 夜雨聆风
夜雨聆风





PyQt5神器级批量图片下载工具
效果图
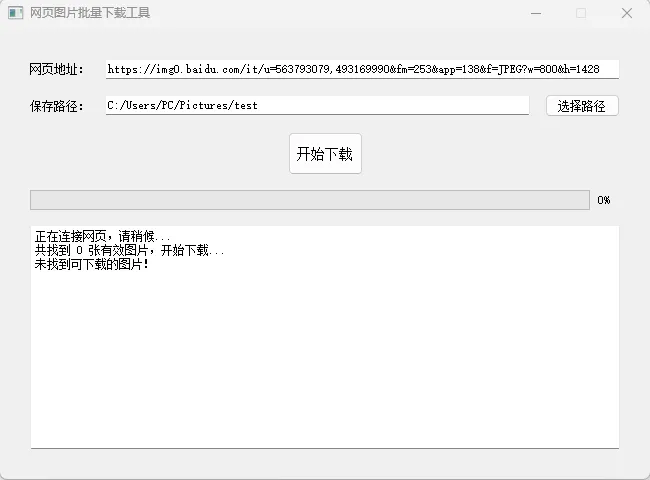
在日常工作、学习、素材整理的过程中,你一定经常遇到这样的需求:看到网页上精美的插画、素材图、产品图,想要批量保存下来,但一张一张右键保存实在太费时间;有些网页限制了右键保存,手动操作更是寸步难行;做自媒体需要快速收集配图、设计师需要批量采集灵感素材、学生党需要整理学习资料图片,手动下载不仅效率低下,还容易遗漏图片、浪费大量时间。
有没有一款零代码、可视化、一键操作的工具,能自动抓取网页上的所有图片,还能自定义保存路径、实时查看下载进度、过滤无效图片?今天就给大家带来一款完全用Python+PyQt5开发的网页图片批量下载工具!
这款工具无需复杂配置,打开即用,只需要输入目标网页链接,选择本地保存文件夹,点击启动就能自动爬取网页中所有有效图片,支持主流图片格式(jpg、png、gif、bmp、webp等),自带进度条实时显示下载状态,下载完成后自动打开文件夹,直观又便捷。工具采用GUI图形化界面,小白也能轻松上手,代码开源可扩展,无论是日常使用还是学习Python爬虫、GUI开发,都是绝佳的选择!
接下来,我将手把手带你拆解这款工具的代码,从界面搭建、核心爬虫逻辑到功能优化,全方面解析,让你不仅能直接使用成品工具,还能理解背后的实现原理,甚至可以根据自己的需求二次开发!
一、工具核心功能一览
-
PyQt5可视化界面:简洁美观,操作无门槛 -
一键批量下载:输入URL自动抓取所有图片 -
自定义保存路径:自由选择图片存储位置 -
实时进度显示:进度条+文本提示,下载状态一目了然 -
异常自动处理:过滤无效链接、破损图片,跳过下载失败文件 -
格式自动适配:支持所有主流网页图片格式 -
下载完成自动打开目录:快速查看下载结果
二、核心代码模块详细解析
本工具分为三大核心模块:GUI界面搭建模块、网页图片爬取模块、下载控制与进度更新模块,我们逐一拆解讲解。
模块1:PyQt5界面主窗口搭建
这是工具的可视化核心,我们使用QMainWindow创建主窗口,搭配输入框、按钮、进度条、文本浏览器等组件,构建美观易用的操作界面。 核心功能:
-
设置窗口标题、大小、样式 -
创建URL输入框、路径选择按钮、下载按钮 -
添加进度条和日志输出框 -
绑定按钮点击事件,实现交互逻辑
模块2:网页图片解析与爬虫核心
这是工具的灵魂,通过requests请求网页源码,用BeautifulSoup解析HTML,提取所有img标签的src属性,自动补全相对路径,过滤无效链接。 核心功能:
-
发送HTTP请求获取网页内容 -
解析HTML提取所有图片URL -
自动处理相对路径/绝对路径 -
去重处理,避免重复下载
模块3:多线程下载与进度控制
为了避免界面卡顿,我们使用QThread实现多线程下载,实时更新进度条和日志信息,逐一下载图片并保存到本地。 核心功能:
-
多线程分离界面与下载逻辑 -
实时更新下载进度 -
图片写入本地文件夹 -
异常捕获,保证工具稳定性
三、完整源代码(直接复制运行)
环境准备
首先安装依赖库:
pip install pyqt5 requests beautifulsoup4
完整代码
import sys
import os
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QLabel,
QLineEdit, QPushButton, QFileDialog,
QProgressBar, QTextBrowser, QVBoxLayout, QHBoxLayout)
from PyQt5.QtCore import Qt, QThread, pyqtSignal
# 多线程下载工作类
classDownloadWorker(QThread):
# 自定义信号:进度更新、日志输出、下载完成
progress_update = pyqtSignal(int)
log_signal = pyqtSignal(str)
finish_signal = pyqtSignal()
def__init__(self, url, save_path):
super().__init__()
self.url = url
self.save_path = save_path
defrun(self):
try:
self.log_signal.emit("正在连接网页,请稍候...")
# 请求头模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
response = requests.get(self.url, headers=headers, timeout=10)
response.raise_for_status()
# 解析网页图片
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")
img_urls = []
for img in img_tags:
src = img.get("src")
if src:
# 补全相对路径
full_url = urljoin(self.url, src)
# 过滤无效链接
if full_url.endswith(("jpg", "png", "gif", "bmp", "webp", "jpeg")):
img_urls.append(full_url)
