夜雨聆风
夜雨聆风





AI 编码工具的底层架构:Cursor 是怎么给你补全代码的
点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
你每天在用的 AI 编码工具(Cursor、Copilot、Continue),它们的底层是怎么工作的?
你按下 Tab 键接受一行补全建议,背后经历了什么?Cursor 是怎么知道你要写什么代码的?为什么有时候补全精准到离谱,有时候又一坨废话?
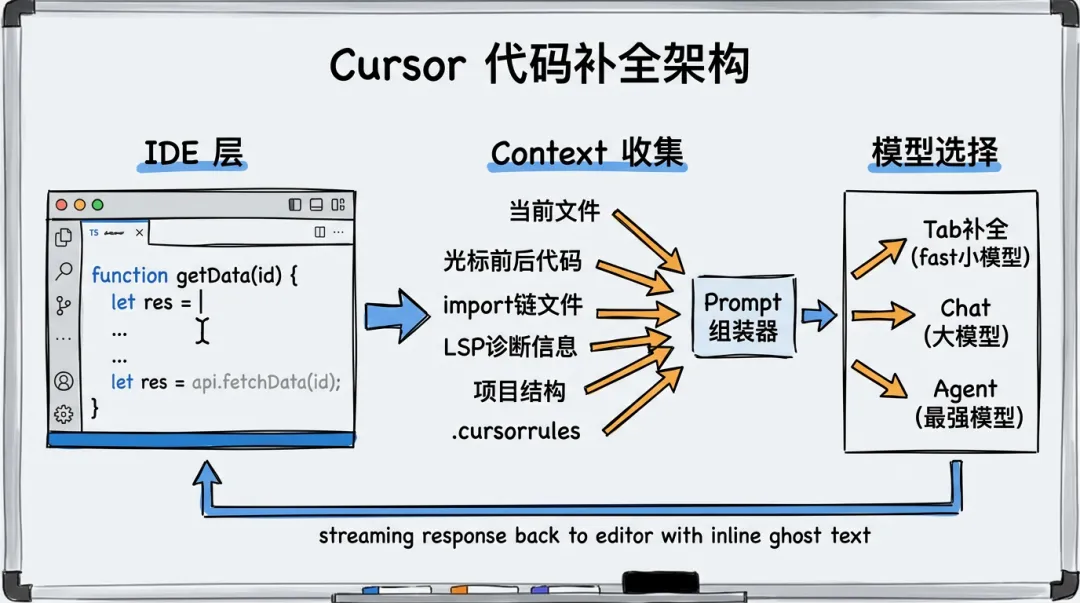
答案藏在三个核心环节里:Context 收集、Prompt 组装、模型选择。
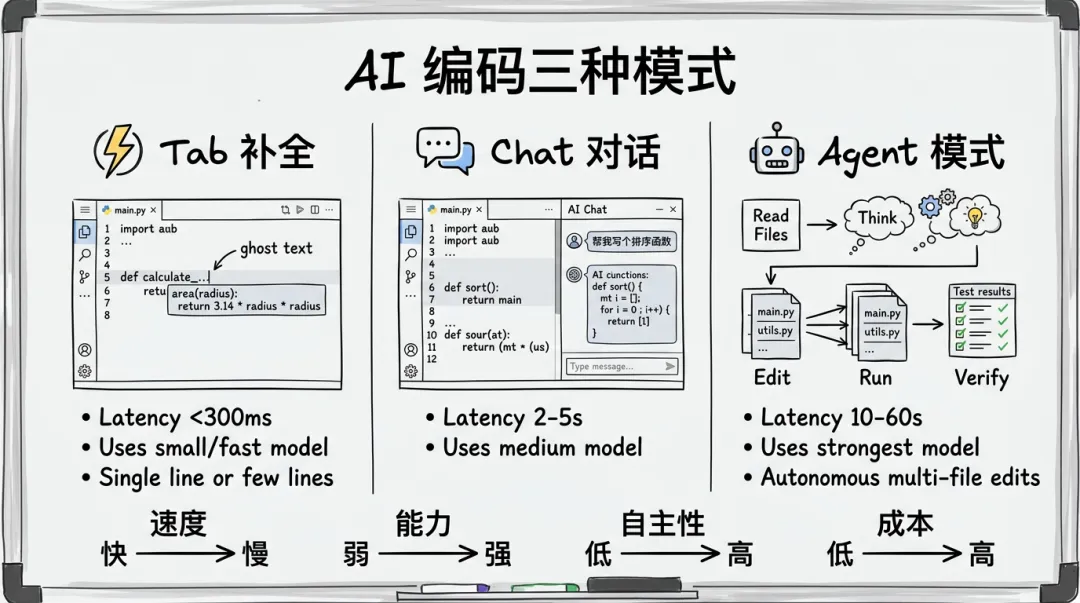
AI 编码的三种模式
在拆架构之前,先分清 AI 编码工具的三种工作模式——它们的底层架构完全不同。
| 模式 | 交互方式 | 延迟要求 | 模型选择 | 典型场景 |
|---|---|---|---|---|
| Tab 补全 | 光标处出现灰色建议,按 Tab 接受 | < 300ms | 小/快模型 | 补全当前行、函数体 |
| Chat 对话 | 侧边栏对话,问答式 | 2~5s | 中等模型 | 解释代码、写函数、调试 |
| Agent 模式 | 自主多步操作 | 10~60s | 最强模型 | 跨文件重构、复杂任务 |
三种模式对速度和能力的权衡完全不同——Tab 补全要快到用户感知不到延迟,Agent 模式可以慢但要准。
Tab 补全:300ms 内的极限优化
Tab 补全是 AI 编码工具的核心体验——用户每敲一个字符都可能触发,必须快到”感觉不到在等”。
▎FIM:Fill in the Middle
传统 LLM 从左到右生成文本。但代码补全不一样——光标可能在文件中间,上面有代码、下面也有代码。如果模型只能看到上面的内容,补全就不准。
FIM(Fill in the Middle) 解决了这个问题——把光标前的代码(Prefix)和光标后的代码(Suffix)都给模型看,让它”填空”。
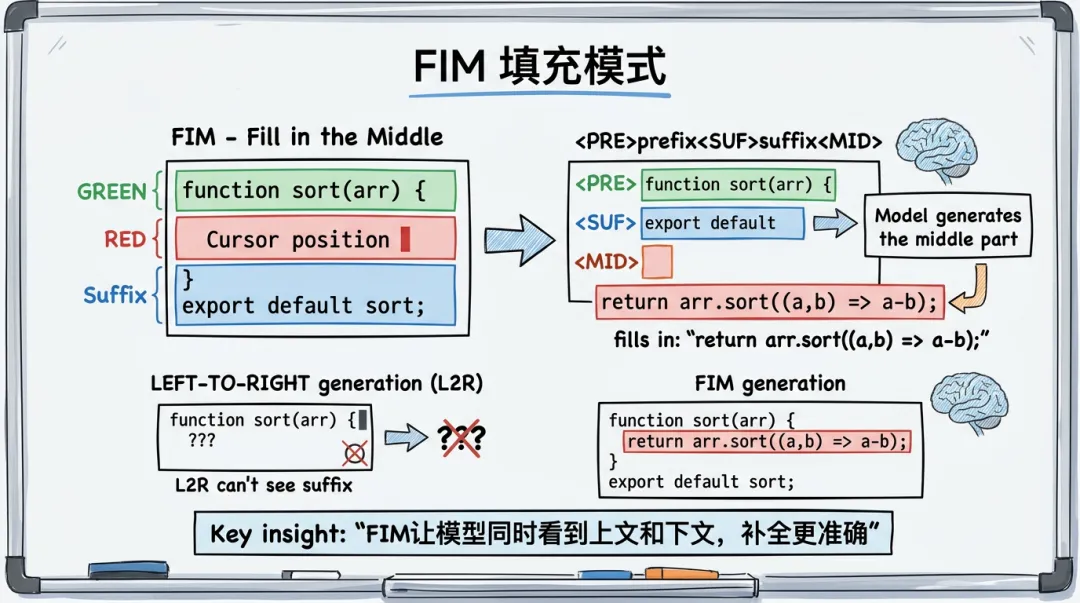
function calculateTotal(items: CartItem[]) {
const subtotal = items.reduce((sum, item) => sum + item.price * item.quantity, 0);
▎
return total;
}
FIM 模型的输入格式:
const subtotal = items.reduce((sum, item) => sum + item.price * item.quantity, 0);
<SUF>
return total;
}<MID>
模型输出:
const total = subtotal + tax;
同时看到上文和下文,模型知道要返回 total,所以补全了计算 total 的逻辑——这是纯左到右生成做不到的。
▎Context 收集:知道得越多补得越准
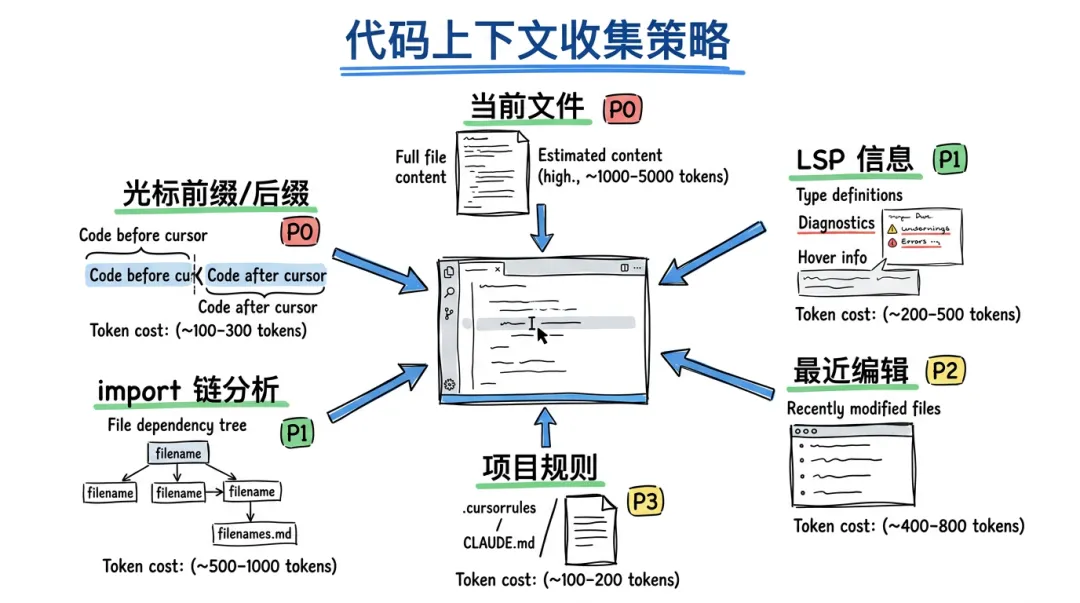
Tab 补全的 token 预算非常有限(通常 2000~4000 token),必须精准选择上下文。优先级从高到低:
P0:光标前后代码(Prefix / Suffix)
这是必选的——没有这个就无法补全。通常取光标前 1000~2000 字符和光标后 500~1000 字符。
P1:当前文件的 import 链
