 夜雨聆风
夜雨聆风





Go sync.Map 源码深度解析

引言
sync.Map 是一个专门为读多写少场景设计的并发安全 map。它通过”双 map + entry 指针共享”的巧妙设计,实现了对 read 中 key 的无锁读写删操作
但 sync.Map 的源码并不简单:延迟删除、nil/expunged 双删除态、dirty 自动升级等机制环环相扣。本文基于源码1.23.6 逐行拆解这些设计,带你彻底理解 sync.Map 的工作原理。
要彻底理解sync.Map,核心是理解下面几个问题:
1. sync.Map 的数据结构、读、写、删除流程是怎样的?
2. 为什么删除操作要用 CAS p = nil 而不是直接修改 map 结构?如果直接在 readOnly.m 上 delete(key) 有什么问题?
3. 为什么value的删除态有两个?nil 和 expunged 有何区别?
4. dirty到readOnly的升级机制是什么?
目录
-
一、核心数据结构 -
1.0 整体架构图 -
1.1 Map 结构体 -
1.2 readOnly 结构体 -
1.3 entry 结构体 -
二、核心方法解析 -
2.1 Load – 加载数据 -
2.2 Store – 存储数据 -
2.3 Swap – 原子交换(核心写方法) -
2.4 LoadAndDelete – 原子删除 -
2.5 Range – 遍历 -
三、核心机制深度解析 -
3.1 完整数据流:read、dirty 与 miss 的协作周期 -
3.2 延迟删除机制 -
四、sync.Map 适用场景 -
总结 -
关键问题解答
一、核心数据结构
在深入每个方法的源码之前,我们先从整体上把握 sync.Map 的数据结构设计
1.0 整体架构图
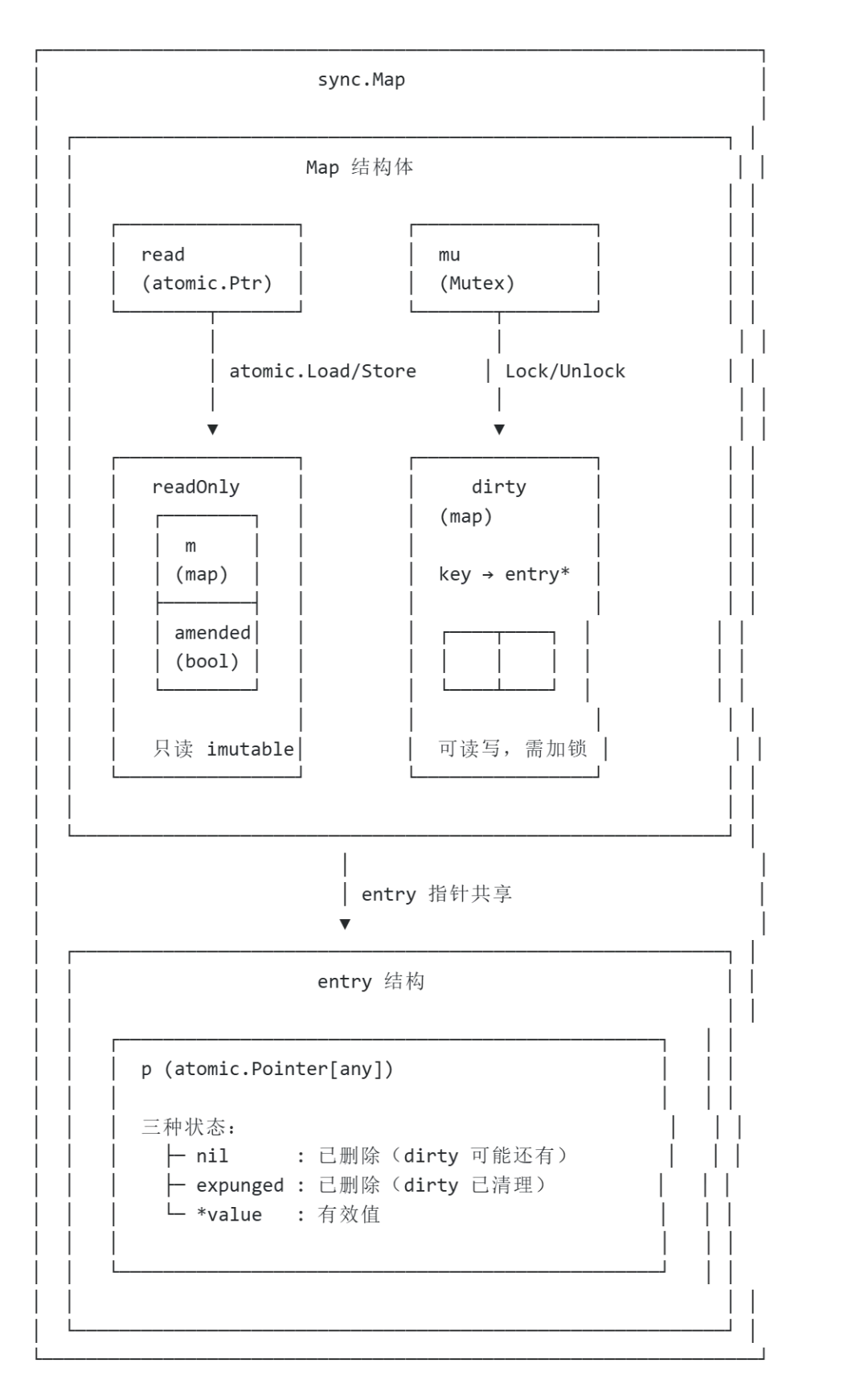
sync.Map 的核心设计是”双 map + entry 指针共享“:
-
read:只读 map,通过原子操作访问,无需加锁,承载大部分读请求 -
dirty:可写 map,需加锁访问,承载写操作和 read 未命中的读操作 -
entry:read 和 dirty 共享同一个 entry 指针,修改 entry.p 会同时影响两个 map,避免数据不一致
在阅读源码之前,需要理解几个核心设定:
为什么要两个 map?
read 通过 atomic.Pointer 访问,读取时无需加锁。但如果直接在 read 上做写操作(增删改),就需要加锁来保证并发安全,这会拖慢读性能。所以 sync.Map 把”写”操作下放到 dirty,让 read 保持纯净的无锁读取。当 dirty 中的数据积累到一定程度(miss 次数 >= len(dirty)),再将 dirty 整体提升为新的 read,减少miss发生的概率
为什么两个 map 的 value 要指向同一个 entry?
