 夜雨聆风
夜雨聆风
一、 大语言模型在软件安全领域的发展背景与研究价值
(一)传统恶意软件分析的技术瓶颈
1. 恶意软件演化带来的检测压力
(1)随着恶意软件的复杂度与迭代速度持续提升,传统基于特征码的检测方法难以跟上威胁演化节奏,对多态、变形、加壳混淆的恶意样本识别能力不足。
(2)传统静态分析高度依赖人工特征工程,对新型零日威胁的泛化能力有限;动态分析受限于沙箱环境,易被反调试、反沙箱技术规避。
2. 逆向工程的效率瓶颈
(1)绝大多数恶意程序以编译后的二进制形式分发,无源代码可用,安全人员需依托反汇编、反编译工具手动还原逻辑,耗时久、技术门槛高。
(2)混淆、加壳等规避技术的普及,进一步提升了逆向分析的难度,传统工具对高度混淆的二进制文件解析准确率不足。
(二)大语言模型的技术基础与适配潜力
1. 大语言模型的核心技术特性
(1)大语言模型基于 Transformer 架构与自注意力机制构建,在大规模文本与代码语料上预训练,具备强大的语义理解、模式识别与逻辑推理能力。
(2)提示工程、微调等技术可实现模型的场景适配,零样本、少样本学习能力支持模型在少量标注数据下完成特定任务。
2. 代码分析场景的适配逻辑
(1)编程语言与自然语言存在相似的语法结构与语义逻辑,大语言模型可通过理解代码的语义与结构特征,识别异常行为与恶意模式。
(2)大语言模型可覆盖从底层汇编、二进制到高层源代码的多粒度代码分析,同时输出人类可读的解释结果,弥补传统黑盒模型的可解释性不足问题。
(三)研究的核心定位与主要贡献
1. 研究全景覆盖
(1)研究系统梳理大语言模型在恶意代码分析领域的最新进展,涵盖检测、生成、监控、逆向工程、家族分析五大核心方向,完整呈现领域研究全貌。
(2)研究同时覆盖静态分析与动态分析两大技术路径,对比不同方案的适用场景与优劣势。
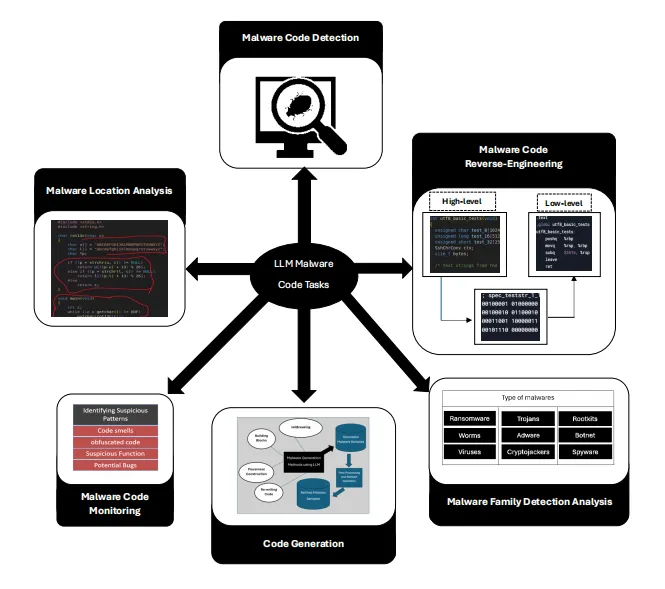
图1 本研究覆盖的恶意代码分析维度总览
2. 四项核心贡献
① 整合领域最新研究成果,梳理大语言模型应用于恶意代码分析的技术发展趋势。
② 首次系统性覆盖恶意代码检测、生成、监控、逆向工程、家族分析全维度的大语言模型应用研究。
③ 阐释大语言模型解读源代码语义与结构、识别恶意行为的技术逻辑。
④ 梳理领域可用数据集与未来研究方向,为后续研究提供资源参考与方向指引。
二、 大语言模型在恶意代码分析领域的核心应用方向
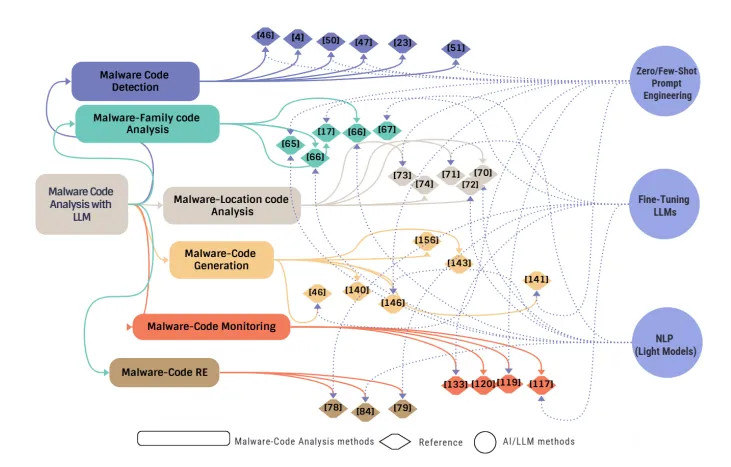
图2 恶意代码分析领域大语言模型与自然语言处理方法的文献计量可视化分析
(一)恶意代码检测技术
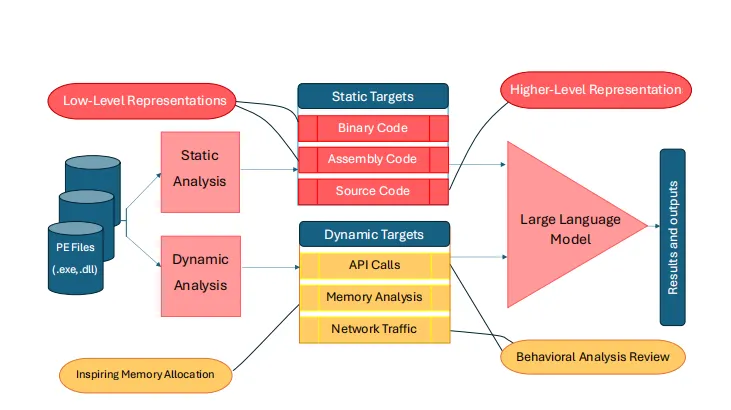
图3 面向大语言模型输入的静态 + 动态恶意软件分析框架总览
1. 多场景的静态检测应用
(1)安卓平台恶意软件检测
