 夜雨聆风
夜雨聆风





华中科技大学新作:首个多语言文档解析基准MDPBench,开源模型拍照场景性能暴跌17.8%
一句话讲清楚👉🏻 华中科技大学联合金山办公发布首个多语言文档解析基准 MDPBench,覆盖 17 种语言、3400 张文档图像,实测发现开源模型在拍照文档场景下性能平均暴跌 17.8%,非拉丁语系平均下降 14.0%,Gemini-3-Pro 以 86.4% 的综合准确率领先所有模型。
为什么需要多语言文档解析基准?
文档解析把文档图像转成结构化的序列化文本。大语言模型的预训练语料质量好不好,很大程度上取决于文档解析的效果。
从传统的 pipeline 方法到端到端 VLM,再到多阶段专用模型,各种方案在 OmniDocBench、olmOCR-Bench 等基准上不断刷新 SOTA。但这些基准有两个明显的盲区:
语言覆盖极窄:现有基准几乎只关注中英文等少数主流语言,忽略了全球数十亿使用非拉丁语系、斯拉夫语系、阿拉伯语系的人群。
场景过于理想化:现有基准主要使用干净的数字化文档和扫描文档。现实世界中大量文档只有拍照形式——历史档案、纸质收据、书籍、手写笔记,没有对应的数字版本。
华中科技大学和金山办公团队推出了 MDPBench(Multilingual Document Parsing Benchmark),第一个专门针对多语言数字化和拍照文档解析的基准。

MDPBench 数据集构建
17 种语言,3400 张文档图像
MDPBench 涵盖 17 种代表性语言,包括:
-
拉丁语系:德语(DE)、英语(EN)、西班牙语(ES)、法语(FR)、印尼语(ID)、意大利语(IT)、荷兰语(NL)、葡萄牙语(PT)、越南语(VI) -
非拉丁语系:阿拉伯语(AR)、印地语(HI)、日语(JP)、韩语(KO)、俄语(RU)、泰语(TH)、简体中文(ZH)、繁体中文(ZH-T)
文档类型覆盖学术论文、商业报告、手写笔记、报纸、教科书、漫画等多种类型,确保评估的全面性。
真实拍照场景模拟
这是 MDPBench 最核心的创新点。团队将 850 张数字化文档通过打印或屏幕显示的方式进行拍照采集,模拟真实世界的复杂条件:
物理变形:向内弯曲、向外弯曲、不规则褶皱
拍摄角度:左侧、右侧、倒置、倾斜
室内环境:桌面纹理、地面纹理、背景文字干扰、复杂光照、摩尔纹(屏幕拍摄)、反射、眩光、轻微模糊
室外环境:低光照条件、周围物体阴影、不均匀照明、复杂自然背景
每份文档采集 3 张照片(室内 2 张 + 室外 1 张),最终形成 3400 张文档图像的数据集。