你引用了 import { UserService } from './user.service',那 user.service.ts 的类型定义就是高价值上下文——模型知道 UserService 有什么方法后,才能正确补全调用代码。
function getImportedFiles(sourceFile: string): string[] {
const ast = parseAST(sourceFile);
const imports = ast.body.filter(node => node.type === “ImportDeclaration“);
return imports.map(imp => resolveModulePath(imp.source.value));
}
P1:LSP 诊断信息
Language Server Protocol 提供类型信息、错误诊断、符号定义——这些是模型理解代码语义的关键线索。
const typeInfo = await languageServer.getHoverInfo(cursorPosition);
// { type: “CartItem[]”, documentation: “购物车商品列表” }
P2:最近编辑的文件
用户刚改过的文件大概率跟当前编辑相关。
P3:项目规则(.cursorrules)
项目级的编码规范、技术栈约束——比如”使用 Tailwind CSS”、”组件用函数式写法”。
▎Prompt 组装
收集完上下文后,组装成模型能理解的 Prompt:
const parts: string[] = [];
// 项目规则
if (context.rules) {
parts.push(`Project rules:\n${context.rules}\n`);
}
// 相关文件类型定义
for (const file of context.relatedFiles) {
parts.push(`// File: ${file.path}\n${file.content}\n`);
}
// FIM 格式
parts.push(`<PRE>${context.prefix}<SUF>${context.suffix}<MID>`);
return parts.join(“\n”);
}
▎模型选择:速度优先
Tab 补全对延迟极度敏感——超过 500ms 用户就会感知到”卡”。所以用的是专门优化过的小模型:
| 工具 | Tab 补全模型 | 特点 |
|---|---|---|
| Cursor | 自研 cursor-small | 针对代码补全优化,极快 |
| Copilot | Codex / GPT-4o-mini | 代码专用模型 |
| Continue | Starcoder2 / DeepSeek | 开源模型,可本地部署 |
这些模型参数量小(1B~7B),推理快,专门在代码数据上训练。跟 Chat 用的 GPT-4o(几百B参数)完全不是一个量级。
▎补全的触发与取消
不是每个按键都触发补全——有一套防抖 + 预测机制:
let abortController: AbortController | null = null;
function onTextChange(event: TextChangeEvent) {
// 取消上一次请求
abortController?.abort();
clearTimeout(debounceTimer);
debounceTimer = setTimeout(async () => {
// 快速判断是否值得请求
if (!shouldTrigger(event)) return;