① 大语言模型可结合安卓应用的权限、API 调用、URL 等静态特征,通过提示工程生成结构化的安全风险摘要,辅助检测结果的可解释性提升。
② 代表性方案如 LAMD 框架,依托大语言模型从底层指令到高层语义多维度分析安卓恶意软件行为,实现上下文驱动的检测与分类。
(2)Windows PE 文件恶意检测
① 基于 PE 文件的汇编指令、头部特征、导入表等静态信息,大语言模型可学习恶意代码的模式特征,实现对良性与恶意样本的分类。
② 堆叠双向长短期记忆网络与 GPT-2 结合的方案,可通过 PE 文件.text 段的汇编指令训练语言模型,实现静态恶意代码检测。
(3)Java 与网站场景检测
① Mixtral 等大语言模型可结合图数据库技术,分析 Java 源代码的结构特征,识别其中的恶意代码片段。
② 针对网站场景,大语言模型可分析 PHP、JavaScript 等网页代码的安全缺陷,识别网页中的恶意脚本与钓鱼页面特征。
2. 核心检测策略
(1)微调优化策略
① 在标注的恶意代码数据集上微调预训练大语言模型,可让模型学习恶意代码结构、混淆技术、规避手法的专属特征,提升对未知样本的识别准确率。
② 微调后的模型可辅助逆向工程流程,对混淆函数、加密载荷等模糊代码段提供上下文驱动的解读建议,加速威胁分析效率。
③ 代表性微调模型包括基于 MalS 数据集微调的 MalT5、基于 BERT 嵌入微调的 APILI、针对 PowerShell 反混淆微调的 Code Llama 等。
(2)零样本与少样本检测
① 零样本与少样本学习技术可让大语言模型在极少甚至无任务专属训练数据的情况下,依托预训练的代码知识与语义理解能力识别恶意软件。
② 通过设计结构化的提示模板,可引导大语言模型完成多视图的应用安全审计,输出标准化的风险分析结果,适配快速迭代的威胁检测需求。

图5 网站场景零样本恶意代码分析提示词示例
(3)动态检测辅助
① 针对传统动态分析对未知 API 调用解析不足的问题,大语言模型可为 API 调用生成解释文本,结合嵌入技术构建精细化的 API 序列表征,再通过检测模型识别恶意行为。
② Nebula 等 Transformer 架构方案,可处理动态日志中的多源异构行为数据,包括网络行为、文件操作等,弥补传统动态分析仅依赖 API 的局限。
(二)恶意软件家族分类与定位分析
1. 恶意软件家族分类技术
(1)非大语言模型的传统方案
① 传统方案基于 NLP 的层级注意力机制提取恶意样本的高阶语义信息,生成表征向量完成家族分类;或基于字节码、汇编代码、PE 结构的多维度特征,结合机器学习分类器实现分类。
② 安卓场景下,可通过提取控制流图、数据流图编码为特征矩阵,结合 n-gram 序列实现恶意家族的分类与特征刻画。
(2)大语言模型驱动的分类方案
① 上下文驱动的分类框架可将恶意软件划分为广告软件、后门、潜在不受欢迎应用、风险软件、恐吓软件、木马六大类,为人工审计提供结构化的解读思路。
