 夜雨聆风
夜雨聆风





Claude Code 不只是写代码:源码级拆解它为什么像一套 AI 应用操作系统
这篇文章不想讨论八卦式“源码泄露”本身,而只关心一个更有价值的问题:为什么 Claude Code 的设计,值得所有做 Agent、AI IDE、AI 工作流平台的人认真研究。
最近关于 Claude Code 的讨论很多,但大多数分析还停留在表层:它会不会写代码、终端体验顺不顺、是不是比某某 Copilot 更强。
这些当然重要,但都不是问题的核心。
真正值得拆的,是它背后那套越来越清晰的系统形态:它不像一个简单的 AI 工具,更像一个有状态、有工具、有权限边界、可跨端运行的 AI Runtime。
很多人第一次接触 Claude Code,会把它理解成“一个能写代码的 CLI”。
这个理解不能说错,但明显太浅。
如果只看表层能力,它确实像一个终端里的 AI 编程助手:能读代码、改文件、跑命令、调 Git、接外部工具。但如果顺着公开文档、官方仓库以及近期社区对其工程结构的拆解往里看,你会发现它真正值得研究的,不是“会不会写代码”,而是它如何把大模型能力封装成一套可持续运行、可扩展、可控、可迁移的 Agent 系统。
这正是 Claude Code 最有启发性的地方:它不是把 LLM 塞进一个 Shell,而是在做一层面向复杂任务执行的 AI Runtime。
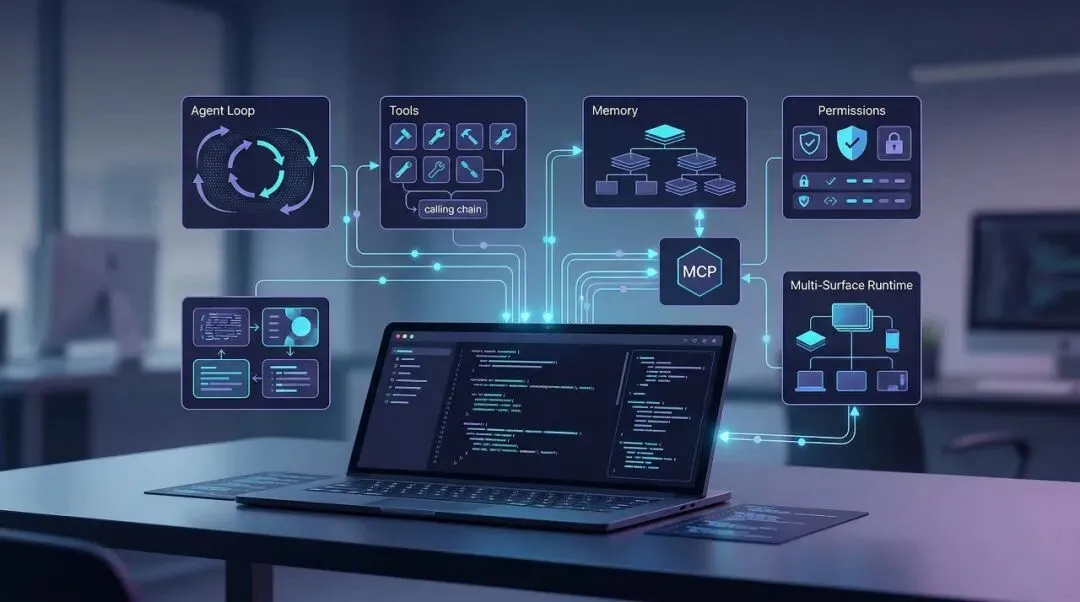
从 Anthropic 官方定位看,Claude Code 是一个 agentic coding tool:它能理解代码库、编辑文件、运行命令、调用开发工具,并在终端、IDE、桌面端、浏览器等多个表面上工作。这个定义其实已经透露出它的核心设计思路:统一内核,多表面分发。
这和很多“AI+编辑器插件”有本质区别。
普通插件思路通常是:
- 1. 在某个具体入口里接住用户请求;
- 2. 调一次模型;
- 3. 返回文本或 patch;
- 4. 由人继续下一轮。
Claude Code 的思路则是:
- 1. 把用户输入变成任务;
- 2. 将任务放入可循环执行的 Agent 回路;
- 3. 在回路中动态决定是否读文件、跑命令、调用外部系统;
- 4. 将工具结果回灌上下文;
- 5. 在权限与策略约束下持续迭代,直到任务完成或人工中止。
也就是说,它不是“一问一答式助手”,而是“模型 + 工具 + 状态 + 权限 + UI”共同组成的任务执行系统。
