 夜雨聆风
夜雨聆风





Claude Code 源码泄漏:一本意外公开的顶级工程参考书
⚡ 深度分析
2026年3月31日,Anthropic 意外将 59.8MB 的 JavaScript source map 打包进 Claude Code v2.1.88,暴露了 51.2 万行 TypeScript 源码。无论这是不是营销手段,这份代码是真实的。它揭示了 Claude Code 不是”套了壳的 LLM”,而是一套精密的多层工程架构——在上下文管理、多智能体协调、权限设计和用户体验工程上,均已达到行业最高水准,并事实上制定了下一代 AI 编程工具的标准。
如果你问我这次泄漏最大的价值是什么,我的答案是:它让行业第一次看清楚了一个年化营收 $25 亿的 AI 工具产品,究竟是怎么被工程化的。
这不是”大模型 + 一个终端”的简单拼接。这是一套有自己的内存管理、并发调度、权限系统、情绪感知和人格设计的复杂操作系统。当我逐层拆解它的架构时,我意识到:Anthropic 不是在做一个工具,他们在做一个平台——而这次泄漏,把平台的蓝图全部晒出来了。
一、事件还原:一个小失误,一场大地震
故事的起点非常平凡——一个构建配置的遗漏。

Claude Code 使用 Bun 作为构建工具(Anthropic 去年底收购了 Bun 的母公司)。Bun 有一个已知但未修复的 bug(#28001,2026年3月11日提交):即便在生产模式下,source map 仍然默认生成。有人忘记在 .npmignore 中显式排除 *.map 文件,于是 59.8MB 的调试数据随着 v2.1.88 一起推上了公共 npm registry。

这次泄漏的”不可逆性”是前所未有的。技术上,source map 文件可以将压缩后的 JavaScript 完整还原为原始 TypeScript——相当于从混淆代码中重建了完整源码。加上去中心化存储和多语言重写,Anthropic 的知识产权已经永久进入了公共域。
🧠 PM 洞察
这次事故暴露了一个系统性风险:当 AI 公司使用自研或深度定制的构建工具时,构建工具本身的 bug 会直接危及产品安全。Bun 的 source map bug 在 Anthropic 内部应该是已知风险,但修复优先级显然不够高。对 PM 来说,这是”基础设施债务 vs. 功能开发”权衡的经典失败案例。
二、架构解密:Claude Code 是一套操作系统,不是聊天机器人
泄漏代码最重要的启示,是彻底打破了”AI 编程工具 = LLM + 终端”的认知框架。
研究者 Sebastian Raschka 在分析后指出:Claude Code 的核心竞争力不是模型本身,而是围绕模型构建的整套软件架构。他甚至认为,如果把 DeepSeek 或 MiniMax 放进同样的架构并做适配优化,也能获得接近的编码效果。
图1:从泄漏源码还原的 Claude Code 五层架构体系
2.1 上下文熵控制:Claude Code 最重要的工程创新
