 夜雨聆风
夜雨聆风





Claude Code 源码架构拆解
2026 年 3 月 31 日,Claude Code v2.1.88 的 npm 发布包中因未剥离 source map 文件,导致 1906 个源文件、51 万行 TypeScript 代码完整暴露。这不是入侵,不是内部泄密,是构建配置错误——sourceMap: false 未设置、.npmignore 未排除 .map 文件。Anthropic 数小时内发版修复,但社区已广泛备份。
从安全分析师的视角读完这套源码,我认为它值得拆解的原因只有一个:这是目前公开的、工程化程度最高的工业级 Agent 系统之一。不管是做安全检测、SOC 分析还是 AI 工程落地,这套代码里都有可以直接借鉴的模式。
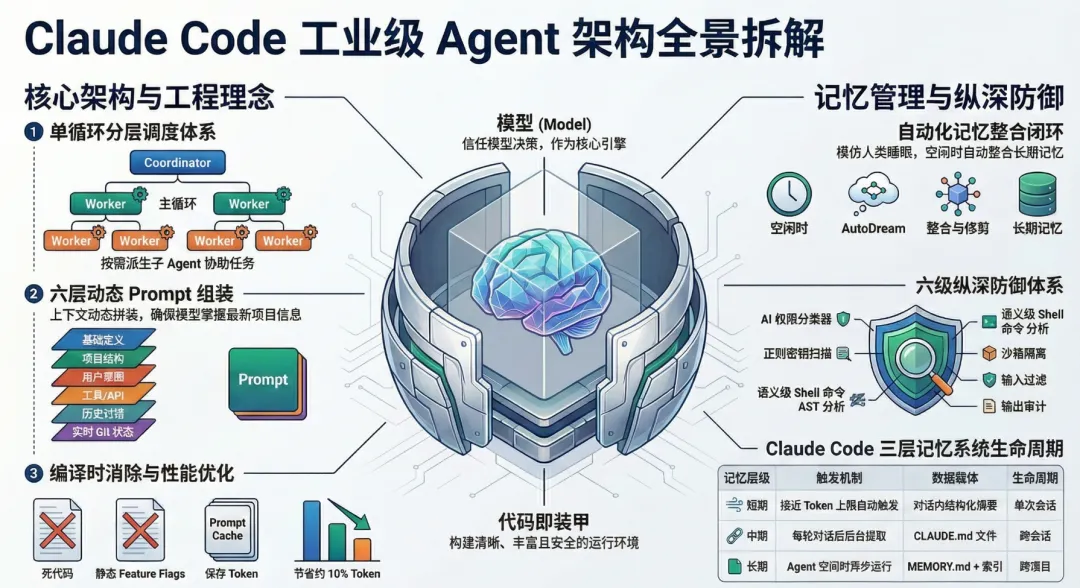
一、全局架构:单循环 + Harness,不是多 Agent 对等协作
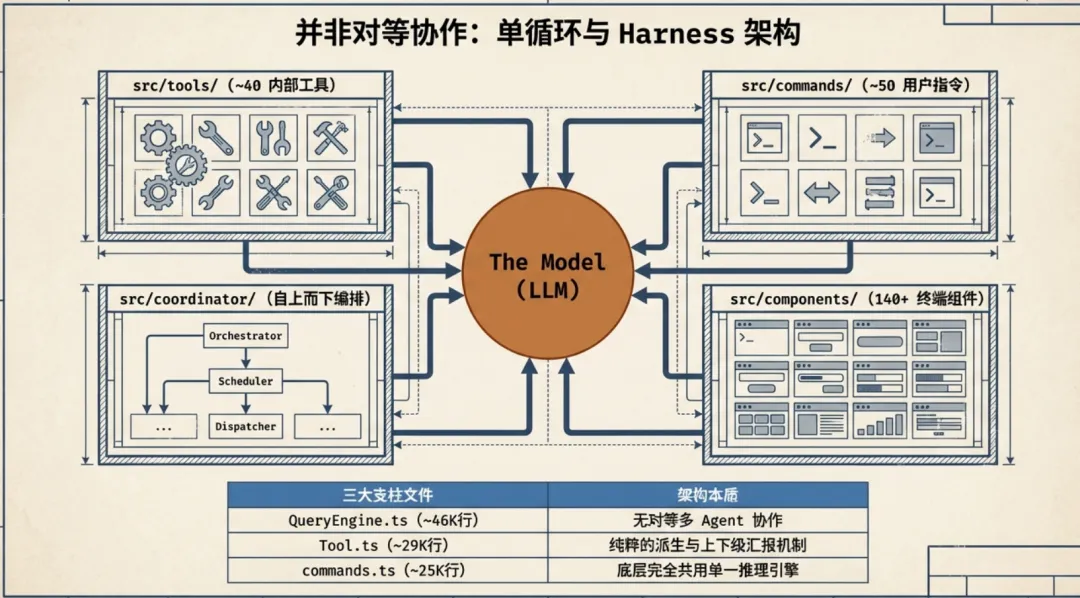
Claude Code 的源码里有 Coordinator、Worker、Fork 这些概念,乍看像多 Agent Swarm。但读完代码会发现,它是分层调度的——一个主循环在顶层,需要时往下派生子 Agent,子 Agent 干完活把结果交回来。上下级关系,不是对等协作。
1.1 核心公式
Claude Code = one agent loop + ~40 tools (bash, read, write, edit, glob, grep, browser...) + on-demand skill loading + context compression + subagent spawning + team coordination with async mailboxes + worktree isolation for parallel execution + permission governance源码按功能划分为 30+ 个顶层目录,每个目录对应一个 Harness 子系统:
| 目录 | 角色 | 说明 |
|---|---|---|
src/tools/ |
|
|
src/commands/ |
|
|
src/services/ |
|
|
src/coordinator/ |
|
|
src/skills/ |
|
|
src/bridge/ |
|
|
src/hooks/ |
|
|
src/plugins/ |
|
|
src/components/ |
|
|
src/memdir/ |
|
|
src/tasks/ |
|
|
src/state/ |
|
|
三个关键文件撑起了整个系统:
-
QueryEngine.ts(~46K 行)—— LLM 查询引擎:流式响应、工具调用循环、思考模式、重试、Token 计数 -
Tool.ts(~29K 行)—— 工具基础类型定义(Zod v4) -