如果把 AI 应用分成三个阶段:
- • Chat App 阶段:核心是对话;
- • Copilot 阶段:核心是局部建议;
- • Agent Runtime 阶段:核心是任务编排与环境操作;
那么 Claude Code 显然已经站在第三阶段。
二、核心骨架:一个围绕 Agent Loop 构建的执行引擎
从官方文档与社区拆解中,Claude Code 最稳定、最可迁移的架构模式,是它的 Agent Loop。
这个 loop 的本质不复杂,但工程实现非常成熟:
1. 输入标准化
用户不管是在终端里直接输入、在 IDE 内触发、在浏览器或桌面端发起,本质都会被收敛为统一的任务请求结构。
这一步很关键。很多团队做 AI 产品时,一开始就被“入口差异”绑死:IDE 一套逻辑,Web 一套逻辑,Bot 又是一套逻辑。结果能力复用做不起来。
Claude Code 反过来做:入口只是壳,任务语义才是核心对象。
2. 上下文装配
在真正调用模型之前,系统会装配一轮任务所需上下文,包括但不限于:
- • 当前项目/代码库信息
- • 用户指令
- • 会话历史
- • 项目级记忆(如
CLAUDE.md) - • 可用工具清单
- • 权限状态
- • 可能的环境能力(Git、MCP、远程控制等)
这里最值得注意的是,工具清单与权限状态也是 prompt 的一部分语义边界。这意味着模型不是在“空想下一步”,而是在一个可执行、受约束的 action space 中推理。
3. 模型生成 + 工具调用决策
模型输出的不是简单文本,而往往是:
- • 直接回复;
- • 一个或多个工具调用;
- • 对后续步骤的计划与结构化意图。
系统拿到这些意图后,会进入工具执行层。
4. 工具执行与结果回灌
工具层执行后,会把结果重新写回消息历史,再次送入模型。
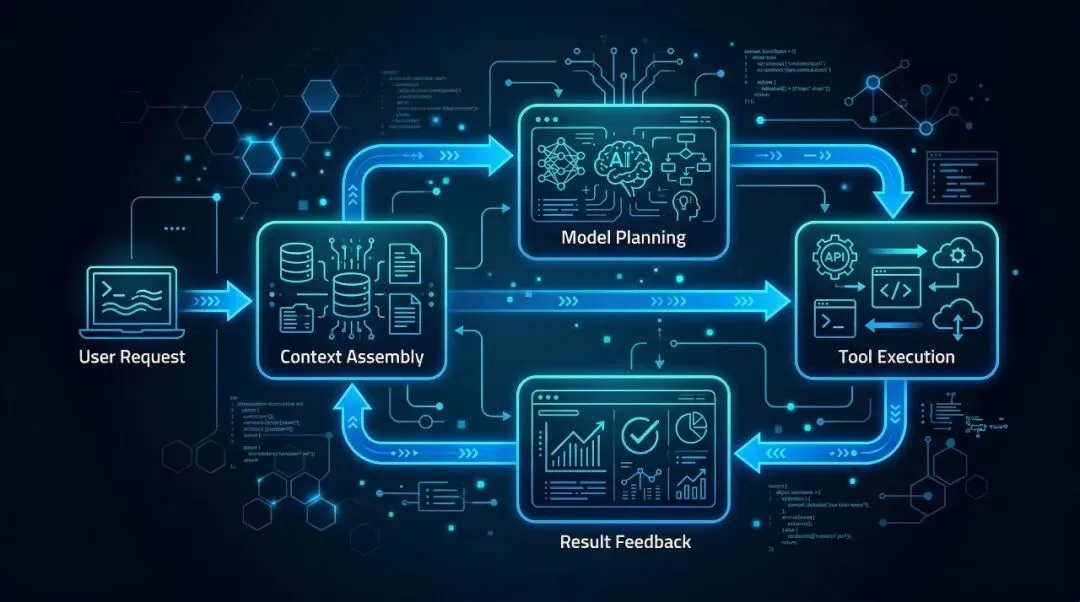
于是形成闭环:
用户目标 → 模型规划 → 工具执行 → 结果反馈 → 再规划
这才是真正的 Agent,而不是“带工具的聊天”。
5. 直到 idle 或结束条件满足
系统会持续循环,直到:
- • 任务完成;
- • 没有新的工具动作;
- • 遇到权限阻断;
- • 用户中断。
这套 loop 有两个非常重要的价值。
第一,它把复杂任务拆成“可持续迭代”的执行过程,而不是幻想模型一次输出最终答案。
第二,它天然兼容多 Agent。因为所谓子 Agent,本质上不过是新的 loop 实例 + 独立上下文。
