夜雨聆风
夜雨聆风粉丝福利:送你一份Claude Skill 构建完全指南,添加vx领取:laohu_224
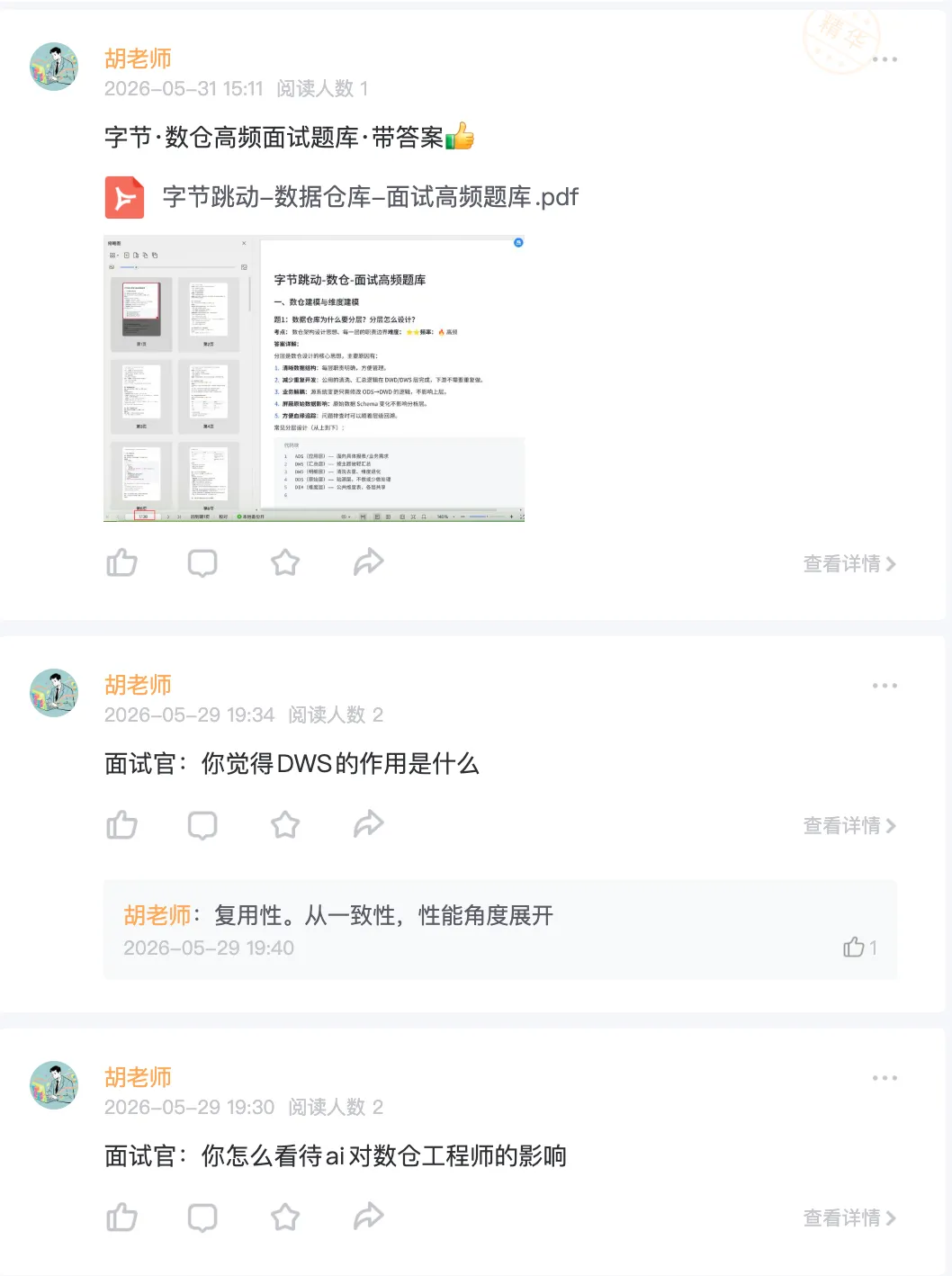
一、为什么你需要一个私有的 RAG 系统
知识管理这件事,大多数人都没想明白。大家都在用各种笔记软件、AI 聊天工具、知识库产品,但很少有人意识到一个尴尬的事实:你用 ChatGPT 查过的每一个私有文档,本质上都在把自己的数据交给别人托管。这不是隐私偏执的问题,而是在很多场景下,数据根本就不该离开你的机器。
RAG 的概念这两年被反复提起。Retrieval-Augmented Generation,检索增强生成,说人话就是:不靠 AI 的记忆力,而是让 AI 先查你的资料库,再基于查到的内容回答问题。这和直接问大模型有天壤之别。直接问,模型是在猜——它的训练数据里可能根本没有你的私域内容。而 RAG 的工作方式是:你给它一份手册、一个知识库、一堆公司文档,它会先在这堆材料里找到相关段落,然后在上下文中生成回答。
大部分人接触 RAG 是从各种云服务开始的。企业级的 RAG 平台一个比一个贵,个人版的产品又往往限制多、不够灵活。自己搭一个?网上教程要么太浅,要么默认你是 DevOps 老手。个人 RAG 系统的核心价值不在于技术复杂度,而在于数据主权——你不需要把笔记、论文、内部文档上传到任何第三方,所有处理都在本地完成。
另一个被忽略的点是场景定制。SaaS 化的 RAG 工具往往对一个维度优化得最好——通用问答。但你很可能需要针对特定领域做调优,比如你的论文库、技术手册、项目文档。这个时候,自己搭一个意味着你能控制 chunk 策略、embedding 模型、检索逻辑、甚至 prompt 模板。这带来的体验提升,不是调几个参数能比的。
所以在动手之前,先想清楚一个问题:你到底需要 RAG 解决什么痛点?是每天翻几十篇论文记不住?是团队知识散落在各处找不到?还是单纯不想把私有数据交给任何云服务?动机不同,搭建方式也差很多。这个问题想明白了,后面每一步都会走得顺。
