 夜雨聆风
夜雨聆风





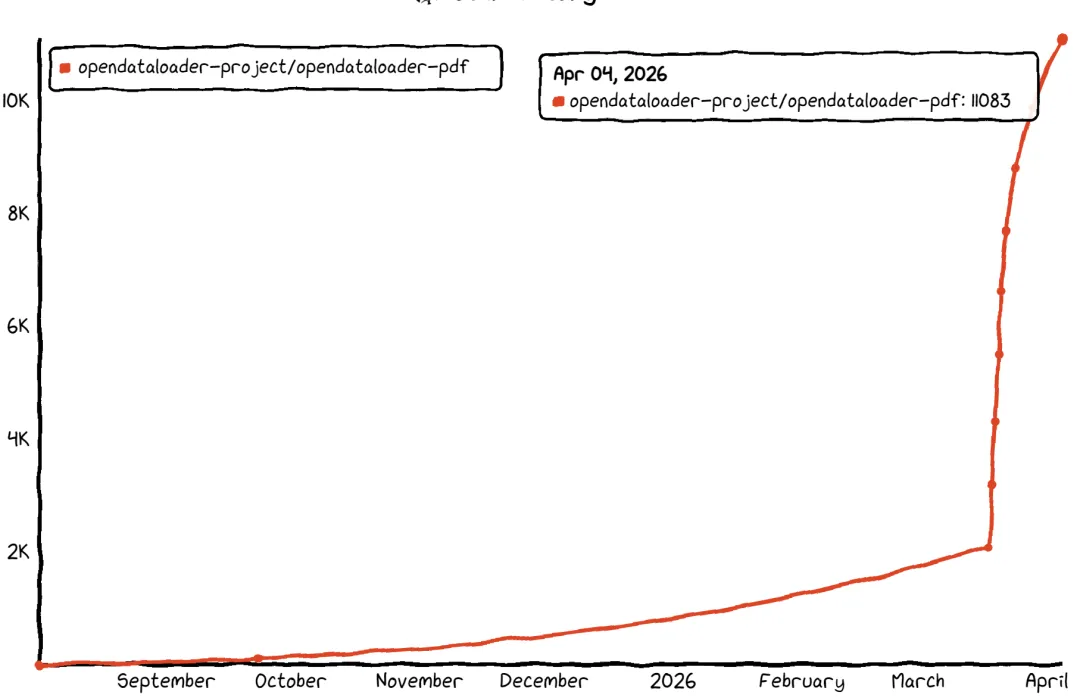
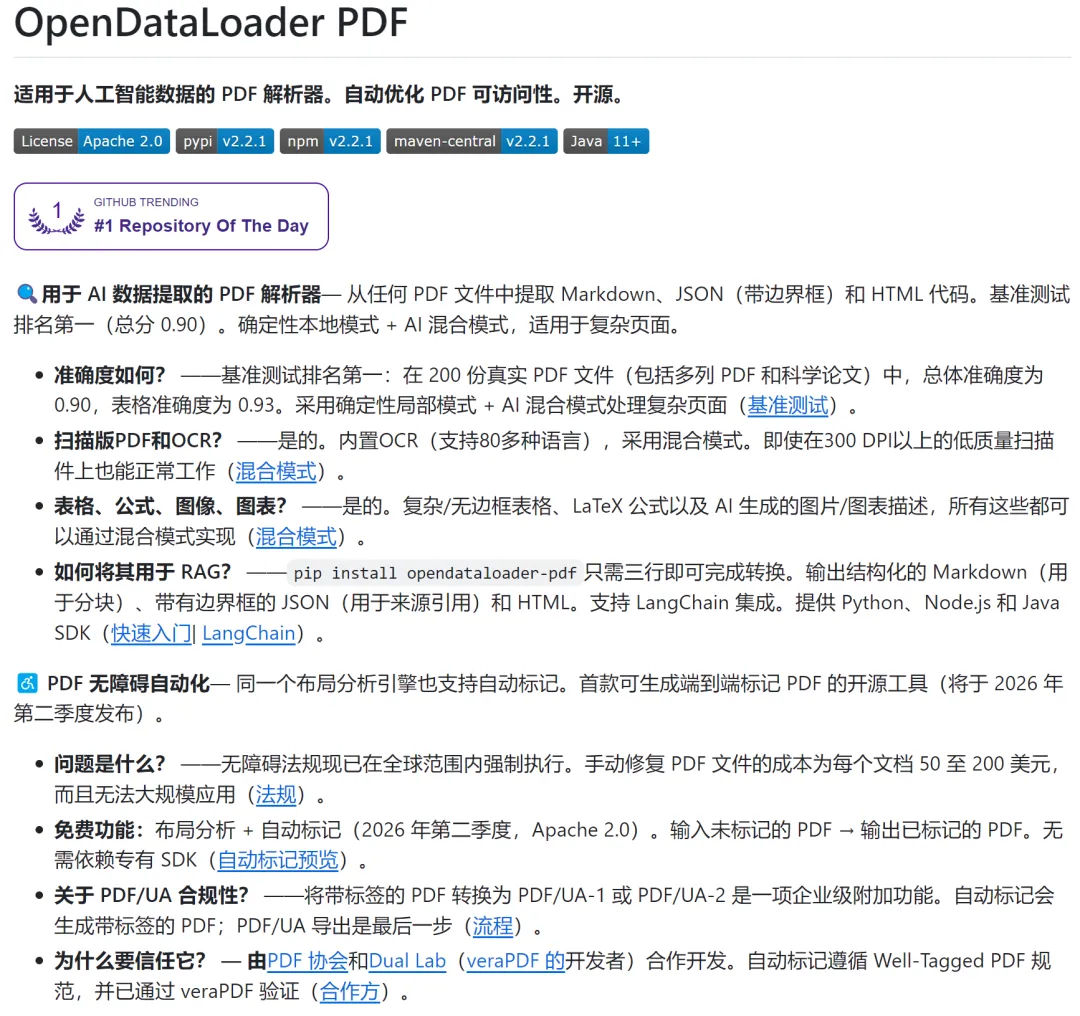
11K + Star!PDF解析痛点破解!这款开源神器,全球第一且免费可用
-
提取表格错乱,复杂/无边框表格直接识别失败,手动整理耗时费力; -
多栏PDF提取文本顺序混乱,上下文衔接断层,需逐段调整; -
扫描版PDF无法复制,OCR识别准确率低,多语言支持不足; -
提取内容藏有隐藏文本,易遭遇提示词注入攻击,存在安全隐患; -
工具要么准确率高但速度慢,要么速度快但识别差,难以兼顾。
-
文本提取:自动识别多栏排版,保持正确阅读顺序,不打乱上下文;
-
元素定位:每个提取元素自带边界框坐标,方便实现“点击来源”功能;
-
表格提取:简单边框表格免费提取,复杂/无边框表格可通过混合模式精准识别;
-
其他提取:支持图片、LaTeX格式数学公式提取,适配学术论文场景;
-
OCR识别:支持80+语言(中英日韩、德法阿拉伯等),轻松处理扫描版PDF;
-
AI辅助:自带AI图表描述、AI安全过滤,自动屏蔽隐藏文本、页外内容,防御提示词注入攻击。
-
JSON(推荐):带边界框和语义类型的结构化数据,适配RAG流水线;
-
Markdown:纯净文本,可直接喂给大模型,无需二次整理;
-
HTML:带样式的网页展示,方便在线预览;
-
注释PDF:可视化调试专用,可直观查看每个元素的识别类型。
opendataloader_pdf.convert( input_path=["file1.pdf", "file2.pdf"], output_dir="output/", format="markdown,json" # 多格式组合输出)
