



文档内容
2024 学年第一学期质量检测高二技术试卷
出题:胡小英 审题:胡沛茹
考生须知:
1.本试卷分两部分,第一部分信息技术,第二部分通用技术。满分100分,考试时间90分钟。
2.考生答题前,务必将自己的姓名、准考证号用黑色字迹的签字笔或钢笔填写在答题纸上。
3.选择题的答案用2B铅笔将答题纸上对应题目的答案选项涂黑,如要改动,须将原填涂处用
橡皮擦净。
4.非选择题的答案用黑色字迹的签字笔或钢笔写在答题纸上相应区域内,作图时可先使用2B
铅笔,确定后用黑色字迹的签字笔或钢笔描黑,答案写在非答题纸上无效。
第一部分 信息技术(共 50 分)
一、选择题(本大题共12小题,每小题2分,共24分,每小题列出的四个备选项中只有一个是符合
题目要求的,不选、错选、多选均不得分。)
阅读下列材料,回答第1至3题:
某市开发部署了一个智能交通系统,通过摄像头和传感器等设备采集交通流量、车辆速度、道
路拥堵状况等数据,并通过数据分析为交管部门提供信息决策支持,市民也可以通过APP查询实时
的路况信息和出行路线建议。
1. 关于该智能交通系统中数据的描述,不正确的是
...
A. 该系统中的数据都依附于同一载体 B. 该系统的数据采集以机器获取为主
C. 该系统采集处理的数据属于大数据 D. 该系统通过摄像头采集的数据是非结构化数据
2. 下列关于数据安全与保护的做法,合理的是
A. 为系统不同的授权用户设置相同的权限
B. 用磁盘阵列技术存储数据保障数据安全
C. 公开交通违章人员人脸头像信息以起到警示宣传的作用
D. 在服务器存放系统相关账号密码的文本文档以防遗忘
3. 下列系统的数据处理方式,不合理的是
...
A. 将视频转换成MPG格式以减少存储空间
B. 将拍摄到的违章车牌号码识别成为文本并保存
C. 该系统的所有数据统一采用批处理方式进行处理
D. 提高该系统音频采集时采样频率和量化位数可以提升音质
4. 下列关于人工智能中联结主义的说法,正确的是
A. 强调符号的推理和运算 B. 专注于知识的精确编码和存储
C. 模仿人类大脑中神经元之间的交互 D. 关注智能体与环境之间的交互和反馈
5. 下列有关数字化及数据编码的说法正确的是
A.模拟信号转为数字信号的过程中不会产生失真
B.不能通过采样、量化和编码的方式将图像信号数字化
C.计算机RGB颜色模式中,RGB(255,255,255)表示白色
D.若某BMP图像的颜色共258种,则其位深度至少为8位
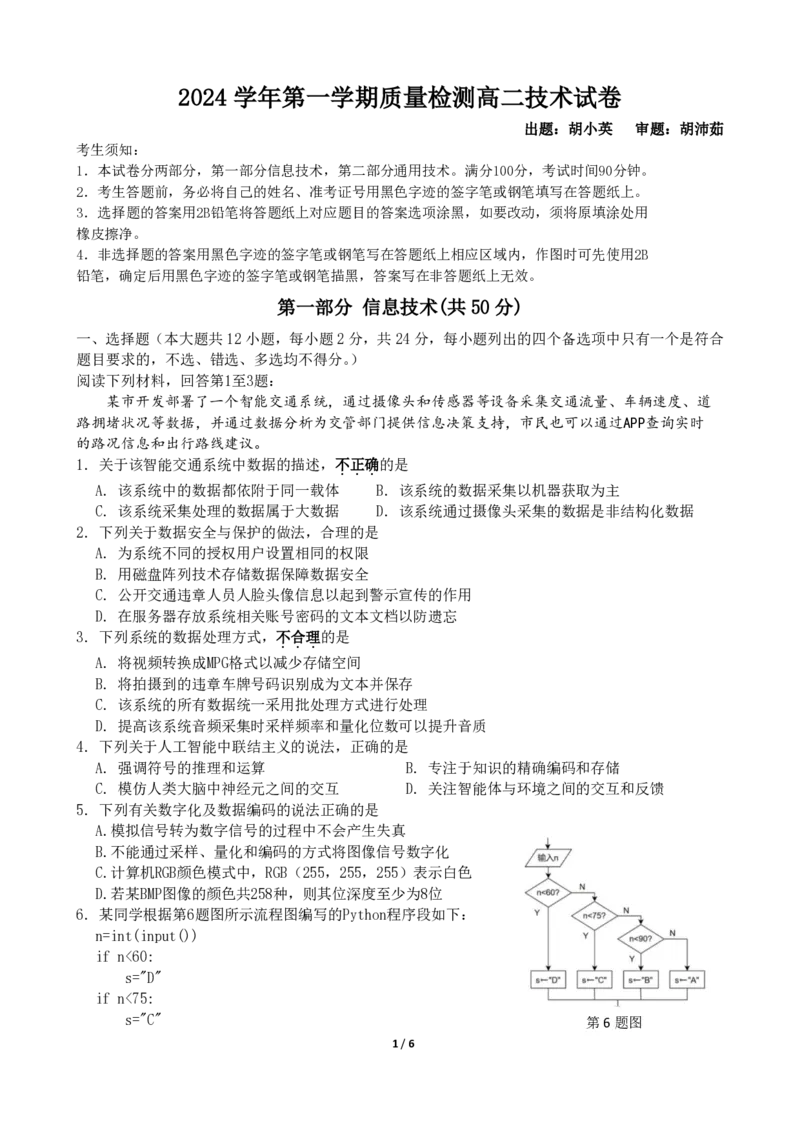
6. 某同学根据第6题图所示流程图编写的Python程序段如下:
n=int(input())
if n<60:
s="D"
if n<75:
s="C" 第6题图
1 / 6elif n<90:
s="B"
else:
s="A"
用下列输入数据测试程序段与流程图,两者得到的s 值不同的
A. 100 B. 75 C. 60 D. 50
7.采用冒泡排序算法对数据序列“22,35,43,56,19,8”完成升序排序,需要交换的次数为
