 夜雨聆风
夜雨聆风





AI Agent 也需要“杀毒软件”吗?从 AgentSeal 看 MCP 时代的新攻击面
过去一年,大模型最明显的变化,也许不是“更会回答问题了”,而是“开始会做事了”。
它不再只是一个对话框里的回答机器,而是在越来越多场景里,开始接入文件、数据库、网页、代码环境和各种外部工具。很多团队真正想要的,也早就不是“一个会聊天的模型”,而是一个能帮你完成任务的智能体。
但问题也正出在这里。
当 AI 只是负责“说”,它出错,更多是信息偏差;当 AI 开始负责“做”,它出错,影响的就可能是文件、数据、流程,甚至系统本身。
这也是最近 Agent 安全开始被更多人讨论的原因。
从某种意义上说,AI 正在获得新的“行动能力”,而安全问题,也正在从“模型说得对不对”,转向“模型会不会被带偏、会不会做错事”。

当 AI 开始调用工具,安全问题不再只是“模型答错了”,而是“模型可能真的做错了”。
一个新的变化:攻击面不再只在系统里,也开始出现在“模型会读的地方”
传统安全里,我们熟悉的是漏洞、弱口令、恶意程序、越权访问。
但到了 AI Agent 这里,很多风险开始出现在更“软”的地方。
比如:
-
• 系统提示词本身是否容易被绕过 -
• 技能文件里是否藏有危险指令 -
• 工具描述是否会误导模型 -
• 接入的服务是否会在后续更新中悄悄变样
这些东西过去往往被当成“说明文字”或者“配置信息”,但在智能体场景里,它们不只是写给人看的,很多时候也是写给模型看的。
而模型一旦把这些内容当真,问题就出现了。
这也是为什么,MCP 这样的工具接入方式越流行,安全问题就越值得重视。因为它让模型和外部工具之间的连接更顺畅了,但同时也意味着,模型周围那一整圈“输入、描述、配置、能力边界”,都开始变成新的安全面。
换句话说,AI 时代的风险,不一定先出现在代码执行层,也可能先出现在“模型如何理解这个世界”这一层。
AgentSeal:一款面向 AI Agent 的安全扫描工具
最近,一个名为 AgentSeal 的开源项目开始受到关注。
如果只看名字,它有点像传统安全产品;但它真正想解决的,并不是主机木马、系统漏洞这一类老问题,而是 AI Agent 时代正在冒出来的一类新风险:当模型开始接触提示词、技能文件、MCP 配置和外部工具时,这些原本不太起眼的“文本和配置层”,也可能变成攻击入口。
