 夜雨聆风
夜雨聆风与其一句句指挥 AI,不如设计一套让它自己转起来的循环Loop
有个正在浮现的做法,叫 Loop Engineering,循环工程。它要取代的,是过去两年我们最熟的那件事,亲手给 agent 写 prompt。它的内核其实很简单,你不再直接去 prompt 一个 agent,而是设计一套系统,由这套系统去 prompt 你的 agent。
这里说的循环(loop),可以理解成一种递归的目标。你先定下一个目的,然后让 AI 一轮一轮地迭代,直到把任务做完。它大致由五个构建块组成,而 Claude Code 和 Codex 这两个工具,现在都已经把这五块凑齐了。
我一直觉得,这很可能就是往后我们和 coding agent 协作的方式。但话要说在前面,现在仍然很早期,我自己对它也保持着怀疑。你得格外留意 token 成本,因为不同的使用模式之间,消耗可能差出好几个量级,尤其取决于你是 token 富裕还是 token 紧张。你也仍然需要某种手段,确保产出的质量不会一路下滑,大家对那种 AI slop 的担忧,完全站得住脚。话虽如此,我们还是先把它讲清楚。
最近有人这样讲。
你不该再去 prompt 那些 coding agent 了。你该做的,是设计一个个循环,让循环去 prompt 你的 agent。
无独有偶,Anthropic 那边负责 Claude Code 的人,也表达过类似的意思。 
我现在已经不直接 prompt Claude 了。我有一套循环在运行,由它们去 prompt Claude,再判断接下来该做什么。我的工作,是写这些循环。
那么这些话,落到实处到底是什么意思。
过去大约两年里,你想让一个 coding agent 替你做事,方式基本就一种,写一段足够好的指令,再把上下文喂够。你输入一段,读它返回的结果,再输入下一段。agent 是一件工具,而你始终握着这件工具,一轮接一轮地用。
这部分工作,某种程度上已经结束了。至少有些人认为,它正在结束。
现在你要构建的,是一个小系统。这个系统会自己发现工作、自己分发工作、自己检查工作、自己记录哪些已经完成,然后自己决定下一步动哪一个。是它去触发一个个 agent,而不再是你亲自上手。
我以前写过一个很接近的概念,叫 harness,可以理解成给单个 agent 配的那套运行环境。harness 是为单个 agent 搭出能跑起来的地基,也就是那个真正把软件造出来的系统。循环工程则架在 harness 之上。它有点像 harness,但它会按时间运行,会派生出一些小帮手,还会自己喂养自己。
真正让我意外的,是这件事现在已经不再是一个工具问题了。
放在一年前,你想做一个循环,得自己写一堆 bash 脚本,再长期维护它。那是你私人的东西,也只有你自己用得动。
可现在,这些能力已经直接内置进产品里了。Steinberger 列出的那几样能力,几乎可以一条一条对应到 Codex app 上,同样,也几乎能一条一条对应到 Claude Code 上。等你回过神来,意识到它们的形状其实是一样的,你就不再纠结到底该选哪个工具,而是开始设计一种循环,让它无论此刻运行在哪个工具里,都依然转得动。
