 夜雨聆风
夜雨聆风





Claude Code 源码记忆系统,竟然会做梦?
这两天一直在看 Claude Code 那套记忆系统。
本来我以为,这一块最多就是“记住用户偏好”“做个长期上下文”,看完才发现,不是这么简单。
它做的不是一个备忘录。
它在做一套认知系统。
很多人一聊 AI,注意力还是会先落在模型上。
模型更强了没有,推理更稳了没有,代码写得更好了没有。
这些当然重要。
但我这次看完最强烈的感受反而是:模型像发动机,记忆更像方向盘、地图,甚至像这个 AI 跟你一起生活过的痕迹。
一个每次都从头认识你的 AI,和一个会慢慢懂你、记住你、修正自己理解的 AI,根本不是一回事。
差距也不只是“更方便一点”。
差距是,它开始有连续性了。
Claude Code 里有个设计,我觉得特别像人话。
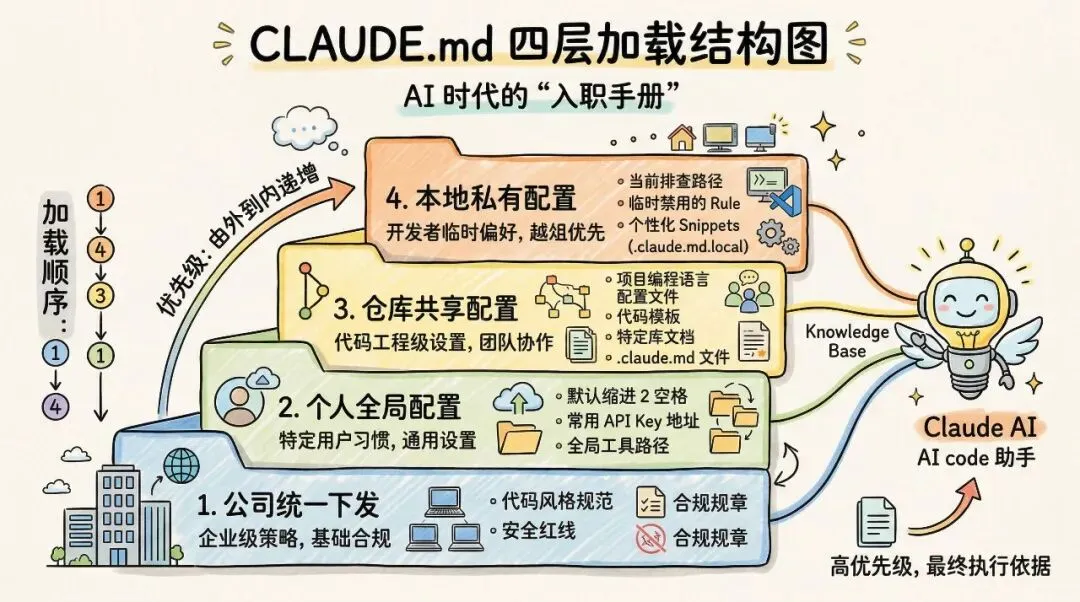
它很重视 CLAUDE.md。
你可以把它理解成:你写给 AI 的入职手册。
里面不是那种很空的说明书,而是很具体的东西:你是谁,这个项目是干嘛的,团队怎么协作,代码习惯是什么,你自己有哪些偏好。
而且它不是只读一份。
它有四层加载:团队级、个人全局级、仓库级、本地私有级。
远一点的,负责统一规范。
近一点的,负责保留你自己的习惯。
这个设计我挺认同。
以前公司给新人做 onboarding,是把人拉进来,再慢慢讲清楚规则。
现在有点反过来了。
AI 时代的 onboarding,是你先把自己写清楚,AI 才能真正进入你的工作流。
很多人说 AI 不够好用,我现在越来越觉得,问题不一定都在模型,也可能在你根本没把自己交代明白。
你没告诉它你是谁,它当然只能泛泛地服务你。
真正厉害的记忆,不只是「记住我骂过它什么」
还有一段我印象特别深。
它在讲反馈记忆的时候,不是只要求记录纠错。
还要求记录:哪些做法被验证过是对的。
这个点太关键了。
我们平时一说“让 AI 记住”,脑子里默认都是负反馈。
我纠正了你一次。
你下次别再犯。
听起来没问题。
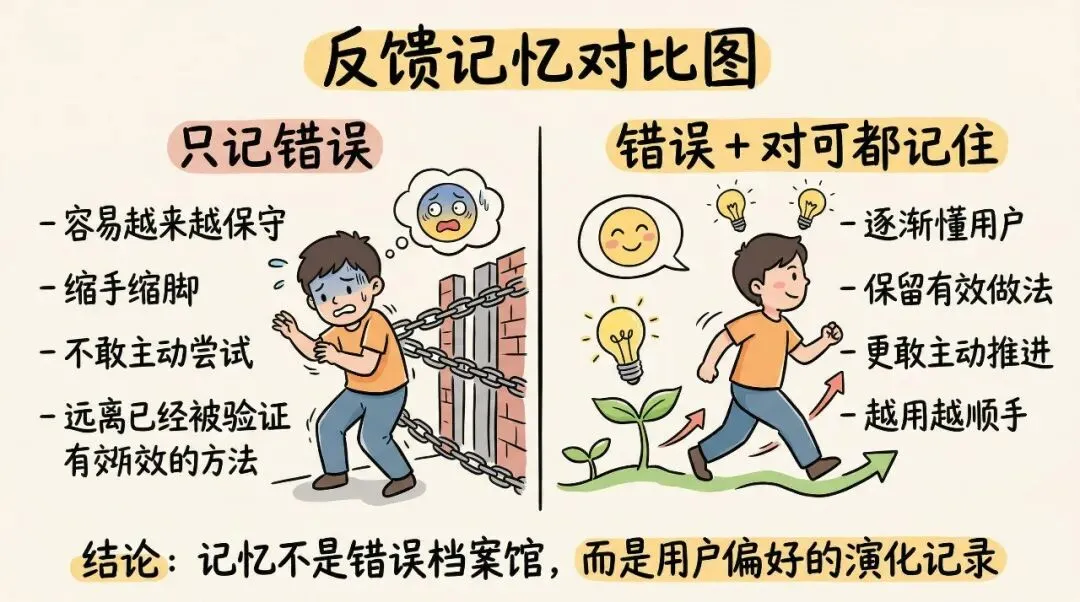
但如果系统只会记错,它最后会变成一个什么东西?
会变得越来越保守。
越来越缩手缩脚。
越来越像一个生怕再被骂、所以什么都不敢主动做的人。
源码里那句话我觉得特别准,大意是:如果你只保存纠正,AI 也许能避免重复犯错,但它会慢慢远离那些已经被用户验证过有效的方法。
这个判断很成熟。
只记错误,不记认可,系统会歪。
你说“这个方向对”,它要记住。
你说“这个处理方式不错”,它要记住。
