 夜雨聆风
夜雨聆风
📚 AI 圣经 · 系列导览这是「AI 圣经」系列第 01 篇。我会带你逐篇精读撑起今天所有大模型的 21 篇经典论文,分 5 个阶段层层递进(本篇已高亮):
| P01《Attention Is All You Need》· 本篇 | |
本篇论文:《Attention Is All You Need》· Vaswani et al., 2017 · NeurIPS。地址 arXiv:1706.03762(arxiv.org/abs/1706.03762)。其余各篇论文地址,随当期文章给出。
📩 回复「AI圣经01」,领取本篇论文 PDF。
太长不读你每天用的 ChatGPT、Claude、豆包、Gemini,内核都是同一样东西——Transformer。它出自 2017 年 Google 八个人的一篇论文,标题狂得很:《Attention Is All You Need》(注意力,就是你需要的全部)。这篇文章跟着原论文一章一章拆,全程大白话 + 论文原图。读完你能拿到一个具体本事——看懂这篇「AI 圣经」的骨架,并能一句话向朋友解释大模型为什么这么聪明又这么烧钱。
关于这篇论文《Attention Is All You Need》,2017 年发表于 AI 顶会 NIPS,作者是当时 Google 的 8 个人。它提出的 Transformer 架构,后来成了 GPT、Claude、文心、通义等几乎所有大模型的共同地基——GPT 里的「T」就是 Transformer。一个细节:作者之一 Noam Shazeer 后来离开又被 Google 以约 27 亿美元请了回去。
先给你一张「章节地图」论文正文 7 章 + 附录,骨架是这样的:
第 1–2 章 说清老办法卡在哪 → 第 3 章 端出新架构 Transformer(全文核心,最长)→ 第 4 章 论证它为什么更好 → 第 5–6 章 怎么训练、考了多少分 → 第 7 章 收尾 → 附录 给注意力的「可视化证据」。下面就照这个顺序一章一章走。
论文开篇先说当时的主流:让机器读懂一句话,靠的是 RNN(循环神经网络)——一个词一个词、按先后顺序处理,前一个词的理解传给后一个,像一队人接力传话。
