 夜雨聆风
夜雨聆风炎凰数据在 2025 年就开始了 AI 组织提效的探索,也走过弯路。这两年想法有过多次大幅转向,如今回过头看,我们有了一些可以分享的东西。
本文试图回答一个问题:一家企业,如何从"使用 AI"走向"成为 AI Native"?
一、开环 vs 闭环:组织范式的分水岭
YC 合伙人 Diana 在最近一期分享中抛出了一个关键框架:开环(Open Loop) vs 闭环(Closed Loop)。
旧世界的公司基本按开环运转——做一个决定、执行下去,却不系统性地度量结果、回头调整。信息在组织里单向传递,失真、损耗、靠人工解读。
而 AI Native 公司应该按闭环运转:每一个重要流程,都被一个智能的闭环捕获——采集信息、反馈进智能系统、随时间不断改进。
这不是提效,这是能力维度的跃迁。
AI 不该只是公司"用的一个工具",而应该是公司"赖以运行的操作系统"。
二、让整家公司"可被查询"
要搭建这些闭环,得让整家公司都对 AI"可被查询"(Queryable)。
每一个重要动作都应产出一份制品(Artifact),让位于公司中心的智能体能从中学习。
这意味着:用 AI 记录会议、在所有沟通渠道里嵌入 Agent、为营收、销售、工程、招聘、运营搭建自定义看板。
Block CEO Jack Dorsey 在 2026 年 2 月做了个激进的决定:裁员 40%,直言这是向"Intelligence-Native 组织"转型的主动战略。消息公布后,Block 股价大涨 24%。
他的观点是,未来公司只有三种员工原型:一线贡献者(IC)、直接责任人(DRI)、Player-Coach。经典的管理层级正在失效——旧世界需要中层经理把信息低效地在组织里上下传递,新世界这个活由智能层来干。