commands.ts(~25K 行)—— 斜杠命令注册与执行
1.2 一个关键洞察
所有模式——单 Agent、Coordinator、Worker——共用同一个引擎。不管是普通对话还是多 Agent 编排,底层跑的都是同一个 QueryEngine 的 Think → Act → Observe → Repeat 循环。Coordinator 和普通 Agent 的区别,仅仅是换了一套 System Prompt。
二、Agent Loop:核心循环的工程实现
QueryEngine.ts 是 Claude Code 的大脑,循环结构很直白。
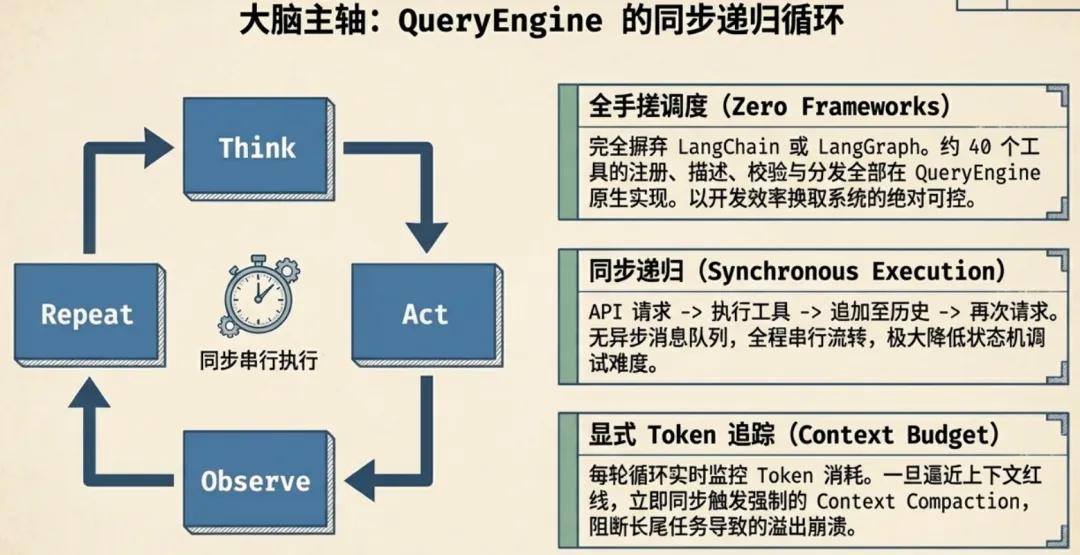
下面是从 query.ts(1730 行)中精简出来的核心循环骨架:
// query.ts — queryLoop 核心结构(精简版)async function* queryLoop(params: QueryParams){let state = { messages: params.messages, turnCount: 1 }while (true) {let messagesForQuery = getMessagesAfterCompactBoundary(state.messages) // 1. 上下文压缩(接近 Token 上限时自动触发) const { compactionResult } = await autocompact(messagesForQuery, ...)if (compactionResult) messagesForQuery = buildPostCompactMessages(compactionResult) // 2. 调用 Claude API,流式接收响应for await (const msg of callModel({ messages: messagesForQuery, tools, systemPrompt })) {if (msg.type === 'assistant') assistantMessages.push(msg) } // 3. 没有工具调用 → 结束循环,返回结果if (toolUseBlocks.length === 0) return { reason: 'end_turn' } // 4. 执行工具 → 收集结果 → 追加到对话历史 → 下一轮 const toolResults = await runTools(toolUseBlocks, canUseTool, toolUseContext) state = { messages: [...messagesForQuery, ...assistantMessages, ...toolResults], turnCount: state.turnCount + 1 } }}2.1 几个值得注意的工程细节
