 夜雨聆风
夜雨聆风
做嵌入式视觉那会儿,我在一块STM32H743上跑YOLO-lite,帧率勉强15fps,CPU占用常年在80%以上,精度还差得离谱——小目标几乎全漏,稍微遮挡就识别崩盘。那时候我觉得目标检测这事儿已经够难了。
直到打开Apollo的感知模块。
GPU推理,10Hz点云输入,从原始点云到带ID的障碍物列表,中间横着一条七步流水线。单帧12万个点,要在100毫秒内跑完预处理、地面分割、ROI过滤、目标检测、包围框构建、目标跟踪、类型融合——最后还得输出一个稳定的结果。这和我当年在MCU上一个YOLO-lite苦撑完全是两个量级。
我花了不少时间啃这条链路,也踩了不少想当然的坑。比如一直以为CNNSeg用的是DBSCAN聚类,翻完代码才发现是并查集。比如以为PointPillars的pillar就是voxel换了个名字,其实它压根不做z方向量化。这些细节,文档里不会告诉你,得自己一行行看。
这篇文章就从头到尾把这条链路捋一遍:一帧点云进去,怎么一步步变成带ID的障碍物列表。
先看全貌。Apollo的LiDAR感知是一条线性流水线,每一帧点云依次流过七个阶段:
原始点云 → 预处理 → 地面检测 → ROI过滤 → 目标检测 → 包围框构建 → 目标跟踪 → 类型融合
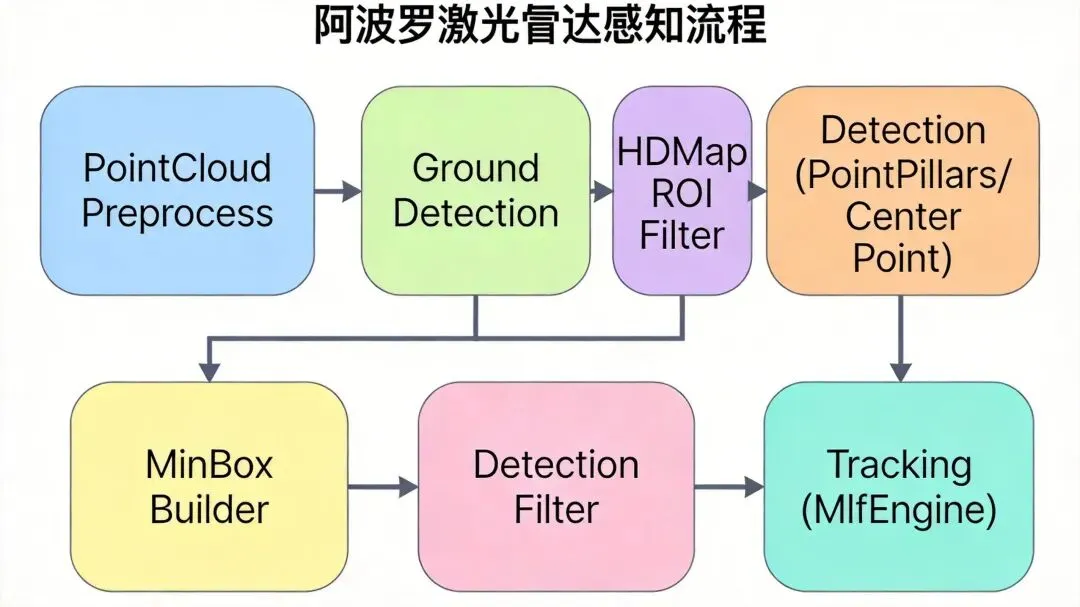
每个阶段都有独立的Component或Submodule,数据通过LidarFrame结构在阶段间传递。下面我逐个拆解。
预处理:去NaN、坐标变换、世界坐标点云
入口在DetectionComponent::Proc()回调。它订阅的话题是/apollo/sensor/velodyne64/pointcloud,收到一帧原始点云后,把控制权交给PointCloudPreprocessor::Preprocess()。
Preprocess做三件事,都很朴实但缺一不可。
第一,去除NaN和无效值。激光雷达的点云里NaN不少,特别是远距离回波弱的时候,距离值直接就是NaN。这些点如果不清掉,后面坐标变换和特征提取全都会炸。
第二,把清洗后的点云拷贝到LidarFrame结构里。LidarFrame是整个感知流水线的核心数据结构,几乎所有后续模块都从它读数据、往它写数据。
第三,用lidar2world_pose把点云从传感器坐标系变换到世界坐标系,存入world_cloud。为什么需要世界坐标?因为地面检测和ROI过滤都要在统一的世界坐标系下做,特别是ROI过滤要和HDMap对齐,传感器坐标根本没法用。
预处理结束后的LidarFrame大致长这样:cloud(传感器坐标点云)、world_cloud(世界坐标点云)、lidar2world_pose(变换矩阵)、sensor_info(传感器元数据)。后面所有模块的输入,基本就是这几样。
地面检测:RANSAC平面拟合
地面点必须先剥离。如果不分离,地面的点云量巨大,既拖慢检测速度,又会产生大量假阳性——地面上的小突起容易被误检成障碍物。
Apollo用RANSAC做平面拟合。RANSAC的核心思路就是反复随机采样三个点拟合平面,统计内点数量,最终选内点最多的那个平面方程。这个方法不新鲜,但在点云场景下效果够用。
输出是non_ground_indices,一个索引列表。注意,地面点没有被删除,只是被标记了。后面ROI过滤和目标检测只处理非地面点,但原始点云始终保留着,万一哪天需要回溯呢?