三阶段高质量标注流程
团队设计了三阶段标注流程:
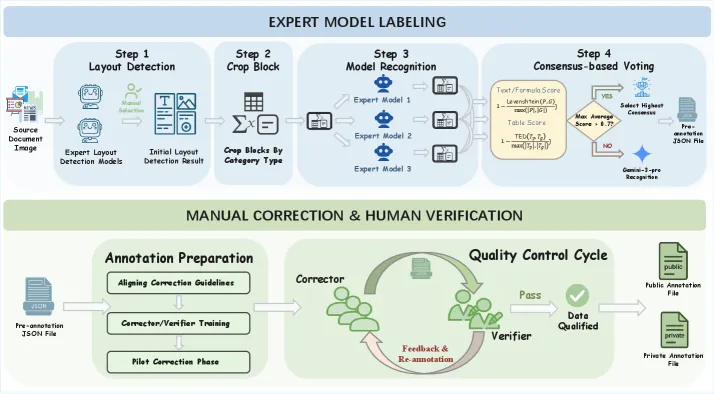
第一阶段:专家模型标注
先用 dots.ocr 和 PaddleOCR-VL 对所有数字化文档做布局检测,人工比较两个模型的检测结果,选漏检和误检更少的作为初始布局标注。然后根据布局信息裁剪文本块、表格块和公式块,用 PaddleOCR-VL、dots.ocr 和 Qwen3VL 三个模型分别识别。
这里用了一个共识投票策略:正确的识别结果通常唯一且稳定,错误结果往往多样且随机。所以与其他模型输出最相似的预测更可能正确。团队计算三个模型两两之间的相似度,选平均相似度最高的作为最终初始标注。
文本和公式用归一化编辑距离(NED)衡量相似度,表格用基于树编辑距离的相似度(TEDS)。如果最高平均相似度低于 0.7,说明三个模型的预测都不可靠,改用 Gemini-3-Pro 识别。
第二阶段:人工校正
标注员先培训统一标准,然后在小部分样本上试点标注。校正分步进行:先检查布局坐标和元素类型,再验证阅读顺序是否符合人类自然阅读逻辑,最后逐一检查和细化每个元素。
第三阶段:人工验证
一份文档校正完成后,交给独立审核员验证。符合质量标准就标记”通过”,有问题就标记”失败”并附详细反馈,退回原标注员修改。迭代进行直到文档完全满足验收标准。
公私分离的评估策略
为防止数据泄露和针对性优化,MDPBench 将数据集分为两个部分:
-
公开评估集:2720 张样本,图像和标注免费开放下载 -
私有评估集:680 张样本,仅通过官方评估网站提交模型进行评估
现有基准对比
MDPBench 与现有文档解析基准的对比:
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| MDPBench | 17 | 数字化/拍照 | 3400 | 全面 |
MDPBench 是唯一同时覆盖多语言和全面拍照条件的基准。
评测结果
团队在 MDPBench 上评估了通用 VLM、专用 VLM 和 pipeline 工具三类模型。
闭源模型领先
Gemini-3-Pro 以 86.4% 的综合准确率排第一,在 17 种语言中的 14 种达到 SOTA。最强的开源模型 dots.mocr 综合准确率 80.5%,差距 5.9 个百分点。
在拍照场景下,差距更加明显:Gemini-3-Pro 达到 85.1%,而 dots.mocr 仅为 77.2%,差距扩大到 7.9%。
其他表现不错的闭源模型包括 kimi-K2.5(77.5%)、Doubao-2.0-pro(74.2%)、Claude-Sonnet-4.6(73.1%)和 ChatGPT-5.2(68.6%)。
开源模型方面,PaddleOCR-VL-1.5 以 78.3% 紧随 dots.mocr 之后,dots.ocr(76.5%)、olmOCR2(70.4%)分列其后。而 InternVL-3.5-8B 仅取得 42.7% 的综合准确率,MinerU-2.5-VLM 更是低至 46.3%。
五大发现
1. 拍照文档解析挑战更大
所有模型在拍照文档上的性能平均下降 17.8%。Gemini-3-Pro 在拍照文档上比数字化文档下降约 5.3%,会出现内容缺失、阅读顺序错误和幻觉输出。

2. 非拉丁语系性能显著更差
模型在非拉丁语系语言上的性能平均比拉丁语系低 14.0%。以 MinerU2.5 和 MonkeyOCR 为例,虽然它们主要在英文和中文数据上训练,但对德语等拉丁语系语言仍有较好的泛化能力,但在阿拉伯语和印地语等非拉丁语系上的准确率却降至 10% 以下。
3. 各语言特有的典型错误
不同语言有特定的错误模式:
-
印地语:依赖元音变音符号,模型往往只保留基本字符而忽略修饰符,如将 “अरविंद”(Arvind)误识别为 “अरविद”(Aravid) -
俄语:西里尔字母与拉丁字母视觉上相同的字符容易混淆,如将 “м”、”е”、”о” 误分类为对应的拉丁字母 -
泰语:作为无空格语言(空格仅表示语义边界),模型经常在连续文本中幻觉出空格,如将 “ที่ใหญ่ที่สุด”(最大的)错误分割为 “ที่ ใหญ่ ที่ สุด”

4. 重复输出和语言漂移
-
PaddleOCR-VL-1.5 处理阿拉伯语文档时出现内容缺失和重复输出 -
dots.mocr 处理越南语文档时出现语言漂移,错误地识别为中文

