 夜雨聆风
夜雨聆风
英伟达下一代 Rubin AI 芯片 2026 下半年发布,需要的就是 HBM4。SK 海力士拿下 70% 订单,三星刚送样验证,美光重做架构推迟到 2027 年。
而国产长鑫存储,HBM2 才刚量产。
HBM 是 AI 算力的真瓶颈——比 7nm 逻辑工艺的寡头格局还集中。这是个比"卡脖子"更深的产业问题。
一、为什么 HBM 突然变成了瓶颈
如果你只看 NVIDIA 历代 AI 芯片的算力数字,会发现一个有意思的现象:
| Rubin | HBM4 | 13 TB/s | 25× | ||
| 1 TB |
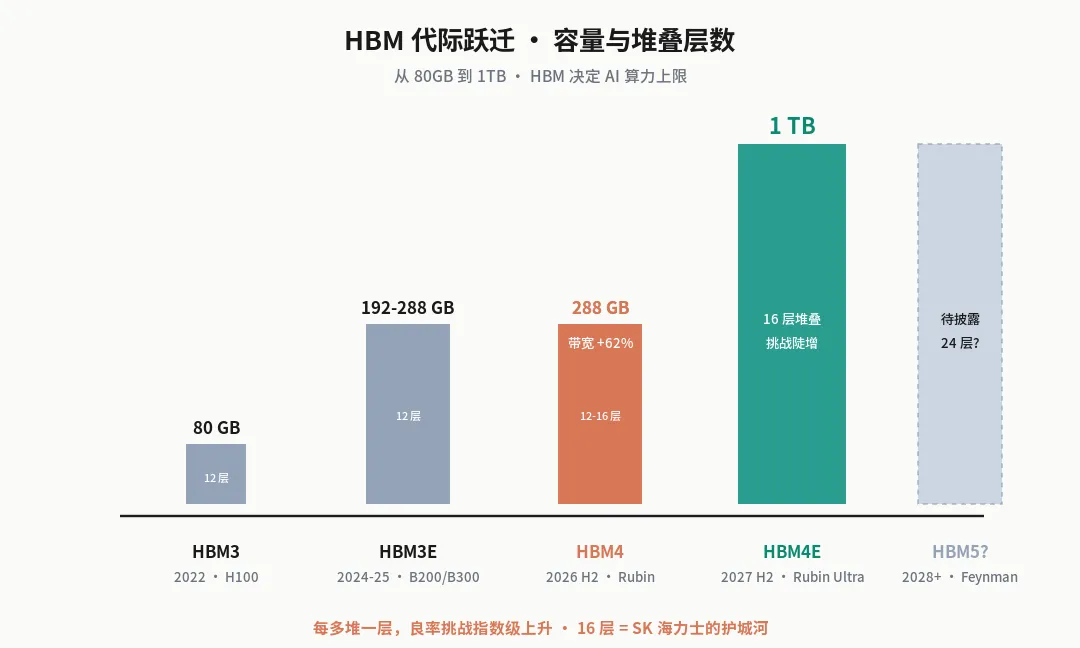
4 年时间,算力涨 25 倍,HBM 容量涨 12.5 倍。
但这里有个反直觉的数字:Rubin 相对 B300 算力涨 3.3 倍——靠的不是工艺(同代 3nm),不是堆 HBM 容量(同 288 GB),而是 HBM4 带宽从 8 TB/s 提到 13 TB/s(+62%)。
算力 = GPU 核心 × 内存带宽利用率。GPU 核心再多,HBM 喂不饱也白搭。
这就是为什么 HBM 在 2025-2026 年突然变成 AI 算力供应链的命门——它不是配角,是主线。
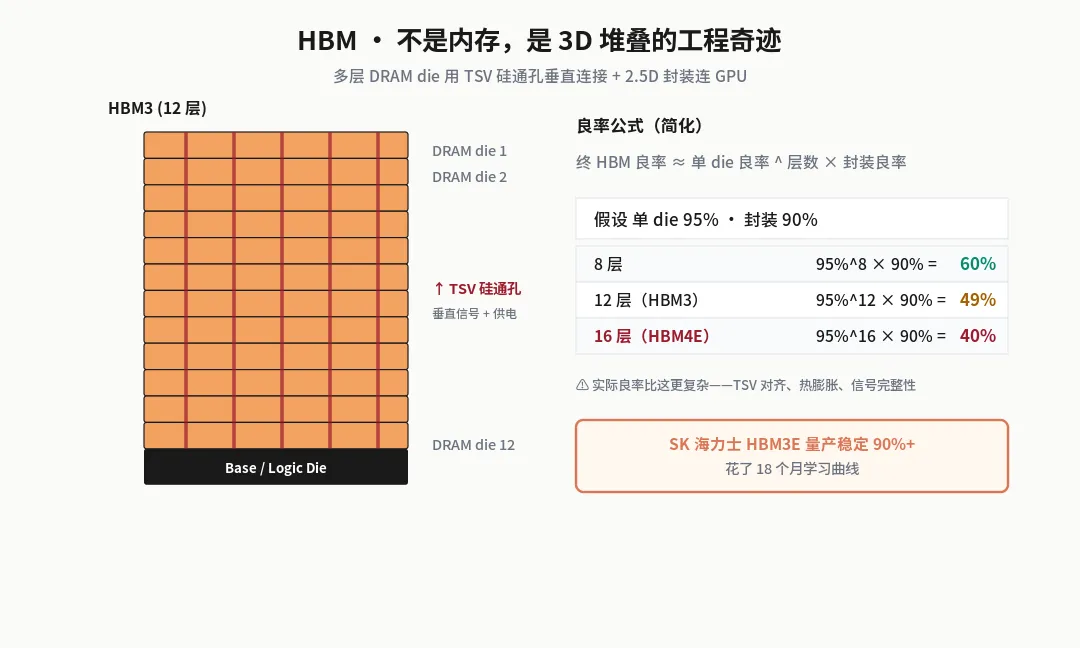
二、HBM 不是"内存",是"3D 堆叠的工程奇迹"
很多人以为 HBM 就是更快的 DRAM。其实差远了。
HBM = 多层 DRAM die 用 TSV(硅通孔)3D 堆叠 + 2.5D 封装连接 GPU。
HBM3:12 层 DRAM die 堆叠 HBM4:12-16 层 HBM4E:16 层 HBM5(研发中):可能 24 层
每多堆一层,良率挑战指数级上升。
良率怎么算? 简化公式:
终 HBM 良率 ≈ 单 die 良率 ^ 层数 × 封装良率
假设单 die 良率 95%,封装 90%:
8 层 = 95%^8 × 90% = 60% 12 层 = 95%^12 × 90% = 49% 16 层 = 95%^16 × 90% = 40%
而 HBM 实际良率比这更复杂——还要考虑 TSV 对齐精度、热膨胀差异、信号完整性。这就是为什么 SK 海力士在 HBM3E 量产稳定 90%+ 花了 18 个月。
三、三大厂的真实位置
回到那个数字:SK 海力士占英伟达 HBM4 订单 70%。这不是偶然。
SK 海力士(领跑)