这正是很多前沿 AI 系统正在采用的模式:不要为“多智能体”写一堆特殊逻辑,而是把它视为同一个运行时递归调用自己。
三、为什么它的工具系统值得学:不是工具多,而是“工具被操作系统化”
很多 Agent 产品都在比谁接的工具更多,但 Claude Code 的启发点不在数量,而在于工具已经被工程化成一个统一治理体系。
从公开信息看,它内置了覆盖文件读写、Shell、Git、搜索、任务管理、MCP 扩展等多类工具,同时支持插件、技能、Hooks 等机制继续扩展能力边界。
这背后不是“工具 marketplace”的问题,而是三个更深的设计亮点。
1. 工具接口统一
当工具被统一抽象后,模型看到的不是一堆零散脚本,而是一组结构稳定、可描述、可授权、可组合的能力单元。
这会直接带来两个收益:
- • 模型更容易学会调用:工具 schema 稳定,参数边界清晰;
- • 系统更容易治理:权限校验、日志、重试、超时、回放都能统一处理。
很多内部 Agent 项目为什么越做越乱?原因就是工具注册像拼乐高,调度像堆 if-else,最后没人知道哪一步能不能安全复用。
Claude Code 显然不是这么干的。它把工具当作运行时的第一等公民,而不是附属插件。
2. MCP 让外部能力接入变成标准协议问题
Anthropic 在官方文档里明确把 MCP 放在核心能力位置上,这说明 Claude Code 的外部连接思路不是“每接一个 SaaS 写一个适配器”,而是用协议做能力抽象。
这个思路很像现代云原生体系里的控制面设计:
- • 上层 Agent 不关心 Jira、Slack、Drive 的底层细节;
- • 运行时只关心这里有一个可调用、可描述、可授权的 capability;
- • 新工具接入尽量遵循标准,而不是侵入核心代码。
这会显著降低系统复杂度,也让 AI 应用从“几个固定集成”升级为“可扩展平台”。
3. 技能、命令、Hook 三层扩展点,覆盖了不同抽象层
Claude Code 不只暴露工具,还提供:
- • Skills:面向任务模式的能力封装;
- • Custom Commands:面向高频工作流的快捷入口;
- • Hooks:面向生命周期事件的自动化控制。
这三类扩展点分别落在“语义层、交互层、系统层”。
这比单纯提供插件机制更成熟。因为真正好用的 AI Runtime,不是只有 API,而是让不同角色都能扩展:
- • 开发者扩展工具;
- • 团队沉淀流程;
- • 平台约束执行时机;
- • 用户复用最佳实践。