② 针对二进制符号缺失的场景,可通过程序分析提取上下文依赖,结合正则化多头注意力的 Transformer 架构,实现恶意软件家族分类等下游任务。
2. 恶意代码定位分析
(1)传统 NLP 定位方法
① 命名实体识别技术可识别代码中的函数名、变量名、库导入、系统命令等实体,辅助定位可疑代码段。
② 主题建模技术可将操作码序列映射为离散分布的主题,实现对恶意代码区域的粗粒度定位。
(2)大语言模型定位逻辑
① 大语言模型通过理解代码上下文与语义结构,可识别异常 API 调用、网络活动、非常规文件操作等恶意特征,精准定位执行有害操作的代码区域。
② 通过在大规模已知恶意样本上训练,大语言模型可掌握异常控制流、可疑系统调用、异常资源交互等典型恶意模式,实现细粒度的恶意代码定位。
(三)恶意软件逆向工程技术升级
1. 逆向工程的技术痛点
(1)传统逆向工程依赖 IDA Pro、Ghidra 等工具完成反汇编与反编译,但高度依赖启发式规则,对加壳、混淆的二进制文件解析准确率低,人工修正成本高。
(2)编译过程会丢失大量高层语义信息,仅通过机器码无法还原原始高级语言、变量名、代码逻辑,逆向结果可读性差。
图6 PE 文件类型 / 格式分类
2. 大语言模型的逆向赋能方向
(1)底层代码生成与加壳样本解析
① 大语言模型可从原始二进制数据中还原汇编代码,提升反汇编输出的准确率,辅助重构代码的高层控制流,加速恶意逻辑与载荷的识别。
② 针对加壳的恶意二进制文件,微调后的大语言模型可识别常见加壳方式的特征模式,辅助脱壳流程,同时解码混淆代码,输出可读性更强的汇编结果。
(2)反编译与高级语言还原
① 大语言模型可弥补传统反编译器的不足,优化伪代码的可读性,补充语义信息,将底层指令还原为更接近人类编写逻辑的高级语言代码。
② 二进制 - 源码匹配技术可通过嵌入模型计算源函数与二进制函数的相似度,实现恶意代码的同源性分析与第三方库检测。
(3)代码混淆与反混淆
① 恶意代码常通过变量名混淆、死代码插入等手段规避检测,传统工具难以快速解析混淆后的代码逻辑。
② 大语言模型可识别混淆代码中的核心功能模式,自动生成反混淆建议,还原代码的真实功能,大幅缩短混淆代码的分析周期。
3.逆向工程的标准化流程
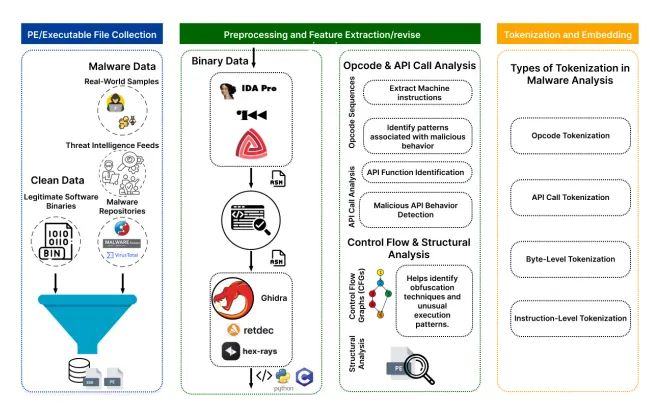
图7 PE 文件数据预处理与逆向工程全流程总览
(1)数据收集与预处理阶段
① 收集多来源的 PE 文件样本,包括恶意软件仓库的标注样本、真实环境捕获的攻击样本、威胁情报共享的活动样本,以及合法软件的良性样本作为基准。
② PE 文件包含.exe、.sys、.dll 等多种格式,是 Windows 环境下恶意攻击的主要载体,也是逆向分析的核心对象。
(2)特征提取与逆向处理阶段
① 通过反汇编、反编译工具将二进制文件转换为汇编指令或伪代码,分别从操作码层面的底层视角、API 调用层面的高层视角提取特征,完整呈现程序行为。