二、RAG 的核心系统拆解
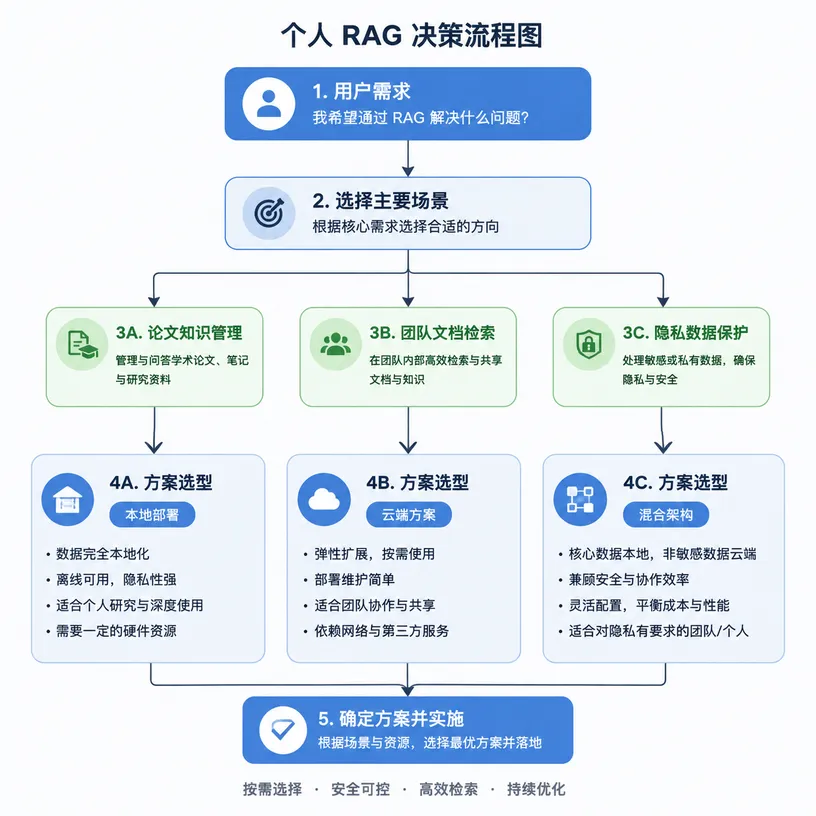
真正动手之前,理解 RAG 的内部结构很有必要。整个系统可以拆成五个核心模块,每个模块都有不同的技术选型空间。
文档解析层是数据进入系统的第一道关卡。PDF、Markdown、Word、网页,这些格式的解析质量直接决定后续检索效果。一个常见踩坑点是:PDF 里的表格和图表如果解析不充分,检索的时候就根本拿不到这些信息。大多数开源方案用 Unstructured 或 LlamaParse 做解析,后者对复杂排版的 PDF 表现更好,但需要 API token。纯本地方案可以选 PyMuPDF 配合正则处理,代价是需要手写不少规则。
文本分割层决定了知识库的粒度。分割太大,一个块里包含多个主题,检索结果会混杂;分割太小,单个块信息量不足,AI 看了也断章取义。通常建议 512-1024 token 一个 chunk,重叠 128-256 token。但这只是一个起点。更靠谱的做法是根据文档结构来切:Markdown 按标题分、PDF 按段落分、代码按函数分。Llamaindex 的 SentenceSplitter 和 Langchain 的 RecursiveCharacterTextSplitter 是比较成熟的选择。
向量化层负责把文本块转成向量。这个环节的选型直接影响检索精度。本地部署的话,BAAI 的 bge-large-zh-v1.5 在中文场景表现不错,大概 1.3GB 显存占用。如果机器配置够,也可以上 intfloat 的 e5-mistral-7b-instruct,但需要 16GB 左右显存。选 embedding 模型的核心原则是:和你的文档语言匹配。中文文档就别用纯英文模型,效果会差一截。
检索层是 RAG 的引擎。最基础的方案是向量相似度检索,用 cosine 距离算最近邻。但真正好用的 RAG 系统不会只用向量检索。混合检索——向量相似度 + BM25 关键词匹配——在大多数场景下效果更好。原因是:向量检索擅长语义匹配但不擅长精确匹配,BM25 正好补上这个短板。Elasticsearch 和 Qdrant 都原生支持混合检索。
