 夜雨聆风
夜雨聆风





Claude Code源码泄露!一场意外,扒出AI好用的40%核心密码
Claude Code源码泄露!一场意外,扒出AI好用的40%核心密码,实测还真有东西
2026年3月31日,Anthropic旗下Claude Code又出大乌龙——更新npm包时,竟把60MB的source map调试文件误打包发布,直接导致1902个TypeScript源文件完整泄露。

但对全球开发者来说,这场低级失误却是天大的福利:这份泄露的源码,直接揭开了Claude Code「好用」的核心秘密——它的体验优势,60%靠Opus模型本身,剩下40%,全靠围绕模型搭建的「驾驭工程」(harness engineering)。

而这份源码,就是目前最鲜活的harness engineering学习教材。
什么是驾驭harness工程?
简单说,AI模型决定了「能不能做」,而笼具工程是围绕模型搭建的全套工程系统:包括提示词、安全机制、记忆系统、上下文处理、多Agent协作等,它决定了AI做得好不好、稳不稳、安不安全,让原本能力强但不可预测的AI,变成稳定可靠的交付工具。

接下来,我们就从泄露的源码里,扒一扒Claude Code这40%的核心设计,每一个思路都能直接借鉴!
1. 你发1句指令,AI收到一整本「专属说明书」

你以为在Claude Code里输入一句话,AI只收到这一句话?错了,这只是冰山一角。
源码里的 prompts.ts 文件,暴露了它的系统提示词拼装逻辑,每次对话都会生成一个庞大的专属提示词,分为静态+动态两部分:
– 静态部分(所有用户共享,可缓存):身份定义、安全准则、做事原则、工具使用规则、输出风格要求;
– 动态部分(千人千面):你的配置文件、当前工作目录/系统信息、Git仓库状态、自动记忆文件、已连接服务器信息。
关键设计:
一个
SYSTEM_PROMPT_DYNAMIC_BOUNDARY 常量,直接把提示词分成两段,既省成本省时间,又保证个性化,堪称教科书级设计。
⚠️ 小提醒:每接入1个MCP服务器,工具定义会消耗4000-6000个tokens,5个服务器就占上下文12%,工具不是越多越好,每一个都有认知成本。
2. 全自动模式背后,有「第二AI」做四层安全审查

用Claude Code的Auto模式时,别以为操作会直接放行——背后其实跑着两个AI,一个干活,一个专门守安全。
源码里的「权限分类器」系统,会把主AI的操作分成三档:Allow(放行)、Soft Deny(需确认)、Hard Deny(直接拦截),还设计了四层安全流水线,层层把关:
1. 查已有规则,命中直接放行;
2. 低风险操作,直接跳过审查;
3. 只读工具,白名单直接放行;
4. 其余操作,调用独立Claude Sonnet做确定性安全分类(温度设0,无偏差)。
还搭配了熔断机制:连续3次被拒/累计20次被拒,直接降级为手动模式,彻底杜绝乱操作。
这就是笼具工程的核心:想让AI敢干活,先给它划清「不能做什么」的边界,边界才是信任的基础。
3. 记忆系统的精髓:只记偏好,绝不记代码

Claude Code的自动记忆功能,应该是很多用户的最爱——它能精准记住你喜欢用TS、用单引号、不喜欢AI腔的文字,但源码里的设计,比想象中更讲究。
– 记忆提取非实时触发:仅在AI完成一轮回答后启动,还有限流,每N轮才检查一次;
– 提取由独立fork agent负责:这个子AI只有读文件、写记忆的权限,连Bash命令都不能跑,彻底隔离风险;
– 记忆严格分四类:user(用户偏好)、feedback(行为反馈)、project(项目信息)、reference(外部资源);
– 核心决策:绝不记代码:代码会随重构更新,固定的代码记忆只会变成误导,代码相关事实,永远实时从源码读取。
还有个暖心设计 autoDream :距上次整理超24小时、且积累5个以上新会话,后台会自动整理记忆文件,像人类睡觉梳理白天的记忆一样~
4. 上下文压缩:不是简单总结,而是9段式结构化提取