这也是它像“应用框架”而不是“单点产品”的原因之一。
四、上下文管理是它真正拉开差距的地方
大多数 AI 应用做到后面都会撞上一个墙:上下文越来越长,质量越来越差,成本越来越高,系统越来越不稳定。
Claude Code 之所以在长任务、多轮执行、跨表面迁移这些场景里体验更稳,一个关键点就在于它不把上下文当作“把历史全塞进去”这么简单。
1. CLAUDE.md 解决的是“显式长期记忆”
官方文档把 CLAUDE.md 定义为每次会话启动都会读取的项目级指令文件。这个设计非常聪明。
因为它把很多本来要反复在 prompt 里重写的信息,转化成了稳定、可维护、版本化的外部记忆层。比如:
- • 代码规范
- • 架构约束
- • 常用命令
- • Review checklist
- • 团队约定
这本质上是在做“静态长期记忆外置”。
2. Auto Memory 解决的是“经验累积”
官方还强调 Claude 会在工作中构建 auto memory,跨会话保存构建命令、调试经验等 learnings。
这说明系统开始从“会话产品”迈向“持续学习型 runtime”。
当然,这里的“学习”不是训练模型,而是将任务执行中的高价值状态结构化保存,供未来检索与调用。
对于企业级 AI Agent 来说,这一点极其关键。因为真正带来复利的,不是每次都从零开始,而是系统是否能在不污染上下文的前提下逐步形成项目记忆。
3. 上下文不只是存储问题,更是压缩与选择问题
近期社区对 Claude Code 源码结构的拆解里,一个反复被提到的方向是:它非常重视上下文压缩、摘要、历史裁剪、缓存复用等机制。
这些细节即使某些具体实现仍待官方确认,但从产品体验上看,这个判断大概率成立。否则它很难在长链任务里维持稳定。
这背后的通用方法论是:
- • 不是把所有历史都送给模型;
- • 而是把“当前任务有用的信息”持续提纯;
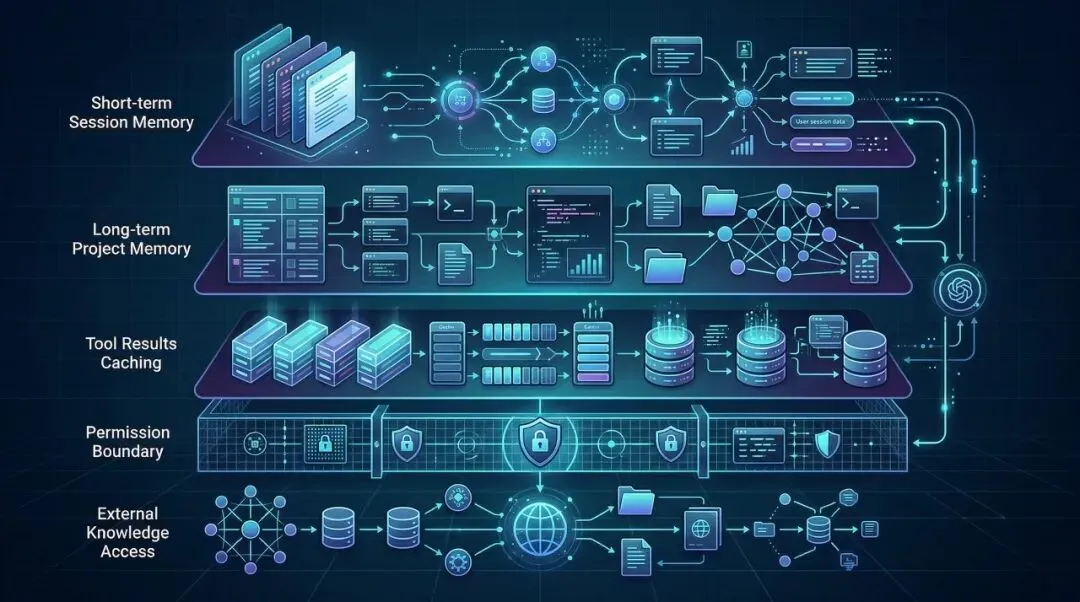
- • 同时把低变化、高复用内容做缓存;
- • 把长期记忆、短期工作记忆、即时工具结果分层管理。
对今天做 Agent 的团队来说,这个思路比“换更长上下文模型”重要得多。
五、安全与权限:它不是把能力放大,而是把风险装进笼子里
很多人谈 Agent 时最容易忽略的一点是:能执行动作,不代表能安全落地。
Claude Code 的另一个工程亮点,是它明显把权限系统、安全策略和用户确认机制放在了主路径里,而不是事后补丁。
这件事为什么重要?
