 夜雨聆风
夜雨聆风
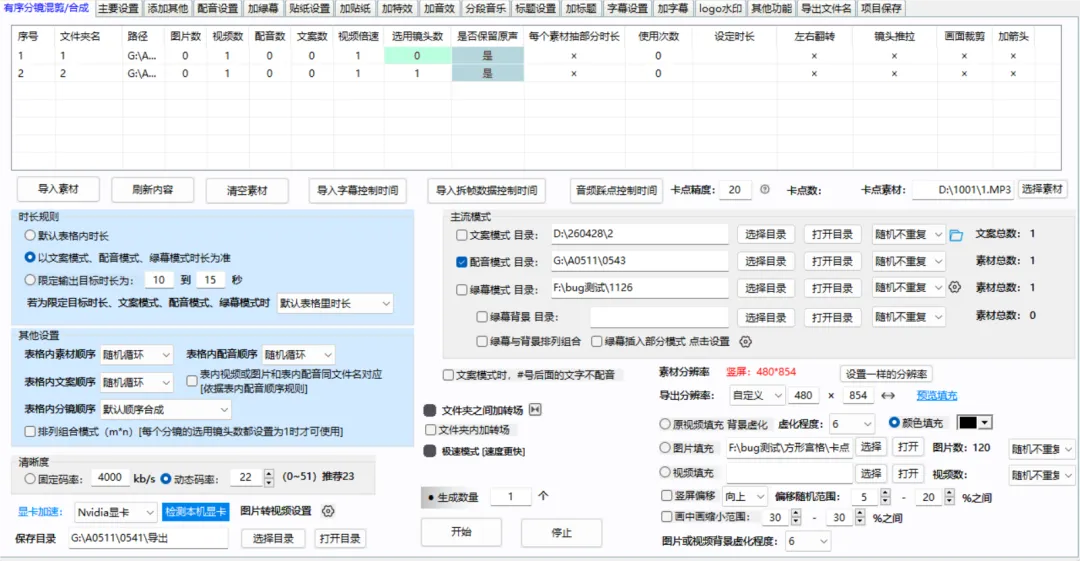
有序分镜组合界面:
功能所在位置:
很多用户第一次接触“按音频时长合成视频”时,会把它理解成一个简单的拼接功能。
其实它做的事情要多得多。
它需要判断音频有多长,素材够不够,文件夹顺序是什么,图片要转成几秒视频,视频是否要裁剪,画面是否要变速,字幕是否要生成,多个场景如何拼接,最后成片怎样和声音对齐。
如果把它拆开看,它更像是一套自动剪辑引擎:用音频时长作为时间轴,用文件夹作为分镜单位,用规则决定素材抽取和画面处理方式。
下面我们从软件运行逻辑的角度,把这个功能完整讲清楚。
1. 输入层:软件先读取素材、音频和文案
合成开始之前,软件需要先读取输入内容。
输入内容主要包括四类:
·视频素材
·图片素材
·音频素材
·文本文案
视频和图片负责提供画面。音频负责提供时长和声音。文案可以通过自动配音变成音频,再参与后续合成。
在有序分镜组合中,这些输入通常被放在多个编号文件夹里。在无序混剪合成中,这些输入可以作为一个整体素材池来使用。
软件第一步不是立刻拼视频,而是先弄清楚:当前任务有哪些素材、哪些音频、哪些文案,以及它们属于哪个场景。
2. 结构层:判断是有序分镜,还是无序混剪
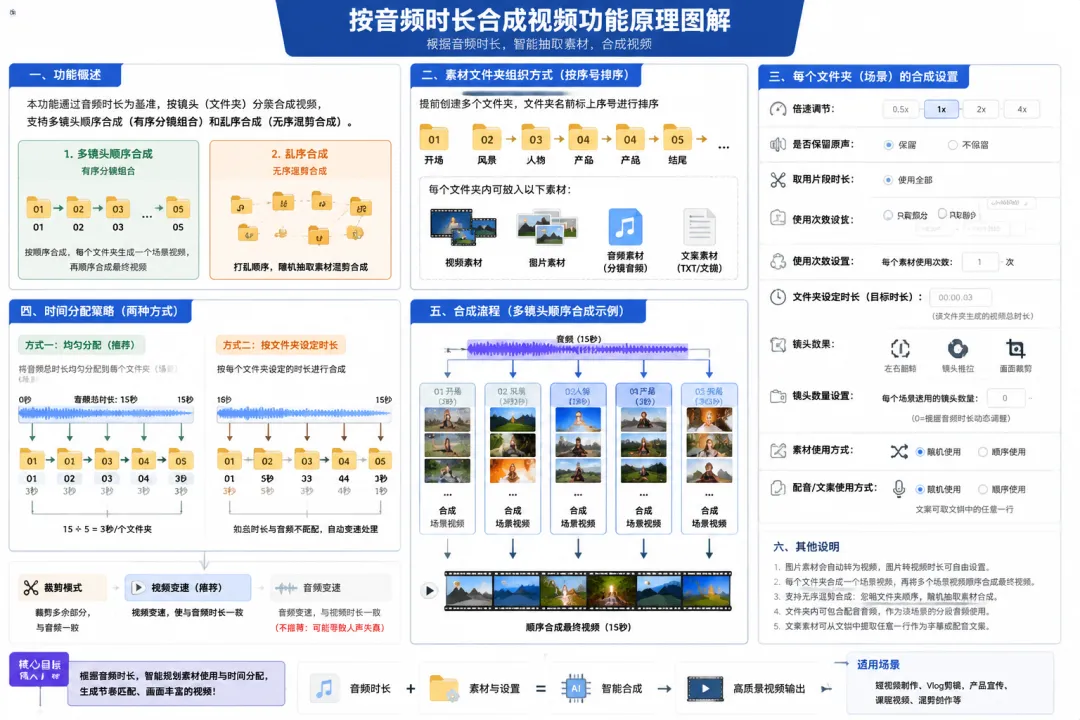
接下来,软件会根据用户选择的模式确定合成结构。
如果选择有序分镜组合,软件会按照文件夹前面的序号进行排序。
例如:
01 开头02 展示03 讲解04 结尾
软件会把这些文件夹识别为多个连续场景。每个文件夹先单独生成一个场景视频,然后再顺序拼接。
这种模式强调结构。它适合有明确剧情顺序、讲解顺序、展示顺序的视频。
如果选择无序混剪合成,软件就不会要求严格分镜顺序。它会从素材池中抽取素材,根据音频时长合成一条视频。
这种模式强调效率和变化。它适合快速混剪、批量出片、背景画面生成等场景。
所以,有序分镜解决的是“按顺序讲清楚”。无序混剪解决的是“快速生成不同画面组合”。
3. 时长层:找到视频合成的时间基准
按音频时长合成视频,最核心的一步是确定时间基准。
时间基准可能来自三种来源。
第一种,来自总音频。比如用户选择了一段30 秒音频,软件就以这 30 秒作为最终成片的目标时长。
第二种,来自分镜音频。在有序分镜里,每个文件夹可以放自己的音频。比如第一个文件夹音频3 秒,第二个文件夹音频 5 秒,第三个文件夹音频 7 秒。软件就会分别按这些音频长度生成对应场景。
第三种,来自文案自动配音。如果文件夹里放的是文档,软件可以取出文案,生成配音。配音生成后,软件再读取这段配音的实际时长,把它作为场景合成的目标。
也就是说,时长不一定是用户手动填写的,它可以从音频中来,也可以从文案配音后自动得到。
4. 分配层:总时长如何分给不同文件夹
