 夜雨聆风
夜雨聆风





让AI不再「失忆」:CLI编程工具上下文管理实战——问题篇 + 方案篇,一次讲透
最近给团队推广编程工具的时候,被问得最多的三个问题是:
「这个上下文怎么搞?」
「是不是它经常会忘?」
「忘了怎么办?」
说实话,这三个问题问得特别实在。因为上下文确实是CLI编程工具最核心、但也最难理解的概念之一。今天这篇文章,我就把上下文的问题掰开揉碎讲清楚,顺便分享一套我实际在用的分层管理方案。
上篇:上下文是什么,为什么会「忘」
1. 上下文就是AI的「工作台」
你有没有见过那种老师傅的工作台?上面摆满了各种工具、零件、图纸。老师傅心里清楚哪个工具在哪、当前在修什么、下一步要做什么。
AI的「上下文」就是一个类似的概念。当你和AI对话时,AI会把你们聊过的内容、相关的代码、当前的任务状态都「摆」在自己的「工作台」上。这样它才能理解你在说什么、要做什么。
简单来说:上下文就是AI在当前对话中能「记住」的所有信息。
2. 为什么会「忘」?
你可能会问:那为什么AI经常会出现「失忆」的情况?明明刚才聊过的东西,它突然就不记得了。
这里有几种可能:
第一种:空间不够了。
AI处理信息的能力是有限的。每个模型都有一个「上下文窗口」,就像工作台的空间是固定的。当对话内容超过这个限制时,早期的内容就会被「挤掉」。这不是AI真的忘了,而是装不下了。
第二种:换了个新工作台。
每次新建一个对话,都是一个全新的「工作台」。AI不会主动把你的聊天记录带过去,除非你手动复制粘贴或者用其他方式「搬运」上下文。这就是为什么每次重新开始对话时,AI会「一脸懵」。
第三种:工具本身的机制。
不同的编程工具对上下文的管理方式不同。有的工具会自动保存历史对话,有的手动管理,有的靠插件扩展。了解你用的工具的上下文机制,是高效使用的关键。
3. 忘了怎么办?
当AI「忘事」的时候,有几种应对方式:
短期补救:主动续接。 把之前的关键内容总结一下,告诉AI「上次的背景是这样的…」,让AI快速重建上下文。
中期方案:文档管理。 把重要的项目信息、需求背景、技术约束写成文档,存放在固定位置。每次开始新对话时,先让AI读一遍这些文档。
长期方案:分层架构。 搭建一套系统化的上下文管理体系,让长期记忆、项目主线、任务状态各司其职。这是我们下篇要重点讲的方案。
下篇:我的四层分层管理方案
1. 为什么要分层?
在介绍方案之前,先说说为什么需要「分层」。
刚开始用编程工具的时候,我也犯过一个错误:把所有东西都塞进一个文档里。项目规则、技术细节、当前进度、个人偏好…全混在一起。结果呢?文档越来越长,AI越来越慢,有时候找东西比自己写还费劲。