HBM4 月供英伟达 50,000 片晶圆样品 量产时间表 Q2 → Q3 2026(推迟一个季度) - 2025 年 Q2 财报:营收 221 亿美元(+35% YoY),利润 67 亿美元(+68% YoY)
HBM 已经是公司利润主引擎 - 关键动作:买了 2 台 ASML High-NA EUV
用于 HBM 制造——HBM 良率竞赛已升级到光刻层
三星(追赶中)
HBM3E 没通过英伟达认证(这是关键失败) HBM4 2025 年 11 月开始送付费最终样品 - 2026 年 HBM 产能扩到 25 万片/月
(比 2025 年 17 万 +47%) 但 HBM4 最终订单数量看 Q1 2026 末敲定
美光(掉队)
12 层 HBM4 样品已交付 - 但无法满足英伟达性能要求
业内传可能需要 9 个月架构重做 - 量产推迟到 2027 年
——至少落后一个完整代际 
寡头格局已经形成:未来 2-3 年,HBM 高端市场只剩 SK 海力士 + 三星两家。
四、国产 HBM 真实差距
接下来必须谈中国。
长鑫存储(CXMT)现状:
HBM2 已经量产(比原计划提前完成) 12 层 HBM3 综合良率 ~80% HBM3 月产能目标 60,000 片(占总产能 30 万片的 20%) 12 层 HBM4 量产计划 2027 年 2026 年 1 月 IPO 募资 42 亿美元 与华为联合开发
数字看着不错。但要注意三件事:
1. "80% 良率"是测试阶段数据。 HBM 有个"规模化诅咒"——小批量验证良率和月产 6 万片的稳定良率,往往差 10-20 个百分点。SK 海力士做到 HBM3E 量产稳定 90%+ 花了 18 个月。
2. 2027 年 12 层 HBM4 实质追的是 SK 海力士 2024-2025 年的水平。 那时 SK 海力士的主流已经是 HBM4E 甚至 HBM5。代差是结构性的。
3. 设备供应链不完整。 HBM 需要先进 DRAM + 先进封装 + 高端 EUV/DUV。中国少了第三个环节——ASML 不能卖 EUV 给中国,连 Low-NA 都禁运。
五、HBM4E 16 层是真正的拐点
如果说 HBM4 是 SK 海力士的胜利,那 HBM4E 16 层就是整个产业的拐点。
为什么 16 层这么关键?
良率挑战指数级上升(前面公式计算过) TSV 对齐精度要求接近光刻设备极限 这就是 SK 海力士买 2 台 High-NA EUV 的真实原因——HBM 良率竞赛已升级到光刻设备代差
三星和美光呢?