生成层就是接一个大模型来回答问题。本地可以用 ollama 跑 llama 或 Qwen 系列,云端可以接 GPT-4 或其他 API。这里有个容易被忽略的细节:生成层的 prompt 设计决定了回答质量。不是把检索结果和问题直接丢给模型就能得到好回答。你需要告诉模型什么情况下说不知道、怎么引用原文、回答格式是什么。这几行 prompt 差一个标点,效果都可能天差地远。
三、落地过程中的几个关键坑
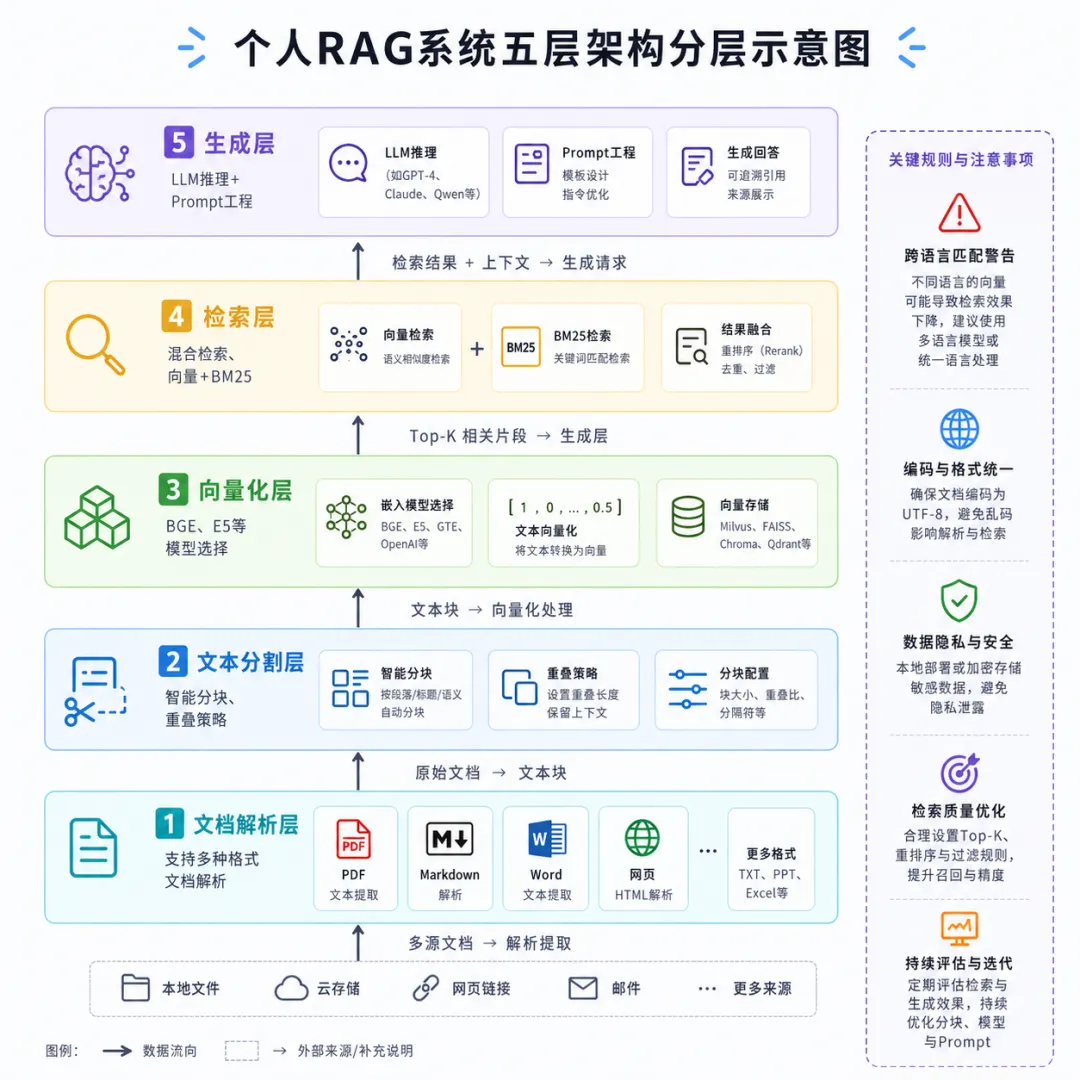
搭建 RAG 的过程中,很多人栽在了同一个地方:把 RAG 想得太简单了。以为装几个开源项目、跑一个 docker-compose,就能得到一个好用的知识库。结果发现回答质量一言难尽,要不就是答非所问,要不就是压根找不到该用的信息。
第一个坑是 embedding 模型选型不当。中文场景下,不少人直接用了 OpenAI 的 text-embedding-ada-002。这个模型在全英文语料上表现确实好,但在中文文档上差强人意。对比测试下来,bge-large-zh-v1.5 在中文段落检索上能高出 5-8 个百分点的 Hit Rate。而且 bge 是开源的、能本地跑、不用走 API。如果你的文档以中文为主,优先选中文预训练的 embedding 模型,这个选择对检索质量的影响比想象中大得多。
第二个坑是 chunk 策略太粗糙。大多数 RAG 框架默认的 chunk 策略就是按固定 token 数切,但这对结构化的技术文档非常不利。一个技术文档中的代码示例和说明文字是绑定的,如果硬切开会把代码和解释分到不同的 chunk,检索时模型只能拿到一半信息。更好的做法是基于文档结构来做分割:给 Markdown 标题加权、保留代码块的完整性、表格不做跨行切分。Llamaindex 的 SemanticSplitterNodeParser 会根据语义边界来切,比固定 token 切法好不少。
