史演变以及背后的情感意义。
还有一些复杂的逻辑推理问题,比如,“如果公司要提高利润,是应该降低成本还是提高售价?”。这类问题,其实是没有绝对答案,是需要结合公司的行业地位、产品竞争力、市场环境等多个因素综合分析。AI无法理解这些复杂变量之间的关系,按照它的回答逻辑,只能给出一个“概率最高”的简单答案,甚至有可能是“逼真”的错误答案。
所以,AI这种“语义理解能力的短板”,让它在面对复杂、抽象、特定情况、文化背景等问题时,很容易因为“理解偏差”而产生幻觉。
 |

可能,你会觉得:“不就是AI说错几句话嘛,人类还会说错话呢。大不了,我多检查几遍不就行啦”。
但实际上,“AI幻觉”的危害,远比你想象的更广泛、更严重。从个人生活、工作,到社会秩序,都可能会受到“AI幻觉”的影响。
1、个人层面:它会让你“踩坑”、“背锅”,损失时间和信誉。
这是最直接的影响。
对于职场人来说,“AI幻觉”可能让你辛苦做的工作白费,甚至影响你的“职业信誉”。
这很好理解。
比如,有一定影响力的自媒体博主,用AI写了篇研报,里面引用了虚假数据,发布后被读者指出错误,不仅要删文道歉,还会让账号失去公信力,“数字资产”缩水;
比如,做学术研究的,用AI整理文献时,AI“编造”了不存在的参考文献,导致其学术论文查重时出现问题,研究白费;
再比如,做销售的,用AI生成的客户案例向新客户推介产品,结果被客户发现案例是虚构,订单泡汤不说,还可能失去这个客户的信任。
而且,更麻烦的是:AI生成的错误信息,往往需要我们花大量时间去验证、修正。本来想用AI提高效率,结果反而增加了工作量,得不偿失。
2、专业领域:可能会引发致命风险,造成严重损失。
在医疗、法律、金融等对“准确性”要求极高的专业领域,“AI幻觉”的危害可能是灾难性的。
比如,医疗领域。AI辅助诊断工具在分析肺部CT影像时,将良性结节误诊为“恶性肿瘤”,还给出了“建议立即手术”的治疗方案。如果医生完全依赖AI,可能会让患者承受不必要的手术痛苦和经济损失。反过来,AI将早期癌症病灶误判为“良性”,延误了最佳治疗时机。
比如,金融领域。AI基于虚假的市场数据,分析股票走势,并给出“买入某股票”的建议,如果投资者盲目跟随建议买入后,可能会因实际情况相反,造成无法挽回的经济损失。
所以,你看,在某些专业领域,“AI幻觉”绝不是你认为的“小错误”,而是可能引发“致命后果”的风险点。
3、社会层面:污染“信息环境”,扰乱社会秩序
上面,聊了“AI幻觉”对个人的影响。当这种影响,从个人扩散到群体,可能就会对整个社会,产生负面影响。
①首先,它会污染“信息环境”。
互联网、移动互联网、短视频时代下,AI生成的虚假信息传播速度快、覆盖面广,很容易淹没真实信息。
比如,某AI生成了“某地区出现禽流感疫情”的虚假消息,被大量转发后,导致当地家禽价格暴跌,养殖户遭受巨大损失。
比如,AI编造的“明星丑闻”、“政策变动”等信息,吸睛明显,大量传播后,可能会引发社会恐慌和不必要的争议。
②其次,被不法分子利用。
一些诈骗分子会利用AI幻觉的语音、视频的“逼真性”,编造虚假的“官方通知”、“中奖信息”、“亲友求助信息”等虚假信息,实施电信诈骗。
比如,诈骗分子利用AI模仿银行客服的语气,生成“您的银行卡存在安全风险,请点击链接重置密码”的短信,很多人因为“不懂AI”或“信任AI”而受骗。
③更严重的是,“AI幻觉”还可能被用于舆论战、信息战。
有的国家,会利用AI生成虚假的政治新闻、社会事件,传播到其他国家,试图影响他国的政治决策和社会稳定。这种AI生成的“虚假信息武器”,已经成为国际安全领域的新挑战。
看到这里,你还会小看“AI幻觉”的影响嘛,还会觉得“不就是AI说错几句话嘛”,它的影响,尤其是被“别有用心”利用的影响,不容小觑的。
那么,问题来了,我们该怎么识别和防范呢?