对话变长后,AI很容易「忘事」,Claude Code的解决办法,不是随便「总结一下」,而是9段式结构化压缩,每一段都有明确指向:
核心请求→关键概念→文件和代码→错误和修复→解决过程→所有用户消息→待办任务→当前工作→下一步行动。
✅ 最关键原则:所有用户消息必须完整保留!用户的每一次纠正、每一句随口的要求,都可能藏着偏好,丢了就容易重蹈覆辙。
这一点值得所有开发者借鉴:让AI保持记忆,别让它「自由总结」,给明确的结构化规则,比什么都靠谱。
5. 源码里的小惊喜:藏着未发布的虚拟宠物+未来功能
除了硬核设计,源码里还扒出了不少趣味细节和未来线索,Anthropic的小心思全暴露了:
– 虚拟宠物系统(src/buddy/目录,未发布):每个用户会有专属精灵,18种物种(鸭子、猫、龙、水豚、仙人掌…)、6种眼睛样式、完整稀有度系统,代码注释还写着「用来挑鸭子,Mulberry32算法够用了」,萌度拉满;
– 待开发功能曝光:feature flags里藏着PROACTIVE(主动模式,AI不等指令自己干活)、KAIROS(助手模式,高频出现154次)、DAEMON(常驻后台守护进程)、ULTRAPLAN(超级规划),看得出来,Claude Code不想只做「你问我答」的编程助手,要变成主动思考、持续运行的AI伙伴。
6. 多Agent协作:像真实公司一样,有领导有团队
Claude Code的多任务能力为什么这么强?因为它的Agent系统,直接复刻了企业级组织管理架构。
utils/swarm/目录下的多Agent框架,设计堪称精妙:
– 每个Team有Leader+Teammate,分工明确;
– 支持3种执行方式:同进程隔离、tmux窗口、iTerm2分割窗格;
– 各Agent用邮箱文件异步通信,独立Git Worktree工作,互不干扰;
– 权限冒泡机制:Teammate遇到需要确认的操作,先上报Leader决策,不是直接弹给用户,和真人团队的管理逻辑一模一样。
任务拆分、信息流转、冲突解决、结果合并,全按企业团队的玩法来,这才是多Agent协作的核心。
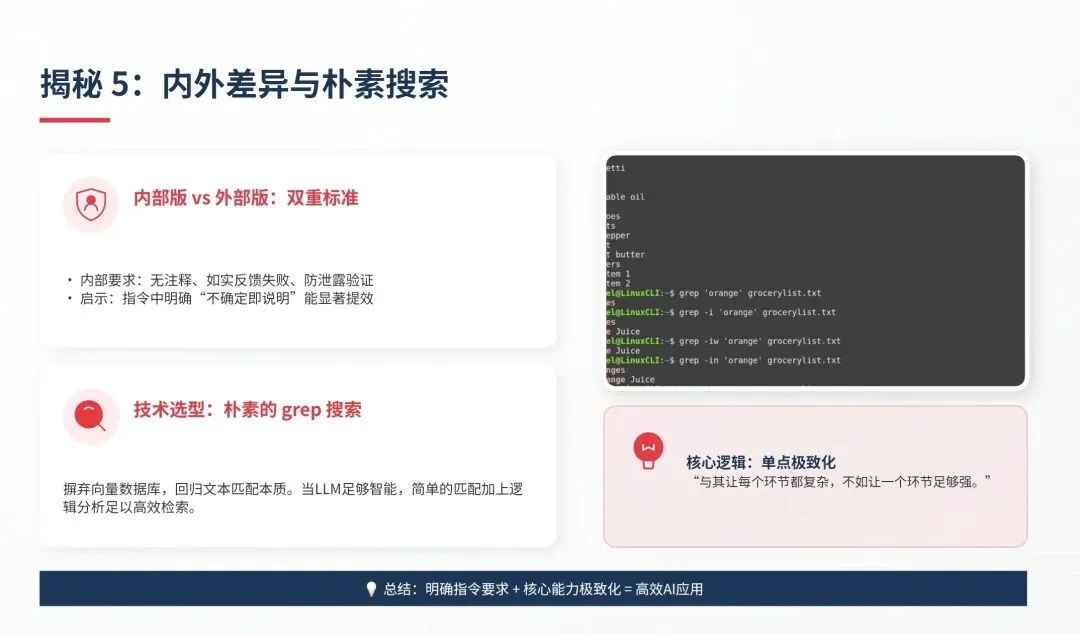
7. 内部版vs外部版:Anthropic的「双标」,藏着AI提效秘诀
源码里大量的 USER_TYPE === ‘ant’ 判断,直接揭开了Claude Code内部版(Anthropic员工用)和外部版的差异,而这些「双标」,正是让AI输出更高质量结果的关键:
– 代码风格:内部版「默认不写注释,只在原因不明显时加」,外部版无此要求;
– 诚实性:内部版要求「测试失败就说失败,没验证就说没验证,绝不粉饰」,外部版没有;
– 输出风格:内部版「像写给人看的文字,假设用户丢失上下文」,外部版仅要求「简洁直接」;
– 专属功能:内部版有Undercover防泄露模式、Verification Agent对抗性验证(完成后必须通过独立agent验证才敢报完成)。
💡 借鉴思路:想让AI出好活,就在指令里明确要求「不确定的地方直说」「完成前必须验证」,别给它模糊过关的空间。
8. 最颠覆的设计:先进AI工具,用最朴素的搜索
你可能以为,Claude Code搜索代码用了什么高大上的向量数据库、Embedding索引?毕竟整个RAG行业都在推这套。
但源码里的答案让人意外:它用的是grep和ripgrep——最朴素的文本搜索,没有Embedding,没有向量数据库。
为什么有效?核心逻辑:当有一个足够聪明的大脑(LLM)能理解搜索结果时,不需要聪明的搜索引擎。grep做精准匹配,LLM分析结果之间的关系,足够高效。
这也是驾驭工程的核心原则之一:与其让每个环节都变复杂,不如让一个环节足够强,其他环节保持简单。
最后:比源码更值得反思的,是两次低级失误
看完1902个文件,最核心的结论就是:同样的底层模型,套上不同的笼具工程,就是完全不同的产品。
市面上很多AI编程工具,底层都是调Claude或GPT的API,但体验天差地别,问题根本不在模型,而在围绕模型的工程设计。
而这次泄露更值得行业反思:Anthropic作为AI大厂,两次栽在「把source map文件打包进npm包」这个前端基础失误上,这提醒我们:AI时代,最大的风险往往不是AI太强,而是人在基础操作上的疏忽。
有趣的是,这份源码已经被GitHub镜像(https://github.com/instructkr/claude-code),即便Anthropic删了npm包,也删不掉开源社区的副本,网友戏称这是Claude Code的「越狱永生」——一场意外,让它的核心设计永远留在了互联网上。
对所有AI开发者和使用者来说,这场泄露都是一次难得的学习机会:当模型能力的比拼进入瓶颈,围绕模型的工程化设计,就是下一个核心竞争点。
Claude Code的这8个驾驭工程设计思路,直接抄作业就够了~

✨ 关注我,带你扒透AI前沿设计,把大厂思路变成自己的实战能力!
(文末互动:你觉得Claude Code哪个设计最惊艳?评论区聊聊~)
ppt晚些放送