
































































































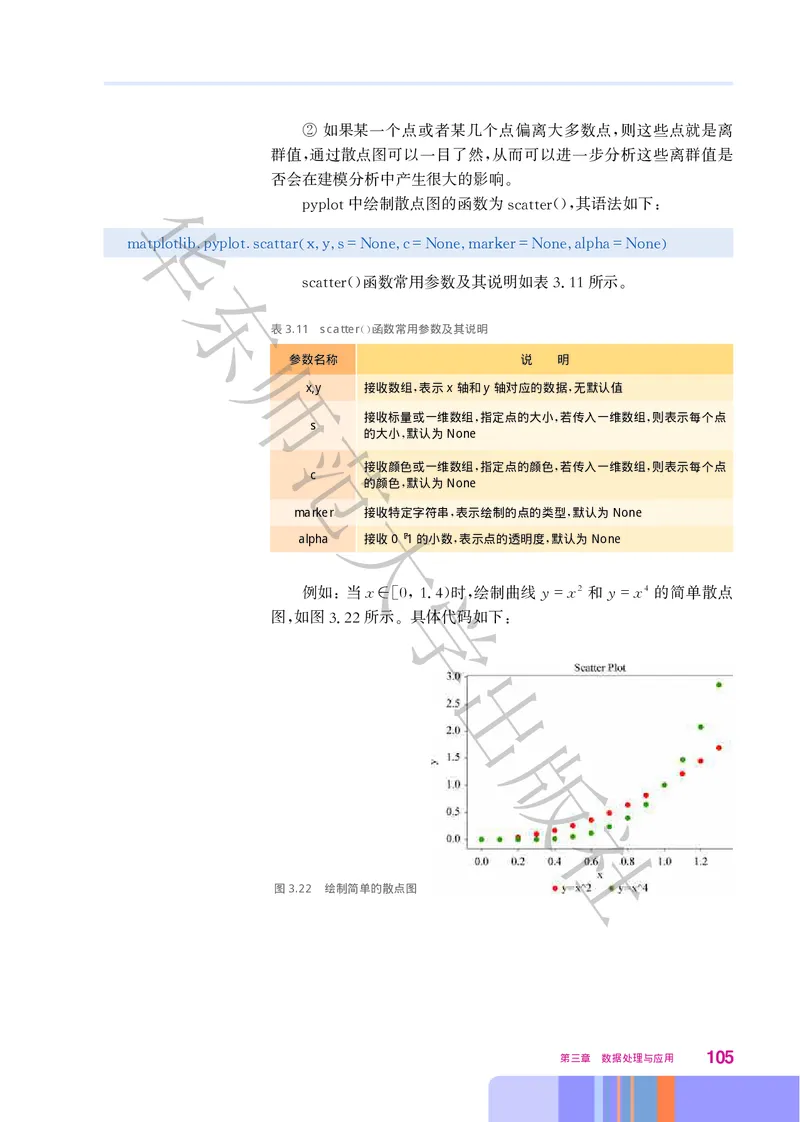

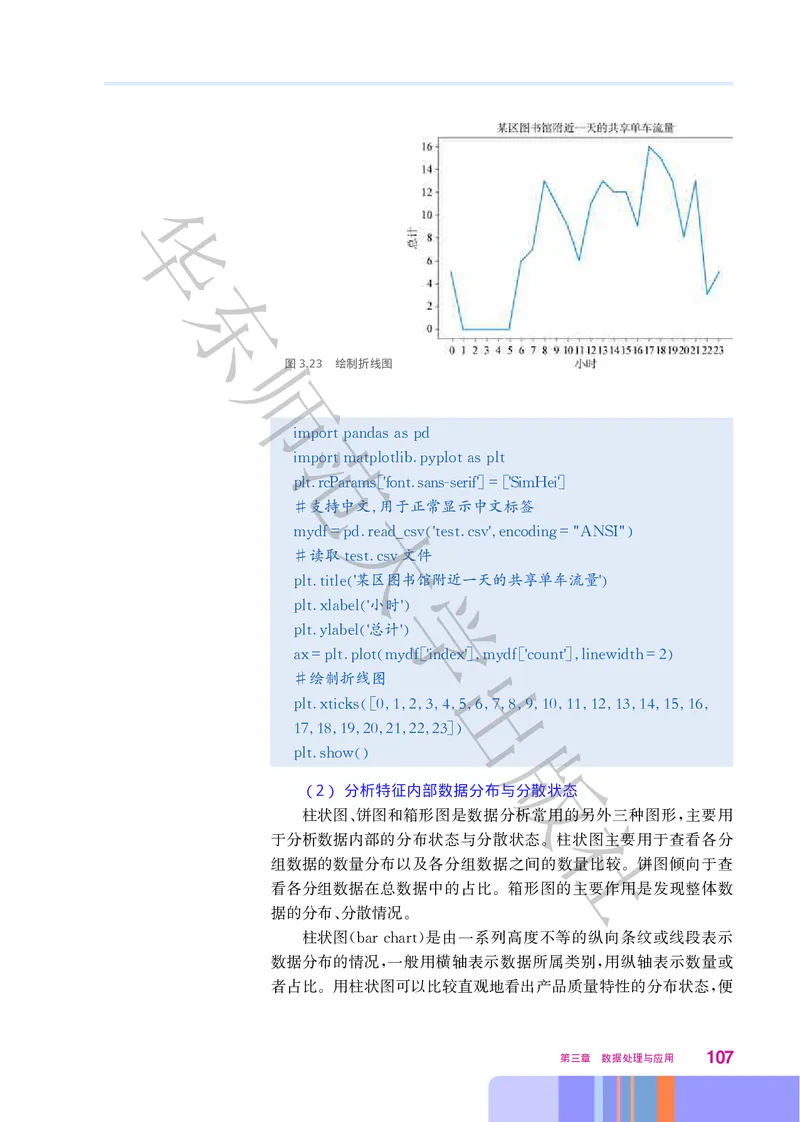






























文档内容
华
东
师
范
大
学
出
版
社总 主 编: 李晓明
副总主编: 赵 健
本册主编: 冯 忻
华
编写人员 按姓氏笔画排序
( ):
毛黎莉 冯 忻 张逸中 欧阳元新 周永麒
责任编辑: 程 东滨
美术设计: 储 平
师
普通高中教科书 信息技术 必修1 数据与计算
范
上海市中小学(幼儿园)课程改革委员会组织编写
出版发行 华东师范大学出版社 上海市中山北路3663号
( 大)
印 刷 上海昌鑫龙印务有限公司
版 次 2020年6月第1版
印 次 2020年6月第1次
学
开 本 890毫米×1240毫米 116
/
印 张 9.25
字 数 166千字
出
书 号 978 7 5760 0547 9
ISBN
定 价 11.60元
版
版权所有 未经许可不得采用任何方式擅自复制或使用本产品任何部分 违者必究
· ·
如发现内容质量问题 请拨打电话021 60821714
,
如发现印 装质量问题 影响阅读 请与华东师范大学出版社联系 电话 021 60821711
、 , , 。 : 社
全国物价举报电话 12315
:
声明 按照 中华人民共和国著作权法 第二十五条有关规定 我们已尽量寻找著作权人
《 》 ,
支付报酬 著作权人如有关于支付报酬事宜可及时与出版社联系
。 。
本册教材图片提供信息
:
本册教材中的部分图片由全景网 视觉中国等图片网站提供
、 。致同学们
华
东
师
亲爱的同学们
:
当今 信息技术的发展日新月异 物联网 大数据 人工智能等新
范, , 、 、
技术 新工具扑面而来 显著地改变着人们的生活 学习和工作模式
、 , 、 。
生存于信息社会中 我们每一个人都不可避免地会接触信息技术 应
, 、
用信息技术 甚至去创造新的信息技术 在具备了基本信息技术应用
大, 。
能力的基础上 高中阶段我们要进一步学习信息技术的知识与技能
, ,
能够利用信息技术负责任地解决生活与学习中的问题 全面提升信息
,
素养 迎接信息社会的挑战
, 。
学
数据与计算 作为高中信息技术学科的必修模块 是学习高中信
“ ” ,
息技术学科其他模块的基础 本教科书采用 项目活动 方式组织学
。 “ ”
习内容 通过 信息技术伴我学 编程应用助健康 交通数据利抉择
, “ ”“ ”“ ”
出
智能工具好帮手 项目 将数据与大数据 算法与编程实现 数据处理
“ ” , 、 、
与应用 人工智能等基础知识与技能融入到学习活动中 教科书的每
、 。
章围绕 信息意识 计算思维 数字化学习与创新 信息社会责任
“ ”“ ”“ ”“ ”
四个学科核心素养提出本章的学习版目标 利用 本章知识结构 图示呈
, “ ”
现本章知识脉络 帮助同学们从总体上了解本章学习内容
, 。
在学习过程中 同学们可以通过 体验思考 栏目 将现实问题 个
, “ ” , 、
人经验与知识技能相关联 带着问题开始学社习 通过 探究活动 和 项
, ; “ ” “
目实践 栏目 将 做中学 与 学中做 的学习方法相互融合 把知识技
” , “ ” “ ” ,
能应用于解决实际问题中 通过 技术支持 栏目 将新技术与新工具
; “ ” ,
适时应用于作品制作中 提高合理选用技术工具创造性完成作品制作
,
的能力 按照个人的学习需求 学习 知识延伸 栏目中的内容 拓展个
; , “ ” ,
人学习视野
。
提升信息素养 要求我们在掌握基本信息技术知识和常用信息技
,
术工具的同时 能够用计算思维来分析问题 要求我们在体验信息技
, ;
致同学们 1华
东
师
术给我们带来的更高效率的同时 积极运用技术来创造性地解决问题
,
和创作作品 要求我们在享受信息技术提供的便利的同时 关注信息
范; ,
安全 参与和促进信息社会的伦理与道德建设 同学们可以通过本教
, 。
科书与配套资源学习信息技术 负责任地应用信息技术 逐步成长为
, ,
新时代合格的社会主义建设者
大。
编 者
学
出
版
社
2 数据与计算目 录
华
东
师
第一章 数据与大数据
... 1
范
项目主题 信息技术伴我学
... 3
第一节 大数据、信息与知识
... 4
第二节 数字化与编码
... 16
学
第三节 大数据及其作用与价值
... 26
出
第二章 算法与程序实现
... 35
版
项目主题 编程应用助健康
... 37
第一节 算法与算法描述
... 38
社
第二节 程序设计语言基本知识
... 50
第三节 常用算法及其程序实现
... 71
目 录 1华
东
师
第三章 数据处理与应用
... 79
范
项目主题 交通数据利抉择
... 81
第一节 数据采大集、整理与安全
... 82
第二节 数据分析与可视化
... 97
学
第三节 数据分析报告与应用
... 114
出
第四章 走近人工智能
... 117
版
项目主题 智能工具好帮手
... 119
第一节 体验计算机视觉应用
... 120
社
第二节 人工智能的发展历程
... 124
第三节 人工智能的作用及影响
... 135
后记
... 141
2 数据与计算华
东
师
范
第 一 章
大
学
数据与大数据
出
本章学习目标 版
在实际生活与学习中感知数据与信息 知道数据与信息的特征 理解数
◉ , ,
社
据 信息与知识的区别和联系 认识数据与信息对社会发展和个人成长
、 ,
的影响
。
掌握二进制数与十进制数 二进制数与十六进制数相互转换的方法 了
◉ 、 ,
解数字化的过程与意义 知道字符 声音 图像编码的基本方式
, 、 、 。
针对学习任务 选择数字化学习工具和资源 感受利用它们进行自主学
◉ , ,
习和知识分享的优势
。信息技术的发展与普及改变着我们的生活与学习 我们的晨起 可能始于查看手腕上带
。 ,
有睡眠监测功能的智能手环 我们的休闲 可能始于点击手机中具有歌曲智能推荐功能的音乐
; ,
软件 我们的出行 可能始于扫描小区外停放的共享单车的二维码 我们的学习 也可能不再是
;华, ; ,
从步入教室的一刻开始 而是始于打开一款能够时时 处处伴随着我们的在线学习软件
, 、 。
目前 越来越多的高中生使用慕课学习平台 数字图书馆 数字实验系统开展学习 登录
, 、 、 。
慕课学习平台后东可以实现跨校学习 共享优质学习资源 访问数字图书馆 能够快速查阅信
, , ; ,
息 自助完成电子图书的借阅和归还 应用数字实验系统 能够体验实验数据的生成过程 以可
, ; , ,
视化方式感知实验规律 信息技术在改变着我们的学习环境 也改变着我们的学习方式 掌
。 , 。
师
握信息技术知识 运用信息技术促进学习 是新时代每位中学生都应具备的能力
, , 。
范
大
本章知识结构
学
-@ 4- *
出
E
T
@ +
+ +
版
*
4 +
- )
- 4 '
@ D .
+ D * /
2
社
E
E
E @
+ 0 M
@
4 4 4
- - -
E
D
D
/
2 数据与计算项目主题 信息技术伴我学
华
项·目·情·境
随着技术的发展 人们阅读的书籍已经从纸质图书拓展为既能看也能听的电
,
东
子图书 人们传统的阅读方式也随之发生变化
, 。
一年一度的学校诗词大会即将举行 学校图书馆收到了一些读者需求 有的同
, :
学希望图书馆能够增购一些电子图书 供同学们借阅 有的同学希望图书馆能够将
, ;
馆藏的纸质校刊制作成电子校刊 方便查阅往年学校诗词大会的征文 有的同学希
师
, ;
望在面对浩瀚书海时 学校图书馆能够根据同学们的阅读习惯 提供个性化的图书
, ,
推荐
。
小申是学校图书馆的志愿者 他能为学校图书馆提供一些建议吗
, ?
范
大
项·目·任·务
任务1 任务2 任务3
学
搜索电子图书网 将学校馆藏的纸 分析电子图书网
站,记录电子图书选择 质校刊制作成电子校 站向读者推送电子图
过程中的参考数据,了 刊,感受数字化的过 书的方法与策略,举例
出
解这些数据所反映的 程,小组合作完成电子 说明大数据在其中的
信息,描述数据在选择 校刊的制作。 作用,为学校图书馆设
电子图书过程中所起 计一份电子图书推荐
到的作用。 版方案。
社
第一章 数据与大数据 3第一节 数据、信息与知识
人类对于数据的应用由来已久 早在春秋战国时期 齐国国相管
, ,
华
仲就通过对农业生产数据的统计分析来制定相关的农业生产政策 在
,
汉书 地理志 史记 平准书 等众多史籍中都留下了有关农业生
《 · 》《 · 》
产 天文历法 地理山川的大量数据 这些数据的应用一定程度上提高
、 、 ,
东
了人类的生产效率 如今 信息技术的发展赋予了人们采集和分析数
。 ,
据的新工具与新方法 通过这些工具和方法 人们可以更高效地处理
, ,
数据 解决问题
, 。
师
体 验 思 考
范
随着学校诗词大会举办日期的临近 图书馆老师希望小申能够根据同学们的需求 列出与诗词相关的
, ,
电子图书购买清单 小申访问了一些电子图书网站 通过查找和比较 列出了电子图书的购买清单
。 , , 。
思考:
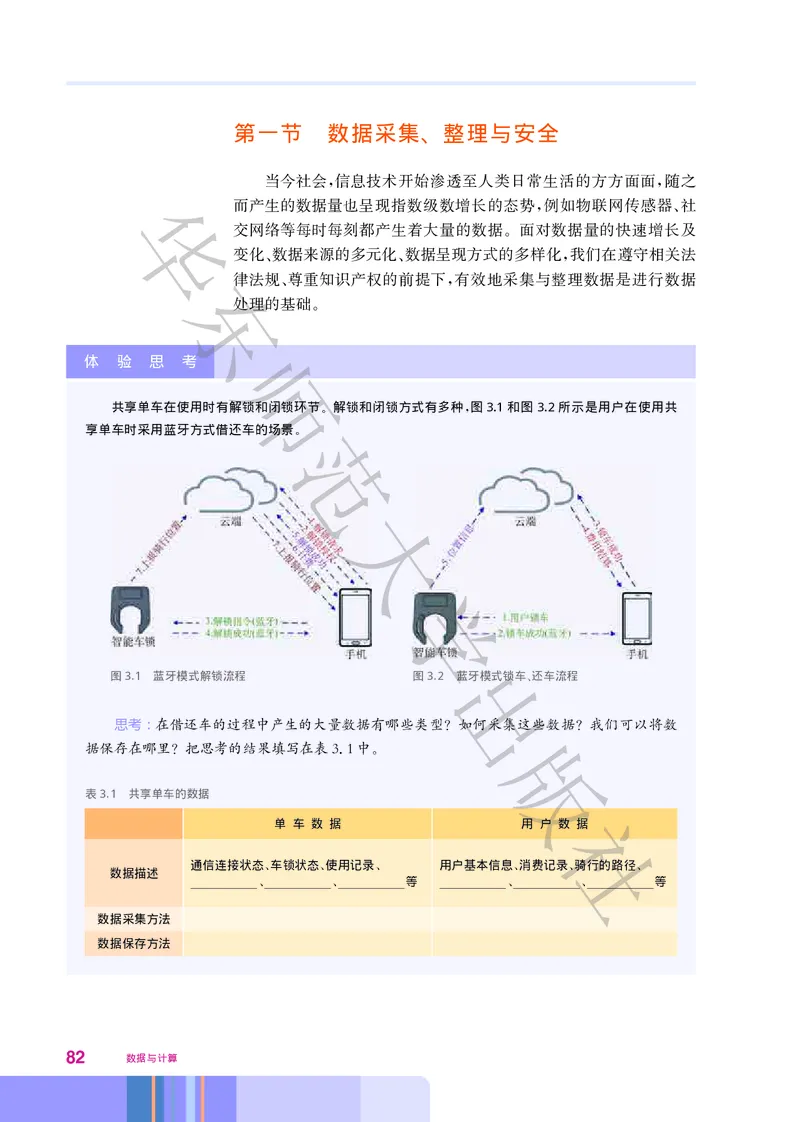
1. 如图11所示,网站上提供了哪些 大 数据来帮助人们选择要购买的图书?
.
2. 这些数据对人们选择图书有什么帮助?
学
出
版
社
图1.1 在电子图书网站上搜索电子图书
4 数据与计算一、 感知数据
数据无处不在 数字图书馆中 人们输入的账号 密码 读者对于
。 , 、 ,
华
图书的评论等都是数据 公交站台电子屏幕上显示的行车线路号 预
; 、
计到达时间等也是数据 天气预报播报的气温 湿度 风级等同样是数
; 、 、
据 数据已广泛应用于我们的生活与学习
。 。
东
1. 数据的概念
师数据是对事物描述的记录 例如 描述一个学生的基本特征 可
。 , ,
以通过姓名 性别 年龄等方面的数据来记录 确定某一地理位置 可
、 、 ; ,
以通过经度和纬度的数据来记录 表示城市空气质量检测中细颗粒物
;
范随时间变化的情况 可以用一个时间序列数据来记录 数据
(PM 2 . 5) , 。
可以帮助人们有效地描述事物
。
数据的表现形式多种多样 可以有数字 文字 图形 图像 声音等
, 、 、 、 、
形式 对同一事物的描述记录也可以有不同的数据表现形式 例如
大
。 , ,
导航仪行车线路中表示车辆左转时 可以用文字 左转 来表示 也可
, “ ” ,
以用图形 来表示 还可以通过语音来播报
, 。
同一数据也可能描述不同的事物 例如 数字 60 可以表示一个
学 。 , “ ”
人的年龄 一次考试的成绩 一件物品的长度 或者是某个路段的机动
、 、 ,
车的最高限速值等 因此 脱离具体的情境和形式 无法确定数据的
。 , ,
意义
。 出
数据是可加工 可处理的 从已知数据出发 参照相关数据进行
、 。 ,
加工计算 生成一些新的数据 从中可以得到新的结论 从而作为人们
, , ,
决策的依据 例如 在线学习网站会记录学习者的访问数据 通过学
。 , ,
版
习者浏览某一页面的起始时间和结束时间 计算得到这一页面的学习
,
时长 并将该学习时长和系统设定的有效学习时长进行比较 从而判
, ,
断学习者的该次学习是否有效
。
社
在人类文明的历史长河中 人们发明了很多处理数据的工具 从
, ,
古人发明的算盘到故宫馆藏的计算尺 从十六世纪帕斯卡发明的加法
,
器到今天功能强大的计算机 人们处理数据的能力越来越强大 数据
, ,
的含义也越来越丰富 在计算机科学中 数据是计算机识别 存储和
。 , 、
加工的对象 例如 我们常用的演示文稿文件 电子表格文件 图像
。 , 、 、
文件 音频文件和视频文件等都是计算机处理的数据 如图12
、 , .
所示
。
第一章 数据与大数据 5华
东
图1.2 用计算机处理的数据
师
2. 数据的价值
范
在信息社会 随着数据处理技术的迅速发展 数据被广泛地应用
, ,
于社会的方方面面 给人们的学习 生活与工作带来了巨大的变化
, 、 。
在数字图书馆中 图书管理人员利用采集到的
大 ,
借阅数据 调整管理方式 提供个性化服务 读者借
, , ;
助网络平台中的图书数据 足不出户就可以有针对
,
性地选择和借阅图书 享受读书的乐趣 图书作者
, ;
学
还可以根据读者对图书的阅读和评价数据 进一步
,
完善图书内容
。
在学校餐饮管理中 通过食堂管理系统 可以
, ,
出
快速获取和分析学生的用餐数据 根据不同菜品的
,
销售数据 食堂管理员可以适时地调整菜品种类
, ,
合理安排每种菜品的数量 提高服务质量
图1.3 数字化实验系统
, 。
在教学实验中 版通过数字化实验系统 可以采
, ,
集需要测量的物理量 如温度 电压 压强等 将其
, 、 、 ,
转换成计算机可以处理的数据 计算机处理后 能
。 ,
够直观地呈现实验结果 提高社学生的探究能力 如
, ,
图13所示
. 。
在道路检修过程中 道路检测车可以自动采集
,
路面的损坏状况 道路平稳度等各项数据 如图14
、 , .
所示 通过数据分析 车载计算机可以判断道路的
。 ,
安全情况 甚至还可以估算出维修费用 避免了由
, ,
于人工目测而导致的误差 为道路养护提供准确
图1.4 道路检测车
, 、
有效的数据支撑
。
6 数据与计算随着信息技术与人们生产生活的交汇融合以及互联网的快速普
及 全球数据呈现出爆发式增长 海量集聚的特点 数据对改善人民
, 、 。
生活 促进经济发展 推动社会进步等 起着越来越重要的作用 它已
、 、 , ,
华
成为像水 电 煤气一样重要的资源 数据作为一种资源 同样需要通
、 、 。 ,
过各种各样的 管道 输送到社会的各个领域中去 将数据转化为用户
“ ” ,
决策或行动的依据 促进社会的发展
, 。
东
二、 认识信息
师自古以来 人类的生存和发展就与信息有着不解之缘 我国古代
, 。
利用烽火台传递示警信息 通过活字印刷术促进知识和文化的广泛传
,
播 今天 移动通信设备和网络成为我们获取信息的重要途径 信息
。 , 。
的范获取与应用影响着我们分析问题与解决问题的方式
。
项 目 实 践
大
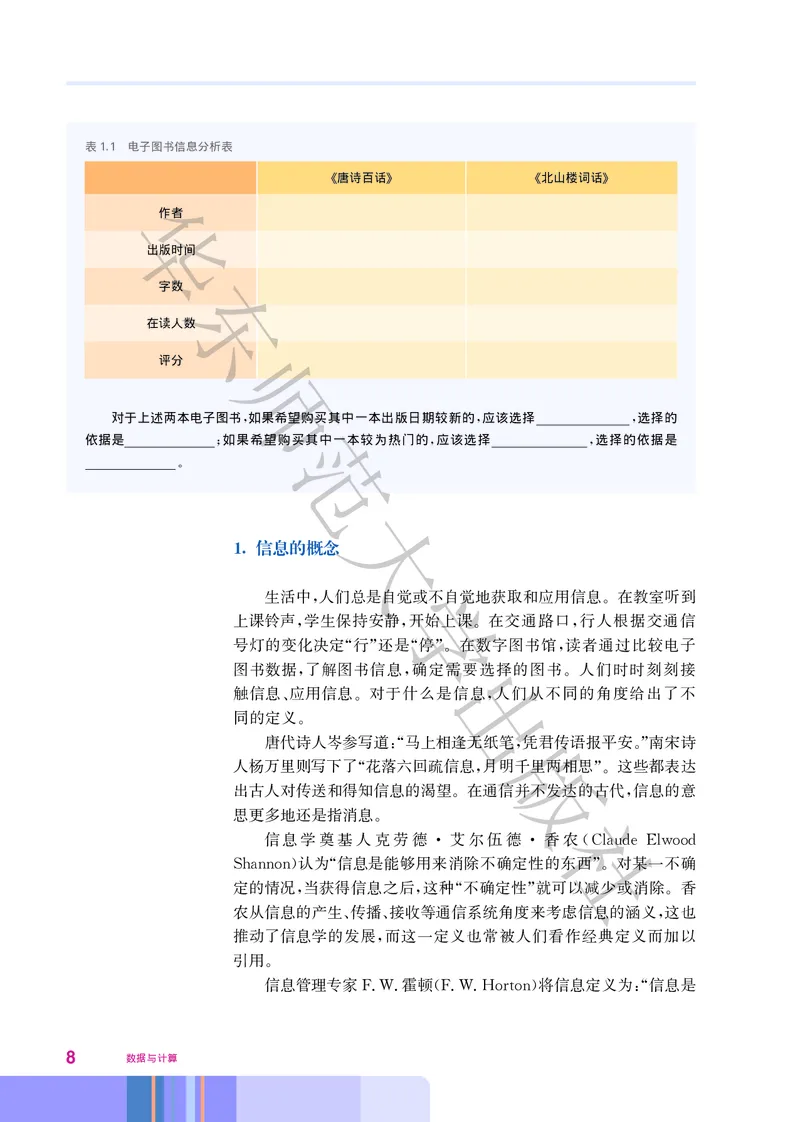
请尝试读取图1.5中的数据 填写表1.1并回答问题
, , 。
学
出
版
社
图1.5 电子图书
搜索页面
第一章 数据与大数据 7表1.1 电子图书信息分析表
《唐诗百话》 《北山楼词话》
华
作者
出版时间
东
字数
在读人数
师
评分
对于上述两本电子图书 如果希望购买其中一本出版日期较新的 应该选择 选择的
, 范 , ,
依据是 如果希望购买其中一本较为热门的 应该选择 选择的依据是
; , ,
。
大
1. 信息的概念
学
生活中 人们总是自觉或不自觉地获取和应用信息 在教室听到
, 。
上课铃声 学生保持安静 开始上课 在交通路口 行人根据交通信
, , 。 ,
号灯的变化决定 行 还是 停 在数字图书馆 读者通过比较电子
“ ” “ ”出。 ,
图书数据 了解图书信息 确定需要选择的图书 人们时时刻刻接
, , 。
触信息 应用信息 对于什么是信息 人们从不同的角度给出了不
、 。 ,
同的定义
。
版
唐代诗人岑参写道 马上相逢无纸笔 凭君传语报平安 南宋诗
:“ , 。”
人杨万里则写下了 花落六回疏信息 月明千里两相思 这些都表达
“ , ”。
出古人对传送和得知信息的渴望 在通信并不发达的古代 信息的意
。 ,
思更多地还是指消息 社
。
信息学奠基人克劳德 艾尔伍德 香农
· · (ClaudeElwood
认为 信息是能够用来消除不确定性的东西 对某一不确
Shannon) “ ”。
定的情况 当获得信息之后 这种 不确定性 就可以减少或消除 香
, , “ ” 。
农从信息的产生 传播 接收等通信系统角度来考虑信息的涵义 这也
、 、 ,
推动了信息学的发展 而这一定义也常被人们看作经典定义而加以
,
引用
。
信息管理专家 霍顿 将信息定义为 信息是
F.W. (F.W.Horton) :“
8 数据与计算为了满足用户决策的需要而经过加工处理的数据 简单地说 信息是
。” ,
经过加工的数据 或者说 信息是数据处理的结果
, , 。
综合上述信息的定义可以看出 信息表示的是事物之间的相互关
,
华
系 它可以通过数字 字符 图像 声音和视频等载体进行传播 人们
, 、 、 、 。
借助信息可以了解情况 形成判断 做出决策 指导行动 在信息社会
、 、 、 。
里 有效获取和合理应用信息已成为人们需要具备的一项重要的信息
,
东
素养
。
2. 信息的特征
师
信息在人际交流 生产管理 知识传播和科学研究等方面都发挥
、 、
着巨大的作用 了解信息的特征有助于我们加深对信息的认识和
。
理范解
。
(1) 信息可以传播和存储
信息的传播和存储需要依附于一定的载体 承载信息的数字 字
。 、
符 图像 声音和视频等可称为信息的载体 在信息处理中 如果存储
大
、 、 。 ,
信息的载体遭到破坏 其承载的信息就会丢失 例如 古书中文字的
, 。 ,
缺失导致了它所传达信息的丢失 通信信号受到强烈干扰 也会破坏
。 ,
其所传递的信息
。学
(2) 信息的价值是相对的
同一条信息对于不同的持有者具有不同的价值 例如 有一条信
, ,
息 我国发现了兵马俑 新闻记者需要将这条信息传播给更多的人
“ ”,出 ,
历史学家需要这条信息帮助其更好地进行历史研究等 同样 信息的
。 ,
价值也取决于信息接收者对信息的理解 认知和应用能力 人们在信
、 。
息的应用过程中 经过对原有信息的加工后可能会产生新的信息 进
, ,
版
而产生新的价值 从而使原来的信息增值
, 。
(3) 信息可以被共享
人们可以将一条信息传播出去 让其他人也能接收
,
社
并反复利用 如图16所示 英国著名戏剧家萧伯纳曾
, . 。
经说过 如果你有一个苹果 我有一个苹果 彼此交换
:“ , , ,
我们每个人仍然只有一个苹果 如果你有一种思想 我有
; ,
一种思想 彼此交换 我们每个人就有了两种思想 甚至
, , ,
多于两种思想 这在一定程度上体现了信息是可以被共
。”
图1.6 信息可以被共享 享的
。
第一章 数据与大数据 9(4) 信息具有时效性
信息往往反映了事物在某个特定时间的状态 信息的时效会随着
,
时间的推移而变化 例如 用户可以通过使用手机扫描二维码登录一
。 ,
华
些网站或邮箱 提供给用户扫描的二维码每隔一定时间便会刷新 重
, ,
新生成 它所传递的信息只在一定时间内有效 在信息社会中 信息
, 。 ,
的变化越来越快 信息价值的实现取决于对其及时的把握和运用 如
, 。
东
果不能及时利用最新信息 信息的价值就可能会贬值甚至会变得毫无
,
价值 这就是信息的时效性
, 。
师3. 合理应用信息
社会信息总量的快速增长为人们应用信息解决问题带来了
便范利条件 但是 过于庞杂的信息量 各种各样的干扰信息 持
。 , , ,
续更新的技术工具 都对人们感知与获取信息 甄别信息的真伪
, 、
和合理应用信息带来了挑战
。
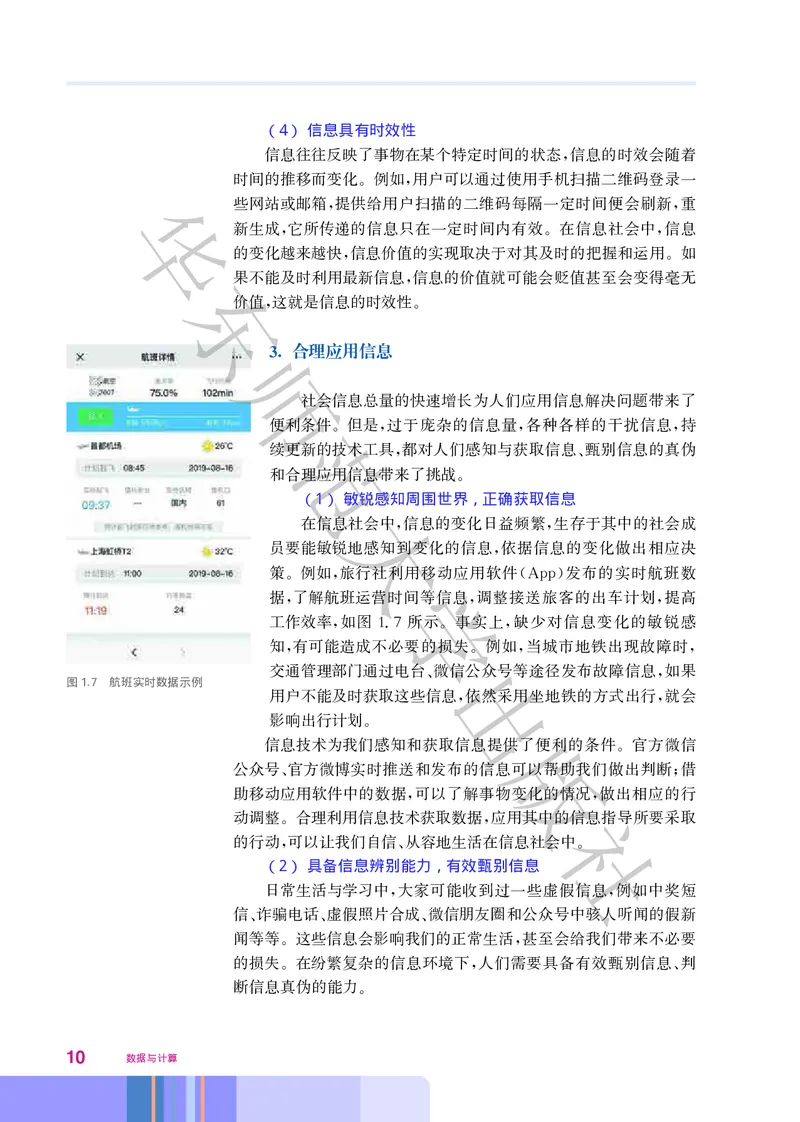
(1) 敏锐感知周围世界,正确获取信息
大
在信息社会中 信息的变化日益频繁 生存于其中的社会成
, ,
员要能敏锐地感知到变化的信息 依据信息的变化做出相应决
,
策 例如 旅行社利用移动应用软件 发布的实时航班数
。 , 学 (App)
据 了解航班运营时间等信息 调整接送旅客的出车计划 提高
, , ,
工作效率 如图17所示 事实上 缺少对信息变化的敏锐感
, . 。 ,
知 有可能造成不必要的损失 例如 当城市地铁出现故障时
, 出。 , ,
交通管理部门通过电台 微信公众号等途径发布故障信息 如果
图1.7 航班实时数据示例 、 ,
用户不能及时获取这些信息 依然采用坐地铁的方式出行 就会
, ,
影响出行计划
。
版
信息技术为我们感知和获取信息提供了便利的条件 官方微信
。
公众号 官方微博实时推送和发布的信息可以帮助我们做出判断 借
、 ;
助移动应用软件中的数据 可以了解事物变化的情况 做出相应的行
, ,
社
动调整 合理利用信息技术获取数据 应用其中的信息指导所要采取
。 ,
的行动 可以让我们自信 从容地生活在信息社会中
, 、 。
(2) 具备信息辨别能力,有效甄别信息
日常生活与学习中 大家可能收到过一些虚假信息 例如中奖短
, ,
信 诈骗电话 虚假照片合成 微信朋友圈和公众号中骇人听闻的假新
、 、 、
闻等等 这些信息会影响我们的正常生活 甚至会给我们带来不必要
。 ,
的损失 在纷繁复杂的信息环境下 人们需要具备有效甄别信息 判
。 , 、
断信息真伪的能力
。
10 数据与计算生活中 人们可以通过多种方式和渠道来辨别信息的
,
真伪 例如通过主流媒体对所获得的信息进行核对 与所获
, ,
信息的相关人员进行实时沟通确认 或者借助技术工具对
,
华
所获信息进行分析辨别 人们在手机中安装移动应用安全
。
软件来识别和标记诈骗电话等 如图18所示 就是一种常
( . ),
见的辨别信息真伪的防护方式
。
东 (3) 遵守信息安全法规,负责任地使用信息
信息技术拓展了人们的生存时空 创造出人们新的生
,
存环境 在新的环境中 人们也要遵守其中的新秩序 为
。 , 。
师维护信息社会的秩序 我国先后出台了一系列旨在推动信
,
息化建设的法律法规 这就要求每位社会成员都要担负起
,
相应的责任 2017年6月 我国正式施行 中华人民共和
。 , 《
范国网络安全法 其中 第十二条要求 任何个人和组织不
》。 , “
得利用网络从事编造 传播虚假信息扰乱经济秩序和社会
、
秩序 以及侵害他人名誉 隐私 知识产权和其他合法权益
, 、 、
等活动
大
”。
网络是继陆地 海洋 天空 太空之外 又一个人类活动
、 、 、 ,
空间 人们在网络空间中的各项活动要遵守信息社会的法
。
律法规 如有违反法律法规的行为 必将会受到法律法规的
学, ,
惩罚 例如 不法分子通过网络散布病毒程序 用以盗取他
。 , ,
人手机通信录 短信 银行卡账号等信息 危害社会信息安
、 、 ,
全 经公安部门查实 认定其违法行为后 根据相应法律法
。 出、 ,
规 对其进行了相应处罚
, 。
三、 学习知识
版
知识就是力量 这句名言一直流传至今 知识可以推
“ ” ,
动社会的进步 在人类文明的历史长河中 人们可以从种
。 ,
社
类繁多的资料记录中获取知识 也可以在生活实践中通过
,
分析数据和信息来发现知识 如今 信息技术的发展为我
。 ,
们学习知识创造了新的条件 结合具体问题情境 应用这
。 ,
图1.8 移动应用安全软件 些知识可以帮助我们解决问题
。
第一章 数据与大数据 11探 究 活 动
在电子图书网站上 小申发现许多位于热门榜单上的电子图书
华,
都拥有大量的读者评论 小申想通过这些评论 了解某一电子图书
。 ,
的读者最突出的阅读感受 老师推荐他借助语义分析工具 对电子
。 ,
图书的相关读者评论进行研究 使用语义分析工具分析 唐诗百
。 《
话 的读者评论东结果如图1.9所示
》 , 。
1. 根据图 1.9分析读者对于 唐诗百话 最突出的阅读感受是
, 《 》
什么
。
2. 尝试利用语义分析工具 分析某一电子图书的读者评论 并
师, ,
思考在此过程中 信息技术工具起到了怎样的作用
, 。
图1.9 唐诗百话 读者评论词频统计图
《 》
范
在前面的活动中 我们尝试使用语义分析工具来辅助分析读者对
,
电子图书的评论 在实际应用中 数字图书馆可以对读者的图书评论
。 ,
加以分析 并以大此为依据向读者提供阅读推荐 信息技术为人们处理
, 。
数据提供了强有力的工具 人们可以利用信息技术对数据进行分析
, ,
找出其中的相互关系 形成规律 获得知识并加以运用
, , 。
学
1. 数据、信息与知识的关系
数据是描述事物的记录 它出能够承载信息 因此人们可以在处理
, ,
数据的过程中获得信息 随着人类的进步以及处理数据和信息的能
。
力不断提升 人类从数据中获取有用信息的能力越来越强
, 。
信息表示的是事物间的相互关系 通版过分析数据可以发现其中包
,
含的关系 例如 分析某电子图书借阅人数和读者评价 可以发现该
。 , ,
图书基本内容和写作特点 为从同类图书中选择合适的图书提供依据
, 。
知识分为一般知识和科学知识 在日常生活和工作中 人们所获
社
。 ,
得的认识和经验的总和 通常称为一般知识 科学知识是人们对信息
, 。
的科学组织 它是经过严谨的验证 获得学界一致认可的内容 如物理
, , ,
学科中的牛顿三大定律 化学学科中的元素周期律和生物学科中的遗
、
传基本定律等 随着认知工具和方法的发展 人们对世界的认识也会
。 ,
不断深入 人类的知识也在不断地发展
, 。
今天 人们运用各种信息技术工具来认识事物 表达思想 分享知
, 、 、
识 让学习和工作更加高效 例如 通过数字实验设备 可以便捷地采
, 。 , ,
12 数据与计算集数据 获取信息 从而发现新知识 借助网络平台加快信息的传播速
、 , ;
度 可以快速分享知识 合理地应用信息技术 人们就能更好地认识
, 。 ,
世界 发现知识 推动人类文明的进步
、 , 。
华
2. 体验数字化学习
东
今天 学习者处于全新的数字化学习环境中 需要不断提升个人
, ,
信息素养 选择合适的学习资源和学习方式开展学习 网络的发展拓
, 。
展了学习时空 学习者足不出户就可以获得优质的
,
师 学习资源 例如 不同地域的学校可以通过网络进
。 ,
行跨校研讨与交流 推动远程合作学习 实现优质教
, ,
育资源的效益最大化 如图110所示
, . 。
范 虚拟现实技术的应用可以模拟真实情境 帮助
,
学习者开展探究学习 例如 在学习海洋生物的相
。 ,
关知识时 学习者很难到深海中去体验深海生物的
,
生存环境 但是 在虚拟现实技术的支持下 学习者
大
。 , ,
可以身临其境地感受深海生物的生存环境 更好地
图1.10 互联网环境下的远程学习
,
学习 理解相关知识 如图111所示
、 , . 。
大数据与人工智能技术在教育中的应用可以记
学
录学习者的学习行为数据 针对学习者的学习需求
, ,
依据数据分析结果提供精准学习支持 目前 一些
。 ,
在线学习平台应用大数据和人工智能技术分析学生
出
的学习过程 实时采集学生的学习数据 依据数据发
, ,
现学生学习的不足 针对学习中存在的问题提供相
,
应的学习资源与指导 让学生感觉到 教师 时时刻
, “ ”
版
图1.11 虚拟现实技术支持深海生物知识的学习 刻都在自己身边
。
技 术 支 持 语义分析工具
社
借助语义分析工具 我们可以用量化的方式分析文本内容 获取文本所表达的深层次信息 例如 通
, , 。 ,
过语义分析工具 可以快速分析读者对图书的评价 了解读者对图书的关注要点等
, , 。
如图1.12所示 在应用语义分析工具时 将要分析的文本复制到分析工具中 通过计算 系统可以完
, , 。 ,
成文本内容的实体抽取 识别文本中出现的人名 地名等关键词 实现词频统计 对不同词性的词语进行分
, 、 ; ,
类呈现 分析每类词语出现的频度 绘制文本的词云 突出文本中出现频率较高的关键词 判断相关词语 分
, ; , ; ,
析语义关联情况 对文本内容进行精简提炼 从长篇文章中提取关键句和关键段落 编辑文本的摘要 等等
, , , , 。
第一章 数据与大数据 13华
东
师
图1.12 应用语义
分析工具分析文本
范
作业练习
小申与学习同伴在 大
数字化信息系统 DIS 实
( )
验室做 测定位移和速度
“ ”
实验 实验过程中 他们
。 , 学
通过 DIS中的位移传感
器采集实验小车的位移数
据 然后将采集的数据传
,
出
入计算机中 利用实验软
,
件系统描绘出s t图像
。
通过s t图像 可以确定
,
实验小车从起始时刻到任
版
意时刻的位移和任意一段
时间内的平均速度 实验
。
环境与实验数据 如 图
社
1.13所示
。
图1.13 测定位移和速度 的DIS环境与实验数据
“ ”
14 数据与计算1. 分析 测定位移和速度 的实验环境与实验数据 填写表1.2
“ ” , 。
华表1.2 测定位移和速度 的实验环境与实验数据分析
“ ”
分析内容 描 述
运用DIS采集了哪些实验数据
从东实验数据中可以发现哪些信息
通过实验可总结出哪些物理知识
列举实验中所使用的数字化工具
师
2. 列举你在日常学习中所使用的数字化学习工具 描述它们的功能 分析它们在学习中的优势和局
, ,
限性
。
范
知 识 延 伸 香农与信息论
大
1948年 香农在定义信息时 借用了物理学中的 熵 一词 解决了对 信息 一词的量化和度量问题
, , “ ” , “ ” 。
从此 信息 一词就有了一次数学化的提炼 信息就有了定量计算的单位 这是一个划时代的进步 推动了
,“ ” , , ,
通信技术的发展 也推动了整个信息技术的发展学信息论在信息与不确定性 信息与信息熵之间架起了
, 。 、
桥梁
。
香农认为 信息是能够用来消除不确定性的东西 他用概率分布来衡量信息的 不确定性 同时引入
“ ”, “ ”,
了 比特 作为计量单位 信息熵 一词是从 热力熵 而来 即求整个系统事件中平均信息量的大小 香农
“ ” 。“ ” “ ” 出, ,
给出了信息熵的数学公式
:
n
HHH(x)>.Σ p(x )log p(x )) ((i=1, 2, , n)
i 2 i
iii=1 版
这些概念奠定了信息论的基础 并且为信息技术领域的进步开辟了新的社道路
, 。
第一章 数据与大数据 15第二节 数字化与编码
信息技术的发展创造出一个全新的数字化环境 生活在其中的每
,
华
个人都能感受到数字化带来的变化 人们利用数字化设备可实时获
。
取自己的心率 血压等身体健康数据 通过分析这些数据 可以主动管
、 , ,
理自己的健康 乘客可以通过移动智能终端查询车辆到站的实时信
;
东
息 避免了以往久等公交车而不知车何时到达的尴尬 移动通信 移
, 。 、
动智能终端等新技术的广泛使用 使全球正在成为一个互联互通的数
,
字化世界
。
师
体 验 思 考
范
同学们希望查阅学校图书馆馆藏校刊上刊载的往年诗词大会征文 由于馆藏的校刊数量较少 因此
。 ,
图书馆只能满足少数同学的借阅需求 同时 同学们在借阅校刊的过程中 也令校刊产生了不同程度的
。 , ,
污损 影响了校刊的收藏 因此 学校图书馆希望能够将历年的纸质校刊制作成电子校刊 供同学们
, 。 , ,
借阅 大
。
思考:
1. 纸质校刊的内容承载于墨迹和纸张之中,那么电子校刊的内容是以怎样的形式存储在计
算机中的?