因为一旦一个 AI 系统能:
- • 读文件
- • 改代码
- • 执行 Shell
- • 调 Git
- • 接外部 SaaS
它就已经不是普通聊天机器人,而是“有操作能力的软件主体”。这时候安全问题不再是内容安全,而是运行时安全。
从官方文档与社区拆解能看到几个一致信号:
1. 权限是执行前置条件,不是执行后审计
工具是否可用,不只是看有没有注册,更要看当前策略是否允许。也就是说,权限控制发生在 action selection 和 tool execution 的关键节点上。
这意味着模型虽然能“想到”某个动作,但不一定能“做到”。
这是正确的。因为真正可靠的 Agent 架构,必须把“意图生成”和“动作落地”分层。
2. 多种表面共用同一内核时,更需要统一权限语义
Claude Code 同时覆盖终端、IDE、桌面端、浏览器、远程控制等场景。如果每个表面都各自实现一套权限体系,系统会迅速失控。
它更合理的做法,是让权限成为内核的一部分,由前端表面去呈现不同交互,而不是决定权限逻辑本身。
这也是“统一 runtime”的一个典型特征:安全策略放中间层,而不是散落在 UI 层。
3. 安全与可用性的平衡,决定它能否进入真实开发流程
纯安全导向会让 Agent 什么都做不了;纯效率导向会让系统无法在真实组织里落地。
Claude Code 真正值得学的是,它试图把风险高的动作纳入审批、策略与最小权限语义下运行。对企业内部平台来说,这几乎是前置条件。
换句话说,Claude Code 给出的不是“最强 Agent”,而是“在真实工程环境中可以被接受的 Agent”。
六、从产品形态看,它已经不是 CLI,而是“多表面统一内核”
这是很多人低估 Claude Code 的地方。
官方文档已经明确:同一个引擎工作在 Terminal、VS Code、JetBrains、Desktop、Web、Remote Control 等多个表面上。表面不同,但底层能力、记忆、MCP、设置、工作流可以共享。
这意味着什么?
意味着 Anthropic 不是在做一个 terminal app,而是在做:
- • 一个通用 Agent 内核;
- • 一套统一的状态与配置系统;
- • 多个交互表面作为“视图层”;
- • 必要时支持会话迁移、任务转交、长任务异步执行。
这套思路非常接近现代应用架构里“headless core + multiple clients”的范式。
这也是为什么它对行业的启发,不应该停留在“命令行能不能替代 IDE”,而应该上升到:
AI 应用是否应当先设计统一 runtime,再去做多入口分发。
如果这个问题想明白,很多产品决策会完全不一样:
- • 记忆应该放哪里;
- • 工具该由谁管理;
- • 权限在哪层收敛;
- • 哪些能力属于通用内核,哪些属于表面体验;
- • 多 Agent 到底是功能,还是 runtime 的递归能力。
七、为什么说它可以被视为前沿 AI 应用框架
如果我们把“前沿 AI 应用框架”定义为:
能稳定承载模型推理、工具调用、状态管理、权限控制、扩展协议与多入口交互的一套应用运行时基础设施。
那么 Claude Code 显然已经满足了很多关键条件。
1. 它有清晰的运行时内核
不是简单 SDK 调用,而是完整的 agent loop、上下文装配、工具回灌与状态推进机制。
2. 它有标准化扩展接口
MCP、Skills、Hooks、Commands,使它具备平台级扩展性,而不是功能堆砌。
3. 它有记忆与状态层
CLAUDE.md、auto memory、会话迁移、历史管理,说明它不只是“即时响应”,而是面向持续任务执行。
4. 它有权限与安全抽象
这使它具备走向团队协作、企业场景和高风险操作域的基础。
5. 它是多表面而非单入口产品
一个 AI Runtime 若只能活在某个插件里,生命周期会很短。Claude Code 的路径则明显更像基础设施化。
从这个意义上说,它对行业最大的启发,不是“Claude 会不会写代码更强”,而是:
未来真正有竞争力的 AI 应用,不会只是一个聊天框,也不会只是一个插件,而是一个有执行内核、状态系统和安全边界的运行时平台。
八、对国内做 AI Agent、AI IDE、企业工作流平台的人,有哪些直接借鉴意义?
