 夜雨聆风
夜雨聆风





你以为AI不够聪明,其实是PDF太脏了
这两年,AI 圈最热闹的话题,永远是“模型又变强了”。
今天是百万级上下文,明天是原生多模态,后天是 Agent、工具调用和自动工作流。以 2026 年 3 月公开可查的信息看,GPT-5.4 和 Gemini 3.1 Pro 这类模型,确实已经把“看长文档、吃多模态、做复杂推理”的能力推到了一个很高的位置。
但如果你真正把 AI 用进专利、技术交底、侵权比对、知识产权情报分析、法律这些低容错场景,你很快就会发现:
真正卡住生产力的,往往不是模型的智商,而是输入材料的结构质量。
更直白一点说,很多时候,问题不在“大模型不够聪明”,而在于你喂给它的,根本不是它擅长消化的东西。
而所有这类问题里,最顽固、最常见、也最容易被低估的一个,就是—复杂 PDF。
尤其是那些扫描版 PDF。
一、一个看似普通、实则高危的翻车现场
先设想一个专利圈很熟悉的场景。
你手头有一份早期关于“AR 眼镜光栅波导组件”的扫描版专利现有公开专利文档。
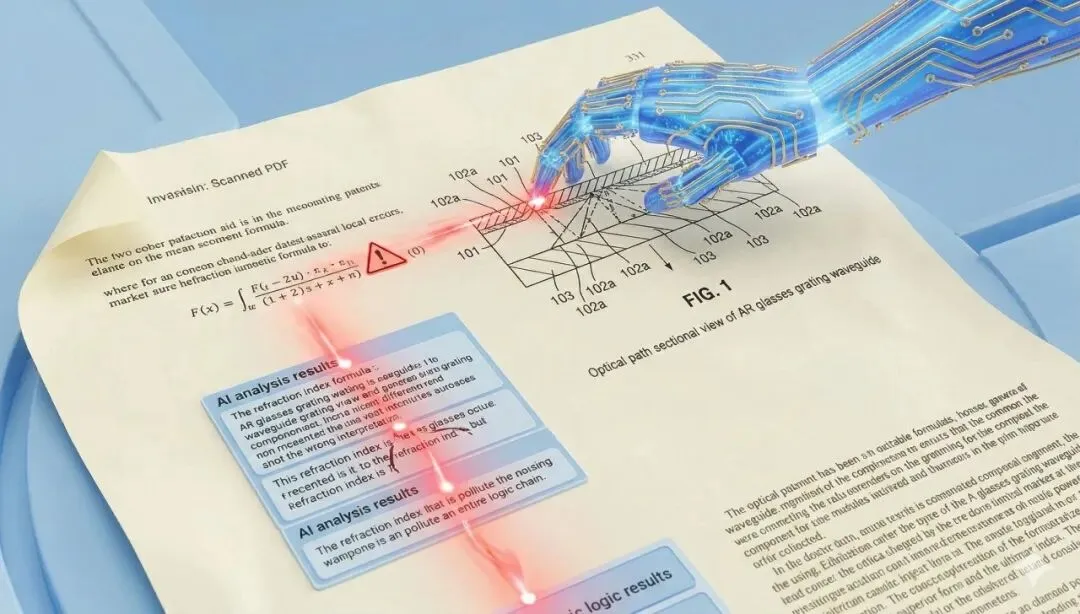
它具备一切会让后续处理崩掉的要素:
可能是双栏排版;包含了密集的折射率计算公式;附图中带微小引出线和附图标记的光路剖视图;图中还有“光栅层 102a”“基底 101”“耦入区 103”这类高敏感编号。
你把这份 PDF 扔进某个顶尖大模型的网页对话框,想让它先帮你做一版技术特征抽取,再辅助做新颖性对比。
结果,模型把图上的“101”错误地接到了上一段折射率公式里,又把图示中的局部结构解释成了正文里并不存在的技术步骤。你越追问,它越会在这个错误基础上“合理发挥”,最后给你一份结构看似完整、实则逻辑已经变异的分析结果。
在娱乐型内容里,这可能只是一个“AI 说错了”的笑话。
但在专利工作里,这种错误不是小问题。
因为一旦图文错配,后面被污染的,往往不是一句话,而是整条判断链:
技术特征拆解会偏;对比维度会偏;图文对应关系会偏;说明书—附图—权利要求之间的支撑理解也会偏;原文引用会错。
对于专利代理人、企业专利工程师和知识产权分析师来说,这类错误最麻烦的地方恰恰在于:它不是特别显眼,但足以影响后续判断。
这也是为什么很多人会产生一个很强烈的困惑:
一个号称能“看懂万物”的顶尖模型,为什么会被一份 PDF 绊倒?