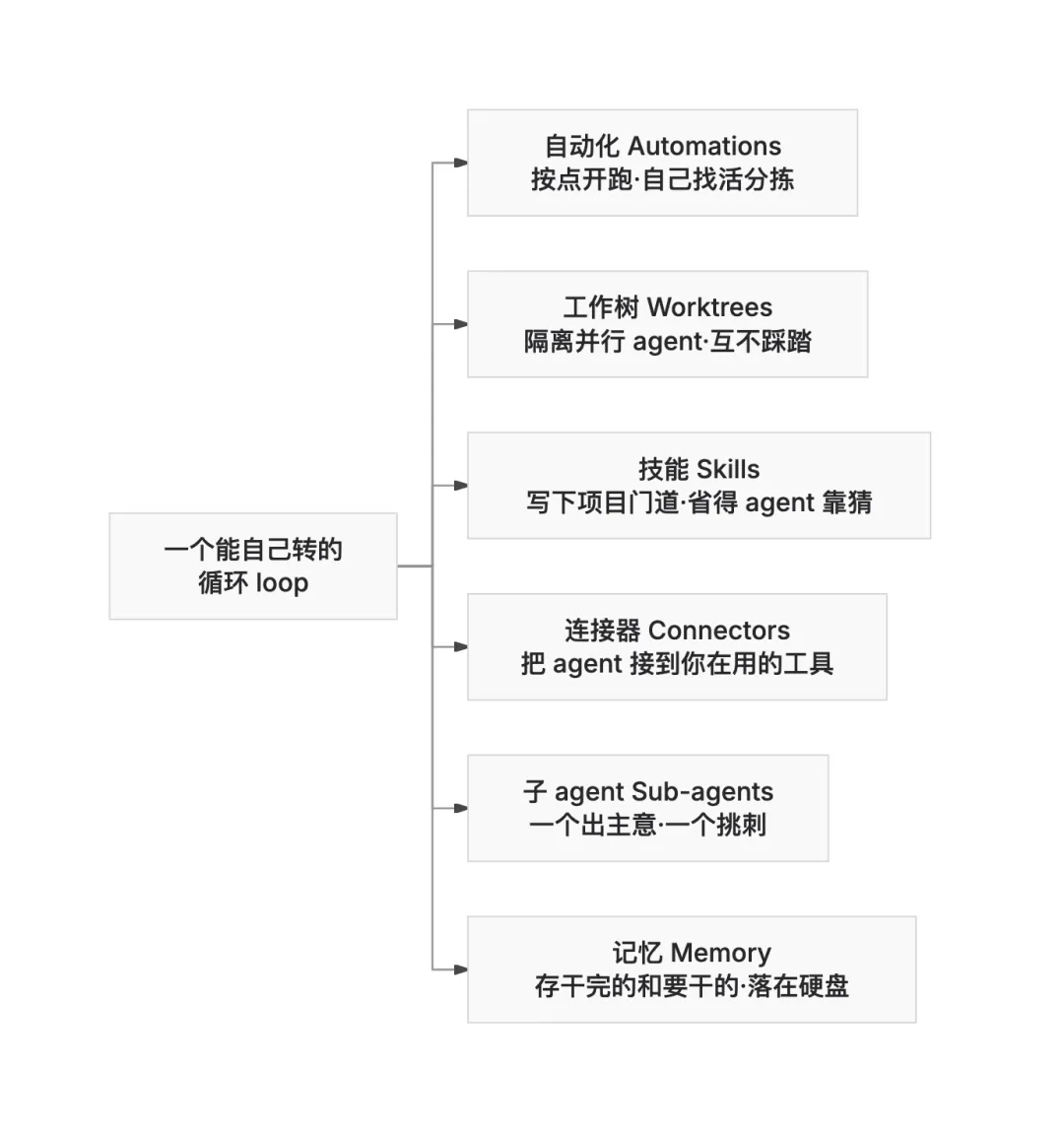
一个循环需要五样东西,外加一个用来记住状态的地方。先把它们列出来,再逐个对应。
自动化(Automations),按计划自动触发,自己做发现和分拣。 工作树(Worktrees),让两个并行工作的 agent 不会互相踩到对方。 skill,把项目知识写下来,省得 agent 靠猜。 插件和连接器(Plugins、connectors),把 agent 接入你已经在用的工具。 子 agent(Sub-agents),让一个 agent 负责提出想法,另一个 agent 负责检查它。
然后是第六样,记忆(memory)。
这个记忆,可以是一个 markdown 文件,可以是一块 Linear 看板,也可以是任何一个存在于单次对话之外、能把已完成的事和接下来要做的事保存住的地方。
它听上去简单得不像个要紧的东西。但它恰恰是每一个长时间运行的 agent 都依赖的同一个窍门。模型在每次运行之间会忘掉一切,所以记忆必须落在磁盘上,而不能只待在上下文里。
agent 会忘记,但仓库(repo)不会。
现在这两个产品,都已经具备了这五项能力。
它们在不同地方的叫法略有出入,但能力的本质是一样的。我们一项一项来看,因为说实话,细节才决定了一个循环到底是真能跑起来,还是会悄悄到处漏水。
自动化(Automations)
自动化这一项,是让循环成为真正的循环、而不是一个只运行一次就结束的任务的关键。
在 Codex app 里,你可以在 Automations 标签页下创建一个自动化。你选好项目、选好它要运行的指令、选好运行的频率,再决定它是在你本地这份代码上运行,还是在后台一个单独的工作树里运行。
那些运行后发现了问题的结果,会进入一个待处理箱(Triage inbox),那些没有发现问题的结果,会自动归档,这一点挺周到。
OpenAI 内部就用它来处理一些枯燥的工作,比如每天的 issue 分拣、汇总 CI 失败的原因、写提交简报、把上周某个人引入的 bug 找出来。
自动化还可以去调用一个 skill,这样重复的任务就更容易维护。你触发的是一个 skill,而不是把一大墙没人会去更新的指令死死贴在日程里。
Claude Code 抵达同一个终点,靠的是定时任务(scheduling)和钩子(hooks)。
你可以用 /loop 按固定间隔反复运行一段指令或一个命令,也可以排一个 cron 定时任务,还可以在 agent 生命周期的某些节点,用钩子去触发 shell 命令。如果你希望它在你合上电脑之后仍然继续跑,干脆把整套东西推到 GitHub Actions 上。
本质完全一样,你定义一个能自主运行的任务,给它一个节奏,然后让发现的结果自己送到你面前,而不是由你满处去检查。
这里还有一对值得了解的就地功能,它们离本文讨论的核心更近。
/loop 会按节奏一遍遍运行。