你没有反对,但默认接受了,它也应该把这当作一种安静的确认。
说白了,记忆不是“错误档案馆”。
记忆应该是“这个人到底喜欢怎样的做事方式”。
这跟带团队很像。
如果一个团队管理者永远只会指出问题,从不留下正向判断,团队最后一定会变形。
大家都会进入自保模式。
AI 也是一样。
为什么它连 Why 都要存下来
Claude Code 还有个地方,我觉得做得很对。
它不只存规则,还要求把 Why 也写下来,再补上 How to apply。
也就是:这条记忆是什么,为什么当时这么定,它该在什么场景下被触发。
这个细节看起来小,实际上是记忆系统能不能长久可用的分水岭。
没有 Why,记忆就只是命令。
有了 Why,记忆才变成判断依据。
一个系统如果只会背规则,不知道这条规则当时是为了解什么问题,它迟早会在边界条件上翻车。
人也是这样。
你带过团队就知道,最怕的不是新人不执行,最怕的是他机械执行。
表面上没错,结果全错。
AI 进入真实工作流之后,这种问题只会更明显。
所以我现在会觉得,好的记忆系统,本质上存的不是结论,而是结论背后的上下文。
上下文满了,不是粗暴截断,而是分层压缩
这一段很工程,但也很值钱。
大模型产品都有一个绕不过去的问题:上下文会满。
一满,很多产品的处理方式其实挺粗暴的。
要么直接截断。
要么让你重开一个新会话。
Claude Code 不是这么干的。
它做了三层压缩:微压缩、自动压缩、完整压缩。
空间还够,就轻一点整理。
空间紧了,就提炼。
真的快爆了,再整体重写骨架。
但更重要的不是“它会压缩”,而是“它知道什么不能丢”。
源码里明确要求保留几类东西:改过哪些文件、踩过哪些错误、用户给过哪些反馈。
还有一个细节特别狠。
如果任务还没结束,它必须保留最近的用户原话,而且最好是一字不差。
这个我一看就知道,写这套系统的人是真做过复杂任务的。
因为很多时候,任务会跑偏,不是模型能力不够,是压缩的时候把用户意图压没了。
“改成异步”跟“优化一下”,看起来只差几个字,方向完全不同。
摘要很容易把这种差别抹平。
原话不会。
还有一处更让我有感。
他们在源码注释里写到,曾经有 session 连续压缩失败几十次,最夸张的一个失败了几千次,白白浪费掉大量 API 调用。
后来修复方案特别朴素:连续失败三次就停。
你看,这就是做产品和做 demo 的区别。
demo 追求“看起来能跑”。
产品要面对的是:每一次失败都在烧钱。
AI 产品做久了,你会越来越明白,token 不是抽象单位,就是成本。
最让我服气的是:它没把记忆藏进黑盒里
很多人会天然觉得,这种记忆系统底层肯定是向量数据库。
结果不是。