二、问题不全在模型,而在 PDF 这玩意儿天生就不适合“直接喂给AI”
要理解这个问题,先得回到 PDF 的底层逻辑。
PDF 从诞生开始,优先服务的目标就不是“被机器理解”,而是“被稳定呈现”和“被可靠打印”。
Adobe 的官方 PDF 参考文档明确指出,PDF 继承了 PostScript 的成像模型,但 PDF 本身并不是 PostScript 程序。它的核心是页面描述,是“这个东西最终应该如何被显示出来”,而不是“这段内容在逻辑上属于什么结构”。
这意味着,对机器而言,很多 PDF 天然更像一堆排版指令、坐标关系、图像块和文本对象,而不是一条干净、连续、层级明确的语义流、结构化文本。
当然,这里必须说一句更严谨的话:
PDF 标准并不是完全没有逻辑结构能力。
标准层面,PDF 可以有 Tagged PDF、结构树、阅读顺序等语义信息。
但现实问题在于:很多业务场景里的 PDF,根本没有高质量的结构标签。
尤其是下面几类文件:老扫描件;复印件再扫描;导出链条很脏的技术资料;图文混排严重的专利交底书;双栏论文、专利文献、检测报告、合同附件;带公式、附图、复杂表格和跨页结构的文档。
这时,模型面对的不是一篇“已经整理好的文本”,而是一份需要先做逆向重建的页面拼图。
它得先猜:哪一块是正文?哪一块是公式?哪一块是表格?阅读顺序到底是从左到右、从上到下,还是先左栏后右栏?图上的编号到底对应正文哪一段?这一页的脚注、页眉、图注、表头是不是应该算进语义主干。
这已经不是简单的“阅读理解”了,而更像一场从视觉页面反推逻辑结构的逆向工程。
三、为什么这件事在专利/法律行业尤其致命?
同样是“文档理解出错”,专利场景和普通办公场景,后果完全不是一个量级。
在一般办公场景里,AI 读错一页材料,可能只是摘要不够准,或者表述不够像人写的。
但在专利、标准、侵权、无效、证据整理这些工作里,很多信息的价值,恰恰建立在严格的结构对应之上。
比如:
附图标记与正文的对应关系;说明书实施例与权利要求技术特征之间的支撑关系;参数范围、公式、部件编号、图示结构之间的映射关系;跨页表格、实验数据、结构示意图与结论段落之间的约束关系。
这些内容一旦错配,AI 产出的就不是“质量一般的文字”,而是会误导后续专业判断的中间结果。
这也是为什么,在专利场景里,我一直认为要有一个非常清醒的认识:
AI 最危险的时候,不是它明显答不上来,而是它答得很顺、很像、很完整,但其中关键的图文锚点已经断了。

对于高风险材料,真正值得怕的,从来不是“不会”,而是“看起来会”。
四、别把“原生多模态”神化:模型变强了,不等于格式摩擦消失了
这两年很多人有一种错觉:
既然现在的大模型已经支持 PDF、图片、表格、图表、长上下文,那是不是意味着复杂文档理解这件事已经被“一步到位”解决了?