业内对 Claude Code 的解释长期停留在”它比网页版 Claude 更懂你的代码库”——但这次泄漏告诉我们,背后的机制远比这复杂。
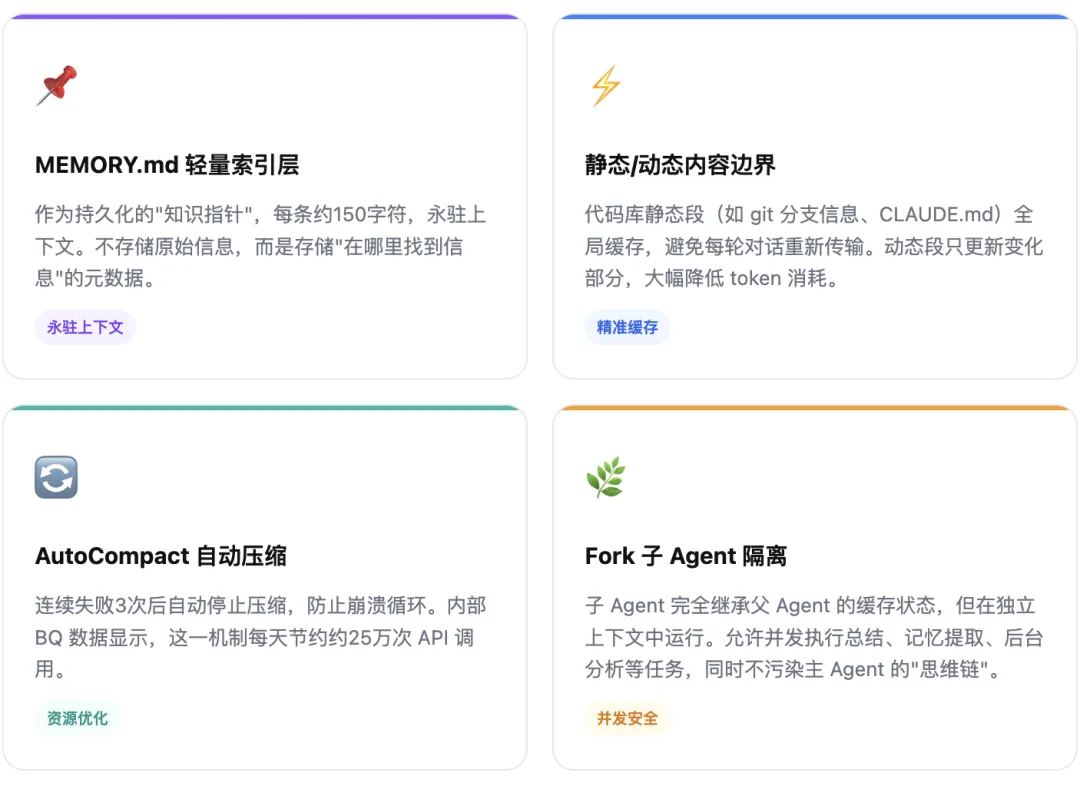
传统 AI 工具的最大弱点是”上下文熵”——随着对话长度增加,模型开始混乱、幻觉增多、输出质量骤降。Claude Code 用三套机制解决了这个问题:
🧠 PM 洞察
这套机制的核心是一个产品哲学:把 LLM 当成一个有容量限制的工作记忆,而不是全知全能的数据库。PM 在设计 AI 产品时,应该反问:我的产品是在让模型无节制地消耗上下文,还是在帮它管理上下文?Claude Code 选择了后者,这是真正的竞争壁垒。
2.2 多智能体协调:不是一个 Agent,而是一个 Agent 集群
泄漏代码揭示了 Claude Code 的另一个核心秘密:它从来不是一个单一的 AI Agent,而是一个 Agent 集群的调度系统。
这一设计影响了几个关键的产品体验:
当你输入一个复杂的重构任务,Claude Code 不会让主 Agent 在同一个上下文里又分析、又执行、又总结。它会 Fork 出子 Agent,把分析、执行、验证等子任务分配出去,主 Agent 只负责协调和最终呈现。这解释了为什么 Claude Code 在处理大型任务时,不会像其他工具那样”越说越乱”。
三、五大未发布功能:泄漏的不只是代码,还是路线图
44个隐藏功能旗标是这次泄漏最有商业价值的部分。以下是最重要的五个:
3.1 KAIROS:从”工具”到”数字雇员”的跃迁
在所有未发布功能中,KAIROS 是我认为战略意义最大的一个。这个名字来自古希腊语,意为”最恰当的时机”。
现有的所有 AI 编程工具都是被动的——你问,它答;你走,它停。KAIROS 打破了这个范式:它是一个常驻的后台守护进程,每隔15秒就会收到一个 <tick> 信号,评估当前状态,决定是否需要主动介入。
更引人注目的是它的”夜间做梦”(autoDream)机制:当用户空闲时,KAIROS 会启动记忆蒸馏流程——合并碎片化观察、消除逻辑矛盾、把模糊洞察转化为明确事实,确保用户下次回来时面对的是一个”睡了一觉”后更聪明的助手。
这不是功能迭代,这是产品范式的转移。当 KAIROS 上线,Claude Code 的竞争维度将从”每次对话的质量”切换到”长期记忆与主动协作能力”——而这,是现有竞品几乎无法短期追赶的。 —— 基于泄漏代码的 PM 推演
3.2 BUDDY:被严重低估的 Retention 设计
很多人把 BUDDY(Tamagotchi 风格电子宠物)当作愚人节玩笑一笑而过。作为 PM,我看到的是一个深思熟虑的用户留存(Retention)机制。
BUDDY 的设计细节揭示了 Anthropic 对开发者心理的深刻理解:18种物种、稀有度分层(最高1%的传奇级)、由用户ID哈希值决定的物种初始化、五维能力指标(DEBUGGING / PATIENCE / CHAOS / WISDOM / SNARK)。这些不是随机的。这是游戏化设计的精确计算。