04该如何识别和防范“AI幻觉”?
作为普通的用户,你我是无法改变AI的技术架构和训练数据的。不过,“改变不了现状,那就改变自己”,我们可以通过一些方法,来识别和防范“AI幻觉”的。
1、首先,要保持“怀疑精神”。
这是最基础、最核心的原则。不管AI说得多么流畅、多么专业,我们都要保持“怀疑”的态度。
AI是工具,它的作用是帮你节省时间、提供思路、整理信息,但工具会出错,所以最终的“审核权”和“决策权”必须在你手里,你也必须保持“怀疑精神”,做最终的“把关人”。
比如,用AI写文章时,对于其中的数据、案例、引用,一定要多次论证,交叉核实真实性、权威性。
比如,用AI做决策参考时,不能只看AI的结论,还要自己分析结论背后的逻辑和依据。
总之,AI就是个工具,它不是“神”。人会犯错,它也一样,所以我们始终要保持一份“怀疑精神”。
2、学会“识别信号”,可以帮我们看穿“AI幻觉”。
“AI幻觉”还是有一些“蛛丝马迹”,可以被发现的。只要我们掌握这些“识别信号”,就能快速判断AI的回答是否可靠。
比如,回答过于绝对,没有任何限定条件。
AI为了让回答“看起来更专业”,往往会用非常绝对的语气,比如“一定”、“必然”、“所有”、“绝对”等词汇。看到这些词汇时,我们可以反问自己:“真是这样的嘛”,“是真的嘛”。
比如,回答的细节过于具体,具体到“令人发指”,但无法验证。
AI编造信息时,会加入很多具体的细节,比如数据、日期、人名、地名、来源等,让回答看起来更真实、更可信。但是,这些细节太具体了,具体到令人发指,却无法通过权威渠道验证。
比如,回答的逻辑,前后矛盾,还一个劲儿的自圆其说。
这是最明显的信号。
如果AI的回答中,前面说的和后面说的完全相悖,那大概率是产生了幻觉。比如,AI在分析“如何做好产品营销”时,前面说“价格是影响购买决策的关键因素”,后面却说“消费者更看重产品质量,不在乎价格”。显然,这种前后矛盾的表述,说明AI只是在拼接语句,自圆其说。
再比如,回答具体问题,用“空话、套话,虚话”来敷衍。给你的感觉“说了,又好像没说”。
当你问AI一个具体的、需要准确答案的问题时,如果AI没有给出明确答案,而是用一些“空话、套话”敷衍,那很可能是它无法找到正确答案,只能编造模糊的回答。
比如你问AI“某公司2023年的净利润是多少”,AI回答“该公司在2023年取得了不错的业绩,净利润实现了稳步增长,为公司的未来发展奠定了坚实基础……”。
你看,像这种回答,没有任何具体数据,完全是在敷衍,大概率是AI不知道准确答案,又不想承认“自己不知道”。
看到这,上面说的这些“识别信号”都记住了吧。下次用AI时,一旦发现它的回答有其中之一,那就需要提高警惕,对AI的回答进行仔细验证了。
3、光知道“识别信号”还不行,还要掌握一些“验证方法”。
其实,验证的方法,就是通过权威渠道、信息源头、常识来判断。这里,我聊几个比较实用的验证方法,供大家做个参考。
方法1:交叉验证,用多个权威来源比对。
这是最有效、最直接的验证方法。
对于AI给出的关键信息,比如数据、案例、政策、判例、索引等,一定要去多个权威渠道进行核实,确保信息一致。
比如,AI给了你一组经济数据,你可以去国家统计局官网、央行官网、行业协会报告中核实。
比如,AI给了你一些法律条款,你可以去中国人大网、最高人民法院官网核实。AI给出的学术观点,你可以去知网、万方等学术数据库核实;AI给出的新闻事件,你可以去央视新闻、人民日报等权威媒体核实。
总之,记住:单一来源的验证不够可靠,一定要“交叉验证”。也就是说,如果多个权威来源都支持了AI的信息,那大概率是真的;如果多个来源的信息都和AI不一致,或者AI的信息在任何权威来源都找不到,那肯定是幻觉。
方法2:追溯源头,要求AI提供信息来源。
这种方法最简单,你可以直接问AI:“你刚才给到的这个信息,来源是什么?请提供具体的引用链接、文献名称或数据报告名称”。下面就看AI给的答复了。
如果AI能提供明确的、可验证的来源,那你可以去核实这个来源的真实性;如果AI无法提供具体来源,或者提供的来源是虚假的、无法访问的,那它的回答大概率是幻觉。
方法3:逻辑验证,也就是用“常识”或“逻辑”来判断。
对于一些没有明确来源的信息,我们可以用“常识或逻辑”来进行验证。也就是说,如果AI的回答违背了基本常识或逻辑,那肯定是幻觉。
比如,AI说“一个成年人的身高可以达到5米”,很明显,这违背了人体生理常识,肯定是虚假的。
有时候,我们不需要复杂的验证工具,只要用“常识或逻辑”多想想,基本上就能识破AI的“胡说八道”。