最后把视角拉回落地。
如果你在做广告算法平台、增长自动化系统、企业内部研发助手,Claude Code 最值得借鉴的不是具体 UI,而是以下五条原则:
原则一:先做任务运行时,再做花哨入口
不要先纠结聊天框长什么样、插件放在哪,而是先回答:
- • 任务如何表示?
- • 状态如何推进?
- • 工具如何注册与授权?
- • 失败如何恢复?
- • 结果如何回灌?
没有 runtime,所有入口都会越做越碎。
原则二:把工具系统平台化
不要让每个 Agent 自己拼工具,更不要把工具调用逻辑散落在业务代码里。工具必须有统一 schema、统一鉴权、统一日志、统一超时与错误模型。
原则三:把记忆分层,不要幻想无限上下文
短期工作记忆、长期项目记忆、用户偏好记忆、工具执行结果,必须分层治理。否则系统会在长链任务中持续退化。
原则四:把权限当成核心产品能力
Agent 一旦能执行动作,就必须在设计之初就有 permission model。审批流、最小权限、风险动作提示,不是企业化阶段才补的东西。
原则五:让“多 Agent”成为运行时能力,而不是单独 feature
多智能体最好的实现方式,往往不是维护一堆异构角色脚本,而是让子任务能以标准 loop 递归运行、彼此隔离上下文、由协调器统一编排。
这也是 Claude Code 给人启发最大的地方:它不像在展示一个 demo,而像在展示一套可以不断长大的架构底座。
结语
Claude Code 的价值,远不止“终端里有个很强的 AI 编程助手”。
更准确地说,它代表了一条越来越清晰的产品路线:把大模型从“回答问题的接口”升级为“可治理的任务执行内核”。
谁能把这件事做成,谁就更有机会从 AI 功能提供者,走到 AI 平台构建者。
从这个角度看,Claude Code 值得研究的,不是它某一个功能有多惊艳,而是它已经把很多 AI 应用下一阶段必须面对的问题——工具、状态、记忆、权限、扩展、多表面——提前做成了一套相对完整的工程答案。
这也是为什么,它可以被看作一个前沿 AI 应用框架样本。
不是因为它名字里有 Code。
而是因为它背后,已经隐约长出了“AI Runtime”的形状。
参考来源:
- 1. Anthropic 官方仓库:anthropics/claude-code[1]
- 2. Anthropic 官方文档:Claude Code overview[2]
- 3. Anthropic 官方仓库:anthropics/skills[3]
- 4. 社区技术拆解:Chapter 1: The Architecture of an AI Agent – Claude Code from Source[4]
- 5. 社区技术拆解:Inside Claude Code — Source Maps, Architecture & What It Means[5]
引用链接
[1] Anthropic 官方仓库:anthropics/claude-code: https://github.com/anthropics/claude-code
[2] Anthropic 官方文档:Claude Code overview: https://code.claude.com/docs
[3] Anthropic 官方仓库:anthropics/skills: https://github.com/anthropics/skills
[4] 社区技术拆解:Chapter 1: The Architecture of an AI Agent – Claude Code from Source: https://claude-code-from-source.com/ch01-architecture/
[5] 社区技术拆解:Inside Claude Code — Source Maps, Architecture & What It Means: https://teamjaaf.com/claude-code-architecture.html