A. 9 次 B. 12 次 C. 15 次 D. 21 次
8.某递归函数,功能是输入一个字符串s,输出其反序字符串。例如输入时“hello”时,输出“olleh”。
程序代码如下:
def reverse(s):
if len(s)<=1:
return s
return
划线处应填入的代码是
A.s[-1]+reverse(s[1:]) B.reverse(s[1:])+s[-1]
C.s[-1]+reverse(s[:-1]) D.reverse(s[:-1])+s[-1]
9.有如下程序段,执行后输出的第一行是:
def move(n,a,b,c):
if n==1:
print(a,"->",c)
return
move(n-1,a,c,b)
move(1,a,b,c)
move(n-1,b,a,c)
move(4,'A','B','C')
A.C->A B.C->B C.A->B D.A->C
10.有如下Python程序段:
#生成6个随机整数,存入列表元素a[0]到a[5]中,代码略
b=[0]*6
for i in range(1,6):
for j in range(i):
if a[i]>a[j]:
b[i]+=1
print(sum(b))
则该算法的时间复杂度为
A.O(1) B.O(log n) C.O(n) D.O(n2)
2
11.对某校高三年级学生按性别和身高进行排序,每个学生的数据格式如下:["徐凯",175,'男'],排
序要求:女生在前,男生在后,同性别按身高升序排序。实现功能的Python程序如下:
# 将高三年级全体学生性别和身高数据读入二维列表a中,代码略
n=len(a)
for i in range(n-1):
for j in range( ① ):
if ② :
a[j],a[j+1]=a[j+1],a[j]
2 / 6elif a[j][2]=="男" and a[j+1][2]=="女":
a[j],a[j+1]=a[j+1],a[j]
A.①0,n-i-1 ②a[j][1]>a[j+1][1] and a[j][2]==a[j+1][2]
B.①n-2,i,-1 ②a[j][1]a[j+1][1] and a[j][2]==a[j+1][2]
D.①n-2,i-1,-1 ②a[j][1]a[m]:
i=m+1;n=n+1
else:
j=m-1;n=n-1
执行该程序段后,下列说法正确的是
A. 变量i的值可能为4 B. 变量n的值范围为[-3,3]
C. 数组f中至少有3个元素值为1 D. 数组f的值可能为[0,0,0,0,1,0,1,1,1]
二、非选择题(本大题共3小题,其中第13小题7分,第14小题9分,第15小题10分,共26分)
13.列表nums有n(n>2)个整型元素,现要查找出缺失的第1个正整数并输出。若1 ~ n 中没有缺失
某个正整数,则输出n+1。例如nums=[3,2,-1,0],则缺失的第1个正整数为1。例如nums=[1,2,3,4,5,6],