# 去重
img_urls = list(set(img_urls))
total = len(img_urls)
self.log_signal.emit(f"共找到 {total} 张有效图片,开始下载...")
if total == 0:
self.log_signal.emit("未找到可下载的图片!")
self.finish_signal.emit()
return
# 逐张下载
success_count = 0
for index, img_url in enumerate(img_urls):
try:
img_response = requests.get(img_url, headers=headers, timeout=10)
img_name = os.path.basename(img_url.split("?")[0])
img_path = os.path.join(self.save_path, img_name)
with open(img_path, "wb") as f:
f.write(img_response.content)
success_count += 1
# 更新进度
progress = int((index + 1) / total * 100)
self.progress_update.emit(progress)
except Exception as e:
self.log_signal.emit(f"图片下载失败:{str(e)}")
continue
self.log_signal.emit(f"下载完成!成功保存 {success_count}/{total} 张图片")
self.progress_update.emit(100)
except Exception as e:
self.log_signal.emit(f"错误:{str(e)}")
finally:
self.finish_signal.emit()
# 主界面类
classImgDownloader(QMainWindow):
def__init__(self):
super().__init__()
self.init_ui()
definit_ui(self):
# 窗口基础设置
self.setWindowTitle("网页图片批量下载工具")
self.setFixedSize(650, 450)
# 核心组件
central_widget = QWidget()
self.setCentralWidget(central_widget)
layout = QVBoxLayout(central_widget)
layout.setSpacing(15)
layout.setContentsMargins(30, 30, 30, 30)
# URL输入区域
url_layout = QHBoxLayout()
url_label = QLabel("网页地址:")
self.url_input = QLineEdit()
self.url_input.setPlaceholderText("请输入需要下载图片的网页URL")
url_layout.addWidget(url_label)
url_layout.addWidget(self.url_input)
layout.addLayout(url_layout)
# 保存路径区域
path_layout = QHBoxLayout()
path_label = QLabel("保存路径:")
self.path_input = QLineEdit()
self.path_input.setPlaceholderText("请选择图片保存文件夹")
self.path_btn = QPushButton("选择路径")
self.path_btn.clicked.connect(self.select_path)
path_layout.addWidget(path_label)
path_layout.addWidget(self.path_input)
path_layout.addWidget(self.path_btn)
layout.addLayout(path_layout)
# 按钮区域
btn_layout = QHBoxLayout()
self.start_btn = QPushButton("开始下载")
self.start_btn.clicked.connect(self.start_download)
self.start_btn.setStyleSheet("height:35px; font-size:14px;")
btn_layout.addStretch()
btn_layout.addWidget(self.start_btn)
btn_layout.addStretch()
layout.addLayout(btn_layout)
# 进度条
self.progress_bar = QProgressBar()
self.progress_bar.setRange(0, 100)
layout.addWidget(self.progress_bar)
# 日志输出框
self.log_browser = QTextBrowser()
self.log_browser.setPlaceholderText("下载日志将在这里显示...")
