夜雨聆风
夜雨聆风





你的 AI 智能体为什么老调错工具?问题出在工具设计
你见过这种代码吗?
defdo_everything(action: str, params: dict) -> str:if action == "query_order": ...elif action == "cancel_order": ...elif action == "refund": ...elif action == "check_logistics": ...elif action == "update_address": ...# 30 个 elif...一个超级函数搞定一切。大模型调用时传一个 action 参数来区分要干啥。听起来省事?
实际上是噩梦——大模型得从 30 个 action 里选一个,选错的概率极高;schema 写不清楚;出了 bug 不知道是哪个分支的问题。
工具注册、工具协议都有人讲,但工具本身怎么设计,很少有人讲透。 这篇就聊这件事:怎么拆、拆多细、拆完怎么组合。
一、为什么”一个大工具”是错的
大模型选工具靠的是什么?工具名 + 描述。
你给它一个工具叫 do_everything,描述是”执行各种操作”——它怎么知道什么时候该调?
对比一下:
❌ 一个大工具: 名称:do_everything 描述:执行订单相关的所有操作,通过 action 参数区分✅ 拆成小工具: 名称:query_order 描述:根据订单号查询订单详情 名称:cancel_order 描述:取消指定订单 名称:apply_refund 描述:提交退款申请 名称:track_logistics 描述:查询包裹物流状态后者每个工具名和描述都明确告诉大模型”这个工具干什么”。大模型选对的概率大幅提升。
实测对比
我用同一组用户问题,分别测试”一个大工具”和”五个小工具”两种方案。核心区别在 schema 设计:
方案 A:一个大工具——所有操作塞进一个函数,靠 action 枚举区分:
big_tool = [{"type": "function","function": {"name": "order_system","description": "订单系统操作,通过 action 参数区分操作类型","parameters": {"type": "object","properties": {"action": {"type": "string","enum": ["query", "cancel", "refund", "track", "update_address"] },"order_id": {"type": "string"},"reason": {"type": "string", "description": "原因(退款时必填)"},"new_address": {"type": "string", "description": "新地址(改地址时必填)"} },"required": ["action", "order_id"] } }}]方案 B:五个小工具——每个操作独立,schema 各自聚焦:
small_tools = [ {"type": "function", "function": {"name": "query_order","description": "根据订单号查询订单详情","parameters": {"type": "object", "properties": {"order_id": {"type": "string"} }, "required": ["order_id"]} }}, {"type": "function", "function": {"name": "cancel_order","description": "取消指定订单","parameters": {"type": "object", "properties": {"order_id": {"type": "string"} }, "required": ["order_id"]} }}, {"type": "function", "function": {"name": "apply_refund","description": "提交退款申请","parameters": {"type": "object", "properties": {"order_id": {"type": "string"},"reason": {"type": "string", "description": "退款原因"} }, "required": ["order_id", "reason"]} }},# track_logistics, update_address 同理...]用 5 条真实用户问题测试(”我的订单什么状态””我要退款””快递到哪了”……),结果:
-
方案 A:工具名选对了,但 action参数经常填错,退款时漏填reason -
方案 B:工具选择和参数填写几乎全对
原因很简单:方案 B 每个工具的 schema 只有 1-2 个参数,大模型不需要”理解哪些参数在哪种场景下必填”。
完整可运行的测试代码见文末 GitHub 链接。
二、工具拆分的五个原则
原则 1:单一职责
一个工具只做一件事。判断标准:能否用一句话描述它的功能。
❌ "管理用户和订单的相关操作" → 做了两件事✅ "根据订单号查询订单详情" → 一件事原则 2:输入最小化
只要完成任务必需的参数,不要多余的。
# ❌ 参数太多,大模型容易填错{"name": "query_order","parameters": {"order_id": "string","user_id": "string", # 不需要,系统能根据 session 获取"include_history": "bool", # 不需要,默认就好"format": "string", # 不需要,工具内部决定 }}# ✅ 只要必需的{"name": "query_order","parameters": {"order_id": "string" }}有个简单的判断方法:这个参数能不能在工具内部自己获取?能的话就不要让大模型传。
原则 3:描述要精准
描述是大模型选工具的唯一依据。写得含糊就等着选错。
# ❌ 含糊"description": "处理订单"# ✅ 精准"description": "根据订单号查询订单的当前状态、商品信息和物流进度"原则 4:输出要结构化
工具的返回值要结构化,让大模型容易理解和引用。
# ❌ 非结构化——大模型得自己"猜"哪段是状态、哪段是物流defquery_order(order_id: str) -> str:return"订单12345,状态已发货,2件商品,快递圆通"# ✅ 结构化——大模型直接按字段引用defquery_order(order_id: str) -> str: result = {"order_id": order_id,"status": "已发货","items": [ {"name": "无线鼠标", "quantity": 1, "price": 79}, {"name": "鼠标垫", "quantity": 1, "price": 29} ],"logistics": {"carrier": "圆通", "tracking_no": "YT12345"} }return json.dumps(result, ensure_ascii=False)原则 5:幂等优先
同一个调用执行多次,结果应该一样。因为大模型可能重复调用同一个工具。
# ❌ 非幂等:每次调用都创建新记录defcreate_ticket(title: str) -> str: ticket_id = db.insert({"title": title}) # 调两次就创建两条returnf"工单 {ticket_id} 已创建"# ✅ 幂等:先检查是否已存在defcreate_ticket(title: str, idempotency_key: str) -> str: existing = db.find({"idempotency_key": idempotency_key})if existing:returnf"工单 {existing.id} 已存在" ticket_id = db.insert({"title": title, "idempotency_key": idempotency_key})returnf"工单 {ticket_id} 已创建"
三、工具粒度:拆到什么程度?