-
本地模式(默认):纯本地Java处理,无需AI后端,0.05秒/页,适合干净的数字PDF;
-
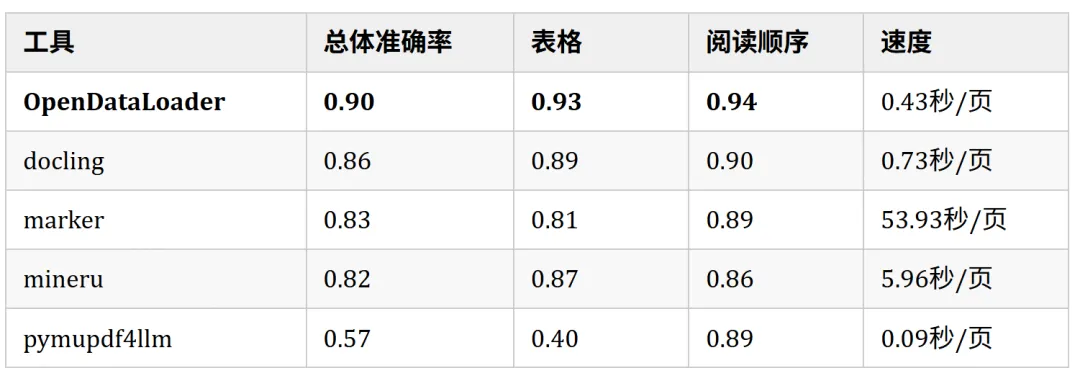
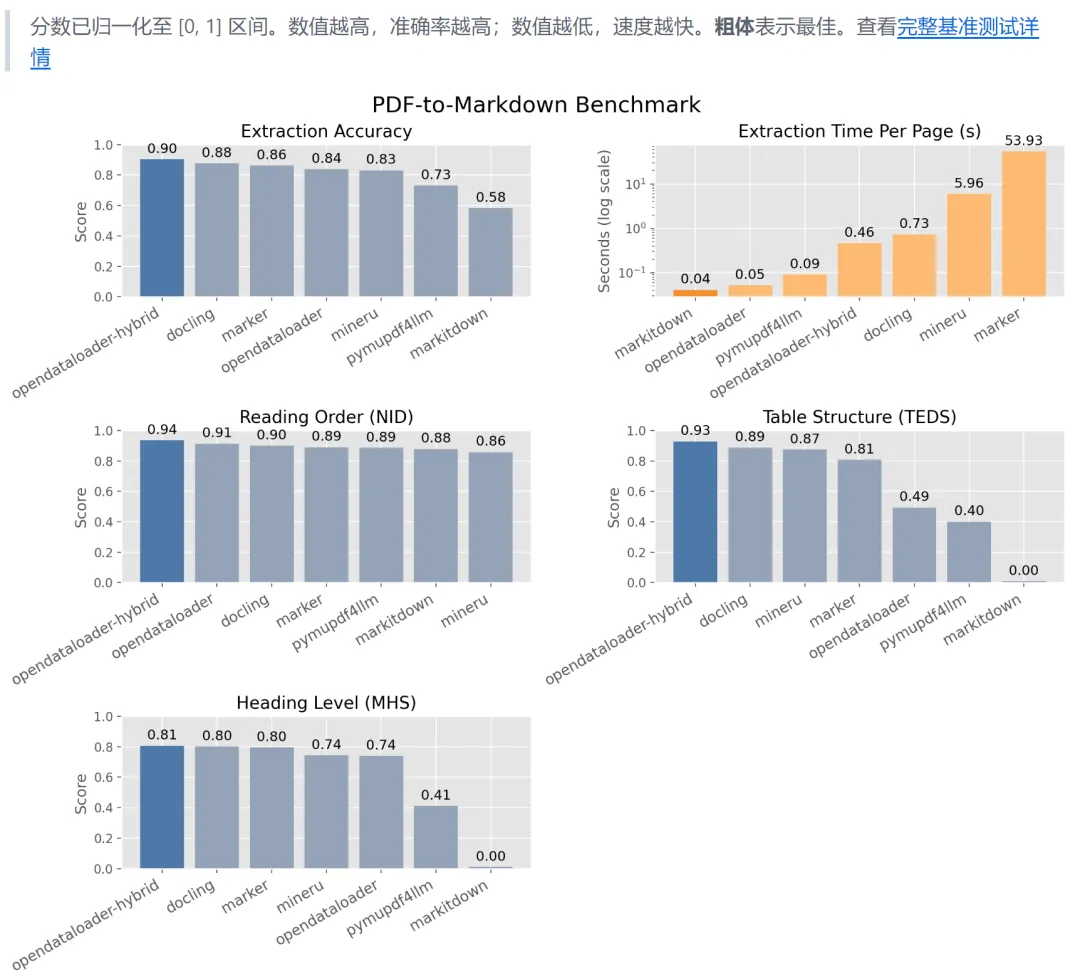
混合模式:本地处理+AI后端,表格准确率从0.49提升至0.93,适合扫描件、复杂表格、学术论文。
-
Java 11+(本地模式核心依赖);
-
Python 3.10+(Python调用依赖);
-
无需GPU,CPU即可运行,支持Python、Node.js、Java三种语言。
# 基础版安装(本地模式)pip install -U opendataloader-pdf# 混合模式安装(需AI增强时)pip install "opendataloader-pdf[hybrid]"
import opendataloader_pdfopendataloader_pdf.convert( input_path=["file1.pdf", "folder/"], # 单个文件或文件夹批量处理 output_dir="output/", # 输出目录 format="markdown,json" # 输出格式,可组合)
# 终端1:启动AI后端opendataloader-pdf-hybrid --port 5002# 终端2:执行PDF解析opendataloader-pdf --hybrid docling-fast file.pdf
# 强制OCR识别,指定中英双语(可替换为其他语言)opendataloader-pdf-hybrid --force-ocr --ocr-lang "ch_sim,en"
-