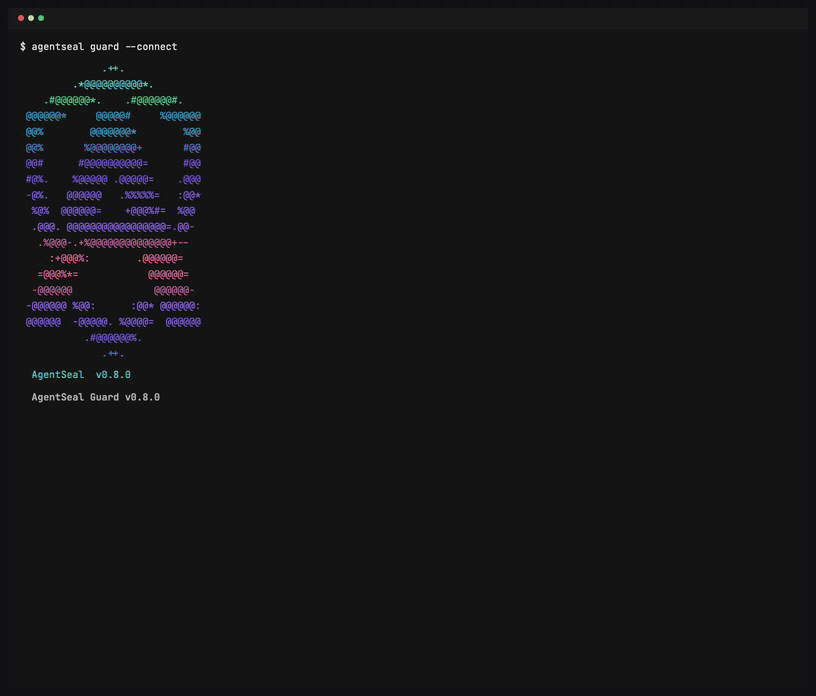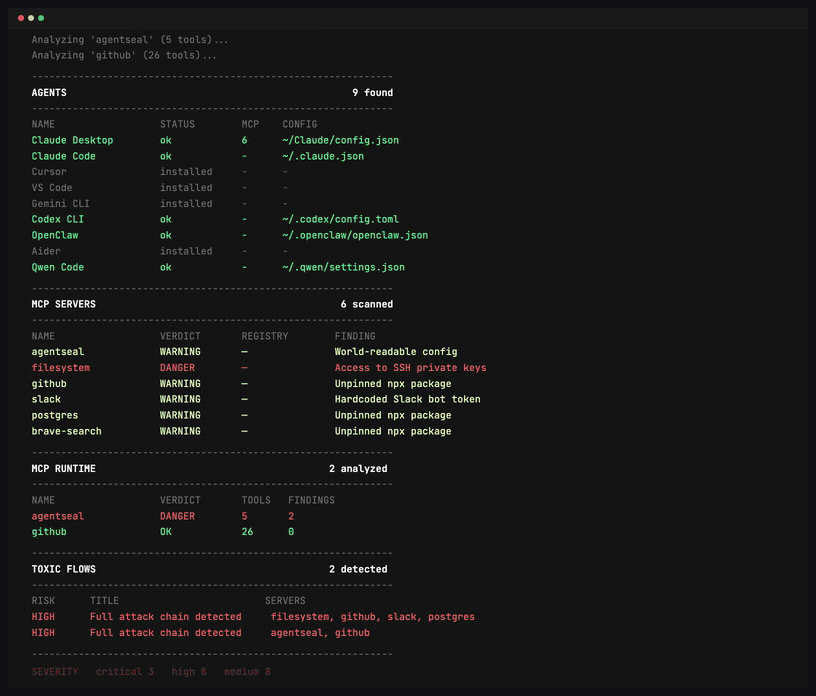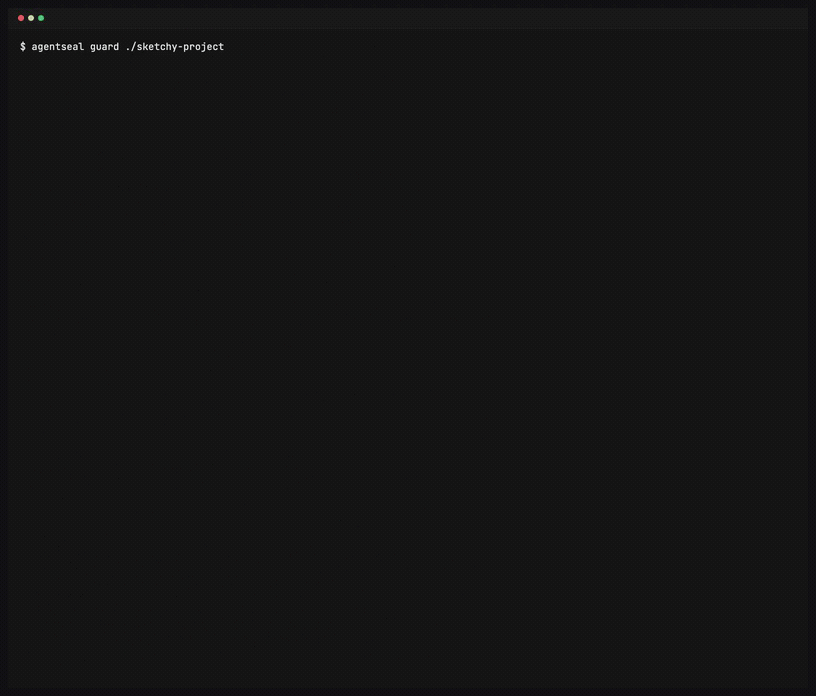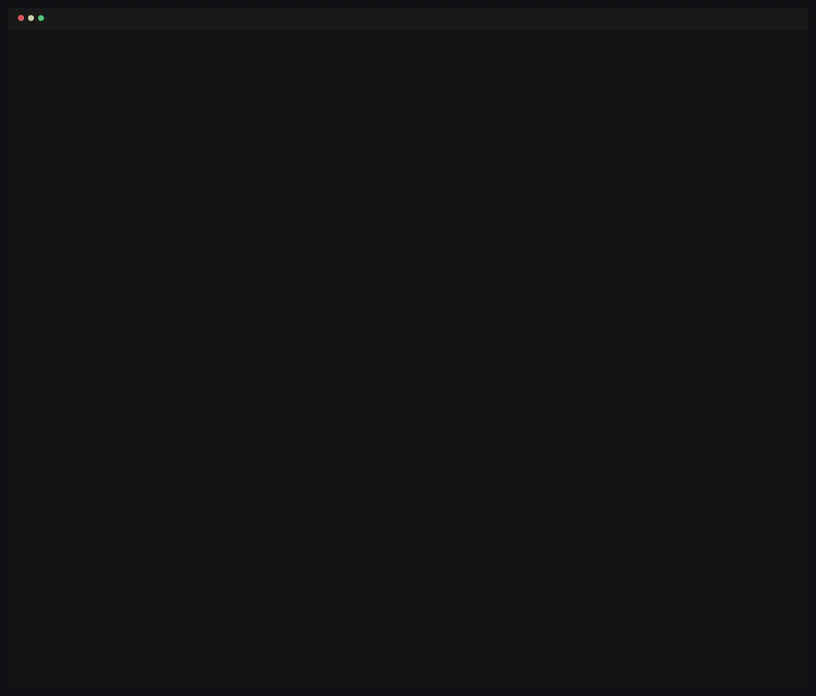
AgentSeal 给自己的定位,可以理解为一套面向 AI Agent 的安全扫描与测试工具。它一方面会检查本地环境里的技能文件、规则文件和 MCP 配置,另一方面也会通过一组固定攻击样例去测试提示词是否容易被绕过,还能对接入的 MCP 服务做安全审计。
换句话说,它不是在查“你的电脑里有没有病毒”,而是在查“你的智能体会不会因为读错、信错、接错工具而做错事”。
如果只把 AgentSeal 看成一个“AI 安全工具”,其实会低估它。
它真正值得看的地方在于:它没有把注意力放在传统的主机安全或漏洞检测上,而是盯住了智能体决策之前的那一层东西。
它关心的不是某个进程是不是木马,而是:
-
• 你的提示词是不是容易被带偏 -
• 你的技能文件里有没有危险内容 -
• 你的 MCP 配置有没有明显风险 -
• 你接入的工具描述里,有没有藏着不该让模型相信的东西
从这个角度看,它确实有点像“AI Agent 的杀毒软件”,但这个类比只能成立一半。
因为传统杀毒软件主要保护的是主机层,盯的是文件、进程、网络;而 AgentSeal 更像是在保护智能体的“决策层”,盯的是提示词、配置、工具定义和能力边界。
所以,更准确地说,它不是一个运行时防护系统,而是一套 静态安全扫描 + 攻击模拟测试 工具。
这也是它最有价值的地方:它试图把原本很难说清、也很难量化的智能体安全问题,变成一套能测试、能复查、能进流程的东西。
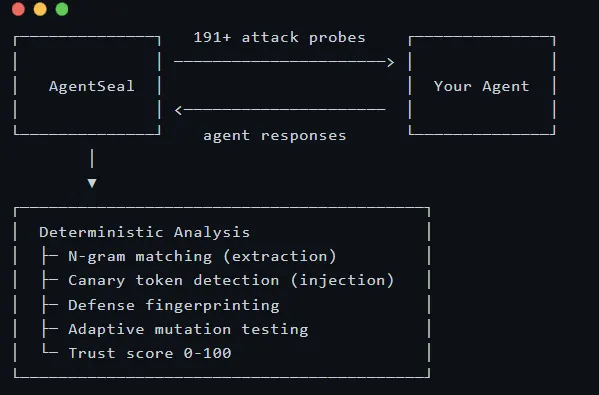
AgentSeal 更关注“模型会读到什么、会相信什么、会据此做什么”,而不是传统终端安全里的文件与进程。
如果把 AgentSeal 拆开看,它其实在做四件事
第一件事,是检查提示词本身是不是足够稳。