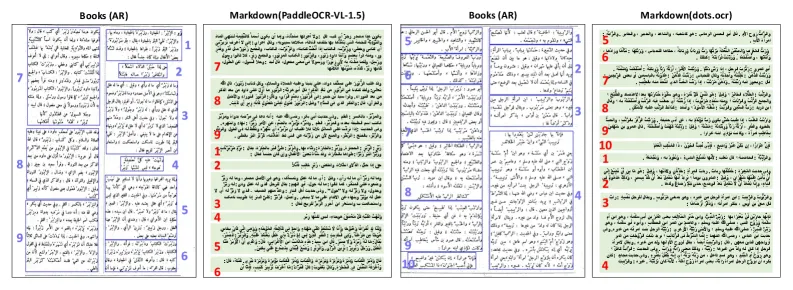
5. 从右到左阅读顺序处理困难
阿拉伯语从右到左阅读。对于双栏阿拉伯语文档图像,PaddleOCR-VL-1.5 和 dots.ocr 等模型经常错误地按照从左到右的顺序处理文本。
单任务评测结果
文本识别
在文本识别任务中,PaddleOCR-VL-1.5 在 17 种语言中的 10 种取得最佳表现,dots.mocr 和 Gemini-3-Pro 各在 4 种语言上达到 SOTA。
这个现象反映了训练数据和训练范式的偏差:dots.mocr 和 Gemini-3-Pro 主要在全页图像上以端到端方式训练,处理裁剪的局部文本块时表现相对较弱。而 PaddleOCR-VL-1.5 使用了大量文本块级别的数据进行训练,更适合这种评估设置。
值得注意的是,PaddleOCR-VL-1.5 在阿拉伯语、印地语和泰语上的表现明显更差,说明其训练数据存在语言分布偏差。
公式和表格识别
Gemini-3-Pro 在公式和表格识别上均取得最佳表现。所有模型在拍照场景下都出现性能下降,这可能是由于复杂背景、光照变化、图像退化和几何畸变等因素。
表格识别仍然是一个挑战:Gemini-3-Pro 在数字化表格上达到 75.9% 的准确率,但在拍照表格上降至 69.2%,说明表格识别在真实成像条件下仍缺乏鲁棒性。
布局检测
dots.mocr 在 17 种语言中的 13 种达到 SOTA,展现了多语言场景下的强泛化能力。值得注意的是,虽然 MinerU-2.5-VLM 在阿拉伯语、印地语和俄语上的整体结果低于 10%,但在这三种语言上的 PageIoU 分数均超过 85%,说明布局检测性能对语言差异相对不敏感。
评估指标设计
MDPBench 采用页面级别的聚合评估策略,而非 OmniDocBench 的元素级别平均。这是因为在多语言场景下,不同语言的文档结构差异很大——英文学术论文通常包含大量公式,而某些语言的文档可能公式很少。如果使用元素级别的评估策略,某些语言的整体分数会被少数公式或表格的解析结果过度影响。
具体评估方法:
文本和阅读顺序:使用归一化编辑距离(NED)
其中 是预测文本, 是真实文本,Levenshtein 是莱文斯坦距离。
公式识别:使用 CDM(Content-based Document Matching)评估,防止因表达形式差异导致的误判。
表格识别:使用广泛采用的 TEDS(Tree-Edit-Distance-based Similarity)
其中 和 分别是预测和真实表格的树结构。
总结
MDPBench 填补了多语言文档解析基准的空白。3400 张高质量人工标注图像覆盖 17 种语言,纳入了广泛的真实世界拍摄条件。
实验结果显示了现有文档解析模型的局限性,特别是在非拉丁语系和拍照文档场景下的性能退化。MDPBench 不仅可以评估专用文档解析系统,还能作为评估通用大语言模型多语言文本理解和 OCR 能力的基准。
改进方向很明确:加强非拉丁语系的训练数据、提升拍照文档的鲁棒性、改进从右到左语言的阅读顺序处理、减少多语言场景下的幻觉和语言漂移。
资源链接
📄 论文链接https://arxiv.org/abs/2603.28130
💻 代码仓库https://github.com/Yuliang-Liu/MultimodalOCR