这个阶段还会往/perception/lidar/pointcloud_ground_detection话题发布中间结果,方便在Dreamview里可视化调试。调试地面检测参数的时候,这个话题帮了我大忙——RANSAC的迭代次数和距离阈值调不好,要么地面切不干净,要么路沿被当地面吃了。
ROI过滤:70米范围0.25米精度的查找表
这一步是我觉得设计最精巧的环节。
核心思路很简单:高精地图里有道路多边形,只保留道路区域内的点,区域外的全扔。但实现细节很讲究。
三步走:先把世界坐标点云变换到局部坐标系;然后根据HDMap的道路多边形构建ROI查找表(LUT);最后用LUT做O(1)查询判定每个点是否在道路内。
LUT的参数写在配置文件modules/perception/model/hdmap_roi_filter.config里:range=70m,cell_size=0.25m,extend_dist=0m。也就是说,以车辆为中心70米半径范围内,按0.25米的精度划分网格,每个网格用一个bit标记是否属于道路区域。
构建LUT的过程用了扫描线算法加位图编码,细节比较绕,但查询是真正的O(1)——给定一个点的坐标,算出它落在哪个cell,直接查bit就行。这比每帧都做点对多边形的包含判定快了不知道多少倍。
效果很直接:12万点砍到道路区域内的几万点,后续检测的计算量直接减半以上。先砍量再算,这是Apollo在工程上反复出现的设计哲学。
目标检测:从CNNSeg到PointPillars到CenterPoint
检测模型是整条链路里迭代最快的部分,Apollo从早期的CNNSegmentation一路换到了PointPillars,再到Mask-Pillars和CenterPoint。
CNNSegmentation是老版本的默认方案,我虽然没在实车上跑过,但它的设计思路值得细看,因为后面很多模块的接口都是按它的输出格式定义的。
它把点云按鸟瞰图离散化成2D网格,每个cell提取8通道特征:max_height、top_intensity、mean_height、mean_intensity、count、direction、distance、nonempty。然后CNN预测4个输出:center_offset(instance_pt)、category(category_pt)、objectness(confidence_pt)、height(height_pt)。
聚类部分是我踩坑最多的地方。我一直以为用的是DBSCAN——很多技术博客也这么写。但翻到modules/perception/obstacle/lidar/segmentation/cnnseg/cluster2d.h的代码才发现,它用的是并查集(Union Find)。具体来说,每个cell基于CNN预测的center_offset构建一条有向边,指向offset所指向的父cell,然后通过压缩并查集找连通分量。objectness阈值大于0.5的cell才算物体cell,才参与并查集构建。