② 操作码分析聚焦 CPU 执行的机器指令细节,API 调用分析追踪程序与系统环境的交互,二者结合可全面还原恶意软件行为。
(3)分词与嵌入阶段
① 对操作码序列、API 调用、字节序列、指令细节等不同粒度的特征进行分词与向量化嵌入,为大语言模型与 Transformer 模型提供标准输入。
② 不同粒度的特征对应不同的分析目标,字节级特征适配底层检测,API 级特征适配行为分析。
4. 大语言模型相对传统方案的优势
(1)具备上下文理解能力,无需大量人工特征工程,可直接处理原始二进制与代码结构。
(2)泛化能力更强,对零日威胁与复杂混淆技术的识别效果优于传统特征驱动模型。
(3)可输出可解释的分析结果,解决传统机器学习模型黑盒、透明度不足的问题。
(四)开发侧代码监控与风险前置防控
1. 代码缺陷与漏洞检测
(1)传统代码审查与静态分析工具存在误报率高、泛化能力差、检测粒度粗等问题,大语言模型可识别代码中的潜在缺陷,同时输出可读解释与修复建议。
(2)大语言模型可结合 CVE、CWE 等标准漏洞框架,精准识别代码中的安全弱点,检测效果优于传统静态分析工具,尤其在小型代码库与低经验开发者代码场景中表现突出。
(3)相关研究显示,GPT-4 可识别出传统工具 4 倍数量的漏洞,且修复后可减少 90% 的漏洞;编辑时检测方案可将漏洞检测融入开发流程,实现实时风险预警。
2. API 安全审查
(1)传统 REST API 测试依赖人工构建用例,存在用例覆盖不全、参数依赖处理困难、适配接口迭代成本高等问题。
(2)大语言模型可从 API 文档的自然语言描述中提取机器可读规则,生成符合约束的测试参数,提升接口测试的准确率与覆盖率。
(3)相关方案可实现端到端的集成测试生成,结合检索增强生成技术处理大型接口规范,辅助测试人员提升工作效率。
3. 代码坏味道识别
(1)代码坏味道属于不良编码实践,会提升软件复杂度与维护难度,部分安全相关坏味道可直接导致注入攻击、未授权访问等安全风险。
(2)参数高效微调等技术可让大语言模型适配方法级的代码坏味道检测,在低计算开销下实现优于传统方案的检测效果。
(3)混合专家架构的方案可结合专业工具与大语言模型,精准识别复杂类型的代码坏味道,同时输出重构建议。
(五)大语言模型的恶意代码生成风险
1. 恶意代码生成的天然障碍
(1)商用大语言模型内置安全对齐机制,会拦截直接要求生成恶意代码的提示,拒绝输出有害内容或仅生成不完整结果。
(2)大语言模型对复杂漏洞开发、权限提升、高级规避技术的理解深度不足,无法自主生成高复杂度的完整恶意程序。
(3)恶意软件开发与传播受法律约束与伦理限制,滥用 AI 生成恶意代码属于违法行为。
2. 主流规避生成技术
(1)提示工程绕过
通过设计特殊提示词绕过安全过滤,生成对应 MITRE 攻击技术的可执行代码,生成的攻击载荷靶向性与复杂度通常高于人工编写。