日常办公(干净数字PDF):优先用本地模式,速度最快,满足基础文本、简单表格提取需求; -
学术研究(含公式、复杂表格):用混合模式,搭配公式增强功能,精准提取LaTeX公式和嵌套表格; -
扫描件处理(图片型PDF):混合模式+强制OCR,根据文档语言指定OCR语言(如非英语需补充对应语言参数); -
RAG流水线集成:用LangChain官方集成包,直接调用,无需额外开发(安装命令:pip install langchain-opendataloader-pdf); -
批量处理:将需要解析的PDF放入同一文件夹,input_path指定文件夹路径,实现批量高效解析; -
未来适配:2026年Q2将推出免费的PDF自动无障碍标记功能,可提前关注项目更新,适配欧洲EAA无障碍法规。
https://github.com/opendataloader-project/opendataloader-pdf
-
Claude Code 团队落地指南:一套可复制的 配置方案 -
史上最快突破 100K+ 星标!Claw Code 开源解析! -
12K+ Star!AI Agent操控全网的万能CLI枢纽! -
20K+ Star!Claude Code 多智能体编排神器! -
16.8K+ Star!会自我成长的开源AI智能体 -
Claude Code 专属仪表盘!3 条命令安装
终身学习,深耕AI领域
持续分享,优质AI开源