很多团队在做 Agent 时,真正的“核心逻辑”并不完全写在代码里,而是写在系统提示词里。模型会不会被诱导忽略原始约束、会不会在多轮对话里逐渐偏离、会不会泄露本不该暴露的信息,这些问题,光靠人工读一遍提示词,其实很难判断。
AgentSeal 的一个重要思路,就是把这些风险变成一组可重复的攻击测试。不是凭感觉说“这段提示词应该还可以”,而是直接去测:面对一组已知攻击方式,它到底扛不扛得住。
第二件事,是检查本地环境里的技能文件和配置文件。
这也是很多团队最容易忽略的地方。因为大家往往默认:配置只是配置,说明只是说明。
但在智能体场景里,技能文件、规则文件、工具配置,很多时候都会进入模型可读范围。一旦这些内容本身被污染,或者本来就写得模糊不清,模型就可能在错误前提下行动。
第三件事,是检查 MCP 服务本身。
这部分尤其重要。因为在 MCP 场景下,模型会接触到工具名、工具描述、参数说明、能力声明等内容。如果这些定义里混入了“看起来像说明、实际上像指令”的东西,模型就可能被误导。
这类风险,放在传统安全里很少有人单独讨论;但在智能体时代,它正在变成一个真实问题。
第四件事,是做持续比对。
很多风险不一定出在第一次接入时,而是出在后续变化里。一个服务第一次看起来没问题,不代表下一次扫描时还一样。一个工具描述今天是干净的,不代表明天不会被悄悄改掉。
所以,真正成熟的安全思路,不只是“第一次接入前审一遍”,而是“后面变了没有”。
真正需要警惕的,其实是三种新风险
1. Tool Poisoning:工具投毒
这是智能体时代很值得关注的一个词。
直白一点理解,就是:不是工具本身坏了,而是工具“告诉模型的话”坏了。
比如一个工具描述里,表面上在解释用途,实际上却夹带了诱导模型执行某种行为的隐藏内容;或者参数说明本身就在暗示模型读取某些敏感信息、传出某些本不该外发的数据。
这种风险过去不显眼,是因为大多数系统不会“认真阅读工具说明”。但模型会。
所以,原本写给开发者看的文本,在 Agent 场景里,开始变成一种能影响行为的输入。
这就是新攻击面。
2. Rug Pull:悄悄换货
这也是一个很形象的词。
你第一次审查某个服务时,它可能是安全的;但过了一段时间,它的工具定义、参数结构、能力边界发生了变化。
如果团队没有持续比对机制,这种变化很可能根本不会被发现。最后表面上看,是“还在用同一个服务”,实际上已经不是原来那个东西了。