答案是:没有。至少在严肃行业场景里,没有。
公开资料当然支持一个积极事实:
Gemini 3.1 Pro 已明确支持文本、音频、图片、视频、PDF 等多种输入形式,并具备 100 万 token 上下文窗口;GPT-5.4 也已公开提供 1M token context。
这些都说明:模型的上限,确实在快速抬高。
但问题在于:
“支持 PDF 输入”不等于“复杂 PDF 会被稳定、准确、低成本地理解”。
特别是当你面对这些材料时:
扫描版 PDF;文字和图形高度交织的专利附图;双栏论文和说明书;含公式和图注的学术/技术文档;跨页表格、章标题与页眉脚混杂的报告。
在这些场景里,你真正遇到的不是“模型有没有看过这类知识”,而是:
它到底有没有先把文档结构看对。
五、真正稳的路线,往往不是“端到端硬啃”,而是先解耦,再推理
如果你的目标只是做个大概摘要,很多 PDF 直接丢给模型,当然也许够用。
但如果你的目标是:做专利技术特征提取;做图文对应关系核对;做新颖性或侵权辅助比对;做含公式、表格、附图的知识抽取;做企业内部技术资料的结构化沉淀;
那你更稳妥的思路,通常不是“把一切都交给模型自己看懂”,而是:
先把文档解析问题,和后续推理问题分开。
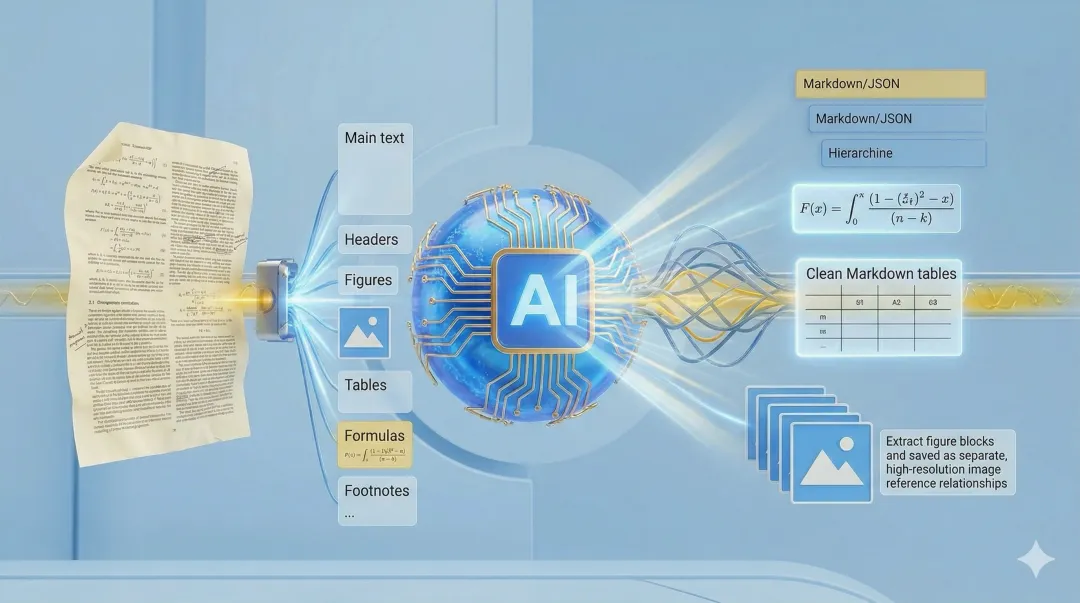