拆太粗不好,拆太细也不好。
粒度判断矩阵
|
|
|
|
|
|---|---|---|---|
| 特征 |
|
|
|
| 问题 |
|
|
|
| 例子 | manage_order |
cancel_order |
find_order
check_cancellable → do_cancel |
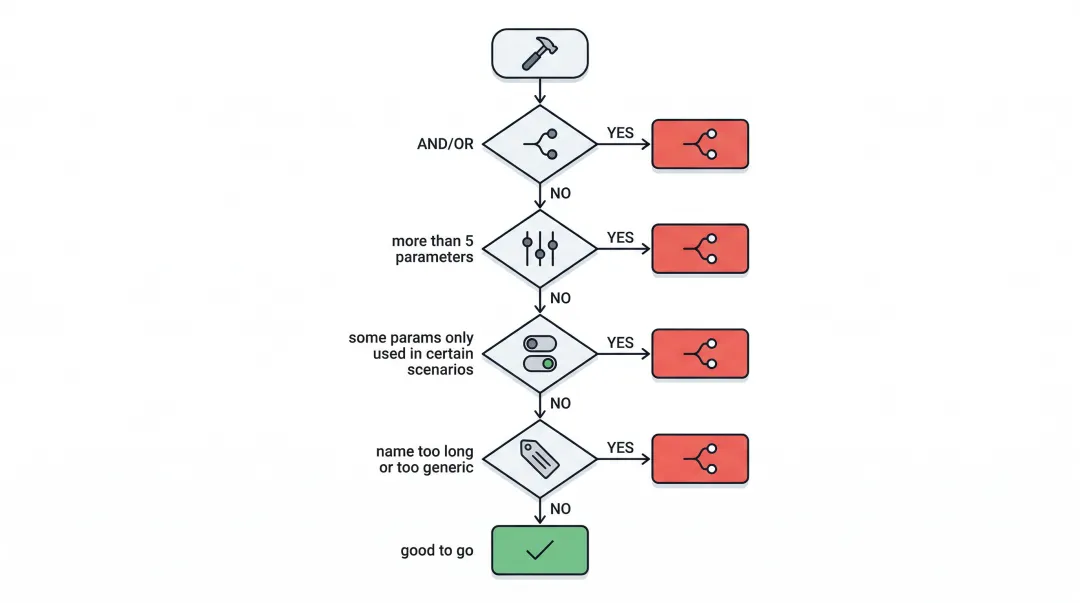
四问决策法
拿到一个工具,问自己四个问题:
-
描述里有”和””并””或者”等连接词? → 功能不单一,建议拆 -
参数超过 5 个? → 可能混合了多个功能,建议拆 -
有些参数只在特定场景用? → 不同场景该是不同工具 -
名字很长或很泛? → 说明职责不清晰,建议拆
如果四个问题全答”否”,粒度就是对的。
正确的粒度示例
以电商客服场景为例:
太粗(1 个工具): order_system(action, order_id, ...) → 大模型老选错 action太细(15 个工具): get_order_id → get_order_status → get_order_items → get_order_price → get_order_address → ... → 查个订单要调 5 次刚好(6 个工具): query_order → 查订单 cancel_order → 取消订单 apply_refund → 退款 track_logistics → 查物流 update_address → 改地址 create_ticket → 提工单四、Skill = 工具的编排层
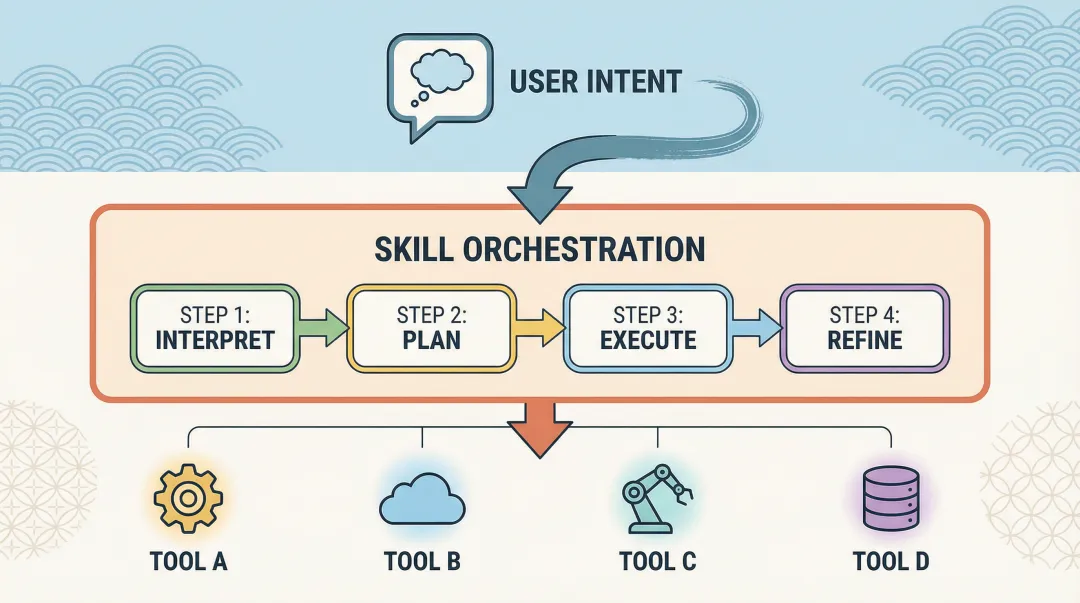
单个工具是原子操作,但用户的需求往往需要多个工具配合。
比如用户说”我要退款”,实际流程是:查订单 → 检查退款资格 → 计算退款金额 → 提交申请。这四步对应四个原子工具,但大模型不需要知道细节——它只需要知道有一个叫”退款申请”的 Skill,传一个 order_id 就行。
用户说:"我要退款,订单号 12345"大模型选择 Skill:退款申请 │ ┌────────┼────────┐────────┐ ↓ ↓ ↓ ↓ 查订单 检查资格 算金额 提交申请 (Tool 1) (Tool 2) (Tool 3) (Tool 4)实现上就是一个编排引擎,把多个原子工具串成一条流水线:
# 四个原子工具defquery_order(order_id: str) -> dict:return {"order_id": order_id, "status": "已发货", "amount": 299}defcheck_refund_eligible(order: dict) -> dict: eligible = order["status"] in ["已发货", "已签收"]return {"eligible": eligible}defcalculate_refund(order: dict) -> dict:return {"refund_amount": order["amount"], "refund_method": "原路退回"}defsubmit_refund(order_id: str, amount: float, reason: str) -> dict:return {"ticket_id": "RF20250310001", "status": "审核中"}# 注册为一个 Skillengine.register( name="退款申请", description="完整的退款流程:查订单→检查资格→计算金额→提交申请", steps=[query_order, check_refund_eligible, calculate_refund, submit_refund], required_params=["order_id"])Tool vs Skill 的本质区别:Tool 是原子操作,大模型直接调;Skill 是流程编排,大模型只选意图,内部自动串联多个 Tool。大模型的认知负担从”理解 4 个步骤的先后顺序”降到”知道有个退款功能”。
五、工具描述的写法
工具描述是大模型选工具的唯一依据。说狠点,写好描述比写好代码更重要。
好描述的四要素
|
|
|
|
|---|---|---|
| 做什么(What) |
|
|
| 什么时候用(When) |
|
|
| 需要什么(Input) |
|
|
| 返回什么(Output) |
|
|
对比一下:
❌ "查询数据库"✅ "根据订单号查询订单的当前状态、商品列表和物流信息。 当用户询问订单状态、发货情况或商品详情时使用。 返回 JSON 格式的订单详情。"参数描述要带格式提示
# ❌ 参数描述太简单{"order_id": {"type": "string", "description": "订单号"}}# ✅ 带格式提示,大模型提取参数更准{"order_id": {"type": "string","description": "订单号,格式为纯数字,如 1234567890。用户可能说'订单12345'或'单号12345',提取其中的数字部分即可。"}}大模型从用户自然语言中提取参数时,描述里的格式提示能大幅提升准确率。
六、工具设计速查清单
回过头看,工具设计最容易犯的错误就是按开发者的思维而不是大模型的思维来设计。
开发者觉得一个 manage_order(action, order_id, ...) 函数很优雅——参数灵活,一个函数搞定所有事。但大模型面对这种工具时,判断链越长,出错概率越高。
我的经验法则:把自己想象成一个实习生。如果实习生拿到这个工具的说明书,5 秒内能知道什么时候用、怎么用,那就是好的设计。
最后给一张速查表,设计工具时逐项对照:
|
|
|
|---|---|
| 单一职责 |
|
| 输入最小化 |
|
| 描述精准 |
|
| 输出结构化 |
|
| 幂等 |
|
| 粒度适中 |
|
| 参数带格式提示 |
|
| 命名直白 | query_order
handle_request |