这个设计比DBSCAN聪明在哪?DBSCAN是盲目搜索邻域,而并查集利用了CNN的center_offset预测来引导聚类方向——CNN已经告诉你这个cell属于哪个实例中心了,沿着这个方向找连通关系就行,不需要漫无边际地扩展邻域。
PointPillars从Apollo 7.0开始成为默认检测模型,也是目前社区里讨论最多的方案。
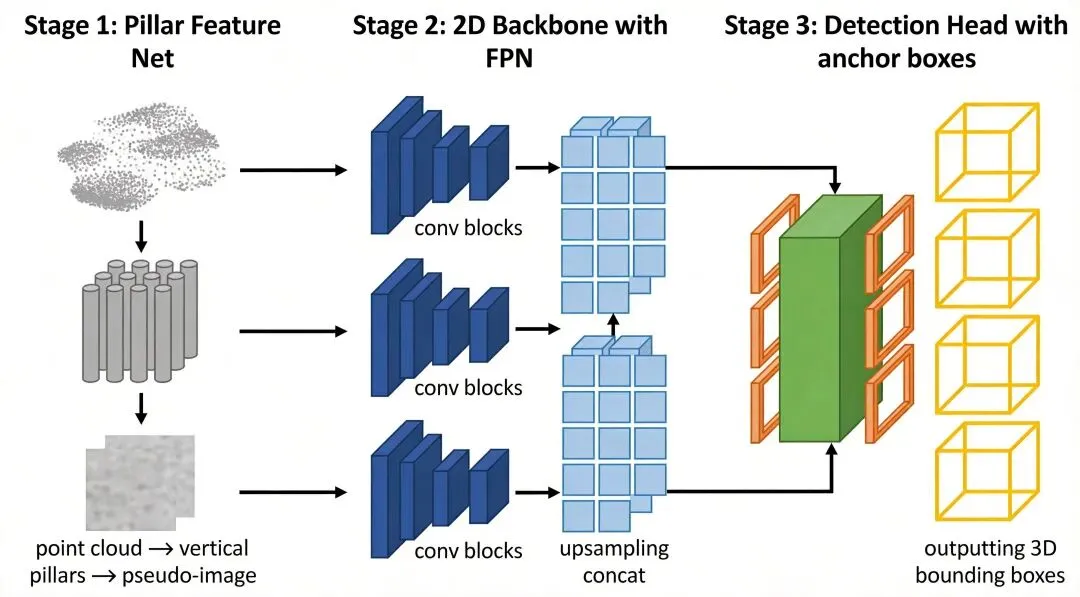
它的核心创新是把点云离散化为垂直柱体(Pillar),而不是3D体素(Voxel)。pillar和voxel的区别很关键:pillar只做xy方向的量化,不在z方向切分。每个pillar是一根从地面到天空的柱子。这样做有两个好处:省掉了z方向的3D卷积,计算量大幅降低;对于稀疏点云更友好,因为同一个pillar内点数通常很少。
每个点提取9维特征:原始坐标和反射强度(x,y,z,r)、点相对所在pillar中心点的偏移(xc,yc,zc)、点相对pillar网格中心的偏移(xp,yp)。然后限制最多P个非空pillar、每pillar最多N个点,构成(D,P,N)的三维张量。
编码部分用了一个简化版PointNet:Linear+BN+ReLU+MaxPool,把每个pillar的点特征编码成一个C维向量,得到(C,P)的输出。然后scatter回伪图像——把每个pillar的特征放回它对应的xy网格位置,空pillar填零,得到(C,H,W)的2D伪图像。
后续就是标准的2D CNN Backbone了,用了FPN结构提取多尺度特征,concat成6C维度的特征图,最后接SSD检测头输出3D包围框(x,y,z,w,l,h,theta)。部署层面用libtorch + torch.jit.trace分5段推理,工程上做了比较细致的优化。代码在modules/perception/lidar/lib/detector/point_pillars_detection/point_pillars.cc。
Mask-Pillars在Apollo 7.0新增,在PointPillars基础上加了两个东西:一是残差注意力模块,公式是F(x)=(1+M(x))*T(x),M(x)是注意力掩码,T(x)是原始变换;二是pillar-level的监督信号,直接在pillar层面加分类loss,提升recall。思路不算复杂,但对小目标的召回确实有帮助。
CenterPoint在Apollo 10.0引入,把3D检测转化为中心点检测问题。体素化参数:0.2m量化粒度,体素网格752×752×30,4维特征(x,y,z,intensity),感知范围±75.2m。这个量化粒度比PointPillars更细,网格更密,对近处小目标的精度有提升,代价是计算量更大。