/goal 则会一直运行,直到你写下的某个条件真正成立。每运行完一轮,会另有一个单独的小模型来检查任务到底完成没有。也就是说,写代码的那个 agent,不是给自己打分的那个。
你可以给它一个条件,比如下面这一句。
test/auth 下所有测试通过,并且 lint 是干净的
然后你就可以走开了。
Codex 也有同样的东西,同样叫 /goal。它会跨多轮持续工作,直到一个可验证的停止条件成立,并且支持暂停、续跑和清空。
同一个功能,两个工具都有。这基本上也是整篇文章反复出现的模式。
所以,这一块负责把工作浮现出来。循环的其余部分,则负责对这些工作采取行动。
工作树(Worktrees)
只要你同时运行的 agent 不止一个,文件就会开始冲突,这会变成一个失败点。
两个 agent 同时改同一个文件,跟两个工程师事先没沟通、却同时往同一段代码上提交是一回事,同样棘手。
git worktree 可以解决这个问题。它是一个独立的工作目录,位于自己的分支上,同时又和其他人共享同一份仓库历史。这样一来,一个 agent 的改动,从字面意义上就不可能碰到另一个 agent 那份代码。
Codex 直接内置了工作树支持,所以多个线程可以同时作用于同一个仓库,而不会互相追尾。
Claude Code 也通过 git worktree 提供了同样的隔离能力。你可以用 --worktree 这个参数,在一份单独的代码里打开一个会话,也可以给子 agent 设上 isolation worktree,让每个小帮手都领到一份新的代码,并在结束后自动清理。
这件事里属于人的那一面,我以前写过。工作树可以把机械层面的冲突移除,但你自己仍然是那个天花板。决定你能同时运行多少个 agent 的,不是工具,而是你审稿的带宽。
技能(Skills)
skill 的作用,是让你不必每开一次会话,都像金鱼一样把同一套项目背景从头解释一遍。
两个工具用的是同一套格式,一个包含 SKILL.md 的文件夹,里面放着说明和元信息,也可以附带脚本、参考资料和素材。
Codex 会在你用 $ 或 /skills 调用时去运行某个 skill,当你的任务与某个 skill 的描述对得上时,它也可能自动调用。这也是为什么一段紧凑、朴素的描述,比一段聪明但含糊的描述更有用。
Claude Code 的做法也是一样的,这个模式我以前也写过。
skill 还是让你的意图不必一遍遍重新付费的地方。
我说过,agent 每开一次会话都是冷启动。只要你的意图里留下哪怕一点空白,它就会用一个相当自信的猜测,把这个空白填上。
skill 就是把这份意图写到外部去,项目里的约定、构建的步骤、那句我们不这么做是因为以前出过一回事故,诸如此类。你只需要写一次,agent 每次运行时都会去读。
没有 skill,循环每转一圈,都要从零把你的整个项目重新推导一遍。
有了 skill,它就开始有一点复利的意思了。
这里有一处区分需要拎清楚,skill 是你撰写它的格式,插件(plugin)才是你分发它的方式。
