 夜雨聆风
夜雨聆风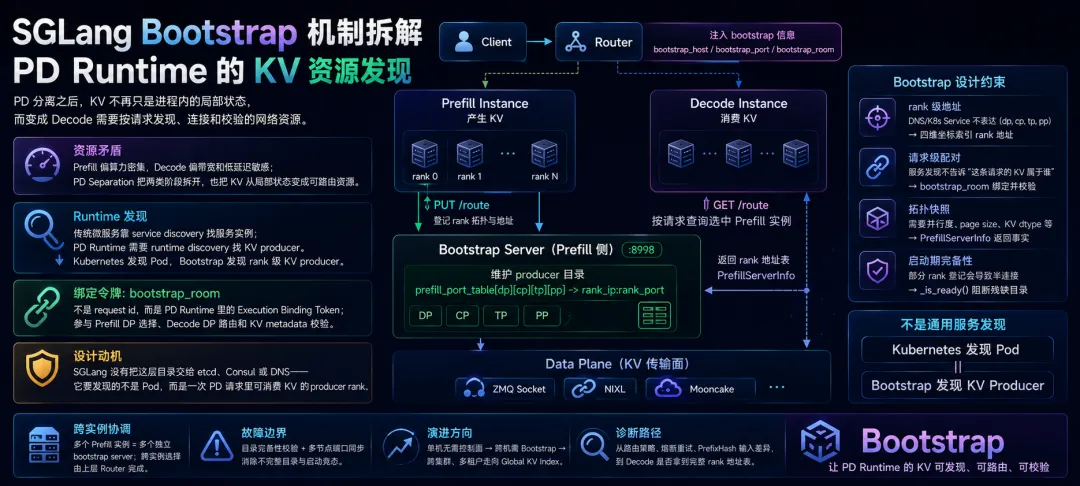
作者介绍:一名正在持续在做大模型统一编排框架(同时支持Dynamo/llm-d/AIBrix/自研)与统一多推理引擎(vllm/sglang/...及多种KVCache后端方案集群方案的工程实践者,当前主要关注并推进统一推理编排层、多后端 serving 抽象、P/D 分离与 runtime 数据面验证。在实践推进过程中,在sglang这个 bootstrap曾绊倒多次,早期HTTP路由认知需要系统性重新系统构建,本文尝试从PD与传统微服务路由出发探究其背后逻辑本质。
继PD 分离之后,KV 不再只是进程内的局部状态,而变成 Decode 需要按请求发现、连接和校验的网络资源。SGLang bootstrap 承担的不是普通启动参数传递,而是 PD Runtime 内部的KV producer 发现:Prefill 侧维护 producer 目录,Decode 侧按请求拉取拓扑和地址,bootstrap_room把 Router 选点、DP 路由和 KV 配对校验串成同一个执行绑定语义。这层目录不是 etcd/Consul/DNS 的等价替代——因为它发现的不是 Pod,而是一次 PD 请求里可消费 KV 的 producer rank。
- 资源矛盾
Prefill 偏算力密集,Decode 偏带宽和低延迟敏感;PD Separation 把两类阶段拆分,也把 KV 从局部状态变成可路由资源。 - Runtime 发现
传统微服务靠 service discovery 找服务实例;PD Runtime 需要 runtime discovery 找 KV producer。Kubernetes 发现 Pod,Bootstrap 发现 rank 级 KV producer。 - 认知坐标
本文分析范围限定在 Prefill 和 Decode 之间的控制面建连,不展开模型执行、调度队列、KV 字节搬运和后端 RDMA 细节。 - 目录边界
CommonKVBootstrapServer工作在 Prefill 侧,默认 HTTP8998,维护prefill_port_table[dp][cp][tp][pp] -> rank_ip:rank_port。 - 绑定令牌
bootstrap_room不是 request id,而是 PD Runtime 里的Execution Binding Token;它同时参与 Prefill DP 选择、Decode DP 路由和 KV metadata 校验。 - 设计动机
SGLang 没有把这层目录交给 etcd、Consul 或 DNS——它要发现的不是 Pod,而是一次 PD 请求里可消费 KV 的 producer rank。 - 数据面分离
HTTP bootstrap 只传拓扑与地址;KV 字节搬运在后续通过 ZMQ socket、NIXL、Mooncake 等传输路径发生。 - 跨实例协调
多个 Prefill 实例 = 多个互不通信的 bootstrap server;跨实例选择由上层 Router 完成,不由 bootstrap server 互相发现。 - 故障边界
_is_ready()通过dp * cp * tp * pp登记完备性阻断残缺目录;多节点端口同步通过 world-rank-0 广播消除 leader 端口竞态。 - 演进方向
单机推理没有独立控制面;跨机 PD 需要 Bootstrap;跨集群、多租户 PD 会走向 Global KV Index,Dynamo 和 llm-d 都在把控制面推向这一层。 - 诊断路径
选不出来不只看负载策略,还要看 worker 池、熔断状态、重试状态码、PrefixHash 的 HTTP/gRPC 输入差异,以及 Decode 是否拿到了完整的 rank 地址表。
PD Separation 源于 Prefill 和 Decode 对 GPU 资源的压力不同,Prefill 阶段一次性处理 prompt,计算密度高、矩阵计算重,吞吐受批处理和算力利用率影响更大;Decode 阶段逐 token 推进,KV 读写频繁,对显存带宽、跨卡通信、尾延迟和流式返回更敏感。
同一套 GPU 同时优化两类阶段会遇到结构性冲突:Prefill 希望把大块 prompt 聚合成高算力利用率,Decode 希望保持小步、低延迟、持续读取 KV。两者共享一个 runtime 时,调度器会在吞吐、延迟和 KV 驻留之间反复折中。PD Separation 把 Prefill 和 Decode 拆成不同执行角色,允许它们使用不同 batch 策略、不同实例形态和不同传输路径。
控制面形态由下面这组关系展开:
Prefill / Decode 资源压力不同-> PD Separation-> KV Producer / Consumer 分离-> KV 成为可路由资源-> Runtime Discovery-> Bootstrap
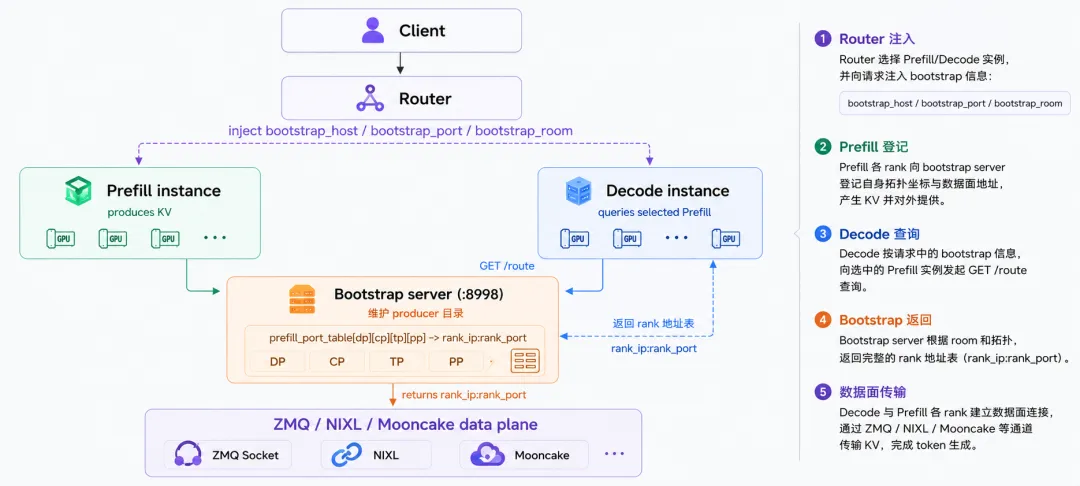
PD 分离推理把一条推理请求拆成两段:Prefill 负责算 prompt 阶段的 KV,Decode 负责后续 token 生成。两段可以在不同进程、不同 GPU、不同节点,甚至不同实例。控制面问题不在 KV 字节怎么通过 NIXL/Mooncake 传输过去,而在 Decode 消费 KV 之前,如何知道“谁生产了这份 KV、该连哪个 rank、如何确认这份 KV 属于当前请求”。
控制面地图如下:
控制面地图包含四条边界:
bootstrap_room做配对校验 |
传统微服务的基础路径通常是:
Service Discovery -> RPC -> Business Logic服务发现解决的是“请求应该打到哪个服务实例”。RPC 负责连接与调用,业务逻辑在服务内部完成。Kubernetes Service、DNS、Consul、etcd 都可以进入这条路径,只是发现粒度、健康语义和一致性代价不同。
PD Runtime 的路径不同:
Runtime Discovery -> KV Routing -> Token ExecutionRuntime Discovery 解决的是“Decode 应该从哪个 KV producer 消费当前请求的状态”。KV Routing 不是普通 RPC 路由,它要把 producer rank、并行拓扑、请求级绑定令牌和数据面连接一起带入执行路径。Token Execution 只有在 KV 到达并通过 metadata 校验后才成立。
Bootstrap 与通用服务发现的差异如下:
Service Mesh 之于微服务,是把服务间调用从应用逻辑中抽离出来;Bootstrap 之于 PD Runtime,则是把KV producer 发现从传输后端中抽离出来。前者让服务调用可治理,后者让跨角色 KV 消费可定位、可重试、可校验。
服务发现层面的常见替代方案包括 etcd、Consul、DNS Service Discovery 和 Kubernetes Service。SGLang 这层 bootstrap 的目标更窄,也更贴近请求执行语义:它发现的不是普通服务实例,而是“某个 Prefill 实例内部,哪个并行 rank 可以作为当前 Decode 的 KV producer”。
这组发现对象带来下面四个约束。
(dp, cp, tp, pp) | prefill_port_tablerank_ip:rank_port | |
bootstrap_room | ||
PrefillServerInfo | ||
_is_ready()dp * cp * tp * pp做目录完整性闸门 |
etcd 或 Consul 可以存这些信息,但会把一个本来实例内、启动期、rank 级的目录问题提升成外部一致性系统问题。SGLang 的 bootstrap 选择把目录放在 Prefill 实例内部,代价是目录单点和重启后重建;收益是依赖少、语义贴近执行路径、调试时能直接用 HTTP 看控制面事实。
DNS Service Discovery 的抽象层级更不够。DNS 能回答prefill-service解析到哪些地址,却无法表达“当前请求由哪个 Prefill DP 处理、Decode 应该连接哪些 TP/PP rank、room 如何进入 KV metadata 校验”。Kubernetes Service 也是同样边界:它擅长做 Pod 入口抽象,不擅长承载一次推理请求内部的 KV producer 拓扑。
Bootstrap 是推理系统内部的runtime service discovery。Kubernetes 发现 Pod,Bootstrap 发现 KV Producer;前者服务于部署入口,后者服务于 request-level execution semantics。
在 SGLang 的 PD 分离推理里,Prefill 和 Decode 不是同一个进程内的两个函数阶段,而是可以分布在不同 worker、不同实例、不同节点上的两类执行角色。Prefill 生成 KV,Decode 消费 KV;中间要解决的第一件事不是“怎么搬”,而是Decode 应该连接哪个 Prefill rank。
源码对象边界如下:
start_disagg_service()-> CommonKVBootstrapServer-> PUT /route # Prefill worker 登记自己-> GET /route # Decode worker 查询拓扑或 rank 地址-> ZMQ / transfer backend # 建立后续 KV 数据面
disaggregation/common/conn.py里的CommonKVBootstrapServer维护四维目录表:
# disaggregation/common/conn.py:941self.prefill_port_table = defaultdict(lambda: defaultdict(lambda: defaultdict(dict)))
目录表的 key 不是抽象实例名,而是并行拓扑坐标:
(dp_rank, cp_rank, tp_rank, pp_rank) -> PrefillRankInfo(rank_ip, rank_port)bootstrap 机制的第一层边界由目录表确定:它只关心单个 Prefill 实例内部每个 rank 的连接地址,不承担全局服务发现,也不维护跨实例一致性。它是只对当前实例负责的私有路由表。
Bootstrap 信息按所在位置和读写方向分成四层,分别对应不同源码路径。
prefill_port_table | common/conn.py:941 | rank_ip:rank_port的目录表 | |
PrefillServerInfo | common/conn.py:49 | ||
bootstrap_host / bootstrap_port / bootstrap_room | managers/io_struct.py:202schedule_batch.py:900 | ||
transfer_engine_info | entrypoints/engine_info_bootstrap_server.py:42 | 6789 |
L1 和 L2 是目录服务的内部状态;L3 是请求携带的路由语义;L4 属于另一个 engine-info bootstrap 服务,主要用于远程实例权重传输,不是 KV 目录表本身。