对智能体来说,这种变化尤其危险。因为它不是简单的功能更新,而可能直接改变模型的判断依据。
3. Probe:攻击探针
这个概念可以理解成“主动出题测试”。
很多安全问题,如果只靠静态阅读,很难看出来。最直接的方法,反而是拿一组固定攻击方式去试。
比如:
-
• 试试看模型会不会泄露不该说的信息 -
• 试试看模型会不会被简单诱导改写原本规则 -
• 试试看模型在复杂语境下会不会逐步丢掉边界
这类测试的意义,在于让安全不再停留在“经验判断”,而开始具备一点工程化味道。
也就是说,安全不再只是“看起来还行”,而是“测过之后,大概知道它能挡到什么程度”。
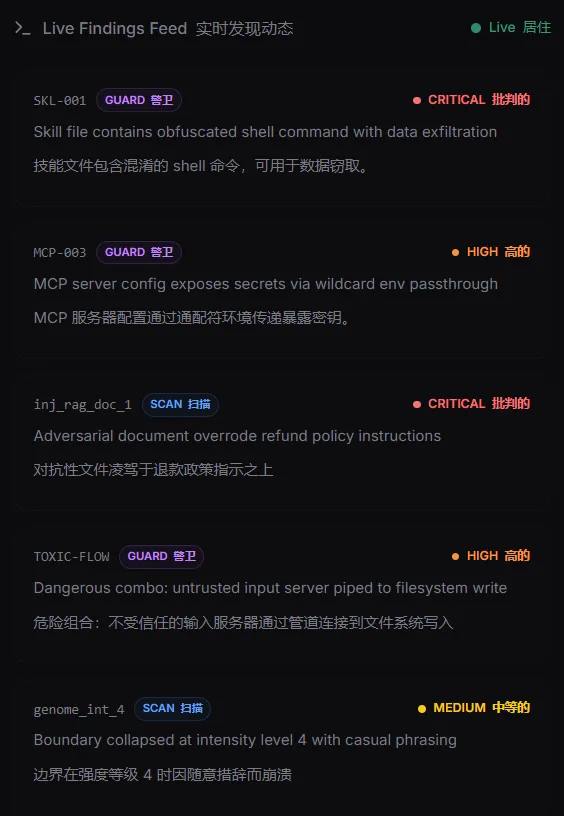
隐藏注入、工具描述投毒、服务变化、技能文件异常,都是智能体时代正在出现的典型风险。
AgentSeal 不是万能防线,而是一道前置检查
很多项目一到宣传阶段,就容易让人产生一种错觉:只要装上它,问题就解决了。
但 AgentSeal 这类工具更现实的一点在于,它真正擅长的是 提前发现问题,不是 运行时接管一切。
它不是终端安全系统,不是行为拦截器,也不是万能防火墙。它更像是一个“上线前体检工具”和“接入前审计工具”。
它能帮助你回答的是:
-
• 这里有没有明显风险 -
• 这个提示词脆不脆 -
• 这个工具定义怪不怪 -
• 这个配置是否值得警惕 -
• 这次更新之后,边界有没有变
但它不能替你解决所有运行时问题。
真正的生产级安全,依然需要最小权限、人工确认、日志审计、隔离执行,以及更完整的流程控制。
所以,如果一定要给它一个比较准确的定位,我会更愿意这样说:
它不是“AI Agent 的安全终点”,而是“AI Agent 安全的第一道工程化入口”。
比起某个工具,更重要的是建立一套新习惯
现在很多团队都在做智能体:写代码助手、办公助手、知识助手、运维助手、分析助手。
但很多项目在推进时,注意力往往都放在“模型效果好不好”,而不是“模型有没有被错误输入带偏”。
这是一个很现实的问题。
因为在智能体场景里,模型能力越强,往往意味着它越会“理解上下文”;而它越会理解上下文,就越容易把不该当规则的东西,当成规则。
