 夜雨聆风
夜雨聆风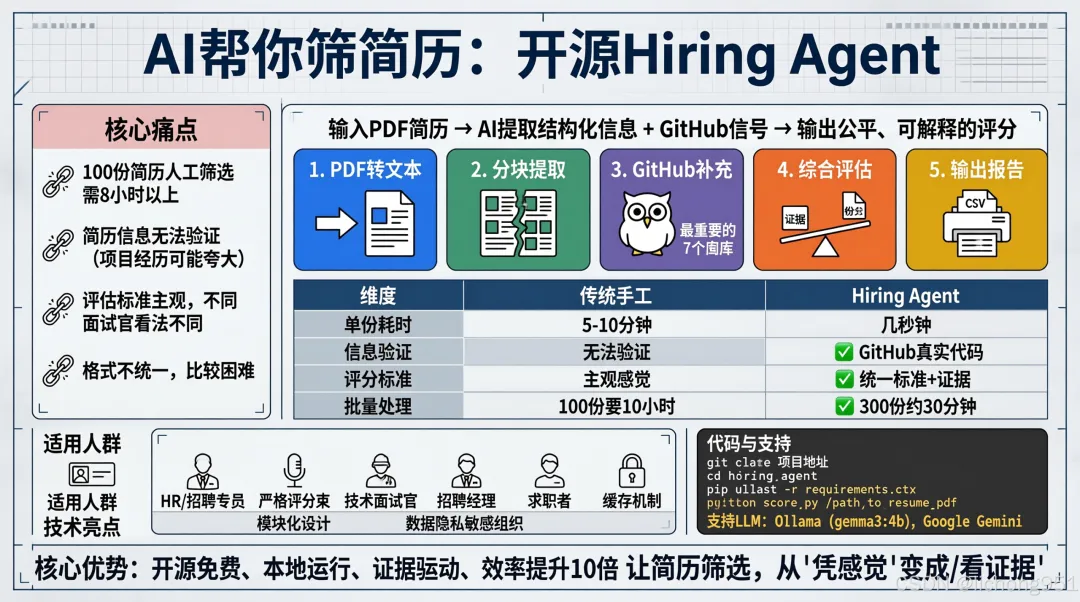
输入一份PDF简历,自动提取结构化信息 结合GitHub代码信号,输出公平、可解释的评分 全程可本地运行,数据不外传
📋 先看痛点:招聘筛简历,为什么又慢又不准?
你是一个技术团队的招聘负责人、HR、或者技术面试官。
你收到100份简历,要从中找出合适的候选人。
问题来了:
每份简历5分钟 → 100份要花 8小时以上,还不一定能看完 简历里的“项目经历”可能夸大 → 你没法验证 GitHub上写了“贡献过开源项目” → 你真的会去一个个查吗? 不同人的简历格式不同 → 比较起来很困难 评估标准不统一 → 不同面试官看法不同
核心矛盾:
简历太多,看不过来;简历里的信息不可验证;评估标准主观。但招聘又必须做——每个错过的优秀候选人和每个被误招的不合适的人,都代价巨大。
✅ Hiring Agent 的解法
Hiring Agent 是一个开源的、AI驱动的简历评估工具。
一句话:输入PDF简历 → AI提取结构化信息 + GitHub信号 → 输出公平、可解释的评分
它不做“简历是否通过”的武断判断。它做的是:
从简历PDF里提取:基本信息、工作经历、教育背景、技能、项目、获奖 如果简历里有GitHub信息,拉取真实代码数据 对候选人进行分类打分,附带证据、加分和扣分理由 输出一份可解释的评估报告
你可以完全本地运行(用Ollama),也可以用Google Gemini API。数据不需要上传到任何第三方。
🔥 它解决了什么?