它有两个死结。一是传得越远越糊:相隔很远的两个词(比如「它」指前面哪个东西)要经过很多次转手才连得上,中途就衰减了。二是没法并行:必须等前一个词算完才能算下一个,像排队,再多 GPU 也使不上劲。论文原话点得很重——「顺序计算这个根本约束,始终没被解决」。
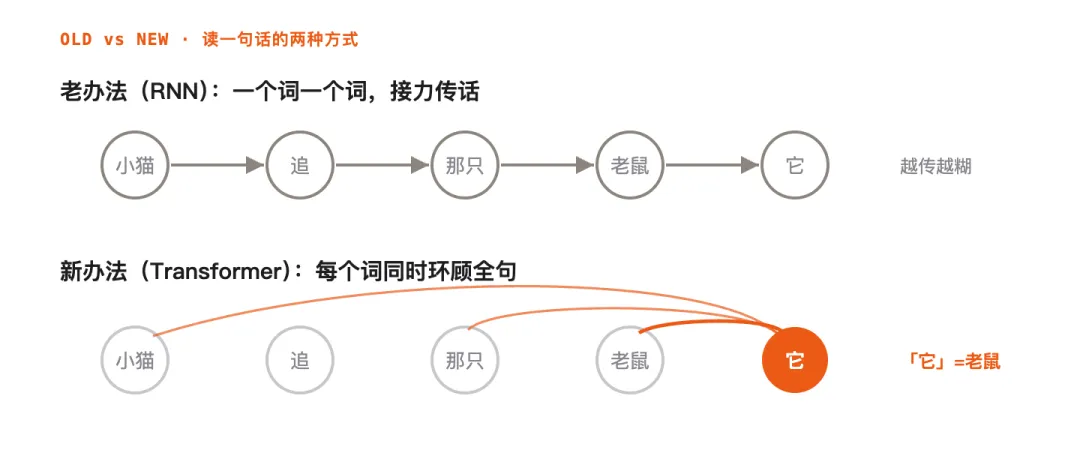
于是作者提出一个大胆的想法:彻底扔掉「循环」,只靠「注意力」来连接一句话里的所有词。这就是 Transformer。
这章是「文献综述」,给一般读者翻译一下:在此之前,已经有人想摆脱「排队」的毛病,改用CNN(卷积网络)来并行处理(论文点名 ByteNet、ConvS2S 等)。但 CNN 有个硬伤——两个词隔得越远,要叠的层数越多才能让它们「见上面」,长距离关系依然难学。
而「注意力」此前多是搭在 RNN 身上的配件,没人敢把 RNN 整个拿掉。论文撂下一句狠话:据我们所知,Transformer 是第一个完全不用 RNN、不用 CNN,纯靠自注意力来做翻译这类任务的模型。底气十足。
这章是论文的心脏,也最长。先看整体:Transformer 是经典的「编码器—解码器」结构——编码器负责读懂输入(比如一句中文),解码器负责一个词一个词地写出翻译(比如对应的英文)。下面这张图你大概率见过,它就是后来所有大模型的祖图:
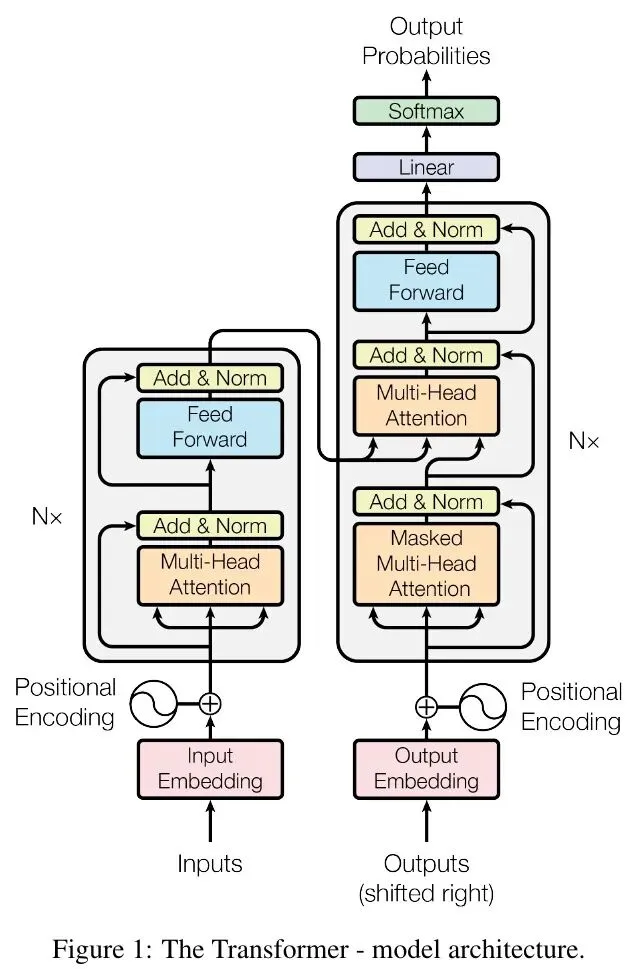
编码器和解码器各由 6 个一模一样的层叠起来(图里的「N×」就是叠 6 次)。每一层里都有「注意力」子层和一个小型前馈网络,并配了残差连接(把输入抄一份加到输出上,防止深层训练时「失忆」)和层归一化(把数值拉回稳定范围)。整个模型的向量宽度是 512。这些是工程细节,记住「叠 6 层、每层都先互相看一眼再各自消化」就够了。
这是全篇的灵魂。自注意力(self-attention)一句话讲:处理每个词时,让它一次性看遍整句所有词,自己决定该重点参考谁。怎么做到?论文给每个词配了三样东西,行话叫 Q、K、V,用大白话就是:
Query(问题) :这个词想搞清楚什么。比如「它」想知道自己指代谁。 Key(标签) :每个词挂出的「我是谁」的标签,供别人匹配。 Value(内容) :每个词真正携带的信息。
处理「它」时,拿它的 Query 去和全句每个词的 Key 比一比,谁的标签最配,就多取谁的 Value。「它」发现「老鼠」最配,于是主要参考「老鼠」——指代关系就被「注意」到了。

论文里那行劝退无数人的公式:Attention(Q,K,V) = softmax(QKᵀ/√d_k)·V。拆成人话就三步:
①算相关度 ( QKᵀ):拿「问题」挨个和「标签」对一下,得到一串分数。②归一成权重 ( softmax):把分数变成加起来等于 100% 的占比。③加权取内容 ( ·V):按占比把各词的「内容」汇总,就是这个词环顾全句后的新理解。
中间的 ÷√d_k 是个工程补丁:词一多、分数会大到让训练「失灵」——数值一大,模型就学不动了(专业叫「梯度消失」),除一下把数值压回正常。论文专门为这点写了脚注。
专业一点(想深的读者看,可跳过)为什么偏偏除 √d_k?假设 Q、K 各维独立、均值 0 方差 1,那么点积 q·k=Σqᵢkᵢ 的方差会随维度 d_k 线性放大到 d_k。维度一大,softmax 的输入就被推到「一家独大、其余近乎 0」的饱和区,梯度几乎消失、没法训练。除以 √d_k 正好把方差拉回 1,让 softmax 留在「有梯度」的健康区间。这是个看似不起眼、却让深层注意力能稳定训练的关键细节。
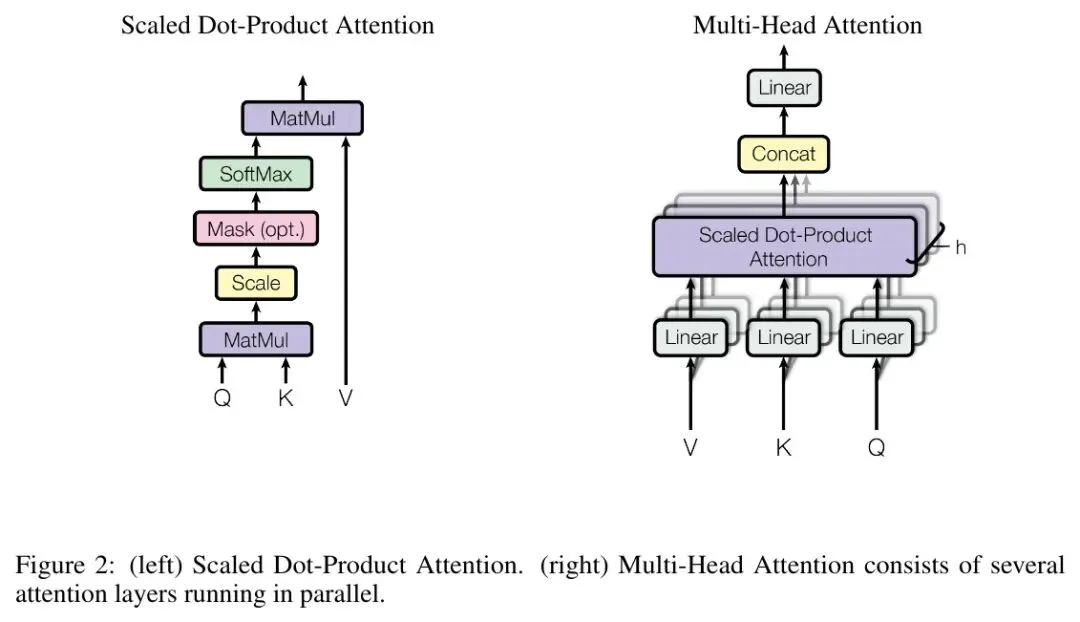
只用一组 Q/K/V,视角太单一。论文的办法是同时跑 8 组(论文取 h=8 个「头」),每组关注不同角度——有的盯语法、有的盯指代、有的盯搭配,最后把 8 份结果拼起来。就像让 8 个专家各看一遍同一句话,再汇总意见。
有意思的是总算力几乎没增加:每个头的维度被压到 512÷8=64 维,8 个头并行算完再拼回 512 维——多了视角,没多花钱。论文的消融实验也证明:砍到只剩 1 个头,翻译质量会掉约 0.9 BLEU 分。(下一节那张「看得见的注意力」图里,不同颜色的线就是不同的头——你能直接看到它们各盯各的。)
论文很巧妙地把注意力复用在三处:① 编码器内部自己看自己(读懂输入);② 解码器内部自己看自己,但只能往前看(写第 N 个词时不许偷看还没写的后文,否则就作弊了);③ 解码器看编码器(写翻译时回头参考原文)。一招三用。
每层在「互相看」之后,还接一个小型前馈网络(每个词各自过一遍,把刚收集的信息「消化」一下)。开头要把词变成一串数字(词嵌入),结尾再把数字变回「下一个词是什么」的概率。一句话:注意力负责「交流」,前馈网络负责「各自消化」,两者交替。
扔掉「循环」带来一个副作用:模型不再知道词的先后顺序了(它一次看全句,分不清「猫追狗」和「狗追猫」)。论文的解法很妙——用一组不同频率的 正弦/余弦波给每个位置算一个独特的「座位号」(PE(pos,2i)=sin(pos/10000^(2i/d))),加到词向量上。选正弦波是因为它能让模型对「相对位置」更敏感、还能外推到训练时没见过的更长句子。这样模型既能并行,又没丢掉语序。
专业补充 · 基础版(base)完整配置想要精确规格的读者,这是论文 base model 的全部关键超参,一次给齐:
· 层数 N=6(编码器/解码器各 6 层);模型宽度 d_model=512;前馈内层 d_ff=2048
· 注意力头 h=8,每头 d_k=d_v=64;dropout P=0.1;标签平滑 ε=0.1
· 大号版(big)把宽度提到 d_model=1024、d_ff=4096、h=16,参数量约 2.13 亿。这套配置,后来被无数大模型反复放大沿用。
这章是论文的「论证」环节,作者列了三个衡量标准:每层的计算量、能并行多少、以及两个词之间要走多远才能「连上」(路径越短,长距离关系越好学)。结论用一张表说尽:

关键就一条:自注意力让任意两个词一步直连(路径长度 O(1)),而 RNN 要走 n 步。既能搭长线、又能拼命并行——这正是它碾压老办法的根本原因。论文还提了一句彩蛋:注意力顺带让模型更可解释,因为你能把它「在看哪」画出来。
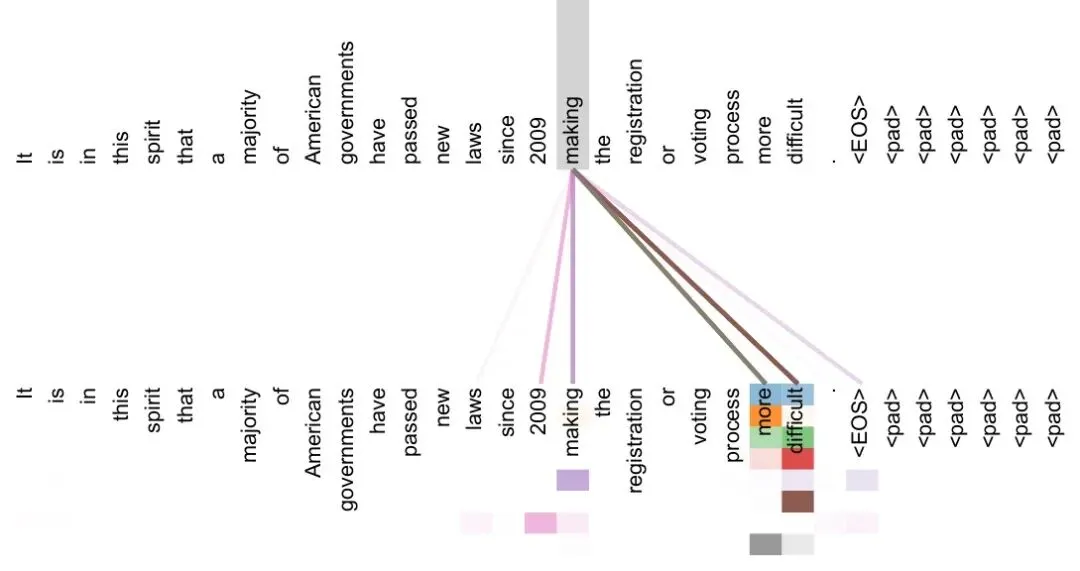
空口无凭。论文附录把模型内部的注意力画成了图——线越粗,代表「看得越重」。先看最惊艳的一张:处理代词 its(它的)时,注意力的线清清楚楚连向了它真正指代的词。