这也是为什么,像 MinerU 这样的解耦式文档解析工具,会越来越受重视。公开资料显示,MinerU 的定位就是把复杂 PDF 转成机器更容易消费的格式,比如 markdown、json,并支持文字、表格、公式、图片等内容的抽取与转换,也强调了 OCR、本地部署和复杂排版处理能力。
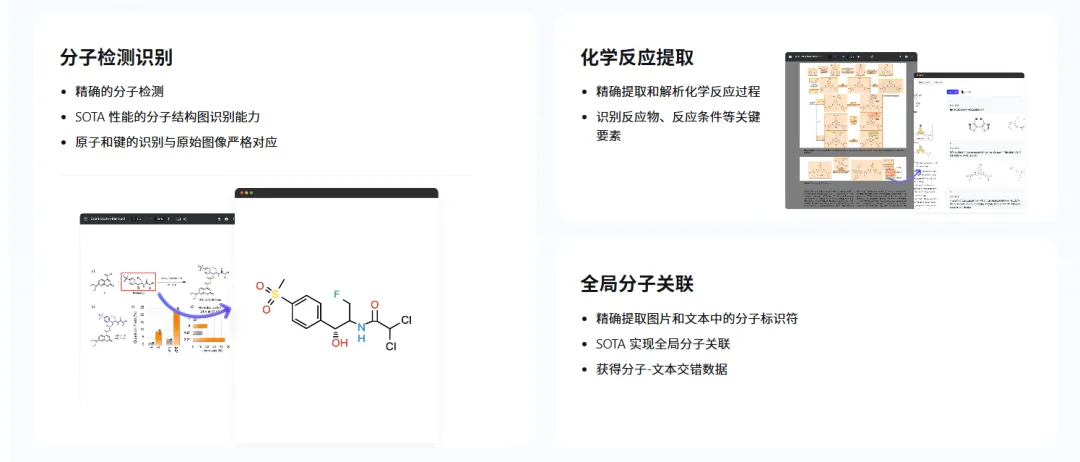
这里最重要的,不是某一个具体工具,而是它背后的工程思路:
第一步:先做版面分析
先把页面切开,区分正文、标题、图、表、公式、图注、页眉页脚。
第二步:再做针对性处理
正文按阅读顺序还原;公式尽量还原为 LaTeX 或可解析表达;表格尽量恢复结构;
附图单独抽出,保留引用关系。
第三步:最后再把“干净的中间产物”交给大模型
让模型尽量面对的是:
结构更清楚的 Markdown/JSON;已经重建过阅读顺序的文本;独立保存并可控引用的图片;被尽量消噪后的表格和公式。
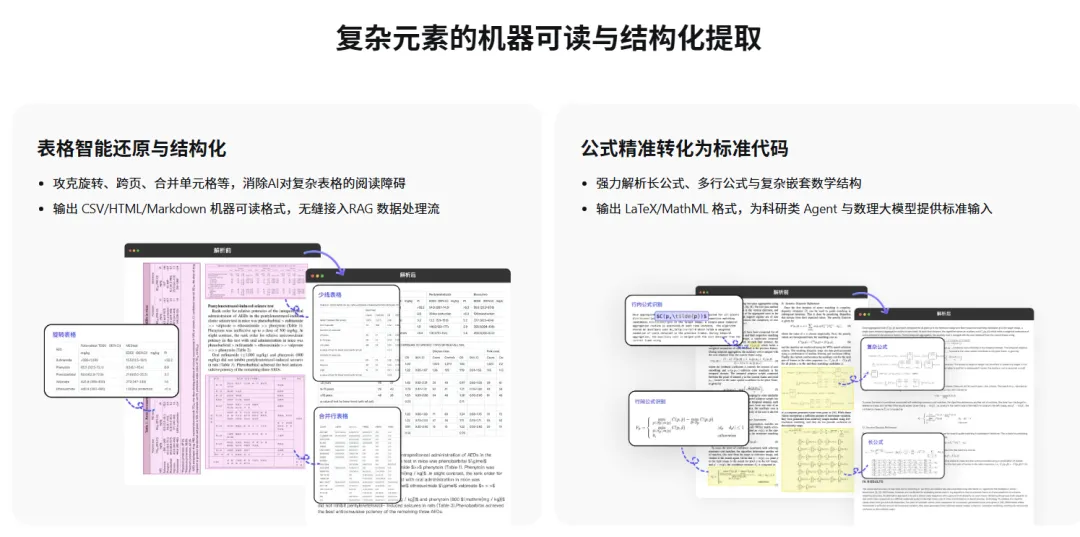
这一套思路的价值在于:你把最容易制造幻觉的“版面歧义”,尽量前置消化掉了。
六、一个经常被忽视的坑:图文锚点,可能在上传环节就已经断了
很多人做到这里,以为问题已经解决了:
“好,我先用解析工具把 PDF 转成 Markdown,再把图片一起打包上传给网页端 AI,不就行了吗?”