切换检测模型只需要改一行配置。配置文件在modules/perception/production/data/perception/lidar/models/lidar_obstacle_pipeline/下的lidar_obstacle_detection.conf里,把detector类型从PointPillarsDetection改成CenterPointDetection就行。这种插件化设计是Apollo工程架构的一大优势,整个pipeline的任何一个阶段都可以通过配置替换。
MinBox Builder:从稀疏点云恢复朝向
LiDAR点云天然稀疏——遮挡、距离衰减、反射率不足,都会导致一个障碍物只被扫到部分表面。从这些残缺的点恢复出一个合理的3D包围框,就是MinBox Builder要干的事。
方法很巧妙:先对非地面点做2D凸包,得到障碍物的外轮廓多边形。然后遍历凸包的每条边,把其他点投影到该边的法线方向,找到最远的两个交点,这样就构成一个候选矩形框。所有边都试一遍,得到一组候选框,选面积最小的那个。
为什么选最小面积?因为凸包外接矩形里,面积最小那个通常最贴合物体的真实轮廓。最大面积那个往往是被凸包的某条长边带偏了。
代码在modules/perception/obstacle/lidar/object_builder/min_box/min_box.cc,分两步:ComputePolygon2dxy做凸包,ReconstructPolygon做最小面积框搜索。另外有个硬性规定:length必须大于width,障碍物朝向就是length方向。这保证了朝向的一致性——不然同一个框可能今天朝东明天朝西。
这个最小面积策略看起来很简洁,但在稀疏点云下确实有效。我在Dreamview里对比过MinBox和PCA方向估计的结果,MinBox对朝向的恢复明显更稳定,特别是点云只有物体一侧的时候。
跟踪:MlfEngine+匈牙利匹配+鲁棒卡尔曼
跟踪模块在Apollo 7.0之后默认用的是MlfEngine,不是更早的HM ObjectTracker。Mlf是Multi-Lidar Fusion的缩写,设计上支持多激光雷达融合跟踪,但单雷达场景下也完全适用。
MlfEngine的流程是这样的:
先做前后景分离。SplitAndTransformToTrackedObjects把检测到的目标分成前景(车辆、行人、自行车等)和背景(植被、杆子等),分别走不同的匹配策略。前景目标匹配更精细,背景目标要求更宽松。
然后给每个目标计算10步直方图特征,ComputeShapeFeatures()把点云的空间分布编码成一个固定长度的特征向量。这个特征后面会参与匹配距离的计算。
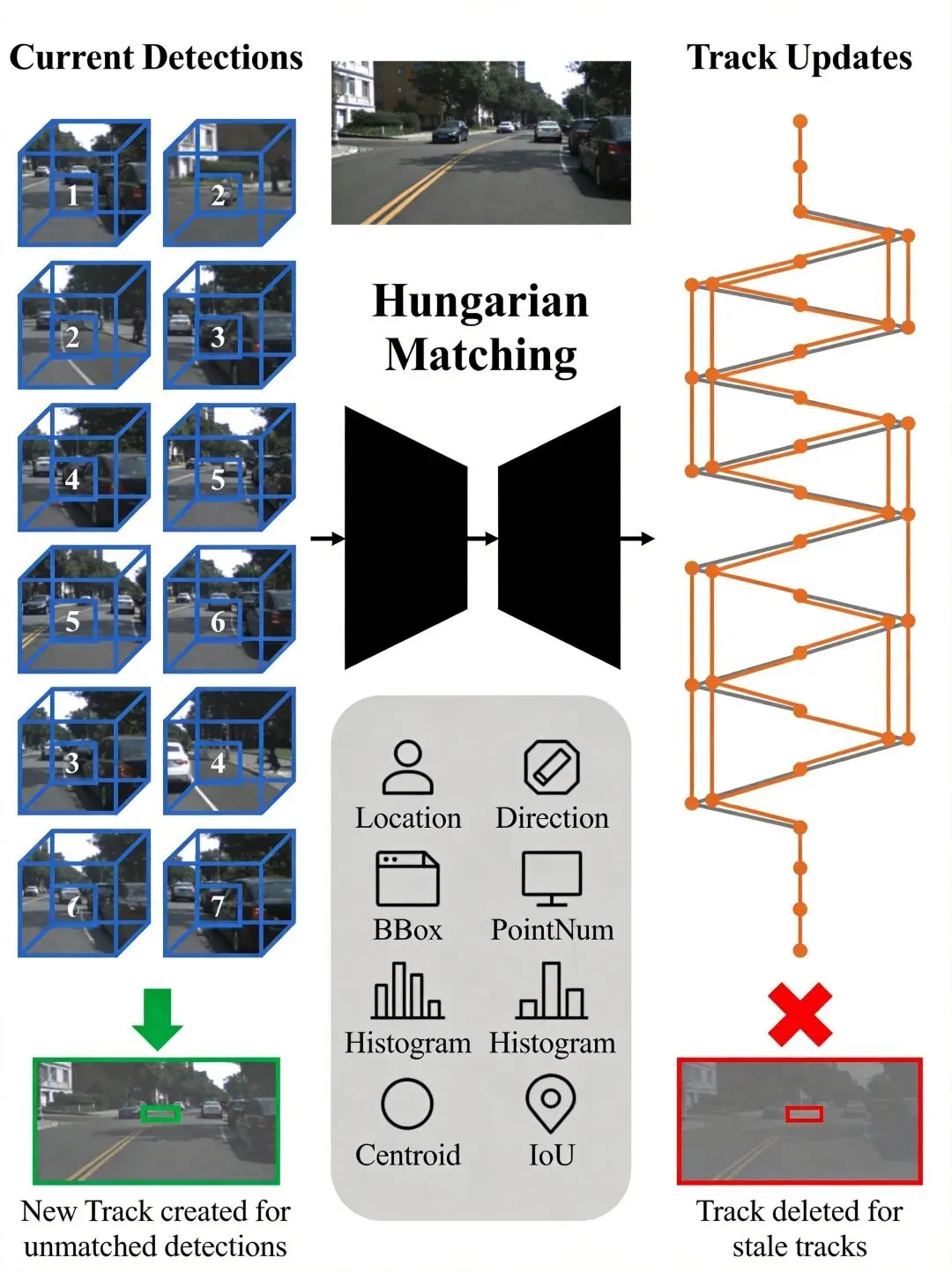