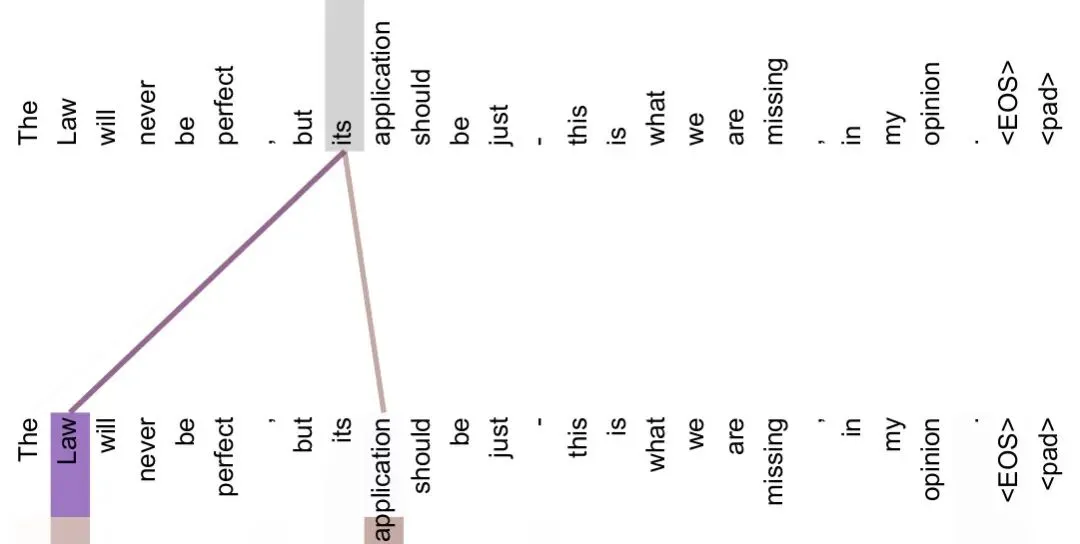
再看一张长距离的:处理动词 making 时,不同颜色的「头」把线甩向了很远处的 more、difficult,补全了「making…more difficult(使…更难)」这个隔了一长串词的搭配。这正是老办法 RNN 最头疼、而 Transformer 一步到位的事。
这章交代怎么把模型训出来,给一般读者挑重点:用的是公开的 WMT 2014 翻译数据集(英德约 450 万句、英法约 3600 万句,用 byte-pair 编码切词);硬件是 8 块 NVIDIA P100 GPU;基础版训练约 12 小时(10 万步)、大号版约 3.5 天(30 万步)。
专业细节:优化器用 Adam(β₁=0.9, β₂=0.98),学习率走「先线性升温 4000 步、再按步数平方根倒数衰减」的经典 warmup 策略;正则化用 dropout 0.1 + 标签平滑 0.1(后者会让困惑度变差,却能提升 BLEU 与准确率——一个反直觉但有效的 trick)。放今天看,这点算力小得惊人,换来的东西却不小。
翻译质量用 BLEU 分(越高越好)衡量。Transformer 的大号版在英德翻译拿到 28.4 分,比之前所有模型——包括好几个模型「抱团」的集成结果——还高 2 分多;英法翻译拿到 41.8 分,刷新单模型纪录。
更狠的是性价比:按训练浮点运算量(FLOPs)算,base 版只花了约 3.3×10¹⁸、big 版约 2.3×10¹⁹,而同期对手动辄 10²⁰ 量级——用对手几分之一甚至几十分之一的算力,做到了更好。这正是「砍掉顺序计算、换上可并行的注意力」最直接的红利。
作者还做了一堆「拆零件」实验(消融):把 8 个头砍成 1 个,质量掉 0.9 分;模型越大越好;位置编码换成另一种方案,效果几乎一样。最后他们把 Transformer 拿去做了个完全不同的任务(英语句法分析),照样表现优异——证明这套架构不挑食、泛化能力强。这一点,正是它后来能横扫一切的伏笔。