abortController = new AbortController();
try {
const completion = await requestCompletion({
context: collectContext(),
signal: abortController.signal,
});
if (completion) {
showGhostText(completion);
}
} catch (e) {
if (e.name !== “AbortError“) throw e;
}
}, 150); // 150ms 防抖
}
function shouldTrigger(event: TextChangeEvent): boolean {
// 删除操作不触发
if (event.isDelete) return false;
// 在注释中不触发(可选)
if (isInsideComment(event.position)) return false;
// 在字符串中可能不触发
if (isInsideString(event.position)) return false;
return true;
}
Chat 模式:对话式代码生成
Chat 模式的架构跟 Tab 补全差别很大——它本质是一个RAG + 代码生成的组合。
▎上下文更丰富
Chat 模式的 token 预算大得多(8k~32k),可以传更多上下文:
return {
// 用户选中的代码(如果有)
selection: editor.getSelection()?.getText(),
// 当前文件完整内容
activeFile: editor.getActiveDocument().getText(),
// 语义搜索相关代码片段
codeSnippets: await semanticCodeSearch(query, projectRoot),
// 终端输出(如果在调试)
terminalOutput: getRecentTerminalOutput(),
// 错误信息
diagnostics: getDiagnostics(editor.getActiveDocument()),
// 项目文件结构
fileTree: getProjectStructure(projectRoot, { depth: 3 }),
};
}
▎Prompt 结构
## 当前文件
{activeFile}
## 选中的代码
{selection}
## 相关代码片段
{codeSnippets}
## 错误信息
{diagnostics}
User: {userQuery}
▎用大模型处理
Chat 没有 Tab 补全那么严格的延迟要求——用户问了问题,愿意等几秒。所以用 GPT-4o / Claude Sonnet 等大模型,效果更好。
Agent 模式:自主编码的完整循环
Agent 模式是最复杂的——它不只是回答问题,而是自主执行多步操作:读文件、理解需求、写代码、运行测试、修复错误。
本质就是前面 18 篇学的 ReAct 循环,只不过工具集换成了 IDE 操作:
// 文件操作
{ name: “read_file”, description: “读取文件内容” },
{ name: “write_file”, description: “写入/修改文件” },
{ name: “list_directory”, description: “列出目录结构” },
// 代码搜索
{ name: “grep_search”, description: “全局搜索代码” },