layout.addWidget(self.log_browser)
# 选择保存路径
defselect_path(self):
path = QFileDialog.getExistingDirectory(self, "选择保存文件夹")
if path:
self.path_input.setText(path)
# 开始下载
defstart_download(self):
url = self.url_input.text().strip()
save_path = self.path_input.text().strip()
# 校验输入
ifnot url ornot save_path:
self.log_browser.append("错误:请填写完整的网页地址和保存路径!")
return
# 禁用按钮,防止重复点击
self.start_btn.setEnabled(False)
self.progress_bar.setValue(0)
self.log_browser.clear()
# 创建并启动线程
self.worker = DownloadWorker(url, save_path)
self.worker.progress_update.connect(self.progress_bar.setValue)
self.worker.log_signal.connect(self.log_browser.append)
self.worker.finish_signal.connect(self.download_finish)
self.worker.start()
# 下载完成回调
defdownload_finish(self):
self.start_btn.setEnabled(True)
# 自动打开文件夹(可选)
try:
os.startfile(self.path_input.text())
except:
pass
# 主程序入口
if __name__ == "__main__":
app = QApplication(sys.argv)
window = ImgDownloader()
window.show()
sys.exit(app.exec_())
四、知识点总结 + 拓展场景 + 测试步骤
1. 核心知识点总结
-
PyQt5 GUI开发 -
掌握主窗口、布局、组件的使用 -
信号与槽机制实现界面交互 -
多线程QThread解决界面卡顿问题 -
Python网络爬虫 -
requests库发送HTTP请求,模拟浏览器访问 -
BeautifulSoup解析HTML,提取目标数据 -
URL路径补全、去重、格式过滤 -
文件操作与异常处理 -
本地文件读写,图片二进制保存 -
全局异常捕获,保证程序稳定运行
2. 拓展应用场景
-
素材网站批量采集:自媒体配图、设计灵感、壁纸批量下载 -
电商产品图抓取:批量下载商品展示图,用于数据分析 -
学习资料整理:网课、博客、文档中的图片一键保存 -
二次开发升级:添加图片筛选、批量重命名、定时下载、代理IP功能 -
打包成exe:使用PyInstaller打包,无Python环境也能使用
3. 工具测试步骤
-
安装依赖库: pip install pyqt5 requests beautifulsoup4 -
复制完整代码,保存为 img_downloader.py -
运行代码,打开工具界面 -
输入测试网页URL(如百度图片、素材网站) -
选择本地保存文件夹 -
点击开始下载,查看进度条和日志 -
下载完成后自动打开文件夹,验证图片是否保存成功
总结
这款基于PyQt5开发的网页图片批量下载工具,完美解决了手动下载图片效率低的痛点,界面美观、功能齐全、操作简单,无论是日常使用还是学习Python编程都非常实用。代码结构清晰,模块化设计易于理解和扩展,你可以在此基础上添加更多个性化功能,打造专属自己的批量下载工具!
如果你是编程新手,这份代码可以帮你快速掌握GUI开发和爬虫基础;如果你是办公人士,这款工具能直接提升你的工作效率,赶紧收藏使用吧!