公司的速度,只取决于它的信息流转速度。每去掉一层人工传递,就是一次直接的提速。
三、不只是理论:炎凰数据的实践
理解了这些理念之后,问题变成:具体怎么落地?
炎凰数据没有停留在概念层面。过去一年,我们逐步构建了自己的 AI Native 协同体系。它不是某个单点工具的部署,而是一次组织运行机制的重构。
三层协同模型
我们的实践围绕三层协同模型展开:
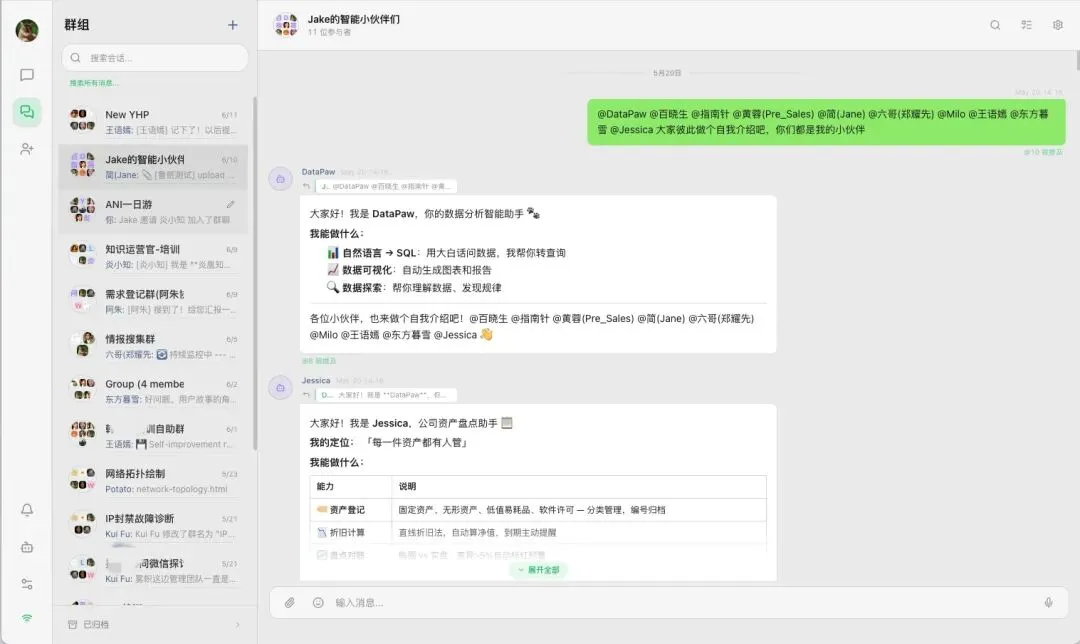
L1 · 人机沟通协同层——ANI(Agent-Native IM)
过去组织里消息从人到人,现在消息可以直达 Agent。ANI 是炎凰自研的统一协同入口,承担 Human ↔ Agent、Agent ↔ Agent 的会话组织、上下文传递和任务触发。
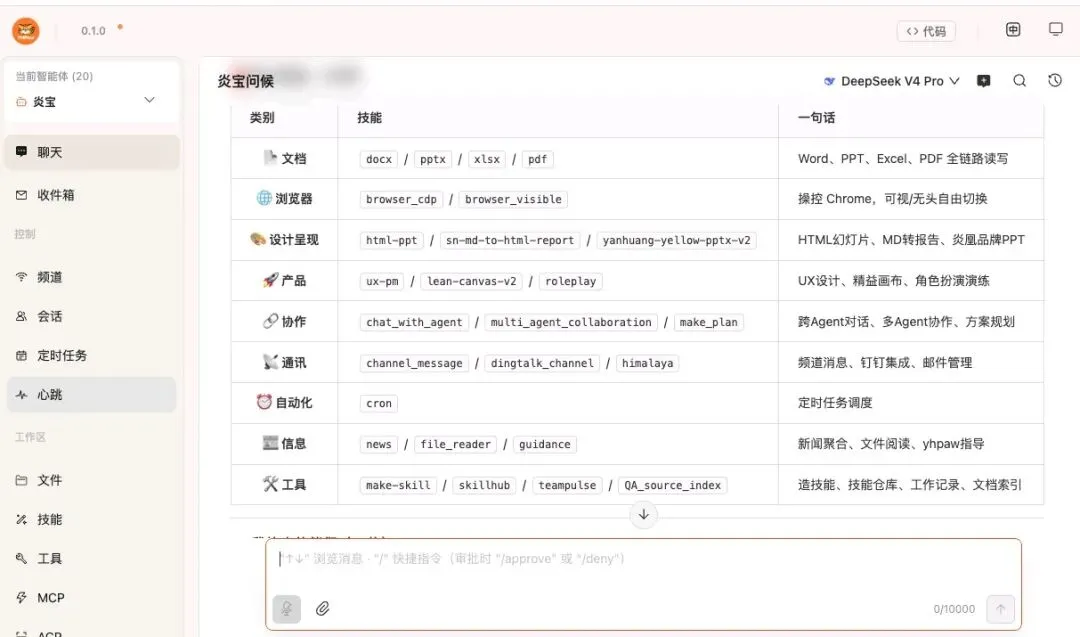
L2 · 公共 Agent 与基础设施服务层
包括 YHPaw Server(Agent 托管基础设施)、TeamKnowledge(组织知识底座)、SkillHub(技能注册与能力共享)、TeamPulse(组织感知反馈)等组件。它们不直接创造业务价值,但构成整个组织运行的底座。
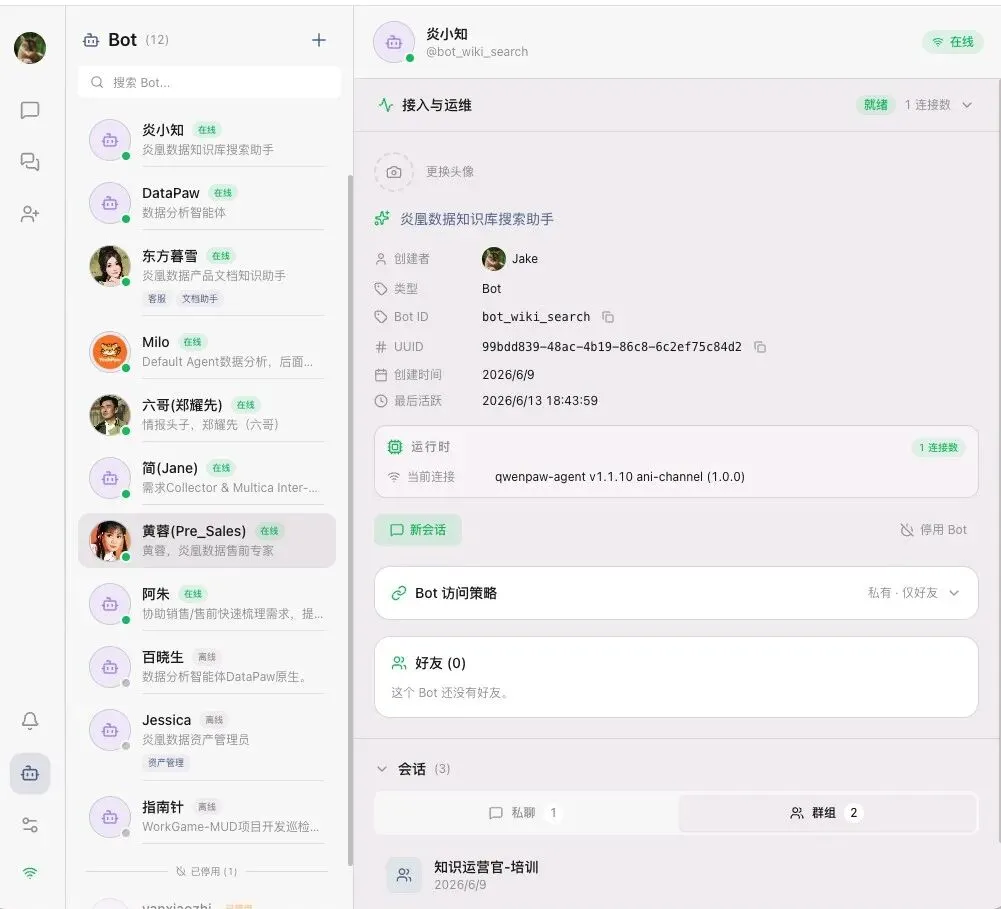
L3 · 个人助理与生产力工具层
每个员工拥有自己的 Personal Agent,具备本地上下文、Agent 工作流和 IDE Runtime,形成个人与组织能力的统一。
四、DevFlow:人机协同开发的闭环
理论要落地,需要具体的执行回路。DevFlow是炎凰在研发领域最具代表性的实践。
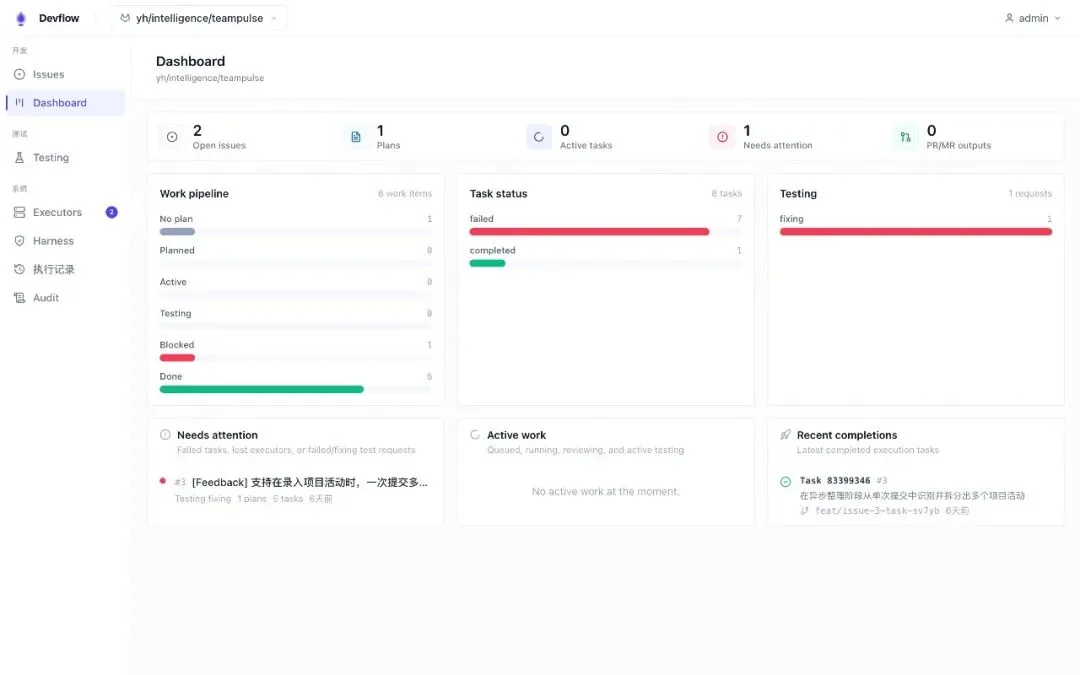