后来结合自己的实际情况,慢慢摸索出了这套分层方案:上下文管理不是靠一个文档兜底,而是靠分层架构。 每一层管好自己的职责,层与层之间互不干扰。
2. 四层架构长什么样?
说白了,这套方案的核心就是:在不同层级维护不同的AGENTS.md文档。
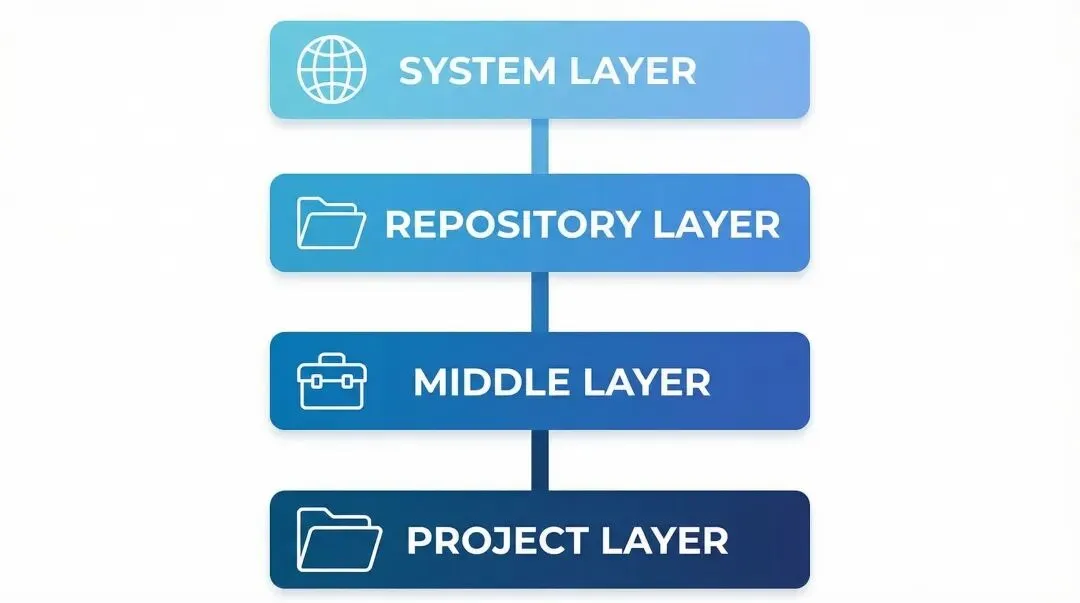
每个层级的 AGENTS.md 各司其职:
|
|
|
|
|---|---|---|
| 系统层 |
|
|
| 仓库层 |
|
|
| 中间层 |
|
|
| 项目层 |
|
|
这个分层的逻辑是:规则只下沉专属事实,不上浮局部细节。
什么意思?所有项目都共用的放系统层,只在这个仓库用的放仓库层,只在这个项目用的放项目层。各守各的边界,不越界、不越权。
3. 载体分工:不同信息写不同地方
光分层还不够,还要回答「具体写到哪里」的问题。
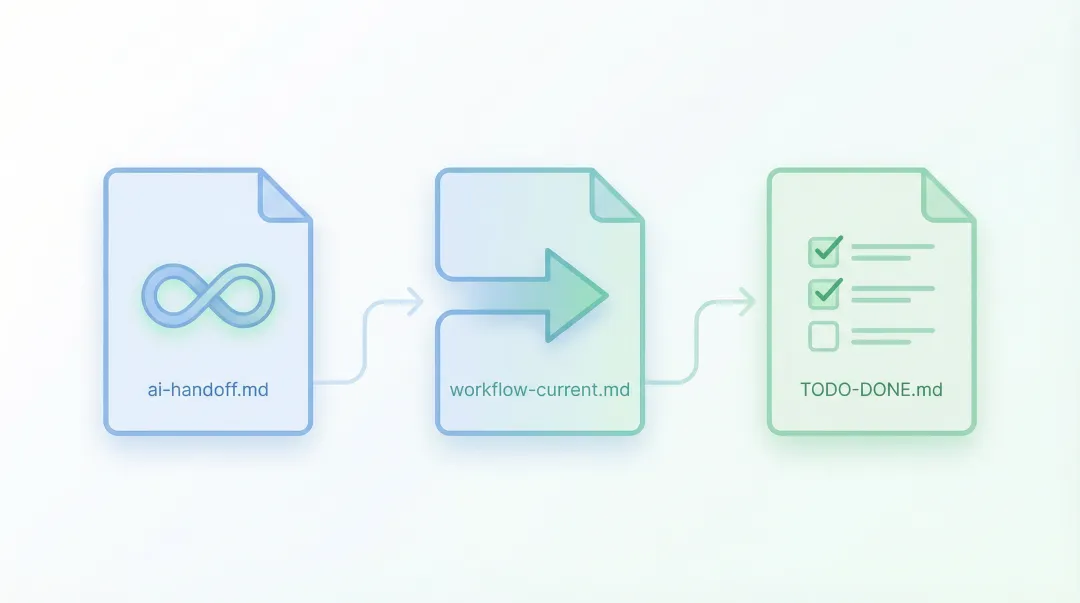
我的方案定义了三种核心上下文载体:
长期稳定事实 → docs/ai-handoff.md
长期有效的目录角色、构建事实、项目约定。简单说就是「下次继续工作仍然成立的东西」。
项目级workflow主线 → docs/workflow-current.md
当前项目在优先推进什么、下一会话沿哪条主线继续。它表达的是项目级现状。
需求台账 → TODO.md / DONE.md
当前待处理的真实需求、已完成事项的归档。
4. 三条设计原则
最后分享三条我一直在用的设计原则:
第一条:长期事实与临时状态分离。
不要把一次性聊天状态塞进长期记忆文档。临时状态用完就扔,长期事实才值得沉淀。
第二条:项目级现状与任务级现状分离。
不要用单次任务的当前状态代替项目主线。项目主线是长期目标,单次任务只是项目的一次执行,两者是全局和局部的关系。
第三条:交接记录必须服从现场核实。
交接文档只能提供线索,不能直接当成现场事实。凡是板端状态、进程、网络、构建结果等可变内容,续接时必须重新核实。
实操效果与下一步
这套方案我已经用了有一段时间了,明显的感受是:
续接效率提高了,踩的坑减少了。
以前经常遇到「AI突然失忆」的尴尬,现在少了。不是因为AI变聪明了,而是因为我知道该把什么信息放在哪里、续接时该从哪里开始。
当然,这套方案还在验证中。下一步我想试试:
-
把这套方法迁移到其他AI工具上 -
看看在更复杂的嵌入式项目中,这套架构是否依然有效 -
能否提炼出可以复用的模板
写在最后
今天的分享就到这里。
关于上下文管理,你有什么困惑或者好的实践?欢迎在评论区聊聊。
另外,如果你在用CLI编程工具时遇到「AI老忘事」的问题,不妨找AI聊聊今天说的分层方案。未必完美,但至少是个可以落地的思路。
我们下期见。