学
2. 分析纸质校刊和电子校刊在借阅过程中各自的优势和不足。
出
一、 进位计数制及其转换
目前 计算机的硬件组成通常可以版呈现两种状态 如电路的导通
, ,
和断开 这样就决定了计算机内部采用二进制 即以 0 和 1 的组合
。 , “” “”
来表示信息 用 1 来表示一种状态 如电路的导通 用 0 来表示相
, “” ( ), “”
反的另一种状态 如电路的断开 由于计算机社采用二进制数进行运
( )。
算和存储 因此要使用计算机进行信息处理 首先要把待处理的信息
, ,
用二进制数来表示
。
1. 进位计数制
进位计数制 是按进位方式实现计数的一种规则 进位计数制包
, 。
含数码 基数和位权三个要素 我们将用来表示某种进位计数制的一
、 。
16 数据与计算组符号称为数码 所使用的数码个数称为基数 数码在不同数位上的
, ,
倍率值称为位权
。
十进制是人们生活中常用的进位计数制 它的基数为10 由0 1
, , , ,
华
2 9共10个数码组成 整数位的位权从右向左依次为100 101
,…, , , ,
102 例如 十进制数463各个数位上的数字所代表的数值分别为
,…。 ,
4×102 6×101 3×100
、 、 。
东
二进制是一种常用于计算机中的进位计数制 它的基数为2 只有
, ,
0 1两个数码 整数位的位权从右向左依次为20 21 22 例如
、 , , , ,…。 :
二进制数 110 中 各个数位上的数字所代表的数值分别为1×22
( )2 , 、
师1×21 0×20
、 。
在计算机科学中 除了二进制之外 为了便于使用 常用的进位计
, , ,
数制还有十六进制 由于采用二进制数描述信息的位数较多 不便于
。 ,
记范忆 交流和阅读 因此为了方便书写和表达 人们常常将二进制数转
、 , ,
换为十六进制数 十六进制的基数是16 包含0 1 2 3 9
。 , , , , ,…, ,A,
共16个数码
B,C,D,E,F, 。
不同 大 的进位计数制用 S 表示 其中S是具体的数码 下标R
( )R , ,
是该进位计数制的基数 例如 102 和 1011 有时 也用特定的
, ( A)16 ( )2。 ,
字母标在末尾来标识进位计数制 例如1011 这里的 是二进制的
, B, “B”
特定字母 十进制和十六进制则分别用 和 来表示 一般情况
, 学 “D” “H” 。
下 十进制是默认进位计数制 因此字母 通常被省略
, , “D” 。
2. 不同进位计数制的相互转换
出
图1.14 十进制数转
换为二进制数
将十进制整数转换为二进制数的方法是除以2反向取余 例如
。 ,
将十进制数37转换为二进制数 即 37 = 100101 如图114
,版:( )10 ( )2, .
所示
。
二进制数转换为十进制数 一般可以将每位二进制数和该位的位
,
权相乘再求和 这种方法称为按权展开 例如
, 。 :
社
图1.15 二进制数转换为十 1011 =1×23 +0×22 +1×21 +1×20 =8+0+2+1= 11
六进制数 ( )2 ( )10
二进制数转换为十六进制数时 把二进制数从低位到高位按4位
,
一组划分 每组用一位十六进制数表示 不足4位二进制数 高位用
, , ,
0 补齐 例如 1011011 = 5 如图115所示
“” 。 ,( )2 (B)16, . 。
十六进制数转换为二进制数时 将每一位十六进制数转换为4位
,
二进制数 不足4位二进制数 高位用 0 补齐 例如 3 =
图1.16 十六进制 , , “” 。 ,(A )16
数转换为 二进制数 10100011 如图116所示
( )2, . 。
第一章 数据与大数据 173. 数据的存储单位
比特 是计算机中最小的数据存储单位 即一个二进制位 一
华
(bit) , ,
位的取值只能是0或1
。
字节 是计算机中信息组织和存储的基本数据存储单位1字
(Byte) ,
节就是8比特 字节常用 表示 描述存储容量的常用单位还有
。 B , KB、
东
等 其换算规则如表13所示
MB、GB、TB、PB、EB , . 。
表1.3 常用存储单位换算表
师
存储单位 换算规则 存储单位 换算规则
KB千字节 1KB=1024B=210B TB太字节 1TB=1024GB=240B
, ,
MB兆字节 1MB=1024KB=220B PB拍字节 1PB=1024TB=250B
, ,
范
GB吉字节 1GB=1024MB=230B EB艾字节 1EB=1024PB=260B
, ,
二、 数字大化
今天 数字技术向人类生活各个领域全面推进 迅速改变着我
, ,
们的学习和生活 网学上购物可以让消费者足不出户购买商品 电子
: ,
地图能及时规划出最优的出行路线 在线政务让市民办事更高效
, ,
数字博物馆让人们跨时空浏览馆藏珍品 在丰富多彩的信息社会
。
里 数字化是计算机处理信息出的基础 将现实世界中各种各样的信
, ,
息用二进制数来表示的过程就是信息的数字化
。
1. 模拟信号和数字信号 版
现实世界中 我们将连续变化的物理量称为 模拟量 如温
, “ ”,
度 速度等 数字化可将模拟量转换成数字社量 数字量的变化在时
、 。 ,
间或数值上都是离散的 模拟量和数字量都是对某一个物理量的反
。
映或表达 两者的主要区别是 模拟量是连续的 数字量是离散的
。 : , 。
例如 水银温度计中的水银汞柱伸缩是连续变化的 反映的是模拟
, ,
量 数字温度计显示的数字是离散的 反映的是数字量
; , 。
在电子设备中 模拟量通常以模拟信号的形式进行传递 数字
, ,
量则以数字信号的形式进行传递 在一定条件下 模拟信号和数
。 ,
图1.17 模拟信号与数字信号 字信号可以相互转换 如图117所示 以声音的数字化为例 麦
, . 。 ,
18 数据与计算克风能够将声波的振动转化为电信号 这是一种模拟信号 再经过模
, ,
数转换设备 如声卡等 的处理后 可以转换成计算机内部能够处理的
( ) ,
数字信号
。
华
2. 模拟信号的数字化过程
东
在计算机领域 数字化是指将复杂多样的信息表示为计算机可以
,
处理的二进制代码的过程 通常 使用电子设备
。 ,
如话筒等 采集的信号是模拟信号 为了能让数
( ) ,
师 字设备进行存储和处理 就需要将模拟信号转换
,
为数字信号 这种转换过程主要包括采样 量化和
, 、
编码
。
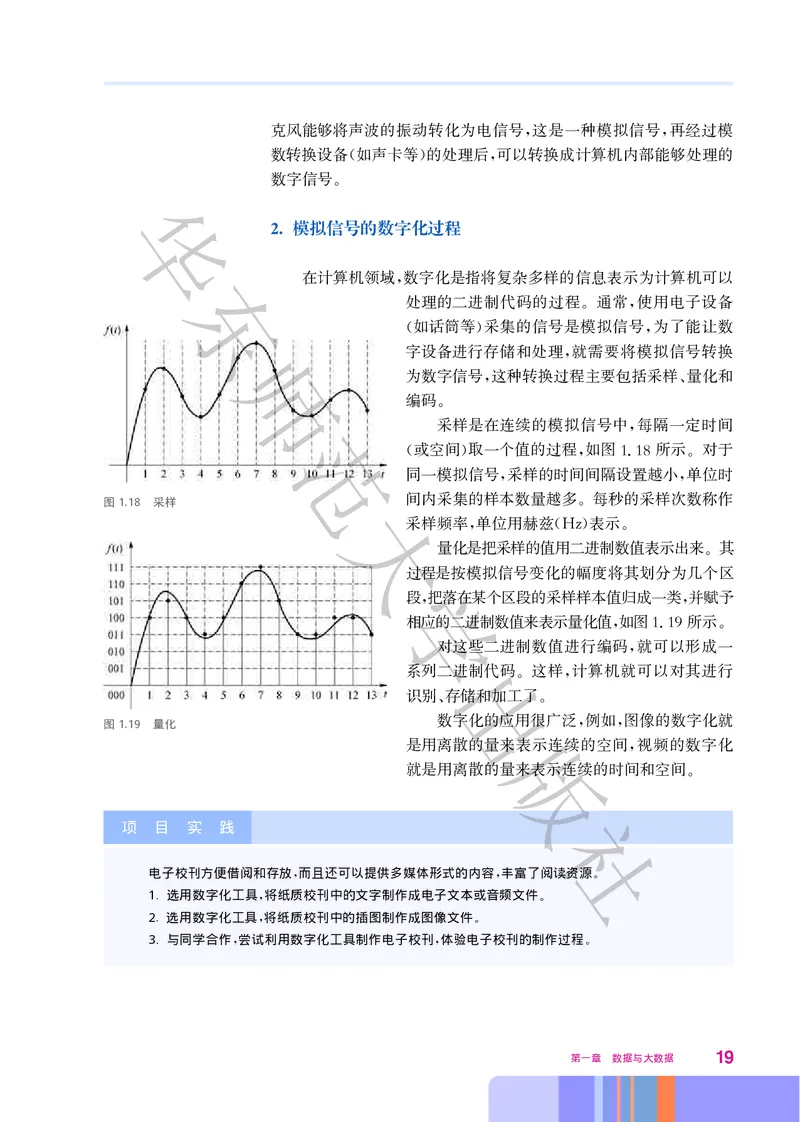
范 采样是在连续的模拟信号中 每隔一定时间
,
或空间 取一个值的过程 如图118所示 对于
( ) , . 。
同一模拟信号 采样的时间间隔设置越小 单位时
, ,
间内采集的样本数量越多 每秒的采样次数称作
图1.18 采样 大
。
采样频率 单位用赫兹 表示
, (Hz) 。
量化是把采样的值用二进制数值表示出来 其
。
过程是按模拟信号变化的幅度将其划分为几个区
学
段 把落在某个区段的采样样本值归成一类 并赋予
, ,
相应的二进制数值来表示量化值 如图119所示
, . 。
对这些二进制数值进行编码 就可以形成一
出 ,
系列二进制代码 这样 计算机就可以对其进行
。 ,
识别 存储和加工了
、 。
数字化的应用很广泛 例如 图像的数字化就
图1.19 量化
, ,
版
是用离散的量来表示连续的空间 视频的数字化
,
就是用离散的量来表示连续的时间和空间
。
社
项 目 实 践
电子校刊方便借阅和存放 而且还可以提供多媒体形式的内容 丰富了阅读资源
, , 。
1. 选用数字化工具 将纸质校刊中的文字制作成电子文本或音频文件
, 。
2. 选用数字化工具 将纸质校刊中的插图制作成图像文件
, 。
3. 与同学合作 尝试利用数字化工具制作电子校刊 体验电子校刊的制作过程
, , 。
第一章 数据与大数据 19三、 编码
为了有效处理信息 人们常常通过编码的方式来表示信息 例
, 。
华
如 公交车线路号就是一种编码 人们通过线路号来选择和区分公交
, ,
线路 学校里 教学楼的楼号和教室号也是编码 老师和同学们根据
。 , ,
楼号和教室号就能确定上课和活动的地点 生活中 身份证号 银行
。 , 、
东
卡号 学籍号 车牌号等都是编码
、 、 。
编码是为了方便信息的存储 检索和使用而规定的符号系统 编
、 。
码的过程是将信息按照一定的规则进行变换 图书馆中 管理员根据
。 ,
师图书类目 种次等信息对图书进行编码 形成索书号 然后按索书号将
、 , ,
图书放在书架相应的位置上 便于读者顺利地找到图书
, 。
要使用计算机处理各种各样的信息 需要通过编码的方式将信息
,
转换成范用 0 和 1 表示的二进制代码
“” “” 。
1. 字符编码
大
(1) ASCII码
目前 国际上广泛使用的英文字符编码是 码
, ASCII (American
美国信息交换标准码
standardcodeforinfor 学 mationinterchange, )。
码诞生于1963年 用于计算机内部字符的存储和计算机与外
ASCII ,
部设备的通信 标准的 码为7位二进制编码 即 6 0位
。 ASCII ( D ~D ),
存储时占用一个字节 最高位为0 例如 字符 的 码编码为
, 出。 , “A” ASCII
1000001 存储时如图120所示 标准的 字符集定义了128个
, . 。 ASCII
字符 其中包括10个阿拉伯数字 0 9 26个大写英文字母
, (“”~“”)、
26个小写英文字母 和33个符号共95个可
(“A”~“Z”)、 (“a”~版 “z”)
打印字符 以及33个控制字符
, 。
0 1 0 0 0 0 0 1
社
7 6 5 4 3 2 1 0
D D D D D D D D
图1.20 字符 A的ASCII码的存储
“”
(2) 汉字编码
汉字也是字符 用计算机处理汉字时也要采用二进制表示的编
。
码 目前 我国主要使用的汉字编码标准是 18030 2005 它支持
。 , GB — ,
多种字节的汉字编码 如单字节 双字节和四字节编码等 在
, 、 。 GB
20 数据与计算18030 2005中 大部分常用汉字采用双字节编码
— , 。
利用键盘输入汉字时 还需要通过另外设计的汉字输入码来实
,
现 汉字输入码可以使用字母 数字或符号来对汉字进行编码 汉字
。 、 。
华
输入码有多种形式 例如以汉字的字音为主的音码和汉字的字形为主
,
的五笔字型码等
。
此外 输出汉字时 还会使用汉字字形码 汉字字形码是字库中
, , 。
东
存储的汉字字形的数字化信息 用于汉字的显示和打印输出 目前
, 。 ,
汉字字形既可以用点阵方式表示 也可以用矢量方式表示
, 。
(3) Unicode字符集和编码方案
师由于不同语言的编码各不相同 为了统一所有文字的编码
, ,Unicode
应运而生 是计算机科学领域里的一项业界标准 它对世界
。Unicode 。
上大部分的文字系统进行了整理 编码 避免由于编码冲突而产生的乱
、 ,
码范问题 使得计算机可以用更为简单的方式来处理和呈现文字
, 。
字符集分为17组 平面 每组含有65536个码位 共
Unicode ( ), ,
1114112个 它就像一本 大字典 每一个码位都唯一对应一个字
。 “ ”,
符 其中 汉字位于0号平面和2号平面
大
。 , 。
要将这本 大字典 里的 字符转换成可用于传输 存储
“ ” Unicode 、
的二进制代码 则需要使用字符编码方案 目前 主要使用的是
, 。 ,
8 16 32三种编码方案
UTF 、UTF学、UTF 。
2. 声音编码
出
声音是振动产生的波 由不同频率的正弦波合成 声波的振幅
, 。
反映了声音的强弱 声波的频率反映了音调的高低 它是一种连续
, 。
变化的模拟信号 需要通过采样 量化和编码后实现数字化
, 、 。
版
声音的采样是指每隔一段时间在声音的模拟信号上采集一个样
本数值 采样间隔时间越短 采样频率就越高 那么单位时间内得到
。 , ,
的样本数据就越多 对声音的模拟信号的表示就越精确 声音的保真
, ,
度就越高 社
。
声音的量化是用二进制数值表示采样所得到的幅度值的过
程 首先将幅度值范围划分为2n个等级 每个等级对应一个幅度
。 ,
值 然后将采样得到的各个幅度值按一定的规则近似到某个等
,
级 并用n位二进制数表示这些值 这里的n是量化位数 划分
, 。 。
的等级越多 量化的位数就越多 量化精度也就越高 采样结果
, , ,
近似到某个等级时产生的误差就越小 音质就越有保证 如图
, ,
图1.21 声音量化的级别 121所示
. 。
第一章 数据与大数据 21通过采样和量化 对获得的二进制数进行编码后 就可以将声音
, ,
的模拟信号转换成二进制代码表示的数据
。
一般情况下 未经压缩的音频文件的数据存储量可以按如下方法
,
华
进行计算
:
数据存储量=采样频率×量化位数×声道数÷8×持续秒数 字节
( )
例如 一组1小时的数字音乐 未经压缩 的采样频率为441
东, ( ) .kHz,
量化位数为16位 声道数为双声道 则其数据存储量可按以下方法
, 。
进行计算
:
数据存储量=44100×16×2÷8×3600 字节
师 ( )
通常 未经压缩的数字音乐会被保存为 文件格式
, WAV 。
3. 图像编码
范
图像的采样是按一定的空间间隔从左到右 自上而
、
下提取画面信息 将图像在空间上转换成若干个像素
大,
点 每个像素点呈现不同的颜色
, 。
水平方向上的像素数量乘以垂直方向上的像素数
量称为图像分辨率 例如 一幅图像的分辨率为640×
学。 ,
480像素 表示该图像由水平方向上640个像素点 垂直
图1.22 同一图像的不同分辨率对比 , 、
方向上480个像素点 共640×480=307200个像素点组
,
成 如果不考虑其他因素的影响 图像分辨率越高 采
。 , ,
出
样的精度就越高 数字化后的图像越清晰 同时图像所
, ,
占的存储空间也越大 如图122所示
, . 。
图像的量化是用若干位二进制数表示采样得到的每个像素点的
版
颜色 首先确定颜色的取值范围 然后将近似的颜色划分成同一种颜
。 ,
色 每种颜色用一个二进制数来表示
, 。
记录每个像素点的颜色所需的二进制数的位数 称为颜色深度
,
位深度 对于一幅图像来说 颜色深度决定社了该图像中的像素可
( )。 ,
以使用的最多颜色数量 例如 颜色深度为8比特时 可以表示256
。 , ,
种颜色 颜色深度为16比特时 则可以表示65536种颜色 颜色深
; , 。
度越大 显示的图像色彩越丰富 画面越自然 逼真 如图123所
, , 、 , .
示 在图像分辨率相同的情况下 颜色深度越大 图像所占的存储
。 , ,
空间也越大
。
通常 计算机中可以采用 颜色模型来描述颜色 颜色
图1.23 同一图像的 , RGB 。RGB
不同颜色 深度对比 模型 又称为三原色光模式 将红 绿
(RGBcolormodel) , (red)、 (green)、
22 数据与计算蓝 三原色以不同的比例相加 可以产生不同的颜色 每一个像
(blue) , 。
素可以用24比特表示 所以三种原色各分8比特 即每一种原色的强
, ,
度可以用0 255之间的整数来表示 用这种方法可以组合成
华 ~ ,
16777216种颜色 例如 纯红色用 颜色模型表示为 255 0
。 , RGB ( , ,
0 纯绿色用 颜色模型表示为 0 255 0
), RGB (, , )。
这种由纵横排列的像素点组成的图像称为位图 位图的质量主
。
东
要由图像分辨率和颜色深度决定 未经压缩的位图图像的数据存储
。
量可以按如下方法进行计算
:
未经压缩的位图图像的数据存储量= 图像分辨率×颜色深度÷8字节
( )
师
例如 一幅分辨率为1920×1080像素的图像 保存格式为 24位
, , “
位图 则其数据存储量可按以下方法进行计算
”, :
范 数据存储量= × × ÷ 字节
1920 1080 24 8( )
通常 未经压缩的位图图像会被保存为 文件格式
, BMP 。
四、 数大据压缩
很多信息 包括视频 音频等多媒体信息 经数字化转换后生成
, 、 ,
的二进制数据是学以文件形式保存的 它们占用的存储空间相对较
,
大 为了更少地占用存储空间 就需要采用合适的方式对数据进行
。 ,
压缩
。
出
探 究 活 动
小申和同学们在将纸质校刊制作成电子校刊的过程中 需要将校刊中的插图制作成计算机中的图像
版
,
文件
。
1. 尝试将图像文件保存为不同的图像文件格式
。
2. 从文件大小 图像质量等方面比较不同图像文件格式的差异
、 。
社
实际上 数据压缩就是采用特殊的编码方式处理数据 使数据占
, ,
用的存储空间相对减少 以便存储和传输
, 。
数据之所以能够被压缩并保证压缩后可用 主要是因为数据存在
,
如下几种现象
:
数据中存在冗余 例如 在一个计算机文件中 某些符号会重复
。 , ,
出现 某些符号会比其他符号出现得更频繁 某些字符总是在各数据
, ,
第一章 数据与大数据 23块中可预见的位置上出现等 这些冗余数据便可在数据编码的过程
。
中去除或减少
。
相邻数据之间经常存在相关性 例如 图片中常常有色彩均匀的
。 ,
华
背景 电视信号的相邻两帧之间可能只有少量的变化 声音信号有时
, ,
具有一定的规律性和周期性等 因此 利用某些变换来尽可能地去除
。 ,
这些相关性数据 也可以实现压缩的目的
, 。
东
由于人的耳 目对信号的时间变化和幅度变化的感受能力都有一
、
定的极限 如人眼对视频有视觉暂留效应 因而将信号中这部分感觉
, ,
不出的地方 掩蔽掉 也可以实现压缩的目的
“ ”, 。
师数据压缩的方法比较多 常用的压缩方法分为无损压缩和有损
。
压缩两种
。
无损压缩是指对压缩后的数据进行还原后 得到的数据与压缩前
,
完全相范同 例如 一幅分辨率为24×24像素的图像 其中一行像素色
。 , ,
彩值的排列为 红红红红红红红红红红红红红红红红绿绿绿绿绿绿绿
“
绿 经过某种压缩后 可以表示为 红16绿8 这种压缩就称为无损
”, , “ ”,
压缩 我们可使用常见的无损压缩软件对文件进行压缩 压缩后生成
大
。 ,
的压缩文件存储容量可能只有原来的几分之一甚至更小
。
压缩文件中的数据需要用压缩软件解压缩后才能还原使
用 对于一些程序数据和文档数据而言 只能采用无损压
。 学 ,
缩 以确保数据的准确性 否则一旦还原的数据有误 就无
, , ,
法使用了
。
相对于无损压缩 有损压缩通常应用于图像 声音等
出, 、
数字化后存在大量冗余信息的文件 有损压缩过程中会
。
损失一定的信息 压缩后的数据无法还原到与压缩前一
,
致 但不会导致人们对原始数据表达的信息产生误解 以
, 。
版
图像的有损压缩为例 图像的有损压缩是在较小地损失图
,
像质量的情况下 对图像文件中相同或相似的数据进行大
,
量压缩 使得生成的文件更小 如图124所示 这种技术
, , . 。
社
在一定程度上损害了图像的原始质量 也就是丢掉了一些
,
数据的信息 同一张图像 保存为不同的格式时 其数据
。 , ,
量的差别可能会非常大 例如 分别使用 和 格
。 , TIF JPEG
式生成的文件 大小有时会相差几十倍 常见的图像 音
, 。 、
频 视频有损压缩格式分别是 图像数据压缩格式
、 JPEG( )、
3 音频数据压缩格式 视频数据压缩格
图1.24 图像文件的有损压缩示例 MP ( )、MPEG(
式 等
) 。
24 数据与计算作业练习
1. 一个7位二进制数 如果其最高位和最低位都为 1则用十进制
华 , ,
表示该二进制数 其最大值可能是 最小值可能是
, ,
。
2. 小申同学录制了一个时长1分钟的音频文件 他准备将这个文件
,
传输至个东人在线学习空间 该文件采用的是 WAV格式 文件采样频率
。 ,
是44.1kHz量化位数为16位 双声道 请计算该文件在个人在线学习
, , 。
空间中占用的存储容量
。
3. 小申和同学们在小组活动中设计了本小组的 LOGO 如图 1.25 图1.25 小组的LOGO
师
,
所示 他们用2位二进制数来表示图中的颜色 并对图中的颜色进行了
。 ,
编码 从而将本小组的LOGO表示为一串二进制数 其中第 4行的编码
, ,
为0101010110000010
。
1 用2位二进制数表示颜色 最多可以表示 种颜色 根
范
() , 。
据上述编码 图中蓝色色块的二进制编码应表示为 红色色块
, ;
的二进制编码应表示为 第6行的编码为 H
; 。
2 请在图1.26中设计自己的LOGO 并涂上相应的颜色 然后对
() , 。
大
使用的颜色进行二进制编码 并说明编码规则
图1.26 我的LOGO
, 。
知 识 延 伸 学图像隐写术
图像作为信息的一种表现方式 其版权问题一直备受关注 通常 很多图像都会被加上水印来标明版
, 。 ,
权 防止盗版 这种方式的确能够在一定程度上减少图像被盗版滥用的情况 但会对图像的美观造成一定的
, 。 出,
影响 也不利于对图像进行再处理 目前除了显式的添加水印的方式 还可以采用数字图像隐写的方式 将
, 。 , ,
版权信息隐藏在图像中 使其能够被检测 隐写术是一门关于信息隐藏的技巧与科学 所谓信息隐藏是指不
, 。 ,
让除预期的接收者之外的任何人知晓信息的传递事件或信息的内容 数字图像隐写术的应用十分广泛
。 。
例如 一个24位位图图像中的每个像素的三原色 红 绿和蓝版各使用8比特来表示 仅考虑红色的
: ( 、 ) 。
情况下 就可以用 28个不同的数值
,
来 表 示 深 浅 不 同 的 红 色 以
。
11111111和11111110这两个数值
社
所表示的红色为例 它们对人眼来说
,
几乎是无法进行区分的 因此 所有
。 ,
的最低有效位 通常指右起最低位
( )
就可以被用来存储颜色以外的某些
信息 如图 1.27所示 如果对绿色
, 。
和蓝色进行同样处理的话 则可以在
,
图1.27 图像隐写术
三个像素中存储一个字节的信息
。
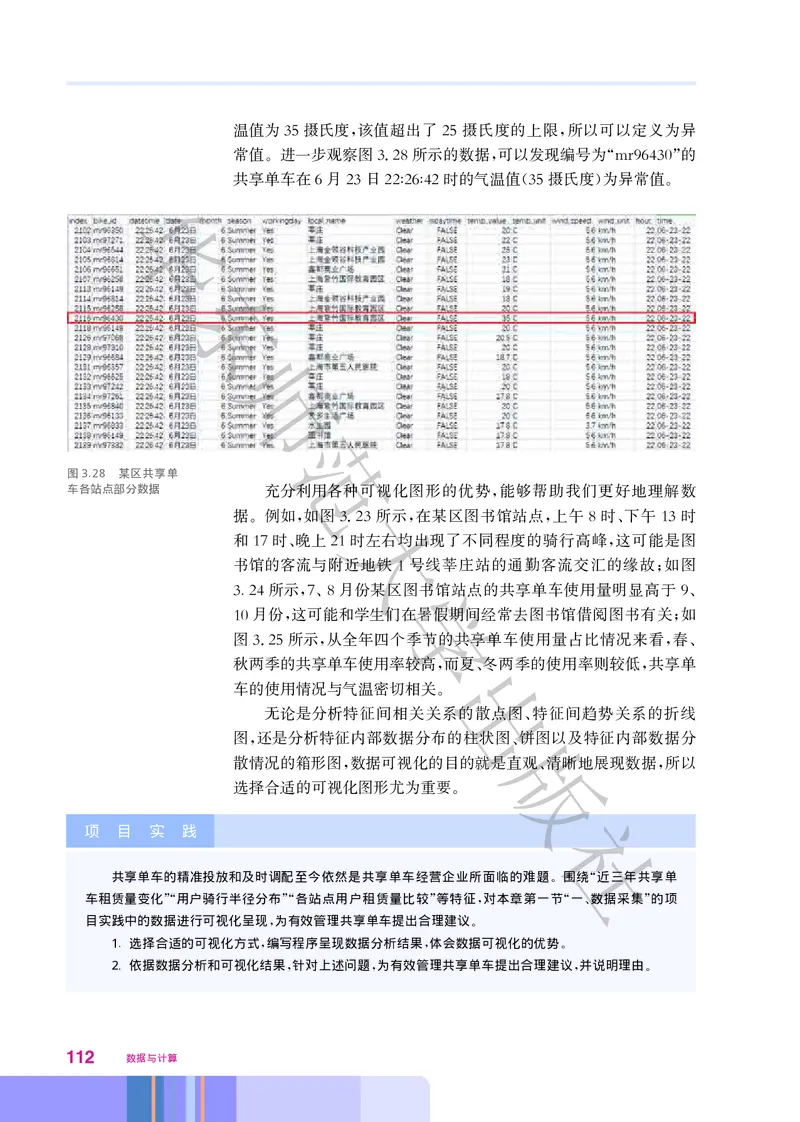
第一章 数据与大数据 25第三节 大数据及其作用与价值
信息技术的快速发展与广泛应用加速了数据总量的增长 公共
。
华
场所的安保监测系统在实时监测过程中会产生数据 人们在使用城市
;
公共交通的刷卡付费系统时也会产生数据 人们在利用各种网络社交
;
工具进行互动交流时同样会产生数据 这些数据的规模呈现指数级数
。
东
增长 人类进入了大数据时代 大数据已成为社会的一项重要资源
, 。 。
体 验 思 考
师
小申在电子图书网站上查看电子图书的信息时 发现网站上会立即显示 搜索此图书的人还在搜索的
, “
图书 或 给您推荐的图书 等信息 这些信息还会根据小申搜索图书情况的变化而持续更新 如图 1.28
” “ ” , ,
所示 范
。
大
学
出
版
社
图1.28 推荐的图书信息
思考:
1. 电子图书网站向小申推荐图书的依据是什么?
2. 举例说明,日常生活中还有哪些场景具有类似的智能推荐功能。
26 数据与计算一、 理解大数据
华
信息技术的快速发展改变着人们对数据的采集 分析与使用方
、
式 依托移动互联网 人们可以更便捷地访问网络 从
。 , ,
而大量地产生和传输数据 通过传感技术 人们可以不
; ,
东
间断地采集数据 这些数据规模巨大 格式多样 已经
。 、 ,
很难用传统的方式进行处理 于是 大数据技术应运而
。 ,
生 人们通过对这些数据进行分析 挖掘 从而发现和应
, 、 ,
师 用其蕴藏的价值
。
大数据也是数据 通常 大数据具有海量的数据规
。 ,
模 多样的数据类型 快速的数据流转和价值密度低四
图1.29 大数据的特征 、 、
范大特征 如图129所示
, . 。
1. 数据规模大
大
借助可穿戴设备 物联网和云计算等技术 人们的行为和物体的
、 ,
运行轨迹可以被采集和保存 形成大规模数据 以出租车定位系统中
, 。
的数据为例 某市出租车公司的出租车通常每隔10秒钟会自动向总
, 学
部的服务器发送一条数据 记录自己所在的经纬度 车速 车上是否有
, 、 、
乘客 行驶方向等信息 那么 按照该市大约有5万余辆在运营出租
、 。 ,
车计算 一天产生的定位数据就大概有4亿余条 今天的数据已经从
, 出 。
级别跃升为 级别
TB PB 。
2. 数据类型多
版
网络时代 数据的种类越来越多样 从二维表格表示的关系数据
, , ,
扩展为文本数据 网络日志 音频 视频 图片 地理位置信息等等 大
、 、 、 、 、 。
数据技术的发展不仅为快速处理海量数据社提供了支持 也为处理不同
,
来源 不同格式的多元化 多维度数据提供了可能
、 、 。
3. 处理速度快
大数据的 快 表现在多个层面上 它既包括数据产生得快 也要
“ ” , ,
求数据处理得快 海量 多样的数据快速处理对数据处理的速度提出
。 、
了更高的要求 过去 需要几天或更多时间处理的数据 现在可能要
。 , ,
第一章 数据与大数据 27在几分钟之内完成处理 以衡量大数据领域计算实力的100 数据
。 TB
的排序速度为例 目前人们已经能够在百秒内完成对100 数据的
, TB
排序
。
华
4. 价值密度低
东
大数据是有价值的 价值密度的高低与数据总量的大小几乎
,
成反比 大量的不相关数据 不经过处理则价值较低 属于价值密
。 , ,
度低的数据 以安全监控视频为例 一部连续1小时不间断的监
。 ,
师控视频中 有用的视频数据可能仅有一两秒 如何对大数据进行
, 。
分析 获得有价值的信息 已成为目前大数据背景下亟待解决的
, ,
问题
。
与范传统数据相比 大数据在数据规模 采集方式 分析方法 价值
, 、 、 、
利用等方面都有了很大的发展 影响着我们每个人的生活与学习 例
, 。
如 人们对网络用户的搜索请求及交互数据进行分析 建立用户行为
, ,
模型 为用户提供个性化智能搜索和内容推荐
大
, 。
二、 大数据处理过程
学
网络时代 每天来自商业 社会 科学 工程 医学以及日常生活等
, 、 、 、 、
方方面面的数据 不断存储到我们的计算机和各种存储设备中 面对
, 。
海量数据 人们利用技术方法 经过整合 归纳与评估 提取出有价值
, ,出、 ,
的信息 为用户的决策提供依据
, 。
计算机与网络技术的快速发展使得数据处理方式发生了巨大
的变化 数据的处理效率得到了极大的提高 借助信息技术 可以
, 。 ,
版
对人的在线行为进行记录 也可以对社会中的各种事物进行记录
, ,
通过大数据分析 更好地做出预测和决策 一般而言 大数据处理
, 。 ,
可分为四个步骤 数据采集 数据预处理 数据分析和数据挖掘
: 、 、
社
应用
。
项 目 实 践
如图1.30所示 使用不同的电子图书阅读平台 网站或移动应用程序 观察这些电子图书阅读平台是
, ( ),
否具有智能推荐功能 尝试查询图书 阅读图书 收藏图书 观察平台推荐的图书是否随之发生变化 判断
。 、 、 , ,
平台是依据读者的哪些行为推荐图书的 并填写表1.4
, 。
28 数据与计算华
东
图1.30 某电子图书阅读平台的图书推荐
师
表1.4 电子图书阅读平台智能推荐功能分析表
电子图书平台 图书推荐 读者行为及其影响 图书推荐依据
读者收藏电子图书后 平台推荐图书
××阅读平台 读过还读 , 读者收藏的图书
范发生变化
大
1. 数据采集
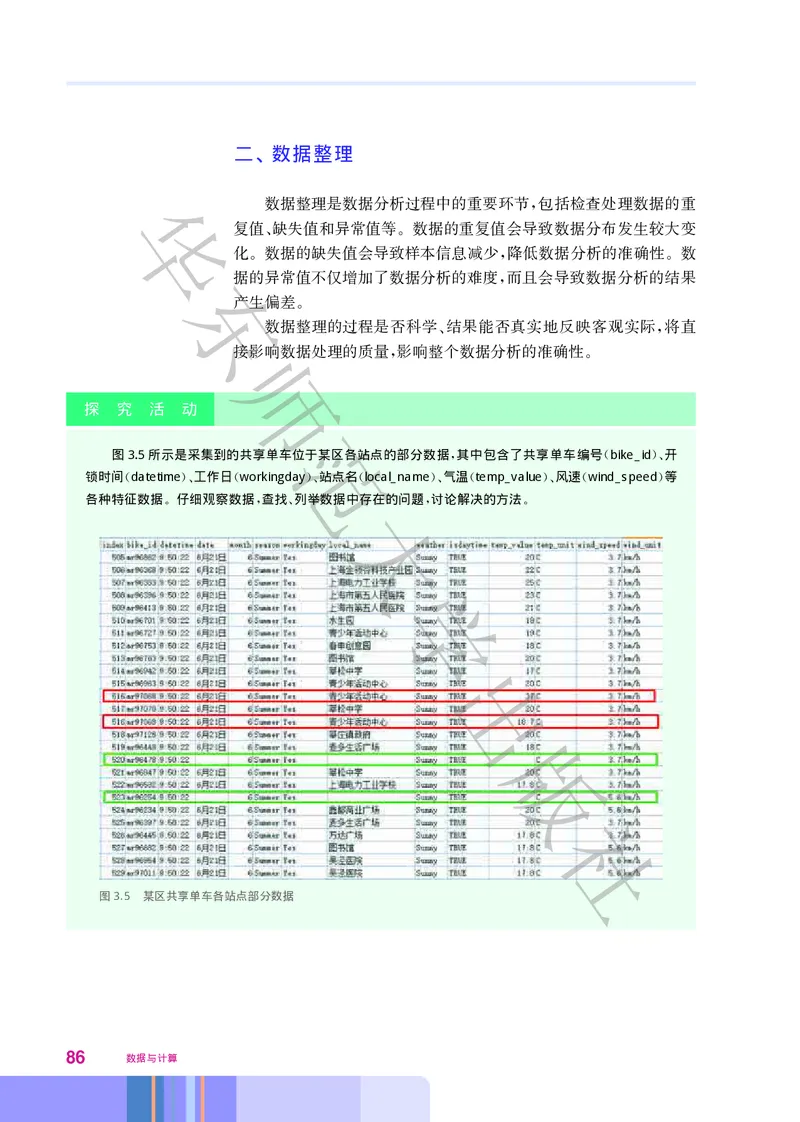
学
大数据的采集是大数据处理过程中的最初环节 它可以通过射频
,
识别技术 传感器技术 社交网络媒体等方式 获得各种类型
(RFID)、 、 ,
的海量数据 例如 随处可见的共享单车就是通过
。 ,
出
智能锁中的通信模块和用户身份识别卡 将
(SIM),
单车的通信连接状态 车锁状态 使用记录等数据
、 、 ,
通过网络上传到共享单车的服务平台上 而有 掌
。 “
版
上实验室 之称的手持实验技术 如图131所示
” ( . )
应用中 通过采集与传感设备把外界环境中的某
,
个物理量的变化以模拟信号输出 再经过模拟数
,
字转换装置进行转换 社得到实验数据后 可上传至
, ,
图1.31 部分手持实验技术仪器
云端存储起来 以备实验分析和处理用
, 。
2. 数据预处理
大数据采集过程中通常有一个或多个数据源 所采集的数据易受
,
到噪声数据 数据缺失 数据冲突等影响 因此 需要对采集的数据进
、 、 。 ,
行预处理 以保证大数据分析与预测结果的准确性与价值 例如 出
, 。 ,
第一章 数据与大数据 29租车在运营过程中 可能会由于高层建筑物遮挡 驶入地下隧道以及
, 、
出租车本身的定位系统装置故障等原因 导致出租车定位数据缺失
, 。
此外 由于数据采集设备的不稳定或者司机的误操作 会导致两条或
, ,
华
多条记录重复 对于这样的重复数据 就需要进行合并或删除操作
。 , 。
预处理后的出租车轨迹数据如图132所示
. 。
东
师
范
大
图1.32 预处理后的出租车轨迹数据示例
学
3. 数据分析
出
数据分析是大数据处理中的关键环节 根据大数据应用情境与
。
决策需求 选择合适的数据分析技术 提高大数据分析结果的可用性
, , 、
准确性和价值 这个过程的主要特点就是目的清晰 按照一定的规则
。 ,
进行处理 才能得到有效分析 例如 在版获得出租车的运行数据后 可
, 。 , ,
以进一步得到出租车每一次载客运营的起点和终点以及相应的时间
,
进而得到人们在工作日各个时间段的出租车用车情况 如图133所
。 .