工具调度是全手搓的。没有用 LangChain、LangGraph 或任何第三方 Agent 框架。约 40 个 Tool 的注册、描述、参数校验、调用分发,全在 QueryEngine 里自己管。对于 Anthropic 这种体量的团队,可控性比开发效率更重要。
工具调用是同步递归的。API 返回工具调用请求 → 执行工具 → 结果追加到对话历史 → 再调 API。串行,没有异步消息队列。简单、可控、容易调试。
每轮循环有显式的 Token 追踪。一旦接近上下文窗口上限,自动触发 Context Compaction。这个机制保证了长时间运行的任务不会因为上下文溢出而崩溃。
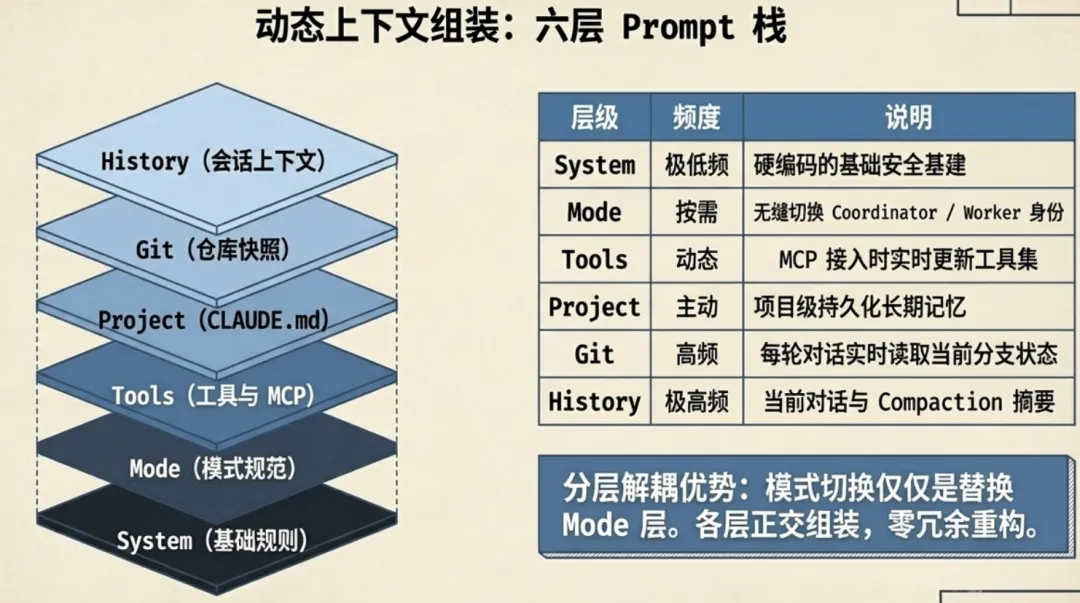
三、动态 Prompt 组装:六层拼装
Claude Code 的系统提示词不是一个写死的长字符串。context.ts 在每次调用 API 之前,从六个不同来源拼出完整上下文:
| 层次 | 来源 | 内容 | 更新频率 |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这种分层的好处是每一层可以独立更新,互不干扰。MCP 接入新工具只更新 Tools 层;Agent 切换到 Coordinator 模式只替换 Mode 层。这解释了为什么”Coordinator 本质上就是换了个 Prompt 的普通 Agent”——模式切换只动了六层里的一层。
四、Coordinator-Worker:需要时才启用的多 Agent 编排
4.1 Coordinator 的 370 行系统提示词
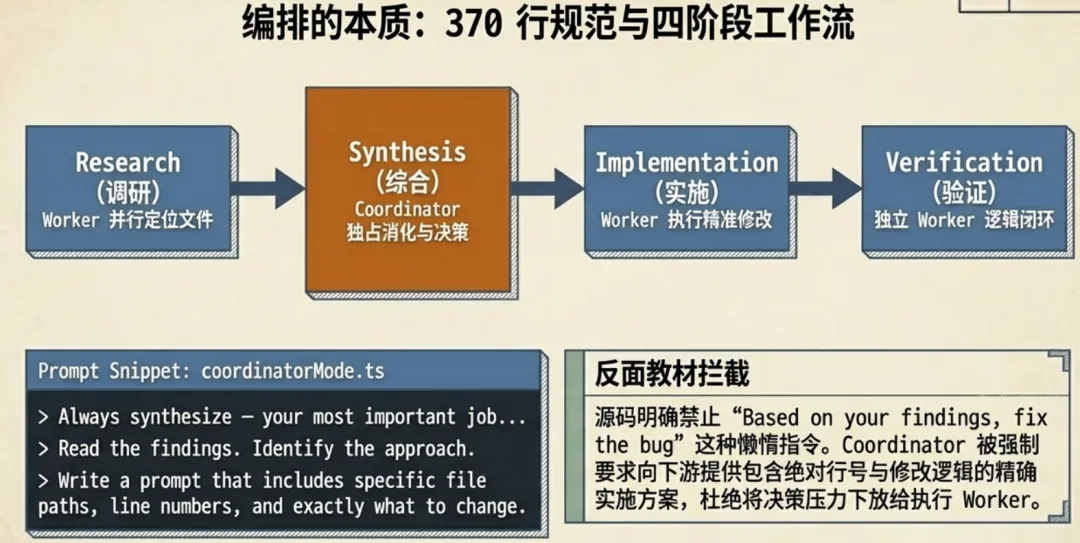
coordinatorMode.ts 里的 getCoordinatorSystemPrompt() 返回了一份超过 370 行的 Prompt,本身就是一份多 Agent 编排的工程规范文档。
核心是四阶段工作流:
| 阶段 | 执行者 | 职责 |
|---|---|---|
|
|
|
|
|
|
Coordinator 自己 |
|
|
|
|
|
|
|
|
|
Synthesis 阶段是关键。Prompt 用了非常强硬的语气(第 255-259 行):
Always synthesize — your most important job. When workers report research findings, you must understand them before directing follow-up work. Read the findings. Identify the approach. Then write a prompt that proves you understood by including specific file paths, line numbers, and exactly what to change.