第三个坑和检索有关。向量相似度检索有个天然缺陷:对高频词和停用词不敏感。比如你在文档里反复提到 RAG 这个词,所有 chunk 都有这个向量信号,检索时相关性拉不开差距。混合检索把 BM25 关键词匹配加进来后,能有效补偿这个问题。ES 里配一下 knn 和 bm25 的组合查询,或者用 Qdrant 的 payload 过滤,都能达到效果。预算有限的话,甚至可以用 Python 写一个简单的重排序层——先用向量召回 Top 50,再算一遍 BM25 得分,取交叉排名前 10 送去给大模型。
第四个坑不太容易被发现,但影响很大:query 和 document 之间的语义 gap。用户的问法和文档的表述往往不是同一个句子。比如文档里写的是金融行业数据模型设计原则,用户问的是你们平台怎么建模。这两者语义接近但表述不同,纯向量检索可能匹配不上。解决方案是做 query 改写:在给用户回答问题之前,先让模型把问题改写成更贴近文档表述的形式。这个改写步骤往往能让检索命中率提升 10-15%,而且几乎零成本。
第五个坑是关于生成质量的幻觉控制。RAG 的核心价值之一是减少幻觉,但并不能完全消除。如果检索到的上下文和问题关联度不够,大模型还是会靠自己的知识来补,补出来的东西就不可控了。比较实用的做法是:在 prompt 中明确告诉模型如果找不到相关信息就如实说找不到,不要自己编造来源。同时在回答中要求模型标注引用来源的 chunk 编号,方便人工核实。这不能完全杜绝幻觉,但至少能让你知道回答的依据是什么。
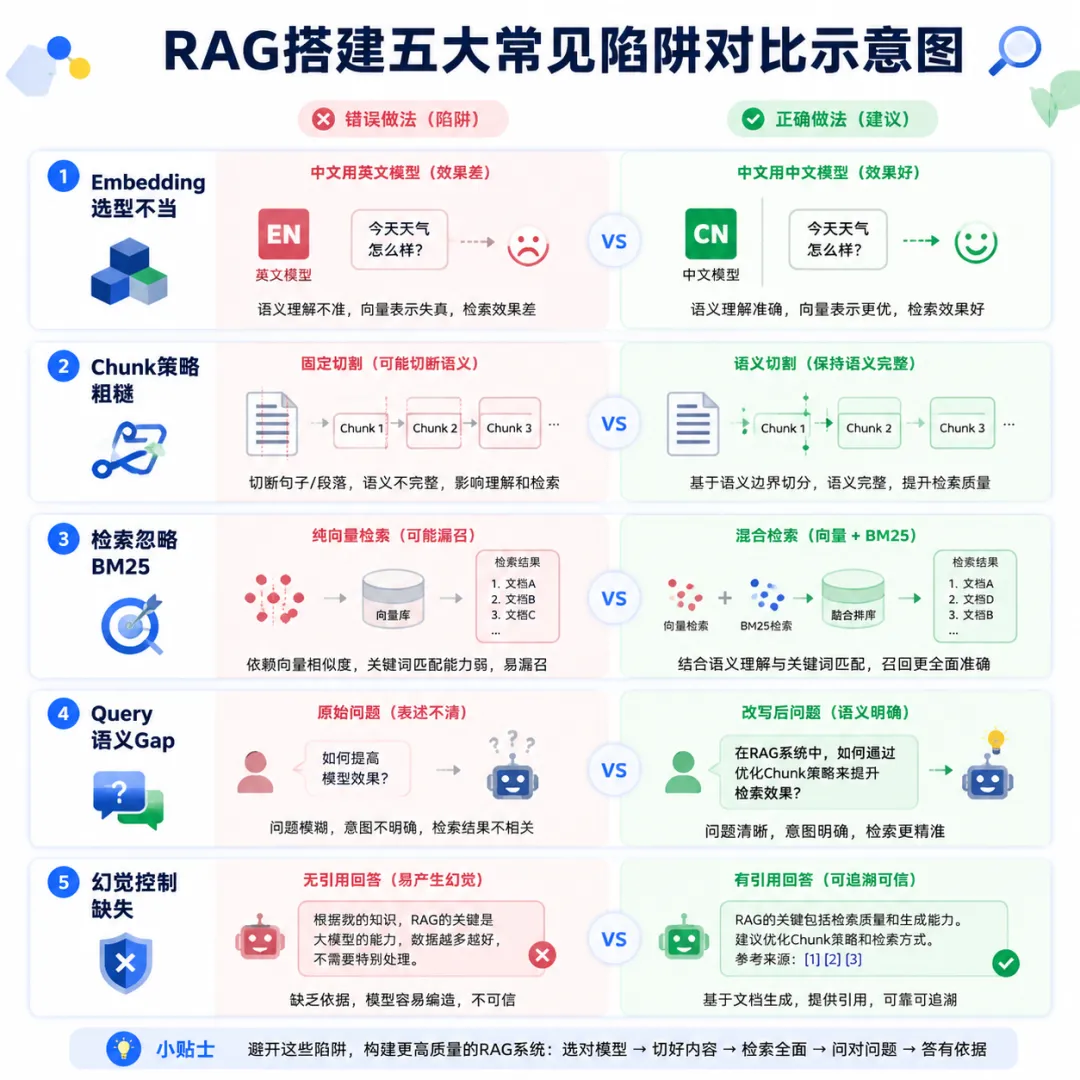
四、从零搭建一个可用的 RAG 系统
选型之前先评估一下自己的设备。本地跑 RAG 至少需要 16GB 内存和 50GB 磁盘。如果要跑 7B 级别的大模型,最好有 8GB 以上显存。没有 GPU 也不是不行,用 CPU 跑 3B 左右的模型配合 ollama,在大部分场景下已经够用。