图1.33 乘客出行时段与 示 在000 600 出租车用车数量较少 在120社0 1800 红色区域表
地区热力 图 , ~ , ; ~ ,
示出租车用车数量较多
。
4. 数据挖掘应用
经过数据分析 可以描述出事物的变化状况 找出其中的规律 将
, , ,
分析结果运用到实践中 例如 根据时段与地区的出行热力图 实时
。 , ,
分析旅游景点 居民区 学校 商业区等地区的人流量变化 调整社会
、 、 、 ,
30 数据与计算安保人员 保持良好的社会秩序
, 。
大数据处理一般需要经历上述四个步骤 在具体实施时 其
。 ,
中的细节 工具的使用 数据的完整性等还需要结合具体需求 行
、 、 、
华
业特点和整个时代的变化而不断变化更新 才能符合大数据时代
,
的特点
。
东
三、 大数据的作用及社会影响
互联网产生的海量数据汇同强大的计算技术 使大数据发挥着越
,
师
来越重要的作用 人们利用算法对收集到的庞大数据进行分析处理
。 ,
找到数据之间的关联性 并匹配出某些结果或现象 从而找寻到某种
, ,
相关性 用于调整和制订后续的各种策略 大数据与人工智能技术的
, 。
紧范密结合 帮助人们从数据中获取更准确 更深层次的信息 挖掘出数
, 、 ,
据背后的价值 催生出新业态和新模式
, 。
大
探 究 活 动
小申在学校图书馆的志愿服务活动中 常常会遇到同学提出这样的要求 能否推荐一本适合自己阅
, :“
读的书籍 学
?”
1. 如果你是小申 在推荐书籍的时候 会考虑哪些因素 需要哪些数据
, , , ?
2. 学校准备在不久的将来 建设数字图书馆 请参考志愿者向读者推荐图书的过程 帮助设计数字图
, 。 ,
书馆的电子图书推荐方案
。 出
1. 大数据的作用 版
大数据可以反映社会现象 借助大数据 能够反映出人们的意
。 ,
图 情感 观点和需求 这些情感因素会决定人们在决策或行动时所采
社
、 、 ,
取的方式和所选择的方法 例如 通过搜索引擎中的检索数据 可以
。 , ,
分析和了解人们的浏览习惯 通过购物网站中的数据 可以了解人们
; ,
的购物喜好 通过微博等平台中的数据 可以了解人们对某一问题的
; ,
评判 通过信息技术实时分析数据 可以反映出社会现象
; , 。
大数据可以预测发展趋势 在大数据分析过程中 通过分析不同
。 ,
类型数据的相互关联 描述数据的动态变化 就可以比较清晰地展示
, ,
事件的脉络关系 预测其发展趋势 例如 基于用户和车辆的 基
, 。 , LBS(
第一章 数据与大数据 31于位置的服务 定位数据 分析人车出行的个体和群体
) ,
特征 进行交通行为的预测 如图134所示 交通部
, , . 。
门可以预测不同时间不同道路的车流量 进行车辆智
,
华
能调度 用户则可以根据预测结果选择拥堵概率更低
,
的道路
。
大数据可以指导决策的制订 通过大数据技术
。 ,
东
人们可以获得所希望的数据 并能得到与之相关联的
,
分析结果 从而能更全面地认识事物的特征及发展趋
,
势 为行动决策奠定基础 例如 在社会治安方面 警
, 。 , ,
师方通过 案件数据分析和趋势预测系统 中的各类数
“ ”
图1.34 大数据与交通 据 预测未来某时段 某区域可能发生治安问题的概率
, 、
及类型 作为警力布置和安全防范的决策 从过去 被
, , “
动围着范案件转 发展为 前瞻性地巡逻防控
” “ ”。
2. 大数据对社会发展的影响
大
随着互联网的发展 大数据已经渗透到很多行业 成为重要的生
, ,
产要素 并通过各行各业的不断创新 逐步为人类创造更多的价值和
, ,
财富
。 学
大数据技术优化社会管理模式 政府部门
。
通过分析社会中各领域的大数据 可以改善城
,
市生活 提升城市管理水平 促进智慧城市的建
,出,
设 例如 由于出租车和公交车都服务于中长
。 ,
距离的居民出行 在人们的出行选择中互相替
,
代的可能性较高 因此 科学家利用出租车运营
, ,
版
系统来获取城市居民出行的起点和终点 经过
、
的路线等数据 分析城市居民出行的交通需求
, ,
对城市公交线路网进行优化 提升城市公交运
,
社
行效率 如图135所示
, . 。
大数据技术创新提升服务质量 通过分析
。
用户的消费数据 商家可以有指向性地向用户
,
推送商品 例如 商业网站记录用户在网站中
。 ,
图1.35 大数据技术提升城市公交运行效率
的搜索 浏览 购买 点评等在线行为数据 通过
、 、 、 ,
分析这些数据 了解用户的购物习惯 判断用户
, ,
的购物喜好 以此为依据进行个性化商品推送 实现个性化服务
, , 。
32 数据与计算大数据技术成为科学研究的新途径 借助
。
对大数据的分析研究 能够发现医学 物理 经
, 、 、
济和社会等领域的新现象 揭示自然与社会中
,
华
的新规律 并预测未来趋势 如图136所示
, , . 。
正在兴起的环境应用科学 基于全球数据共享
、
的天文观测 下一代传感器网络与地球科学等
、 ,
东
都是正在快速成长和发展的交叉学科方向 也
,
是大数据在科学研究和发现中的新应用
。
随着大数据技术的广泛应用 大数据技术
,
图1.36 大数据技术助力科学研究
师 已经渗透社会的很多领域 许多国家先后将大
。
数据研究提升到国家战略层面 我国也充分认
。
识到大数据时代带来的重大机遇 部署了一系列与大数据研究紧密相
,
关范的科研计划 大数据已经成为关系国家经济发展 社会安全和科技
。 、
进步的重要战略资源
。
通过对大数据的挖掘以及对分析结果的应
用 在给生活带来便利的同时 也可能会引发一
大
, ,
些新的社会问题 随着指纹识别 人脸识别等
。 、
技术的应用 人们开始关注指纹 虹膜 面容等
, 、 、
个人生物信息的所有权问题 如图137所示
学 , . 。
如何避免因生物信息被搜集可能带来的个人隐
私泄露 数据窃取 网络欺诈等问题 甚至还曾
、 、 ?
有网络不法分子通过收集电子邮件 微博 电子
出 、 、
商务等数据 利用大数据技术向所搜索的目标
,
发起精准攻击 因此 我们在学习利用大数据
图1.37 指纹识别技术 。 ,
预测并做出决策的方法时 也要掌握特定的防
,
版
护措施 加强数据安全意识
, 。
作业练习
社
1. 在日常出行中 越来越多的人开始使用电子地图进行导航 电子地
, 。
图在GPS导航系统的支持下 能够较为准确地显示行进的路线和路况 并能
, ,
实时地进行调整 请分析为什么GPS导航系统能根据路况实时调整行进的
。
路线 它又是如何知道路况变化情况的呢
? ?
2. 结合个人网络学习体验 如慕课学习 在线课程等 从学习诊断 资
( 、 ), 、
源推送 过程管理等方面 思考大数据是如何支持个性化学习的
、 , 。
第一章 数据与大数据 33知 识 延 伸 用户画像
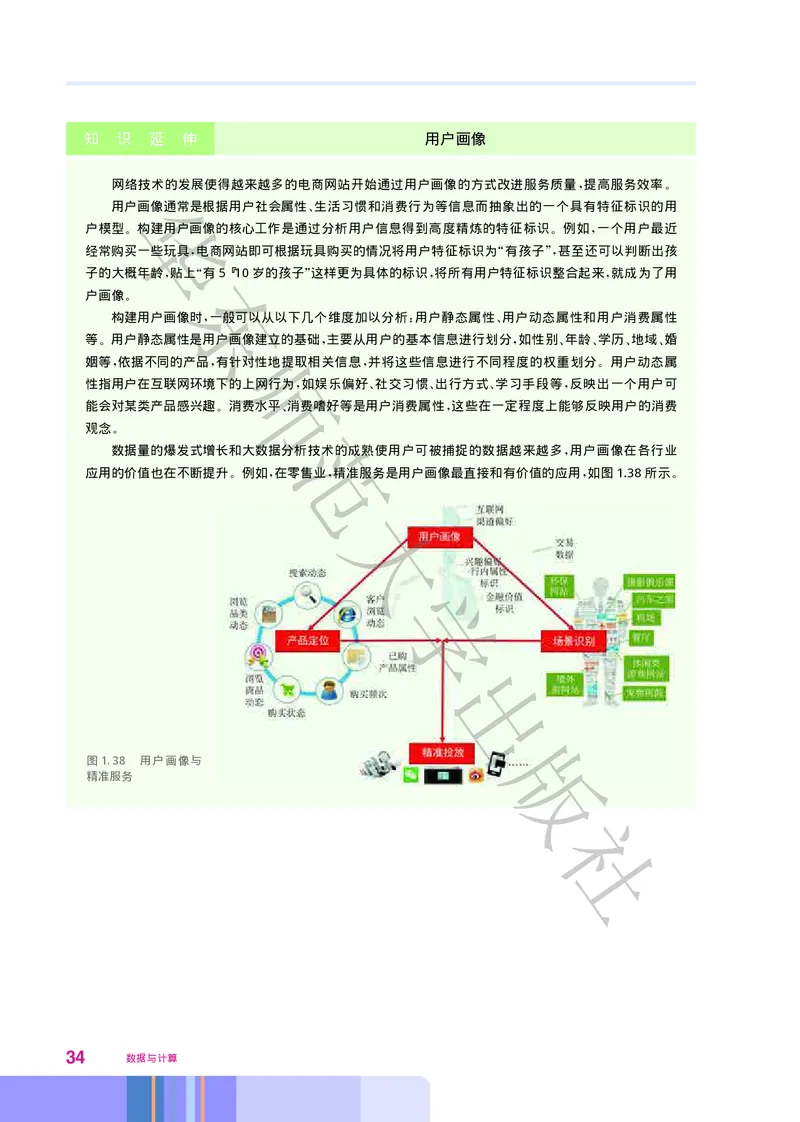
网络技术的发展使得越来越多的电商网站开始通过用户画像的方式改进服务质量 提高服务效率
华 , 。
用户画像通常是根据用户社会属性 生活习惯和消费行为等信息而抽象出的一个具有特征标识的用
、
户模型 构建用户画像的核心工作是通过分析用户信息得到高度精炼的特征标识 例如 一个用户最近
。 。 ,
经常购买一些玩具 电商网站即可根据玩具购买的情况将用户特征标识为 有孩子 甚至还可以判断出孩
, “ ”,
子的大概年龄 东贴上 有5~10岁的孩子 这样更为具体的标识 将所有用户特征标识整合起来 就成为了用
, “ ” , ,
户画像
。
构建用户画像时 一般可以从以下几个维度加以分析 用户静态属性 用户动态属性和用户消费属性
, : 、
等 用户静态属性是用户画像建立的基础 主要从用户的基本信息进行划分 如性别 年龄 学历 地域 婚
。 师, , 、 、 、 、
姻等 依据不同的产品 有针对性地提取相关信息 并将这些信息进行不同程度的权重划分 用户动态属
, , , 。
性指用户在互联网环境下的上网行为 如娱乐偏好 社交习惯 出行方式 学习手段等 反映出一个用户可
, 、 、 、 ,
能会对某类产品感兴趣 消费水平 消费嗜好等是用户消费属性 这些在一定程度上能够反映用户的消费
。 、 ,
观念 范
。
数据量的爆发式增长和大数据分析技术的成熟使用户可被捕捉的数据越来越多 用户画像在各行业
,
应用的价值也在不断提升 例如 在零售业 精准服务是用户画像最直接和有价值的应用 如图1.38所示
。 , , , 。
大
学
出
版
图1.38 用户画像与
精准服务
社
34 数据与计算华
东
师
范
第 二 章
大
学
算法与程序实现
出
版
本章学习目标
社
理解算法的概念和特征 运用恰当的描述方法和控制结构表示简单算
◉ ,
法 认识算法在问题解决中所起的作用
, 。
掌握一种程序设计语言的基本知识 并使用程序设计语言编写程序解决
◉ ,
简单问题 掌握运行和调试程序的方法
, 。
体验编程解决问题的一般过程 认识问题解决过程中不同算法的效率
◉ , ,
学会选择恰当的算法进行求解
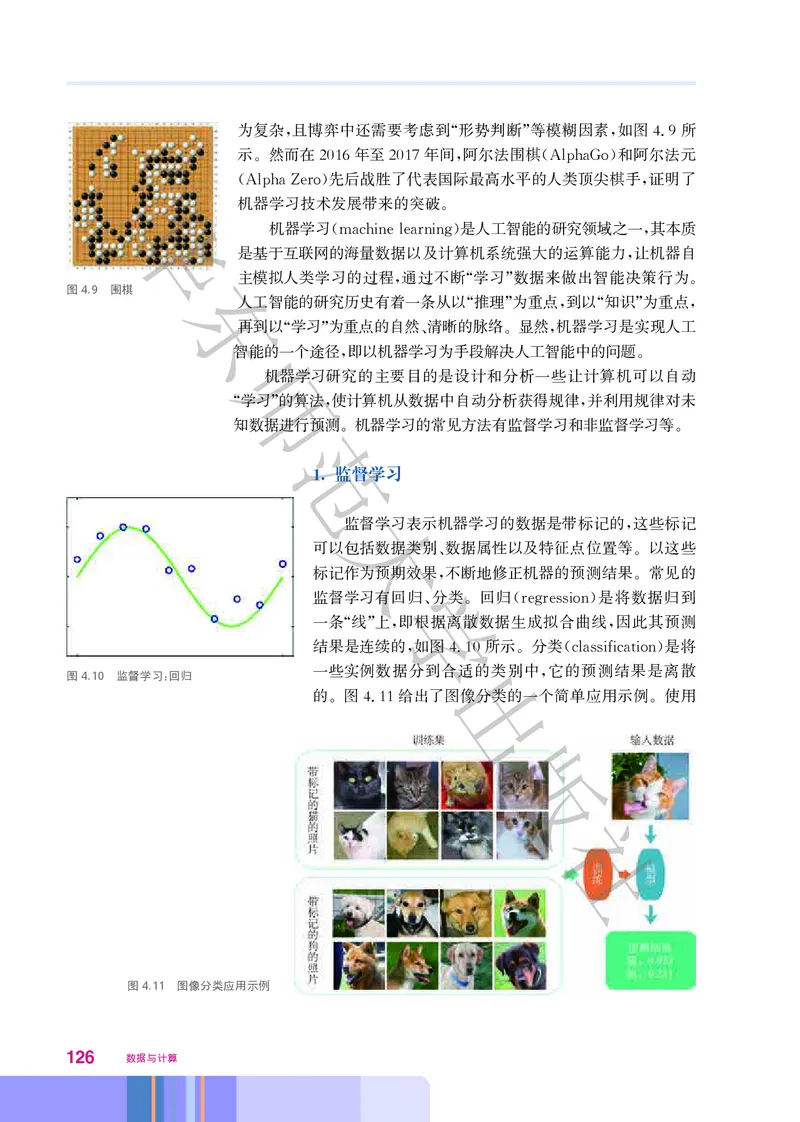
。算法非常古老 它的诞生早于计算机数千年 但它的神奇之处就在于它存在于我们生活中
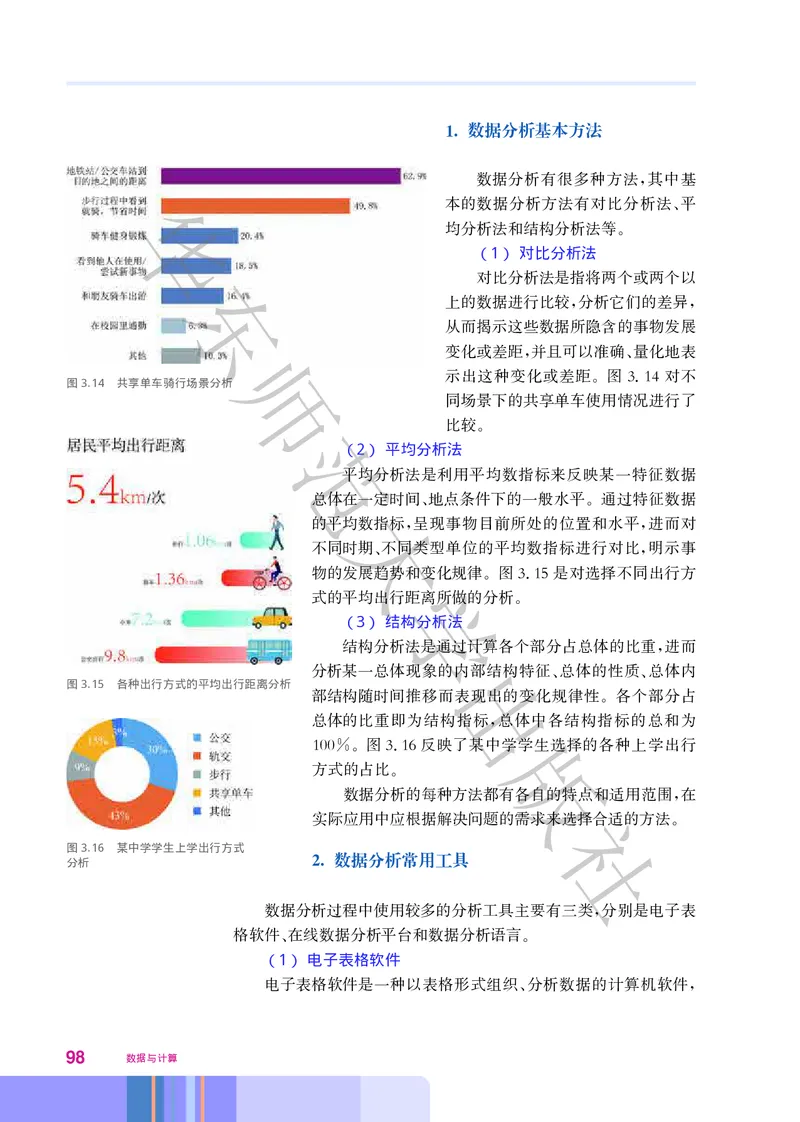
, ,
的各个角落 并使得我们的生活更加轻松 美好 比如 最大公约数算法可用于铺地砖时的砖
, 、 。 ,
块规格选择 最短路径算法可用于公共交通网络规划 人脸识别算法广泛用于数码相机拍照时
华; ;
的人脸捕捉 启发式算法可用于机场决定飞机的起飞顺序 匹配算法可用于器官移植配对
; ; ……
算法无处不在
!
随着信息技东术的发展 人们使用程序设计语言对各种算法进行了程序实现 并将程序安装
, ,
在不同的数字化设备上 当我们使用这些设备来解决生活中的各类问题时 就更加便捷了 面
, , 。
对同一问题 往往可以使用多种不同的算法 算法的效率则又会影响到程序的效率和问题的解
, ,
师
决 因此 如何选择合适的算法来解决实际问题 也是解决问题过程中至关重要的一步
。 , , 。
范
本章知识结构
大
学
出
版
社
36 数据与计算项目主题 编程应用助健康
华
项·目·情·境
要保持健康的身体 就离不开科学 规律的运动 进入智能时代后 以物联网
, 、 。 , 、
东
云计算 大数据为特征的智能运动环境正改变着人们的运动方式
、 。
小申是一名运动爱好者 这学期学校健身中心更新了一批跑步机 他和同学就
, ,
经常在体育活动课上去锻炼 他们发现在跑步机上可以选择不同的跑步预设模
。
式 在不同的模式下 跑步机会动态调节运行速度和坡度 跑步机上还有很多传感
师
, , ;
设备 可以在运动过程中实时监测运动者的各种身体数据 他们都很疑惑 跑步机
, 。 :
是如何实现这些功能的呢
?
范
项·目·任·务
大
任务1 任务2 任务3
学习智能跑步
学
机 学习使用 Python 使用常用算法,设
中预设跑步模式的算 程序实现身体质量指 计跑步训练课程报表,
法,理解算法的特征, 数的计算、显示和简单 并描述完成这些信息
设计并完成跑步机其 统计,查阅资料并完成 统计所选择的算法和
出
他预设模式的算法 卡路里的计算、显示和 理由。
描述。 统计等各项任务。
版
社
第二章 算法与程序实现 37第一节 算法与算法描述
在实际生活中 人们一直都在寻求有效的问题解决方法 例如
, 。 ,
华
做饭时 如何在做完一桌饭菜后 还能保证饭 菜 汤都有一个合适的
, , 、 、
温度 旅游时 如何规划旅行路线 以确保在有限的时间和预算内使行
; , ,
程的性价比最高 如何设置有效的电梯调度方案 以确保乘客等待的
; ,
东
总时间最短 对问题解决的思考在生活中比比皆是 当这些解决问
…… ,
题的步骤被人们描述并记录下来之后 就成为了可以重复执行的 用
, 、
来解决一类问题的算法
。
师
体 验 思 考
范
由于城市中的人口
密集度高 在有限的空间
,
内进行锻炼成为了大部
分人的不二选择 所以智
, 大
能跑步机逐渐成为了人
们家庭中常备的运动器
材 为了满足不同人群
。
学
的锻炼需求 提高锻炼效
,
果 常见的家用智能跑步
,
机可以提供多种预设模
式选择的功能 例如 心
出
, “
率跑 坡度跑 等 如图
”“ ” , 图2.1 某智能跑步机
2.1所示
。
思考:
版
1. 智能跑步机是如何根据用户选择的跑步模式,控制用户的具体跑步过程的?
2. 当设定为某种跑步模式时,跑步机又是如何根据不同的人和实时运动的情况进行调节,从
而使人获得最佳运动效果的?
社
一、 认识算法
信息时代 日益先进的采集设备和存储技术记录着人们每天产生
,
的大量数据 人们对于各种应用需求的类型和难度也逐渐增加 无论
, ,
是三维图形生成 海量数据处理 机器学习 还是图像识别等 都需要
、 、 , ,
38 数据与计算靠算法来解决
。
探 究 活 动
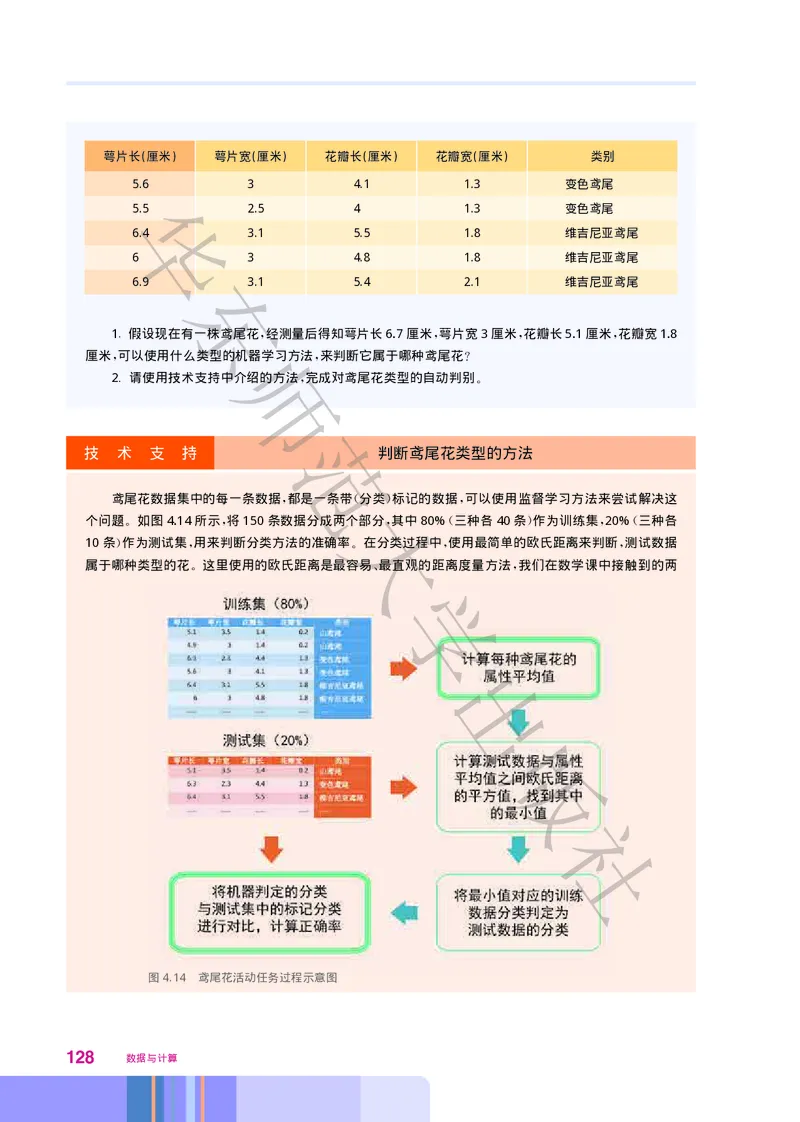
智能跑步机能够为用户提供多种预设的跑步模式 会根据用户的选择和用户输入的跑步参数(包括年
,
龄 体重 跑步时长等)控制跑步机的机电设备运转 以某款智能跑步机为例 当用户开机并选择 心率跑
、 、 , 。 , “ ”
(即用心率来指导跑步训练 在特定的心率下进行训练来提高心肺能力)模式后 跑步机运转过程描述如下
, , :
第二章 算法与程序实现
华
东
直接选择预设值 或是等待用户输入个人体重、跑步时长、年龄、跑步时速等
①
计算并显示目标心率
②
师
倒计时3秒 然后提示用户开始跑步
③
给电机发送信号 启动跑带 运转至设定的跑步时速
④
在跑步过程中监测当前心率 如果当前心率不在目标心率的浮动范围内 则调节跑带坡度 直至
⑤
当前心率稳定在目标心率的浮动范围内
范
判定是否达到设定的跑步时长 如未达到 则继续监测当前心率 否则给电机发送信号 逐渐降低
⑥
跑带运转速度至停止
结束本次跑步。
⑦ 大
请仔细阅读以上关于 心率跑 模式的说明 思考以下问题
“ ” , :
1. 上述描述是否存在不够明确的地方 请罗列出来
? 。
2. 描述中有一项为 选择预设值 请解释一下此处 预设值 的含义和作用
“ ”, “ ” 。
学
1. 算法的概念 出
算法在生活中是普遍存在的 广义地讲 算法是在有限步骤内求
, ,
解某一问题所使用的步骤和方法版例如 在炒菜时 先放什么 后放什
。 , , ,
么 这也有一定的顺序和方法 这种顺序和方法我们称之为炒菜的算
, ,
法 在做数学题时 每一道题都有对应的具体计算方法和步骤 可以称
; , ,
之为这道题的解题算法 使用跑步机跑步社时 跑步机会根据用户的选
; ,
择执行不同的跑步模式 每种跑步模式对应一种算法
, 。
在计算机科学领域中 算法是一系列的计算步骤 用来将输入的
, ,
数据转换成输出的结果 借助于计算机处理的高效 自动化计算能
。 、
力 人们的很多算法思想已经变成现实 例如 将设计人员设计好的
, 。 ,
三维模型交给计算机来渲染 可以实现三维虚拟场景生成 将下棋的
, ;
规则和方法借助计算机来实现 可以实现人与计算机对弈 将人对图
, ;
片的识别和认识过程通过模型设计让计算机进行模拟 可以实现图像
,
39的自动识别等等
。
2. 算法的特征
华
算法是解决问题过程中 做什么 和 怎么做 的步骤的描述 一个
“ ” “ ” ,
算法必须满足有穷性 确定性 可行性 有零个或多个输入 有一个或
、 、 、 、
东
多个输出这五个特征
。
(1) 有穷性
算法必须是由有限个步骤组成 即算法一定要能够结束 例如
, 。 ,
师智能跑步机中预设的各种跑步模式的算法都可以完成并结束一次跑
步训练
。
(2) 确定性
算范法中的每一个步骤都应该是确定的 没有歧义的 模糊不清
、 。 、
模棱两可或带有二义性的描述都会影响算法的确定性 例如 智能跑
。 ,
步机检测用户当前心率是否在目标心率浮动范围内时 这个范围就必
,
须是明确的值 或者是可以通过输入值计算后得到的明确的值
大
, 。
(3) 可行性
算法的可行性就是指每一个步骤都可以被计算机执行 可以方便
,
地用来解决某一类问题
学。
(4) 有零个或多个输入
输入就是算法在执行时要从外部获取的数据 输入可以是多个
。
也可以是零个 零个输入并不代表这个算法没有输入数据 所需数据
, 出 ,
一般已包含在算法中 只是这个输入的数据没有直观地显现出来 例
, 。
如 智能跑步机在提醒用户开始跑步前会有3秒的倒计时 这个3秒
, ,
就是在算法中预设的值
。
版
(5) 有一个或多个输出
输出就是算法实现所得到的结果 是算法对输入的数据加工处理
,
后得到的 输出可以有一个或多个 没有输出的算法是没有意义的
。 , 。
社
例如 用户在智能跑步机上的实时心率显示就是一种输出 对跑带坡
, ;
度的调节也是一种输出
。
探 究 活 动
之前的 探究活动 中描述的智能跑步机 心率跑 模式的操作还不能够直接被跑步机执行 它并没有
“ ” “ ” ,
满足算法的特征 如 计算并显示目标心率 中并没有说明如何计算目标心率
, “ ” 。
40 数据与计算请结合算法的特征 针对已经找出的描述不够明确的方面 提出修改建议 并记录在表2.1中
, , , 。
表2.1 智能跑步机 心率跑 模式说明分析表
“ ”
序号 不符合算法特征的方面 修改建议
1
2
二、 算法的描述
算法的描述就是把解决问题的方法和步骤用规范的方式描述出
来 这种描述既可以作为程序设计人员编写代码的依据 又可以供算
。 ,
法研究 学习和交流之用 并不依赖于任何一种语言
、 , 。
探 究 活 动
之前的 探究活动 中描述的 心率跑 模式存在着一些不符合算法特征的地方 经过调整后的算法
“ ” “ ” ,
如下
:
第二章 算法与程序实现
华
东
师
范
大
学
出
初始化 个人体重 千克 weight=60 跑步时长 分time=60 年龄 岁age=30 跑步速度 千
①
米 时speed=6计时 分count=0
版
显示weight、t ime、 age、speed的预设值 并等待用户修改和确认
②
根据公式TargetHR=07 220-age 计算并显示目标心率TargetHR
③ *
倒计时3秒 显示 开始跑步
④
给电机发送 启动跑带运转 信号 启动跑带 运转速度达到speed 社
⑤
监测当前心率CurrentHR 如果CurrentHR TargetHR-5 则增大跑带坡度Angle 如果
⑥ <
CurrentHR TargetHR+5则减小跑带坡度Angle
>
计时count加1分钟
⑦
如果counttime则执行步骤 否则执行步骤
⑧ ≥ ⑨ ⑥
给电机发送 逐渐降低跑带运转速度 信号 直至跑带运转速度降至停止0千米 时
⑨
结束本次跑步。
⑩
41经过以上算法的学习后 请思考一下 以上算法描述有什么优缺点 除了这种描述方法之外 通常还
, , ? ,
有哪些其他的描述方法
?
华
算法的描述方法很多 其中主要有自然语言 流程图和伪代码
, 、
三种
东。
1. 自然语言
师
自然语言就是人们日常生活中使用的语言 用自然语言描述的
。
算法通俗易懂 但也有明显的不足
, :
用自然语言描述比较复杂的算法时 会显得很冗长 表述不够直
, ,
范
观 清晰 自然语言在描述上容易出现歧义 容易引起算法步骤的
、 。 ,
不确定性 尤其是在算法中存在较复杂的逻辑时 不易清晰地表示
, ,
出来
。
大
2. 流程图
流程图是由一些简学单的图形符号组成 用来表示问题解决的步骤
,
及顺序的方法 根据我国颁布的信息文件编制符号及约定标准
。
1526 89 常用的流程图符号如下
(GB ), :
出
起止框 表示算法的开始或结束
处理框 表示要处理的内容
版
输入 输出框 表示数据的输入或结果的输出
/
表示条件判断的情况 满足条件
社: ,
判断框 执行一条路径 不满足条件 则执
; ,
行另外一条路径
用于连接因页面不够而断开的流
连接符
程线
流程线 指出流程控制方向 即执行的次序
,
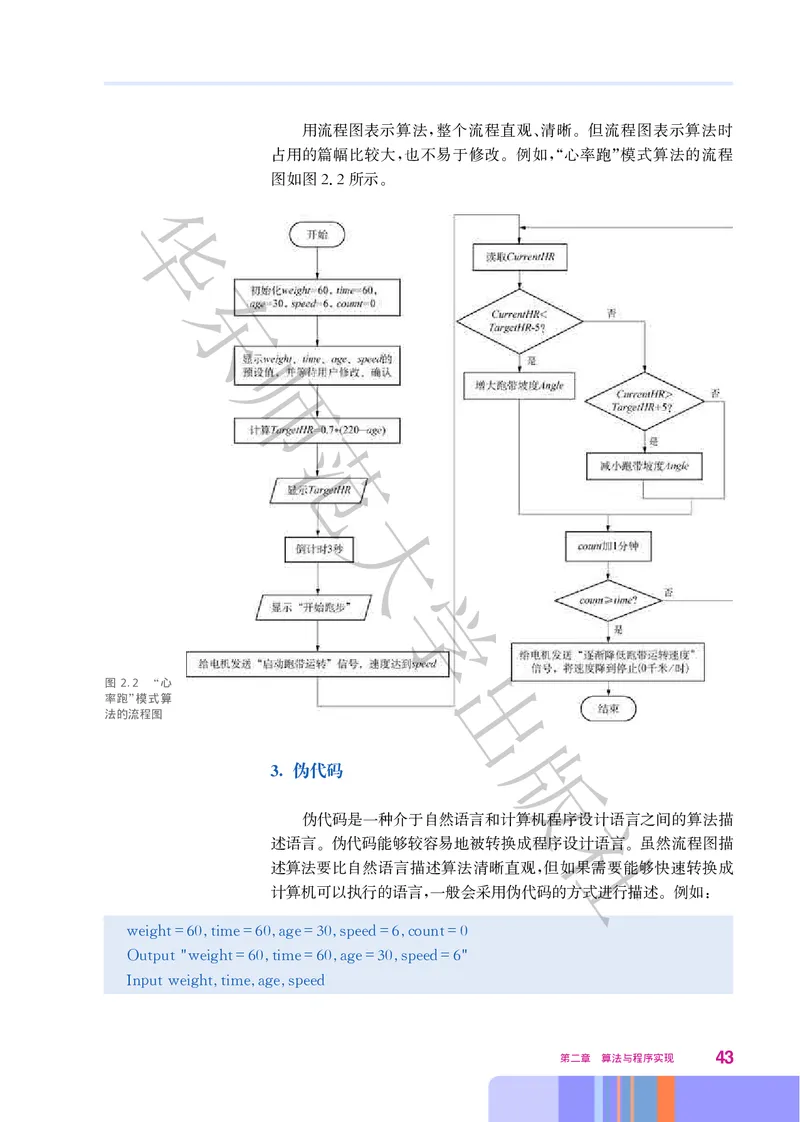
42 数据与计算用流程图表示算法 整个流程直观 清晰 但流程图表示算法时
, 、 。
占用的篇幅比较大 也不易于修改 例如 心率跑 模式算法的流程
, 。 ,“ ”
图如图22所示
. 。
图 2.2 心
“
率跑 模式算
”
法的流程图
3. 伪代码
伪代码是一种介于自然语言和计算机程序设计语言之间的算法描
述语言 伪代码能够较容易地被转换成程序设计语言 虽然流程图描
。 。
述算法要比自然语言描述算法清晰直观 但如果需要能够快速转换成
,
计算机可以执行的语言 一般会采用伪代码的方式进行描述 例如
, 。 :
第二章 算法与程序实现
华
东
师
范
大
学
出
版
社
=60 =60 =30 =6 =0
weight time age speed count
=60 =60 =30 =6
Output"weight time age speed "
Inputweight time age speed
43数据与计算
=07 220-
TargetHR * age
OutputTargetHR
倒计时3秒
华
开始跑步
Output" "
给电机发送 启动跑带运转 信号 直至跑带运转速度达到
speed
Repeat 东
读取当前心率值
CurrentHR
-5
IfCurrentHRTargetHR
减小跑带坡度
Angle
EndIf
加1分钟 范
count
=
Untilcount> time
给电机发送 逐渐降低跑带运转速度 信号 直至跑带运转速度降到停止 0千米 时
大
三、 算法的基本控制结构
学
顺序结构 分支结构和循环结构是用来描述算法的三种基本控制
、
结构 由这三种基本结构组成的算法结构清晰 易于正确性验证和
。 ,
纠错
。
出
图2.3 顺序结构示意图
1. 顺序结构
版
顺序结构是一种自上而下 按先后顺序依次执行算法中各个步骤
,
的结构 如图23所示 例如 某人的刷牙过程就可以用顺序结构表
, . 。 ,
示 如图24所示
, . 。
社
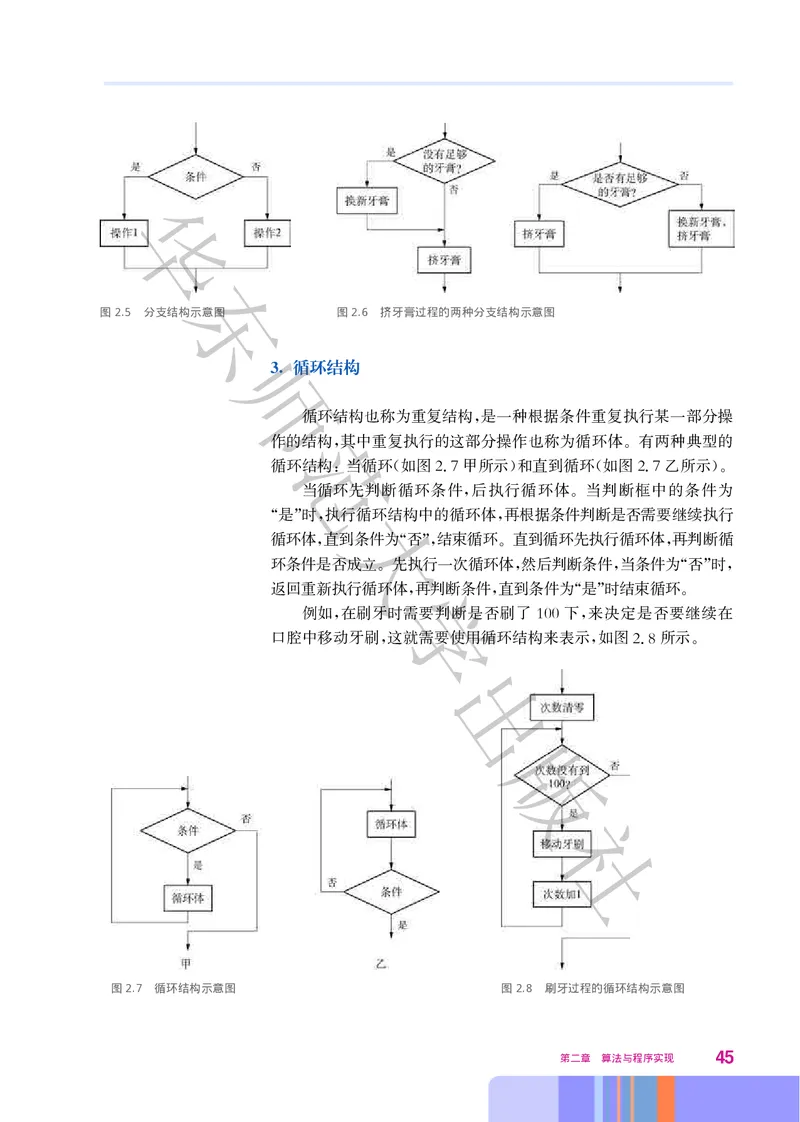
2. 分支结构
分支结构也称为选择结构 是根据给定的条件进行判断 再依据判
, ,
断结果的不同而执行不同操作的一种结构 分支结构流程图中一定会
。
有判断框 当满足条件时执行一个分支 不满足条件时执行另一个分
, ,
支 分支结构的流程图表示方法如图25所示 例如 挤牙膏时会判
。 . 。 ,
断是否有足够的牙膏 就可以使用分支结构来表示 如图26所示
图2.4 刷牙过程的顺序结
, , . 。
构示意图
44华
东
图2.5 分支结构示意图 图2.6 挤牙膏过程的两种分支结构示意图
师
3. 循环结构
循环结构也称为重复结构 是一种根据条件重复执行某一部分操
范 ,
作的结构 其中重复执行的这部分操作也称为循环体 有两种典型的
, 。
循环结构 当循环 如图27甲所示 和直到循环 如图27乙所示
: ( . ) ( . )。
当循环先判断循环条件 后执行循环体 当判断框中的条件为
大, 。
是 时 执行循环结构中的循环体 再根据条件判断是否需要继续执行
“ ” , ,
循环体 直到条件为 否 结束循环 直到循环先执行循环体 再判断循
, “ ”, 。 ,
环条件是否成立 先执行一次循环体 然后判断条件 当条件为 否 时
。 , , “ ” ,
学
返回重新执行循环体 再判断条件 直到条件为 是 时结束循环
, , “ ” 。
例如 在刷牙时需要判断是否刷了100下 来决定是否要继续在
, ,
口腔中移动牙刷 这就需要使用循环结构来表示 如图28所示
, , . 。
出
版
社
图2.7 循环结构示意图 图2.8 刷牙过程的循环结构示意图
第二章 算法与程序实现 45项 目 实 践
很多智能跑步机都提供了 坡度跑 模式供选择 坡度跑 也就是指跑步机会自动调节跑带的坡度 为
华 “ ” ,“ ” ,
用户模拟爬坡的情况 为了能够让用户得到科学 安全的跑步体验 在 坡度跑 模式中也需要考虑合理的
。 、 , “ ”
热身过程 锻炼过程和调整过程
、 。
1. 通过查询了解 坡度跑 模式 分析智能跑步机 坡度跑 模式的实现过程
“ ” , “ ” 。
2. 如果请东你来实现智能跑步机的 坡度跑 模式 该算法应如何设计
“ ” , ?