紧接着给了一个反面教材(第 262-268 行):
// 反面教材 —— 偷懒式委派AgentTool({ prompt: "Based on your findings, fix the auth bug", ... })// 正面示例 —— 综合后的精确指令AgentTool({ prompt: "Fix the null pointer in src/auth/validate.ts:42.The user field on Session is undefined when sessions expire but thetoken remains cached. Add a null check before user.id access —if null, return 401 with 'Session expired'. Commit and report the hash.", ... })“Based on your findings, fix the bug” 这种写法把理解工作推给了 Worker,Coordinator 自己没做任何综合判断。正确的做法是自己消化理解,给 Worker 一个包含文件路径、行号和修改方案的精确指令。
4.2 AgentTool:Fork vs Fresh Agent
AgentTool/prompt.ts 定义了子 Agent 的两种模式:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Prompt 里还定义了两条规范:
-
Don’t peek(不要偷看)—— Fork 返回结果后,Coordinator 不要去读 Fork 的中间过程文件。”Reading the transcript mid-flight pulls the fork’s tool noise into your context, which defeats the point of forking.” -
Don’t race(不要抢跑)—— Fork 还在运行时,Coordinator 不能预测或编造结果。”Never fabricate or predict fork results in any format.”
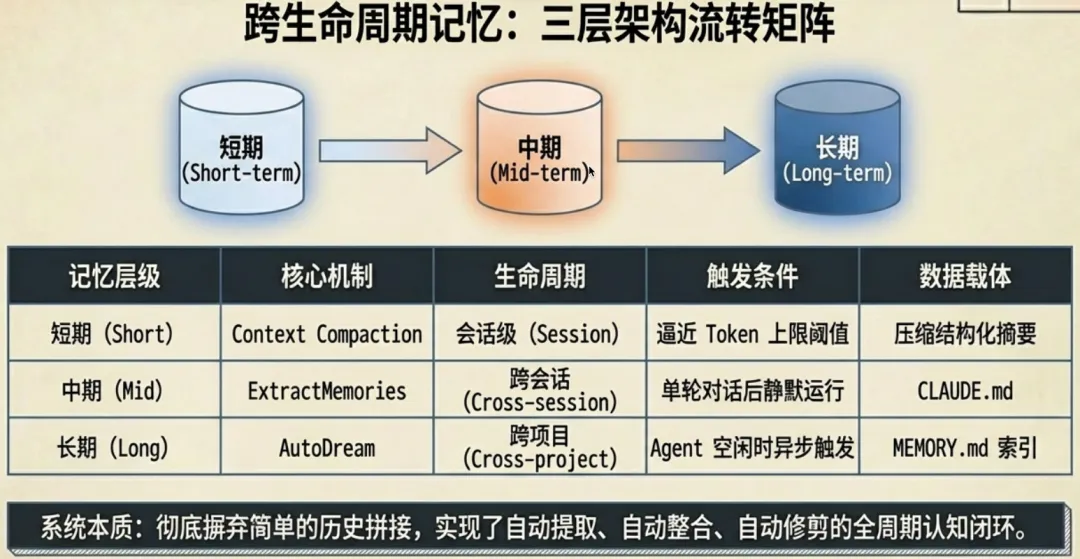
五、三层记忆系统:短期压缩、中期萃取、长期整合
这是我认为源码中技术含金量最高的部分。
5.1 Context Compaction:9 段式结构化摘要
services/compact/prompt.ts(375 行)定义了上下文压缩逻辑。不是简单截断历史,而是用专门的 LLM 调用把对话压缩成结构化摘要,严格 9 段格式:
1. Primary Request and Intent(主要需求和意图)2. Key Technical Concepts(关键技术概念)3. Files and Code Sections(涉及的文件和代码片段,含实际代码)4. Errors and fixes(遇到的错误和修复方案)5. Problem Solving(问题解决过程)6. All user messages(所有用户消息,逐条保留,不能遗漏)7. Pending Tasks(待办任务)8. Current Work(当前工作状态)9. Optional Next Step(可选的下一步,含原始对话直接引用,防止任务漂移)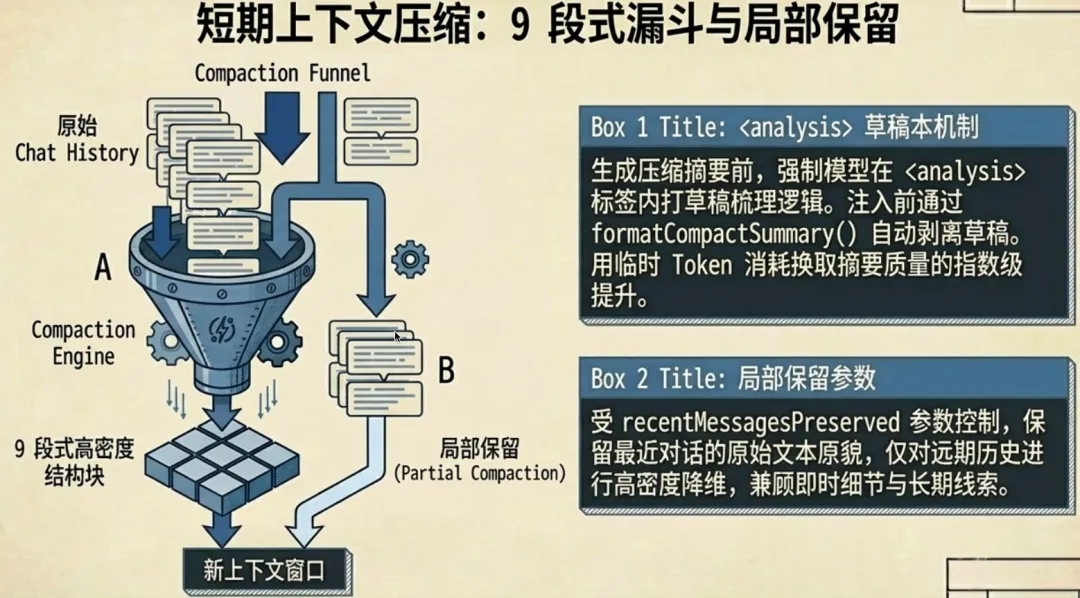
两个工程细节:
<analysis> scratchpad 机制 — 摘要生成时,模型先在 <analysis> 标签里写草稿梳理思路,生成后 formatCompactSummary() 自动剥离。用额外 Token 换取更高质量摘要,但不长期占用上下文窗口。
Partial Compaction — 不是全部压缩,只压缩靠前的旧内容,保留最近几轮原始对话(recentMessagesPreserved 控制)。近的保持原貌,远的变成高密度摘要。
5.2 ExtractMemories:后台自动记忆萃取
services/extractMemories/prompts.ts 定义了一个后台子 Agent,作为主对话的 Fork 独立运行,自动从对话中提取值得长期保存的信息。
前置判断:如果主 Agent 已经主动写过记忆文件(通过 hasMemoryWritesSince 检测),ExtractMemories 跳过,不重复提取。
执行约束:turn budget——要求先并行 Read 所有可能需要更新的记忆文件,再并行 Write,不允许交替读写。保证记忆更新的原子性。
记忆区分 private memory(个人记忆)和 team memory(团队记忆),写入不同路径。
5.3 AutoDream:记忆整合
services/autoDream/consolidationPrompt.ts 定义了 Dream 功能——Agent 空闲时自动整理已有记忆文件。四阶段执行:
| 阶段 | 动作 |
|---|---|
|
|
ls
MEMORY.md 索引,搞清楚当前有哪些记忆 |
|
|
|
|
|
|
|
|
MEMORY.md 索引不超过 200 行或 25KB |
这借鉴了认知科学中睡眠与记忆整合的研究——人在睡眠期间大脑对短期记忆做整理,转化为长期记忆。Claude Code 在 Agent 不忙时做了同样的事。
5.4 三层协同总览
| 记忆层 | 机制 | 生命周期 | 触发条件 | 数据载体 |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
对比市面上的 Agent 框架(LangGraph Checkpointer、CrewAI Memory),Claude Code 在自动化和结构化程度上都高出一个量级。大多数框架的记忆还停留在”把对话历史存起来”,Claude Code 做到了自动提取、自动整合、自动修剪的完整闭环。
六、权限系统:6 级纵深防御
Claude Code 的安全体系拒绝”一层顶全部”,构建了多层嵌套、层层兜底的防御:
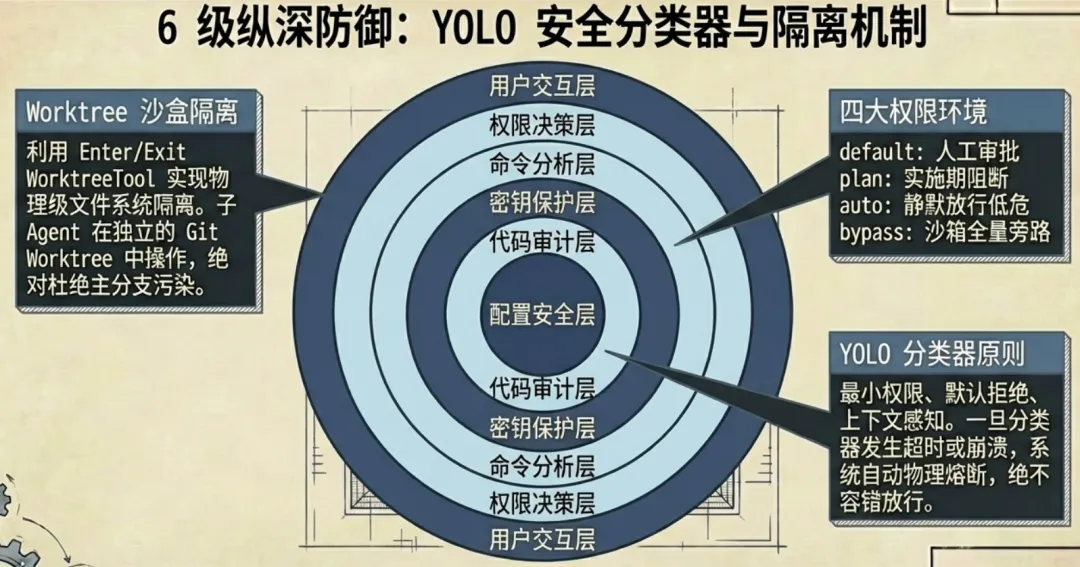
┌─────────────────────────────────────────────┐│ 用户交互层 ││ ┌─────────────────────────────────────────┐ ││ │ 权限决策层 │ ││ │ ┌─────────────────────────────────────┐│ ││ │ │ 命令分析层 │ │ ││ │ │ ┌─────────────────────────────────┐ │ │ ││ │ │ │ 密钥保护层 │ │ │ ││ │ │ │ ┌─────────────────────────────┐ │ │ │ ││ │ │ │ │ 代码审计层 │ │ │ │ ││ │ │ │ │ ┌─────────────────────────┐ │ │ │ │ ││ │ │ │ │ | 配置安全层 │ │ │ │ │ ││ │ │ │ │ └─────────────────────────┘ │ │ │ │ ││ │ │ │ └─────────────────────────────┘ │ │ │ ││ │ │ └─────────────────────────────────┘ │ │ ││ │ └─────────────────────────────────────┘ │ ││ └─────────────────────────────────────────┘ │└─────────────────────────────────────────────┘6.1 子系统 1:YOLO 安全分类器
AI 驱动的权限守门人,两阶段决策:
用户请求 → Stage 1 快速分类 → 明确允许? → ✅ 放行 ↓ 不确定 Stage 2 深度思考 → 允许? → ✅ 放行 ↓ 仍不确定 ❌ 默认阻止 (Fail-Closed)设计原则:最小权限、默认拒绝、上下文感知。分类器崩溃/超时自动阻止,绝不放行。
权限支持细粒度规则配置:
-
工具类型:不同工具有不同的默认权限级别 -
操作类型:读取比写入更容易获得批准 -
文件路径模式:限制 Agent 只在特定目录下操作 -
命令模式:BashTool 可配置允许的命令白名单
6.2 子系统 2:密钥扫描器
基于 30+ Gitleaks 正则规则,覆盖全场景密钥检测:
-
云服务:AWS / GCP / Azure / DO 全系列凭证 -
AI 平台:Anthropic / OpenAI / HuggingFace Token -
版本控制:GitHub / GitLab 密钥 -
SaaS:Slack / Twilio / npm / PyPI / Databricks -
支付:Stripe / Shopify -
通用:RSA / EC / PGP 私钥、通用 API Key 模式
核心底线:密钥永不离开用户机器。发现密钥 → [REDACTED] 替换 → 脱敏后才上传。
6.3 子系统 3:Shell 命令安全验证
不是黑名单匹配,而是语义级 AST 分析。支持 PowerShell 完整解析:词法分析 → 语法树构建 → 语义分析 → 安全裁决。能识别别名、管道隐式删除、变量拼接构造的危险命令。

6.4 多级权限模式
| 模式 | 行为 | 场景 |
|---|---|---|
default |
|
|
plan |
|
|
auto |
|
|
bypassPermissions |
|
|
6.5 Worktree 隔离
EnterWorktreeTool / ExitWorktreeTool 实现 Git Worktree 文件系统隔离:
main branch: /project/ (shared)├── worktree-task-1/ (Agent A 的 sandbox)├── worktree-task-2/ (Agent B 的 sandbox)└── worktree-task-3/ (Agent C 的 sandbox)每个子智能体在独立 sandbox 工作,不影响主分支。