则缺失的第1个正整数为7。实现该功能的部分程序段如下:
def findz(nums):
n=len(nums)
for i in range(n):
if 1<=nums[i]<=n:
p=nums[i]-1
if :
nums[p],nums[i]=nums[i],nums[p]
for i in range(n):
if ① :
return i+1
return ②
#列表nums 中存储了n 个整型元素,代码略
#调用函数findz,并输出结果,代码略
(1)若nums=[-5,4,3,-1,0,1],则缺失的第1个正整数为 。
(2)方框中应填入的代码为 (单选,填字母)。
A.nums[p] > 0 B.nums[p] != nums[i] C.nums[p] > nums[i]
(3)请在划线处填入合适的代码。
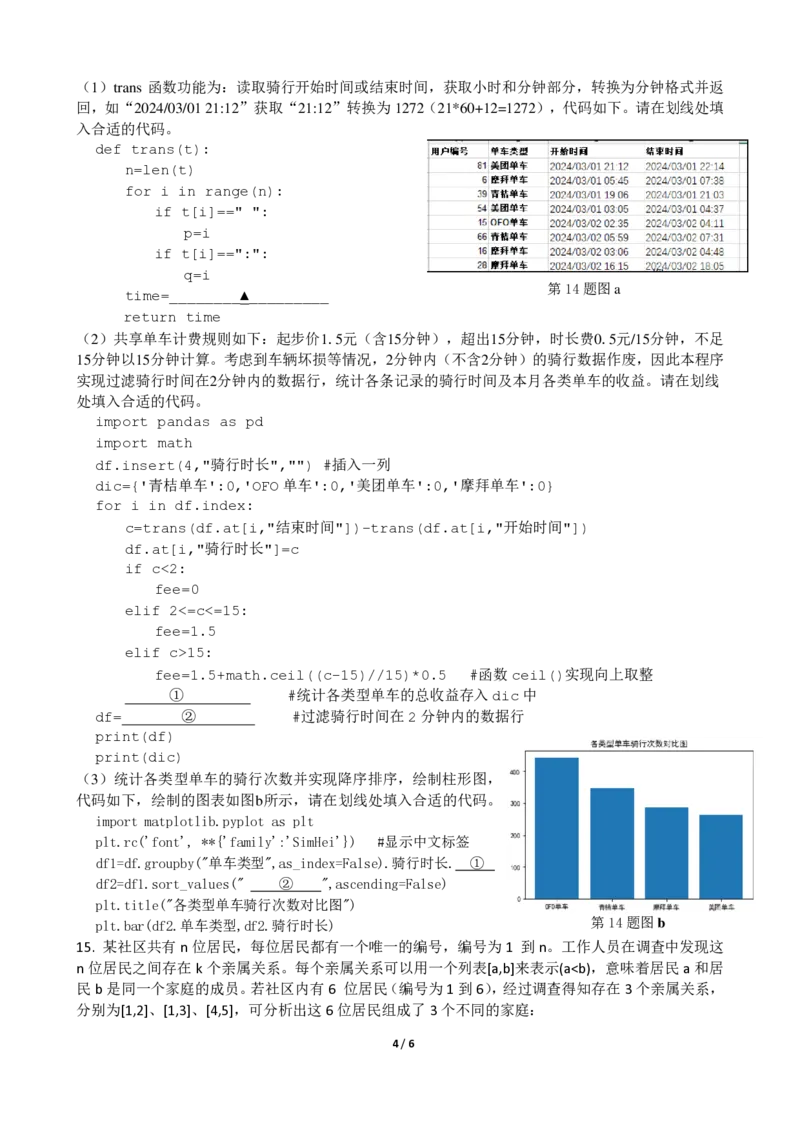
14. 小明收集了浙江省某地3月各类共享单车的部分骑行数据记录,每天的用户数据存储在
“bike.xlsx”文件中(不考虑跨天数据)。部分数据格式如第14题图a所示,请回答下列问题:
3 / 6(1)trans 函数功能为:读取骑行开始时间或结束时间,获取小时和分钟部分,转换为分钟格式并返
回,如“2024/03/01 21:12”获取“21:12”转换为1272(21*60+12=1272),代码如下。请在划线处填
入合适的代码。
def trans(t):
n=len(t)
for i in range(n):
if t[i]==" ":
p=i
if t[i]==":":
q=i
第14题图a
time=________▲_________
return time
(2)共享单车计费规则如下:起步价1.5元(含15分钟),超出15分钟,时长费0.5元/15分钟,不足
15分钟以15分钟计算。考虑到车辆坏损等情况,2分钟内(不含2分钟)的骑行数据作废,因此本程序
实现过滤骑行时间在2分钟内的数据行,统计各条记录的骑行时间及本月各类单车的收益。请在划线
处填入合适的代码。
import pandas as pd
import math
df.insert(4,"骑行时长","") #插入一列
dic={'青桔单车':0,'OFO单车':0,'美团单车':0,'摩拜单车':0}
for i in df.index:
c=trans(df.at[i,"结束时间"])-trans(df.at[i,"开始时间"])
df.at[i,"骑行时长"]=c
if c<2:
fee=0
elif 2<=c<=15:
fee=1.5
elif c>15:
fee=1.5+math.ceil((c-15)//15)*0.5 #函数ceil()实现向上取整
① #统计各类型单车的总收益存入dic中
df= ② #过滤骑行时间在2分钟内的数据行
print(df)
print(dic)
(3)统计各类型单车的骑行次数并实现降序排序,绘制柱形图,