1. 手工看简历 vs AI提取结构化信息
| 传统手工看简历 | Hiring Agent | |
|---|---|---|
| 几秒钟 | ||
2. 简历内容 vs GitHub真实代码信号
| 只看简历 | + GitHub信号 | |
|---|---|---|
3. 主观判断 vs 可解释评分
| 传统主观判断 | Hiring Agent评分 | |
|---|---|---|
它不替你做决定。它帮你做决定前,把候选人的信息整理好、量化好、对比好。
📦 工作流程(五个步骤)
PDF简历 → 提取文本 → 分块提取结构化数据 → GitHub信号补充 → 评分输出第1步:PDF转文本
用 pymupdf_rag.py 把PDF转换成Markdown格式的文本。
第2步:分块提取结构化信息
用LLM按模块提取:
基本信息(Basics):姓名、邮箱、位置、个人链接 工作经历(Work):公司、职位、时间、描述 教育背景(Education):学校、专业、学历、时间 技能(Skills):技术栈、工具、语言 项目(Projects):项目名称、描述、技术栈、链接 获奖(Awards):奖项名称、时间、级别
每个模块有独立的提示词模板(prompts/templates/*.jinja),确保提取的一致性和准确性。
第3步:GitHub信息补充
从简历里提取GitHub用户名 拉取个人资料和仓库列表 用LLM从候选人的所有仓库里选出最重要的7个 分类:开源项目 / 个人项目 / 课程项目 / 生产项目
第4步:综合评估
评估维度:
- 开源贡献
(Open Source):贡献了多少开源项目?影响力如何? - 个人项目
(Self Projects):独立完成的项目质量和复杂度 - 生产项目
(Production):有没有在生产环境中使用过的项目? - 技术技能
(Technical Skills):技术栈的广度和深度
加减分机制:
加分:有影响力的开源贡献、技术博客、专利、获奖 减分:GitHub活跃度低、项目描述模糊、技术栈过时
第5步:输出报告
控制台打印可读的评分报告 CSV导出(开发模式): resume_evaluations.csv,包含关键字段中间结果缓存(开发模式): cache/目录
输出示例:
📊 评估报告:候选人_X开源贡献:72/100(3个活跃开源项目,7次贡献)个人项目:58/100(2个项目,其中1个有技术深度)生产项目:—(无生产级项目)技术技能:65/100(Python/Go/React)加分项:+5 有技术博客,月访问1000++3 1个开源项目被50+人fork减分项:-5 GitHub活跃度低(近3个月无提交)-3 项目描述缺少技术细节综合推荐:★★★☆☆(3.5/5)证据:详见评估详情...
🚀 怎么用?
前提条件
Python 3.11+ 一个LLM后端(任选): - Ollama
(本地免费): ollama pull gemma3:4b - Google Gemini
(需要API Key)
安装
git clone 项目地址cd hiring-agentpython -m venv .venvsource .venv/bin/activate # Windows: .venv\Scripts\activatepip install -r requirements.txt
配置
cp .env.example .env在 .env 里设置:
LLM_PROVIDER=ollama # 或 geminiDEFAULT_MODEL=gemma3:4bGEMINI_API_KEY=your-key # 如果用GeminiGITHUB_TOKEN=your-token # 可选,提升API配额
运行
python score.py /path/to/resume.pdf输出:控制台打印评估报告 + CSV(开发模式)。
🎯 谁最适合用?
| HR/招聘专员 | |
| 技术面试官 | |
| 招聘经理 | |
| 人力资源系统开发者 | |
| 求职者(自我测试) | |
| 对数据隐私敏感的组织 |
一个典型的“批量筛选”场景
问题:某科技公司收到300份技术岗简历。HR团队只有2个人,要在一周内筛出50份进入下一轮。
传统方式:每人分150份,每份5-8分钟,总计10-20小时。精神疲劳后判断质量下降。
Hiring Agent方式:
批量运行 python score.py resume_001.pdf、resume_002.pdf……输出所有候选人的评分和CSV HR按评分排序,优先看高分候选人的详细报告 结合报告里的证据(开源贡献、项目质量)做决策
时间:300份简历,自动化跑完约30分钟(模型推理时间)。HR用2小时看完高分候选人的详细报告。
效率提升:10倍以上。
⚙️ 技术亮点
1. 模块化设计,可替换每个环节
2. 严格的评分约束
避免“套利”:不能用“我参与了Linux内核开发”拿高分,必须提供可验证的GitHub证据 保证公平:同样条件下,评分标准一致 证据驱动:每条分数都要有具体依据
3. 缓存机制(开发模式)
PDF解析结果缓存,不用重复读文件 GitHub数据缓存,不用重复拉取API 方便迭代调试和批量跑
⚠️ 注意事项
1. 它不是“决策工具”,是“信息工具”
它提供结构化的评分和证据 最终招不招,还是要看面试、文化匹配、团队需求
2. GitHub不是唯一的评估维度
候选人可能没有GitHub账号(尤其是非技术岗或资深专家) 没有GitHub信号时,评分会依赖其他维度
3. 本地运行需要足够的硬件
4B模型(如gemma3:4b)在普通笔记本上可跑 更大模型需要更多内存/显存
🔗 链接
- GitHub
:github.com/interviewstreet/hiring-agent - 许可证
:MIT - 作者
:HackerRank
✅ 总结
| 解决了什么 | |
| 核心能力 | |
| 怎么用 | python score.py resume.pdf |
| 谁适合 | |
| 成本 |
Hiring Agent —— 让简历筛选,从“凭感觉”变成“看证据”。MIT协议,开源免费,数据自托管。
全文完。既然已经看到这里,请随手点个“赞”和“在看”吧。
◆ 发愿:四十如年少◆

公众号:为郎
更多项目实战部署、问题答疑尽在知识星球:

