 夜雨聆风
夜雨聆风不需要编程基础,跟着步骤走就能搞定。
为什么要用本地AI?
为什么要用本地AI!
在学术科研场景里,我们经常需要处理一些不能上传到云端的文件——未发表的论文草稿、实验数据、商业合同、保密报告……
这些内容用 ChatGPT 或 Claude 处理,数据会经过境外服务器,存在隐私泄露风险,很多单位和学校也明确禁止。
本地AI完美解决这个问题:模型完全运行在你自己的电脑上,文件从不离开本机,断网也能用,天然符合数据安全要求。 除此之外还有几个好处:
不需要翻墙,网速再差也不影响 不限次数,用多少都不花钱 一次部署,长期使用
本教程结束后,你能得到这样一个效果:双击一个脚本,自动弹出菜单选择模型,打开浏览器就能聊天,体验和 ChatGPT 几乎一样。
准备工作
硬件要求
配置 最低要求
显卡显存 6GB 以上(越大越好)
内存 16GB 以上
硬盘 至少 20GB 空余空间
系统 Windows 10/11
没有独立显卡也能跑,但速度会很慢。有 N 卡(NVIDIA)体验最好。
第一步:安装 Python 3.11
打开 https://www.python.org/downloads/,下载 Python 3.11
(注意不要下 3.12 或 3.13,Open WebUI 目前只支持 3.11)。
安装时 一定要勾选 "Add Python to PATH",否则后面的命令都跑不起来。
第二步:安装 llama.cpp
llama.cpp 是跑本地模型的"引擎",负责把模型加载到显卡上运行。
打开 https://github.com/ggml-org/llama.cpp/releases 找到最新版本,下载 llama-*-bin-win-cuda-cu12.x.x-x64.zip(N 卡选这个)
解压到 E:\AI\llamacpp\ 文件夹
如果你没有 N 卡,下载
llama-*-bin-win-noavx-x64.zip用 CPU 跑。
第三步:安装 Open WebUI Open WebUI 是我们和模型对话的界面,长得很像 ChatGPT。
按 Win + S 搜索「PowerShell」打开,输入:
pip install open-webui等它安装完成(可能需要几分钟)。
如果提示找不到 pip,说明第一步的 Python 没有正确安装,回去重装一遍。
第四步:下载本地模型 模型是 AI 的"大脑",我们用魔搭社区(国内访问速度快)下载。 首先安装下载工具:
pip install modelscope然后创建一个模型存放文件夹 E:\AI\models\,再运行下载命令: 推荐新手先下这个(中文效果好,14B 参数):
modelscope download Qwen/Qwen3-14B-GGUF --include "*Q4_K_M*" --local_dir E:\AI\models文件大小约 9GB,下载时间取决于网速,耐心等待。
Q4_K_M 是什么? 这是量化格式,把模型压缩到原来的 1/4 大小,质量损失极小,是性价比最高的选择。
第五步:使用一键启动脚本 每次手动输命令太麻烦,我做了一个菜单式启动脚本,双击就能用。
下载地址: https://github.com/Monay69/local-ai-launcher 下载 启动AI.bat,放到 E:\AI\ 文件夹里。 最终你的文件夹结构应该是这样:
E:\AI\├── llamacpp\ ← 第二步解压的文件│ └── llama-server.exe├── models\ ← 第四步下载的模型│ └── Qwen3-14B-Q4_K_M.gguf└── 启动AI.bat ← 刚下载的脚本开始使用 双击 启动AI.bat,会弹出这样的菜单:
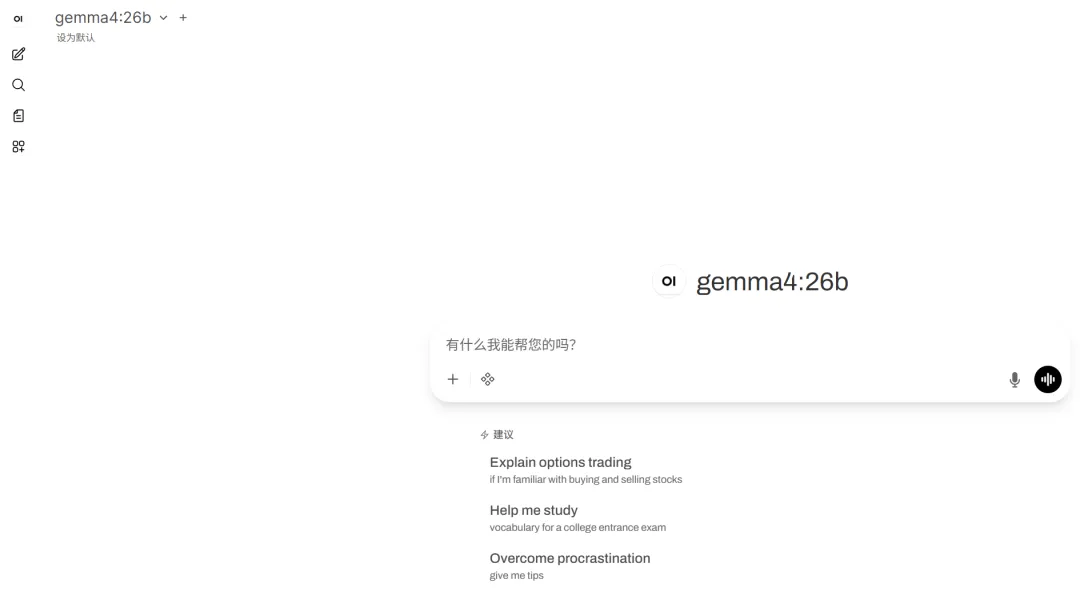
============================================ AI 本地模型启动菜单============================================ 检测到以下模型: [1] Qwen3-14B-Q4_K_M.gguf [0] 退出请输入数字后按回车:输入 1 回车,等待约 1 分钟加载完成,然后打开浏览器访问:
http://localhost:8080就能看到和 ChatGPT 一样的对话界面了!
常见问题
Q:显示"无法连接到 Anthropic 服务"怎么办?
A:这是下载 Open WebUI 时触发的,不影响本地模型使用,忽略即可。
-----------
Q:加载很慢怎么办?
A:检查启动命令里有没有 --n-gpu-layers 99,这个参数让模型跑在显卡上,少了它就会用 CPU,速度会慢很多。
-----------
Q:需要安装 Git、Node.js 或 npm 吗?
A:完全不需要。本教程所有工具都直接下载或用 pip 安装,不依赖 Git 或 Node 环境。
-----------
Q:pip install open-webui 提示找不到安装包?
A:Python 版本不对,Open WebUI 要求 3.11 以上。用 python --version 确认版本,再用 py -3.11 -m pip install open-webui 指定版本安装。
-----------
Q:我电脑上装了两个 Python 版本怎么办?
A:Open WebUI 只支持 Python 3.11,如果你同时装了 3.10 或其他版本,安装时要指定用
3.11:--py -3.11 -m pip install open-webui
启动时也用:--py -3.11 -m open_webui serve
-----------
Q:下载模型时提示"Repo not exists"?
A:模型名写错了。注意是 Qwen3-14B-GGUF 不是 Qwen3.5-14B-GGUF,Qwen3.5 目前没有 14B 版本。
-----------
Q:模型跑起来了但速度很慢?
A:大概率是 --ctx-size 设太大导致显存溢出,模型一部分跑在内存上。把它调小到 8192 或 16384 再试,速度会明显提升。
-----------
Q:启动时报错 unknown value for --flash-attn?
A:这个版本的 llama.cpp 需要给参数加上值,写成 --flash-attn on 而不是单独的 --flash-attn。
-----------
Q:Open WebUI 打开后模型列表是空的?
A:llama-server 没有启动,或者端口配置不对。确认 llama-server 已经在运行,并且 Open WebUI 里填的地址是 http://localhost:8081/v1
写在最后,整个过程我自己也踩了不少坑,比如 --flash-attn 参数格式、Python 版本问题、显存溢出导致速度慢等等,都在上面的教程里帮你避开了。
如果遇到问题,欢迎在评论区留言,我看到会回复~ 觉得有帮助的话点个赞和在看,让更多人能用上本地 AI 🙌