3. 请采用流程图的方式来描述 坡度跑 模式 想一想该算法需要包含哪些基本控制结构
“ ” , ?
师
四、 编程解决问题的过程
范
在生活中 我们经常会遇到各式各样的问题需要解决 而随着计
, ,
算机技术的发展 计算机在问题解决中已经成为越来越重要的角色
, 。
人们从一开始依赖计算机的高速运算能力 到目前无处不在的计算机
,
大
应用 计算机也在各类问题解决的过程中 从单一的计算发展成了全
, ,
过程的参与
。
当面对特定的问题时 往往需要根据设计的算法编写特定的程序
,
学
来解决问题 编程解决问题的一般过程包括 抽象与建模 设计算法
。 : 、 、
编写程序 调试运行这四个步骤 如图29所示 根据问题的需要 可
图2.9 编程解决问题
、 , . 。 ,
的一般过程 以反复修正和执行这四个步骤 直到问题得到有效解决
, 。
出
1. 抽象与建模
解决问题前 需要对问题进行深入版分析 明确问题的需求 然后
, , 。
分析问题的求解目标 约束条件等 将问题抽象化 模型化 抽象与建
、 , 、 。
模是指从现实问题出发 忽略非本质的细节 提炼出核心要素 将具体
, , ,
的问题抽象化 并将其描述成为一个明确已知条社件 约束条件和求解
, 、
目标的问题 再用数学符号来描述计算模型 人们每天都在不自觉地
, 。
使用抽象和建模 例如地铁线路图就是一种抽象 在图中并没有显示
, ,
所有的细节 而仅仅是提炼了路线 站点和换乘的信息 当人们在计
, 、 。
算地铁乘车费用时 则是通过已建立的计算模型 针对不同起点和终
, ,
点进行计算 获得对应的票价信息
, 。
以计算中国农历年份为例 在中国古代的历法中 甲 乙 丙 丁
, , 、 、 、 、
戊 己 庚 辛 壬 癸被称为 十天干 子 丑 寅 卯 辰 巳 午 未 申
、 、 、 、 、 “ ”, 、 、 、 、 、 、 、 、 、
46 数据与计算酉 戌 亥叫作 十二地支 十天干和十二地支依次相配 组成六十个
、 、 “ ”。 ,
基本单位 两者按固定的顺序互相配合 组成了干支纪年法 基于天
, , 。
干地支序列 如果已知2000年是庚辰年 则对于输入的公历年份2019
, ,
年 可以通过以下方法来推算其农历年份 天干地支列表为循环推算
, ( ,
即 癸 的后一个天干为 甲 亥 的后一个地支为 子
“ ” “ ”,“ ” “ ”):
天干 用2019减去2000 得到的差除以10取余后得到9 然后天
: , ,
干从 庚 向后推9位为 己
“ ” “ ”;
地支 用2019减去2000 得到的差除以12取余后得到7 然后地
: , ,
支从 辰 向后推7位为 亥
“ ” “ ”。
最后 可以推算出公历2019年是农历己亥年
, 。
因此 本问题可以抽象为已知天干 地支序列和对照的年份2000
, 、
庚辰年basey 对于输入的公历年份year 求出其对应的农历年份
, , 。
该问题的计算模型如下
:
天干 用year减去basey 得到的差除以10取余后得到余数 然
: , ,
后根据余数的数值 在已知天干列表中从 庚 向后推算相应位数
, “ ” ;
地支 用year减去basey 得到的差除以12取余后得到余数 然
: , ,
后根据余数的数值 在已知地支列表中从 辰 向后推算相应位数
, “ ” 。
2. 设计算法
在中国农历年份的计算中 我们可以选择现有的软件进行查询
, ,
也可以自己设计算法 编写程序来完成对用户输入年份的天干地支显
、
示 针对问题分析的结果 设计一个对应求解的算法 其关键步骤
。 , ,
如下
:
第二章 算法与程序实现
华
东
师
范
大
学
出
版
设定十天干、十二地支序列
①
设定对照年份2000年及其所对应的天干和地支
②
输入公历年份 year
③
根据计算模型计算该公历年份所对
社
应的天干
④
根据计算模型计算该公历年份所对应的地支
⑤
输出该公历年份对应的农历年份。
⑥
3. 编写程序
确定算法后 就可以使用计算机编程实现了 编写程序就是选择
, 。
47合适的计算机程序设计语言按照算法来实现问题求解 程序是一组
。
计算机能识别和运行的指令 是计算机执行算法的具体步骤的实现
, ,
计算机通过运行这些指令来完成预期的任务 根据中国农历年份的
。
求解算法 可以使用多种不同的程序设计语言来编程实现 以下为使
, ,
用 语言实现的程序
Python 。
数据与计算
华
= 甲 乙 丙 丁 戊 己 庚 辛 壬 癸
东
tian " " " " " " " " " " " " " " " " " " " "
= 子 丑 寅 卯 辰 巳 午 未 申 酉 戌 亥
di " " " " " " " " " " " " " " " " " " " " " " " "
=2000
师
basey
=6
basetian
=4
basedi
= 请输入年份
year int input " 范 "
+ - 10 10 = =
print tian basetian year basey % % sep "" end ""
+ - 12 12
print di basedi year basey % %
大
4. 调试运行
编写完成的程序需要进行调试运行 以验证所编写的程序是否正
学
,
确 在这个阶段 不仅在发现错误时需进行修改 还要对运行结果进
。 , ,
行分析和验证 根据调试结果不同 可能还需要重复前面的几个阶
。 ,
图2.10 计算中国农历年 段 进行问题的分析 算法的优化和程序的重新编写 如图210所示
份程序的 运行结果 , 、 出 。 .
是计算中国农历年份程序的运行结果
。
作业练习版
智能服药系统也是家庭健康系统中重要的一部分 可以针对 忘记服药
, “ ”
不按时服药 重复服药 等多种问题进行监测和提醒 现在请你设计一款
“ ”“ ” 社,
智能药盒
“ ”。
1. 请描述你设计的 智能药盒 的功能
“ ” 。
2. 针对某个功能进行算法设计 并用流程图方式进行描述
, 。
3. 智能药盒和大数据 物联网结合 又可以增加哪些功能 为生活提供
、 , ,
哪些便利
?
48知 识 延 伸 算法的效率
解决问题的算法往往不止一个 通常可以从时间和空间两个角度来对算法的效率进行评价 使用的
华 , 。
指标分别为时间复杂度和空间复杂度
。
1. 时间复杂度 用于描述算法运行所需要的时间开销 一般采用算法中基本语句的执行次数进行度
: ,
量 例如 要将一张纸等分成16个大小相等的格子 可以有多种算法 一种算法是以每次画一个格子的
。 , , 。
方式 画东16个格子将纸等分 如果画一个格子记为一次操作的话 那就需要16次 另一种算法是将纸折
, 。 , 。
起来 再折 再折 再折 经过4次操作后 打开就可以得到 16个格子了 显然 第二种算法所需要的执行
、 、 、 , , 。 ,
时间比第一种算法要少 也称为第二种算法的时间复杂度较小
, 。
2. 空间复杂度 用于描述算法运行所需要的存储空间 一般主要考虑临时占用的空间大小
师: , 。
范
大
学
出
版
社
第二章 算法与程序实现 49第二节 程序设计语言基本知识
当人们完成问题的抽象与建模 并通过各种方法和设备采集了大
,
华
量的数据 设计了解决问题的有效算法后 还需要相应的计算机程序
、 ,
来实现这些算法 只有通过编写程序 给计算机下达指令 才能处理
。 , ,
数据 得到有价值的信息 因此 就需要选择合适的程序设计语言 根
, 。 , ,
东
据其语法规则编写程序 最终在计算机上实现自动运行
, 。
体 验 思 考
师
很多智能跑步机会内置称重传感器 可以快速获取用户的体
,
重数据 体重数据被传送到远程服务器上之后 用户可以使用配
。 ,
套的移动应用程序再次读取该数据范移动应用程序除了能够显
。
示体重数据之外 还能够同时显示身体质量指数(body mass
,
index, BMI)和体型描述 如图2.11所示
, 。
思考:
大
1. 程序是如何实现 指数的计算的?
BMI
2. 程序是如何根据 指数显示用户的胖瘦程度的?
BMI
学
出
图2.11 移动应用程序上显示的体重等数据
版
一、 Python语言基础 社
人们要想借助计算机快速准确地得到结果 完成某些特定的功
,
能 就要为计算机编写相应的程序
, 。
程序设计语言是人与计算机进行交互的语言 为了使用计算机
。
解决问题 人们用程序设计语言编写程序 让计算机运行后完成预期
, ,
的任务 程序是一组操作指令或语句序列 是计算机执行算法的操作
。 ,
步骤
。
50 数据与计算1. 程序设计语言
华
程序设计语言经历了从机器语言到高级语言的发展过程
。
(1) 机器语言
机器语言是一种用二进制代码标识的 计算机能够直接识别和执
、
东
行的机器指令的集合 机器语言具有灵活 直接执行和速度快等特
。 、
点 以完成 9+11 的计算为例 用某种类型计算机适用的机器语言
。 “ ” ,
编写的程序如表22所示
. 。
师
表2.2 机器语言示例
语 句 说 明
范
10110000 00001001 将9放入累加器A
00101100 00001011 11与累加器A中的值相加 结果仍放在累加器A中
,
11110100 停止操作
大
一般 一条指令就是机器语言的一条语句 指令包括操作码和地
, 。
址码 其中操作码指明了指令的操作性质及功能 地址码则给出了操
, 学 ,
作数或操作数的地址
。
(2) 汇编语言
用机器语言编写程序非常困难 因此产生了汇编语言 也称为符
出, ,
号语言 在汇编语言中 用类似英语缩略词的语言代替机器指令的操
。 ,
作码 用地址符号或标号代替指令或操作数的地址 运行时再转换为
, ,
机器语言 以完成 9+11 的计算为例 用汇编语言编写的程序如表
。 “ ” ,
版
23所示
. 。
表2.3 汇编语言示例
社
语 句 说 明
MOV AL,9 将9放入累加器A其中AL表示累加器A
,
ADD AL,11 11与累加器A中的值相加 结果仍放在累加器A中
,
HLT 停止操作
(3) 高级语言
由于汇编语言依赖于硬件体系 且助记符量大难记 于是人们又
, ,
第二章 算法与程序实现 51发明了更加易用的高级语言 高级语言是以人类的日常语言为基础
。
的一种编程语言 使用一般人易于接受的文字来表示 从而使程序编
, ,
写更容易 有较高的可读性 目前 常用的高级语言有 ++
华
, 。 , C、C 、
等 以完成 9+11 的计算为例 用 语言编写的
Java、Python 。 “ ” , Python
程序如表24所示
. 。
东表2.4 Python语言示例
语 句 说 明
print(9+11) 计算9+11并输出
师
高级语言和汇编语言一样 编写的程序也不能直接被计算机执
,
行 必须经过转换后才能被执行
, 范 。
2. Python常用数据类型
大
为了能够处理日常生活中各式各样的数据 程序设计语言提供了
,
多种数据类型 常见的 数据类型如表25所示
。 Python . 。
学
表2.5 常见Python数据类型
数据类型 类型标识符 类型说明
Python中的整数可以是任意大小 如
整型 int 出 ,
51-670等
、 、
由整数部分与小数部分组成 也可以使用科
浮点型 float ,
学记数法表示 如3.076-2e3等
, 、
版
用单引号(' ')或双引号(" ")括起来的一串字
字符串型 str
符 如'Hello'或"上海" "\n"等
,
只存在两种值 真(True)或假(False)常用
布尔型 bool : ,
于逻辑判断 社
在程序设计过程中 可以通过强制类型转换操作 把数据从一种
, ,
类型强制转换成另一种类型 语言中可用于数据类型转换的
。Python
内置函数如表26所示
. 。
52 数据与计算表2.6 Python语言的数据类型转换函数
数据类型转换函数 说 明
float(3) 将整型数据3转换为一个浮点型数据 为3.0
华 ,
int(3.6) 将浮点型数据3.6转换为一个整型数据 为3
,
str(3) 将整型数据3转换为字符串型数据 为'3'或"3"
,
东
3. Python中的常量、变量与赋值符
常量是直接给定的 指在程序运行过程中不变的量 如常用的数
师 , ,
学常数 就是一个常量
π 。
变量指程序运行过程中可以被改变的量 在程序运行过程中 变
。 ,
量被存储在内存中 可以通过变量名进行访问 变量命名时 需要遵
范, 。 ,
守命名规则 由大小写英文字母 数字或下划线组成 以英文字母或
: 、 ,
下划线为首字符 长度不限 不能与 保留字同名 大小写敏感
, , Python , 。
变量的数据类型由被赋值的数据对象的类型决定
大 。
= 为 中的赋值符 其作用是把赋值号右边表达式的计
“ ” Python ,
算结果存储到赋值号左边指定的变量中 例如 =3 就是将3赋值
。 :c ,
给变量c
。
学
4. Python中的运算符与表达式
中的表达式是出操作数 参与运算的数据 变量和运算符
Python ( )、
的组合 是用来描述数据的计算过程 或描述对于某种情况下所遇到
, ,
的条件判断 单独一个操作数或变量都可以看作是表达式 常用的运
, 。
算符有算术运算符 关系运算符 逻版辑运算符等
、 、 。
(1) 算术运算符
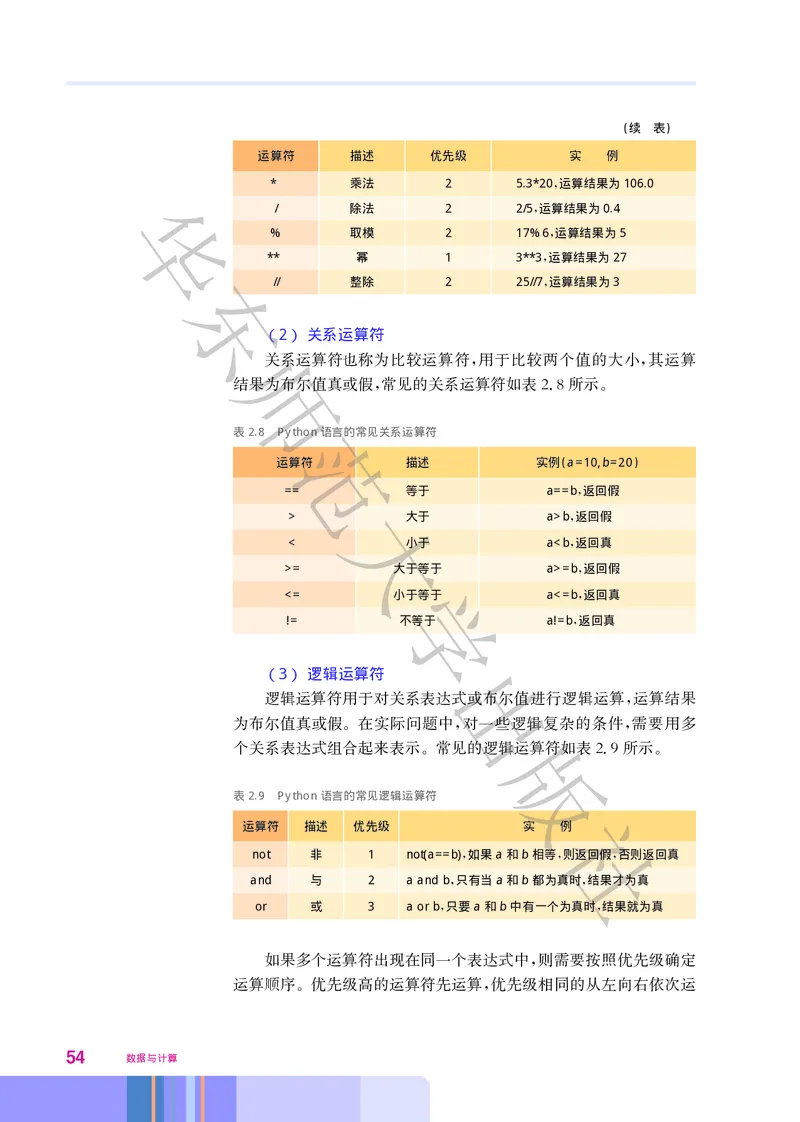
算术运算符主要用于算术运算 运算的结果为整型或浮点型 常
, 。
见的算术运算符如表27所示 运算符有社优先级 最高级别表示为1
. , , ,
数字越大 优先级越低
, 。
表2.7 Python语言的常见算术运算符
运算符 描述 优先级 实 例
+ 加法 3 23+45运算结果为68
,
- 减法 3 78.4-34.2运算结果为44.2
,
第二章 算法与程序实现 53(续 表)
运算符 描述 优先级 实 例
* 乘法 2 5.3*20运算结果为106.0
华 ,
/ 除法 2 2/5运算结果为0.4
,
% 取模 2 17%6运算结果为5
,
** 幂 1 3**3运算结果为27
,
东
// 整除 2 25//7运算结果为3
,
(2) 关系运算符
师
关系运算符也称为比较运算符 用于比较两个值的大小 其运算
, ,
结果为布尔值真或假 常见的关系运算符如表28所示
, . 。
范
表2.8 Python语言的常见关系运算符
运算符 描述 实例(a=10,b=20)
== 等于 a==b返回假
,
大
> 大于 a>b返回假
,
< 小于 a= 大于等于 a>=b返回假
学 ,
<= 小于等于 a<=b返回真
,
!= 不等于 a!=b返回真
,
出
(3) 逻辑运算符
逻辑运算符用于对关系表达式或布尔值进行逻辑运算 运算结果
,
为布尔值真或假 在实际问题中 对一些逻辑复杂的条件 需要用多
。 , 版,
个关系表达式组合起来表示 常见的逻辑运算符如表29所示
。 . 。
表2.9 Python语言的常见逻辑运算符
社
运算符 描述 优先级 实 例
not 非 1 not(a==b)如果a和b相等 则返回假 否则返回真
, , ,
and 与 2 a and b只有当a和b都为真时 结果才为真
, ,
or 或 3 a or b只要a和b中有一个为真时 结果就为真
, ,
如果多个运算符出现在同一个表达式中 则需要按照优先级确定
,
运算顺序 优先级高的运算符先运算 优先级相同的从左向右依次运
。 ,
54 数据与计算算 括号运算的优先级最高 应先计算括号内的表达式 三种运算符
。 , ;
的优先级为 算术运算符 关系运算符 逻辑运算符
: > > 。
5. Python中的内置函数与模块导入
内置函数是已经预定义并且已经实现的 可以供用户直接调用的
、
函数 很多高级语言都有内置函数 函数可以直接通过 函数名 参数
, 。 “ (
列表 的方式调用 多个参数值之间一般以逗号分隔 例如
)” , 。 ,abs x
为 提供的求取绝对值的内置函数 -1 的返回值为1
Python ,abs ;
为求取指定位数的小数的内置函数 314159262
round a b ,round .
的返回值为314
. 。
语言中的模块是一个程序文件 在使用之前通过
Python , “import
模块名 的方式导入 例如 通过 导入数学模块后 在
” 。 , “importmath” ,
程序中就可以直接调用该模块中定义的函数了 使用 函数
, factorial()
输出阶乘的程序代码如下
:
第二章 算法与程序实现
华
东
师
范
大
importmath
6
print math factorial
学
6. Python中的字符串
出
字符串主要用于存储和表示文本 是 中最常用的数据类
, Python
型之一 计算机中文本的最基本单位是字符 包括可见字符和不可见
。 ,
字符 其中可见字符有英文大小写字母 数字字符 标点符号和一些常
, 、 、
版
见符号 不可见字符包括回车 空格等
; 、 。
语言提供了对字符串类型数据的一些通用操作 包括连
Python ,
接 复制等 如表210所示
、 , . 。
社
表2.10 Python语言中字符串类型数据的通用操作
操作 描述 实例(str1="Hello",str2="Python")
x+y 连接两个字符串x和y str1+" "+str2返回"Hello Python"
,
x*n 复制n次字符串x str1*3返回"HelloHelloHello"
,
len(x) 返回字符串x的长度 len(str1)返回5
,
557. Python中的列表
列表是 中常见的一种数据形式 它可以把大量的数据放
Python ,
在一起 对其进行集中处理 列表是以 包围的数据集合 不同成
, 。 “[]” ,
员间以 分隔 列表中可以包含任何数据类型 也可以包含另一个
“,” 。 ,
列表 我们可以通过序号来访问列表中的成员 例如有列表 =
。 , :tian
甲 乙 丙 丁 戊 己 庚 辛 壬 癸 其中
[" "," "," "," "," "," "," "," "," "," "],
tian0 为 甲 tian2 为 丙
[] “ ”, [] “ ”。
语言对列表提供了一些与字符串相似的通用操作 此
Python 。
外 还提供了一些常用的列表方法 如表211所示
, , . 。
表2.11 Python语言中的常用列表方法
方法 描 述
list.append(x) 在列表尾部追加成员x
list.insert(i,x) 向列表中指定位置i插入x
删除列表中的指定成员 有多个则只删除第一个 指定成员不
list.remove(x) ( ,
存在则报错
)
在交互环境下对列表进行操作的示例代码如下
:
数据与计算
华
东
师
范
大
学
= 子 丑 寅 卯 辰 巳 午 未 申 酉 戌
>>>di " " " " " " " " " " " " " " 出" " " " " " " "
>>>di
'子' '丑' '寅' '卯' '辰' '巳' '午' '未' '申' '酉' '戌'
亥
>>>di append " " 版
>>>di
'子' '丑' '寅' '卯' '辰' '巳' '午' '未' '申' '酉' '戌' '亥'
0 亥
>>>di insert " "
社
>>>di
'亥' '子' '丑' '寅' '卯' '辰' '巳' '午' '未' '申' '酉' '戌' '亥'
亥
>>>di remove " "
>>>di
'子' '丑' '寅' '卯' '辰' '巳' '午' '未' '申' '酉' '戌' '亥'
56二、 顺序结构的 Python实现
探 究 活 动
华
当手机和智能跑步机通过无线网络连接后 移动应用程序上即可获得跑步过程中的各类数据 例如
, 。 ,
移动应用程序上除了能显示体重值 还可以显示 BMI指数 BMI指数是用体重千克数除以身高米数的平
, 。
东
方得出的数值 是目前国际上常用的衡量人体胖瘦程度以及评定身体是否健康的参考标准之一 BMI指
, 。
数可以通过以下数学公式计算得出
:
体重 千克
BMI= ( )
师 身高2 米2
( )
例如 一个人的身高为1.75米 体重为68千克 他的BMI指数计算如下
, , , :
68
BMI= =22.2
1.752
范
根据这个公式 我们可以使用纸笔 计算器等工具进行 BMI指数的计算 但这些都需要根据不同的身
, 、 ,
高体重值来重复进行手动计算 而程序只需要根据传感器实时测得的用户数据 就可以进行实时 自动计
, , 、
算并输出结果
。 大
1. 讨论一下 要通过编程解决BMI指数的计算 需要哪些步骤
, , ?
2. 要编写程序 可能需要用到哪些数据类型 运算符和函数等
, 、 ?
学
顺序结构的程序设计简单 只要按照解决问题的顺序写出相应的
,
语句即可 它的执行顺序是自上而下 依次执行 直到结束 常见的顺
, , , 。
序结构语句有输入语句 输出出语句和赋值语句
、 。
例如 要根据不同的身高和体重值计算 指数 就可以使用顺
, BMI ,
序结构来编程实现
。
版
1. 抽象与建模
计算 指数 需要用到身高和体重社值 因此程序需要通过用户
BMI , ,
输入的方式获取不同的身高 体重值 计算后输出 指数 其中
、 , BMI 。 ,
用height表示身高 weight表示体重bmi表示 指数
, , BMI 。
输入 heightweight
: 、 ;
输出 b mi
: ;
weight千克
计算模型 对于不同的输入 可以通过bmi= ( )公式
: , height2 米 2
( )
进行计算
。
第二章 算法与程序实现 572. 设计算法
经过分析 需要先输入身高和体重值 然后根据公式计算并输出
, ,
指数的算法描述如下 其流程图如图212所示
BMI , . 。
图2.12 计算 BMI指数
算法流程图
数据与计算
输入身高height
①
输入体重weight
②
根据公式计算 指数
③ BMI
输出 指数
④ BMI
3. 编写程序
程序设计是能够将算法转换成计算机可以处理的指令的重要步
骤 为了提高程序代码的可读性 方便维护 在程序设计的过程中 需
。 , , ,
要加入注释 中的注释从 字符开始 该行代码 字符
。Python “#” , “#”
之后所有的内容都是注释 用来实现根据不同的输入值 计算相应的
。 ,
指数的 程序如下
BMI Python :
华
东
师
范
大
= 请输入身高 输入身高
height float input " m " 学 # height
= 请输入体重 输入体重
weight float input " kg " # weight
= 2 根据公示计算 指数
bmi weight height** # BMI
= 输出 指数
print "BMI " bmi #出BMI
该段 程序中使用了输入输出语句 变量定义 运算符 表
Python 、 、 、
达式和类型转换 其中 输入输出是用户与程序进行交互的主要途
。 ,
径 通过输入语句 程序能够获取运行版所需要的原始数据 通过输出
。 , ;
语句 程序能够将数据处理结果告知用户
, 。
中使用 函数接收用户的输入 当用户输入程序所
Python input() ,
需的数据时 会以字符串形式返回 在输入时也社可给出提示信息 例
, 。 ,
如 = 请输入身高 程序将在屏幕上显示
:height float(input(" (m):")),
请输入身高 信息 并等待用户输入 程序接收用户输入的数据
“ (m):” , ;
后 将输入的数据转换为浮点型数据 保存在变量height中
, , 。
中使用 函数显示一项或多项程序处理的结果 中
Python print() ,
间用逗号分隔 例如 程序将在屏幕上输出
。 :print("Hello,world!"),
信息 再如 = 程序将在屏幕上
“Hello,world!” 。 :print("BMI ",bmi),
输出 = 2220408163265306 信息
“BMI . ” 。
584. 调试运行
在 运行环境中对程序进行调试运行 程序会根据不同的
Python ,
身高 体重值 相应地输出计算后的 指数
、 , BMI 。
第二章 算法与程序实现
华
请输入身高 175
m
请输入体重 68
东
kg
= 2220408163265306
BMI
师
项 目 实 践
许多移动应用程序除了可以显示BMI指数外 还能够显示运动过程中消耗的卡路里数 请查询卡路里
, ,
消耗的计算方式 完成计算卡范路里消耗的程序编写 并填写表2.12
, , 。
表2.12 计算卡路里消耗 的分析与实现
“ ”
输入 大
抽象与建模 输出
计算模型
学
流程图 Python程序
出
设计 编写
算法 程序
版
社
调试运行
情况记录
三、 分支结构的 Python实现
顺序结构的程序能严格按照语句出现的先后顺序解决计算 输
、
59入 输出等问题 但对于要做判断和选择的问题而言 就需要使用分支
、 , ,
结构 依据一定的条件选择执行路径
, 。
华
探 究 活 动
虽然BMI指数可以直接通过身高 体重值计算得出 但这个指数代表的具体含义并不是大多数人所熟
、 ,
东
悉的 例如 身高为1.75米 体重为68千克的人 他的BMI指数为22.2到底代表什么 大家并不清楚 世
。 , , , , 。
界卫生组织(WHO)的判断标准如表2.13所示
。
表2.13 BMI指数参考标准师表
描述 WHO标准 描述 WHO标准
偏瘦 <18.5 肥胖 30~34.9
正常 1范8.5~24.9 重度肥胖 35~39.9
偏胖 25~29.9 极重度肥胖 40
≥
请参考表2.13设计算法 实现对于计算得出的任意BMI指数显示相应的人体胖瘦程度的描述
, , 大 。
在分支结构的程序设计中 程序要能根据是否满足条件来执行不
,
同的语句 语言学中使用 语句实现分支结构 主要包括三种
。Python if ,
基本格式 如表214所示
, . 。
表2.14 Python语言的三种分支结构基出本格式
分支类型 基本格式
if条件表达式
单分支语句 :
版语句块
if条件表达式
:
语句块1
双分支语句
else 社
:
语句块2
if条件表达式1
:
语句块1
elif条件表达式2
:
多分支语句 语句块2
……
else
:
语句块n
60 数据与计算单分支语句中 语句首先判断条件表达式 结果为真 则执行语
,if , ,
句块中的语句序列 结果为假 则不执行任何语句 例如 求x绝对值
; , 。 ,
的语句如下
:
第二章 算法与程序实现
0
ifx<
=-
x x
程序要求代码全部使用缩进来分层 否则将导致程序错
Python ,
误 无法运行 编程规范中指出 缩进最好采用空格形式 每
, 。Python : ,
一层向右缩进4个空格 在同一段代码中不能混用 键和空格键
, Tab ,
如表215所示
. 。
表2.15 缩进对Python程序设计语言的影响
Python语言
if a>b if a>b
程序
print(">") print(">")
说明 正确 可读性好 错误
,
双分支语句中 用 语句实现 如果条件表达式结果为真
, if…else , ,
则执行语句块1中的语句序列 如果结果为假 则执行语句块2中的
; ,
语句序列 例如 判断x的奇偶性的语句如下
。 , :
华
东
师
范
大
学
2==0
出
ifx%
为偶数
print "x "
else
为奇数 版
print "x "
多分支语句中 用 语句实现 程序首先判断 语句
, if…elif…else 。 if
的条件表达式 如果结果为真 则执行语句块1中的语句序列 如果结
, , 社;
果为假 则继续判断 语句的条件表达式 如果条件表达式结果为
, elif ,
真 则执行这个 对应的语句块中的语句序列 如果结果为假 则继
, elif , ,
续判断下一个 语句的条件表达式 依此类推 如果所有的条件表
elif 。 ,
达式结果均为假 则执行 后的语句块 例如 根据气温判断高温
, else 。 ,
预警信号级别的语句如下 其对应的流程图如图213所示
, . 。
61数据与计算
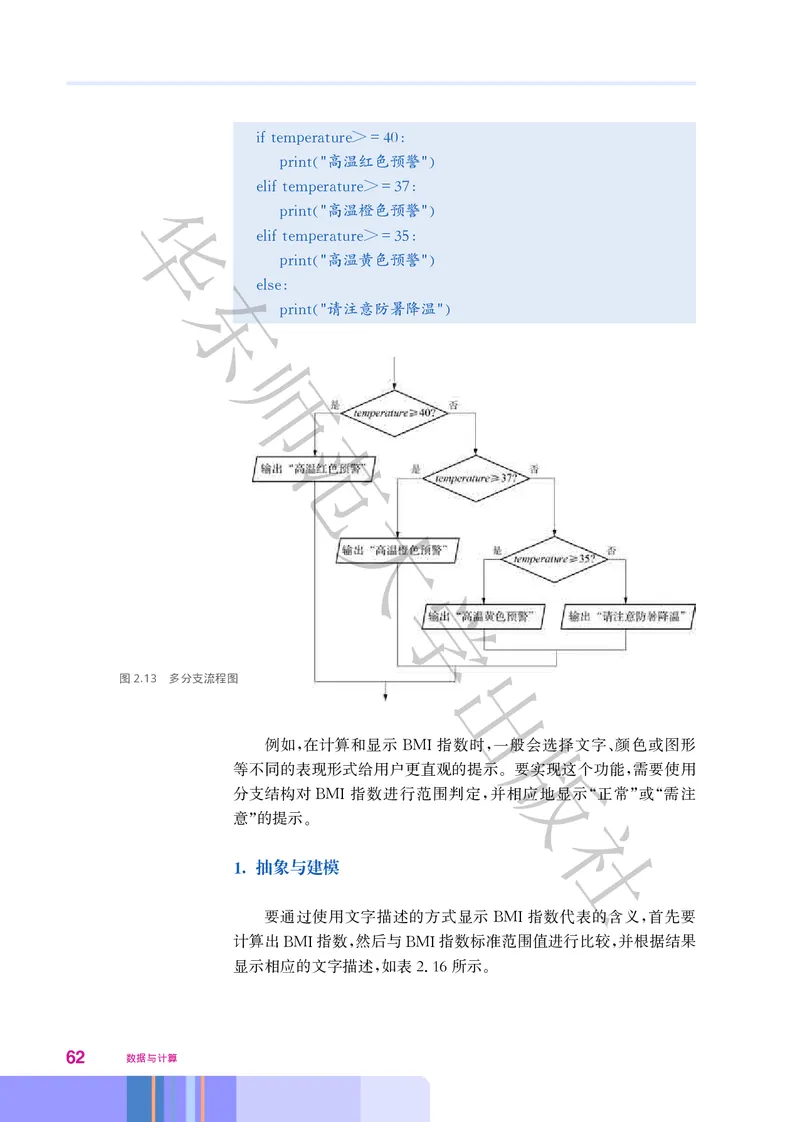
=40
iftemperature>
高温红色预警
print " "
=37
华 eliftemperature>
高温橙色预警
print " "
=35
eliftemperature>
高温黄色预警
东 print " "
else
请注意防暑降温
print " "
师
范
大
学
出
图2.13 多分支流程图
版
例如 在计算和显示 指数时 一般会选择文字 颜色或图形
, BMI , 、
等不同的表现形式给用户更直观的提示 要实现这个功能 需要使用
。 ,
分支结构对 指数进行范围判定 并相应地显示 正常 或 需注
BMI , “ ” “
社
意 的提示
” 。
1. 抽象与建模
要通过使用文字描述的方式显示 指数代表的含义 首先要
BMI ,
计算出 指数 然后与 指数标准范围值进行比较 并根据结果
BMI , BMI ,
显示相应的文字描述 如表216所示
, . 。
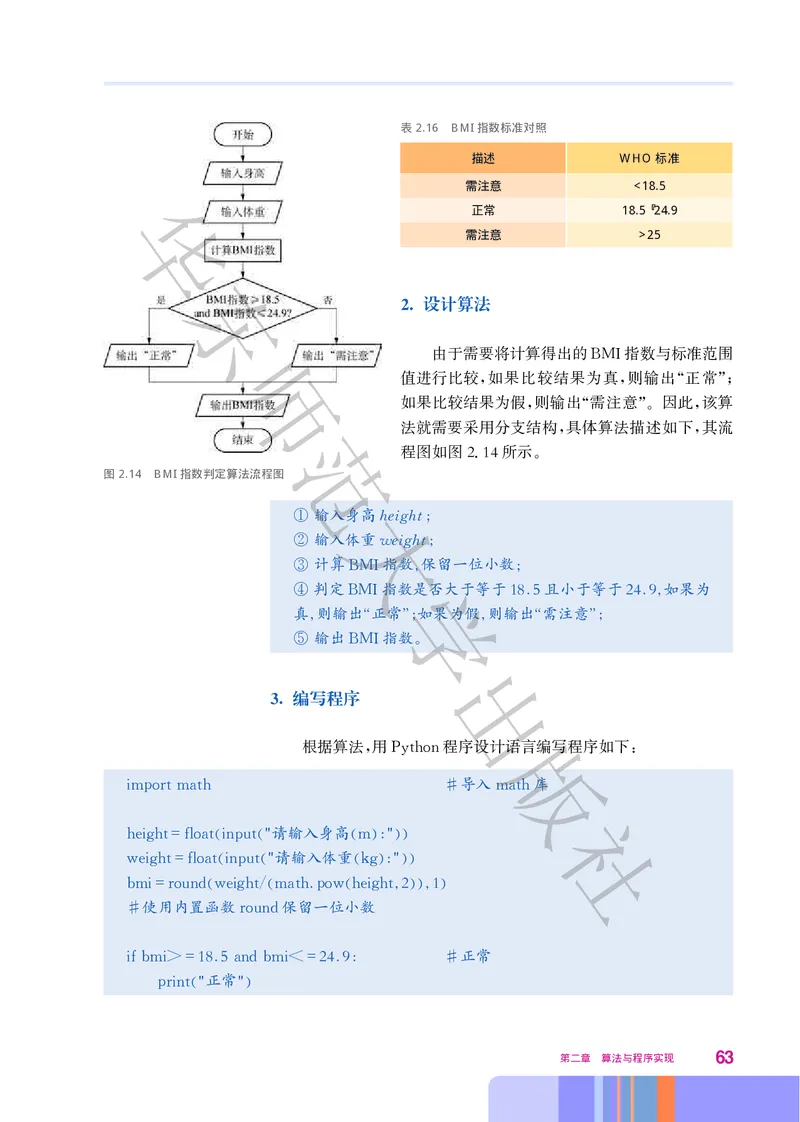
62表2.16 BMI指数标准对照
描述 WHO标准
需注意 <18.5
正常 18.5~24.9
需注意 >25
2. 设计算法
由于需要将计算得出的 指数与标准范围
BMI
值进行比较 如果比较结果为真 则输出 正常
, , “ ”;
如果比较结果为假 则输出 需注意 因此 该算
, “ ”。 ,
法就需要采用分支结构 具体算法描述如下 其流
, ,
程图如图214所示
. 。
图2.14 BMI指数判定算法流程图
第二章 算法与程序实现
输入身高height
①
输入体重weight
②
计算 指数 保留一位小数
③ BMI
判定 指数是否大于等于185且小于等于249 如果为
④ BMI
真 则输出 正常 如果为假 则输出 需注意
输出 指数。
⑤ BMI
3. 编写程序
根据算法 用 程序设计语言编写程序如下
, Python :
华
东
师
范
大
学
出
版
导入 库
importmath # math
社
= 请输入身高
height float input " m "
= 请输入体重
weight float input " kg "
= 2 1
bmi round weight math pow height
使用内置函数 保留一位小数
# round
=185 =249 正常
ifbmi> andbmi< #
正常
print " "
63数据与计算
需注意
else #
需注意
print " "
华
= 输出 指数
print "BMI " bmi # BMI
东
4. 调试运行
将程序在 环境中进行调试运行 程序会更根据不同的身
师Python ,
高 体重值 相应地给出不同的文字描述 并输出计算后的 指数
、 , , BMI ,
如图215所示
图2.15 程序运行结果 . 。
范
探 究 活 动
上述程序中用两种文字描述来表示BM大I指数的两个范围 请你使用turtle库再设计一个图形显示方案
,
来表示这两种BMI指数范围(例如可使用两种不同颜色的形状等)并填写表2.17
, 。
表2.17 图形化显示BMI指数范围 的分析与实现
“ ”
学
输入
抽象与建模 输出
计算模型
出
流程图 Python程序
版
设计 编写
算法 程序
社
调试运行
情况记录
64技 术 支 持 turtle库介绍
turtle库是Python语言中一个较常用的绘制图像函数库 类似一个小乌龟 从一个横轴为x纵轴为y
华 , , 、
的坐标系原点 该原点位于画布中心位置 (0,0)位置开始 根据一组函数指令的控制 在这个平面坐标系中
( ) , ,
移动 从而在它爬行的路径上绘制图形 常用的turtle绘图基础知识包括画布和画笔两部分
, 。 。
画布用于表示绘图区域 画布大小和颜色可以设置 例如 turtle.screensize(400,300,"black")表示宽
, 。 : ,
400像素东长300像素的黑色画布 画笔为画布上一个默认的箭头 常用的属性和命令如表2.18所示
、 。 , 。
表2.18 画笔常用命令表
命 师令 描 述
turtle.goto(x,y) 将画笔移动到坐标为(x,y)的位置
turtle.pendown() 放下笔 移动时绘制图像
,
turtle.penup() 范提起笔 移动时不绘制图像
,
turtle.circle(radius) 画圆 radius为正 负 表示画圆时圆心在画笔的左边 右边
, ( ), ( )
turtle.color(color1,color2) 同时设置pencolor为color1fillcolor为color2
,
turtle.begin_fill() 准备开始填充图形 与turtle.end_fill()命令配合使用
大,
turtle.end_fill() 填充完成 与turtle.begin_fill()命令配合使用
,
可以通过help()函数查看详细说明和用途 如help(turtle.circle)
,学。
四、 循环结构的 Python实现
出
在不少实际问题中 有许多具有规律性的重复操作 因此在程序
, ,
中就需要重复执行某些语句 如果仅使用顺序结构和分支结构是无法
, 版
完全实现的 此时就需要使用循环结构了
, 。
探 究 活 动
社
智能跑步机每次测量的实时体重数据都会被自动上传到远程服务器上进行存储 当配套的移动应用
。
程序启动并连接到远程服务器上时 就能够自动读取并显示多日的体重数据和BMI指数变化
, 。
1. 分析多日的体重数据分别用变量和列表来储存的不同之处
。
2. 设计算法 完成连续一周的体重数据和BMI指数显示 并用流程图进行描述
, , 。
在循环结构中 通过判定条件 来确定部分语句是否需要被重复
, ,
第二章 算法与程序实现 65执行 当条件结果为真时 循环体被重复执行 直到条件结果为假
, , ,
为止 语言中 循环结构主要通过 语句和 语句
。Python , while for
实现
。
语句的基本格式为
while :
数据与计算
条件表达式
while
语句块
语句中的条件表达式为循环条件 语句块为循环体 表达式
while , ,
后的冒号不能省略 例如 要输出给定列表中数字的平方数 可以用
。 , ,
语句实现 程序代码及运行结果如下
while , :
= 12345 运行结果
alst
= 1 的平方是 1
total len alst
=0 2 的平方是 4
i
3 的平方是 9
whilein): #如果m比n大 if(m>n): #如果m比n大
m,n=n,m #则交换两个变量的值 m,n=n,m #则交换两个变量的值
gcd=1 times=0 #设定循环计数变量初值