因为 read 和 dirty 中可能同时存在同一个 key。如果它们各自持有独立的 entry 副本,修改其中一个另一个不会感知到,导致数据不一致。共享 entry 指针后,无论是从 read 还是 dirty 修改值,另一个 map 都能看到变化,避免了复杂的同步逻辑
一个重要的不变量(invariant):
如果 dirty 不为 nil,那么 dirty 一定包含 read 中所有未被删除(p != expunged)的 entry。这个不变量保证了:
-
当 read 中找不到 key 时,dirty 中可能有(amended = true 时) -
当 read 中找到了 key 且 p != expunged 时,dirty 中一定也有(dirty 不为 nil 时) -
当 read 中找到了 key 但 p = expunged 时,dirty 中一定没有(因为 expunged 正是在 dirty 重建时被排除的)
1.1 Map 结构体
type Map struct { _ noCopy // 禁止拷贝(静态分析检测) mu Mutex // 互斥锁,仅保护 dirty map// 原子指针,指向只读的 readOnly 结构// 这是"读通道",可以无锁并发读取(但写入时需通过 atomic 操作) read atomic.Pointer[readOnly]// 原始 map,需要加锁访问// 这是"写通道",所有写操作和 read 未命中的读操作都走这里 dirty map[any]*entry// 计数器:记录自上次 read 更新以来,有多少 Load 操作需要加锁才能找到 key// 当 misses >= len(dirty) 时,dirty 会被升级为新的 read misses int}1.2 readOnly 结构体
type readOnly struct { m map[any]*entry // 只读 map,存储有效的键值对(不可变) amended bool// 标记位:dirty 中是否存在 read 中没有的 key// 为 true 时,表示 dirty 有额外的 key,需要加锁处理}1.3 entry 结构体
type entry struct {// 原子指针,存储实际的值// 三种状态:// p == nil: 已被删除(但 entry 仍存在于 map 中)// p == expunged: 已被删除,且不在 dirty 中(脏数据已清理)// p == 其他: 有效的键值对 p atomic.Pointer[any]}这种设计实现了延迟删除:删除时只将值设为 nil 或 expunged,而不是真正移除 entry,从而避免复杂的同步操作。
二、核心方法解析
了解了数据结构,接下来我们逐个分析 sync.Map 的核心方法
2.1 Load – 加载数据
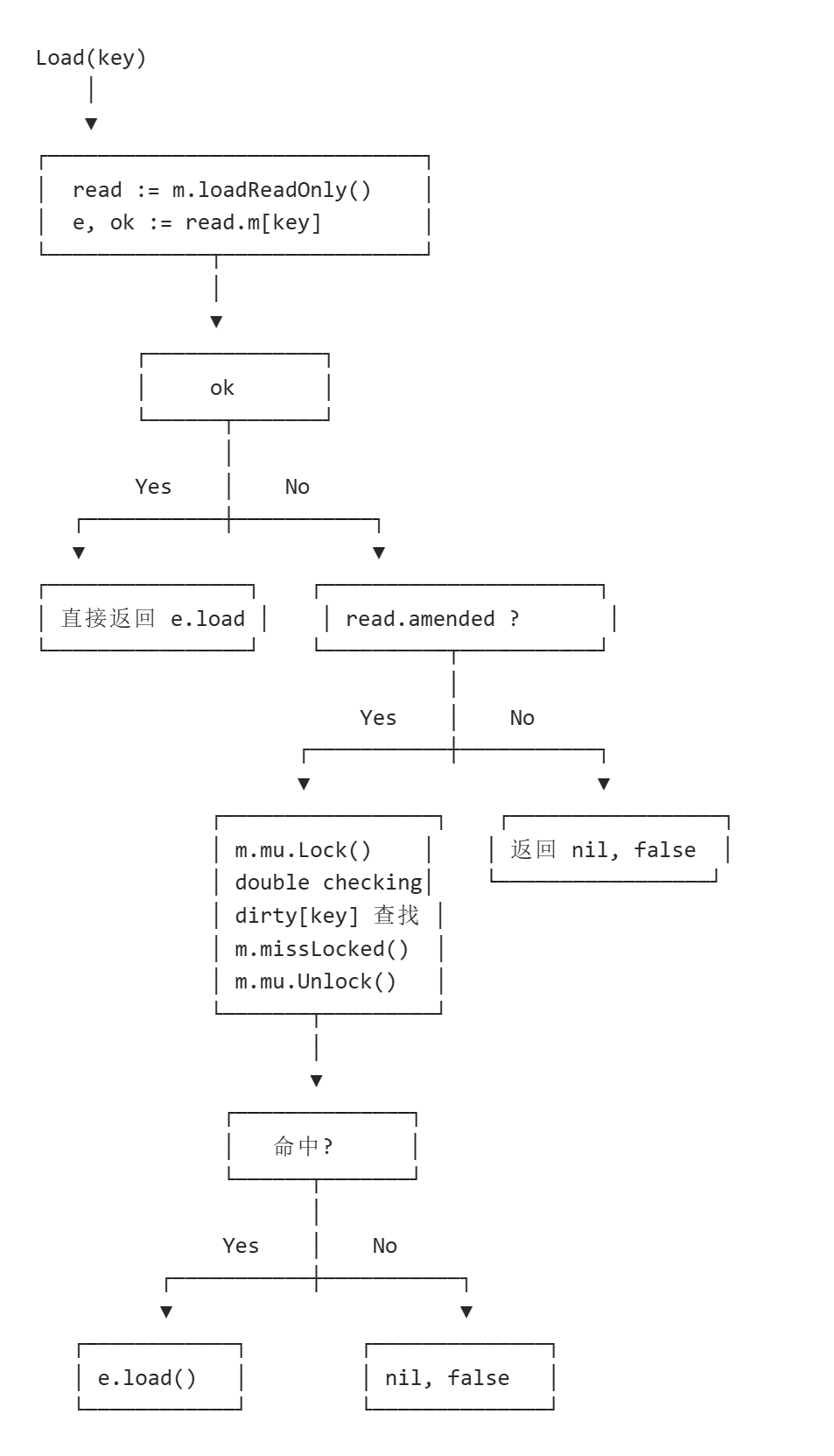
// Load 返回 map 中 key 对应的值// 如果没有值,返回 nil, false// 时间复杂度: amortized O(1)func(m *Map)Load(key any)(value any, ok bool) {// 步骤 1: 读取 read 快照(无锁 fast path) read := m.loadReadOnly() e, ok := read.m[key]// 步骤 2: 检查是否需要走 slow path// 条件:read 中没有命中 且 dirty 有额外 key(amended=true)if !ok && read.amended {// 步骤 3: 加锁,进入 slow path m.mu.Lock()// ---- double checking ----// 防止在等待锁期间,dirty 被升级到 read// 导致我们误判为未命中 read = m.loadReadOnly() e, ok = read.m[key]// 步骤 4: 再次检查 read,仍未命中且 dirty 有额外 keyif !ok && read.amended {// 从 dirty 中查找(这是唯一可能存在新 key 的地方) e, ok = m.dirty[key]// ---- 关键: 记录 miss,触发 dirty 升级 ----// 当 misses 累积到一定程度,dirty 会被升级为新的 read m.missLocked() } m.mu.Unlock() }// 步骤 5: 返回结果if !ok {returnnil, false// key 不存在 }return e.load() // 从 entry 中加载值}子方法详解