(2)模块化构建
将完整恶意软件拆解为文件操作、进程注入、权限提升等独立功能模块,分别请求大语言模型生成,再手动拼接为完整程序。该方法可规避安全审查,且能生成多实现的变种,降低特征码检测的命中率。
(3)越狱攻击
通过 DAN 等越狱提示解除大语言模型的内容限制,可生成多类型恶意软件与攻击工具。相关研究显示,越狱后生成的部分恶意样本检测率极低,Linux 场景下的恶意工具检测率可低于 3%。
(4)分段构建
将恶意软件的功能拆分为多个看似无害的编程任务分别请求生成,再拼接组合为完整的恶意程序,无需越狱即可绕过内容安全机制。
(5)代码重写生成变种
基于现有恶意代码,通过大语言模型重写生成变种,改变代码的语法结构但保留核心功能,可生成大量规避检测的恶意样本。相关研究显示,重写生成的部分变种可规避多数杀毒引擎的检测。
(6)GAN 与大语言模型混合生成
结合生成对抗网络与大语言模型生成合成恶意样本,可生成针对机器学习检测器的对抗性样本,提升恶意软件的规避能力。
三、 主流支撑模型与数据集体系
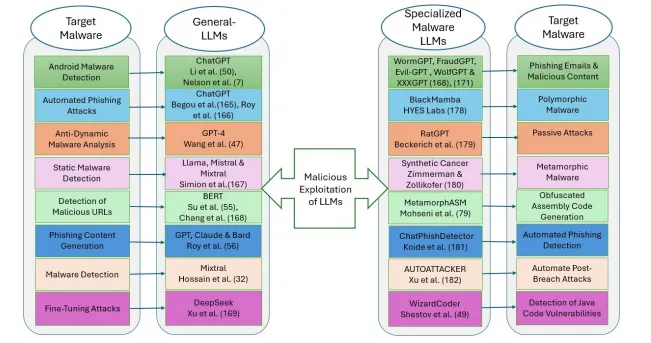
图8 不同大语言模型在多目标恶意代码分析中的应用分布
(一)通用大语言模型的安全领域适配
1. OpenAI 系列模型
(1)GPT 系列与 ChatGPT 是安全领域应用最广泛的通用模型,覆盖恶意软件检测、分析、钓鱼生成、逆向辅助等多个场景。
(2)在检测场景中,GPT 模型可辅助解释检测结果,提升恶意软件分析的可解释性;在逆向场景中,可识别反动态分析技术、解析混淆字符串、提取 API 调用模式。
(3)该系列模型也常被用于生成钓鱼网站、钓鱼邮件等恶意内容,是网络犯罪的主要滥用对象之一。
2. 开源系列模型
(1)Llama 系列:开源权重的 Llama2 等模型支持本地部署与自定义微调,广泛用于安全研究,也易被篡改训练数据用于恶意目的。未经微调的开源模型直接用于恶意软件检测准确率较低,需结合领域数据微调。
(2)Mixtral:混合专家架构的 Mixtral 模型可结合图分析技术,实现 Java 源代码的恶意代码检测,适配零日威胁与混淆样本的识别场景。
(3)BERT:双向编码器架构的 BERT 模型广泛用于恶意 URL 检测、恶意文本识别,可捕捉 URL 的语义关联与上下文模式,同时适配多视图的输入处理。
3. 其他商用模型
(1)Claude、Gemini 等商用模型同样具备代码分析能力,可被通过递归提示工程等方式绕过安全限制,生成钓鱼攻击内容。
(2)DeepSeek 等开源代码模型具备强大的代码推理能力,但存在微调攻击风险,经过对抗微调后会大幅提升有害内容的生成比例。
(二)专用安全领域模型与攻击性模型
1. 专用检测分析模型
(1)WizardCoder:针对代码任务优化的模型,微调后可实现 Java 源代码的漏洞二分类检测,准确率与鲁棒性优于 CodeBERT 类基线模型。