它大量用的是文件系统。
每条记忆都是独立的 Markdown 文件。
你能打开看,能手动改,能做版本管理,能 diff,能回滚。
我觉得这个选择特别好。
因为 AI 时代,很多人真正缺的不是功能,是控制感。
你最怕的不是 AI 记不住。
你最怕的是,它记住了什么你根本不知道。
那种感觉很糟。
像屋里多了一个一直在长大的东西,但你看不见它脑子里都装了什么。
文件系统这套方式的好处就在这儿。
它不是最性感的技术选型。
但它给了人审查权。
你知道它记了什么。
你也能改它记了什么。
这件事在长期协作里,比“是不是更智能一点”重要得多。
最有意思的一段,是它真的在让 AI 「做梦」
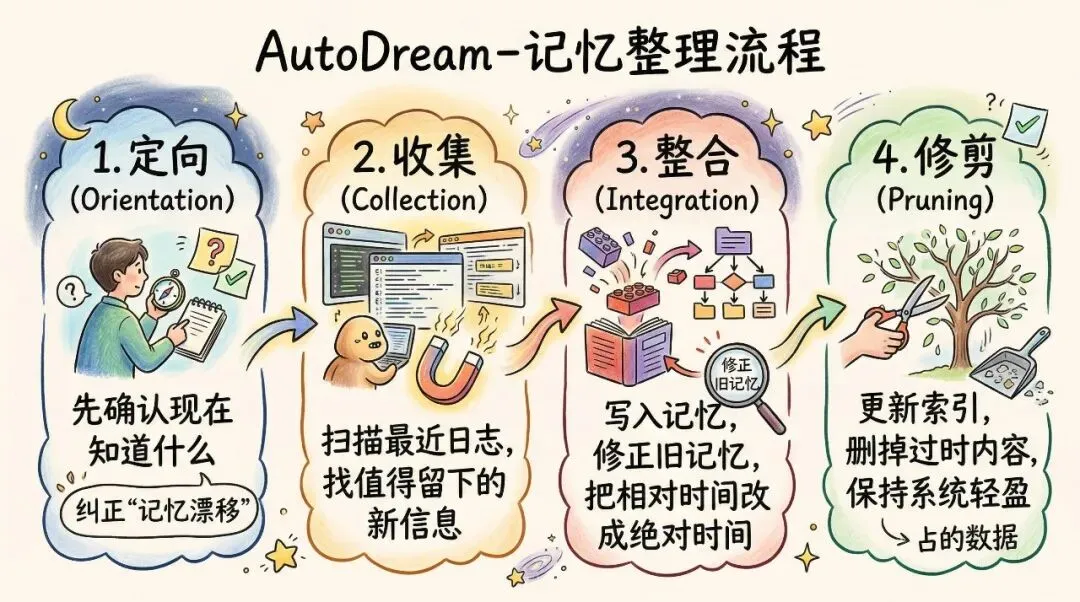
源码里有个模块叫 AutoDream。
这个名字我一开始还以为是玩梗,结果不是。
它真的是把“睡一觉,整理记忆”这件事做成了机制。
隔一段时间,它会回看最近的日志,把新的信息整合进去,把相对时间改成绝对时间,把已经漂移的旧记忆修正掉,再顺手修剪索引,防止整个系统越来越臃肿。
这里面我特别喜欢一个词:记忆漂移。
就是有些记忆在当时是对的,但时间一过,情况变了,它就不准了。
这时候不是简单再加一条新记录,而是要回头修正旧理解。
这就不是存档逻辑了。
这已经很像认知维护。
人脑为什么要睡觉,某种程度上也是在做这件事。
把白天进来的信息重新整理,旧的清掉,新的归位,矛盾的修掉。
Claude Code 这套设计让我最受触动的,就是它不只是想让 AI “会回答”,它开始认真思考:一个长期协作的智能体,怎么才能慢慢长出连续的自我。
我现在越来越确定一件事
我自己早期也有过一个误区。
总觉得模型足够强,很多问题自然会被抹平。
后来越做越发现,不会。
模型决定上限。
记忆决定关系。
一个真正好用的 AI,不是那种每次都给你一个看起来很聪明的回答。
而是你用久了以后,会有一种很明显的感觉:它开始懂你了。
它知道你在意什么,知道你之前试过什么,知道什么方式你会接受,什么方式你会嫌烦。
这种东西,靠单次推理堆不出来。
只能靠时间,靠记忆,靠一整套持续修正自己的机制。
所以如果你现在也在做 AI 产品,或者在判断一个 AI 产品到底有没有长期价值,我会很建议你别只盯着模型参数和 demo 效果。
去看它的记忆系统。
去看它有没有连续性。
去看它记住你的方式,是不是可控、可修正、可积累。
因为说到底,模型决定它聪不聪明。
记忆决定它会不会越来越像一个真正的伙伴。
你现在用 AI 的时候,会明显感觉到“它越来越懂你”吗?我还挺想知道,你在哪个瞬间第一次有这种感觉。