times=0 #设定循环计数变量初值 while(n!=0):版#辗转相除法求最大公约数
for i in range(2,m+1): #枚举法求最大公约数 t=m%n
if(m%i==0 and n%i==0): m=n
gcd=i n=t
times=times+1 #循环计数增加 times=times+1 #循环计数增加
print(m) 社
print(gcd) print(times)
print(times)
输入m:12345 输入m:12345
输入n:54433 输入n:54433
1 1
12344 11
第二章 算法与程序实现 73二、 枚举法的程序实现
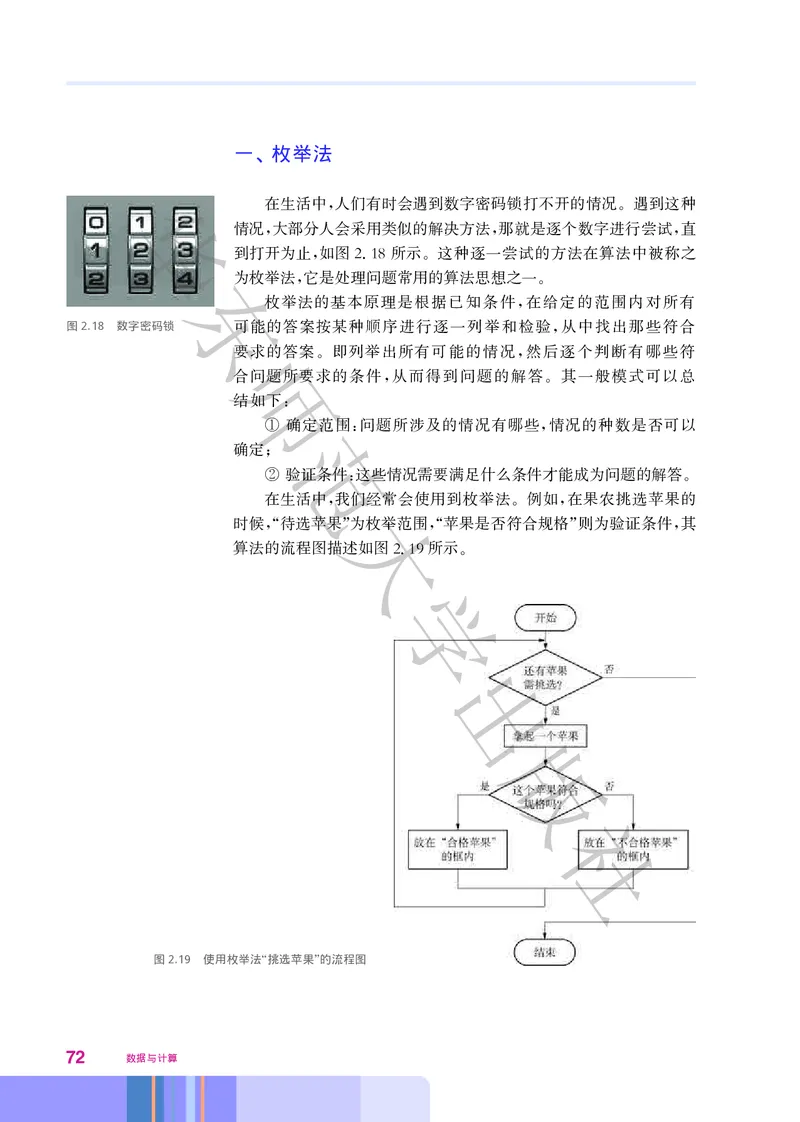
华
用程序设计语言实现枚举法时 需要列举出所有可能的情况 逐
, ,
个判断有哪些情况符合问题所要求的条件 可以采用循环结构实现列
,
举的过程 而其中判断有哪些情况符合问题所要求的条件则可以采用
,
东
分支结构来实现
。
探 究 活 动
师
一般 智能跑步机配套的移动应用程序会通过统计报表的形式给用户提供明确的跑步训练课程完成
,
度信息 用户也可以选择日报表 周报表或月报表进行查看 假设用户设定的某跑步训练课程需要持续一
, 、 。
周 每天需要完成固定的训练内容和范时长 完成后的数据会上传到远程服务器上
, , 。
1. 请设计算法 显示某用户在训练课程中完成了哪几项训练内容 未完成哪几项训练内容
, , 。
2. 选用适当的方法描述算法
。
大
根据跑步课程的设定 用户每天的跑步数据都会被实时传输到远
,
程服务器上 当用户打开移动应用程序时 会通过网络对服务器上的
。 ,
学
数据进行读取 并且显示该用户的课程完成情况
, 。
1. 抽象与建模
出
要显示用户的跑步课程完成情况 就需要对课程每日的训练内容
,
以及完成后自动上传的已消耗卡路里数进行统计
。
版
输入 跑步课程中的每日训练内容和对应训练内容消耗的卡路里
:
数 这些信息由程序自动读取数据库中存储的数据 不需要用户输入
, , ;
输出 完成的项目数和未完成的项目名称
: ;
计算模型 已完成项目数= n data 社
: i=1 i,
∑
0 消耗的卡路里数=0
( ),
data =
i
1 消耗的卡路里数 0
( ≠ );
未完成项目数= n item
∪
i=
1
i,
空字符串 消耗的卡路里数=
( 0),
item =
i
项目名称 消耗的卡路里数
( ≠0)。
74 数据与计算其中n为该跑步课程共有多少项训练内容 消耗的卡路里数为
, ,
大于等于零的整数 为求和符号
, 。
∑
2. 设计算法
在进行统计时 可以使用枚举法来逐一列举并检测 根据枚举法
, 。
的一般模式 确定范围和验证条件如下
, :
确定范围 用户一周的跑步课程训练内容
: ;
验证条件 检测某训练内容消耗的卡路里数是否为0 如不为0
: , ,
则表示已完成训练 并计数 如为0 则表示该训练内容未完成 需要记
, ; , ,
录该训练内容
。
算法描述如下
:
第二章 算法与程序实现
读入一周的跑步课程训练内容
①
读入对应课程训练内容消耗的卡路里数
②
初始设定已完成项目数 finished为0 未完成项目名称unfinished为空字符串
③
逐一列举一周的对应训练内容消耗的卡路里数
④
如果当前枚举的卡路里数为0 则将对应的训练内容名称加入unfinished 否则
⑤
finished的计数加1
输出完成项数目及未完成项目名称。
⑥
3.编写程序
移动应用程序读取服务器上的数据后 可将用户在跑步课程中消
,
耗的卡路里数存储在列表中 例如某用户一周训练课程对应消耗的卡
,
路里数的初始列表值为 0000000 训练内容则固定存储在另
[,,,,,,],
一个列表中 并且与消耗的卡路里数存储位置一一对应 以下显示的
, 。
是某用户一周训练内容安排和每天对应消耗的卡路里数在列表中的
存储情况 可以看出 该用户在 变速练习 训练中消耗了600千卡
。 , “ ” ,
总共完成了6项训练 但没有完成 快走 训练
, “ ” 。
华
东
师
范
大
学
出
版
社
低速低强度 变速练习 低速低强度 快走 低速低强度 坡度练习 低速低强度
" " " " " " " " " " " " " "
4006003800420620397
75根据设计的算法 用 程序实现如下
, Python :
数据与计算
= 低速低强度 变速练习 低速低强度 快走 低速低强度 坡度练
itemlist " " " " " " " " " " "
习 低速低强度
" " "
= 4006003800420620397
datalist
=0 记录完成了多少项训练内容
finished #
= 记录未完成的训练内容
unfinished "" #
7
foriinrange
==0
ifdatalist i
= + +
unfinished unfinished itemlist i ""
else
= +1
finished finished
完成了 项
print " " finished " "
未完成项目
print " " unfinished
4. 调试运行
在 环境中调试运行以上程序 结果显示如下
Python , :
华
东
师
范
大
学
完成了6项
未完成项目 快走
出
项 目 实 践
版
假设每项训练内容都有要求的卡路里消耗最低值 请参考以上程序进行编程 实现统计 该用户哪些
, , “
训练项目未达标 请将你的分析和程序填入表2.22中
”, 。
例如 每项训练内容要求的卡路里消耗最低值存储在mindata380,580,380,450,380,650,380中 从
, [ ] ,
中可以看出 坡度练习 训练要求的卡路里消耗最低值为650千卡 社
“ ” 。
请同学们分析一下本题使用枚举法实现的Python程序 从程序结构的角度上总结枚举法一般需要包
,
含哪几种基本控制结构
。
76表2.22 算法分析及程序实现表
输入
华抽象与建模 输出
计算模型
流程图 Python程序
东
师
设计 编写
算法 程序
范
大
学
调试运行
情况记录
出
版
知 识 延 伸 排序和查找
排序算法 就是如何使得记录按照要求 升序或降序 排列的方法 与枚举法一样 排序算法早在计算
, ( ) 。 ,
机出现之前就已经被人们在实际生活中使用了 人们可以通过 看一眼 扫社一遍 的方式对两个数据快速
。 “ ”“ ”
分辨大小 因此可以在较短的时间内对有限的数据快速地进行排序 而计算机只有通过比较才能够分清
, 。
两个数 在计算机中不仅仅指数值数据 的大小 从而在排序时要进行反复的比较和交换 但由于计算机具
( ) , ,
有高速运算的能力 因此面对大数据量时就比人显得更有优势
, 。
选择排序的基本思想非常直接 每一次从序列的所有元素中先找到最小的 然后放到第一个位置 之
, , 。
后再看剩余元素中最小的 放到第二个位置 依此类推 就可以完成整个排序工作了 选择排序的关键
, …… , 。
是帮助固定位置找到合适的元素
。
例如 待排序数据为 45 67 12 78 39 23 使用选择排序算法的排序过程如表2.23所示
, “ ”, 。
第二章 算法与程序实现 77表2.23 选择排序算法过程记录表
步骤 待排序数据 最小值 备注
华
第1步 45 67 12 78 39 23 12 45和12位置交换
第2步 12 67 45 78 39 23 23 67和23位置交换
第3步 12 23 45 78 39 67 39 45 和39位置交换
东
第4步 12 23 39 78 45 67 45 78和45位置交换
第5步 12 23 39 45 78 67 67 78和67位置交换
第6步 12 23 39 45 67 78 结束排序
师
除了选择排序 还有冒泡排序 插入排序 归并排序 快速排序 堆排序等许多排序算法 每一种排序算
, 、 、 、 、 ,
法都能按照一定的基本原理 完成对数据的排序
, 。
查找也是生活中最常用的算法之一 指通过一定的方法找出与给定关键字相同的数据元素的过程
范, 。
常用的查找算法有顺序查找和二分查找 顺序查找是一种最基本 最简单的查找算法 例如 使用顺序查
。 、 。 ,
找在手机通信录里查找名字叫 孙老师 的联系人信息 则需要从通信录的第一个联系人开始 逐个往下比
“ ” , ,
较 直到找到名字叫 孙老师 的联系人为止 如果所有联系人都查找完了 仍旧找不到这个联系人 则表
, “ ” 。 , ,
大
示查找不成功 二分查找也称为折半查找 其基本思想是当待查找数据有序时 首先找到待查找数据中的
。 , ,
中间元素 将其值与关键字进行比较 若不等 则根据该值与关键字的比较结果来决定继续查找待查数据
, , ,
的前半部分或后半部分 例如 要在手机通信录中查找 孙老师 的联系信息是不会有人愿意从头开始一
。 , “ ”
一比较的 手机中的联系人信息一般都会按拼音首字母进行排序 因此要查找 孙老师 的信息 就可以初
学
。 , “ ” ,
步判定 S应该处于通信录的后部 点击通信录的相应位置 如果运气好 一次就能找到 即使没找到 也可
“” , , , ; ,
以根据相对位置往前或往后翻阅通信录 这种算法和顺序查找相比 比较次数少 查找效率要高得多 但
。 , , ,
实施二分查找的先决条件就是待查范围的数据必须是有序排列的
。
出
查找算法的效率取决于查找的次数 顺序查找的次数由所查找的元素在序列中的位置所决定 而二
, 。
分查找的效率要高得多 但二分查找必须基于有序排列 因此 针对查找规模较小的无序数列 顺序查找
, 。 , ,
也是一种常用的有效方法
。
版
社
78 数据与计算华
东
师
范
第 三 章
大
学
数据处理与应用
出
版
本章学习目标
社
通过典型的应用实例 了解数据采集和整理的基本方法 理解数据安全
◉ , ,
的重要性
。
选用合适的软件工具或平台处理数据 掌握数据可视化的基本方法
◉ , 。
了解数据分析报告的结构形式 完成解决问题的数据分析报告 感悟数
◉ , ,
据分析的价值
。数据处理是对数据的采集 整理 分析和可视化表达的过程 数据处理的基本目的是从大
、 、 。
量的 可能杂乱无章或难以理解的数据中抽取并推导出有价值 有意义的数据 为人们的判断
、 、 , 、
决策 预测提供依据
、华。
如今 数据处理已贯穿社会生产和社会生活的各个领域 数据处理技术的发展及其应用的
, ,
广度和深度 极大地影响着人类社会发展的速度 人流如织的地铁站中 无论是刷卡进站 还
, 。 , ,
是线路选择 数东据处理都悄然相伴于人们的步履匆匆 繁忙的物流行业中 无论是物流效率的
, ; ,
提高 还是物流成本的降低 都离不开数据处理对物流网络的优化 宏伟的城市群布局中 无论
, , ; ,
是城市规划 还是环保监测 数据处理都为城市的科学管理提供了强有力的支撑
, , 。
师
在数据处理的学习和应用中 我们可以感受数据的魅力 探索数据的价值 提升驾驭数据
, , ,
的能力 让数据成为我们学习 工作和生活的得力助手
, 、 。
范
大
本章知识结构
学
)*
FK) > *
出
版
F
>
K )
+ + +
. 3
1
社
" " " *
5
> +
4 A
) ) ) +
F F 4 K *
F
K @
K
"
80 数据与计算项目主题 交通数据利抉择
华
项·目·情·境
共享单车的诞生 顺应了 绿色出行 的环保理念 解决了人们出行 最后一公
, “ ” , “
东
里 的烦恼 但与此同时 又有新的问题浮出水面
” 。 , 。
小申是一名 优秀志愿者 他的服务岗位是学校附近的共享单车站点 因为
“ ”, 。
学校周边还有地铁站 图书馆等 所以小申服务的站点的共享单车租放量很大 有
、 , 。
时共享单车太多而挤占了人行道 有时人多而共享单车却供不应求 小申看在眼里
师
, ,
急在心里 共享单车使用的 潮汐 难题如何破解呢
。 “ ” ?
范
项·目·任·务
大
任务1 任务2 任务3
利用信息技术工 学习数据处理的 应用项目活动中
具收集共享单车使
学
用 常用工具和方法,对数 的数据处理结果,以小
过程中的相关数据,形 据集进行整理,用可视 组为单位撰写数据分
成数据集。 化方式呈现出来。 析报告,交流分享学习
成果。
出
版
社
第三章 数据处理与应用 81第一节 数据采集、整理与安全
当今社会 信息技术开始渗透至人类日常生活的方方面面 随之
, ,
华
而产生的数据量也呈现指数级数增长的态势 例如物联网传感器 社
, 、
交网络等每时每刻都产生着大量的数据 面对数据量的快速增长及
。
变化 数据来源的多元化 数据呈现方式的多样化 我们在遵守相关法
、 、 ,
东
律法规 尊重知识产权的前提下 有效地采集与整理数据是进行数据
、 ,
处理的基础
。
师
体 验 思 考
共享单车在使用时有解锁和闭锁环节 解锁和闭锁方式有多种 图3.1和图3.2所示是用户在使用共
。 ,
享单车时采用蓝牙方式借还车的场范景
。
大
学
出
图3.1 蓝牙模式解锁流程 图3.2 蓝牙模式锁车 还车流程
、
思考:在借还车的过程中产生的大量数据有哪些类型? 如何采集这些数据? 我们可以将数
版
据保存在哪里? 把思考的结果填写在表31中。
.
表3.1 共享单车的数据
社
单 车 数 据 用 户 数 据
通信连接状态 车锁状态 使用记录 用户基本信息 消费记录 骑行的路径
数据描述 、 、 、 、 、 、
等 等
、 、 、 、
数据采集方法
数据保存方法
82 数据与计算一、 数据采集
数据采集一般需要经历明确数据要求 确定数据来源 选择采集
、 、
华
方法 实施数据采集的过程 数据来源有多种渠道 如传感设备 互联
、 。 , 、
网 问卷调查 企业内部数据库等途径 采集数据的方法有很多 目前
、 、 。 ,
较为广泛使用的是传感数据采集和互联网数据采集
。
东
1. 传感数据采集
师 传感数据是由传感设备收集和测量的数据 传感设备
,
可穿戴在用户身上 也可设置在现实环境中 如图33所
, , .
示 传感数据涉及很多方面 如人体的传感数据 网络信
。 , 、
范号的传感数据和气象的传感数据等 通常情况下 传感设
。 ,
备以一定的频率采集数据并发送至相应的数据接收端 这
,
些数据精准地记录着某个具体参数的实时变化情况 基
。
于传感设备所采集的数据为后续的数据分析和数据可视
大
化提供了重要的数据来源
图3.3 可穿戴设备示意图 。
2. 互联网数据采集
学
互联网数据采集是指利用互联网搜索引擎技术实现有针对性 行
、
业性的数据抓取 并按照一定规则和筛选标准进行数据归类 最终形
, 出 ,
成数据库文件的一个过程
。
通常 实现互联网数据采集的流程有三个步骤 获取网页 解析
, : 、
网页 提取数据 和保存数据
( ) 。
版
(1) 获取网页
获取网页的工作主要是获取网页的源代码 源代码里包含了网
。
页的部分有用信息 只要得到源代码 就可以从中提取想要的信息了
, , 。
获取源代码的关键就是构造一个请求并发社送给服务器 然后在接收到
,
服务器的响应后将其解析出来
。
提供了许多库来帮助我们实现这个操作 如
Python , urllib、
等 请求和响应都可以用库提供的数据结构来表示 得到响
Requests 。 ,
应之后只需要解析数据结构中的 部分 即可得到网页的源代码
body , ,
这样我们就可以用程序来实现获取网页的过程了
。
(2) 解析网页
获得网页的源代码后 接下来就是要分析网页源代码 从中提取
, ,
第三章 数据处理与应用 83我们想要的数据 由于网页的结构有一定的规则 所以可以利用一些
。 ,
用于提取网页信息的库 如 等 高效
( BeautifulSoup、PyQuery、lxml ),
快速地提取网页信息
。
解析网页并从中提取信息 可以使杂乱的数据变得条理清晰 以
, ,
便我们后续处理和分析数据
。
(3) 保存数据
提取数据后 我们一般会将其保存 以便后续使用 保存的形式
, , 。
多种多样 如文件存储 数据库存储或网络存储等
, 、 。
项 目 实 践
上网搜索共享单车的运营和用户使用信息 尝试使用互联网数据采集的方法 采集我们生活区域内的
, ,
共享单车数据 如站点数量 单车数量 开 闭 锁时间 骑行距离等 以TXT文件格式进行保存
, 、 、 ( ) 、 , 。
技 术 支 持 网页爬取与解析
1. 网页请求过程
要让网页展示在我们的面前 首先要经历的第一步 就是向服务器
, ,
发送访问请求 requests 服务器接收到请求后 会验证请求的有效
( )。 ,
性 然后向客户端发送响应的内容(responses)客户端接收服务器响 图3.4 请求示意图
, ,
应的内容 将内容展示出来 如图3.4所示
, , 。
2. 网页请求方式
Python有一个强大的Requests库能够让我们很方便地发送HTTP请求 这个库的功能比较完善 而
, ,
且操作比较简单 导入Requests库的语法为
。 :
数据与计算
importrequests
网页请求方式有多种 GET是最常见的方式 一般用于获取或者查询资源信息 响应速度较快 相比
, , , 。
GET方式 POST方式多了以表单形式上传参数的功能 因此除了可以查询信息外 还可以修改信息
, , , 。
在写程序前要先确定向谁发送请求 用什么方式发送
, 。
以下是以GET方式获取所需网页源代码的Python程序代码
。
华
东
师
范
大
学
出
版
社
导入 库
importrequests # Requests
=' ' 确定请求对象
url http www xxxxxx cn #
= 用 方式获取网页数据
html requests get url # GET
= -8 用 8文本编码
html encoding "utf " # UTF-
输出网页的源代码
print html text #
84html=requests.get(url)语句中的html是一个URL对象 它代表整个网页 而 html.text才是网页源
“ ” , ,
代码 很多情况下 如果直接使用html.text会出现乱码的问题 而使用html.encoding属性来设置文本编
。 , , ,
码 如GBK UTF8等 就解决了通过html.text直接返回会显示乱码的问题
( 、 - ), 。
3. 网页解析
通过Requests库抓取到网页源代码后 我们要从源代码中找到并提取数据 Beautiful Soup库也是
, 。
Python的一个功能很强的库 其主要功能是从网页中抓取数据 Beautiful Soup库目前已经被移植到
, 。
bs4库中 所以导入Beautiful Soup库的语法为
, :
第三章 数据处理与应用
4
frombsimportBeautifulSoup
导入Beautiful Soup库后 先用Requests库中的GET方法取得网页源代码 然后利用 Python内建
, ,
的html.parser解析器对源代码进行解析 解析的结果返回到Beautiful Soup类对象sp中 具体语法为
, 。 :
= 源代码 ' '
sp BeautifulSoup html parser
以下是获取网页内容的Python程序代码
。
导入 库
importrequests # Requests
4 导入 库
frombsimportBeautifulSoup # BeautifulSoup
=' ' 确定请求对象
url http www xxxxxx cn #
= 用 方式获取网页数据
html requests get url # GET
= -8 用 8文本编码
html encoding "utf " # UTF-
= ' ' 解析源代码
sp BeautifulSoup html text html parser #
= 用 属性抓取 数据
title sp select "title" # select title
输出 数据
print title text # title
Beautiful Soup库常用的属性和方法见表3.2
。
表3.2 Beautiful Soup库常用的属性和方法
属性和方法 说 明
title 返回网页标题
text 返回去除所有HTML标签后的内容
find() 返回第一个符合条件的标签 例如sp.find("a")
,
find_all() 返回所有符合条件的标签 例如sp.find_all("a")
,
返回指定CSS样式 如id或class的内容 例如sp.select"#id"可实现通过标
select() ( ) , ( )
签的id抓取 sp.select(".classname")可实现通过标签的类名抓取
,
4. 数据存储
将所抓取的数据存储到本地的TXT文件中 只需再加上三行代码
, :
华
东
师
范
大
学
出
版
社
' ' +
withopen title txt "a " as f
f write title
f close
85二、 数据整理
华
数据整理是数据分析过程中的重要环节 包括检查处理数据的重
,
复值 缺失值和异常值等 数据的重复值会导致数据分布发生较大变
、 。
化 数据的缺失值会导致样本信息减少 降低数据分析的准确性 数
。 , 。
东
据的异常值不仅增加了数据分析的难度 而且会导致数据分析的结果
,
产生偏差
。
数据整理的过程是否科学 结果能否真实地反映客观实际 将直
、 ,
师接影响数据处理的质量 影响整个数据分析的准确性
, 。
探 究 活 动
范
图3.5所示是采集到的共享单车位于某区各站点的部分数据 其中包含了共享单车编号 bike_id 开
, ( )、
锁时间 datetime 工作日 workingday 站点名 local_name 气温 temp_value 风速 wind_speed等
( )、 ( )、 ( )、 ( )、 ( )
各种特征数据 仔细观察数据 查找 列举数据中存在的问题 讨论解决的方法
大
。 , 、 , 。
学
出
版
社
图3.5 某区共享单车各站点部分数据
86 数据与计算1. 检测与处理重复值
处理重复数据是数据分析经常要面对的问题之一 对重复数据
。
进行处理前 需要分析重复数据产生的原因以及去除这部分数据后可
,
能造成的不良影响 常见的数据重复情况分为两种 一种为记录重
。 :
复 即某几条记录的一个或多个特征值完全相同 另一种为特征重复
, ; ,
即存在一个或者多个特征名称不同 但数据完全相同的情况 针对记
, 。
录重复的处理 的数据分析核心库 提供了一个名为
,Python Pandas
的去重方法 该方法只对 或者
drop_duplicates() 。 DataFrame Series
类型有效 其基本语法如下
。 :
第三章 数据处理与应用
华
东
师
_ = =' ' =
pandas DataFrame Serie范s dropduplicates self subsetNone keepfirst inplaceFalse
该方法的常用参数及其说明如表33所示
. 。
表3.3 dro大p_duplicate 方法的常用参数及其说明
()
参数名称 说 明
subset 接收字符串或序列 表示进行去重的列 默认为None表示全部列
, , ,
学
接收特定字符串 表示重复时保留第几个数据 first保留第一个
keep , : , ,
默认为firstlast保留最后一个 False只要有重复都不保留
; , ; ,
inplace 接收bool型数据 表示是否在原表上进行操作 默认为False
, ,
出
例如 对 某区共享单车数据 进行数据检测与去重处
, “ ”(test.csv)
理的过程如下
:
(1) 分析数据
版
以图35所示的数据为例 编号为 97068 的共享单车记录不
. , “mr ”
仅出现了编号重复的情况 而且开锁时间等也有重复的情况出现
, 。
(2) 确定方法
社
因为同一辆单车在同一时间不可能被开锁两次 所以删除其中一
,
条记录不会对数据造成不良影响 可以用 方法对数
, drop_duplicates()
据进行去重处理
。
(3) 编程与调试
编写程序 对 中的数据进行去重处理 具体代码
, test.csv ,
如下
:
87数据与计算
importpandasaspd
= _ ' ' = 读取 文件
df pd readcsv test csv encoding "ANSI" # test csv
= _ = ' _ ' ' ' =' ' =
mydf df dropduplicates subset bikeid datetime keep first inplace True
去除 _ 和 的重复数据
# bikeid datetime
print df
2. 检测与处理缺失值
缺失值是指数据中的某个或多个特征的值是不完整的
。Pandas
库提供了识别缺失值的方法 和识别非缺失值的方法
isnull() notnull(),
这两种方法在使用时返回的都是布尔值 即 和 删除法是
, True False。
常用的缺失值处理方法 它通过减少样本量来换取信息完整度 是一
, ,
种较简单的缺失值处理方法 库中提供了简便的删除缺失值
。Pandas
的方法 通过参数控制 该方法既可以删除观测记录 也可
dropna()。 , ,
以删除特征 其基本语法如下
, :
华
东
师
范
大
=0 =' ' =
pandas DataFrame dropna self axis how any inplaceFalse
该方法的常用参数及其说明如表34所示
学 . 。
表3.4 dropna 方法主要参数及其说明
()
参数名称 说 明
出
接收0或1表示轴向 0为删除观测记录 行 1为删除特征 列
axis , ; ( ), ( ),
默认为0
接收特定字符串 表示删除的形式 any表示只要有缺失值存在就
, 版:
how 执行删除操作 默认为anyall表示当且仅当全部为缺失值才执行
, ;
删除操作
inplace 接收bool型数据 表示是否在原表上进行操作 默认为False
, ,
社
例如 对 某区共享单车数据 进行数据检测与处理缺
, “ ”(test.csv)
失值的过程如下
:
(1) 分析数据
同样以图35所示数据为例 编号为 96478 和 96254 的
. , “mr ” “mr ”
共享单车记录中出现了缺失日期 和站点名 这两个
(date) (local_name)
特征值的情况
。
88(2) 确定方法
缺失日期和站点名两个特征值的记录对后续数据统计的意义不
大 可以用 方法进行删除
, dropna() 。
(3) 编程与调试
编写程序 对 中的数据处理缺失值 具体代码如下
, test.csv , :
第三章 数据处理与应用
华
东
importpandasaspd
= _ ' ' = 读取 文件
df pd readcsv test csv encoding "ANSI" # test csv
= =0 = 处理缺失值 按行删除
mydf df dropna axis inplace True #
师
print df
对图35所示数据进行去重和处理缺失值后 结果如图36
. , .
所示
。
范
大
学
出
图3.6 处理后
的某区共享单
车各站点部分
数据
版
3. 检测与处理异常值
社
异常值是指数据中个别值的数值明显偏离其余的数值 有时也称
,
为离群点 检测异常值就是检验数据中是否有输入错误以及是否含
。
有不合理的数据 一般使用箱形图或散点图能较清晰地观察到异常
。
值的存在 如图37所示 异常值的处理方法包括 直接将含有异常
, . 。 :
值的记录删除 用前后两个观测值的平均值修正该异常值 将异常值
; ;
视为缺失值 利用处理缺失值的方法进行处理等
, 。
89图3.7 用箱形图和散点
图分析异常值
技 术 支 持 Pandas库与 DataFrame()方法
Pandas库兼具NumPy库的高性能数组计算功能以及电子表格和关系型数据库灵活的数据处理功
能 Pandas库是本章中使用的主要工具 导入Pandas库的语法为
。 。 :
数据与计算
importpandasaspd
Pandas库主要的数据类型有两种 Series是一维数据结构 其用法与列表类似 DataFrame是二维
: , ;
数据结构 表格即为DataFrame的典型结构
, 。
创建DataFrame的语法为
:
数据变量= 数据类型
pd DataFrame
数据类型 可以是多种类型 由包含相同数量的列表数据作为键值的字典创建的 DataFrame数据
“ ” : 、
自行设置的行及列标题创建的DataFrame数据等
。
例如 创建一个包含四种交通工具以及每种交通工具的日均客运量和占比的DataFrame数据变量名
, ,
称为df
:
= 9692539 6029335 208116 13608
datas
= 轨道交通 公共汽 电车 出租车 轮渡
indexs " " " " " " " "
= 日均客运量 万人次 占公共交通日均客运总量
columns " " " % "
= = =
df pd DataFrame datas columns columns index indexs
生成的DataFrame如下
:
华
东
师
范
大
学
出
版
社
日均客运量 万人次 占公共交通日均客运总量
%
轨道交通 9692 539
公共汽 电车 6029 335
出租车 208 116
轮渡 136 08
这种方式会按用户输入数据的顺序来生成 DataFrame且具有行 列标题 如无特殊需求 我们通常
, 、 。 ,
90会以这种方式生成DataFrame。
读取DataFrame一个列数据的语法为:
第三章 数据处理与应用
列标题
df
要读取两个以上列数据的语法为
:
列标题1列标题2
df
我们可以按行或列读取数据 也可以读取全部数据 读取 DataFrame数据的方法有很多种 如 df.
, 。 ,
values df.loc df.iloc df.ix等 我们可以根据需要进行选用
、 、 、 , 。
4. 数据读取与存储
数据读取与存储是进行数据处理与分析的前提 不同的数据源
。 ,
需要使用不同的函数来读取 内置了十余种数据源读取函数
。Pandas
和对应的数据写入函数 常见的数据源有文本文件 包括一般文本文
。 (
件和 文件 电子表格文件等
CSV )、 。
文本文件是一种由若干行字符构成的计算机文件 它是一种典型
,
的顺序文件 是一种用分隔符分隔的文件格式 因为其分隔符
。CSV ,
不一定是逗号 因此又被称为字符分隔文件格式 文件以纯文
, 。CSV
本形式存储表格数据 数值和文本
( )。
(1) 文本文件的读取
库提供了 函数来读取 文件 其语法如下
Pandas read_csv() CSV , :
华
东
师
范
大
学
出
_ =' ' =' ' = _ =
pandas readcsv filepath sep header infer names None indexcol None
= = 8 版
dtype None encoding utf-
函数的常用参数及其说明如表35所示
read_csv() . 。
社
表3.5 read_csv()函数的常用参数及其说明
参数名称 说 明
filepath 接收字符串 表示文件路径 无默认值
, ,
sep 接收字符串 表示分隔符 默认为 ,
, , “”
header 接收int型数据 表示将某行数据作为列名 默认为infer表示自动识别
, , ,
names 接收数组 表示列名 默认为None
, ,
dtype 接收字典 表示写入的数据类型 默认为None
, ,
91(2) 文本文件的存储
文本文件的存储与读取类似 对于结构化数据 可以通过
, , Pandas
库中的 函数实现以 文件格式进行存储 函数
to_csv() CSV 。to_csv()
的语法如下
:
数据与计算
华
_ _ _ = =' ' _ = = =
DataFrame tocsv pathorbuf None sep narep " columns None header
东
= _ = =' ' =
True index True indexlabel None mode w encoding None
函数的常用参数及其说明如表36所示
to_csv() . 。
师
表3.6 to_csv()函数的常用参数及其说明
参数名称 说 明
path_or_buf 接收字符串 表示文件路径 无默认值
范, ,
sep 接收字符串 表示分隔符 默认为 ,
, , “”
na_rep 接收字符串 表示缺失值 默认为空
, ,
columns 接收列表 表示写出的列名 默认为None
大, ,
header 接收bool型数据 表示是否将列名写出 默认为True
, ,
index 接收bool型数据 表示是否将行名 索引 写出 默认为True
, ( ) ,
index_label 接收序列 表示索引名 默认为None
学, ,
mode 接收特定字符串 表示数据写入模式 默认为 w
, , “”
encoding 接收特定字符串 表示存储文件的编码格式 默认为None
, ,
出
项 目 实 践
在本章第一节 一 数据采集 的项目实践中 我们尝试上网搜索了共版享单车的运营和用户使用信息
“ 、 ” , ,
并使用互联网数据采集的方法 采集了我们生活区域内的共享单车站点数量 单车数量 开 闭 锁时间 骑
, 、 、 ( ) 、
行距离等数据 用本节所学的数据整理方法 检测采集的数据是否存在重复 缺失和异常值 并编写程序
。 , 、 ,
加以处理 以CSV文件格式保存结果
, 。 社
三、 数据安全
随着大数据 物联网 云计算等技术和应用的日渐兴起 大数据应
、 、 ,
用越来越被人们所重视 然而 数据在体现和创造价值的同时 也面
。 , ,
临着严峻的安全风险 在复杂的应用环境下 保障国家重要数据 企
。 , 、
92业机密数据和用户个人隐私数据等不发生外泄 是数据安全的首要任
,
务 海量多源数据在大数据平台汇聚 强化数据隔离和访问控制 实
。 , ,
现数据 可用不可见 是大数据环境下数据安全的新要求
“ ”, 。
华
探 究 活 动
东
目前 全国各地正在积极有序地推进新版社会保
,
障卡的换发工作 如图3.8所示 新版社会保障卡既有
, 。
社会保障应用功能 也有金融应用功能 并采用先进的
, ,
互联网安全技术手师段 构建网络与人之间的可信链接
, ,
确保在互联网上实现 实人 实名 实卡 使人们能够
“ 、 、 ”,
高效 安全地享受各项公共服务
、 。
查阅资料并讨论
: 范
1. 新版社会保障卡增加了哪些功能 有什么 图3.8 新版社会保障卡示意图
?
用途
?
2. 新版社会保障卡应用了哪些新技术 这些新技术是如何保护我们的个人信息的
? ?