当你想把一个 skill 跨仓库共享,或者把好几个 skill 打成一包时,你就把它们封装进一个插件里。
Codex 是这样,Claude Code 也是这样。
连接器(Connectors)
一个只看得见本地文件的循环,是一个很小的循环。
连接器构建在 MCP 之上,可以让 agent 去读你的工单系统、查询数据库、调用测试环境的 API、往 Slack 里发消息。
Codex 和 Claude Code 都支持 MCP,所以你为其中一个写的连接器,通常在另一个里也能直接使用。
插件还可以把连接器和 skill 打成一包。这样你的队友只要装上你这套配置,而不必凭记忆把整套东西重新搭一遍。
这就是两种状态之间的区别。一种,是 agent 告诉你,这是修复方案,另一种,是循环自己打开一个 PR、挂上 Linear 工单,并在 CI 变绿之后顺手在频道里 @ 你一下。
连接器,是循环能够在你真实的环境里行动起来的原因,而不只是嘴上告诉你,我要是能做,我会怎么做。
子agent(Sub-agents)
在一个循环里,最有用的一处结构性设计,遥遥领先的那一个,是把动手写的人和回头检查的人拆开。
写代码的模型,在给自己的作业打分时太宽容了。
换一个带着不同指令、有时甚至换用不同模型的第二个 agent,就能逮住第一个 agent 在自我说服之后视而不见的问题。
Codex 只在你提出要求的时候,才会生成子 agent。它们会并行运行,再把结果合并回一个答案。
你可以把自己的 agent 定义成 .codex/agents/ 下的 TOML 文件。每个文件写上名字、描述、指令,外加可选的模型和推理力度。
这样一来,你那个做安全审查的 agent,可以配一个强模型加高推理力度,而你那个负责探路的 agent,可以是某个只读的、运行很快的家伙。
Claude Code 也用 .claude/agents/ 下的子 agent 和 agent 团队做同样的事,让工作在不同 agent 之间传递。
两个工具里常见的拆分方式都是这样。一个 agent 负责探索,一个 agent 负责实现,一个 agent 负责照着规格(spec)去验证结果。
这件事我以前从两个角度都讲过。
它在循环里格外要紧,原因在于循环会在你没盯着的时候运行。所以,一个你真正信得过的验收者,是你敢于走开的唯一理由。
当然,子 agent 会消耗更多 token,因为每一个都要自己跑模型、自己用工具。所以,要把它们花在那些第二个人的意见值这个钱的地方。
这基本上也就是 Claude Code 那个 /goal 在底层做的事,由一个全新的模型来判断循环到底完成没有,而不是由完成工作的那个模型自己说了算。
说到底,生产者和检查者这一拆分,连到底停不停这个判断本身,都被一并拆了进去。
把它们拼到一起
把这些东西粘起来,一个单线程的任务,就会变成一个小小的控制台。
下面是我自己一直在用的一种形状。
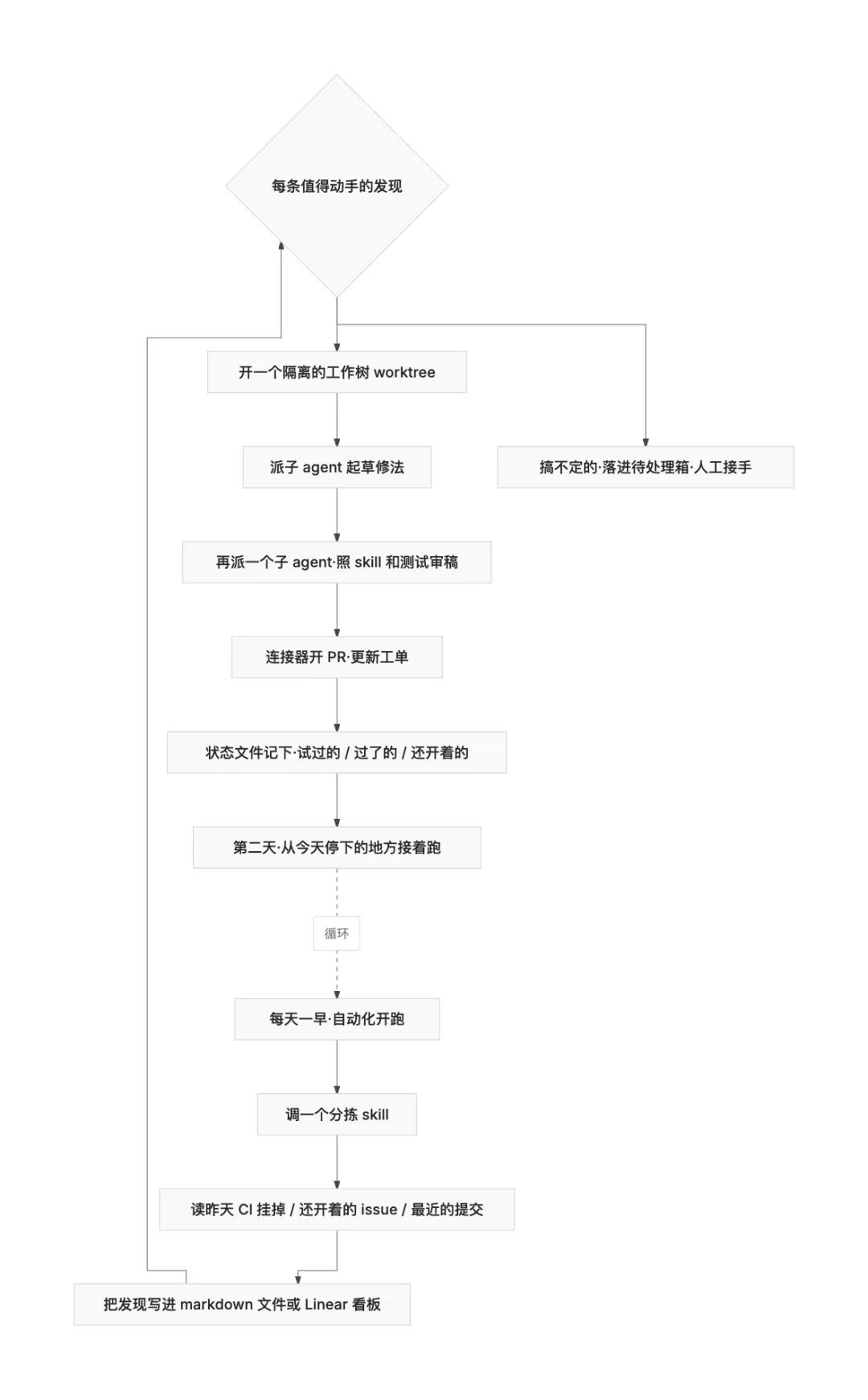
每天一早,一个自动化在仓库上开始运行。