{ name: “semantic_search”, description: “语义搜索代码” },
// 执行
{ name: “run_command”, description: “在终端运行命令” },
// IDE
{ name: “get_diagnostics”, description: “获取 LSP 诊断信息” },
{ name: “go_to_definition”, description: “跳转到定义” },
];
一个典型的 Agent 执行轨迹:
Agent: [思考] 先看看 UserService 的代码
→ read_file(“src/services/user.service.ts”)
Agent: [思考] 看到了 createUser 方法,需要加 zod 校验
→ read_file(“package.json”) // 检查是否有 zod
Agent: [思考] 没有 zod,先安装
→ run_command(“npm install zod”)
Agent: [思考] 现在写校验代码
→ write_file(“src/services/user.service.ts”, updatedCode)
Agent: [思考] 检查有没有类型错误
→ get_diagnostics(“src/services/user.service.ts”)
Agent: [思考] 有一个类型错误,修复
→ write_file(“src/services/user.service.ts”, fixedCode)
Agent: [思考] 再检查一次
→ get_diagnostics(“src/services/user.service.ts”)
Agent: 完成!给 createUser 和 updateUser 方法添加了 zod 参数校验…
开源替代:Continue 的架构
Cursor 是闭源的,想深入理解底层可以看 Continue(开源 AI 编码助手,Star 40k+)。
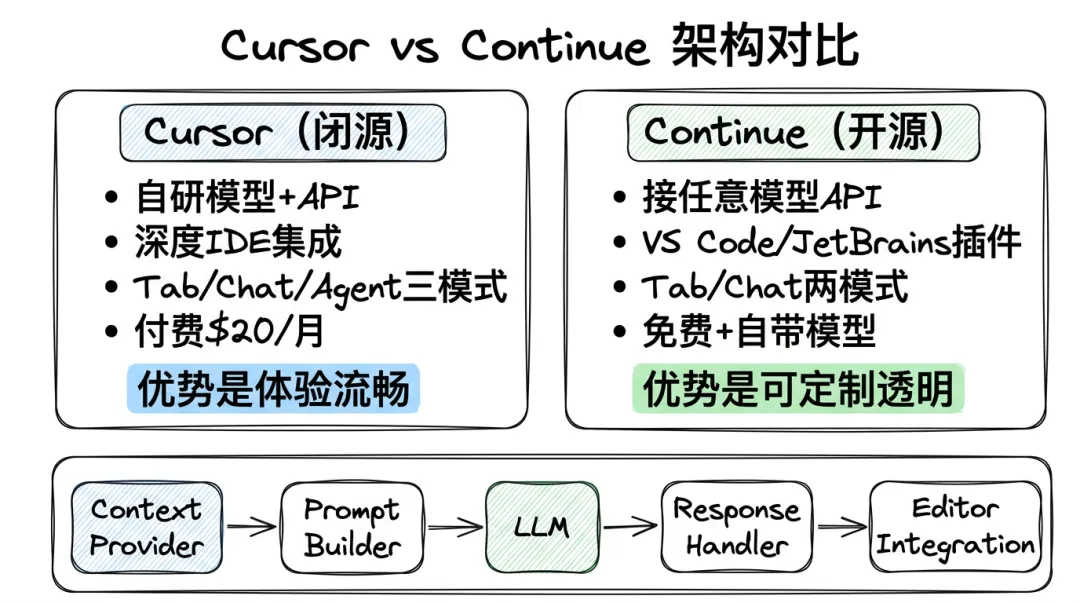
Continue 的架构清晰地分为五层:
– 收集代码、文件、终端、Git 等信息
– 可自定义扩展
2. Prompt Builder(Prompt 构建器)
– 把上下文组装成模型可用的 Prompt
– 不同模式用不同模板
3. LLM Provider(模型提供器)
– 支持 OpenAI / Anthropic / Ollama / 本地模型
– 统一接口,一键切换
4. Response Handler(响应处理器)
– 解析模型输出
– 代码 diff 应用到编辑器
5. Editor Integration(编辑器集成)
– VS Code / JetBrains 插件
– 处理 ghost text、inline diff 等 UI
Continue 的 config.json 让你能完全控制架构的每一层:
“models”: [
{
“title”: “GPT-4o”,
“provider”: “openai”,
“model”: “gpt-4o”,
“apiKey”: “sk-xxx”
}
],
“tabAutocompleteModel”: {
“title”: “Starcoder2 3B”,
“provider”: “ollama”,
“model”: “starcoder2:3b”
},
“contextProviders”: [
{ “name”: “code”, “params”: {} },