missLocked() – 记录 miss 并触发 dirty 升级
// missLocked 记录一次 miss,并检查是否需要升级 dirtyfunc(m *Map)missLocked() { m.misses++ // miss 计数 +1// ---- 关键:当 miss 次数 >= dirty 长度时,触发升级 ----// 将 dirty 升级为 read 更有利if m.misses < len(m.dirty) {return// 未达到阈值,等待更多 miss }// dirty 升级为新的 read m.read.Store(&readOnly{m: m.dirty}) m.dirty = nil// 清空 dirty m.misses = 0// 重置计数}missLocked() 是 sync.Map 实现自动升级机制的核心。当从 dirty 中查询 key 时(read 未命中),会调用此方法记录一次 miss。当 miss 次数达到 dirty 的长度时,意味着查询开销已经非常大了,此时将 dirty 整体升级为新的 read,实现数据的自动流转。
2.2 Store – 存储数据
// Store 设置 key 对应的值// 这是一个简单的包装,实际调用 Swapfunc(m *Map)Store(key, value any) { _, _ = m.Swap(key, value)}2.3 Swap – 原子交换(核心写方法)
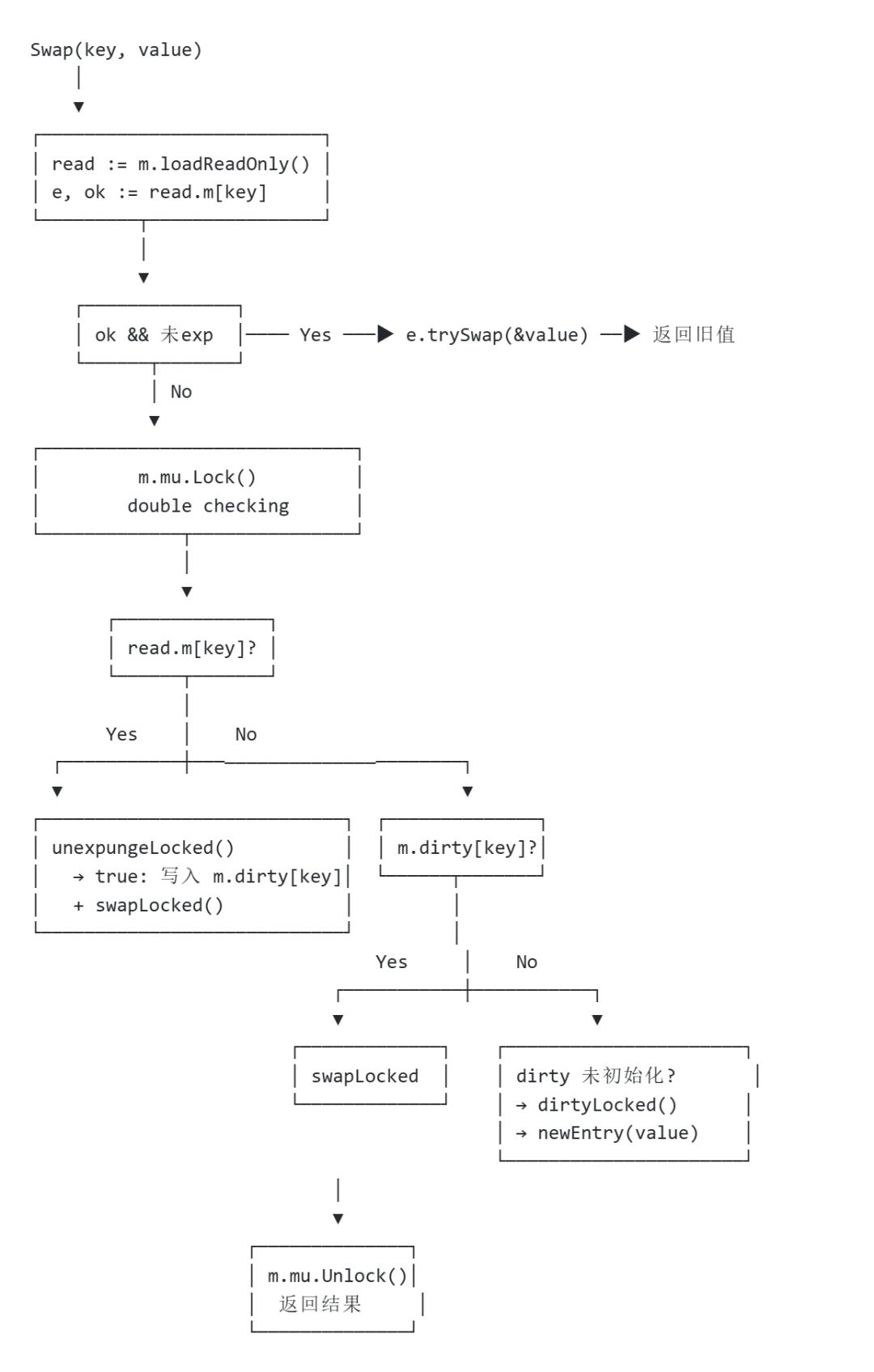
// Swap 原子地交换 key 的值,并返回旧值// 如果 key 不存在,loaded 返回 falsefunc(m *Map)Swap(key, value any)(previous any, loaded bool) {// 步骤 1: 读取 read 快照 read := m.loadReadOnly()// 步骤 2: 快速路径 - key 存在于 read 中// trySwap 尝试原子替换,如果 entry 未被 expunged 则成功if e, ok := read.m[key]; ok {if v, ok := e.trySwap(&value); ok {// 交换成功if v == nil {returnnil, false// 旧值为 nil(被删除过) }return *v, true// 返回旧值 }// trySwap 失败(entry 被 expunged),进入 slow path }// 步骤 3: 慢速路径 - 加锁处理 m.mu.Lock()// 再次读取 read(防止等待期间 dirty 升级) read = m.loadReadOnly()if e, ok := read.m[key]; ok {// 情况 A: key 存在于 read 中// 检查是否需要从 expunged 状态恢复// unexpungeLocked 尝试将 expunged 替换为 nil// 返回 true 表示之前确实是 expunged 状态if e.unexpungeLocked() {// 现在 entry 恢复正常,需要添加到 dirty 中// 否则后续从 dirty 找不到这个 key m.dirty[key] = e }// 原子交换值if v := e.swapLocked(&value); v != nil { loaded = true previous = *v } } elseif e, ok := m.dirty[key]; ok {// 情况 B: key 不在 read 中,但在 dirty 中if v := e.swapLocked(&value); v != nil { loaded = true previous = *v } } else {// 情况 C: key 是新插入的// 如果这是第一个新 key,需要初始化 dirty// 因为 read 中没有这个 key,dirty 可能有额外的 keyif !read.amended {// 创建 dirty 并将 read 中的非删除 entry 复制过去 m.dirtyLocked()// 标记 read 为"不完整"(dirty 有额外 key) m.read.Store(&readOnly{m: read.m, amended: true}) }// 插入新 entry m.dirty[key] = newEntry(value) } m.mu.Unlock()return previous, loaded}子方法详解
trySwap() – 无锁原子交换
// trySwap 尝试原子替换 entry 的值// 如果 entry 未被 expunged 则成功// 返回 (旧值, true) 表示成功,返回 (nil, false) 表示失败func(e *entry)trySwap(i *any)(any, bool) {for { p := e.p.Load()if p == expunged {returnnil, false// entry 已被删除,不在 dirty 中 }if e.p.CompareAndSwap(p, i) {return p, true// 交换成功 } }}trySwap() 是 entry 的无锁交换方法,用于快速路径。它使用无限循环 + CAS 尝试原子替换值:
-
如果 entry 已被 expunged(从 dirty 中删除),返回失败 -
如果 CAS 成功,返回旧值 -
如果 CAS 失败(并发修改),重试
unexpungeLocked() – 从 expunged 状态恢复
// unexpungeLocked 尝试将 entry 从 expunged 状态恢复到 nil// 返回 true 表示之前确实是 expunged 状态// 这是加锁版本,只能在持有 mu 锁时调用func(e *entry)unexpungeLocked()bool {return e.p.CompareAndSwap(expunged, nil)}当 dirty 重新创建时(dirtyLocked),会遍历 read map,将其中 entry.p == nil 的 entry 标记为 expunged(通过 CAS),这些被标记的 entry 不会被复制到新的 dirty。当再次向该 key 写入时,需要先通过 unexpungeLocked() 将其从 expunged 状态恢复到 nil,然后才能添加到 dirty 中。
swapLocked() – 加锁原子交换(内部使用)
// swapLocked 在持有锁的情况下原子交换值func(e *entry)swapLocked(i *any) *any {for { p := e.p.Load()if p == expunged {// 如果是 expunged 状态,先恢复到 nilif e.p.CompareAndSwap(p, nil) {returnnil }// CAS 失败,重试continue }if e.p.CompareAndSwap(p, i) {return p } }}dirtyLocked() – 初始化 dirty map