PrefillServerInfo的价值在于它把 Prefill 侧的并行拓扑暴露给 Decode。Decode 第一次处理请求时通过四个-1参数查询整体拓扑快照,再用try_ensure_parallel_info推算自己应该连接哪些 Prefill rank。并行度对称时这件事不显眼;Prefill 和 Decode 的 TP/CP/PP 组合不一致时,这一步决定了后续连接图是否成立。
Bootstrap server 只有少量 HTTP 端点,但每个端点都承载明确的控制面语义。
/route | rank_ip:rank_port | ||
/route | (dp, cp, tp, pp)的连接地址 | ||
/route | -1时返回PrefillServerInfo | ||
/register_dp_rank | bootstrap_room -> dp_rank | ||
/query_dp_ranks | bootstrap_room对应的 Prefill DP | ||
/health |
/route同时承载“整体拓扑快照”和“具体 rank 地址查询”两种语义。对应到源码里的_handle_route_get,四参全为-1走PrefillServerInfo;否则按四维坐标从prefill_port_table取PrefillRankInfo。
协议职责限定在控制面边界内:HTTP 只负责小体量控制信息。目录服务返回rank_ip:rank_port后,Decode 才用_connect_to_bootstrap_server()建 ZMQ PUSH socket,并通过_register_kv_args把 Decode 端 KV buffer 信息注册给 Prefill。控制面和数据面在这一层分开:HTTP 的可观测性和易调试性留在目录层,KV 搬运交给更贴近 GPU/RDMA 的传输后端。
一条请求从启动到 KV 可消费,运行路径如下:
Prefill worker 初始化-> register_to_bootstrap()-> PUT /route 写入 prefill_port_table-> _is_ready() 检查登记完备性-> Decode 首请求 GET /route(-1,-1,-1,-1) 拉 PrefillServerInfo-> try_ensure_parallel_info 计算 target ranks-> _setup_bootstrap_infos 逐 rank GET /route-> _connect_to_bootstrap_server 建 ZMQ socket-> _register_kv_args 注册 Decode KV buffer-> Prefill 推 KV + metadata-> Decode 按 bootstrap_room 校验并消费 KV
请求路径包含两个运行时约束。
第一,_is_ready()是目录完整性的闸门。源码要求登记数达到:
dp_size * attn_cp_size * attn_tp_size * pp_size登记未完成时查询返回503。这不是普通健康检查,而是为了阻止 Decode 拿到半截目录后建立错误连接。对于分布式系统来说,半成功比失败更难排查;SGLang 选择让目录在不完整时显式失败。
第二,连接信息会被缓存。connection_pool按 bootstrap 地址和 rank 维度缓存拉到的bootstrap_info,_socket_cache按 endpoint 缓存 ZMQ socket。缓存减少了反复查询和建连成本,但也意味着 worker 重启、rank 地址变化、连接失效时要依赖失效和重试路径把状态拉回正确位置。
bootstrap_room不是单纯的 request id,而是 PD Runtime 里的Execution Binding Token。request id 的主要用途是追踪:日志、trace、指标和错误归因围绕它展开。bootstrap_room的用途是绑定:它把一次请求里的 Router 选点、Prefill DP、Decode DP、metadata buffer 和最终 KV 消费绑定到同一个执行语义里。追踪字段辅助定位请求;绑定字段决定系统能不能把正确的 KV 交给正确的 Decode。
这个模式对应 Binding Token Pattern:
bootstrap_room |
在请求协议层,相关字段出现在managers/io_struct.py:202附近:
bootstrap_host: Optional[Union[List[str], str]] = Nonebootstrap_port: Optional[...] = Nonebootstrap_room: Optional[Union[List[int], int]] = None
在 DP controller 里,默认的follow_bootstrap_room_scheduler()使用取模把请求分发到 worker:
# data_parallel_controller.py:584-593target_rank = req.bootstrap_room % len(self.workers) self.workers[target_rank].send_pyobj(req)
Decode 侧在follow_bootstrap_room模式下,也会用同一个整数选择 Prefill DP:
return req.bootstrap_room % prefill_info.dp_size这带来一个强约束:同一请求在 Router、Prefill 和 Decode 三个位置看到的bootstrap_room必须一致,否则 KV 会出现“控制面选点成功、数据面配对失败”的假成功。Prefill 在 metadata buffer 里写入 room,Decode 收到 KV 后用 room 校验配对关系;这一步把路由语义落到了 KV 消费之前。源码里对应的错误字符串形如... corruption detected ... bootstrap_room mismatch(在 decode/metadata 校验路径抛出),说明 room 已经进入执行侧数据校验,而不是只停留在 HTTP 请求字段。
当路由策略不跟随 room,例如外部 round-robin 选择了 Prefill DP,SGLang 需要额外维护room_to_dp_rank。Prefill 处理请求时通过/register_dp_rank登记{bootstrap_room, dp_rank},Decode 再通过/query_dp_ranks反查。这个表带时间戳,并由_cleanup_expired_entries定期清理,防止请求级映射长期膨胀。
单节点里,bootstrap server 监听配置的--disaggregation-bootstrap-port,默认8998。多节点 Prefill 实例里,真实拓扑不是每个节点各起一个目录,而是node0 上的 TokenizerManager 旁边有全实例唯一的 bootstrap server,其他节点的 worker 也要登记到这一个目录。
_sync_bootstrap_port_across_nodes()用来消除这个端口分歧。外部 launcher 可能为每个节点动态预留不同的空闲端口;如果非 leader 节点拿自己的本地端口去连leader_ip:自己的端口,leader 实际监听的是leader_ip:leader_port,结果就是Connection refused,目录表缺行。
源码用 world-rank-0 广播统一端口,所有 rank 最终都使用 leader 的 bootstrap port:
world-rank-0 local_port-> torch.distributed broadcast_object-> all prefill ranks use leader_port-> PUT /route -> leader_ip:leader_port
多机 Prefill 实例仍然只有一个 bootstrap server。它是跨节点实例内部目录,不是跨实例全局服务。
水平扩容时,一个 Prefill 实例对应一个 bootstrap server。两个 Prefill 实例就是两个相互独立的目录;bootstrap server 之间没有 RPC、没有选举、没有同步,也不互相发现。
跨实例选择在 Router 层完成:
Client-> PD Router->select one Prefill instance-> inject bootstrap_host / bootstrap_port / bootstrap_room-> Prefill instance private bootstrap server-> Decode queries that selected server
这层边界直接影响排障路径。Decode 侧的disaggregation_bootstrap_port只是一个端口号配置,不代表 Decode 自己启动了 bootstrap server。Decode 查询的是请求里携带的bootstrap_host:bootstrap_port,也就是 Router 选中的那个 Prefill 实例的私有目录。
因此,多实例场景下的集群调度发生在 Router,而不是 bootstrap server 之间的“一致性协议”:Router 决定请求进入哪个 Prefill 实例,再把那个实例的 bootstrap 地址写入请求。
SGLang 内置的sgl-model-gateway是 Rust 实现的 HTTP Router。在 PD 模式下,一次请求会经过六层:
WorkerRegistry-> PolicyRegistry-> select_pd_pair()-> inject_bootstrap_into_value()-> tokio::join!(prefill.send(), decode.send())-> circuit breaker / retry / record_outcome()
WorkerRegistry把 Prefill 和 Decode 维护成两个池。Prefill worker 还携带bootstrap_port,Router 能从 URL 解析出bootstrap_host,因此它不需要先问 bootstrap server,运行时就能注入请求字段。
PolicyRegistry允许 Prefill 和 Decode 使用不同策略,例如 Prefill 用 CacheAware 抓前缀亲和,Decode 用 PowerOfTwo 平衡队列。策略的共同接口是LoadBalancingPolicy,返回Option<usize>,表示是否选出 worker。
选择层有三道经常触发故障的闸门:
prefill_urlsdecode_urls配置缺失,或类型过滤后为空 | No ... workers available | |
is_available()全 false | all circuits open or unhealthy | |
None |
PowerOfTwo 单实例本身可以返回Some(0),不是“只有一个实例不能选”。选不出来时,优先查池是否为空、角色是否配错、健康检查和熔断状态是否把唯一实例踢掉。
SGLang router 还有一个独立的执行语义:Prefill 和 Decode 是并发双派发。