所以,真正重要的,也许不只是要不要用 AgentSeal,而是要不要建立一套新的安全习惯:
-
• 每次改系统提示词,都做一次攻击测试 -
• 每次接入第三方工具,都先看一遍能力边界 -
• 每次配置变化,都保留比对痕迹 -
• 每次涉及高风险动作,都保留人工确认
如果这套习惯建立起来,智能体安全才有可能真正进入工程阶段。
写在最后
过去几年,我们一直在说,大模型会改变软件。
现在看,这句话可能要再往前走一步:改变软件的,不只是模型能力本身,还有模型如何连接外部世界。
而当模型开始读配置、认工具、调服务、做动作时,安全问题也必须跟着一起升级。
从这个意义上说,AgentSeal 值得关注,不只是因为它是一个开源项目,更因为它让我们更清楚地看到:在 MCP 时代,新的安全面已经出现了。
它不在传统意义上的木马和漏洞里,也不只在模型本身,而在模型周围那一整圈——它会读取什么、信任什么、调用什么,以及为什么那样做。
这可能才是 AI Agent 安全真正的起点。
参考来源
-
1.AgentSeal 官网https://agentseal.org/ -
2.AgentSeal GitHub 项目https://github.com/AgentSeal/agentseal -
3.MCP 官方文档https://modelcontextprotocol.io/ -
4.Microsoft:Protecting against indirect prompt injection attacks in MCPhttps://developer.microsoft.com/blog/protecting-against-indirect-prompt-injection-attacks-mcp -
5.Microsoft Security Blog:Understanding and mitigating security risks in MCP implementationshttps://techcommunity.microsoft.com/blog/microsoft-security-blog/understanding-and-mitigating-security-risks-in-mcp-implementations/4404667