// dirtyLocked 初始化 dirty map,并将 read 中有效的 entry 复制过去func(m *Map)dirtyLocked() {// 如果 dirty 已存在,直接返回if m.dirty != nil {return }// 创建新的 dirty map,预分配 len(read.m) + 1 个空间 m.dirty = make(map[any]*entry, len(m.read.m)+1)// 遍历 read,将非删除的 entry 复制到 dirtyfor k, e := range m.read.m {if !e.tryExpungeLocked() { // 尝试将 p=nil 标记为 expunged m.dirty[k] = e // 复制有效 entry } }// 设置 amended 标记:dirty 中有 read 没有的 key read := m.loadReadOnly() m.read.Store(&readOnly{m: read.m, amended: true})}dirtyLocked() 在首次写入新 key 时被调用。它创建 dirty map 并从 read 复制有效 entry。关键点:
-
过滤已删除的 entry:调用 tryExpungeLocked()将 nil 转换为 expunged。转换成功的话,不会复制到dirty中 -
设置 amended 标记:告知系统 dirty 中有额外的 key
2.4 LoadAndDelete – 原子删除(Delete 底层实现)
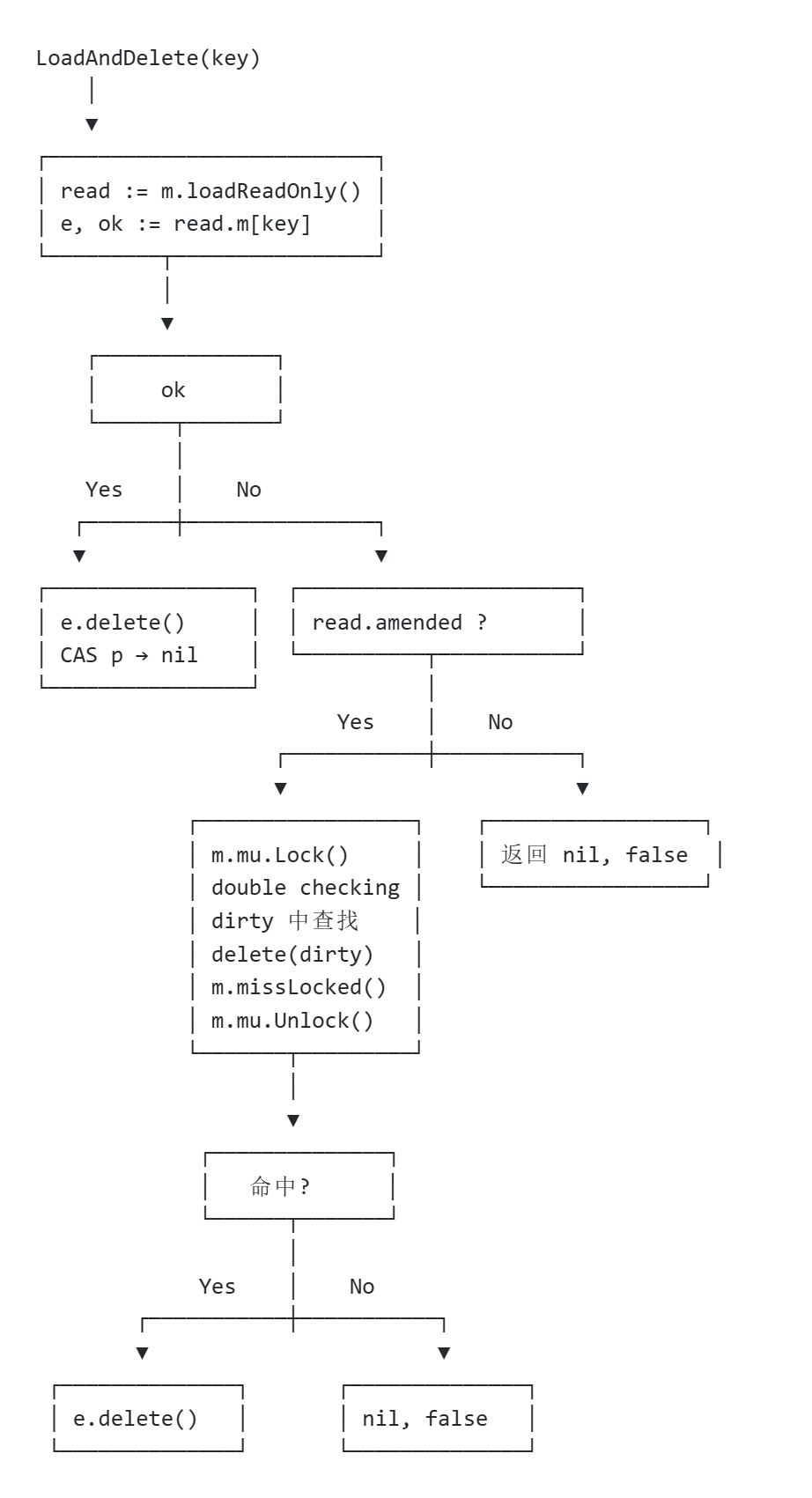
// LoadAndDelete 删除 key 对应的值,并返回旧值// 如果 key 不存在,返回 nil, falsefunc(m *Map)LoadAndDelete(key any)(value any, loaded bool) {// 步骤 1: 读取 read 快照 read := m.loadReadOnly() e, ok := read.m[key]// 步骤 2: 检查是否需要进入 slow pathif !ok && read.amended { m.mu.Lock()// double checking read = m.loadReadOnly() e, ok = read.m[key]if !ok && read.amended {// 从 dirty 中查找 e, ok = m.dirty[key]// 从 dirty 中真正删除(因为它已经迁移到 read)delete(m.dirty, key)// 记录 miss m.missLocked() } m.mu.Unlock() }// 步骤 3: 如果找到 entry,调用 delete() 原子删除// delete() 使用 CAS 将 p 从非 nil 改为 nilif ok {return e.delete() }returnnil, false}子方法详解
entry.delete() – 原子删除
// entry.delete() - 原子删除// 使用 for 循环 + CAS 处理并发竞争func(e *entry)delete()(value any, ok bool) {for { p := e.p.Load() // 读取当前值if p == nil || p == expunged {returnnil, false// 已被删除 }// CAS: 尝试将 p 替换为 nilif e.p.CompareAndSwap(p, nil) {return *p, true// 删除成功,返回旧值 }// CAS 失败,说明有并发修改,重新尝试 }}delete() 方法使用无限 for 循环 + CAS 操作实现原子删除。关键点:
-
首先检查当前值是否为 nil 或 expunged(已删除状态) -
使用 CompareAndSwap原子地将值替换为 nil -
如果 CAS 失败(说明有并发修改),则重试
2.5 Range – 遍历