let (prefill_result, decode_result) = tokio::join!(prefill_request.send(), decode_request.send(), );Router 同时向两侧发送 HTTP 请求,结果分别归因。若 Decode 失败但 Prefill 成功,熔断记录不能把 Prefill 一起打坏;record_outcome要按 worker 真实结果更新。这种逐 worker 归因,是多实例 PD 路由里避免误伤健康节点的关键。
选择层之后还要继续看熔断器、重试执行器和 PrefixHash 输入面。它们决定了“worker 已经配置,Router 仍然选不出来”这类问题的真实归因。
选择层第二道闸门来自is_available()。这个布尔值不是简单健康检查,而是健康状态和 circuit breaker 状态共同作用的结果。一个 worker 连续失败达到阈值后,熔断器打开,Router 会在一段冷却窗口内把它从可选集合里排除;冷却结束后进入 half-open,允许少量探测请求验证恢复状态。
单实例部署对熔断路径尤其敏感:
request failure-> record_outcome(false)-> consecutive_failures reaches threshold-> circuit open-> is_available() = false-> available_workers empty->"all circuits open or unhealthy"
因此,“只有一个实例不能选”通常不是 PowerOfTwo 的语义,而是唯一实例已经被健康检查或熔断器移出候选集。排障时先看 Router 日志里的record_outcome和目标实例/health,再看策略本身。
Router 的 retry 层不是无限重放请求。它受两类边界约束:指数退避和可重试状态码。超时、连接错误、部分 5xx 可以进入重试;业务侧已经进入执行语义的错误不能被无脑重放,否则 Prefill 和 Decode 两侧可能出现重复执行、配对状态漂移或熔断归因污染。
PD 双派发让这个边界更细:Prefill 请求和 Decode 请求是两条独立 HTTP 流,重试和熔断都要按 worker 归因。Decode 失败不能天然证明 Prefill 不健康;Prefill 成功也不能证明 request-level KV 配对完成。Router 层只能证明派发和响应事实,KV 是否被 Decode 消费,还要回到bootstrap_roommetadata 校验。
PrefixHash 和 CacheAware 都试图提高前缀亲和,但它们依赖的输入面不同。HTTP 路由路径下 tokens 可能是None,源码注释指向“use gRPC for PrefixHash”。这意味着纯 HTTP 部署即使配置了 PrefixHash,也可能拿不到足够的 token 前缀输入,最终退化到其他选择逻辑或表现成“策略选不出来”。
排查 PrefixHash 不应只查策略名是否配置成功,还要确认请求路径是否提供 token 级输入:
needs_request_text() | |
None,是否只能拿到文本或完全拿不到前缀 | |
None |
这类问题的表象接近负载均衡失败,实际边界在“策略需要的证据没有进入 Router”。
选择失败按第一阻断点组织成诊断矩阵:
No prefill/decode workers available | prefill_urls/decode_urls和实例启动角色 | ||
all circuits open or unhealthy | /health、record_outcome、熔断冷却时间 | ||
None | needs_request_text() | ||
room -> target ranks -> socket -> metadata检查 |
Dynamo 和 llm-d 的价值不在于改写 SGLang 的 bootstrap 协议,而在于替换更上层的路由决策平面。三者的差异不只是并列表格里的组件名称,而是控制面入口选择:SGLang 是路由入口型,Dynamo 是解码入口型,llm-d 是网关入口型。它们不是同一个 Router 的三种实现。
SGLang router 把 Prefill 和 Decode 都当作被选择的 worker。请求先进入独立 Router,Router 从两个池里分别选出 Prefill 和 Decode,再把相同的bootstrap_room注入两侧请求,并通过tokio::join!并发双派发。
这种拓扑的优点是边界清晰:Router 是入口,worker 是执行者,熔断和负载策略可以在 Router 层集中处理。代价是 Router 要维护两套 worker pool、两套策略、双派发归因和重试语义。它接近传统反向代理加推理语义扩展。
Dynamo 的核心差异是Decode 入口:请求先到 Decode,再由 Decode 或调度层选择 Prefill。它把服务发现、KV-aware 路由和 operator 拓扑整合进自己的控制面,但 SGLang 侧的bootstrap_host、bootstrap_room、KV 搬运协议仍然保留。
解码入口型的好处是入口和生成阶段绑定更紧。Decode 持有客户端连接,也更自然地成为后续 token 流的控制者;Prefill 被选中后接近一次远程预填充服务。代价是路由决策进入 Dynamo 自己的 operator/service discovery 体系,系统形态比 SGLang 内置 Router 更重,但也能承接更强的集群级调度信号。