它的指令会去调用一个分拣 skill。这个 skill 会读取昨天 CI 失败的记录、仍然开着的 issue、最近的几次提交,然后把发现写进一个 markdown 文件,或者写进一块 Linear 看板。
对于每一条值得处理的发现,这条线程都会打开一个隔离的工作树,派一个子 agent 去起草修复方案,再派第二个子 agent,照着项目里的 skill 和现成的测试,去审这份草稿。
连接器让循环可以打开 PR、更新工单。
任何循环处理不了的事情,都会落到我的待处理箱里。
那个记录状态的文件,是整套东西的脊柱。它记住了哪些尝试过、哪些通过了、哪些还开着。所以第二天一早的那次运行,可以从今天停下的地方接着走。
看看你到底做了什么。
你只设计了一次。
这中间的每一步,没有一步是你亲手 prompt 的。
这就是 Steinberger 那个观点落地之后的样子。而且不管是在 Codex 里,还是在 Claude Code 里,这都是同一个循环,因为这些零件,原本就是同样的零件。
Loop会改掉工作,但删不掉你
循环会改变工作的方式,但它删不掉你这个人。
而且随着循环越做越好,有三个问题会变得更尖锐,而不是更轻松。
第一,验证这件事,仍然压在你身上。
一个无人值守运行的循环,也是在无人值守的情况下犯错。
你之所以把验收的子 agent 和动手的拆开,就是为了让循环嘴里那句完成,多少有点分量。可即便如此,完成也只是一句声明,而不是一份证明。
有一句话,我一直反复念叨。
你的工作,是交付你确认过、能够运行的代码。
第二,如果你撒手不管,你对系统的理解仍然会腐烂。
循环越快地交付那些不是你亲手写的代码,真实存在的那套系统,和你以为自己理解的那套系统之间的差距就越大。
一个流畅的循环,只会让这个差距增长得更快,除非你真的去读它产出的东西。
第三,最舒服的姿势,很可能也是最危险的姿势。
当循环开始自己运转,你很容易就不再持有自己的判断,它给你什么,你就接受什么。
我把它称作一种危险的状态。
当你带着判断力去设计循环,设计循环就是解药。
当你为了逃避思考去设计循环,它就是加速剂。
同一个动作,会结出相反的果。
这大概是工作方式往后怎么变的一次预演
我认为,这是我们工作方式即将发生的演化的一次预演。
不过,如果我不亲自 review AI 产出的内容,或者完全把问题甩给自动化的循环去修,我的产品质量一定会往下掉。我很可能会滑进一个持续下行的螺旋,自己一铲一铲地把自己往更深的坑里挖。
话虽如此,去把你的循环搭起来吧。
但也别忘了,亲手 prompt 你的 agent 这条老路,到今天仍然有效。关键在于找准那个平衡点。
循环还会因为使用它的人不同,而结出截然相反的果。
两个人可以搭出一模一样的循环,却得到完全相反的结果。
一个人用它,在自己理解得很透彻的工作上跑得更快。
另一个人用它,是为了逃避把工作搞懂这件事本身。
循环分不出这两者的区别。
但你分得出。
这就是为什么,设计循环比写 prompt 更难,而不是更简单。
Cherny 的意思,不是说工作变轻松了。
而是那个用力的支点,挪了位置。