将讨论结果填入表3.7中 大
。
表3.7 新 旧版社会保障卡应用对照
、
旧版社会保障学卡 新版社会保障卡
功能用途
主要技术
安全保障 出
版
1. 数据安全意识
数据安全问题越来越被个人 企业乃至社国家所重视 对数据安全
、 。
的威胁主要有计算机病毒 黑客攻击 数据存储介质的损坏 自身数据
、 、 、
管理不善等方面
。
计算机病毒能影响计算机软件 硬件的正常运行 破坏数据的正
、 ,
确性与完整性 甚至导致系统崩溃 黑客通常是先收集被攻击方的有
, 。
关信息 分析可能存在的漏洞 然后实施攻击 黑客一旦入侵成功 就
, , 。 ,
可以读取邮件 搜索和盗窃文件 毁坏重要数据 破坏系统信息 造成
、 、 、 ,
不堪设想的后果 数据存储介质的安全隐患包括物理损坏 设备故障
。 、
第三章 数据处理与应用 93和电磁辐射影响等 自身数据管理不善主要是人为因素造成的 用户
。 ,
安全意识不强 口令选择不慎 用户将自己的账号随意转借他人或与
、 、
别人共享等都会对数据安全带来威胁
。
华
我们的姓名 学历 家庭地址 身份证号 手机号等都是个人隐私
、 、 、 、
数据 2018年5月1日正式颁布实施的 信息安全技术个人信息安全
。 《
规范 中进一步明确 人的基因 指纹 声纹 耳廓 面部识别特征等都
》 , 、 、 、 、
东属于个人敏感信息 大数据时代的各种便利已经渗透进我们生活的
。
每一个角落 我们在访问互联网享受各项服务时 应同时意识到自己
, ,
会留下个人隐私信息 会被他人获取用户数据等情况的存在 我们要
、 。
师辨别和使用可信的网站 网络服务或其他联网的应用程序 谨慎提交
、 ,
个人隐私信息等 要定期清理历史信息及更换各类账户的密码 保护
, ,
自身的数据安全 防止数据外泄
, 。
数据安全是一项系统工程 需要政府机关 行业主管部门 组织和
范
, 、 、
企业 个人等积极发挥多元主体的作用 依据 国家安全法 网络安全
、 , 《 》《
法 等法律法规要求 共同参与到数据安全保障体系的建设中来 做到
》 , ,
知法守法 认真履行有关数据安全风险控制的义务和职责 增强数据
, 大 ,
安全可控意识 共同维护国家安全秩序
, 。
2. 数据安全防护
学
为了保护数据安全 我们还需要在提高数据安全意识的同时 于
, ,
技术层面上提升数据安全的防护水平 数据安全一般有两方面的含
。
出
义 一方面是数据本身的安全 主要采用现代密码算法对数据进行主
: ,
动保护 如数据加密 数据脱敏 访问控制等 另一方面是数据防护的
, 、 、 ;
安全 主要是采用现代信息存储手段对数据进行主动防护 如通过数
, ,
版
据备份 异地容灾等手段保证数据的安全
、 。
(1) 数据加密
数据加密是计算机系统对数据进行保护的一种较为可靠的办法
。
对需要保护的数据 也称为明文 进行加密 即利社用加密算法和加密密
( ) ,
钥将需要保护的数据转化成另外一种数据 也称为密文 然后将密文
( ),
进行存储或者传输给需要使用数据的人 使得窃取者在没有密钥和不
,
了解加密算法的情况下无法识别密文 从而起到数据保密的作用
, 。
(2) 数据脱敏
数据脱敏是在不影响数据分析结果准确性的前提下 对需要保护
,
的数据进行一定的变换操作 如替换 过滤或删除等 从而降低数据的
, 、 ,
敏感性 保护用户的隐私不被泄露 如图39所示
, , . 。
94 数据与计算原始数据
:
序号 姓名 性别 银行卡号 消费金额
1 申 华 男 6225210106311234 12830
.
华
脱敏后数据
:
东 序号 性别 银行卡号 消费金额
1 男 6225 1234 12830
******** .
图3.9 数据脱敏示例
师
(3) 访问控制
在各种计算机系统中 涉及各类服务的使用 文件的访问 数据的
, 、 、
存取时 需要规定特定的人对部分数据负责或获得管理权限 从而做
范
, ,
到被授权的人允许使用特定信息 此时 就需要进行访问控制 这是
。 , ,
确定用户身份及其所享有权限的一种技术 访问控制主要由身份验
。
证与授权两个部分组成 身份验证是用于验证用户身份合法性的一种
大,
技术 身份验证本身并不足以防护数据 还需要授权技术来确定用户
。 ,
是否可以访问数据或执行其所尝试的操作
。
(4) 数据备份
学
数据备份是指为了防止由于操作失误 系统故
、
障等人为因素或意外原因导致数据丢失 而将整个
,
系统的数据或者一部分关键数据通过一定的方法从
出
主计算机系统的存储设备中复制到其他存储设备中
的过程 如图310所示 一旦数据丢失 就可以从
, . 。 ,
备份中恢复历史版本的数据 数据备份往往需要定
。
版
期定时进行 从而使得备份的数据能够保持最新的
,
图3.10 数据备份 状态
。
(5) 异地容灾
当某处的计算机系统因意外 不可抗社力因素 如火灾 地震等 的
、 ( 、 )
原因导致停止工作并且无法提供计算机服务时 往往需要切换到另外
,
一套备用系统上 使其能够继续提供相关计算机服务 如果两套或多
, 。
套计算机系统都安放在同一处 一旦遭到不可抗力因素的影响时 将
, ,
会是灾难性的 为了防止出现这种情况 人们采用了一种异地容灾的
。 ,
方式 在相隔较远的地方 建立两套或多套功能相同的计算机系统 相
, , ,
互进行数据备份或应急时提供备用计算机服务 例如 银行的数据中
。 ,
心都实现了异地容灾 从而可以保证用户的金融数据安全
, 。
第三章 数据处理与应用 95作业练习
目前 停车难 几乎成为了掣肘城市发展 影响市民生活的顽疾 市中心周转腾挪的空间越来越有限
华,“ ” 、 。 ,
在众多停车问题中 路面停车问题尤为突出 图3.11是道路停车标准化管理系统示意图 该系统通过视频自
, 。 ,
动检测和记录停车过程 无需
,
人工干预 结合停车费线上支
,
付和停车信息发东布 实现路面
,
停车管理无人值守 节省人力
,
成本 提升泊位周转率 从而实
, ,
现道路停车智能化的管理
师。
利用所学的数据采集方
法 采集 停车点名称 停车
, “ ”“
点地址 停车泊位 车辆出
”“ ”“
入记录 收费记录 等相关特 范
”“ ”
征数据 并用合适的方法进行
,
整理 保存为 道路停车数据. 图3.11 道路停车自动检测和缴费示意图
, “
csv文件
” 。 大
知 识 延 伸 云存储
学
云存储是一种新型的互联网存储技术 它采用集群应
,
用 网格技术和分布式文件系统等 将网络中大量不同类型
、 ,
出
的存储设备通过应用软件集合起来协同工作 共同对外提供
,
数据存储和业务访问功能 如图3.12所示
, 。
从用户使用的角度来看 云存储的优势主要表现为
, :
1. 便捷存取文件
版
通过联网装置连接到云端后 用户就可以随时 随地存
, 、
取文件 便于备份本地数据并可异地处理文件
, 。
2. 易于存储扩容
社
在需要扩大存储空间时 用户可以依靠云存储服务方提
,
供的存储扩展功能 随时扩大存储空间 按需使用 而无需自
, , ,
图3.12 云存储示意图
身购置存储硬件和相关设施
。
3. 节省存储成本
由于云存储的相关设施是由服务方来承担和负责维护的 用户采用云存储后 就不必操心设备的购
, ,
置 升级与维护等方面的问题 这样就可以节省大量的设备投资经费
、 , 。
尽管当前云存储还存在着存取速度受网络带宽限制 数据安全还需加强等方面的问题 但其便捷地存
、 ,
取文件 易于存储空间扩容 节省存储成本等优势已越来越受到用户的重视 并得到了广泛的应用
、 、 , 。
96 数据与计算第二节 数据分析与可视化
数据分析是指使用适当的分析方法对采集和整理后的数据加以
华
详细研究 提取有用的信息和形成概括总结的过程 我们通常运用统
, 。
计方法 对数据进行定性与定量的分析 然后借助可视化工具 直观清
, , ,
晰地呈现信息 并把信息的特征形象地传递给人们
, 。
东
体 验 思 考
师
共享单车的出现方便了民众出行 但是随着车辆投放总量的增多 整体调控不足 也就出现了肆意挤
。 , ,
占城市公共道路 局部公共空间饱和 偏远地区车辆不足的问题 依据骑车用户已有数据 合理调控车辆
, , 。 ,
已成为管理共享单车的一种有效策略 图3.13是某市共享单车骑行特征和时间分布数据图
。 。
范
大
学
出
图3.13 某市共享单车骑行特征和时间分布数据图
思考:
1 分析图313,指出图中所反映的用户使用共享单车的特征。
. . 版
2 针对分析得到的特征,尝试提出共享单车管理的建议。
.
社
一、 数据分析
为了从数据中获取有价值的信息 对数据进行采集和整理后 还
, ,
需要选用适当的方法与工具对数据进行分析 通过数据分析 可以描
。 ,
述事物的现状 发现相关要素的关系 并对事物的发展趋势做出相应
, ,
的预测
。
第三章 数据处理与应用 971. 数据分析基本方法
数据分析有很多种方法 其中基
,
华
本的数据分析方法有对比分析法 平
、
均分析法和结构分析法等
。
(1) 对比分析法
东
对比分析法是指将两个或两个以
上的数据进行比较 分析它们的差异
, ,
从而揭示这些数据所隐含的事物发展
师 变化或差距 并且可以准确 量化地表
, 、
示出这种变化或差距 图314对不
图3.14 共享单车骑行场景分析 。 .
同场景下的共享单车使用情况进行了
范 比较
。
(2) 平均分析法
平均分析法是利用平均数指标来反映某一特征数据
总体在一定时间 地点条件下的一般水平 通过特征数据
大
、 。
的平均数指标 呈现事物目前所处的位置和水平 进而对
, ,
不同时期 不同类型单位的平均数指标进行对比 明示事
、 ,
物的发展趋势和变化规律 图315是对选择不同出行方
学。
.
式的平均出行距离所做的分析
。
(3) 结构分析法
结构分析法是通过计算各个部分占总体的比重 进而
出 ,
分析某一总体现象的内部结构特征 总体的性质 总体内
图3.15 各种出行方式的平均出行距离分析 、 、
部结构随时间推移而表现出的变化规律性 各个部分占
。
总体的比重即为结构指标 总体中各结构指标的总和为
,
版
100 图316反映了某中学学生选择的各种上学出行
%。 .
方式的占比
。
数据分析的每种方法都有各自的特点和适用范围 在
,
社
实际应用中应根据解决问题的需求来选择合适的方法
。
图3.16 某中学学生上学出行方式
分析 2. 数据分析常用工具
数据分析过程中使用较多的分析工具主要有三类 分别是电子表
,
格软件 在线数据分析平台和数据分析语言
、 。
(1) 电子表格软件
电子表格软件是一种以表格形式组织 分析数据的计算机软件
、 ,
98 数据与计算它以直观的表格形式进行数据分析 具有 所见即所得 的特点 电子
, “ ” 。
表格软件通常具有表格制作 统计计算 图表处理等功能 图317所
、 、 。 .
示是一款电子表格软件的应用界面
。
华
东
师
范
图3.17 电子表格
软件应用界面示例
大
(2) 在线数据分析平台
在线数据分析平台是在网络环境下对所采集的数据进行实时分
析的一种交互式数据服务平台 它可以通过与数据源的实时连接来
。
学
获取最新数据 提供实时数据分析结果 也可以根据用户的数据分析
, ;
计划实施数据分析 提供针对性的分析结果 在线数据分析平台提供
, 。
了简单易用的交互界面 集成了多种数据分析功能 可以使用户更方
, ,
出
便地获取数据分析结果 图318所示是我国国家统计局的一个在线
。 .
版
社
图3.18 在线数据分析平
台示例
第三章 数据处理与应用 99数据分析平台
。
(3) 数据分析语言
使用数据分析语言编写程序对数据进行分析时 可以按照实际需
,
华
求 灵活 深入地进行数据分析和挖掘 在一定程度上 可以摆脱具体
, 、 。 ,
软件格式和平台专用功能的限制 目前 比较主流的数据分析语言有
。 ,
语言 语言和 语言
Python 、R MATLAB 。
东
在对数据进行分析时 语言具有较强的网络数据获取优
,Python
势 还可调用丰富的工具库 例如 库中的
, 。 ,Numpy sum()、mean()、
和 库中的 等都是可以用于统计
min()、max() Pandas value_counts()
师的函数 语言和 语言依靠其独特的功能在相关专业领
。R MATLAB
域使用得更为广泛 例如 语言在统计学领域使用较多 而
。 ,R ,
语言则在工程计算等领域更受欢迎
MATLAB 。
针范对图319所示的数据 使用 语言的 和
. , Python Numpy Pandas
库编写程序 统计共享单车某个站点全天的开锁量 并计算其单位时
, ,
间 小时 内最大的开锁量 其过程如下
( ) 。 :
大
学
出
图3.19 某区
共享单车各站
点部分数据
版
分析数据
①
图319所示的开锁时间 站点名 和日期
. (datetime)、 (local_name)
社
这三个特征值为统计提供了数据支撑
(year_month) 。
确定方法
②
要统计全天的开锁量 先要利用 函数进行频数统
, value_counts()
计 得到单位时间 小时 内的开锁量 然后利用 函数和
, ( ) , sum() max()
函数分别求得总开锁量和单位时间 小时 内的最大开锁量
( ) 。
编程与调试
③
具体代码如下
:
100 数据与计算第三章 数据处理与应用
importnumpyasnp
importpandasaspd
= _ ' ' = 读取 文件
华df pd readcsv test csv encoding "ANSI" # test csv
= ' _ ' =0'6 21 00' ' _ ' =0' 6 21 23'
count df df yearmonth > & df yearmonth <
' _ ' =='图书馆'
& df localname
选出日期是6月21日且地点是 图书馆 的数据集
# 东
= ' _ ' _ 按照时间进行频数统计
thiscount count yearmonth valuecounts #
print thiscount
查看6月21日一天中共享单车单位时间内的最大开锁量
print np max 师thiscount #
查看6月21日一天中共享单车的开锁总量
print np sum thiscount #
程序运行结果如图320所示
. 。
范
大
学
出
图3.20 程序运行结果
版
项 目 实 践
编写程序 对本章第一节 一 数据采集 的项目实践中整理后的数据进行分析 统计共享单车某个站
, “ 、 ” 社,
点全天的单位时间 小时 内平均开锁量 并计算单位时间 小时 内的最少开锁量
( ) , ( ) 。
二、 数据可视化
数据可视化是将数据以图形化方式呈现 从而能够清晰 有效地传
, 、
达与沟通信息 与文字和表格相比 用图形方式展示数据的特征 能够
。 , ,
101更准确地表示数据的分布情况 便于人们有效地分析和理解数据
, 。
1. 数据可视化的基本工具
目前 数据可视化的工具有很多 常用的数据分析软件一般都包
, ,
含了创建可视化图表的功能 例如 电子表格软件中的图表功能可以
。 ,
基于选定的数据 用柱形图 折线图 饼图等方式呈现出来 创建图表
, 、 、 。
后 可以通过修改数据标记 图例 标题 文字等来美化图表或强调某
, 、 、 、
些信息 也可以用图案 颜色 对齐方式 字体及其他格式属性来对图
, 、 、 、
表进行设置 电子表格软件的数据可视化过程直观 易用 但是对于
。 、 ,
大量数据可视化的实现就比较困难了
。
当数据量较大时 可以使用编程语言对这些数据进行可视化
, 。
语言中 是一种应用较广的绘图工具包 使用其中
Python ,Matplotlib ,
的 子库所提供的函数可以快速绘制图形 并能使用标签进行修
pyplot ,
饰 从而制作出高质量的数据分析图
, 。
语言中 引入 的 子库的语法为
Python , Matplotlib pyplot :
数据与计算
华
东
师
范
大
importmatplotlib pyplotasplt
绘制图形有学一个基本流程 创建画布与创建子图 添加
pyplot : 、
画布内容 保存与显示图形 使用这个流程可以完成大部分图形的
、 。
绘制 创建画布与创建子图的主要作用是构建一张空白的画布 并
。 ,
可以选择是否将整张画布划分出为多个部分 以便在同一幅图上绘制
,
多个图形 当只需要绘制一个简单的图形时 这部分内容可以省
。 ,
略 在 中 创建画布以及创建并选中子图的函数如表38
。 pyplot , .
所示
版
。
表3.8 pyplot中创建画布以及创建并选中子图的常用函数
函数名称 函 数 作社用
plt.figure 创建一张空白画布 可以指定画布大小 像素
() , 、
figure.add_subplot 创建并选中子图 可以指定子图的行数 列数和选中图片的编号
() , 、
添加画布内容是绘图的主体部分 其中的添加标题 添加坐标轴
。 、
名称 绘制图形等步骤是并列的 没有先后顺序 可以先绘制图形 也
、 , , ,
可以先添加各类标签 但是添加图例一定要在绘制图形之后
。 。pyplot
中添加各类标签和图例的函数如表39所示
. 。
102表3.9 pyplot中添加各类标签和图例的常用函数
函数名称 函 数 作 用
华
plt.title() 在当前图形中添加标题 可以指定标题的名称 位置 颜色 字体大小等参数
, 、 、 、
plt.xlabel() 在当前图形中添加x轴名称 可以指定位置 颜色 字体大小等参数
, 、 、
plt.ylabel() 在当前图形中添加y轴名称 可以指定位置 颜色 字体大小等参数
东 , 、 、
plt.xlim() 指定当前图形x轴的范围 只能确定一个数值区间 而无法使用字符串标识
, ,
plt.ylim() 指定当前图形y轴的范围 只能确定一个数值区间 而无法使用字符串标识
, ,
plt.xticks() 指定x轴刻度的数目与取值
师
plt.yticks() 指定y轴刻度的数目与取值
plt.legend() 显示当前图形的图例 可以指定图例的大小 位置 标签
, 、 、
范
保存和显示图形的常用函数只有两个 并且参数很少 如表310
, , .
所示
。
大
表3.10 pyplot中保存和显示图形的常用函数
函数名称 函 数 作 用
plt.savefig 学保存绘制的图形 可以指定图形的分辨率 边缘的颜色等参数
() , 、
plt.show 在本机显示图形
()
例如 已知两条曲线出y=x 2和y=x 4 当x 0 1.1 时 绘制一
: , ∈[, ) ,
个最简单的不含子图的图形 如图321所示 具体代码如下
, . 。 :
版
社
图3.21 绘制不含子图的
图形
第三章 数据处理与应用 103数据与计算
importnumpyasnp
importmatplotlib pyplotasplt
= 011001
华 data np arange
在 011 区间内 以001为间隔 创建一维数组
#
' ' 添加标题
plt title lines #
' ' 添加 轴的名称
东 plt xlabel x # x
' ' 添加 轴的名称
plt ylabel y # y
01 确定 轴范围
plt xlim # x
01 确定 轴范围
师 plt ylim # y
0020406081 确定 轴刻度
plt xticks # x
0020406081 确定 轴刻度
plt yticks # y
2 添加 =^2曲线
plt plot data data** # y x
范 4 添加 =^4曲线
plt plot data data** # y x
' =^2' ' =^4'
plt legend y x y x
plt show
大
2. 常用的数据分析图
学
为了选择合适的图形实现数据的可视化 可以从分析特征间的关
,
系 特征内部的数据分布与分散情况等方面 来选择和制作数据分
、 ,
析图
。
出
(1) 分析特征间的关系
散点图和折线图是数据分析最常用的两种图形 这两种图形都
。
能够分析不同数值型特征间的关系 其中 散点图主要用于分析特征
。 ,
版
间的相关关系 折线图则用于分析自变量特征和因变量特征之间的趋
,
势关系
。
散点图 又称为散点分布图 是以一个特征为
(scatterdiagram) ,
横坐标 以另一个特征为纵坐标 利用坐标点社散点 的分布形态反
, , ( )
映特征间统计关系的一种图形 散点图中 值由点在图中的位置
。 ,
表示
。
散点图可以提供两类关键信息
:
特征之间是否存在数值或者数量的关联趋势 以及关联趋势
① ,
是线性的 还是非线性的
, 。
104如果某一个点或者某几个点偏离大多数点 则这些点就是离
② ,
群值 通过散点图可以一目了然 从而可以进一步分析这些离群值是
, ,
否会在建模分析中产生很大的影响
。
中绘制散点图的函数为 其语法如下
pyplot scatter(), :
第三章 数据处理与应用
华
= = = =
matplotlib pyplot scattar x y s None c None marker None alpha None
东
函数常用参数及其说明如表311所示
scatter() . 。
表3.11 scatter 函数常用参数及其说明
()
师
参数名称 说 明
x,y 接收数组 表示x轴和y轴对应的数据 无默认值
, ,
接收标量或一维数组 指定点的大小 若传入一维数组 则表示每个点
范s , , ,
的大小 默认为None
,
接收颜色或一维数组 指定点的颜色 若传入一维数组 则表示每个点
c , , ,
的颜色 默认为None
,
大
marker 接收特定字符串 表示绘制的点的类型 默认为None
, ,
alpha 接收0~1的小数 表示点的透明度 默认为None
, ,
学
例如 当x 0 1.4 时 绘制曲线y=x 2和y=x 4的简单散点
: ∈[, ) ,
图 如图322所示 具体代码如下
, . 。 :
出
版
社
图3.22 绘制简单的散点图
105数据与计算
importnumpyasnp
importmatplotlib pyplotasplt
= 01401
x np arange
在 014 区间内 以01为间隔 创建一维数组
#
' ' 设置标题
plt title ScatterPlot #
' ' 设置 轴标签
plt xlabel x # x
' ' 设置 轴标签
plt ylabel y # y
2 =' ' =' ' 画散点图
plt scatter x x** c r marker o #
4 =' ' =' '
plt scatter x x** c g marker o
' =^2' ' =^4' 设置图标
plt legend y x y x #
显示所画的图
plt show #
折线图 是一种将数据点按照顺序连接起来的图形 可
(linechart) ,
以看作是将散点图按照x轴坐标顺序连接起来 折线图的主要功能
。
是查看因变量y随着自变量x改变的趋势 最适合用于显示随时间
,
根据常用比例设置 而变化的连续数据 同时还可以看出数量的差异
( ) ,
和增长趋势的变化
。
中绘制折线图的函数为 其语法如下
pyplot plot(), :
华
东
师
范
大
= 学='-' =05
matplotlib pyplot plot x y color None linestyle linewidth
函数的常用参数及其说明如表312所示
plot() . 。
出
表3.12 plot 函数的常用参数及其说明
()
参数名称 说 明
x,y 接收数组 表示x轴和y轴对应的数据 无默认值
, 版,
color 接收特定字符串 指定线条颜色 默认为None
, ,
linestyle 接收特定字符串 指定线条类型 默认为 -
, , “”
linewidth 接收float型数据 指定线条宽度 默认为0.5
, ,社
以 某区共享单车数据 为例 绘制折线图 观察某区图
“ ”(test.csv) , ,
书馆站点的共享单车在一天24小时中的使用情况 如图323所示
, . 。
具体代码如下
:
106图3.23 绘制折线图
第三章 数据处理与应用
华
东
师
范
importpandasaspd
importmatplotlib pyplotasplt
' ' = ' '
plt rcParams font sans-serif SimHei
支持大中文 用于正常显示中文标签
#
= _ ' ' =
mydf pd readcsv test csv encoding "ANSI"
读取 文件
# test csv
'某区学图书馆附近一天的共享单车流量'
plt title
'小时'
plt xlabel
'总计'
plt ylabel
= ' 出 ' ' ' =2
ax plt plot mydf index mydf count linewidth
绘制折线图
#
012345678910111213141516
plt xticks
17181920212223
版
plt show
(2) 分析特征内部数据分布与分散状态
柱状图 饼图和箱形图是数据分析常社用的另外三种图形 主要用
、 ,
于分析数据内部的分布状态与分散状态 柱状图主要用于查看各分
。
组数据的数量分布以及各分组数据之间的数量比较 饼图倾向于查
。
看各分组数据在总数据中的占比 箱形图的主要作用是发现整体数
。
据的分布 分散情况
、 。
柱状图 是由一系列高度不等的纵向条纹或线段表示
(barchart)
数据分布的情况 一般用横轴表示数据所属类别 用纵轴表示数量或
, ,
者占比 用柱状图可以比较直观地看出产品质量特性的分布状态 便
。 ,
107于判断其总体质量分布情况
。
中绘制柱状图的函数为 其语法如下
pyplot bar(), :
数据与计算
=08 =
matplotlib pyplot bar left height width color None
函数的常用参数及其说明如表313所示
bar() . 。
表3.13 bar 函数的常用参数及其说明
()
参数名称 说 明
left 接收数组 表示x轴数据 无默认值
, ,
height 接收数组 表示y轴数据 无默认值
, ,
width 接收0~1之间的float型数据 指定柱状图宽度 默认为0.8
, ,
color 接收特定字符串或者包含颜色字符串的数组 表示柱状图颜色 默认为None
, ,
以 某区共享单车数据 为例 绘制柱状图 比较某区图
“ ”(test.csv) , ,
书馆站点的共享单车在7月至10月的使用情况 如图324所示 具
, . 。
体代码如下
:
图3.24 绘制柱状图
华
东
师
范
大
学
出
版
社
importpandasaspd
importmatplotlib pyplotasplt
' ' = ' '
plt rcParams font sans-serif SimHei
支持中文 用于正常显示中文标签
#
= _ ' ' =
mydf pd readcsv test csv encoding "ANSI"
读取 文件
# test csv
_ =10
plt tickparams labelsize
'7 10月 某区图书馆站点共享单车租赁情况'
plt title ~
108第三章 数据处理与应用
'月份'
plt xlabel
'总计'
plt ylabel
' ' ' ' 绘制柱状图
plt bar mydf month mydf count #
78910
plt xticks
plt show
饼图 是将各项的大小与各项总和的比例显示在一张
(piegraph)
饼 中 以占 饼 的面积大小来确定每一项的占比 饼图可以比较清
“ ” , “ ” 。
楚地反映出部分与部分 部分与整体之间的比例关系 易于显示每组
、 ,
数据相对于总数的大小 而且显示方式直观
, 。
中绘制饼图的函数为 其语法如下
pyplot pie(), :
= = =
matplotlib pyplot pie x explode None labels None color None
= =06 =11 =1
autopct None pctdistance labeldistance radius
函数的常用参数及其说明如表314所示
pie() . 。
表3.14 pie 函数的常用参数及其说明
()
函数名称 说 明
x 接收数组 表示用于绘制饼图的数据 无默认值
, ,
explode 接收数组 表示指定项距离饼图圆心为n个半径 默认为None
, ,
labels 接收数组 指定每一项的名称 默认为None
, ,
color 接收特定字符串或者包含颜色字符串的数组 表示饼图颜色 默认为None
, ,
autopct 接收特定字符串 指定数值的显示方式 默认为None
, ,
pctdistance 接收float型数据 指定autopct距离饼图圆心的位置相对于半径的比例 默认为0.6
, ,
labeldistance 接收float型数据 指定labels距离饼图圆心的位置相对于半径的比例 默认为1.1
, ,
radius 接收float型数据 表示饼图的半径 默认为1
, ,
以 某区共享单车数据 为例 绘制饼图 观察某区
“ ”(test.csv) , ,
内的共享单车在全年四个季节中的使用占比 如图325所示
, . 。
具体代码如下
:
图3.25 绘制饼图
华
东
师
范
大
学
出
版
社
importpandasaspd
importmatplotlib pyplotasplt
' ' = ' '
plt rcParams font sans-serif SimHei
支持中文 用于正常显示中文标签
#
109数据与计算
= _ ' ' =
mydf pd readcsv test csv encoding "ANSI"
读取 文件
# test csv
='春季' '夏季' '秋季' '冬季'
labels
'共享单车四季租赁情况'
plt title
' ' = =' 11 '
plt pie mydf count labels labels autopct % f%%
绘制饼图
#
' '
plt axis equal
plt show
绘制箱形图 时需要使用常用的统计量 它能提供有关
(boxplot) ,
数据位置和分数情况的关键信息 尤其在比较不同特征时 更可表现
, ,
其分散程度差异 图326标出了箱形图中每条线所表示的含义
。 . 。
图3.26 箱形图中每条线的含义
箱形图利用数据中的五个统计量 最小值 下四分位数 中位数
( 、 、 、
上四分位数和最大值 来描述数据 四分位数也称为四分位点 是把
) 。 ,
所有数据由小到大排列并四等分后 处于三个分割点位置的数值 处
, 。
在25 位置上的四分位数称为下四分位数 处在75 位置上的四分
% , %
位数称为上四分位数 处在中间的四分位数即为中位数 利用箱形
, 。
图 可以粗略地看出数据是否具有对称性以及数据分布的分散程度等
,
信息 也可以用于对数据进行异常值检测
, 。
中绘制箱形图的函数为 其语法如下
pyplot boxplot(), :
华
东
师
范
大
学
出
版
社
= = =
matplotlib pyplot boxplot x notch None sym None vert
=15 = = =
None whis positions None widths None meanline
=
False labels None
函数的常用参数及其说明如表315所示
boxplot() . 。
110表3.15 boxplot 函数的常用参数及其说明
()
函数名称 说 明
x 接收数组 表示用于绘制箱线的数据 无默认值
, ,
notch 接收bool型数据 表示中间箱体是否有缺口 默认为None
, ,
sym 接收特定字符串 指定异常点形状 默认为None
, ,
vertr 接收bool型数据 表示图形是纵向或者横向 默认为None
, ,
whis 接收float型数据 指定正常值范围 默认为1.5
, ,
widths 接收标量或者数组 表示每个箱体的宽度 默认为None
, ,
meanline 接收bool型数据 表示是否显示均值线 默认为False
, ,
labels 接收数组 指定每一个箱形图的标签 默认为None
, ,
positions 接收数组 表示图形位置 默认为None
, ,
以 某区共享单车数据 为例 绘制箱形图 对某区共享
“ ”(test.csv) , ,
单车各站点的部分数据进行异常值检测 如图327所示 具体代码
, . 。
如下
:
图3.27 绘制箱形图
第三章 数据处理与应用
华
东
师
范
大
学
出
版
社
importpandasaspd
importmatplotlib pyplotasplt
= _ ' ' =
mydf pd readcsv test csv encoding "ANSI"
' _ ' =' ' =30
plt boxplot mydf tempvalue sym o whis
绘制箱形图
#
plt show
从图327所示的箱形图中很容易就可以找出异常值 例如 气
. 。 ,
111温值为35摄氏度 该值超出了25摄氏度的上限 所以可以定义为异
, ,
常值 进一步观察图328所示的数据 可以发现编号为 96430 的
。 . , “mr ”
共享单车在6月23日222642时的气温值 35摄氏度 为异常值
( ) 。
华
东
师
范
图3.28 某区共享单
车各站点部分数据 充分利用各种可视化图形的优势 能够帮助我们更好地理解数
大 ,
据 例如 如图323所示 在某区图书馆站点 上午8时 下午13时
。 , . , , 、
和17时 晚上21时左右均出现了不同程度的骑行高峰 这可能是图
、 ,
书馆的客流与附近地铁1号线莘庄站的通勤客流交汇的缘故 如图
;
学
3.24所示 7 8月份某区图书馆站点的共享单车使用量明显高于9
,、 、
10月份 这可能和学生们在暑假期间经常去图书馆借阅图书有关 如
, ;
图325所示 从全年四个季节的共享单车使用量占比情况来看 春
. , , 、
出
秋两季的共享单车使用率较高 而夏 冬两季的使用率则较低 共享单
, 、 ,
车的使用情况与气温密切相关
。
无论是分析特征间相关关系的散点图 特征间趋势关系的折线
、
图 还是分析特征内部数据分布的柱状版图 饼图以及特征内部数据分
, 、
散情况的箱形图 数据可视化的目的就是直观 清晰地展现数据 所以
, 、 ,
选择合适的可视化图形尤为重要
。
社
项 目 实 践
共享单车的精准投放和及时调配至今依然是共享单车经营企业所面临的难题 围绕 近三年共享单
。 “
车租赁量变化 用户骑行半径分布 各站点用户租赁量比较 等特征 对本章第一节 一 数据采集 的项
”“ ”“ ” , “ 、 ”
目实践中的数据进行可视化呈现 为有效管理共享单车提出合理建议
, 。
1. 选择合适的可视化方式 编写程序呈现数据分析结果 体会数据可视化的优势
, , 。
2. 依据数据分析和可视化结果 针对上述问题 为有效管理共享单车提出合理建议 并说明理由
, , , 。
112 数据与计算作业练习
共享单车这种结合了移动支付 物联网 定位系统等多种技术 旨在满足城市出行 最后一公里
华 、 、 , “ ”
需求的新兴出行方式 受到了社会各界的关注 图 3.29是 年度共享单车行业发展分析报告 中的部
, 。 《 》
分图示
。
东
师
范
图3.29 年度共享单车
《
行业发展分析报告
》
思考分析报告中采集了什么数据 应用了哪些分析方法 选用了怎样的形式来呈现分析结果 把思考
大
, , ?
的结果填写在表3.16中
。
表3.16 共享单车的数据分析
学
数据处理 可视化呈现
数据描述
方法 理由 形式 理由
出
版
社
第三章 数据处理与应用 113第三节 数据分析报告与应用
运用数据来反映 研究和分析某项事物的现状 问题和原因 发现
、 、 ,
华
其本质和规律 得出分析的结论并给出解决方案 是数据分析过程和
, ,
思路的最后呈现 一份完整的数据分析报告 应当围绕目标确定范
。 ,
围 遵循一定的架构 系统地反映事物数据分析的全貌 为决策者提供
, , ,
东
科学 严谨的依据
、 。
体 验 思 考
师
任何新生事物都不可能是完美的 迅速火爆起来的共享单车也不例外
, 。
各种品牌的共享单车出现在人们眼前 逐渐融入人们的生活 它们被使用的
, ,
频率越来越高 随之而带来的问题也范越来越明显 图3.30所示的词云图反
, 。
映了当前消费者对共享单车关注的热点
。
思考:
如何找准一个共享单车使用中的“痛点”问题,运用所学的数据
大
分析方法,利用数据来反映、研究和分析问题的现状及原因,并提出
图3.30 词云图
解决问题的方法。
学
一、 数据分析报告的种类
常用的数据分析报告有专题出分析报告 综合分析报告和日常数据
、
通报等
。
专题分析报告是对社会现象的某一方面或某一个问题进行专门
研究的一种数据分析报告 它的主要作版用是为决策者制定某项政策
, 、
解决某个问题提供决策参考和依据 它具有两个特点 单一性和深
。 :
入性 如 某年度共享单车新增移动应用程序注册用户专题分析报
, 《
告 等 社
》 。
综合分析报告是全面评价一个地区 单位 部门的业务或其他方
、 、
面发展情况的一种数据分析报告 它具有两个特点 全面性和联系
。 :
性 如 世界人口发展报告 全国经济发展报告 某年度共享单车运
, 《 》《 》《
营分析报告 等
》 。
日常数据通报是以定期数据分析报表为依据 反映计划执行情
,
况 并分析其影响和形成原因的一种数据分析报告 它具有三个特
, 。
点 进度性 规范性和时效性
: 、 。
114 数据与计算二、 数据分析报告的组成
华
数据分析报告依据不同的种类和不同的数据分析方法
,
其最后呈现的方式也可能会有所不同 数据分析报告通常
。
由标题 目录 前言 正文 结论等组成 如图331所示
、 、 、 、 , . 。
东
标题是对数据分析报告的高度概括 标题不仅要体
。
现数据分析的主题 并且能够激发读者的阅读兴趣 在
, 。
命名标题时 可以直接在标题中呈现报告的结论 如 商
, , 《
师 业综合体类停车场日均使用率低 有较大优化空间 等
, 》 ;
也可以在标题中提出分析研究的问题 如 商务写字楼停
, 《
车场如何实施分时管理 等
》 。
范目录体现了数据分析报告的整体结构 读者通过目
。
录可以快捷地找到所需的内容 所以在目录中要列出报
,
告主要章节的名称 并附上对应的页码
, 。
前言是数据分析报告的一个重要组成部分 主要阐
大
,
述分析的背景和目的 需要解决的问题 运用的分析思路
、 、
和方法 预期的效果或结论等
、 。
正文是数据分析报告的核心部分 正文要系统地阐
学 。
述数据分析的过程与结果 其中给出的事实 观点及分析
, 、
论证必须严谨合理 逻辑性强 正文通常采用数据图表
、 。
及文字相结合的方式 方便阅读和理解
出, 。
结论是对整个数据分析报告的总结 应包括依据数
,
据分析结果得出的结论 建议和解决问题的方案等 结
、 。
论要和正文相互衔接 与前言相互呼应
, 。
版
完成一份数据分析报告通常需经历发现与界定问
题 基于数据分析问题 基于数据分析给出解决问题的方
、 、
案等过程 其中 发现与界定问题是关键 基于数据分析
。 , ,
社
给出解决问题的方案是核心 在撰写数据分析报告时
图3.31 数据分析报告示例 。 ,
首先需理清要解决什么问题 养成 先谋而后动 的习惯
, “ ” 。
项 目 实 践
在完成本章第二节项目实践的基础上 小组成员明确分工 分步实施数据采集 整理 统计分析和制作
, , 、 、
可视化图示 体验数据处理的全过程 小组成员合作完成一份数据分析报告 并在班级中交流展示
, ; , 。
第三章 数据处理与应用 115三、 数据分析报告的价值
华
数据分析报告实质上是一种沟通与交流的形式 撰写数据分析报
,
告的主要目的是呈现分析结果 可行性建议 问题解决方案等 其价值
、 、 ,
东
就在于使读者对结果做出正确的理解与判断 并可以根据其做出有针
,
对性 操作性 战略性的决策 数据分析报告的价值如图332所示
、 、 。 . 。
师
范
图3.32 数据分析报告的
价值
大
一份有效的数据分析报告能够为用户了解事物发展现状 有效判
,
断所需解决问题的影响因素 有针对性地选择解决问题的方案 以及
, ,
预判事物发展趋势提供数据支持和行动依据 例如 撰写 共享单车
学 。 , 《
运营风险 数据分析报告 在数据分析的基础上描述城市共享单车的
》 ,
应用现状和存在的问题 找出引发问题的主要原因 针对问题和相关
, ,
原因提出解决问题的建议和方案 为更好地管理城市共享单车提供依
,
出
据与支持
。
版
社
116 数据与计算华
东
师
范
第 四 章
大
学
走近人工智能
出
版
本章学习目标
社
体验借助人工智能平台实现人脸图像智能处理的过程 了解计算机视觉
◉ ,
系统的作用和应用场景
。
通过实例体验机器学习的基本过程 知道人工智能的发展历程
◉ , 。
认识人工智能在信息社会中的重要作用 感受人工智能产生的影响 了
◉ , ,
解人工智能的广泛应用可能会引发的社会问题及应对策略
。计算机真的能够具有 像人类一样思考 的能力吗 其实 人类对于机器智能的思考可以
“ ” ? ,
追溯到 1950年艾伦 麦席森 图灵 Alan Mathison Turing在 智慧 Mind期刊发表的
· · ( ) 《 》( )
学术论文 计算机器与智能 Computing Machinery and Intelligence 1956年 约
华《 》( )。 ,
翰 麦卡锡 John McCarthy等学者发起举行 人工智能夏季研讨会 指出 人工智能 的研
· ( ) “ ”, “ ”
究目标是实现能模拟人类的机器 该机器能够使用语言 具有概念抽象和理解能力 能够完成
, , ,
人类才能完成的东任务 并不断提高自身
, 。
人工智能 这一概念提出后 迅速发展成为一门广受关注的交叉和前沿学科 一方面 随
“ ” , 。 ,
着互联网的普及 物联网的渗透 大数据的形成 信息社区的崛起 数据和信息在人类社会 物
、 、 、 , 、
师
理空间和信息空间之间逐渐交叉融合与相互作用 另一方面 新技术 新产业和新业态的不断
; , 、
涌现 也促使对人工智能基本理论和方法的研究出现新的变化 正是这些变化使得人工智能
, 。
的新型应用呈现出勃勃生机
。 范
大
本章知识结构
学
BD6
出
O@0 >>* 6+/ 6+*
版
@
6 6 6
0
6
.
>
2
>
6 4 M
2
4 ) + 社 +
*
7
L
+ 6 *
+
, 6 6 6 6 6 A O
,
' F M O 6
E " <
118 数据与计算项目主题 智能工具好帮手
华
项·目·情·境
人工智能的发展深深地影响着人们的生活 学习和工作 它在给人们带来各种
、 ,
东
便利条件的同时 也对未来人类的思维方式 交流方式和工作方式的发展提出了
, 、
挑战
。
小申从小就对摄影感兴趣 近年来 小申发现不仅是数码相机 很多智能手机
。 , ,
在拍摄人像的时候 都会用一个矩形框标记取景框中的人脸 也就是说 数码相机
师
, 。 ,
和智能手机已经能够和人类一样 通过 观察 和 思考 判断出 有没有人 以及 人
, “ ” “ ”, “ ” “
在哪里 这是不是可以理解为一种由人创造的 类人智能 小申经常在各种场
”。 “ ”?