匹配是核心环节。MlfTrackObjectMatcher对前景目标用MultiHmBipartiteGraphMatcher——就是匈牙利算法做二部图匹配。对背景目标用GnnBipartiteGraphMatcher,贪心匹配就行,背景不需要那么精确。匹配距离阈值是4.0。
匹配距离不是简单的IoU,而是7种特征距离的加权组合:Location(位置)、Direction(朝向)、BBoxSize(尺寸)、PointNum(点数)、Histogram(直方图)、CentroidShift(质心偏移)、BBoxIoU(包围框交并比)。7种,不是5种。CentroidShift和BBoxIoU经常被忽略,但它们在遮挡和形变场景下特别有用——IoU可能很低但质心偏移小,说明目标只是形状变了没跑远,依然应该关联上。
滤波用Robust Kalman Filter,恒速模型。它比标准卡尔曼多了几个设计:观测冗余,同时使用anchor point shift、bbox center shift和bbox corner point shift三种观测来约束状态;Breakdown阈值机制,抑制肥尾噪声导致的过度估计;按关联质量调节更新增益,匹配距离越远的关联,对状态的更新影响越小。这些机制让跟踪在遮挡和短暂丢失场景下更稳定。
轨迹管理是常规逻辑:未匹配的新检测创建新轨迹,连续多帧未匹配的轨迹标记为丢失并最终删除。
还有一个容易忽略的细节:Sequential TypeFusion。它用线性链CRF做时序类型融合,减少同一目标在帧间类型切换的问题。比如一个目标在第10帧被分类为行人,第11帧变成自行车,TypeFusion会参考历史类型分布,倾向于保持一致。
一些个人体会
从嵌入式视觉转来看Apollo的感知链路,最直观的感受是量级差距。我当年在MCU上一个YOLO-lite跑到15fps已经满负荷,Apollo是在GPU上10Hz跑完整条pipeline——预处理、分割、检测、构建、跟踪、融合,一步不少。
并查集聚类是我觉得最被低估的设计。DBSCAN在点云聚类里几乎是默认选择,但Apollo的CNNSeg用并查集利用CNN预测的center offset引导聚类方向,不是盲目搜索邻域,思路完全不同。可惜很多人写文章还说是DBSCAN,大概是因为没翻到cluster2d.h那行代码。
ROI过滤的LUT设计也让我印象深刻。70m范围、0.25m精度、O(1)查询,先砍量再算。这种工程思路在Apollo里随处可见——不是追求算法的数学最优,而是在有限算力下把瓶颈问题用最直接的方式解决。
MinBox的最小面积策略,简洁到有点朴素,但在稀疏点云下确实比PCA更稳定。7维特征距离的匈牙利匹配也比单纯IoU匹配鲁棒得多,特别是遮挡场景——IoU可能崩了但质心偏移还在,不至于丢跟。
插件化设计让整条链路的可替换性极强。换检测模型改一行配置,换跟踪器也改一行配置。这种架构在工程迭代里省下的调试时间,比任何算法优化都实在。