// Range 遍历所有键值对// 注意:不保证强一致性,可能反映遍历期间的修改func(m *Map)Range(f func(key, value any)bool) {// 步骤 1: 读取 read 快照 read := m.loadReadOnly()// 步骤 2: 如果 dirty 有额外 key,需要先升级// 这是为了保证 Range 能遍历到所有 keyif read.amended { m.mu.Lock()// double checking read = m.loadReadOnly()// 再次检查 amended(可能其他 goroutine 已经升级了)if read.amended {// ---- 立即将 dirty 升级为 read ----// 这是因为 Range 本身是 O(N) 操作,// 复制 dirty 的成本可以摊销 read = readOnly{m: m.dirty} // dirty 变成新的 read copyRead := read m.read.Store(©Read) // 原子写入 m.dirty = nil// 清空 dirty m.misses = 0// 重置 miss 计数 } m.mu.Unlock() }// 步骤 3: 遍历 read mapfor k, e := range read.m { v, ok := e.load()if !ok {continue// 跳过已删除的 entry }if !f(k, v) {break// 用户停止遍历 } }}三、核心机制深度解析
前面我们逐个分析了各个方法的源码,现在我们把这些点串成线,深入理解 read、dirty、miss 三者之间的协作机制,以及延迟删除的完整生命周期。
3.1 完整数据流:read、dirty 与 miss 的协作周期
sync.Map 的核心设计是 **read(无锁读)、dirty**(写操作)和 misses(升级触发器)三者协作实现的自动流转机制。
核心数据结构与关键函数

完整生命周期流转图
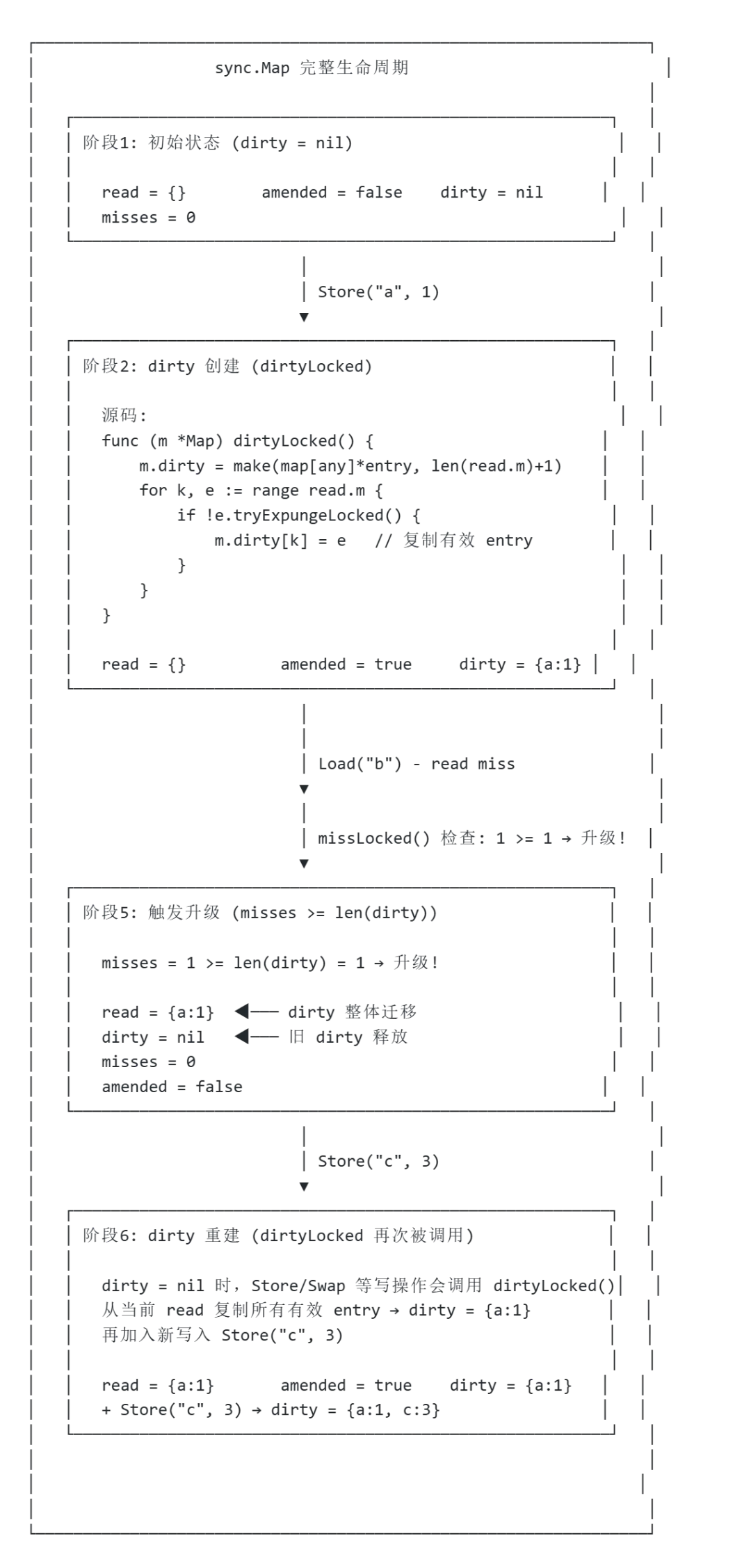
状态流转的关键函数回顾
1. dirty 的创建/重建时机
// dirtyLocked() 只在 dirty == nil 时才会创建/重建func(m *Map)dirtyLocked() {if m.dirty != nil {return// dirty 已存在,直接返回 }// 从 read 复制所有有效 entry 到新 dirty read := m.loadReadOnly() m.dirty = make(map[any]*entry, len(read.m))for k, e := range read.m {if !e.tryExpungeLocked() { m.dirty[k] = e } }}2. miss 触发升级的时机
// missLocked() 在每次 read miss 但 dirty 命中时被调用func(m *Map)missLocked() { m.misses++if m.misses >= len(m.dirty) {// 已经出现了这么多次miss,说明需要升级了// 将 dirty 升级为 read,让读操作可以无锁进行 m.read.Store(&readOnly{m: m.dirty}) m.dirty = nil m.misses = 0 }}3. dirty 升级后不是立即重建
-
dirty 被清空后,只有下一次写操作才会触发 dirtyLocked()重建 dirty -
重建时从当前 read 复制所有有效 entry
3.2 延迟删除机制
sync.Map 的删除采用延迟删除策略:删除操作不会立即从 map 中物理移除 entry,而是通过多阶段标记最终清理。这种设计避免了在热点路径(read map)上加锁,同时保证了并发安全。
3.3.1 三种删除场景分析
根据 key 所在的位置,删除操作分为三种情况:
场景1:只在 read 中存在