七、可观测性:三层观测 + Agent 语义级 Span
Claude Code 把可观测性拆成了三个独立层次:
| 层 | 模块 | 回答什么问题 |
|---|---|---|
|
|
services/analytics/ |
|
|
|
utils/telemetry/instrumentation.ts |
|
|
|
utils/telemetry/sessionTracing.ts |
|
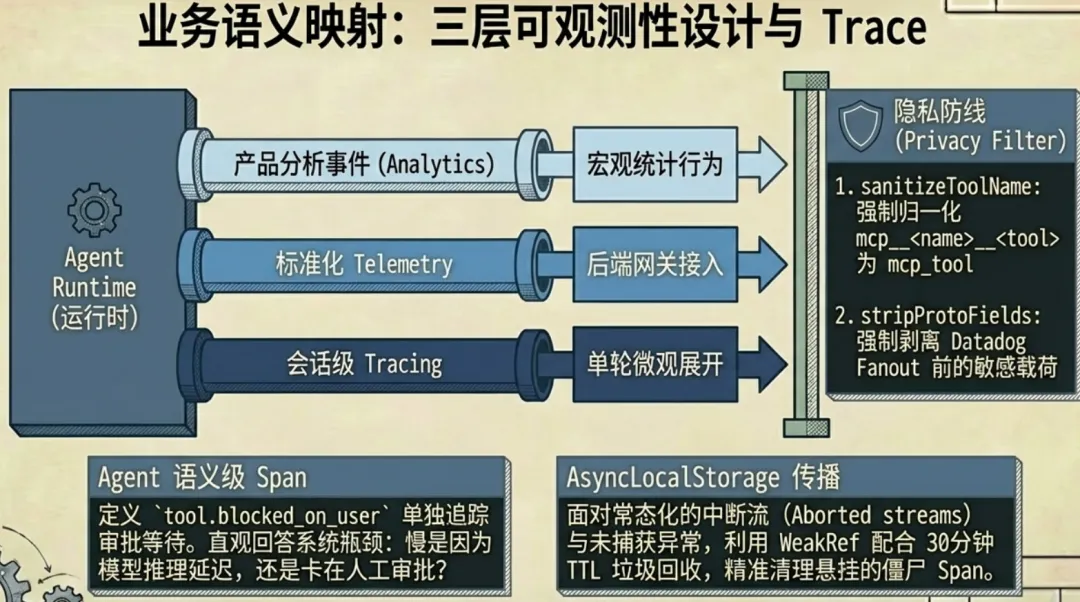
关键设计是把 Agent 业务语义直接编码成 span 类型:
interaction(用户交互回合,root span) ├── llm_request(模型调用) ├── tool(工具被选中) │ ├── tool.blocked_on_user(等待用户批准) │ └── tool.execution(实际执行) └── hook(钩子执行)tool.blocked_on_user 单独追踪等待批准的时间。这意味着 trace 能回答:慢是因为模型慢,还是审批慢?某类工具成功率低,是执行问题还是被拒绝太多?
实现上用 AsyncLocalStorage 做上下文传播,WeakRef + 30 分钟 TTL cleanup 处理悬挂 span。注释写得很直接:这是 safety net for spans that were never ended——aborted streams、uncaught exceptions、mid-query 中断在 Agent runtime 里是常态,不是边缘情况。
事件出口还有隐私设计:sanitizeToolNameForAnalytics() 默认把 mcp__<server>__<tool> 收敛成 mcp_tool,防止自定义 MCP server 名包含个人信息泄露。_PROTO_* 字段在 Datadog fanout 前统一 stripProtoFields(),一个过滤点管住所有 sink。
八、极限工程细节:几个很实用的设计
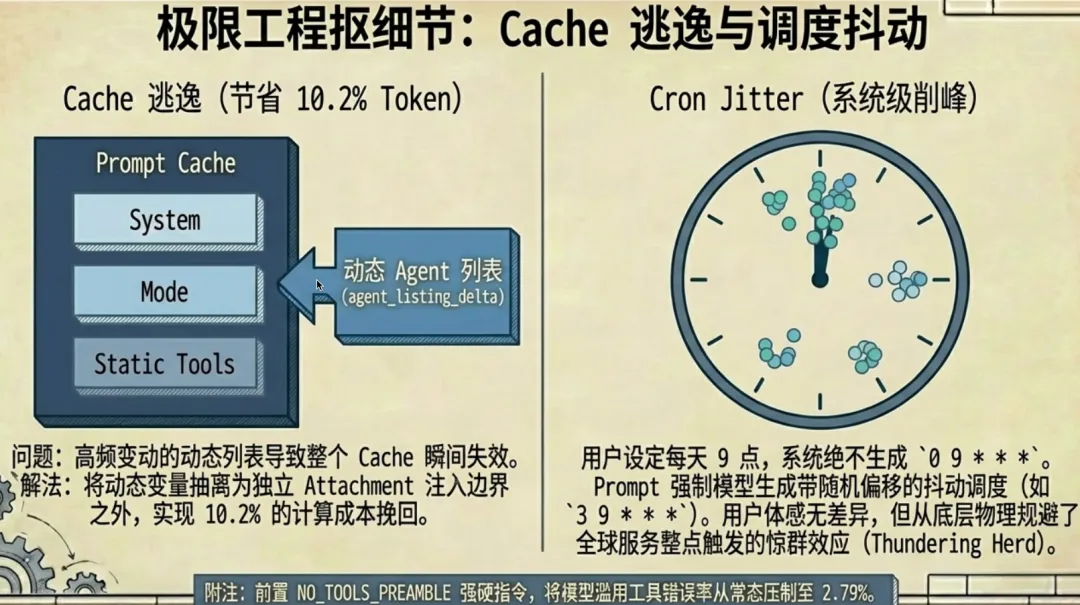
8.1 Agent 列表从内联改 Attachment:省了 10.2% Cache Token
原来的 Agent 列表写在工具描述里。MCP 连接、插件加载、权限变更时列表变化 → 工具描述变化 → 整个 tools-block 的 Prompt Cache 失效。
源码注释记录了精确数据:
“The dynamic agent list was ~10.2% of fleet cache_creation tokens”
解决方案:Agent 列表从工具描述移到 agent_listing_delta attachment 消息注入。工具描述变静态,Cache 不再因列表变化失效。
通用启示:凡是用 Prompt Cache 的场景,把频繁变化的内容从 Cache 边界内移到边界外。
8.2 Cron 调度的 Jitter 设计
用户说”每天早上 9 点提醒”,不设成 0 9 * * *,而是偏移几分钟如 57 8 * * * 或 3 9 * * *。
Prompt 原文:
“Pick a minute that is NOT 0 or 30… the user will not notice, and the fleet will.”