llm-d 的 EPP 更接近云原生调度器。它通过 Gateway API Inference Extension 和 Envoy ext_proc 把选择逻辑放在网关扩展点上,再通过 KV Cache Indexer 维护跨 pod 的 KV block 索引,用最长连续前缀命中给 pod 排名。它替换的是“选哪个 Prefill/Decode pod”的决策层,不是 SGLang 内部从 Prefill 到 Decode 搬 KV 的机制。
网关入口型的价值在于它把推理路由放进 Kubernetes 网络入口,适合多模型、多租户、多后端的云原生控制面。代价是证据链更长:请求先经过 Gateway/Envoy/EPP,再落到模型服务,KV 命中证据依赖事件管道和全局索引。
三者的分歧可以压缩成一句工程判断:协议层大体相同,控制面入口不同。SGLang router 是路由入口型的本地决策加并发双派发;Dynamo 是解码入口型,把服务发现和 KV-aware 调度收进自身 operator 体系;llm-d 是网关入口型,把决策推进到 Gateway API 和全局 KV 索引。它们都可以复用 SGLang bootstrap,是因为 bootstrap 的边界足够窄:只负责选中 Prefill 实例内部的 KV producer 发现和配对语义。
PD Runtime 的控制面不是一开始就存在。它是 KV 从局部状态变成网络资源之后,被执行路径倒逼出来的结构。
SGLang bootstrap 落在第三代:它解决跨机、跨实例内部 rank 的 producer 发现,但不维护全局 KV block index。Dynamo 和 llm-d 更接近第四代方向:前者把服务发现、KV-aware 调度和 operator 体系合并到 Decode 入口;后者把 Gateway API、EPP 和 KV Cache Indexer 放到集群入口,试图让路由决策看到跨 pod 的 KV 状态。
控制面演进同时限定了 Bootstrap 的边界。它不是 Global KV Index,也不是多租户调度器;它是跨机 PD 阶段必须出现的最小 runtime discovery 层。第四代控制面可以替换上层入口,但仍然要在某个位置回答同一个问题:当前 Decode 应该从哪个 producer 消费 KV。
Bootstrap 的故障大多不是“算法错误”,而是控制面事实没有对齐。
PUT /route失败 | register_to_bootstrap() | |
GET /route返回503 | _is_ready() | |
_sync_bootstrap_port_across_nodes() | ||
/register_dp_rank/query_dp_ranks建立请求级反查 | ||
_cleanup_expired_entries | ||
bootstrap_room校验 | ||
try_ensure_parallel_info | ||
all circuits open or unhealthy | is_available() | |
这些失败模式有一个共同点:控制面成功不等于执行语义成立。PUT /route成功只说明某个 worker 登记进目录;GET /route成功只说明 Decode 拿到了地址;ZMQ socket 建立成功也只说明通道连上。只有 Prefill 生成的 KV 带着正确 room 到达 Decode,并通过 metadata 校验,request-level 的 KV 配对才算成立。
证据面由两类来源支撑:SGLang 源码中的运行时检查点,以及我们统一编排Runtime 验证工作里使用的 evidence level 方法论。Bootstrap 的证据链沿用 KVCache 验证里的分层口径——register / resolve / connect / verify 四段不能收缩成一个“连接成功”,每层证明的对象不同,缺少哪一层,结论就停止于在哪一层。
| register | common/conn.pyregister_to_bootstrap()与_handle_route_put();payload 含attn_tp_rank / attn_cp_rank / attn_dp_rank / pp_rank / rank_ip / rank_port | ||
| resolve-topology | _is_ready()503 Prefill server not fully registered yet | ||
| resolve-rank | _handle_route_get()_setup_bootstrap_infos()、_get_bootstrap_info_from_server();-1查询拿PrefillServerInfo,具体 rank 查询拿PrefillRankInfo | ||
| connect | _connect_to_bootstrap_server() | ||
| verify | ... corruption detected ... bootstrap_room mismatch | bootstrap_room已进入执行侧校验,而非只停留在路由字段 | |
| consume |
真实运行环境里的证据采集顺序如下:
PUT /route registered # register-> GET /route(-1,-1,-1,-1) PrefillServerInfo # resolve-topology-> GET /route(dp,cp,tp,pp) PrefillRankInfo # resolve-rank-> socket / transfer backend connected # connect-> metadata bootstrap_room == request bootstrap_room # verify-> Decode consumes KV, request completes # consume