// LoadAndDelete 关键代码 (line 300-321)func(m *Map)LoadAndDelete(key any)(value any, loaded bool) { read := m.loadReadOnly() e, ok := read.m[key]// read 中找到,且 dirty 可能为 nil 或与 read 一致if ok {return e.delete() // 直接 CAS 删除,无需加锁! }// ...}// entry.delete - 无锁操作func(e *entry)delete()(value any, ok bool) {for { p := e.p.Load()if p == nil || p == expunged {returnnil, false// 已删除或已清理 }// CAS 将 p 从指向 value 改为 nilif e.p.CompareAndSwap(p, nil) {return *p, true// 逻辑删除成功 } }}流程说明:
-
在 read.m中找到 entry(无锁) -
调用 e.delete()通过 CAS 将entry.p设为nil -
注意:此时 entry 仍在 read.m中,只是 value 指针被清空
场景2:只在 dirty 中存在(read 未命中,加锁删除)
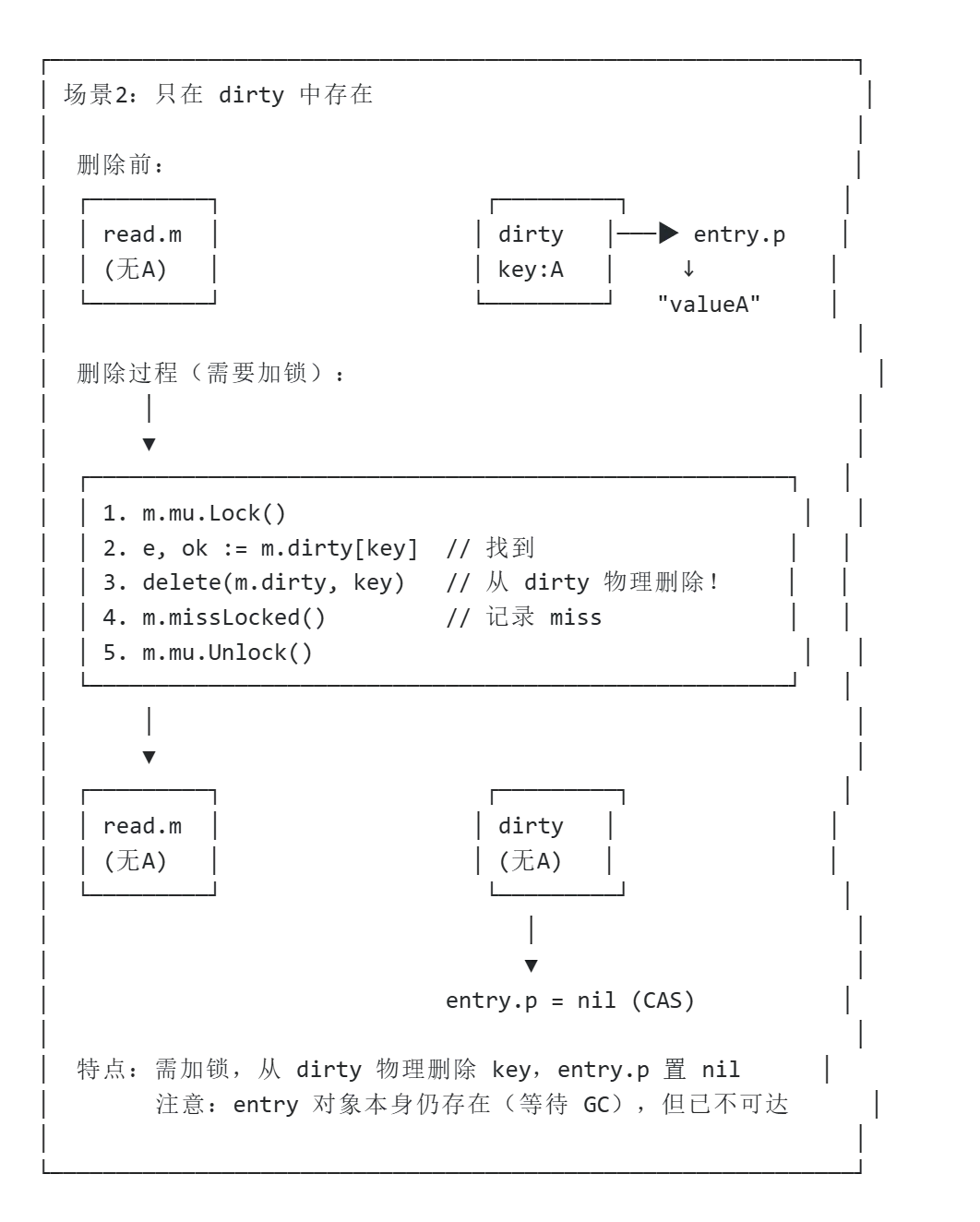
func(m *Map)LoadAndDelete(key any)(value any, loaded bool) { read := m.loadReadOnly() e, ok := read.m[key]if !ok && read.amended { // read 未找到,且 dirty 可能有 m.mu.Lock()// 双重检查...if !ok && read.amended { e, ok = m.dirty[key]delete(m.dirty, key) // 从 dirty map 中物理删除 key! m.missLocked() // 记录一次 miss } m.mu.Unlock() }if ok {return e.delete() // 再 CAS 标记 entry.p = nil }returnnil, false}流程说明:
-
read.m未找到 key,但read.amended == true(说明 dirty 有新 key) -
加锁后查 dirty,找到了 entry -
delete(m.dirty, key)– 从 dirty map 中物理删除该 key -
m.missLocked()– 记录一次 miss(促进 dirty 提升) -
调用 e.delete()CAS 标记entry.p = nil
场景3:同时在 read 和 dirty 中存在
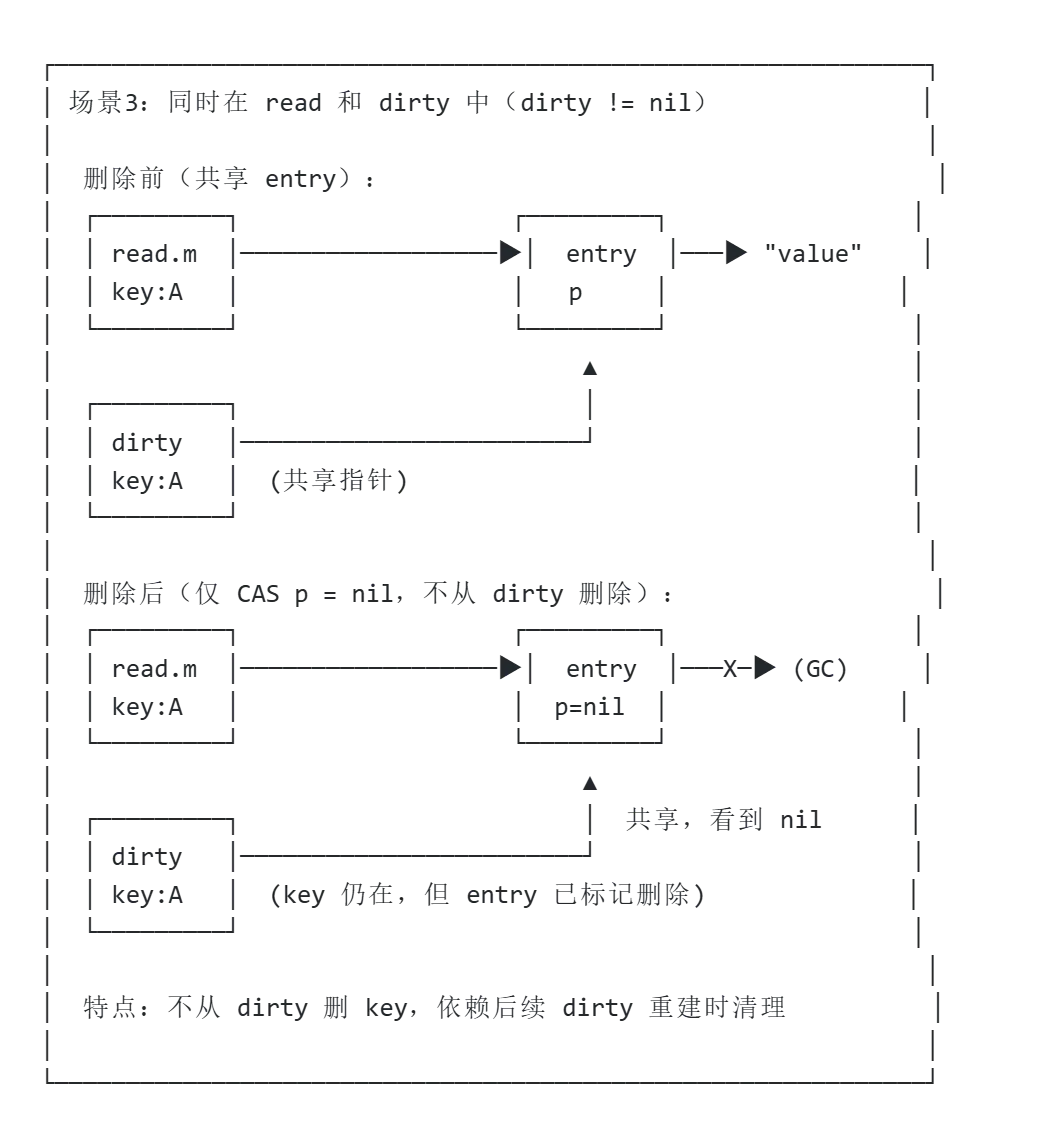
这种情况是场景1的特例。当 dirty != nil 时,dirty 包含所有非 expunged 的 read 条目,所以 key 会同时在两个 map 中。
if ok { // 在 read 中找到return e.delete() // CAS 置 nil}// 注意:没有 delete(m.dirty, key)!关键点:
-
只 CAS 设置 entry.p = nil,不会从 dirty 中删除 key -
read 和 dirty 共享同一个 entry,所以看到相同的 nil -
该 key 最终会在 dirty 提升为 read 时自然消失(如果 p 仍为 expunged)
3.3.2 从逻辑删除到物理清除的完整流程
删除操作只是将 entry.p 设为 nil(逻辑删除),entry 本身和 key 仍留在 map 中。彻底清理需要经历以下阶段:

关键代码解析 – tryExpungeLocked:
// 尝试将 nil 标记为 expunged,返回是否成功func(e *entry)tryExpungeLocked()(isExpunged bool) { p := e.p.Load()for p == nil {// CAS: nil → expungedif e.p.CompareAndSwap(nil, expunged) {returntrue// 成功标记为 expunged } p = e.p.Load() // 失败重读 }return p == expunged // 是否已经是 expunged}为什么需要这么复杂的删除流程?