选哪个 RAG 框架是第一个选择题。目前主流的有三个选项:Langchain 生态最丰富但抽象层太多,调一个参数要翻三层文档;Llamaindex 对 RAG 场景更专注,API 设计也更直观,推荐入门用;Dify 提供可视化搭建,适合不想写代码的团队,但灵活性稍差。个人搭建的话,Llamaindex 是功能完整度和学习曲线平衡最好的选择。
部署流程可以简化成三步。第一步,安装 ollama 拉起 Qwen2.5-7B-Instruct 作为生成模型,再拉起 bge-large-zh-v1.5 作为 embedding 模型。两条命令就够了。第二步,用 Llamaindex 的 VectorStoreIndex 把本地文档索引起来。指定好文档目录、embedding 模型和 chunk 参数,差不多 20 行代码。第三步,配一个基础的检索问答 pipeline,设定 top_k 为 5,temperature 为 0.2。跑起来之后先用自己的文档试一遍,看看召回效果。
这是最简配置,但生产级的 RAG 需要在这之上加几层优化。第一层是文档预处理流水线,把 PDF 转成 Markdown、清洗掉页眉页脚和页码。第二层是检索后重排序,用 cross-encoder 模型把召回的结果再排一遍,很多不相关的文档在这一步就被过滤掉了。第三层是对话记忆,让 RAG 能记住上下文,而不是每次都是独立的问答。这些优化加上去后,体验会有质的提升。
存储层的选择也需要花心思。文本和向量分开存还是合在一起存,各有利弊。Chroma 对个人开发者最友好,装一个 pip 就能用。Qdrant 性能更好但需要多维护一个服务。ES 功能最强但配置复杂。个人场景建议从 Chroma 起步,等数据量到了几十万条以上再考虑迁移。
五、个人 RAG 的进阶玩法和选型思考
当基础的 RAG 跑通之后,大多数人都会遇到同一个瓶颈:通用配置下效果还行,但针对性不强。这时候就需要进入调优阶段了。
Agent+RAG 是目前比较被看好的演进方向。传统的 RAG 是被动式的——你问什么,它查什么。但 Agent 模式的 RAG 可以主动规划:先判断问题需要什么信息,然后分步骤去不同索引中检索,最后汇总回答。比如你问这个月的销售数据为什么下滑,Agent 类型的 RAG 会先去销售数据库中查数字,再去聊天记录中查客户反馈,最后把两个结果综合起来。LlamaIndex 的 AgentRunner 和 LangGraph 都是这条路。