{ “name”: “docs”, “params”: {} },
{ “name”: “terminal”, “params”: {} }
]
}
Tab 补全用本地 3B 小模型(零延迟零成本),Chat 用远程大模型——混合架构,是开源方案的最佳实践。
关键技术细节
▎Speculative Decoding(推测解码)
Tab 补全要快,有一个常用优化——小模型先快速生成候选,大模型验证:
2. 大模型一次性验证这 5 个 token 对不对
3. 如果前 3 个对、后 2 个不对 → 接受前 3 个,从第 4 个重新生成
验证比生成快得多,所以整体速度接近小模型,质量接近大模型。
▎Caching:多级缓存
补全请求非常频繁——用户每敲一个字符都可能触发。多级缓存避免重复请求:
private prefixCache = new Map<string, string>();
async getCompletion(prefix: string, suffix: string): Promise<string | null> {
const key = hashKey(prefix, suffix);
// L1:精确匹配
if (this.prefixCache.has(key)) {
return this.prefixCache.get(key)!;
}
// L2:前缀匹配(用户刚接受了一部分补全,剩下的还能用)
for (const [cachedKey, cachedCompletion] of this.prefixCache) {
if (prefix.startsWith(getCachedPrefix(cachedKey))) {
const remaining = trimAcceptedPart(cachedCompletion, prefix);
if (remaining) return remaining;
}
}
// L3:调模型
const completion = await requestFromModel(prefix, suffix);
this.prefixCache.set(key, completion);
return completion;
}
}
▎Ghost Text 渲染
补全建议以灰色”幽灵文本”显示——这需要 VS Code 的 InlineCompletionProvider API:
class AICompletionProvider implements vscode.InlineCompletionItemProvider {
async provideInlineCompletionItems(
document: vscode.TextDocument,
position: vscode.Position,
context: vscode.InlineCompletionContext
): Promise<vscode.InlineCompletionItem[]> {
const prefix = document.getText(
new vscode.Range(new vscode.Position(0, 0), position)
);
const suffix = document.getText(
new vscode.Range(position, document.lineAt(document.lineCount – 1).range.end)
);
const completion = await this.getCompletion(prefix, suffix);