三星:考虑用于 sub-2nm 节点,HBM4E 未明确路线 美光:自身 HBM4 还没量产 国产:完全禁运
这意味着 2027-2028 年 HBM4E 时代,SK 海力士可能不只是 70%,而是 90%+。
六、真问题:电力 + 良率 + 经济性
如果你站在中国半导体产业链角度看,HBM 的问题比 7nm 更难解。
第一道墙:产业链完整性。 HBM 需要:
先进 DRAM 工艺(长鑫 1z nm / 1α nm) 先进封装(CoWoS 类似工艺) 高端光刻(EUV)
前两个中国能搞,第三个完全卡死。
第二道墙:经济性。 即使 2027 年长鑫量产 12 层 HBM4:
单晶圆成本可能是 SK 海力士的 1.5-2 倍 配合 SMIC 5nm 的 Ascend 芯片 单位算力成本是 NVIDIA 方案的 2-3 倍
参考上一篇华为 CloudMatrix 384 vs NVIDIA GB200 NVL72 的数据——4 倍功耗 + 5 倍数量换 2 倍算力——这就是 HBM 代差的真实代价。
第三道墙:电力基础设施。 单机柜功耗 560 kW 等于普通住宅楼供电的 5-10 倍。即使做出来芯片,全国大规模部署受电力基础设施限制。
结尾
HBM 决定 2026-2030 年 AI 算力供应链格局。
这不是简单的"卡脖子"故事——是个产业生态故事。
SK 海力士的护城河不是一道墙,是三道墙叠加: 量产良率 18 个月领先 + 与英伟达深度绑定 + 高端 EUV 设备护城河。三星和美光在某一道上掉队,国产在三道全部落后。

但也不是没有机会。中国能做的最重要事是:
长鑫扩产 + HBM 设备国产化 + 与华为 Ascend 形成闭环。
用"代差小但性价比高"的方式撕开一个口子。
不一定要追上 SK 海力士。但一定要让自己的 AI 算力供应链跑通。
💬 留个争议给评论区:
国产 HBM 2027 年才能量产 12 层 HBM4。等长鑫追上时,主流市场已经是 HBM5。
你觉得国产 HBM 能不能用"代差小但性价比高"的方式撕开一个口子?还是说必须等自研 EUV 之后才能真正追平?
📌 本文综合编译自:TrendForce 关于 HBM4 量产追踪、SK Hynix 2025 Q2 财报、DigiTimes / Tom's Hardware 关于 CXMT 进度的报道、SemiAnalysis 关于 HBM 良率与封装的分析、TechPowerUp 关于 ASML High-NA EUV 客户的报道。所有数据均来自公开权威来源。