全球用户说”9 点”都映射到 :00,不偏移就会整点集中爆发。用户无感,系统受益。
8.3 NO_TOOLS_PREAMBLE:防止模型在不该调工具时调工具
Context Compaction 通过 Fork 主对话执行,Fork 继承完整工具集(为命中 Prompt Cache)。但摘要任务不需要调用工具。Sonnet 4.6+ 有时自作主张调用工具,失败率精确到 **2.79%**(4.6 vs 4.5 的 0.01%)。
解决方案——在 Prompt 最前面加强硬约束:
CRITICAL: Respond with TEXT ONLY. Do NOT call any tools.- Do NOT use Read, Bash, Grep, Glob, Edit, Write, or ANY other tool.- Tool calls will be REJECTED and will waste your only turn — you will fail the task.约束放在 Prompt 开头而不是末尾,因为模型对 Prompt 开头的注意力最集中。
8.4 Feature Flags 的编译时消除
通过 bun:bundle 的 feature() 函数控制功能开关。不是运行时判断——是编译时 Dead Code Elimination。关闭的 flag 相关代码在构建产物里根本不存在。不会占内存,没有运行时分支开销。
泄露的 flags 暴露了未发布功能方向:PROACTIVE(主动模式)、KAIROS(定时任务系统)、DAEMON(守护进程模式)、VOICE_MODE(语音交互)、MONITOR_TOOL(监控工具)。
九、技术栈总览
| 类别 | 技术选型 | 意义 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
十、隐藏功能:Feature Flag 背后的未发布内容
源码中发现的几个有意思的未发布功能:

Buddy — 电子宠物系统(Tamagotchi 风格 ASCII 宠物),18 种物种,6 种稀有度,闪光款设定。时间戳显示 4 月 1 日首次亮相 → 愚人节彩蛋。
Kairos — 持久化助手模式,跨会话长期记忆。你不使用时自动执行四阶段记忆整合(定向→收集→整合→修剪)。
Ultraplan — 使用 Opus 4.6 支持最长 30 分钟深度任务规划。Plan → Approve → Execute 三阶段模型。规划用强模型(高成本、低频),执行用快模型(低成本、高频)。
Undercover Mode — 向开源 PR 提交时移除 Anthropic 信息,让 AI 伪装成人类。引发社区争议。
共 35 个编译时特性标志、120+ 隐藏环境变量、200+ 远程控制开关。
十一、安全影响:源码公开后的已知风险
源码公开加速了安全研究,已发现并修复的问题包括:
-
CVE-2025-54795 — 代码执行漏洞 -
符号链接绕过、沙箱逃逸、配置文件注入 -
恶意仓库在用户确认信任前窃取 API 密钥 -
管道 sed操作绕过文件写入限制 -
.claude/settings.json不存在时沙箱未正确保护,允许恶意代码注入持久化钩子
对于做安全检测的人来说,这套源码的价值在于:你可以精确理解一个工业级 Agent 的攻击面在哪里。权限模型的每个 hook 点、密钥扫描的每条正则、Shell 命令 AST 分析的每个边界条件——这些就是检测规则和防护策略的蓝本。
十二、总结
Claude Code 的源码给我们的最核心启示只有一句话:
“The model is the agent. The code is the harness.”
模型决定做什么,Harness 负责怎么做。Claude Code 不试图通过规则引擎或决策树来模拟智能——它完全信任模型的决策能力,把全部工程精力投入到为模型提供一个清晰、丰富、安全的工作环境。
从工具系统(40+ 原子工具、分层行动-感知体系)到知识管理(按需加载、渐进式披露),从上下文工程(三层压缩策略)到多智能体协调(六种架构模式、异步邮箱通信),从权限治理(6 级纵深防御)到性能优化(并行预取、懒加载、编译时死代码消除)——每一个子系统都展现了成熟的工程决策。
最好的 Agent 产品来自于那些理解”自己的工作是 Harness,而非智能”的工程师。当工程精力从”试图编程智能”转向”为智能构建世界”时,Agent 系统的能力上限将由模型本身的智能水平决定,而非被差劲的 Harness 设计所限制。
源码参考:https://github.com/instructkr/claude-code