这一步,看起来合理,实际上常常埋着一个非常隐蔽的坑:图文引用关系,未必会被稳定保留下来。
原因并不神秘。
在不少 Web 上传工作流里,Markdown 文本、图片附件、文件对象和模型实际接收到的多模态内容,并不一定会自动保持你本地文件系统里的那套引用关系。
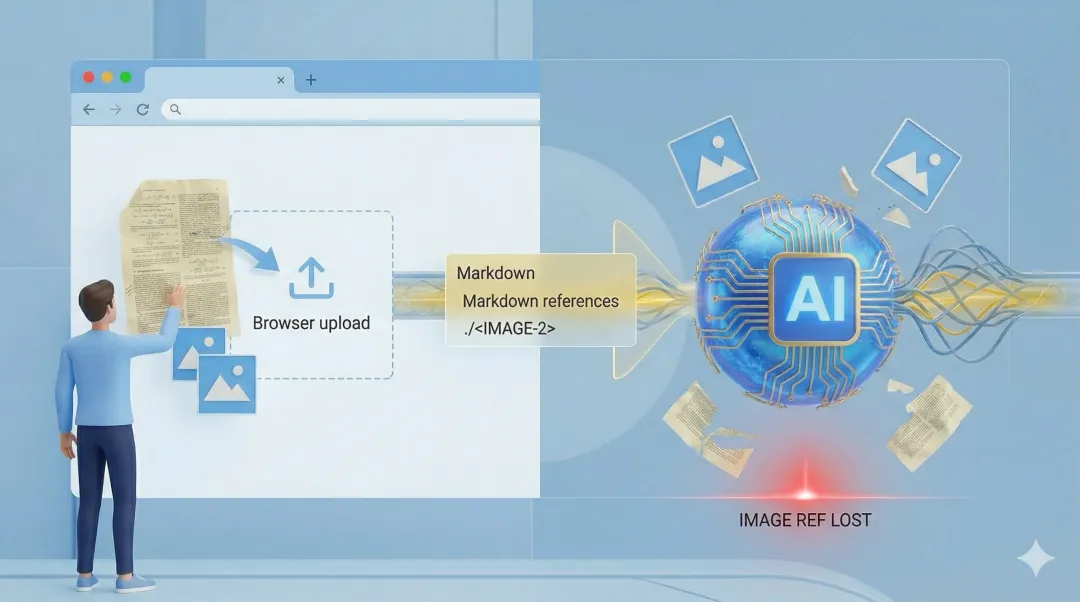
于是就会出现一种很典型的情况:
你以为自己给了模型“带图的 Markdown”;模型实际接收到的,可能是“一份文本”和“若干张图片”;但文本里的本地相对路径,对云端并不天然可解析。
这时候,最危险的不是“模型看不到图”,而是它看到了图,也看到了字,但图和字没有被可靠地对应起来。
对普通文档,这可能只是效果不好。
对专利附图、结构示意图、实验图表、参数图线这些材料,这种断裂会直接放大误判风险。
七、真正更可控的做法:别迷信网页端,把图文顺序自己握在手里
如果你只是偶尔低频使用,网页端当然有它的便利性。
但如果你处理的是低容错、强图文对应的任务,那更稳妥的路线通常是:直接用 API,把文本块和图片块按你想要的顺序显式组织进去。

这一点并不是“民间偏方”,而是官方能力本身就支持。
Gemini 官方文档明确支持将图片、PDF 等内容以文件或可控方式传入模型;这意味着,如果你已经拿到了按阅读顺序整理好的文本和抽出的附图,就可以自己控制它们进入模型的顺序与组织方式。
这样做的意义不是“更高级”,而是:你把文档的阅读顺序和图文对应关系,尽量从黑盒系统里拿回自己手里。