Mooncake、NIXL、Mori、Ascend、Fake 后端共享同一套 bootstrap server 抽象,差异主要在后续传输层。
MooncakeKVBootstrapServer | ||
NixlKVBootstrapServer | ||
MoriKVBootstrapServer | ||
AscendKVBootstrapServer | ASCEND_MF_STORE_URLconfig store | |
FAKE_BOOTSTRAP_HOST="2.2.2.2",room 可自增 |
bootstrap 的核心不是某个传输后端的私有协议。后端决定 KV 如何搬,bootstrap 决定 Decode 如何拿到 Prefill rank 的地址,以及请求如何保持配对语义。
Decode 如何取信息,和 Prefill 跨机如何同步,是两个独立平面。它们共享同一个 bootstrap server 和同一个prefill_port_table,但方向、时机和协议都不同。
(ip, port)收拢成 4D 表 | _sync_bootstrap_port_across_nodes()register_to_bootstrap() | ||||
_get_bootstrap_info_from_server()_setup_bootstrap_infos() |
Decode 不预先保存所有 Prefill 地址。Router 把bootstrap_host / bootstrap_port / bootstrap_room注入请求后,Decode 才构造CommonKVReceiver,并形成bootstrap_addr = host:port。随后它先用四个-1查询PrefillServerInfo,拿到 Prefill 的 TP/CP/DP/PP 拓扑、page_size、kv_cache_dtype等信息。
拿到拓扑快照后,Decode 调try_ensure_parallel_info计算目标 rank 集合,再由_setup_bootstrap_infos()按笛卡尔积逐个查询具体地址:
GET /route?prefill_dp_rank=dp&prefill_cp_rank=cp &target_tp_rank=tp &target_pp_rank=pp -> PrefillRankInfo(rank_ip, rank_port)这些结果进入connection_pool。缓存命中时,后续请求不需要重新走完整 GET 矩阵。_connect_to_bootstrap_server()把rank_ip:rank_port转成tcp://ip:port并建立 ZMQ socket;KV 字节搬运再交给 Mooncake/NIXL 等后端。
这个平面是“读目录”:Decode 主动读,bootstrap server 被动返回。
跨多机的 Prefill 实例里,leader 不是运行时选举出来的,而是启动时由 launcher 静态指定:torchrun 路径里是--node-rank=0与MASTER_ADDR/MASTER_PORT,Ray 路径里是rank0_node_ip。同一个dist_init_addr既是 torch.distributed rendezvous 地址,也是 bootstrap server host 的来源。
这让同步过程天然对齐:
dist_init_addr-> torch.distributed world group rendezvous-> world-rank-0 broadcasts bootstrap port-> every prefill rank PUT /route to leader_ip:leader_port-> leader fills prefill_port_table[dp][cp][tp][pp]
_sync_bootstrap_port_across_nodes()通过world_group.broadcast_object(local_port, src=0)把 rank0 的 bootstrap port 广播给所有 rank,消除每台机器各自预留本地端口带来的Connection refused。随后每个 rank 调register_to_bootstrap(),把自己的attn_tp_rank / attn_cp_rank / attn_dp_rank / pp_rank / rank_ip / rank_port写进 leader 上的 4D 表。
这个平面是“写目录”:Prefill 各 rank 主动写,leader bootstrap server 汇总。
多机内部同步和多 Prefill 实例扩容经常被混在一起。它们是正交关系:
prefill_port_table |
Router 管“选哪个实例”;平面 A 管“选定实例内部各 rank 怎么汇表”;平面 B 管“Decode 怎么读那张表”。这三个层次分开后,bootstrap 问题的排查路径更短。
Bootstrap 的工程收益来自边界窄,扩展性风险也来自同一个事实。当前实现更接近一张 leader memory table:每个 Prefill 实例维护自己的prefill_port_table,多节点通过 world-rank-0 端口同步把所有 rank 写到同一张表,跨实例选择交给 Router。
这个形态适合单个 Prefill 实例内部的 rank 发现,同时也暴露出放大边界:
connection_pool缓存 | |||