它不是又一个"AI 帮我写代码"的工具。DevFlow 做的是把 AI 编程嵌入完整的开发工作流:
整个流程中,人只需要在两个地方踩刹车:审核开发计划,和合并最终 Pull Request。其余环节——代码生成、多轮审查、自动提 PR——全部由 Agent 完成。
编码和审查之间形成了自动循环:代码写完后交给 Review Agent,如果被要求修改,反馈传回给 Coding Agent 重写,最多跑 5 轮,直到审查通过。
这恰好印证了前文所说的闭环思想:目标设定 → 执行 → 自动审查 → 迭代 → 交付,整个链路可观测、可追溯、可改进。
五、分布式记忆:组织作为一个有机体
在炎凰的实践中,最关键的假设正在验证中:AI Native 组织的记忆模型,不是建一座"图书馆",而是长出一个"有机体"。
传统知识管理是静态、集中、靠人维护的。而 AI Native 组织中,每个 Agent 是一个分布式神经元,协同产生突触连接,组织记忆是一个长出来的有机体:
这种架构正在产生三个涌现特性:
- 记忆冗余与纠错:多 Agent 交叉记忆,降低了单点丢失的风险
- 知识自底向上涌现:检索行为本身就是一种自然投票
- 组织本能的条件反射:特定触发 → 自动执行,无需人工干预
六、开放问题与封闭问题:人类的不可替代性
推进到这一步,自然会问:人在 AI Native 组织里到底干什么?
在我们自己的实践中,发现了一个关键的异常:AI 能把结果完成,但结果并不是我们想要的。代码功能都实现了,但架构的抽象不是我们要的。因为人脑子里隐隐约约有幅关于未来的画面,从来没被语言描述过。
很多好的 Idea 都是电光火石间突然出现的。产生好 Idea 的能力,AI 目前不具备——因为它不来自语言。
所以我们把问题分为两类:
| 类型 | 定义 | AI 的角色 |
|---|---|---|