当视频包含多个分镜文件夹时,软件需要决定每个文件夹负责多少时长。
这里有两种常见策略。
策略一:平均分配
假设总音频是15 秒,文件夹有 5 个。
软件可以把15 秒平均分成 5 份,每个文件夹 3 秒。然后每个文件夹根据 3 秒目标时长抽取素材并生成画面。
这种策略适合节奏均匀的内容。它的好处是简单、稳定、容易理解。
图片素材会自动转成视频,图片持续时间可以设置。视频素材可以按需要截取片段,或者通过速度调整来贴合目标时长。
策略二:按文件夹自身规则生成
另一种方式是每个文件夹按自己的规则来。
比如:
·第一个文件夹设置2 秒
·第二个文件夹设置6 秒
·第三个文件夹设置4 秒
·第四个文件夹设置3 个镜头
软件会先按照各自设置生成每个场景。这样可以让不同场景拥有不同长度和不同画面密度。
如果所有场景拼接后和音频不一致,再进入最终对齐步骤。
这种策略更灵活,适合内容结构不均匀的视频,比如重点功能展示、教程步骤说明、产品细节讲解等。
5. 抽取层:软件决定每个场景用几个素材
确定目标时长之后,软件要开始抽取素材。
这里有一个关键设置:每个场景选用的镜头数量。
如果镜头数量设置为0,代表由软件动态判断。软件会根据音频时长、图片转视频时长、视频片段长度等因素,自动决定需要几个素材。
例如一个场景只有2 秒,可能 1 个素材就够。一个场景有12 秒,可能需要多个视频或图片来组合,画面才不会单调。
如果镜头数量设置为非0,比如 2、3、4,软件就按指定数量抽取素材。
这种方式适合用户想固定画面结构的情况。比如每个场景必须出现3 个镜头,或者某个分镜只允许用 1 个核心素材。
镜头数量为0,是智能规划。镜头数量为具体数值,是人工约束。
这两个方式可以结合使用,让不同场景拥有不同程度的自动化。
6. 规则层:素材怎么用,不是完全随机
自动合成并不等于素材乱用。
软件可以根据用户设置决定素材使用方式。
素材可以随机使用,也可以顺序使用。配音可以随机使用,也可以顺序使用。文件夹可以设置使用次数。单个素材也可以设置使用次数。
随机使用适合批量生成多个版本。顺序使用适合教程、步骤、对比、流程类内容。
使用次数设置可以控制素材重复率。如果某个素材只想出现一次,就可以限制它的使用次数。如果某个文件夹需要多次参与生成,也可以设置文件夹使用次数。
这套规则让自动合成既有变化,又有边界。
7. 处理层:抽到素材后,还要做画面加工
素材被选中之后,软件还会根据设置对画面进行处理。
对于视频素材,可以:
·只取其中一部分时长
·调整播放倍速
·保留或关闭原声
·左右镜像翻转
·进行画面裁剪
·添加镜头推拉效果
·添加箭头或提示元素
对于图片素材,可以:
·自动转成视频片段
·设置图片展示时长
·添加推近或拉远效果
·参与字幕和音频对齐
这些处理决定了最终成片是否像真正剪过,而不是简单堆素材。