多索引架构也是升级中常见的选择。人不会把所有书堆在一个房间里,RAG 也一样。不同领域、不同格式的文档应该分库存储,配不同的 chunk 策略和 embedding 模型。技术文档按标题切分、论文按摘要和正文分别索引、对话记录按时间窗口切。检索时根据问题类型路由到对应的索引,效率和准确率都会更好。
成本方面,本地 RAG 最大的开销是电费和硬件折旧。一台带 3080 的机器跑 7B 模型的功耗大概 300W 左右,24 小时开的话,电费一天不到两块钱。相比之下,通过 API 调用 GPT-4 做 RAG,看文档量大小,一个月几百到几千都很正常。数据量越大、查询越多,本地的成本优势越明显。当然,如果文档只有几十页、一天只问几次,那用云服务反而更划算。
一个容易被忽视但很重要的思考:RAG 不是银弹。有些场景下它表现很好,比如需要翻阅大量技术文档的 QA 场景。但在需要深度推理、多步计算、或者处理高度结构化的数据时,RAG 的优势并不明显。把 RAG 和传统数据库、或者直接的大模型推理结合,往往比纯 RAG 效果好。这也是为什么很多团队在实际落地时选择了 hybrid 方案——用 SQL 处理结构化查询、用 ES 做关键词检索、用向量做语义匹配,三个结果再合并排序。
整体回顾来看,搭建个人 RAG 其实不是技术难度的问题,而是思路问题。很多人花大量时间在调 embedding 参数和 chunk 大小上,却在文档预处理和 prompt 设计上一笔带过。实际情况是:高质量的知识库清理往往比调模型参数更能提升最终效果。花一周整理好文档结构、建好索引策略,可能比花一个月调模型参数收益更大。这大概也是做技术的人容易犯的错——总想用更复杂的方案解决简单的问题。
获取更多大厂数仓面试资料和信息! 长按扫描下方二维码进入星球下载 ⏬ 扫码即可加入星球👇,现在加入可以免费获取胡老师1V1辅导一次 ⛽️