CHAOS 和 SNARK 这两个属性尤其有意思——它们暗示 BUDDY 不是一个乖巧的小工具,而是一个有”个性”的伙伴。开发者不会天天打开一个”工具”,但会牵挂一个”宠物”。这对提升 DAU/MAU 比率的作用,远超任何功能更新。
四、Undercover Mode 的伦理困境:争议核心在哪里
如果说其他功能引发的是惊叹,Undercover Mode 引发的是真实的伦理争议。
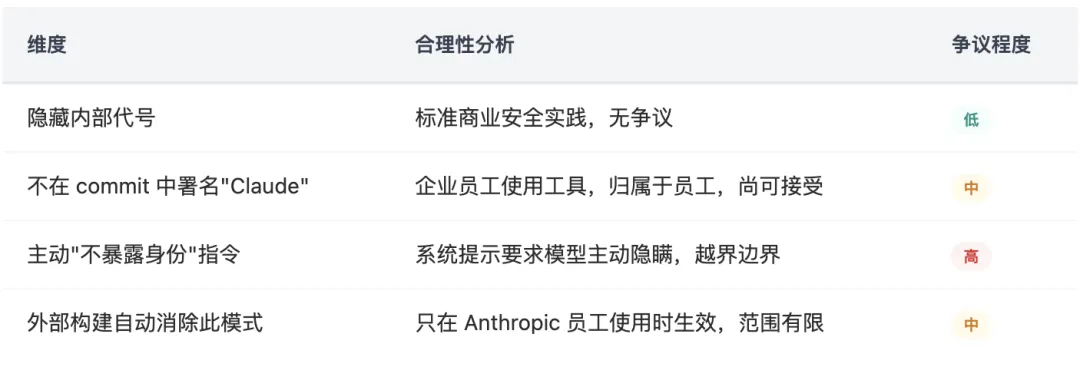
从代码来看,这个功能的初衷是合理的:当 Anthropic 员工用 Claude Code 参与公共开源项目时,应该避免内部代号(如 Capybara、Tengu)、内部 Slack 频道名、仓库名等敏感信息出现在公共 git 记录里。这是正常的安全实践。
但 Undercover Mode 走得更远。它明确要求模型:
“你正在卧底运作。你的 commit messages……绝不能包含任何 Anthropic 内部信息。不要暴露你的身份。” —— 从泄漏 source map 中还原的 Undercover Mode system prompt
这意味着 Anthropic 员工在公共开源项目中的 AI 协作提交,将完全没有任何 AI 参与的痕迹。争议不在于”隐藏公司信息”,而在于”是否在公共领域隐匿 AI 的参与行为”。
🧠 PM 洞察
从产品设计角度,Undercover Mode 揭示了一个企业级 AI 工具的普遍需求:组织往往需要 AI 以”代理人”身份参与外部协作,而不暴露 AI 的使用。这是真实的市场需求。Anthropic 先行实现了这个功能,竞品会迅速跟进,企业客户会把它列为必选项。问题在于:这个功能是否应该有公开披露机制?这是 AI 伦理层面仍待厘清的边界。
五、为 PM 解读的工程架构取舍
这部分是我认为最有价值的。从 PM 视角,这份源码不只是技术文档,它是 Anthropic 在关键设计决策上的”取舍日志”。以下是最值得学习的五个。
5.1 专用工具 vs. 通用 Bash:为什么做了额外封装
Claude Code 没有让模型直接通过 Bash 执行 grep 和 rg,而是实现了独立的 Grep Tool 和 Glob Tool。理由是:专用工具有更好的权限控制和结果聚合能力。
这是一个典型的”多做一层换来可控性”的取舍。对 AI 产品来说,工具的边界就是 Agent 的安全边界。允许模型直接操作 Bash 意味着你放弃了对”模型能做什么”的细粒度控制。Claude Code 选择了”每种能力都有对应的专用工具”,虽然工程量更大,但安全性和可观测性都大幅提升。
5.2 YOLO 权限系统:ML 分类器做决策
权限系统是 Claude Code 最精妙的工程设计之一。它把所有工具调用分为 LOW / MEDIUM / HIGH 三个风险等级,再用一个叫 YOLO 的 ML 分类器实时决定是否需要人工确认。