代码如下,绘制的图表如图b所示,请在划线处填入合适的代码。
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'}) #显示中文标签
df1=df.groupby("单车类型",as_index=False).骑行时长. ①
df2=df1.sort_values(" ② ",ascending=False)
plt.title("各类型单车骑行次数对比图")
plt.bar(df2.单车类型,df2.骑行时长) 第14题图b
15. 某社区共有n位居民,每位居民都有一个唯一的编号,编号为1 到n。工作人员在调查中发现这
n位居民之间存在k 个亲属关系。每个亲属关系可以用一个列表[a,b]来表示(a=0:
if x>=0 and lst1[x][0]>lst2[y][0]:
lst1[tail]=lst1[x]
x-=1
else:
lst1[tail]=lst2[y]
y-=1
tail-=1
return lst1
若lst1为[[1,2],[3,4],[10,11],[12,13],[17,18]],
lst2为[[5,6],[9,10],[14,15],[15,16],[19,20]],调用merge(lst1,lst2)函数, 则语句
“lst1[tail]=lst1[x]”的执行次数为 ▲ 。
(3)实现上述功能的部分Python程序如下,程序中用到的列表函数与方法如第15题图所示,请在程
序中划线处填入合适的代码。
函数与方法 功 能
w.append(x) 在列表w末尾添加元素x
x=w.pop() 将列表w末尾元素赋值给x ,并将其从w 中删除
def check(x):
num=0
q.append(x)
f[x]=1
num+=1
while ① :
t=q.pop()
for i in range(0,len(s[t])):
if f[s[t][i]]==0:
q.append(s[t][i])
f[s[t][i]]=1
5 / 6num+=1
return num
n=int(input("请输入社区总人数:"))
q=[]
f=[0]*(n+1)
total=0;maxsum=0
'''读取csv文件中的关系数据,存入列表r1、r2,2个列表中的每个元素包含2个数据
项,分别存放一对亲属关系。2个列表的数据已分别按编号升序排列,代码略'''
a=merge(r1,r2) #根据列表r1、r2 中亲属关系数据,进行合并排序
s=[]
for i in range(n+1):
s.append([]) #s[i]初始为空列表,存放编号为i的居民直接相关的亲属编号
k=len(a)
for i in range(k):
②
for i in range(1,n+1):
if f[i]==0:
tmp=check(i)
if tmp>maxsum:
maxsum=tmp
③
print(n,'位居民中总共有', total,'个不同的家庭')
print('最大的家庭中有',maxsum,'人')
6 / 6