这个问题要从 sync.Map 的核心设计目标说起——保持 read 的无锁读取能力。

如果删除操作直接修改 read 或从 read 中删除 entry,会有什么问题?❌ 如果直接 delete(read.m, key): - read.m 是共享的 map,并发修改会 panic - 必须加锁,失去了"无锁读"的优势❌ 如果替换整个 readOnly 结构来删除 key: - 需要先 copy 整个 read.m(O(n) 拷贝) - 然后从副本中 delete(key) - 再 atomic.Store 替换(又多一次原子操作) - 每次删除都是 O(n) 复杂度,无法接受正确做法:只修改 entry.p,不修改 map 结构 ✅ e.delete() = CAS p = nil // O(1) 操作!
3.3.3 删除流程总结表
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
四、sync.Map 适用场景
理解了 sync.Map 的核心机制后,我们来看看它适合用在什么场景
根据以上源码分析,sync.Map 的核心价值在于:对已存在于 read 中的 key,读、写、删操作无需获取互斥锁,可并发执行
RWMutex + map: 写者 Lock() → 阻塞所有读者(整个 map 被锁住)sync.Map: 对 read 中的 key 操作 → 完全无锁,不阻塞任何读者具体来说:1. Load(key): 原子加载 m.read 直接内存访问 read.m[key],全程无锁2. Store(key, value): 如果 key 在 read 中且对应的 entry 未被标记为 expunged,则直接通过 CAS (Compare-And-Swap) 更新该 entry 的值指针 这个过程不需要获取 mu 锁3. Delete(key): 同样,如果 key 在 read 中,直接 CAS 将 entry.p 设为 nil,无锁总结
sync.Map 的核心设计思想包括:
-
读写分离:read 无锁,dirty 加锁 -
延迟删除:通过 nil 和 expunged 标记实现安全删除 -
自动升级:通过 miss 计数触发 dirty → read 的升级
关键问题解答
问题1:sync.Map 为什么能实现对 read 中 key 的无锁读写?
核心在于 readOnly 结构不可变:
type Map struct { read atomic.Pointer[readOnly] // 原子指针,指向只读结构 mu Mutex // 仅保护 dirty dirty map[any]*entry ...}readOnly.m 是一个普通 map,但通过 只创建一次、从不修改 的方式实现了并发安全:
-
Load()用atomic.Load()获取 read 指针,然后直接访问read.m[key] -
没有任何锁操作,纯内存读取
关键:不需要锁来保护”读取”,因为根本不修改任何东西。
问题2:为什么删除操作要用 CAS p = nil 而不是直接修改 map 结构?
**如果直接 delete(read.m, key)**:
-
read.m 是共享的 map,并发修改会 panic -
即使加锁,每次删除都要 O(n) 拷贝整个 map(不可接受)
延迟删除的优势:
-
只修改 entry.p = nil(O(1) 操作) -
read.m 的结构不变,Load 仍可直接访问 -
真正的物理删除推迟到 dirty 重建时批量处理
问题3:为什么需要 expunged 标记?nil 和 expunged 有何区别?
p = nil 表示 entry 已被删除(逻辑删除),但此时可能还在 dirty 中(如果 dirty 之前有这个 entry)。
expunged 表示 entry 已被删除,且确定不在 dirty 中
下面以一个具体的场景说明
Delete(key) │ ▼┌─────────────────────────────────┐│ entry.p = nil(标记已删除) │└─────────┬───────────────────────┘ │ ▼ dirty 重建时┌─────────────────────────────────────────────┐│ 遍历 read,发现 entry.p = nil ││ 不拷贝到 dirty ││ 将 entry.p 从 nil 改为 expunged ││ 这是关键一步! │└─────────┬───────────────────────────────────┘ │ ▼ 后续 Store(key, valueB)┌─────────────────────────────────────────────┐│ read 中找到 entry,p = expunged ││ 知道 dirty 中没有这个 key ││ 先将 key→entry 加入 dirty ││ 再 CAS 更新 entry.p = valueB ││ ✓ 保证 dirty 重建时不会丢失这个 key │└─────────────────────────────────────────────┘总结对比:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
expunged 就像一个”确认函”:告诉 Store 操作”这个 key 确实不在 dirty 中,你必须重新添加”。这样就保证了 read 和 dirty 的一致性
问题4:dirty 到 read 的升级机制是什么?
升级条件:misses >= len(dirty)
func(m *Map)missLocked() { m.misses++if m.misses < len(m.dirty) {return// 未达到阈值 }// 升级! m.read.Store(&readOnly{m: m.dirty, amended: m.amended}) m.dirty = nil m.misses = 0}设计思想:
-
不是每次 miss 都升级(避免频繁重建) -
用 misses 计数器累积,当 miss 次数”值得”重建时才升级 -
dirty 重建后变空,misses 归零,重新开始计数