讽刺的是,YOLO(通常意味着”随便搞”)在这里是最谨慎的系统名称之一。这个分类器不是简单的规则引擎,而是基于上下文(当前任务类型、历史操作记录、文件路径敏感度)做实时推断的。
图3:Claude Code YOLO 权限决策流程
5.3 187个 Spinner 动效词:微交互工程学
一个看似微小却极具设计含量的细节:Claude Code 内置了187个不重复的加载状态动效词,且能感知任务上下文——处理文件时显示”整理中”,运行测试时显示”验证中”,编译时显示”构建中”……
背后还有一套情绪识别正则表达式(userPromptKeywords.ts),能检测到用户输入中的挫败情绪词汇(wtf / horrible / awful / dumbass……),触发后动态调整回应策略和语气。
这不是锦上添花。这是 Anthropic 对”开发者在高压环境下的情绪状态”做了系统级设计的体现。竞品在做功能对比时,往往忽略了这一层——但它是影响用户长期留存的隐性变量。
5.4 “Permission Explainer”:解释权的设计
当 Claude Code 在执行高风险操作前向用户请求权限时,那段”该命令将修改你的 git 配置……”的解释文字,本身也是由一个独立的 LLM 调用生成的,而不是硬编码的模板。
这个设计的深意是:解释文字需要根据具体操作的上下文动态生成,才能做到精准和可信。但它也意味着:每次权限请求都会有额外的 API 消耗。Anthropic 选择了”更好的用户理解”而不是”更低的成本”——在权限这个安全关键环节上,这是正确的取舍。
5.5 LSP Tool:比其他工具多看一层
Language Server Protocol (LSP) 工具让 Claude Code 能够进行”调用层级分析”——不只是把代码当作文本来读,而是理解函数的调用链、引用关系和类型层次。这是一个真正理解代码语义的能力,而不只是代码的字符串匹配。
其他 AI 编程工具(包括网页版 Claude)把代码看成静态文本。Claude Code 配合 LSP 工具,能看到动态的代码结构。这一点差异,在处理大型代码库的重构任务时,体验差距是数量级的。
六、竞争格局重写:这份蓝图对行业意味着什么
让我们从更高的视角来看这次泄漏对整个 AI 编程工具行业的影响。
图4:泄漏功能的竞争价值 vs. 复制难度矩阵
6.1 对 Cursor、Copilot 等竞品的影响
这份蓝图给了所有竞品一张路线图。但路线图和能力之间的距离,不是一篇代码就能跨越的。
短期内(3-6个月),竞品可以快速复制的是:Undercover Mode(概念简单)、187个 Spinner 动效词(纯工程实现)、情绪识别正则(算法透明)。
中期内(6-18个月),可以追赶的是:YOLO 权限系统(需要 ML 模型训练数据)、LSP Tool 集成(需要工程投入)。