if (!completion) return [];
return [
new vscode.InlineCompletionItem(
completion,
new vscode.Range(position, position)
),
];
}
}
vscode.languages.registerInlineCompletionItemProvider(
{ pattern: “**” },
new AICompletionProvider()
);
避坑指南
▎坑 1:Context 太少导致补全不准
模型只能基于你给它的上下文来补全。如果只传了当前行的前几个字符,补全结果就像盲猜。
解法:确保 import 链文件、类型定义、项目规则都在上下文里。Cursor 的 .cursorrules 和 @ 引用就是解决这个问题的。
▎坑 2:Context 太多导致补全变慢
塞太多上下文,token 数飙升,延迟也跟着涨。
解法:设 token 预算上限,按优先级裁剪。Tab 补全控制在 2000~4000 token,Chat 控制在 8000~16000。
▎坑 3:不同模式用了同一个模型
Tab 补全用 GPT-4o?每个按键都要等 2 秒,体验灾难。
解法:Tab 补全用专门的快模型(cursor-small / Starcoder2 3B / DeepSeek Coder),Chat 和 Agent 用大模型。
▎坑 4:忽略了 FIM 的重要性
很多开发者自建补全服务时只传 prefix(光标前的代码),忽略 suffix(光标后的代码)——补全效果打五折。
解法:一定用 FIM 格式,prefix + suffix 一起传。主流代码模型(StarCoder、DeepSeek Coder、CodeLlama)都支持 FIM。
总结
AI 编码工具的底层架构,核心是三个环节的极致优化:
Context 收集——知道得越多补得越准
- ▸P0:光标前后代码(Prefix / Suffix)
- ▸P1:import 链文件 + LSP 类型信息
- ▸P2:最近编辑的文件
- ▸P3:项目规则(.cursorrules)
- ▸在 token 预算内按优先级裁剪
Prompt 组装——把代码变成模型能理解的格式
- ▸Tab 补全用 FIM 格式(Prefix + Suffix + Middle)
- ▸Chat 用系统提示 + 上下文 + 用户问题
- ▸Agent 用工具定义 + 上下文 + 任务描述
模型选择——速度和能力的权衡
- ▸Tab 补全:小快模型(< 300ms)
- ▸Chat:中大模型(2~5s)
- ▸Agent:最强模型(10~60s)
想深入了解可以去读 Continue 的源码——它把这三个环节做成了可插拔的模块,代码结构清晰,是学习 AI 编码工具架构的最佳教材。
下一篇我们聊 Prompt Engineering 进阶——System Prompt 的设计模式、Few-Shot 策略、以及如何让 LLM 的输出稳定可控。
推荐资源:
- ▸Continue 开源项目:https://github.com/continuedev/continue
- ▸Cursor 官方博客:https://cursor.com/blog
- ▸FIM 论文:https://arxiv.org/abs/2207.14255
- ▸VS Code InlineCompletion API:https://code.visualstudio.com/api/references/vscode-api#InlineCompletionItemProvider

往期推荐