05 堵不如疏,未来如何让AI更“靠谱”?
聊到这里,对于AI 幻觉的定义、危害和原因,以及如何识别和验证,咱们都清楚了。
那么,最关键的问题来了:未来该如何让AI更“靠谱”点?
作为普通用户,你我能做的,就是“被动防范”。要从根本上解决“AI幻觉”问题,就需要技术开发者、监管部门和整个社会的“主动作为”啦。只有多方协同发力,才能让AI变得更“靠谱”。
1、技术层面:让AI从“概率优先”转向“事实优先”。
看过前期文章的小伙伴应该知道:AI的“聪明回答”,是靠“概率”推测出来的。那么,要解决“AI幻觉”的关键,还是要从底层,靠技术创新。开发者需要从根本上改进AI的技术架构和算法,让AI不仅能“说流畅的话”,还能“说正确的话”。
比如,在AI模型中加入“事实核查模块”。这样,AI在给出答案后,先通过权威知识库、数据库进行比对,验证信息真实后,才输出。
再比如,改进AI的训练方法,引入“强化学习”和“人类反馈机制”,让AI在学习过程中,不断修正错误,提高对事实和逻辑的理解能力,提高“概率推测”的准确性;
还有,提升AI的“语义理解能力”,让AI不仅能读懂字面意思,还能理解深层逻辑、抽象概念和文化背景。这点,可能需要开发者在自然语言处理技术上,要不断突破。
2、监管层面:用规则和法律为AI“划红线”。
技术的发展,是需要监管的引导,不然很容易“跑偏”。
政府和相关监管部门,需要制定明确的规则和法律,规范AI的开发和使用,从制度上防范“AI幻觉”的危害。
比如,制定AI产品的“准确性标准”,要求AI开发者对训练数据的质量和来源进行严格把关,确保数据的真实性、完整性和合法性;
再比如,要求AI产品在输出信息时,必须“明确标注信息的可靠性”。比如哪些信息是经过验证的,哪些信息是AI推测的,让用户能够清晰识别;
还有,建立AI产品的“评估和审核机制”。所有进入市场的AI产品,都必须通过“幻觉检测”和“风险评估”,只有达标才能上市。同时,对于故意利用“AI幻觉”制造虚假信息、危害社会的行为,要加大法律惩处力度,形成有力的威慑。
目前,我国已经出台了《生成式人工智能服务管理暂行办法》,其中明确要求“生成式人工智能服务提供者应当对生成的内容进行审核,不得生成虚假信息”。这是一个很好的开始,未来还需要更多细化的规则和法律,为AI的健康发展保驾护航。
 |
3、教育层面:提升全民“数字素养”,让每个人都能“驾驭AI”。
AI技术的普及,不仅需要技术和监管的支持,还需要全民“数字素养”的提升。只有当每个人都能正确认识AI,了解AI,使用AI,才能真正发挥AI的价值,避免“AI幻觉”的危害,就如当年的“互联网”一样。
提升全民的“数字素养”,这就需要开展广泛的教育宣传活动,让公众了解AI的工作原理、优势和局限性,知道“AI幻觉”是什么、有什么危害。就如我写这篇文章一样,让更多人了解。
如此,培养公众的“信息辨别能力”,让每个人都学会如何验证AI输出的信息,不盲目相信和传播AI生成的内容。
同时,对于那些专业领域的从业人员,要加强专业培训,提高他们识别和应对AI幻觉的能力。比如医生、律师、金融从业者等,需要专门学习如何正确使用AI辅助工具,避免被“AI幻觉”误导。
当然,全民“数字素养”的提升,不是一朝一夕的事。不过,这是AI时代每个人都必须具备的“基本技能”。就像互联网时代,我们要学会“辨别网络谣言”一样,AI时代我们也要学会辨别“AI幻觉”。

06最后,是你在驾驭AI,而不是它主宰你。
写到这里,关于“人工智能幻觉”的话题内容,基本上聊完了。
AI,确实是一项强大的“生产力工具”,它能帮我们节省时间、提高效率、拓展认知。
不过,它不是完美的,它会犯错,会产生幻觉,会带来风险。但这并不意味着我们要拒绝AI,就像汽车会发生交通事故,但我们不会放弃汽车,而是“会学习驾驶技巧、遵守交通规则、系好安全带”一样,对待AI,我们也应该采取同样的态度:不是逃避,而是学习“驾驭”。驾驭AI的关键,不是让AI变得“无所不能”,而是让我们自己变得“更有判断力”。
所以,请记住:AI是工具,工具的价值取决于使用它的人。只有当你具备了识别风险、验证信息、独立判断的能力,才能真正让AI为你所用,而不是被AI所坑。

 。
。PS:请允许我推荐一下刘云浩老师的这本书。刘云浩是清华教授、中科院院士,这本书分上下篇,探讨了AI的过去、现在和未来,重点在具身智能。内容通俗易懂,是一本不错的入门级读物,豆瓣评分也不错。当然,我是微信读书买的电子版~读起来没有纸质版有感觉。