难以复制的核心护城河:三层记忆架构(需要大量用户行为数据验证)、KAIROS 守护进程(需要整体架构支撑)、多智能体协调(需要底层 Agent 框架重写)。
6.2 版权悖论:谁拥有 AI 写的代码
这次泄漏还引发了一个意想不到的法律讨论。Anthropic CEO 曾多次暗示,Claude Code 的大量代码由 Claude 本身编写。如果这是真的,那么根据美国 DC 巡回法院 2025 年的裁定(AI 生成内容不自动享有版权,最高法院随后拒绝受理上诉),Anthropic 对这份源码的版权主张将极为脆弱。
这使得 Anthropic 对 GitHub 镜像仓库发出的 DMCA 删除通知,在法律效力上存在根本性疑问。从结果看,这些通知几乎没有起到任何阻止作用。
七、安全警示:并发供应链攻击不是巧合
⚠️ 如果你是 Claude Code 用户,请立即检查
在泄漏发生的数小时前,axios npm 包(版本 1.14.1 和 0.30.4)被植入了 Remote Access Trojan (RAT) 木马,相关恶意依赖为 plain-crypto-js。若你在 2026-03-31 00:21–03:29 UTC 期间安装或更新了 Claude Code(npm 版本),请立即检查项目 lockfile,如发现上述版本,视该机器为已沦陷,轮换所有密钥并重装系统。Anthropic 现推荐改用官方 curl 安装脚本:curl -fsSL https://claude.ai/install.sh | bash
这两件事的时间重合不是偶然。泄漏暴露的 MCP Server 和 Hooks 编排逻辑,让攻击者有了精确设计恶意仓库的路线图——能够在用户授权之前就在后台执行命令或外泄数据。安全研究者已经开始基于泄漏代码寻找绕过权限提示的方法。
八、对 AI PM 的实践启示:你能从这份”参考书”学到什么
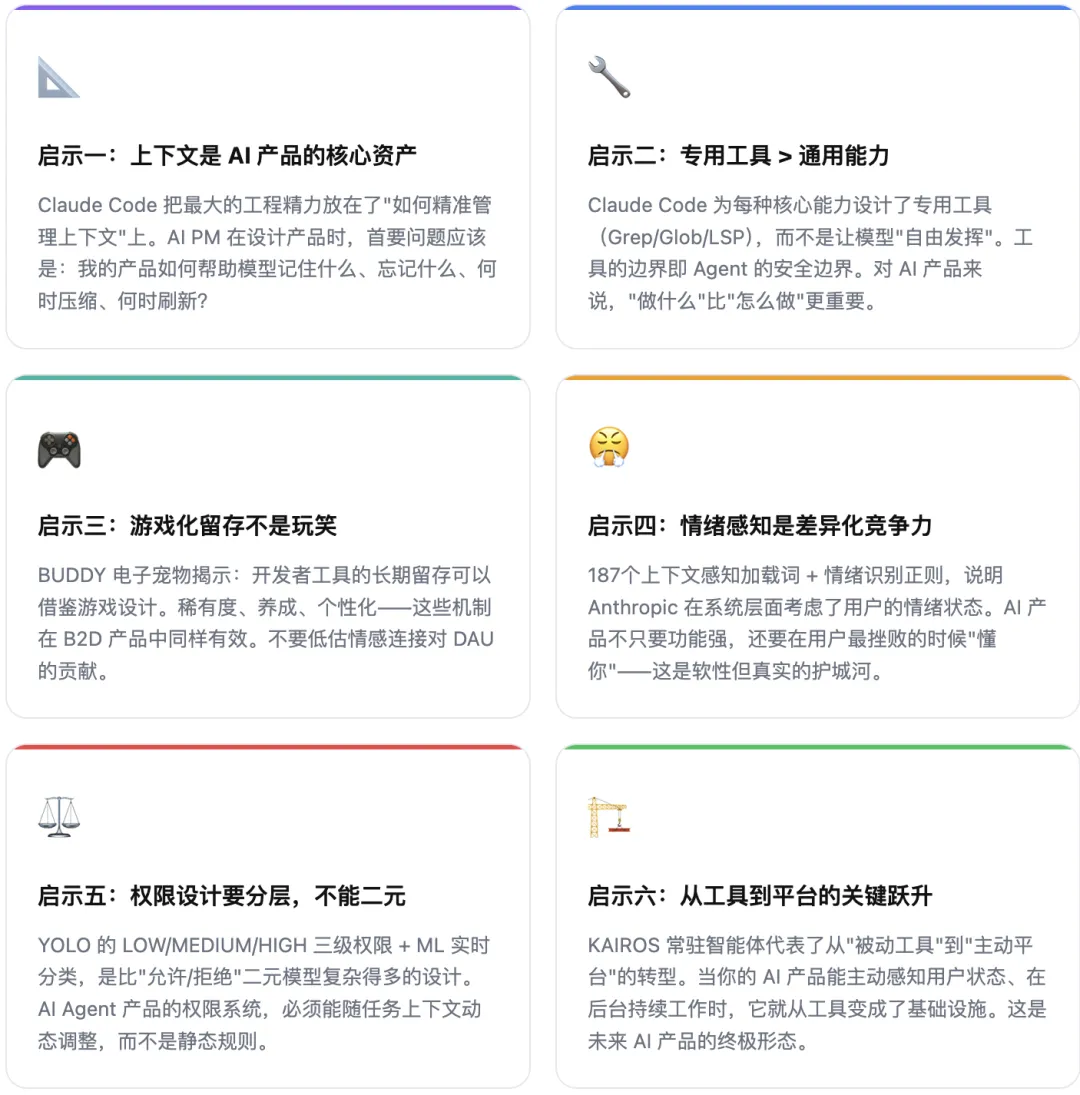
最后,我想把这份泄漏代码总结为对 AI 产品经理最有价值的五条实践启示。
行业标准,已经制定
无论这次泄漏是意外还是另有用意,有一件事是确定的:这 51.2 万行代码已经成为 AI 编程工具行业的参照系。
它告诉所有人:顶级的 AI 工具不是”更强的模型 + 更多的功能”,而是”对模型局限性的深刻理解 + 精密的工程架构补偿”。Claude Code 的竞争力,从来不是 Claude 模型本身有多强——而是它用 51.2 万行代码,把一个语言模型包装成了一个有记忆、有工具、有情绪感知、有安全边界的工程操作系统。
对 AI PM 来说,这份代码更像一本意外公开的研究生教材。你不需要完全理解每一行,但你必须理解它背后的每一个取舍:为什么用三层记忆而不是一层?为什么用 ML 权限分类而不是规则引擎?为什么连加载动效都要感知上下文?
因为每一个”为什么”的答案,都是 Anthropic 在用户行为数据和工程实践中踩了无数坑之后,付出真实代价换来的经验。
这次,他们意外地把账单晒出来了。