合中听到 机器学习 这个概念 那么 机器如何学习 经过学习后 又能完成哪些
“ ” 。 , ? ,
范
任务呢 伴随着各种智能应用的普及 人工智能可能产生哪些社会问题 我们又应
? , ,
该如何应对呢
?
大
项·目·任·务
学
任务1 任务2 任务3
学习人工智能平 体验使用监督学 采用小组活动方
出
台相关接口和图像处 习方法实现鸢尾花分 式,对“人工智能可能
理模块的使用步骤,与 类的关键步骤,参考教 产生的社会问题及应
同伴协作完成人脸识 材中的技术支持,与同 对策略”进行研讨,记
别功能简单应用的 伴协作完版成鸢尾花识 录每位小组同学的观
开发。 别程序的开发。 点,完 成 一 份 研 讨
报告。
社
第四章 走近人工智能 119第一节 体验计算机视觉应用
视觉是人最重要的感觉 至少有80 的外界信息需要通过视觉来
华 , %
获取 如外界物体的大小 数量 颜色 动静等 在日常生活中 我们可
, 、 、 、 。 ,
以分辨出不同的动物 也可以识别出一间教室里有几个人 这主要是
, ,
依靠我们的眼睛 视神经和大脑的视觉中枢实现的 眼睛用于成像
、 。 ,
东
大脑对视网膜上的图像进行处理 最终得出反馈结果
, 。
体 验 思 考
师
随着信息时代的发展 互联网上时时刻刻都在产
,
生和传播着海量的图像 正是在这些海量数据和人工
,
智能算法的帮助下 计算机的 视范觉 正变得越来越
, “ ”
清晰 因此 基于计算机视觉的应用被广泛推广
“ ”。 , ,
其中与我们生活最密切的恐怕要数人脸定位与人脸
识别了
。 大
当我们在使用数码相机或智能手机拍摄照片的
时候 都会用到人脸检测功能 即使用矩形框将拟捕
, ,
捉画面中的人脸标记出来 如图 4.1所示 有些应用
, 。
软件还可以在成功定位人脸后 对人脸进行 美颜 处学图4.1 拍照过程中的人脸自动检测
, “ ”
理 或者添加各种装饰
, 。
思考:对于计算机而言,无论是图像还是视频,都是一串由“0”和“1”构成的序列。那么计算
机是如何在这些“0”和“1”中“找到”人脸的呢?
出
计算机视觉是一门研究如何使机器 看清 和 看懂 的学科 更进
“ ” “ ” ,
版
一步地说 就是指用图像采集设备和计算机代替人眼完成对目标的识
,
别 跟踪和测量等工作 计算机视觉研究相关的理论和技术 从而构
、 。 ,
建能够从图像或多维数据中获取信息的人工智能系统 因为感知可
。
以看作是从感官信号中提取信息 所以计算机视社觉也可以看作是研究
,
如何使人工智能系统能够从图像或多维数据中 感知 的科学
“ ” 。
人脸识别 是基于人的脸部特征信息进行身份识别的一种生物识
,
别技术 有时也被称为人像识别 面部识别 也是计算机视觉重要的研
, 、 ,
究方向之一 广义的人脸识别包括构建人脸识别系统的一系列相关
。
技术 如人脸图像采集 人脸检测 含定位 身份确认以及身份查找
, 、 ( )、
等 而狭义的人脸识别特指通过人脸进行身份确认或者身份查找的技
;
术或系统
。
120 数据与计算早在20世纪50年代 认知科学家就已经开展了人脸识别方面的
,
研究 20世纪60年代 人脸识别开始进入工程化应用 当时的方法
。 , 。
主要利用了人脸的几何结构 通过分析人脸器官特征点及其之间的位
,
置关系进行识别 这种方法简单直观 但是一旦人脸姿态 表情发生
。 , 、
变化 则识别正确率严重下降 1991年 著名的 特征脸 方法第一次
, 。 , “ ”
将分析和统计特征引入人脸识别任务 在实用效果上取得了长足的
,
进步
。
进入21世纪 随着人工智能技术的发展 研究者开始关注在各种
, ,
面部图像采集条件 不同的光照 不同的传感器以及是否进行了压缩
( 、
等 或被拍摄者各种主观条件 面部的不同姿态 不同表情以及是否有
) ( 、
遮挡等 下 是否都能成功进行识别 2014年前后 随着大数据和深
) , 。 ,
度学习的发展 神经网络技术在图像分类 手写体识别 语音识别等应
, 、 、
用中获得了远超经典方法的成果 人脸识别应用也因此取得了突破性
,
进展
。
项 目 实 践
1. 以小组为单位 围绕计算机视觉中的人脸检测
,
与人脸识别开展调研 看看现在有哪些人工智能开发平
,
台提供了这些功能
?
2. 通过查找资料 讨论交流 选择其中一个平台 了
、 , ,
解该平台提供的人脸检测工具开发包 software
(
development kit SDK的使用方法和操作步骤
, ) 。
3. 选择一张你喜欢的生活照 调用人工智能平台
,
的人脸检测功能 定位照片中的人脸 使用技术支持中
, ,
介绍的 Pillow库 将照片中的人脸位置标记出来 如
, ,
图4.2 人脸标记结果实例
图4.2所示
。
技 术 支 持 使用 Pillow库实现人脸标记
使用Pillow库 可以实现图像的缩放 切片 旋转以及画图等各种操作 而且操作方法非常简单
, 、 、 , 。
第四章 走近人工智能
华
东
师
范
大
学
出
版
社
导入 库
# Pillow
fromPILimportImage ImageDraw
打开图像
#
=
im Image open imageName
121数据与计算
生成一个可以用于画图的对象
#
=
draw ImageDraw Draw im
使华用人工智能平台返回的人脸坐标信息 在图像中人脸的位置画一个红色的矩形框
#
用 、 、 、 分别表示人脸框左上角的横、纵坐标以及人脸框的宽度、高度
# lefttopwidthheight
+ + =25500
draw rectangle left top left width top height outline
将图像展示出来
# 东
im show
目前 有多个人工智能平台提供人脸
, SDK
检测和人脸识别应用的开发接口服务 不 1
师,
同平台返回的数据格式各不相同 但均能
SDK
,
2
提供绘制人脸框所需的左上角位置横 纵
、
坐标以及人脸框的宽度 高度信息 各平
、 。 3
范
台的调用过程也大致相同 主要步骤如
,
图4.3所示
。 4
图4.3 调用人工智能平台实现人脸标记主要步骤
大
学
作业练习
利用人工智能平台的人脸识别功能获得人脸位置后 请进一步获取人脸的性别 将不同性别的人脸用
, ,
不同颜色的框标出 常见的性别表示方式如表4.1所示 出
。 。
表4.1 人工智能平台返回的人脸性别信息
序号 返回值类型 说 明
版
1 字符串 male表示男性 female表示女性
“ ” ,“ ”
用整型数值表示性别的可能性 越接近0代表该人脸为女性的概率
2 整型数 0 99 , ,
(~ ) 更大 越接近99代表该人脸为男性的概率更大
; ,
社
除了用字符串 male表示男性 female表示女性之外 还可以使
“ ” ,“ ” ,
3 字符串+浮点数 用一个小于1的正浮点数表示性别的可能性 数值越接近1表示该
, ,
性别的可能性越大
例如 用绿色的框将女性的脸标出 用红色的框将男性的脸标出 在程序设计过程中 可以使用第一
, , 。 ,
章中介绍过的RGB颜色模型来描述想要的颜色
。
122知 识 延 伸 人脸检测与人脸识别
人脸检测 face detection的作用就是要检测出图像中人
华( )
脸的所在位置 如图4.4所示 人脸检测算法的输入是一张图
, 。
像 输出是人脸框坐标序列 具体结果是0个 1个或多个人脸
, , 、
框 输出的人脸框可以是正方形 矩形等 人脸检测算法的
。 、 。
原理简单东来说就是一个 扫描 加 判定 的过程 即首先在整
“ ” “ ” ,
个图像范围内扫描 再逐个判定候选区域是否是人脸 因此
, 。 ,
人脸检测算法的计算速度会与图像尺寸大小及图像内容相
关 在设计算法时 我们可以通过设置 输入图像尺寸 最小
。 师, “ ”“
图4.4 人脸检测
脸尺寸限制 或 人脸数量上限 的方式来加速算法
” “ ” 。
在人脸检测的基础上 可以实现人脸配准(也称为人脸关键点定位)如图4.5
, ,
所示 人脸配准算法的输入是 一张人脸图像 和 人脸坐标框 输出是五官关
。 “ ” “ ”,
键点的坐标序列 五官关键范点的数量是预先设定好的一个固定数值 常见的有
。 ,
5点 68点 90点等
、 、 。
当前效果比较好的人脸配准技术基本通过深度学习框架实现 关于机器学
(
习与深度学习我们将在下一节中介绍 这些方法都是基于人脸检测的结果 按
大)。 ,
某种事先设定的规则将人脸区域抠取出来 缩放到固定尺寸 然后进行关键点位
, , 图4.5 人脸关键点定位
置的计算
。
人脸识别的目标是找出人脸图像所对应的身份 它的输入是一个人脸特征 通过和注册在库中的N
。 ,
个身份对应的特征进行逐个比对 找出 一个 与学输入特征相似度较高的特征 将这个较高相似度值和预
, “ ” 。
设的阈值进行比较 如果大于阈值 则返回该特征对应的身份 否则返回 不在库中 如图4.6所示
, , , “ ”, 。
出
版
社
图4.6 1∶N人脸识别
第四章 走近人工智能 123第二节 人工智能的发展历程
在不同的阶段 人类对 智能 的理解也不相同 因此历史上人工
, “ ” ,
华
智能的定义也历经了多次转变 人工智能就是研究如何使计算机去
。
做过去只有人类才能做的智能的工作 这是人工智能最通俗 简明的
, 、
定义 这个定义反映了人工智能学科的基本思想和基本内容 即人工
。 ,
东
智能是研究人类智能活动规律 构造具有一定智能的人工系统 研究
, ,
如何应用计算机的软 硬件来模拟人类某些智能行为的基本理论 方
、 、
法和技术 另一种定义认为 人工智能是关于知识的学科 研究怎
。 , ———
师样表示知识 获得知识并使用知识的科学 这个定义突出了人工智能
、 。
的知识基础 同时指出了计算机模拟智能行为的本质是模拟人类的知
,
识行为能力 如图47所示 上述两种定义是人工智能领域中被广泛
, . 。
流传和范认可的 本书中 我们采用下列定义 人工智能是指由人创造
。 , :
出来的 具有感知 认知 决策 学习 执行和社会协作能力 符合人类
, 、 、 、 、 ,
情感 伦理与道德观念的虚拟的或人工的系统
、 。
大
学
出
图4.7 人工智能的表
现形式 版
体 验 思 考
社
2016年 阿尔法围棋 AlphaGo在与围棋世界冠军李世石进行的围棋人机对弈中以4∶1的总比分获
, ( )
胜 这是人工智能发展史上又一个新的里程碑 2017年 它又进化为阿尔法元 Alpha Zero 通过 自学成
, 。 , ( ), “
才 仅用3天就成为了围棋界的顶尖高手
”, 。
思考:
1. 请同学们分别了解互联网上不同的人机对弈平台,并体验人机对弈过程。
2. 以小组为单位进行讨论: 在对弈过程中,机器是如何进行“思考”的。
124 数据与计算一直以来 棋艺高超都被当作智力高超的象征 因此棋类博弈自
, ,
古被视为一种代表人类智力的高级挑战 棋类博弈中的随机性和不
。
可控因素要求对局双方的决策能更直接地控制整个局面的走势 进一
,
华
步增强了智力的对抗性 这也是为什么 在每次有更好的人工智能程
。 ,
序面世时 被挑战的对象往往都是棋类
, 。
1951年 世界上诞生了第一个西洋跳棋程序 1962年 西洋跳棋
, 。 ,
东
程序开始击败跳棋高手 这一时期的博弈程序基本上都是使用搜索
。
的方式来求解问题 其中采用了多种算法技巧来提高搜索效率
, 。
师一、 专家系统
专家系统最杰出的代表之一就是1997年战胜了国际象棋世界冠
军范的深蓝计算机 专家系统是早期人工智能的一个重要
(DeepBlue)。
分支 它可以看作是一类具有专门知识和经验的计算机智能程序系
,
统 这类系统就像在模仿人类专家做决定的过程 基于已经掌握的领
。 ,
域知识 根据推理规则得到相关结论 进而解决问题 因此专家系统也
大
, , ,
被称为基于知识的系统 专家系统适合于完成那些没有公认的理论
。
和方法 数据不精确或信息不完整 人类专家短缺或专门知识十分昂
、 、
贵的诊断 解释 监控 预测 规划和设计等任务
、 、学、 、 。
医疗是专家系统的典型应用领域之一 中医药经过数千年的发
。
展 积累了丰富的经验 我国在2008年研发出了基于知识的中医药
, 。
对症开方专家系统 该系统能够在知识库的基础上 结合中药方剂理
。 出 ,
论及组方原则 为用户开出治疗特定病症的量化中药方剂 为医生及
, ,
中药研发人员提供辅助决策支持 如图48所示
, . 。
版
社
图4.8 中医药对症开方
专家系统工作流程示意图
二、 机器学习
在人工智能战胜国际象棋世界冠军后 人们普遍认为围棋对局将
,
是唯一一种计算机无法战胜人类的棋类博弈 因为围棋对局的变化最
,
第四章 走近人工智能 125为复杂 且博弈中还需要考虑到 形势判断 等模糊因素 如图49所
, “ ” , .
示 然而在2016年至2017年间 阿尔法围棋 和阿尔法元
。 , (AlphaGo)
先后战胜了代表国际最高水平的人类顶尖棋手 证明了
华
(AlphaZero) ,
机器学习技术发展带来的突破
。
机器学习 是人工智能的研究领域之一 其本质
(machinelearning) ,
是基于互联网的海量数据以及计算机系统强大的运算能力 让机器自
,
东
主模拟人类学习的过程 通过不断 学习 数据来做出智能决策行为
图4.9 围棋 , “ ” 。
人工智能的研究历史有着一条从以 推理 为重点 到以 知识 为重点
“ ” , “ ” ,
再到以 学习 为重点的自然 清晰的脉络 显然 机器学习是实现人工
“ ” 、 。 ,
师智能的一个途径 即以机器学习为手段解决人工智能中的问题
, 。
机器学习研究的主要目的是设计和分析一些让计算机可以自动
学习 的算法 使计算机从数据中自动分析获得规律 并利用规律对未
“ ” , ,
知数据范进行预测 机器学习的常见方法有监督学习和非监督学习等
。 。
1. 监督学习
大
监督学习表示机器学习的数据是带标记的 这些标记
,
可以包括数据类别 数据属性以及特征点位置等 以这些
、 。
标记作为预期效果 不断地修正机器的预测结果 常见的
学, 。
监督学习有回归 分类 回归 是将数据归到
、 。 (regression)
一条 线 上 即根据离散数据生成拟合曲线 因此其预测
“ ” , ,
结果是连续的 如图410所示 分类 是将
, 出. 。 (classification)
一些实例数据分到合适的类别中 它的预测结果是离散
图4.10 监督学习 回归
: ,
的 图411给出了图像分类的一个简单应用示例 使用
。 . 。
版
社
图4.11 图像分类应用示例
126 数据与计算各种各样的猫和狗的图片构成监督学习训练集 其中的每张图片都
,
已被正确标记为是猫还是狗 经过训练 可以得到基于监督学习
。 ,
的分类模型 当输入一张待分类图片时 如吐着舌头的猫 分类
。 ( ),
华
模型可以给出该图片的分类预测结果 该输入图片是猫的可能性
:
为0923923 是狗的可能性为0231231
. ( .%), . ( .%)。
东 2. 非监督学习
非监督学习表示机器学习的数据是没有标记的
,
师 机器需要从中探索并推断出潜在的联系 比如 在聚
。 ,
类 工作中 由于事先不知道数据类别 只
(clustering) , ,
能按照样本的某些属性将不同数据分开 把相似数据
,
范聚合 成一类 即使得在同一类中的样本相似性尽可
“ ” ,
能大 不同类间的样本相似性尽可能小 如图412所
, , .
示 例如 文本聚类根据文本的某种联系或相关性对
。 ,
图4.12 非监督学习 聚类 文本集合进行有效的划分 方便人们从文档集中发现
大
: ,
相关的信息
。
项 目 实 践 学
鸢尾花又名蓝蝴蝶 紫蝴蝶 是生活中常见的一种观赏花 本任务的 原材料 是鸢尾花数据集 这是
、 , 。 “ ” ,
一个常用的分类实验数据集 其中包含了 150
, 出
条带标记 即标明花卉种类 的鸢尾花数据 数
( ) 。
据集中的鸢尾花分为三类 如图 4.13所示 分
( ),
别是山鸢尾 变色鸢尾和维吉尼亚鸢尾 每类
、 。
50条数据 每条数据包含四个属性 萼片长度 版
, : 、
萼片宽度 花瓣长度 花瓣宽度 数据示例如
、 、 ,
表4.2所示 图4.13 山鸢尾 变色鸢尾和维吉尼亚鸢尾
。 、
社
表4.2 鸢尾花数据集示例
萼片长(厘米) 萼片宽(厘米) 花瓣长(厘米) 花瓣宽(厘米) 类别
5.1 3.5 1.4 0.2 山鸢尾
4.9 3 1.4 0.2 山鸢尾
4.7 3.2 1.3 0.2 山鸢尾
6.3 2.3 4.4 1.3 变色鸢尾
第四章 走近人工智能 127萼片长(厘米) 萼片宽(厘米) 花瓣长(厘米) 花瓣宽(厘米) 类别
5.6 3 4.1 1.3 变色鸢尾
华
5.5 2.5 4 1.3 变色鸢尾
6.4 3.1 5.5 1.8 维吉尼亚鸢尾
6 3 4.8 1.8 维吉尼亚鸢尾
东
6.9 3.1 5.4 2.1 维吉尼亚鸢尾
1. 假设现在有一株鸢尾花 经测量后得知萼片长6.7厘米 萼片宽3厘米 花瓣长5.1厘米 花瓣宽1.8
, , , ,
师
厘米 可以使用什么类型的机器学习方法 来判断它属于哪种鸢尾花
, , ?
2. 请使用技术支持中介绍的方法 完成对鸢尾花类型的自动判别
, 。
范
技 术 支 持 判断鸢尾花类型的方法
鸢尾花数据集中的每一条数据 都是一条带 分类 标记的数据 可以使用监督学习方法来尝试解决这
, 大( ) ,
个问题 如图4.14所示 将150条数据分成两个部分 其中80% 三种各40条 作为训练集 20% 三种各
。 , , ( ) , (
10条 作为测试集 用来判断分类方法的准确率 在分类过程中 使用最简单的欧氏距离来判断 测试数据
) , 。 , ,
属于哪种类型的花 这里使用的欧氏距离是最容易 最直观的距离度量方法 我们在数学课中接触到的两
。 、 ,
学
出
版
社
图4.14 鸢尾花活动任务过程示意图
128 数据与计算个点在空间中的距离一般都是指欧氏距离 例如二维平面上点 a(x,y)与 b(x,y)之间的欧氏距离为
, 1 1 2 2 :
d = (x-x)2+(y-y)2 具体到鸢尾花数据集 每条数据有四个属性 相当于四个维度 所采用的
12 1 2 1 2 。 , , ,
欧氏距离公式为 d(x,y)= ( 4 (x-y)2) 在本程序中 由于仅需要比较大小 找到与测试数据距离
: i=1 i i 。 , (
∑
最短的鸢尾花属性均值所对应的分类 并不需要输出具体距离值 因此只需要计算欧氏距离公式中的平
), ,
方和 可以省略平方根的计算
, 。
具体实现过程中的关键步骤及核心代码如下
。
第一步 数据文件准备 将120条训练数据和30条测试数据分别存入iris_training.csv和iris_testing
: 。
文件 两个文件的第一行为每一列数据项对应的标题 依次为 se_lense_widpe_lenpe_wid和
, , 、 、 、
classification分别代表训练数据的萼片长度 萼片宽度 花瓣长度 花瓣宽度和实际分类 之后每一行为一
, 、 、 、 ;
条训练数据或测试数据 属性标题之间 属性数值之间均使用英文逗号分隔 如图4.15所示
。 、 , 。
se_len,se_wid,pe_len,pe_wid,classification
51351402
.,.,.,.,Iris-setosa
4931402
.,,.,.,Iris-setosa
47321302
.,.,.,.,Iris-setosa
63234413
.,.,.,.,Iris-versicolor
5634113
.,,.,.,Iris-versicolor
5525413
.,.,,.,Iris-versicolor
64315518
.,.,.,.,Iris-virginica
634818
,,.,.,Iris-virginica
69315421
.,.,.,.,Iris-virginica
……
图4.15 使用CSV文件存储鸢尾花训练数据
第二步 初始化 导入Pandas库 以实现对CSV文件的读取 并对程序中用到的常量和变量进行初
: 。 , ,
始化赋值 主要流程如图4.16所示
, 。
Pandas
图4.16 初始化阶段的主要流程
第四章 走近人工智能
华
东
师
范
大
学
出
将山鸢尾、变色鸢尾和维吉尼亚鸢尾的名称使用列表 _ 进版行存储
# iristype
_ = ' ' ' ' ' '
iristype Iris-setosa Iris-versicolor Iris-virginica
初始化三个列表 分别存储三种鸢尾花每个属性的总值和训练样本数量
# 社
_ =00000 山鸢尾
setosasum #
_ =00000 变色鸢尾
versicolorsum #
_ =00000 维吉尼亚鸢尾
virginicasum #
设置四个常量 分别代表三个列表的索引位所表示的含义
#
_ =0 列表第0位代表萼片长度
selen #
_ =1 列表第1位代表萼片宽度
sewid #
129数据与计算
_ =2 列表第2位代表花瓣长度
pelen #
_ =3 列表第3位代表花瓣宽度
pewid #
=4 列表第4位代表鸢尾花训练样本的数量
amount #
第三步 训练 通过Pandas库读入iris_traing.csv文件中的训练数据并循环逐条处理 对四个属性分
: 。 ,
别进行累加求和 同时计算每种类型鸢尾花的训练样本数量 分别存储在setosa_sum versicolor_sum和
, , 、
virginica_sum三个列表中 主要流程如图4.17所示
, 。
图4.17 训练阶段的主要流程
华
东
通过 库的 _ 函数读入训练集数据文件 _
# Pandas readcsv iristraining csv
= _ ' _ '
trainData pd readcsv iristraining csv
师
循环处理训练集 文件中的每一条训练数据
# CSV
分别累加计算每种类型鸢尾花的四个属性的总值以及训练样本数量
#
forindex rowintrainData iterrows范
==' '
ifrow classification Iris-setosa
_ _ += _ 萼片长度
setosasum selen row selen #
_ _ += _ 萼片宽度
setosasum sewid row sewid #
_ _ += _ 大花瓣长度
setosasum pelen row pelen #
_ _ += _ 花瓣宽度
setosasum pewid row pewid #
_ +=1 样本数量
setosasum amount #
==' '
elifrow classification Iris-versicolor 学
_ _ += _
versicolorsum selen row selen
_ _ += _
versicolorsum sewid row sewid
_ _ += _
versicolorsum pelen row pelen
_ _ += _ 出
versicolorsum pewid row pewid
_ +=1
versicolorsum amount
==' '
elifrow classification Iris-virginica
_ _ += _
virginicasum selen row selen 版
_ _ += _
virginicasum sewid row sewid
_ _ += _
virginicasum pelen row pelen
_ _ += _
virginicasum pewid row pewid
_ +=1 社
virginicasum amount
其中 在for循环中使用Pandas库提供的iterrows()方法 可以在循环中每次返回CSV文件中的一行
, ,
数据 并分别将该行的序号和内容存储到变量index和row中 配合使用 CSV文件中第一行的标题名
, 。 ,
即可分别访问每个数据项 例如 row.se_len表示训练数据对应的萼片长度 row.pe_wid表示训练数据
。 , ,
对应的花瓣宽度等
。
130第四步 预测 通过 Pandas库读入 iris_testing.csv文件中的
: 。
测试数据并循环逐条处理 对于每条测试数据 分别计算其与三
。 ,
种鸢尾花属性均值的欧氏距离的平方值 并存储在列表 distance
,
中 因为在训练阶段中 我们只计算了各属性的总值 所以在这里
。 , ,
需要使用属性的总值除以样本数量 以获得相应的均值 之后 根
, 。 ,
据 distance列表中最小值元素的序号 在 iris_type列表中找到
,
对应的分类信息 将其作为预测结果输出 主要流程如图 4.18
, ,
所示
。
图4.18 预测阶段的主要流程
第四章 走近人工智能
华
东
师
读入测试集数据文件 _
# iristesting csv
= _ ' _ '
TestData pd readcsv iristesting csv
循环读取测试集 文件中的每一条训练数据并进行处理
范
# CSV
forindex rowinTestData iterrows
分别计算输入数据与三种鸢尾花属性均值的欧氏距离平方值
# 大
存储在列表 中
# distance
=
distance
_ _ _ _ 2
distance append row selen-setosasum selen setosasum amount **\
+ _ _ 学_ _ 2
row sewid-setosasum sewid setosasum amount **\
+ _ _ _ _ 2
row pelen-setosasum pelen setosasum amount **\
+ _ _ _ _ 2
row pewid-setosasum pewid setosasum amount **
出
_ _ _ _ 2
distance append row selen-versicolorsum selen versicolorsum amount **\
+ _ _ _ _ 2
row sewid-versicolorsum sewid versicolorsum amount **\
+ _ _ _ _ 2
row pelen-versicolorsum pelen versicolorsum amount **\
+ _ _ _ 版_ 2
row pewid-versicolorsum pewid versicolorsum amount **
_ _ _ _ 2
distance append row selen-virginicasum selen virginicasum amount **\
+ _ _ _ _ 2
row sewid-virginicasum sewid virginicasum amo社unt **\
+ _ _ _ _ 2
row pelen-virginicasum pelen virginicasum amount **\
+ _ _ _ _ 2
row pewid-virginicasum pewid virginicasum amount **
获取最小的欧氏距离的平方值
#
_ =
mindistance min distance
131数据与计算
获取最小值的序号
#
= _
idx distance index mindistance
华
将 _ 列表中对应序号位置的分类信息作为预测分类结果
# iristype
打印当前样本的实际分类和预测分类
#
'实际分类 ' ' 预测分类 ' _
print 东 row classification iristype idx
输出结果如图4.19所示 从输出结果中可以看出 有一条维吉尼亚鸢尾数据被错误地分类到了变色
。 ,
鸢尾中 因此共有29条测试数据被正确分类 分类正确率为 29÷30×100% = 96.67% 图4.20给出了
, , : 。
数据集中所有训练数据的分布 其中蓝色代表山鸢尾数据 橙色代表变色鸢尾 绿色代表维吉尼亚鸢尾 三
师, , , ,
种鸢尾数据的均值使用比数据点大的圆形标出 图中红色X为未正确分类的测试数据 从图中可以看出
。 , ,
其距离橙色变色鸢尾的均值比距离绿色维吉尼亚鸢尾的均值要近 故被错判为变色鸢尾
, 。
范
大
学
出
版
社
图4.19 输出结果
132华
东
师
图4.20 鸢尾花分类示意图
范
作业练习
大
K 近邻 KNNknearest neighbor算法是机器学习算法中比较基础和简单的算法之一 经常被用于
( ,- ) ,
分类任务 它的基本原理是 找到离测试样本最近的K条已标记训练数据 将其中最多的类别作为测试样
。 : ,
本的类别
。 学
如图 4.21所示 当 K取 1时 测试样本 图中黄色三角
, , (
形 周围最近的已标记训练数据点为其右上角的绿色正方形
) ,
则将其归为绿色正方形所属分类 当K取2时 距离测试样本
; ,
出
最近的两个训练数据点均为绿色正方形 则同样将其归为绿
,
色正方形所属分类 当K取3时 距离测试样本最近的三个训
; ,
练数据点包括两个绿色正方形和一个红色圆形 则仍将其归
,
为绿色正方形所属分类 当K取5时 距离测试样本最近的五
版
; ,
个训练数据点包括两个绿色正方形和三个红色圆形 则将其
,
归为红色圆形所属分类 与其他监督学习分类方法相比 K
。 ,
近邻方法并没有显式的训练过程 而是先把训练样本保存起
,
社
来 待收到测试样本后再进行处理
, 。 图4.21 K 近邻算法示意图
请修改鸢尾花分类程序 利用 K 近邻的思想 取 K=1
, , ,
计算刚才未正确分类的那条测试样本与所有已标记训练数据
之间的欧氏距离 找到距离最短的那条训练数据 将其分类作
, ,
为测试样本的分类 看看是否能够正确分类
, 。
第四章 走近人工智能 133知 识 延 伸 机器学习的其他方法
机器学习的其他常见方法还包括半监督学习
华
和强化学习
。
与监督学习相比 半监督学习的输入数据中仅
,
有部分数据已被标记 即存在未被标记的输入数
,
据 这种学习模东型首先需要学习数据的内在结构
。 ,
以便合理地组织数据来进行预测 其应用场景同
。
样包括回归和分类 如图4.22所示
, 。
图4.22 半监督学习 分类
如图4.23所示 强化学习是带激励机制的 :
, 师 。
如果机器行动正确 将给予一定的 正激励 如果
, “ ”;
行动错误 也同样会给出一个惩罚 也可称为 负激
, ( “
励 在这种情况下 机器将会考虑如何在一个环
”)。 ,
境中行动才能达到激励的最大化 范具有一定的动态 )* ) *
, )*
规划思想 强化学习最有代表性的一个应用便是
。
阿尔法围棋的升级产品 阿尔法元 阿尔法元
——— 。
舍弃了先验知识 不再需要人为设计特征 直接将
, ,大图4.23 强化学习
棋盘上黑白棋子的摆放情况作为原始数据输入到
模型中 使用强化学习来自我博弈 不断提升自己
, , ,
最终出色地完成了棋局 阿尔法元的成功证明了在没有人类的经验和指导下 深度强化学习依然能够出
。 ,
色地完成指定的任务 学
。
近年来 机器学习方面取得了诸多突破性进展 深度学习也是其中之一 深度学习的概念最早于2006
, , 。
年提出 它指的是基于样本数据 通过一定的训练方法 得到包含多个层级的深度网络结构的机器学习过
, , ,
程 深度学习的优势在于可以采用非监督式或半监督式的高效算法来替代人工方式获取特征 对于不同
。 出 。
的观测值 如一幅图像 既可以用像素值来表示 也可以更抽象地用一系列边或特定形状的区域等来表
( ), ,
示 使用某些特定的表示方法时 能够更容易通过样本数据实现学习任务 如人脸识别或面部表情识别
。 , ( )。
深度学习的 深度 是相对机器学习中浅
“ ”
层学习的方法而言的 浅层学习的方法通常 版
。
采用只有一个输入层 一个隐藏层和一个输出
、
层的神经网络 而在深度学习的模型中 可能
, ,
包含多个隐藏层 如图 4.24所示 迄今为止
, 。 , 社
已经出现了多种深度学习框架 如深度神经网
,
络 卷积神经网络 深度置信网络和递归神经
图4.24 生物神经网络与深度学习神经网络
、 、
网络等 这些方法已被成功应用于计算机视
,
觉 语音识别 自然语言处理等领域
、 、 。
134 数据与计算第三节 人工智能的作用及影响
人工智能是我国新一轮科技革命和产业变革的重要驱动力量
。
华
2017年 国务院出台的 新一代人工智能发展规划 中提出 到2020
, 《 》 :“
年人工智能总体技术和应用与世界先进水平同步 到2030年人工智
;
能理论 技术与应用总体达到世界领先水平 成为世界主要人工智能
、 ,
东
创新中心
。”
体 验 思 考
师
2018年4月,博鳌亚洲论坛 2018年年会 在海南
“ ”
博鳌拉开帷幕 来自世界各国的两千多位嘉宾汇聚一堂
, 。
本次论坛官方首次使用人工范智能翻译机 如图 4.25所
(
示 实现了中文和英语 日语 韩语 法语 西班牙语等多
), 、 、 、 、
种语言的实时互译 为现场嘉宾提供服务 可以预见 随
, 。 ,
着核心关键技术的突破 大多数人工翻译工作 包括笔
, 大(
译 口译甚至是同声传译 将会被机器全部或者部分
、 )
取代
。
思考:
图4.25 人工智能翻译机
1. 人工智能应用在哪些方面具有人类学所不具
备的优势? 随着人工智能技术的发展,哪些行业或
工种会受到比较大的冲击? 又会出现哪些新的行业?
2. 与人工智能应用相比,人类自身有哪些优势? 人类与人工智能应该建立什么样的合作
出
关系?
版
一、 人工智能在不同领域发挥的作用
为了加快推进产业智能化升级 推动社人工智能与各行业融合创
,
新 我国将在制造 农业 物流 金融 家居等重点行业和领域开展人工
, 、 、 、 、
智能应用试点示范 推动人工智能规模化应用 全面提升产业发展智
, ,
能化水平
。
1. 智能制造
智能制造旨在围绕建设制造强国重大需求 推进制造系统集成应
,
第四章 走近人工智能 135用 研发制造服务平台 推广新型制造模式 建立智能
, , ,
制造标准体系 推进制造全生命周期活动智能化 如
, ,
图426所示
华 . 。
在国内某智能手机制造商的自动化生产线上 从
,
送料开始到包装出货 每隔285秒就可以生产出一台
, .
智能手机 生产的全过程采用智能化管理 包括向生
。 ,
东
产基地运货 物料自动仓储入库 生产线自动提取配
、 、
件 成品出库等各个环节 生产组装过程中 采用人机
图4.26 智能制造 、 。 ,
结合的方式 由机器完成其中的大部分工作 同样贯
, 。
师穿在全部生产过程中的还有生产数据的可视化管理 每一台生产设备
, 、
每一件物料 甚至是每一位员工 都可以转化为一个可视化的节点
, , 。
范2. 智能农业
智能农业建设的主要工作包括 研制农业智能
:
传感与控制系统 智能化农业装备 农机田间作业自
大
、 、
主系统等 并在此基础上建立典型农业大数据智能决
,
策分析系统 开展智能农场 智能化植物工厂 智能牧
, 、 、
场 智能渔场 智能果园 农产品加工智能车间 农产
图4.27 智能农业 、 学、 、 、
品绿色智能供应链等集成应用示范 如图427所示
, . 。
以往种植桃树的农民在收获后需要通过人力分拣桃子 不但所需
,
工时长 而且只能凭手感和肉眼观察进行分拣 误差较大 除了重量
, 出, 。 ,
桃子的外观 色泽 是否有伤疤等品相指标同样重要 人工挑选时难免
、 、 ,
会出现看错的情况 2018年 有些地区的果农用上了智能大桃分拣
。 ,
机 分拣机结合了开源平台提供的人工智能技术 能根据桃子的大小
, , 、
版
颜色 形状等自动分拣 省时省工 有了这台机器 往年琐碎繁重的桃
、 , 。 ,
子分拣工作变得轻松省力了
。
3. 智能物流
社
智能物流通过加强智能化装卸搬运 分拣包装
、 、
加工配送等智能物流装备的研发和推广应用 建设深
,
度感知智能仓储系统 提升仓储运营管理水平和效
,
率 如图428所示
, . 。
在国内某公司正着力打造的智慧物流中心里 从
,
图4.28 智能物流 入库 在库到拣货 分拣 装车 整个过程都无需人力
、 、 、 ,
136 数据与计算参与 使得仓储管理拥有极高的效率和出色的灵活性 这种以 无人
, 。 “
仓 作为载体的全新一代智能物流技术 其核心特色体现为数据感知
” , 、
机器人融入和算法指导生产 可以全面改变目前仓储的运营模式 极
, ,
华
大提升效率并降低人力消耗 与传统的仓储模式相比 无人仓 在运
。 ,“ ”
营效率 灵活性 吞吐量等方面跨上了一个新的台阶
、 、 。
东 4. 智能金融
智能金融借助金融大数据系统 提升金融多媒体数据的处理与理
,
师解能力 创新智能金融产品和服务 发展金融新业态 通过在金融行
, , 。
业应用智能客服 智能监控等技术和装备 可以有效建立金融风险智
、 ,
能预警与防控系统
。
范随着互联网的发展 一些不法分子利用商家规则和
,
技术的漏洞来牟取暴利 严重影响了普通用户的权益和
,
体验 从2016年至今 大数据风险控制相关产品已成
。 ,
功应用于电商 外卖 网约车 共享单车 医院 互联网金
大
、 、 、 、 、
融等行业 实现对营销作弊 身份冒用等主要金融风险
, 、
的自动识别 商家可以根据风险控制产品提供的分析
。 ,
限制风险用户的购买 下单等行为 保障真正用户的权
学、 ,
图4.29 智能金融 益 如图429所示
, . 。
5. 智能家居
出
加强人工智能技术与家居建筑系统的融合应用 研
,
发适应不同应用场景的家庭互联互通协议 接口标准
、 ,
版
提升家电 耐用品等家居产品的感知和联通能力 能够
、 ,
有效提升建筑设备及家居产品的智能化水平 如图430
, .
所示
图4.30 智能家居 。
社
如今的智能家居产品早已不再停留在概念阶段 智能语音助手
。
的快速崛起已经成为连接智能家居设备的重要 入口 可以实现包括
“ ”,
家居设备控制在内的多种语音操作功能 而智能安防产品的不断发
。
展 则明显提升了生活质量
, 。
二、 人工智能创新发展方向
2017年11月15日 国家科技部召开了新一代人工智能发展规划暨
,
第四章 走近人工智能 137重大科技项目启动会 会上宣布了首批国家新一代人工智能开放创新平
,
台 分别是智能语音平台 医疗影像平台 自动驾驶平台和城市大脑平台
, 、 、 。
华
1. 智能语音平台
智能语音旨在实现人机交互
东
无障碍 使人与机器之间可以通过
,
语音 图像 手势等自然交互方式
、 、 ,
进行持续 双向 自然的沟通 智
、 、 。
师 能语音平台并不是面向某个具体
应用场景而设计的 它可以应用于
,
诸多领域 如智能电视 可穿戴设
, 、
范 备 智能车载设备 移动应用中的
、 、
语音交互服务等 如图431所示
, . 。
图4.31 智能语音平台产品框架
大2. 医疗影像平台
医疗影像平台是一个医疗机
构 科研团体 器械厂商 高等院
学、 、 、
校 公益组织等多方参与的开放平
、
台 是由图像识别 大数据处理 深
, 、 、
度学习等领先技术与医学跨界融
出
合研发而成 其目的是共同推进人
,
工智能技术在医学影像 辅助诊
、
断 医疗机器人等众多医疗环节的
、
版
探索和应用 例如 基于人工智能
。 ,
技术的辅助诊疗系统主要功能如
图4.32 人工智能辅助诊疗系统功能示意
图432所示
. 。
社
3. 自动驾驶平台
自动驾驶平台将帮助汽车行业及自动驾驶领域的合作伙伴 结合
,
车辆和硬件设备 快速搭建一套自动驾驶系统 平台拥有海量数据仿
, 。
真引擎和基于深度学习的自动驾驶算法 并且能够为用户提供覆盖
,
广 高自动化的高精度地图服务 由此 用户可以更快地研发 测试和
、 。 , 、
部署自动驾驶车辆 平台也会在用户的参与下变得越来越完善
, 。
138 数据与计算4. 城市大脑平台
华
城市大脑平台可以对整个城市进行全局实时分析 自动调配公共
,
资源 修正城市运行中的漏洞 成为未来城市的基础设施 在已经部
, , 。
署城市大脑平台服务的地区 利用视频巡检替代人工巡检 日报警量
, ,
东
多达500余次 识别准确率在92 以上
, % ;
高架车辆道路通行时间缩短15 采用信
%;
号灯自动配时的路段 平均道路通行速度
,
师 提升15 应急车辆到达时间节省50
%; %。
城市大脑平台最理想的状态就是帮助我们
更高效地治理社会 如图433所示 除了
, . 。
范 交通治理之外 城市大脑平台还将能源 供
, 、
水等基础设施做数据化处理 以节约更多
,
的资源 实现城市的有效管理
, 。
图4.33 城市事件感知与智能处理
大
三、 人工智能对社会发展的影响
人工智能已经开始逐渐与各领域紧密结合 渗透人们日常生活的
学 ,
方方面面 极大地提高了人们的工作效率和服务水平 在一些具有确
, 。
定目标的任务中 人工智能已经表现出了更加优秀的性能 例如 某
, 。 ,
公安分局使用自动人脸识别系统后 在40个工作日内辨认出69名嫌
出,
疑人 相比人工识别的效率提升了近200倍 2018年6月 在由我国
, 。 ,
举办的全球神经影像人工智能人机大赛总决赛中 首次与公众正式见
,
面的神经影像人工智能辅助诊断系统以高出约20 的准确率战胜了
版%
人类战队 比赛中的 人类战队 由25名全球神经影像领域专家
“ ”。 “ ” 、
学者 优秀临床医生组成 而人工智能系统则基于某医院近十年来接
、 ,
诊的数万余神经系统相关疾病病例影像数据研发 人工智能技术产
。
生的巨大推动力 促使人类社会的各方面都社在发生着剧烈的变化
, 。
人工智能应用的目的是将人类从部分脑力劳动中解放出来 在
。
计算能力和数据储存方面 人工智能的优势毋庸置疑 一些原来由人
, ,
工方式通过相对简单的重复性劳动来完成的任务 已经开始被人工智
,
能应用所取代 但与此同时 新的工作岗位也在不断出现 并且对从
。 , ,
业者提出了更高的素质要求 特别是一些非标准化 不确定性强的任
。 、
务 需要从业者具有更加系统性 创造性和创新性的思维方式以及综
, 、
合应用多方面知识解决问题的能力
。
第四章 走近人工智能 139项 目 实 践
智慧城市 并不仅仅是为城市增加一些智能化系
华,
统 更是将人工智能和大数据技术应用于城市的发展
,
和优化 形成城市交通 城市医疗 工业制造 农业生产
, 、 、 、
等各个方面的智能化发展 如图 4.34所示 智慧城市
, 。
中的许多人工智东能应用都以大数据分析为基础 这其
,
中涉及了大量的个人私密信息 如何在提供智能服务
。
的同时 确保个人私密信息的安全 这是部署和实施人
, ,
工智能应用必不可少的前提
师。
随着人工智能在各行各业中的普及与应用 包括
,
图4.34 智慧城市
个人隐私泄露在内 究竟会引发哪些社会问题 请以
, ?