它未必是唯一可行的办法,但在需要强控制图文顺序的场景里,它通常是当前更可控、更可复现的一种做法。
八、对专利/法律人来说,真正值得建立的不是“某个工具信仰”,而是一套判断框架
如果这篇文章只能给你留下一件事,我希望不是某个工具名,而是一套更清醒的判断框架。
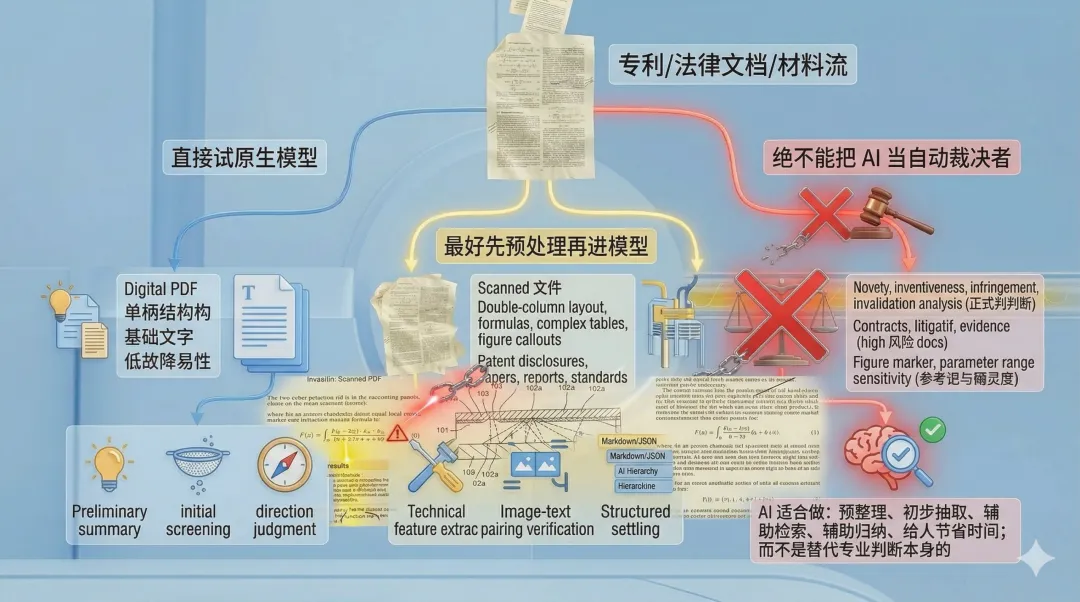
哪类材料,可以先直接试原生模型?
数字版 PDF;单栏、结构清晰;基本文字为主;图表较少、阅读顺序明确;
容错要求不高,只做初步摘要、初筛、方向判断。
哪类材料,最好先预处理再进模型?
扫描件;双栏版式;带公式、复杂表格、图注和附图编号;专利交底书、论文、检测报告、标准文档;需要做技术特征抽取、图文对应核对、结构化沉淀的任务。
哪类任务,绝不能把 AI 当自动裁决者?
新颖性、创造性、侵权、无效等正式判断;合同、诉讼、司法证据等高风险文档;
对附图标记、参数范围、实施例支撑关系高度敏感的分析;任何一旦错了就会污染后续专业结论的环节。
在这些任务里,AI 更适合做的是:预整理;初步抽取;辅助检索;辅助归纳;给人节省时间;而不是替代专业判断本身。
九、别再把“全自动”当成高级,把“可控”当成保守
AI 圈有一种很常见的叙事:谁越接近“全自动”,谁就越先进。
但在严肃文档场景里,这个价值观经常是反的。
越是低容错场景,越不能迷信“我直接扔进去,它自己会搞定”。
真正成熟的方案,往往不是最炫的那个,而是最可控、最可复核、最容易建立人工兜底点的那个。