作者收尾很克制:Transformer 是第一个纯靠注意力的此类模型,更快、更强、刷新纪录。然后写下一句当时看像愿景、now 看像预言的话——「我们计划把它扩展到图像、音频、视频。」
八年过去,这句全应验了:文生图、语音、视频生成,背后大多还是 Transformer。但天下没有免费的革命——「让每个词看遍所有词」意味着句子长一倍、计算量翻四倍(O(n²))。这一条,正是今天你能直接感受到的两件事的根源:
大模型为什么这么烧钱、吃显卡 :注意力的平方成本 × 海量文本=天文算力账单。 「长上下文」为什么又贵又不总好用 :窗口每拉长一截成本陡增,塞太多模型还会「读到中间走神」。
从 2017 那 8 页论文,到今天每天几亿人用的 ChatGPT、Claude——所有的「大力出奇迹」,都立在「注意力」这一个想法上。标题没吹牛。
主动回忆一遍才记得住(这点「小难度」是故意的)。三问,想好再看下一段答案:
1. 老办法 RNN 的两个死结是什么? 2. 用「查资料」打比方,Q、K、V 分别是什么? 3. 为什么大模型这么烧钱、长上下文这么贵?
答案1. 顺序接力、远词信息会衰减(搭不上长线)+ 必须排队、没法并行(用不满 GPU)。
2. Query=我想搞清的问题;Key=每个词的标签;Value=每个词真正的内容。谁的标签最配我的问题,就多取谁的内容。
3. 注意力要「每个词看遍所有词」,长度翻倍计算翻四倍(O(n²)),所以越长越贵、越烧算力。
只记一句:Transformer 用「注意力」让一句话里每个词同时环顾全文、按相关度互相取信息,从此机器既能搭长线又能大规模并行——这就是这一代 AI 的地基。现在你可以把它讲给任何一个好奇「ChatGPT 怎么 work」的朋友了。
想再深入一点最好的图解入门是 Jay Alammar 的 《The Illustrated Transformer》(全程动图讲 Q/K/V,搜标题即得);想看代码怎么从零搭,看 Karpathy 的 《Let's build GPT》 视频。这两个公认讲得最清楚。
你最早是从哪个产品意识到「AI 突然变强了」的?评论区聊聊。下一篇我们接着把「大模型为什么会胡说八道(幻觉)」讲清楚。