(2)MalBERT:专门针对安卓恶意软件静态检测优化的 BERT 类模型,通过分析应用源代码特征实现恶意分类。
2. 黑产攻击性模型
(1)WormGPT、FraudGPT、Evil-GPT 等地下论坛的恶意模型,无安全对齐限制,专门用于生成钓鱼邮件、恶意代码、黑客工具,降低网络犯罪的技术门槛。
(2)DarkGPT 等无过滤模型,可生成高规避能力的恶意代码,生成的程序可正常编译且规避多数杀毒软件检测。
3. 概念验证型恶意软件
(1)BlackMamba:多态键盘记录恶意软件,运行时调用大语言模型 API 动态生成恶意代码,无磁盘落地,每次执行的代码形态均不同,可规避传统端点检测方案。
(2)RatGPT:将大语言模型作为攻击代理的概念验证方案,利用大语言模型生成载荷与 C2 通信逻辑,绕过传统恶意代码检测机制。
(3)Synthetic Cancer:变形恶意软件原型,通过大语言模型在复制时重写代码,每次传播都生成新变种,规避特征码检测,同时结合社会工程学提升传播成功率。
(三)恶意软件分析的核心数据集资源
1. 安卓恶意软件数据集
(1)AndroZoo:百万级的安卓应用样本仓库,是机器学习恶意软件分类研究的主流基准数据集。
(2)DREBIN:大规模安卓恶意软件数据集,支持静态与动态分析研究;KronoDroid 为混合特征的安卓恶意数据集,覆盖多年度的样本。
2. Windows PE 恶意软件数据集
(1)BODMAS:带时间戳与家族标注的 PE 恶意数据集,适用于时序维度的恶意软件分析研究。
(2)SOREL-20M:两千万级的 PE 文件特征数据集,包含千万级无害化恶意样本,是静态检测模型训练的主流基准。
(3)EMBER:PE 恶意软件分析的经典数据集,广泛用于机器学习特征工程与模型对比。
(4)MOTIF:带真实家族标注的公开恶意数据集,支持恶意软件分类与攻击归因研究。
3. 其他通用数据集
(1)VirusShare、Vx-underground 等多平台恶意软件仓库,提供海量样本与源代码资源,其中部分需验证权限方可访问。
(2)MalwareBazaar 等威胁情报平台,持续更新零日恶意样本,支撑实时威胁研究。
(3)TaintBench 等专项基准数据集,用于安卓污点分析工具的效果评估。
(四)大语言模型驱动的数据集增强技术
1. 跨语言翻译扩增
通过大语言模型将不同编程语言的恶意代码翻译为目标语言,扩充特定语言的恶意样本规模,帮助检测模型覆盖更多攻击模式,识别传统规则方法遗漏的威胁。
2. 混淆变种扩增
通过大语言模型对现有恶意代码进行混淆变换,生成功能一致但形态不同的变种样本,补充到训练数据中可提升检测模型的泛化能力与抗规避能力。
四、 现存技术局限与未来研究方向
(一)当前技术的核心局限
1. 上下文长度限制