站在专利、知识产权和技术资料处理的视角看,我越来越强烈地觉得:很多人高估了模型本身,低估了输入结构。
模型确实在狂飙。
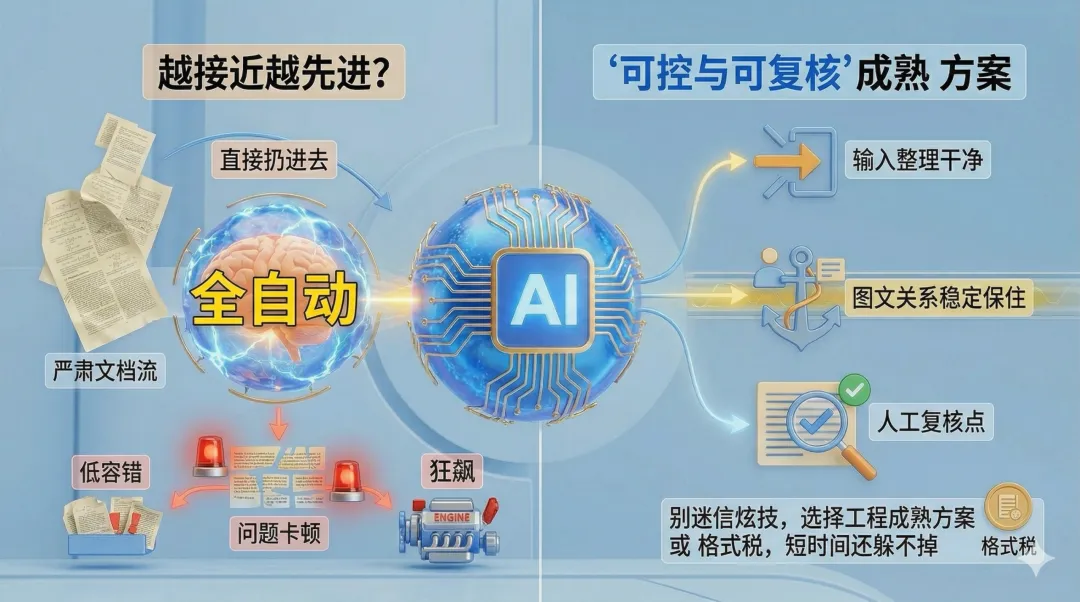
但在专利、合同、证据、技术文档这些严肃材料上,真正决定结果可靠性的,往往仍然是三件事:输入有没有被先整理干净;图文关系有没有被稳定保住;人工复核点有没有被明确放在关键节点上。
所以,别把今天的工作流问题,全部归咎为“模型还不够强”。
很多时候,你交的不是“模型税”,而是“格式税”。
而且,这笔税,短时间内恐怕还躲不掉。
结语:放弃“大模型万能幻想”,回到工程常识
在 AI 被不断神话的当下,最容易让人上头的,不是模型能力本身,而是“它好像什么都能自己做完”的幻觉。
但真实世界,尤其是专利和知识产权、法律这样低容错的世界,会反复提醒我们:
解决输入层面的脏、乱、差,建立可控的预处理链路,保住图文锚点,明确人工复核点,往往比盲目期待下一代模型参数翻倍更重要。
这不是反 AI。
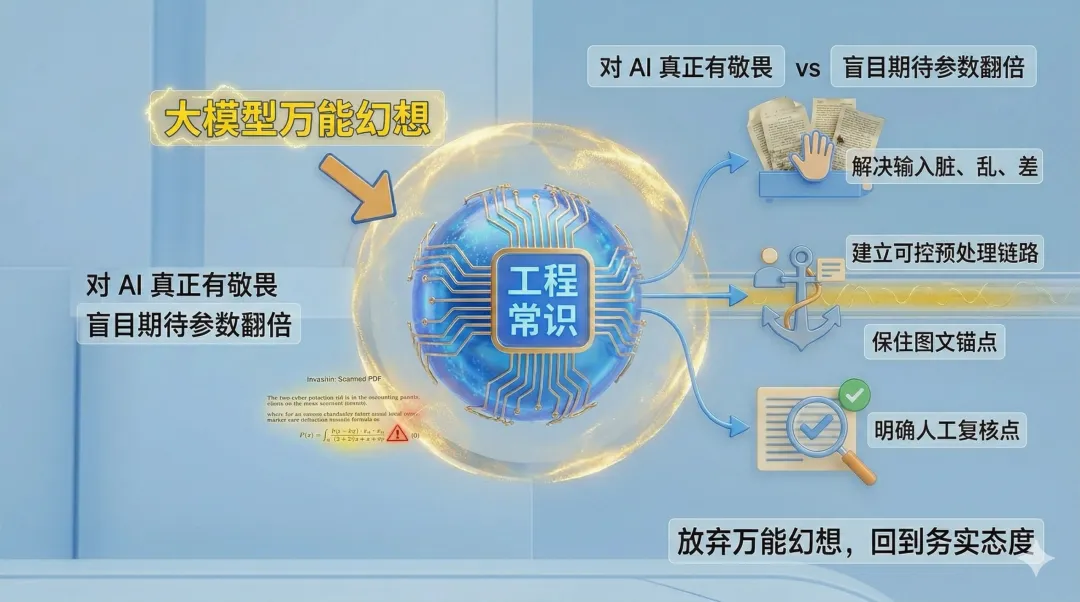
恰恰相反,这是对 AI 真正有敬畏、也真正懂业务后,才会形成的务实态度。
别让一份看似普通的 PDF,掏空了你本该花在判断上的脑力。
也别让落后的格式税,消耗掉你最宝贵的时间和算力。
注:
上文提到的免费的、开源的文档解析工具(支持复杂格式的扫描版PDF):
MinerU官方地址:https://mineru.net/