_is_ready()保证完整性 | |||
llm-d 的 KV Cache Indexer、Dynamo 的 operator/service discovery 体系,价值不在于“替代一个 HTTP 目录”,而在于把可见范围从单 Prefill 实例内部扩大到集群控制面。Bootstrap 负责实例内 producer discovery;Global KV Index 负责跨实例、跨 pod、跨后端的 KV resource discovery。两者不是同一层对象。
Bootstrap = Runtime Service Discovery for KV Producers普通服务发现解决“请求应该打到哪个服务实例”;Bootstrap 解决“Decode 应该从哪个 Prefill rank 消费这条请求的 KV”。前者通常发生在部署入口,后者发生在一次推理请求的执行路径内部。
(dp, cp, tp, pp) |
这些源码对象共同指向同一个抽象:prefill_port_table是 KV producer index,PrefillServerInfo是 producer topology snapshot,bootstrap_room是 request-level binding token,_is_ready()是 producer index completeness gate。HTTP 是控制面载体,ZMQ/NIXL/Mooncake 是拿到 producer 地址之后的数据面。
SGLang bootstrap 不是 Mooncake 或 NIXL 的附属机制,而是 PD 架构中一层独立的内部服务发现协议。PD 分离推理的难点不只在“把 KV 搬快”,还在“把一次请求里的生产者、消费者和拓扑事实绑定正确”。Prefill 和 Decode 被拆到不同实例、不同节点、不同并行拓扑后,这层 runtime discovery 会以某种形式存在。SGLang 选择了实例内 HTTP 目录,Dynamo 和 llm-d 选择在更上层替换路由决策,但它们仍然要解决同一个问题:Decode 消费的 KV 对应哪个 producer。
PrefillServerInfo | common/conn.py:49 | ||
PrefillRankInfo | common/conn.py:80 | rank_ip:rank_port | |
prefill_port_table | common/conn.py:941 | ||
room_to_dp_rank | common/conn.py:944 | ||
transfer_engine_info | engine_info_bootstrap_server.py:42 | ||
bootstrap_host/port/room | io_struct.py:202 | ||
register_to_bootstrap() | common/conn.py:368 | PUT /route | |
_get_bootstrap_info_from_server() | common/conn.py:836 | GET /route | |
_setup_bootstrap_infos() | common/conn.py:780 | ||
_sync_bootstrap_port_across_nodes() | common/conn.py:338 | ||
_connect_to_bootstrap_server() | common/conn.py:890 | ||
follow_bootstrap_room_scheduler() | data_parallel_controller.py:584 | ||
try_ensure_parallel_info | common/conn.py:~300 |
单机推理里,KV 是局部状态;PD Runtime 里,KV 是可路由资源。Bootstrap 的职责,就是让 Decode 找到这份资源的拥有者,并在消费之前确认它属于当前请求。
目录服务的边界限定在实例内部:Prefill worker 登记,Decode 查询,_is_ready()保证表完整,端口同步保证多节点都写入同一张表。执行绑定令牌贯穿请求路径:Router 生成或传递bootstrap_room,DP Controller 用它取模,KV metadata 用它校验。跨实例调度进入 Router、Dynamo 或 llm-d 这类上层控制面,bootstrap server 本身不做集群协调。
HTTP 目录让控制面可观测、可重试、可定位;ZMQ/RDMA/Mooncake/NIXL 让数据面保持高性能路径。代价是 bootstrap server 成为单 Prefill 实例内部的目录单点,多节点部署还要处理 leader 地址和端口同步。排障时要沿bootstrap_host -> prefill_port_table -> target ranks -> socket -> metadata room确认 request-level 的 KV 配对是否闭合;如果请求在 Router 层已经选不出来,再沿worker pool -> is_available/circuit breaker -> policy input -> retry定位。
所有 PD Runtime 最终都会出现某种 Runtime Discovery 层,入口可以是 Router、Decode 或 Gateway,索引可以从实例内 memory table 演进到全局 KV index,但问题不会消失:Prefill 和 Decode 被拆开之后,系统必须重新建立 request-level 的执行绑定。
