 夜雨聆风
夜雨聆风





大家追的是 Claude Code 源码,我看到的却是 Agent 的第一课
很多人以为,最近这类仓库会火,是因为里面藏着 Claude Code 的秘密。
我看完 tvytlx/ai-agent-deep-dive 之后,判断刚好相反。
它会火,不是因为神秘,而是因为它第一次把 Agent 讲到了普通工程师终于能学。
这两天我在 X 上看到 Xiao Tan 的一条帖子,印象很深。
他在 2026 年 4 月 1 日说,自己那份《Claude Code 源码架构深度解析》第一版一天就超过了 2K star,随后又发布了第二版。很多人看到这种帖子,第一反应是去追热点,去猜大厂产品到底藏了什么秘密。
但我看完这个仓库之后,真正更在意的不是“又一个爆款分析贴”,而是另一件事:
为什么这样一份材料,会让这么多工程师愿意转发、收藏,甚至拿去给团队看?
我的判断是,因为大家并不真的缺“神秘源码”。
大家缺的是一条可以把 Agent 学明白的路径。
真正让人上头的,不是八卦,是降维
很多人一聊 Agent,就会直接跳到最容易把人劝退的那一层:
这些问题当然重要。
但问题是,如果你一上来就把自己丢进一个成熟产品的全量工程实现里,绝大多数人学到的不是结构,而是挫败。
这也是我觉得 tvytlx/ai-agent-deep-dive 值得写的原因。
它在 README 里讲得很清楚,这个仓库保留的是面向学习与评论的分析材料,不是直接扔给你一份完整源码目录。同时,它还放了一个教学用的最小 Python Agent 项目,专门用来演示一个 Agent 的核心结构应该怎么组织。
这就很聪明。
它没有继续制造“神秘感”,而是主动把复杂系统拆回普通工程师能消化的颗粒度。
说白了,这不是在卖“我知道得比你多”。
这是在做一件更有价值的事:
把原本只有少数人能看懂的东西,变成大多数工程师也能跟上的学习材料。
先别神化 Claude Code,先看一个 Agent 最小骨架长什么样
这个仓库最值得看的地方,不是热闹,而是三个层次。
第一层是 src/agt/agent.py。
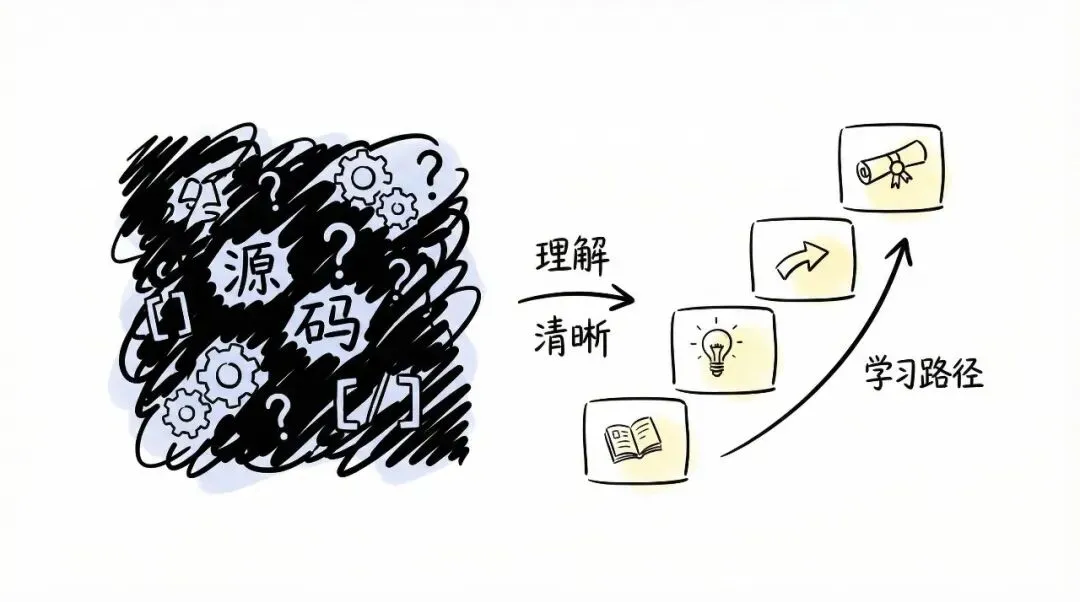
这份文件几乎就是在告诉你,Agent 先不要想得太玄。它最底层其实就是几块东西拼起来:
你会看到它先定义 Message、ToolResult、Tool,再用 LLMClient 把模型层抽象出来。后面给了一个 FakeLLMClient,最后再放进 Agent.run() 这个最小主循环里。
这件事的重要性在于,它把“Agent 是什么”从概念拉回了结构。
不是先讨论魔法,而是先讨论骨架。
而且这背后还有一个更值得钉住的判断:
现代 Agent 产品真正难的,很多时候不是模型本身,而是运行时组织。
消息怎么流动,工具怎么挂载,权限怎么收口,验证怎么补上,记忆怎么存取,失败怎么收场。
这些东西单独看都不神秘,但一旦没有结构,它们就会把普通学习者直接压垮。
你把这层看懂了,再去看更复杂的编排、权限、上下文裁剪、子代理协作,心里就不会虚。
我一直觉得,技术学习里最容易浪费时间的一步,就是过早迷信成品。
你以为自己在研究高级系统,实际上只是在被复杂度镇住。
这里最聪明的一笔,是 Fake LLM
如果你自己做过一点 AI 开发,就会知道一个很现实的问题:
很多时候,最难排查的不是代码会不会写,而是你根本分不清问题到底出在流程、工具,还是模型本身。
模型不稳定,工具返回不稳定,提示词也不稳定。
最后你写了半天,整个人只剩下一种感觉:
到底是谁错了?