小组为单位 围绕人工智能可能产生的社会问题及应
,
对策略 展开讨论并撰写报告 交流范分享学习成果
, , 。
知 识 延 伸 大新一代人工智能发展方向
为构建开放协同的人工智能科
技创新体系 围绕增加人工智能创
, 学
新的源头供给 从前沿基础理论 关
, 、
键共性技术 基础平台 人才队伍等
、 、
方面强化部署 促进开源共享 系统
, ,
出
提升持续创新能力 确保我国人工
,
智能科技水平跻身世界前列 为世
,
界人工智能发展做出更多贡献 需
,
要建立新一代人工智能基础理论体
版
系 2017年初 中国工程院院刊信
。 ,
息与电子工程学部分刊 信息与电 图4.35 新一代人工智能的五大智能方向
《
子工程前沿 英文 发表了学术论
( )》
社
文 人工智能2.0 Special Issue on Artificial Intelligence 2.0 对新一代人工智能中所涉及的大数据智
《 》( ),
能 群体智能 跨媒体智能 混合增强智能和自主智能系统等进行了阐述 如图 4.35所示
、 、 、 , 。
新一代的人工智能有以下几个跃变 一是从人工知识表达到大数据驱动的知识学习技术 二是从分类
: ;
型处理的多媒体数据转向跨媒体的认知 学习 推理 三是从追求智能机器到高水平的人机 脑机相互协同
、 、 ; 、
和融合 四是从聚焦个体智能到基于互联网和大数据的群体智能 它可以把很多人的智能集聚融合起来变
; ,
成群体智能 五是从拟人化的机器人转向更加广阔的自主智能系统 并不是一个单纯的机器人才叫人工
; ,
智能
。
140 数据与计算后 记
华
东
师
本册教科书依据教育部 普通高中信息技术课程标准 2017年版
《 (
2020年修订 编写 并经国家教材委员会专家委员会审核通过 全
范)》 , 。
体编写人员认真领会国家基础教育改革精神 精心研究当代信息社会
,
的人才培养要求 广泛调研上海及各地高中信息技术教育的现状和挑
,
战 深入了解高中学生的学习需求 并汲取了上海市 普通高中信息科
, 大 , 《
技 试用本 的编写经验
( )》 。
编写过程中 上海市中小学 幼儿园 课程改革委员会专家工作委
, ( )
员会 上海市教育委员会教学研究室 上海市课程方案教育教学研究
, ,
学
基地 上海市心理教育教学研究基地 上海市基础教育教材建设研究
、 、
基地 上海市信息技术教育教学研究基地 上海高校 立德树人 人文
、 ( “ ”
社会科学重点研究基地 及基地所在单位华东师范大学等单位给予了
)
出
大力支持 李锋等老师作出了重要贡献 在此表示感谢
, 。 !
本册教科书出版之前 我们已通过多种渠道与教科书选用作品
,
包括照片 画作 的作者进行了联系 得到了他们的大力支持 对此
( 、 ) , 。 ,
我们衷心地表示感谢 恳请尚未联版系到的作者与我们联系 以便出版
! ,
社及时支付相关稿酬
。
我们真诚地希望广大教师 学生及家长在使用本册教科书的过程
、
中提出宝贵意见 我们将集思广益 不断修社订 使教科书趋于完善
。 , , 。
编 者
后 记 141 </div>
</div>
</div>
<div class="hnlfty60a7-65be-70e4-e753hnlfty copyright" style="margin-top: 18px; padding: 15px; text-align: center; color: #999; font-size: 12px; border-top: 1px solid #eee;">
本文档来自网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com。
</div>
<!-- 上一篇和下一篇 -->
<div style="margin-top: 30px; padding: 20px 0; border-top: 1px solid #eee; overflow: hidden;">
<div class="hnlfty65be-70e4-e753-29fehnlfty related-list" style="float: left; width: 48%;">
<div style="font-size: 12px; color: #999; margin-bottom: 5px;">上一篇</div>
<h3 style="margin: 0;"><a href="/wendang/463790.html" title="知识清单18原电池化学电源-上好课2025年高考化学一轮复习知识清单(新高考专用)(解析版)_05高考化学_2025年新高考资料_一轮复习" style="font-size: 14px; color: #555; text-decoration: none;">知识清单18原电池化学电源-上好课2025年高考化学一轮复习知识清单(新高考专用)(解析版)_05高考化学_2025年新高考资料_一轮复习</a></h3>
</div>
<div class="hnlfty65be-70e4-e753-29fehnlfty related-list" style="float: right; width: 48%; text-align: right;">
<div style="font-size: 12px; color: #999; margin-bottom: 5px;">下一篇</div>
<h3 style="margin: 0;"><a href="/wendang/463792.html" title="第二十四章圆知识归纳与题型突破(21题型清单)(学生版)_初中数学_九年级数学上册(人教版)_知识点汇总-U105_2025版" style="font-size: 14px; color: #555; text-decoration: none;">第二十四章圆知识归纳与题型突破(21题型清单)(学生版)_初中数学_九年级数学上册(人教版)_知识点汇总-U105_2025版</a></h3>
</div>
</div>
</div>
</div>
</div>
<!-- 侧边栏 -->
<div class="hnlfty70e4-e753-29fe-4e5fhnlfty aside l_box">
<div class="hnlftyce37-6cb2-a815-d07bhnlfty sidebar" id="side-new-document-item">
<div class="hnlfty6cb2-a815-d07b-284bhnlfty side-title">
<h3 class="hnlftya815-d07b-284b-a8f8hnlfty function_t">最新文档</h3>
</div>
<ul style="list-style: none; padding-left: 0;">
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480927.html" target="_blank" title="第2章第2节第2课时炔烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章第2节第2课时炔烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480926.html" target="_blank" title="2015-2016学年湖南省邵阳市武冈市九年级第一学期期末考试试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖南省邵阳市武冈市九年级第一学期期末考试试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480925.html" target="_blank" title="2015-2016学年湖南省株洲市攸县校级九年级(下)入学化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖南省株洲市攸县校级九年级(下)入学化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480924.html" target="_blank" title="第2章第2节第1课时烯烃讲义新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章第2节第1课时烯烃讲义新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480923.html" target="_blank" title="2015-2016学年湖南省岳阳市君山区岳西中学九年级(上)期末化学模拟试卷(一)(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖南省岳阳市君山区岳西中学九年级(上)期末化学模拟试卷(一)(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480922.html" target="_blank" title="2015-2016学年湖北省黄冈市黄梅县校级九年级(上)第四次月考化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖北省黄冈市黄梅县校级九年级(上)第四次月考化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480921.html" target="_blank" title="第2章第2节第1课时烯烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章第2节第1课时烯烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480920.html" target="_blank" title="2015-2016学年湖北省恩施州咸丰县校级九年级(上)期末化学复习试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖北省恩施州咸丰县校级九年级(上)期末化学复习试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480919.html" target="_blank" title="2015-2016学年湖北省宜昌市点军区九年级(上)期末化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖北省宜昌市点军区九年级(上)期末化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftyd07b-284b-a8f8-0e12hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480918.html" target="_blank" title="第2章第1节烷烃讲义新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章第1节烷烃讲义新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
</ul>
</div>
<div class="hnlftybb2c-60a7-65be-70e4hnlfty sidebar" id="side-hot-document-item">
<div class="hnlfty60a7-65be-70e4-e753hnlfty side-title">
<h3 class="hnlfty65be-70e4-e753-29fehnlfty function_t">热门文档</h3>
</div>
<ul style="list-style: none; padding-left: 0;">
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480917.html" target="_blank" title="第2章第1节烷烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章第1节烷烃习题新教材2020-2021学年人教版(2019)高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480916.html" target="_blank" title="2015-2016学年湖北省十堰市竹溪县九年级(上)期末化学模拟试卷(三)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年湖北省十堰市竹溪县九年级(上)期末化学模拟试卷(三)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480915.html" target="_blank" title="2015-2016学年浙江省绍兴市诸暨市五校联考九年级(上)期中化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年浙江省绍兴市诸暨市五校联考九年级(上)期中化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480914.html" target="_blank" title="第2章烃单元测试卷新教材2020-2021学年人教版2019高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章烃单元测试卷新教材2020-2021学年人教版2019高二化学选择性必修三(机构用)_高化_2025春-人教版高中化学_05新版高中化学选择性必修3_7.机构专用_讲义+习题(机构用)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480913.html" target="_blank" title="2015-2016学年河南省开封市祥符区西姜寨乡一中九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年河南省开封市祥符区西姜寨乡一中九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480912.html" target="_blank" title="2015-2016学年河南省开封市九年级(上)期末化学模拟试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年河南省开封市九年级(上)期末化学模拟试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480911.html" target="_blank" title="第2章化学反应速率与化学平衡-知识清单(人教版2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_选择性必修1册(人教版)_知识清单" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第2章化学反应速率与化学平衡-知识清单(人教版2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_选择性必修1册(人教版)_知识清单</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480910.html" target="_blank" title="2015-2016学年河北省石家庄市正定县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年河北省石家庄市正定县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480909.html" target="_blank" title="第29讲第四章《化学反应与电能》单元测试(基础巩固)(教师版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第29讲第四章《化学反应与电能》单元测试(基础巩固)(教师版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlfty70e4-e753-29fe-4e5fhnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480908.html" target="_blank" title="2015-2016学年河北省石家庄市正定县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年河北省石家庄市正定县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
</ul>
</div>
<div class="hnlftyb4d9-778d-9d4e-091ehnlfty sidebar" id="side-rand-document">
<div class="hnlfty778d-9d4e-091e-bb2chnlfty side-title">
<h3 class="hnlfty9d4e-091e-bb2c-60a7hnlfty function_t">随机文档</h3>
</div>
<ul style="list-style: none; padding-left: 0;">
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480907.html" target="_blank" title="2015-2016学年河北省唐山市乐亭县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年河北省唐山市乐亭县九年级(上)期末化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480906.html" target="_blank" title="2015-2016学年江西袁州区校级初三第三次化学模拟试题_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年江西袁州区校级初三第三次化学模拟试题_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480905.html" target="_blank" title="第29讲第四章《化学反应与电能》单元测试(基础巩固)(学生版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第29讲第四章《化学反应与电能》单元测试(基础巩固)(学生版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480904.html" target="_blank" title="2015-2016学年江西省校级中考模拟试题_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下_18春九化下(RJ)--7.各地真题" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年江西省校级中考模拟试题_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下_18春九化下(RJ)--7.各地真题</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480903.html" target="_blank" title="2015-2016学年度上学期初三模拟考试化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下_2015-2016中考模拟卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年度上学期初三模拟考试化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下_2015-2016中考模拟卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480902.html" target="_blank" title="2015-2016学年广西贵港市港南区校级九年级(上)联考化学试卷(二)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年广西贵港市港南区校级九年级(上)联考化学试卷(二)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_2015-2016中考模拟卷</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480901.html" target="_blank" title="第29讲第四章《化学反应与电能》单元测试(培优提升)(教师版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第29讲第四章《化学反应与电能》单元测试(培优提升)(教师版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480900.html" target="_blank" title="2015-2016学年广西玉林市博白县九年级(上)期末化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年广西玉林市博白县九年级(上)期末化学试卷_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学全套(课件--教案--配套)_18年初中化学9年级下</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480899.html" target="_blank" title="2015-2016学年广西玉林市博白县九年级(上)期中化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷_人教版九年级化学上册2018" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>2015-2016学年广西玉林市博白县九年级(上)期中化学试卷(解析版)_初中化学_01.人教版初中化学_01.初中化学课件PPT--教案--试题_初中化学18年试卷_人教版九年级化学上册2018</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
<li class="hnlftybb2c-60a7-65be-70e4hnlfty " style="padding-right: 10%;padding-bottom: 5px;">
<a href="/wendang/480898.html" target="_blank" title="第29讲第四章《化学反应与电能》单元测试(培优提升)(学生版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义" style="display: inline-flex; align-items: center;">
<img src="https://static.diaifu.net/ssd/ssd5/wenku/word.png" alt="word" style="width: 32px; height: 32px; vertical-align: middle; margin-right: 5px; flex-shrink: 0;">
<span>第29讲第四章《化学反应与电能》单元测试(培优提升)(学生版)-(人教2019选择性必修1)_高化_595801221724高中化学新人教版选择性必修一二三电子版教案PPT课件高中试卷_讲义</span>
</a>
</li>
<!-- 增加一条浅色分割线 -->
<div style="height: 2px; background-color: #f0f0f0; margin: 10px 0;"></div>
</ul>
</div>
</div>
<!-- baidu_img 百度图片 三秒钟后自动消失 -->
<script>
setTimeout(function() {
$('.baidu_img').fadeOut(1000);
}, 3000);
</script>
</div>
<footer>
<!-- 只在index/index显示友情链接 -->
</p>
<!-- 百度统计开始 -->
<script>
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?e3c7c646f6dc3939a45e787390380a8a";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
<!-- 百度统计结束 -->
<style>
#think_page_trace {position:fixed; bottom:0; right:0; font-size:14px; width:100%; z-index:999999; color:#000; text-align:left; font-family:'微软雅黑';}
#think_page_trace_tab {display:none; background:white; margin:0; height: 250px;}
#think_page_trace_tab_tit {height:30px; padding: 6px 12px 0; border-bottom:1px solid #ececec; border-top:1px solid #ececec; font-size:16px;}
#think_page_trace_tab_tit>span {color:#000; padding-right:12px; height:30px; line-height:30px; display:inline-block; margin-right:3px; cursor:pointer; font-weight:700;}
#think_page_trace_tab_cont {overflow:auto; height:212px; padding:0; line-height:24px;}
#think_page_trace_tab_cont>div {display:none;}
#think_page_trace_tab_cont>div>ol {padding:0; margin:0;}
#think_page_trace_tab_cont>div>ol>li {border-bottom:1px solid #eee; font-size:14px; padding:0 12px;}
#think_page_trace_close {display:none; text-align:right; height:15px; position:absolute; top:10px; right:12px; cursor:pointer; z-index: 999999;}
#think_page_trace_close>img {vertical-align:top;}
#think_page_trace_open {height:30px; float:right; text-align:right; overflow:hidden; position:fixed; bottom:0; right:0; color:#000; line-height:30px; cursor:pointer; z-index:999999;}
#think_page_trace_open>div {background:#232323; color:#fff; padding:0 6px; float:right; line-height:30px; font-size:14px;}
</style>
<div id="think_page_trace">
<div id="think_page_trace_tab">
<div id="think_page_trace_tab_tit">
<span>基本</span>
<span>文件</span>
<span>流程</span>
<span>错误</span>
<span>SQL</span>
<span>调试</span>
</div>
<div id="think_page_trace_tab_cont">
<div>
<ol>
<li>请求信息 : 2026-04-02 15:45:48 HTTP/1.1 GET : https://www.yeyulingfeng.com/wendang/463791.html</li><li>运行时间 : 0.221364s [ 吞吐率:4.52req/s ] 内存消耗:6,639.49kb 文件加载:144</li><li>缓存信息 : 0 reads,0 writes</li><li>会话信息 : SESSION_ID=2fdcff809fb9d0daadd732363f3733e9</li> </ol>
</div>
<div>
<ol>
<li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/public/index.php ( 0.79 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/autoload.php ( 0.17 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/composer/autoload_real.php ( 2.49 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/composer/platform_check.php ( 0.90 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/composer/ClassLoader.php ( 14.03 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/composer/autoload_static.php ( 6.05 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/helper.php ( 8.34 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-validate/src/helper.php ( 2.19 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/ralouphie/getallheaders/src/getallheaders.php ( 1.60 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/helper.php ( 1.47 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/stubs/load_stubs.php ( 0.16 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Exception.php ( 1.69 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-container/src/Facade.php ( 2.71 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/symfony/deprecation-contracts/function.php ( 0.99 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/symfony/polyfill-mbstring/bootstrap.php ( 8.26 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/symfony/polyfill-mbstring/bootstrap80.php ( 9.78 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/symfony/var-dumper/Resources/functions/dump.php ( 1.49 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-dumper/src/helper.php ( 0.18 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/symfony/var-dumper/VarDumper.php ( 4.30 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/guzzlehttp/guzzle/src/functions_include.php ( 0.16 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/guzzlehttp/guzzle/src/functions.php ( 5.54 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/App.php ( 15.30 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-container/src/Container.php ( 15.76 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/psr/container/src/ContainerInterface.php ( 1.02 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/provider.php ( 0.19 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Http.php ( 6.04 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/helper/Str.php ( 7.29 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Env.php ( 4.68 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/common.php ( 0.03 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/helper.php ( 18.78 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Config.php ( 5.54 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/alipay.php ( 3.59 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/facade/Env.php ( 1.67 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/app.php ( 0.95 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/cache.php ( 0.78 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/console.php ( 0.23 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/cookie.php ( 0.56 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/database.php ( 2.48 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/filesystem.php ( 0.61 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/lang.php ( 0.91 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/log.php ( 1.35 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/middleware.php ( 0.19 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/route.php ( 1.89 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/session.php ( 0.57 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/trace.php ( 0.34 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/config/view.php ( 0.82 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/event.php ( 0.25 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Event.php ( 7.67 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/service.php ( 0.13 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/AppService.php ( 0.26 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Service.php ( 1.64 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Lang.php ( 7.35 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/lang/zh-cn.php ( 13.70 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/initializer/Error.php ( 3.31 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/initializer/RegisterService.php ( 1.33 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/services.php ( 0.14 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/service/PaginatorService.php ( 1.52 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/service/ValidateService.php ( 0.99 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/service/ModelService.php ( 2.04 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-trace/src/Service.php ( 0.77 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Middleware.php ( 6.72 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/initializer/BootService.php ( 0.77 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/Paginator.php ( 11.86 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-validate/src/Validate.php ( 63.20 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/Model.php ( 23.55 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/Attribute.php ( 21.05 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/AutoWriteData.php ( 4.21 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/Conversion.php ( 6.44 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/DbConnect.php ( 5.16 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/ModelEvent.php ( 2.33 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/concern/RelationShip.php ( 28.29 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/contract/Arrayable.php ( 0.09 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/contract/Jsonable.php ( 0.13 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/model/contract/Modelable.php ( 0.09 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Db.php ( 2.88 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/DbManager.php ( 8.52 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Log.php ( 6.28 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Manager.php ( 3.92 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/psr/log/src/LoggerTrait.php ( 2.69 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/psr/log/src/LoggerInterface.php ( 2.71 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Cache.php ( 4.92 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/psr/simple-cache/src/CacheInterface.php ( 4.71 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/helper/Arr.php ( 16.63 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/cache/driver/File.php ( 7.84 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/cache/Driver.php ( 9.03 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/contract/CacheHandlerInterface.php ( 1.99 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/Request.php ( 0.09 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Request.php ( 55.78 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/middleware.php ( 0.25 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Pipeline.php ( 2.61 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-trace/src/TraceDebug.php ( 3.40 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/middleware/SessionInit.php ( 1.94 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Session.php ( 1.80 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/session/driver/File.php ( 6.27 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/contract/SessionHandlerInterface.php ( 0.87 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/session/Store.php ( 7.12 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Route.php ( 23.73 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/RuleName.php ( 5.75 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/Domain.php ( 2.53 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/RuleGroup.php ( 22.43 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/Rule.php ( 26.95 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/RuleItem.php ( 9.78 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/route/app.php ( 3.94 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/facade/Route.php ( 4.70 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/dispatch/Controller.php ( 4.74 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/route/Dispatch.php ( 10.44 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/controller/Index.php ( 9.87 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/app/BaseController.php ( 2.05 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/facade/Db.php ( 0.93 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/connector/Mysql.php ( 5.44 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/PDOConnection.php ( 52.47 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/Connection.php ( 8.39 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/ConnectionInterface.php ( 4.57 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/builder/Mysql.php ( 16.58 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/Builder.php ( 24.06 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/BaseBuilder.php ( 27.50 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/Query.php ( 15.71 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/BaseQuery.php ( 45.13 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/TimeFieldQuery.php ( 7.43 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/AggregateQuery.php ( 3.26 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/ModelRelationQuery.php ( 20.07 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/ParamsBind.php ( 3.66 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/ResultOperation.php ( 7.01 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/WhereQuery.php ( 19.37 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/JoinAndViewQuery.php ( 7.11 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/TableFieldInfo.php ( 2.63 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-orm/src/db/concern/Transaction.php ( 2.77 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/log/driver/File.php ( 5.96 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/contract/LogHandlerInterface.php ( 0.86 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/log/Channel.php ( 3.89 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/event/LogRecord.php ( 1.02 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-helper/src/Collection.php ( 16.47 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/facade/View.php ( 1.70 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/View.php ( 4.39 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Response.php ( 8.81 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/response/View.php ( 3.29 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/Cookie.php ( 6.06 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-view/src/Think.php ( 8.38 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/framework/src/think/contract/TemplateHandlerInterface.php ( 1.60 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-template/src/Template.php ( 46.61 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-template/src/template/driver/File.php ( 2.41 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-template/src/template/contract/DriverInterface.php ( 0.86 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/runtime/temp/10a0c909b6afa23b5a52a2e2d58c3c0f.php ( 22.02 KB )</li><li>/yingpanguazai/ssd/ssd1/www/wwww.yeyulingfeng.com/vendor/topthink/think-trace/src/Html.php ( 4.42 KB )</li> </ol>
</div>
<div>
<ol>
</ol>
</div>
<div>
<ol>
</ol>
</div>
<div>
<ol>
<li>CONNECT:[ UseTime:0.000954s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4</li><li>SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.001494s ]</li><li>SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000676s ]</li><li>SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.009311s ]</li><li>SHOW FULL COLUMNS FROM `set` [ RunTime:0.001276s ]</li><li>SELECT * FROM `set` [ RunTime:0.000560s ]</li><li>SHOW FULL COLUMNS FROM `wendang` [ RunTime:0.001415s ]</li><li>SELECT * FROM `wendang` WHERE `id` = 463791 LIMIT 1 [ RunTime:0.003273s ]</li><li>UPDATE `wendang` SET `liulancishu` = 9 WHERE `id` = 463791 [ RunTime:0.036173s ]</li><li>UPDATE `wendang` SET `lasttime` = 1775115948 WHERE `id` = 463791 [ RunTime:0.001404s ]</li><li>SELECT * FROM `wendang` WHERE `id` < 463791 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.001253s ]</li><li>SELECT * FROM `wendang` WHERE `id` > 463791 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.006121s ]</li><li>SELECT * FROM `wendang` WHERE `id` <> 463791 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.004942s ]</li><li>SELECT * FROM `wendang` WHERE `id` <> 463791 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.003160s ]</li><li>SELECT * FROM `wendang` WHERE `id` <> 463791 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.002181s ]</li> </ol>
</div>
<div>
<ol>
</ol>
</div>
</div>
</div>
<div id="think_page_trace_close">
<img src="data:image/gif;base64,R0lGODlhDwAPAJEAAAAAAAMDA////wAAACH/C1hNUCBEYXRhWE1QPD94cGFja2V0IGJlZ2luPSLvu78iIGlkPSJXNU0wTXBDZWhpSHpyZVN6TlRjemtjOWQiPz4gPHg6eG1wbWV0YSB4bWxuczp4PSJhZG9iZTpuczptZXRhLyIgeDp4bXB0az0iQWRvYmUgWE1QIENvcmUgNS4wLWMwNjAgNjEuMTM0Nzc3LCAyMDEwLzAyLzEyLTE3OjMyOjAwICAgICAgICAiPiA8cmRmOlJERiB4bWxuczpyZGY9Imh0dHA6Ly93d3cudzMub3JnLzE5OTkvMDIvMjItcmRmLXN5bnRheC1ucyMiPiA8cmRmOkRlc2NyaXB0aW9uIHJkZjphYm91dD0iIiB4bWxuczp4bXA9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC8iIHhtbG5zOnhtcE1NPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvbW0vIiB4bWxuczpzdFJlZj0iaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wL3NUeXBlL1Jlc291cmNlUmVmIyIgeG1wOkNyZWF0b3JUb29sPSJBZG9iZSBQaG90b3Nob3AgQ1M1IFdpbmRvd3MiIHhtcE1NOkluc3RhbmNlSUQ9InhtcC5paWQ6MUQxMjc1MUJCQUJDMTFFMTk0OUVGRjc3QzU4RURFNkEiIHhtcE1NOkRvY3VtZW50SUQ9InhtcC5kaWQ6MUQxMjc1MUNCQUJDMTFFMTk0OUVGRjc3QzU4RURFNkEiPiA8eG1wTU06RGVyaXZlZEZyb20gc3RSZWY6aW5zdGFuY2VJRD0ieG1wLmlpZDoxRDEyNzUxOUJBQkMxMUUxOTQ5RUZGNzdDNThFREU2QSIgc3RSZWY6ZG9jdW1lbnRJRD0ieG1wLmRpZDoxRDEyNzUxQUJBQkMxMUUxOTQ5RUZGNzdDNThFREU2QSIvPiA8L3JkZjpEZXNjcmlwdGlvbj4gPC9yZGY6UkRGPiA8L3g6eG1wbWV0YT4gPD94cGFja2V0IGVuZD0iciI/PgH//v38+/r5+Pf29fTz8vHw7+7t7Ovq6ejn5uXk4+Lh4N/e3dzb2tnY19bV1NPS0dDPzs3My8rJyMfGxcTDwsHAv769vLu6ubi3trW0s7KxsK+urayrqqmop6alpKOioaCfnp2cm5qZmJeWlZSTkpGQj46NjIuKiYiHhoWEg4KBgH9+fXx7enl4d3Z1dHNycXBvbm1sa2ppaGdmZWRjYmFgX15dXFtaWVhXVlVUU1JRUE9OTUxLSklIR0ZFRENCQUA/Pj08Ozo5ODc2NTQzMjEwLy4tLCsqKSgnJiUkIyIhIB8eHRwbGhkYFxYVFBMSERAPDg0MCwoJCAcGBQQDAgEAACH5BAAAAAAALAAAAAAPAA8AAAIdjI6JZqotoJPR1fnsgRR3C2jZl3Ai9aWZZooV+RQAOw==" />
</div>
</div>
<div id="think_page_trace_open">
<div>0.222983s </div>
<img width="30" style="" title="ShowPageTrace" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAADAAAAAwCAYAAABXAvmHAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAyBpVFh0WE1MOmNvbS5hZG9iZS54bXAAAAAAADw/eHBhY2tldCBiZWdpbj0i77u/IiBpZD0iVzVNME1wQ2VoaUh6cmVTek5UY3prYzlkIj8+IDx4OnhtcG1ldGEgeG1sbnM6eD0iYWRvYmU6bnM6bWV0YS8iIHg6eG1wdGs9IkFkb2JlIFhNUCBDb3JlIDUuMC1jMDYwIDYxLjEzNDc3NywgMjAxMC8wMi8xMi0xNzozMjowMCAgICAgICAgIj4gPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4gPHJkZjpEZXNjcmlwdGlvbiByZGY6YWJvdXQ9IiIgeG1sbnM6eG1wPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvIiB4bWxuczp4bXBNTT0iaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wL21tLyIgeG1sbnM6c3RSZWY9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9zVHlwZS9SZXNvdXJjZVJlZiMiIHhtcDpDcmVhdG9yVG9vbD0iQWRvYmUgUGhvdG9zaG9wIENTNSBXaW5kb3dzIiB4bXBNTTpJbnN0YW5jZUlEPSJ4bXAuaWlkOjVERDVENkZGQjkyNDExRTE5REY3RDQ5RTQ2RTRDQUJCIiB4bXBNTTpEb2N1bWVudElEPSJ4bXAuZGlkOjVERDVENzAwQjkyNDExRTE5REY3RDQ5RTQ2RTRDQUJCIj4gPHhtcE1NOkRlcml2ZWRGcm9tIHN0UmVmOmluc3RhbmNlSUQ9InhtcC5paWQ6NURENUQ2RkRCOTI0MTFFMTlERjdENDlFNDZFNENBQkIiIHN0UmVmOmRvY3VtZW50SUQ9InhtcC5kaWQ6NURENUQ2RkVCOTI0MTFFMTlERjdENDlFNDZFNENBQkIiLz4gPC9yZGY6RGVzY3JpcHRpb24+IDwvcmRmOlJERj4gPC94OnhtcG1ldGE+IDw/eHBhY2tldCBlbmQ9InIiPz5fx6IRAAAMCElEQVR42sxae3BU1Rk/9+69+8xuNtkHJAFCSIAkhMgjCCJQUi0GtEIVbP8Qq9LH2No6TmfaztjO2OnUdvqHFMfOVFTqIK0vUEEeqUBARCsEeYQkEPJoEvIiELLvvc9z+p27u2F3s5tsBB1OZiebu5dzf7/v/L7f952zMM8cWIwY+Mk2ulCp92Fnq3XvnzArr2NZnYNldDp0Gw+/OEQ4+obQn5D+4Ubb22+YOGsWi/Todh8AHglKEGkEsnHBQ162511GZFgW6ZCBM9/W4H3iNSQqIe09O196dLKX7d1O39OViP/wthtkND62if/wj/DbMpph8BY/m9xy8BoBmQk+mHqZQGNy4JYRwCoRbwa8l4JXw6M+orJxpU0U6ToKy/5bQsAiTeokGKkTx46RRxxEUgrwGgF4MWNNEJCGgYTvpgnY1IJWg5RzfqLgvcIgktX0i8dmMlFA8qCQ5L0Z/WObPLUxT1i4lWSYDISoEfBYGvM+LlMQQdkLHoWRRZ8zYQI62Thswe5WTORGwNXDcGjqeOA9AF7B8rhzsxMBEoJ8oJKaqPu4hblHMCMPwl9XeNWyb8xkB/DDGYKfMAE6aFL7xesZ389JlgG3XHEMI6UPDOP6JHHu67T2pwNPI69mCP4rEaBDUAJaKc/AOuXiwH07VCS3w5+UQMAuF/WqGI+yFIwVNBwemBD4r0wgQiKoFZa00sEYTwss32lA1tPwVxtc8jQ5/gWCwmGCyUD8vRT0sHBFW4GJDvZmrJFWRY1EkrGA6ZB8/10fOZSSj0E6F+BSP7xidiIzhBmKB09lEwHPkG+UQIyEN44EBiT5vrv2uJXyPQqSqO930fxvcvwbR/+JAkD9EfASgI9EHlp6YiHO4W+cAB20SnrFqxBbNljiXf1Pl1K2S0HCWfiog3YlAD5RGwwxK6oUjTweuVigLjyB0mX410mAFnMoVK1lvvUvgt8fUJH0JVyjuvcmg4dE5mUiFtD24AZ4qBVELxXKS+pMxN43kSdzNwudJ+bQbLlmnxvPOQoCugSap1GnSRoG8KOiKbH+rIA0lEeSAg3y6eeQ6XI2nrYnrPM89bUTgI0Pdqvl50vlNbtZxDUBcLBK0kPd5jPziyLdojJIN0pq5/mdzwL4UVvVInV5ncQEPNOUxa9d0TU+CW5l+FoI0GSDKHVVSOs+0KOsZoxwOzSZNFGv0mQ9avyLCh2Hpm+70Y0YJoJVgmQv822wnDC8Miq6VjJ5IFed0QD1YiAbT+nQE8v/RMZfmgmcCRHIIu7Bmcp39oM9fqEychcA747KxQ/AEyqQonl7hATtJmnhO2XYtgcia01aSbVMenAXrIomPcLgEBA4liGBzFZAT8zBYqW6brI67wg8sFVhxBhwLwBP2+tqBQqqK7VJKGh/BRrfTr6nWL7nYBaZdBJHqrX3kPEPap56xwE/GvjJTRMADeMCdcGpGXL1Xh4ZL8BDOlWkUpegfi0CeDzeA5YITzEnddv+IXL+UYCmqIvqC9UlUC/ki9FipwVjunL3yX7dOTLeXmVMAhbsGporPfyOBTm/BJ23gTVehsvXRnSewagUfpBXF3p5pygKS7OceqTjb7h2vjr/XKm0ZofKSI2Q/J102wHzatZkJPYQ5JoKsuK+EoHJakVzubzuLQDepCKllTZi9AG0DYg9ZLxhFaZsOu7bvlmVI5oPXJMQJcHxHClSln1apFTvAimeg48u0RWFeZW4lVcjbQWZuIQK1KozZfIDO6CSQmQQXdpBaiKZyEWThVK1uEc6v7V7uK0ysduExPZx4vysDR+4SelhBYm0R6LBuR4PXts8MYMcJPsINo4YZCDLj0sgB0/vLpPXvA2Tn42Cv5rsLulGubzW0sEd3d4W/mJt2Kck+DzDMijfPLOjyrDhXSh852B+OvflqAkoyXO1cYfujtc/i3jJSAwhgfFlp20laMLOku/bC7prgqW7lCn4auE5NhcXPd3M7x70+IceSgZvNljCd9k3fLjYsPElqLR14PXQZqD2ZNkkrAB79UeJUebFQmXpf8ZcAQt2XrMQdyNUVBqZoUzAFyp3V3xi/MubUA/mCT4Fhf038PC8XplhWnCmnK/ZzyC2BSTRSqKVOuY2kB8Jia0lvvRIVoP+vVWJbYarf6p655E2/nANBMCWkgD49DA0VAMyI1OLFMYCXiU9bmzi9/y5i/vsaTpHPHidTofzLbM65vMPva9HlovgXp0AvjtaqYMfDD0/4mAsYE92pxa+9k1QgCnRVObCpojpzsKTPvayPetTEgBdwnssjuc0kOBFX+q3HwRQxdrOLAqeYRjkMk/trTSu2Z9Lik7CfF0AvjtqAhS4NHobGXUnB5DQs8hG8p/wMX1r4+8xkmyvQ50JVq72TVeXbz3HvpWaQJi57hJYTw4kGbtS+C2TigQUtZUX+X27QQq2ePBZBru/0lxTm8fOOQ5yaZOZMAV+he4FqIMB+LQB0UgMSajANX29j+vbmly8ipRvHeSQoQOkM5iFXcPQCVwDMs5RBCQmaPOyvbNd6uwvQJ183BZQG3Zc+Eiv7vQOKu8YeDmMcJlt2ckyftVeMIGLBCmdMHl/tFILYwGPjXWO3zOfSq/+om+oa7Mlh2fpSsRGLp7RAW3FUVjNHgiMhyE6zBFjM2BdkdJGO7nP1kJXWAtBuBpPIAu7f+hhu7bFXIuC5xWrf0X2xreykOsUyKkF2gwadbrXDcXrfKxR43zGcSj4t/cCgr+a1iy6EjE5GYktUCl9fwfMeylyooGF48bN2IGLTw8x7StS7sj8TF9FmPGWQhm3rRR+o9lhvjJvSYAdfDUevI1M6bnX/OwWaDMOQ8RPgKRo0eulBTdT8AW2kl8e9L7UHghHwMfLiZPNoSpx0yugpQZaFqKWqxVSM3a2pN1SAhC2jf94I7ybBI7EL5A2Wvu5ht3xsoEt4+Ay/abXgCQAxyOeDsDlTCQzy75ohcGgv9Tra9uiymRUYTLrswOLlCdfAQf7HPDQQ4ErAH5EDXB9cMxWYpjtXApRncojS0sbV/cCgHTHwGNBJy+1PQE2x56FpaVR7wfQGZ37V+V+19EiHNvR6q1fRUjqvbjbMq1/qfHxbTrE10ePY2gPFk48D2CVMTf1AF4PXvyYR9dV6Wf7H413m3xTWQvYGhQ7mfYwA5mAX+18Vue05v/8jG/fZX/IW5MKPKtjSYlt0ellxh+/BOCPAwYaeVr0QofZFxJWVWC8znG70au6llVmktsF0bfHF6k8fvZ5esZJbwHwwnjg59tXz6sL/P0NUZDuSNu1mnJ8Vab17+cy005A9wtOpp3i0bZdpJLUil00semAwN45LgEViZYe3amNye0B6A9chviSlzXVsFtyN5/1H3gaNmMpn8Fz0GpYFp6Zw615H/LpUuRQQDMCL82n5DpBSawkvzIdN2ypiT8nSLth8Pk9jnjwdFzH3W4XW6KMBfwB569NdcGX93mC16tTflcArcYUc/mFuYbV+8zY0SAjAVoNErNgWjtwumJ3wbn/HlBFYdxHvSkJJEc+Ngal9opSwyo9YlITX2C/P/+gf8sxURSLR+mcZUmeqaS9wrh6vxW5zxFCOqFi90RbDWq/YwZmnu1+a6OvdpvRqkNxxe44lyl4OobEnpKA6Uox5EfH9xzPs/HRKrTPWdIQrK1VZDU7ETiD3Obpl+8wPPCRBbkbwNtpW9AbBe5L1SMlj3tdTxk/9W47JUmqS5HU+JzYymUKXjtWVmT9RenIhgXc+nroWLyxXJhmL112OdB8GCsk4f8oZJucnvmmtR85mBn10GZ0EKSCMUSAR3ukcXd5s7LvLD3me61WkuTCpJzYAyRurMB44EdEJzTfU271lUJC03YjXJXzYOGZwN4D8eB5jlfLrdWfzGRW7icMPfiSO6Oe7s20bmhdgLX4Z23B+s3JgQESzUDiMboSzDMHFpNMwccGePauhfwjzwnI2wu9zKGgEFg80jcZ7MHllk07s1H+5yojtUQTlH4nFdLKTGwDmPbIklOb1L1zO4T6N8NCuDLFLS/C63c0eNRimZ++s5BMBHxU11jHchI9oFVUxRh/eMDzHEzGYu0Lg8gJ7oS/tFCwoic44fyUtix0n/46vP4bf+//BRgAYwDDar4ncHIAAAAASUVORK5CYII=">
</div>
<script type="text/javascript">
(function(){
var tab_tit = document.getElementById('think_page_trace_tab_tit').getElementsByTagName('span');
var tab_cont = document.getElementById('think_page_trace_tab_cont').getElementsByTagName('div');
var open = document.getElementById('think_page_trace_open');
var close = document.getElementById('think_page_trace_close').children[0];
var trace = document.getElementById('think_page_trace_tab');
var cookie = document.cookie.match(/thinkphp_show_page_trace=(\d\|\d)/);
var history = (cookie && typeof cookie[1] != 'undefined' && cookie[1].split('|')) || [0,0];
open.onclick = function(){
trace.style.display = 'block';
this.style.display = 'none';
close.parentNode.style.display = 'block';
history[0] = 1;
document.cookie = 'thinkphp_show_page_trace='+history.join('|')
}
close.onclick = function(){
trace.style.display = 'none';
this.parentNode.style.display = 'none';
open.style.display = 'block';
history[0] = 0;
document.cookie = 'thinkphp_show_page_trace='+history.join('|')
}
for(var i = 0; i < tab_tit.length; i++){
tab_tit[i].onclick = (function(i){
return function(){
for(var j = 0; j < tab_cont.length; j++){
tab_cont[j].style.display = 'none';
tab_tit[j].style.color = '#999';
}
tab_cont[i].style.display = 'block';
tab_tit[i].style.color = '#000';
history[1] = i;
document.cookie = 'thinkphp_show_page_trace='+history.join('|')
}
})(i)
}
parseInt(history[0]) && open.click();
tab_tit[history[1]].click();
})();
</script>
</body>
</html>