(1)大语言模型存在最大令牌长度限制,无法直接处理完整的恶意程序代码,只能拆分到函数级粒度分析,增加了整体分析的整合难度。
(2)现有反编译专用大语言模型的最大处理长度普遍在数千令牌级别,难以支撑大型复杂恶意程序的全量分析。
2. 新型威胁泛化不足
(1)大语言模型的效果高度依赖训练数据,对于训练集中未出现的新型恶意软件变种、新型混淆技术、专属软件环境下的攻击,识别能力会明显下降。
(2)模型无法脱离训练数据的模式边界,面对完全未知的攻击范式时易出现漏检。
(二)重点未来研究方向
1. 知识图谱与大语言模型融合
将威胁情报知识图谱与大语言模型结合,注入结构化的攻击战术、技术、流程知识,提升模型对恶意行为关联关系的识别能力,自动化构建威胁情报知识图谱。
2. 混合逆向工程方案
将大语言模型与 IDA Pro、Ghidra 等专业逆向工具结合,形成工具负责基础反编译、大语言模型负责语义补全与逻辑解读的混合流程,提升逆向分析的准确率与效率。
3. 思维链反编译技术
将思维链提示技术应用于反编译任务,引导模型分步拆解反编译流程,模拟人工逆向的思考逻辑,提升复杂二进制文件的反编译还原效果。
4. 数据流分析与大语言模型结合
将确定性数据流分析的精准性与大语言模型的语义理解能力结合,实现更精准的恶意代码污点分析与传播路径识别,提升恶意行为定位的准确率。
5. 知识增强预训练模型
将领域专属的安全知识注入预训练阶段,打造知识增强的预训练语言模型,让模型原生具备安全领域的专业知识,提升恶意代码检测的准确率与泛化能力。
6. 大概念模型应用
探索大概念模型在恶意代码分析中的应用,从令牌级处理升级为概念级处理,提升长上下文理解与抽象推理能力,适配大型复杂恶意程序的分析需求。
五、 行业价值与发展总结
(一)技术价值
大语言模型为恶意软件分析领域带来了范式升级,从传统的特征驱动转向语义驱动,大幅提升了对未知威胁、混淆样本的识别能力,同时弥补了传统方案可解释性不足的短板,为安全分析师提供了高效的辅助工具。
(二)行业意义
1. 防御侧:可实现检测、分析、响应全流程的自动化升级,降低安全分析的技术门槛,提升威胁处置效率,强化网络安全防御体系的韧性。
2. 风险侧:大语言模型的两用性也带来了新的威胁,恶意代码生成门槛的降低会加速威胁迭代,对安全防御体系提出了更高的要求。
(三)发展前景
随着大语言模型技术的持续迭代,其在软件安全领域的适配深度将持续提升,与专业安全工具、知识体系的融合将不断深化,成为网络安全攻防两端的核心技术支撑。

来源:Hamed Jelodar, Samita Bai, Parisa Hamedi, et al. Large Language Model (LLM) for Software Security: Code Analysis, Malware Analysis, Reverse Engineering. arXiv Preprint, 2025, 2504.07137v1, 1-34.