特别是图片转视频和镜头推拉,对图文类视频很重要。静态图片如果只是停在那里,会显得单调;加上合适的时长和动态效果后,就更像一段完整视频。
8. 对齐层:当视频和音频长度不一致时怎么办
自动合成时,视频和音频不可能每次天然一致。
比如音频15 秒,素材合成出来 16.8 秒。或者音频20 秒,画面只拼到了 18 秒。
这时软件可以使用不同方式对齐。
第一种是裁剪。如果视频长了,可以裁掉多余部分,让成片长度接近音频。
第二种是视频变速。让视频播放速度变快或变慢,从而匹配音频时长。
第三种是音频变速。让音频速度变化,从而匹配视频时长。
实际使用中,通常更推荐视频变速匹配音频。因为音频里如果有人声,变速很容易影响听感;画面轻微变速往往更自然。
这一步是整个功能里非常重要的部分,因为它保证了最终成片不会出现明显的声画错位。
9. 字幕层:文案和配音可以自动变成字幕
如果使用文档文案生成配音,软件还可以进一步生成字幕。
字幕不是必须开启的。用户可以选择加字幕,也可以选择不加。
开启字幕后,视频会更适合知识讲解、口播、商品介绍、教程说明等场景。关闭字幕后,画面会更干净,适合纯混剪、氛围视频、背景视频等内容。
文案、配音、字幕之间可以形成一条自动链路:
文案决定说什么。配音决定声音时长。时长决定画面怎么抽取。字幕负责把内容显示出来。
这样,用户不需要把文案、配音、字幕和画面分开处理。
10. 输出层:场景视频先生成,最终视频再合成
在有序分镜组合中,软件通常会先生成多个场景视频。
例如:
01 文件夹生成第一段场景视频。02 文件夹生成第二段场景视频。03 文件夹生成第三段场景视频。
然后这些场景视频再按序号拼接,形成完整视频。
这种方式的好处是结构清晰。每个场景可以独立配置,最终又能组合成完整内容。
在无序混剪合成中,软件则会直接围绕总音频时长抽取素材,生成最终成片。它不强调分段结构,更强调快速组合和版本变化。
总结:这是一套围绕“时间”的自动剪辑系统
按音频时长合成视频,本质上不是一个简单拼接功能,而是一套围绕时间规划的自动剪辑系统。
它先识别声音或文案配音的时长,再判断视频结构是有序分镜还是无序混剪。接着,它根据文件夹规则、镜头数量、素材使用方式、图片转视频时长、视频裁剪和变速策略,生成和音频尽可能匹配的视频。
它能处理:
·多文件夹顺序分镜
·无序素材混剪
·音频时长自动读取
·文案自动配音
·字幕自动生成
·图片自动转视频
·视频倍速和裁剪
·原声保留或关闭
·随机或顺序抽取素材
·文件夹和素材使用次数控制
·画面翻转、推拉、裁剪、箭头提示
对于用户来说,不需要每次都手动计算每段视频要多长,也不需要反复拖动素材去对齐音频。只要把素材和规则准备好,软件就能根据声音自动规划画面。
这就是按音频时长智能合成视频的真正意义:用规则代替重复操作,用音频驱动画面生成,让复杂的视频批量合成变得更可控、更稳定,也更高效。