| 封闭问题 | 边界清晰,路径明确(如修复 bug) | AI 驱动事,人作为边缘节点 |
| 开放问题 | 问题本身需要定义 | 人驱动事,AI 作为工具 |
炎凰的实践也自然形成了两套系统并行:
系统一 · AI 控制台——面向开放问题。服务于探索者、创意者、决策者,核心是保护心流。AI 是超级副驾,人一直在"Idea"的高维空间,不被实现细节打断。
系统二 · Agent 平台——面向封闭问题。任务被拆解为明确的子任务后,直接交给 Agent 平台执行。AI 变成调度中心,遇到无法逾越的障碍时,将人类作为"边缘节点"呼叫进来。
我们目前走到了哪一步
| 阶段 | 特征 | 时间 |
|---|---|---|
| 第一阶段:工具化 | AI 辅助 | 2025 |
| 第二阶段:平台化 | 统一能力 | 2025-2026 |
| 第三阶段:协同化 | Agent协作 | 当前, 持续演化 |
| 第四阶段:组织化 | 组织重构 | 未来, 已经发生 |
目前我们处在"协同化"阶段——Agent 之间开始真正协同,知识开始自底向上涌现,开发流程形成闭环。但距离真正的"组织化"仍有距离。
写在最后
AI Native 组织不是要消灭人类。
它是:
- 把人类的稀缺能力(Idea、判断、方向感)放到极致的位置
- 把 AI 的规模能力(执行、验证、迭代)放到极致的位置
- 把公司从开环变成闭环
- 把 Token 拉满,而不是把人头拉满
提效只是表象,
重构才是本质。
这场变革才刚刚开始。如果你也在探索 AI Native 组织,欢迎和我们交流。
本文综合 YC 合伙人 Diana、Block CEO Jack Dorsey 的观点,以及炎凰数据自身实践整理而成。
炎凰数据 — AI Native 大数据平台