这也是为什么我很喜欢这个仓库里的 FakeLLMClient。
它不是为了装可爱,也不是因为作者接不上真模型。
恰恰相反,它体现的是一种很成熟的工程思路:
在学习和验证阶段,先把最不稳定的那层替换掉,让你专心看清主循环、消息流和工具边界到底有没有跑通。
这一步特别像我们平时做系统设计时的“先切掉噪音,再验证主链路”。
很多人学 Agent 学不下去,不是因为能力不够,而是因为第一步就同时背了太多不确定性。
这个最小实现做的,其实就是帮你卸重。
第三个价值,不在代码,在文档组织
仓库里还有一个特别值得讲的点,是 docs/README.md。
这部分不是带你逐行看代码,而是反过来问:
如果你要做一款现代 Agent 产品,你到底要把哪些问题想清楚?
它把文档拆成了这些模块:
这其实已经不是“写一个 demo”了。
它在做的是另一件更成熟的事:
给团队建立一套共享语言。
为什么很多工程团队明明都在做 Agent,彼此讨论却很容易对不上?
因为一个人脑子里想的是 prompt,另一个人想的是工具调用,第三个人在担心权限和隔离,第四个人在做验证和回滚。
每个人都在说 Agent,但说的根本不是同一层。
而这种仓库最值钱的地方,就是它帮你把这些层次摆平了。
先命名,再组织,再实现。
这也是为什么它会火。
不是因为它神秘,而是因为它终于把“怎么学”和“怎么对齐”讲清楚了。
普通开发者真正该学什么
如果你看这种仓库,只停在“哇,Claude Code 原来这么设计”,那其实还是围观视角。
真正有用的看法应该是:
我能从这里拿走什么,放进自己的学习路径里?
我会建议按这个顺序来。
第一步,先把 agent.py 看懂。
不要一开始就盯着复杂框架。先看消息、工具、模型接口、主循环这四块是怎么接起来的。
第二步,接受“Fake LLM 是必要的训练轮”。
先别急着接最强模型。你要先确认自己的主链路是清楚的,不然你永远会把模型的随机性误以为是系统能力。
第三步,再去理解 cli.py 和 skill 发现机制。
这一步会让你明白,Agent 不是只有一个会说话的大脑,它还是一个运行时入口,一个工具分发器,一个能力装配系统。
第四步,最后再看 docs/README.md 那一套架构拆分。
因为到了这一步,你才真正有能力把“demo 能跑”升级成“产品能长”。
这条路线的好处是,你不会一上来就被大厂工程实现淹没。
你先掌握骨架,再补组织,再谈复杂度。
我为什么觉得这类材料对工程团队特别重要
我越来越强烈地感觉到,Agent 这个领域接下来最稀缺的,不是再多几个概念,不是再多几个截图,也不是再多几个一眼很厉害的 benchmark。
真正稀缺的,是可教学、可复现、可迁移的理解框架。
一个工程师看懂,当然有价值。
但一份材料如果能让整个团队对“主循环、工具、权限、记忆、验证”这些层次同时达成共识,它的价值就完全不一样了。
它会直接影响你们后面怎么分工、怎么讨论、怎么定边界、怎么少走弯路。
这也是我看完这个仓库最大的感受。
别再把 Agent 想成一个天才工程师脑子里的神秘黑盒了。
它首先是一套可以被拆开、被命名、被练习、被重建的系统。
而对普通工程师来说,这恰恰是最好的消息。
因为技术不该先给你压迫感。
技术应该先给你掌控感。