 夜雨聆风
夜雨聆风





OpenClaw 多文档整理 Agent 搭建
↑阅读之前记得关注+星标⭐️,😄 每天才能第一时间接收到更新。
大家好,我是赛博大宋,也可以称呼我大宋老师,嘻嘻~
【还不会装龙虾的“关注公众号后 进入公众号点菜单栏一起交流→点联系我”,“免费领取全套教程及实战互助群”】
【实操分享】OpenClaw 多文档多输入源笔记整理 Agent 搭建
我是一个每天都要用 AI 整理大量资料的人。过去这段时间,我几乎天天都在调提示词、改流程、踩坑、复盘。
我试过让 AI 一次性读 10 篇文档,结果内容丢一半、逻辑乱成麻、输出全靠运气。我也试过不停优化提示词,结果今天能用,明天翻车;短篇能用,长篇崩溃。
我经历过这些非常具体的问题:
-
• 整理到一半卡住 -
• 关键结论消失 -
• 多来源内容互相打架 -
• 长文末尾直接截断 -
• 发出去才发现漏段
后来我才慢慢确认:问题不只是提示词写得不够花,而是整个整理链路没有工程化。
所以这篇文章我不讲玄学,直接讲一套我觉得能真正落地的方案:用 OpenClaw 搭一个多文档、多输入源的内容整理 Agent,把资料整理这件事做成稳定、可复用、可验证的生产线。
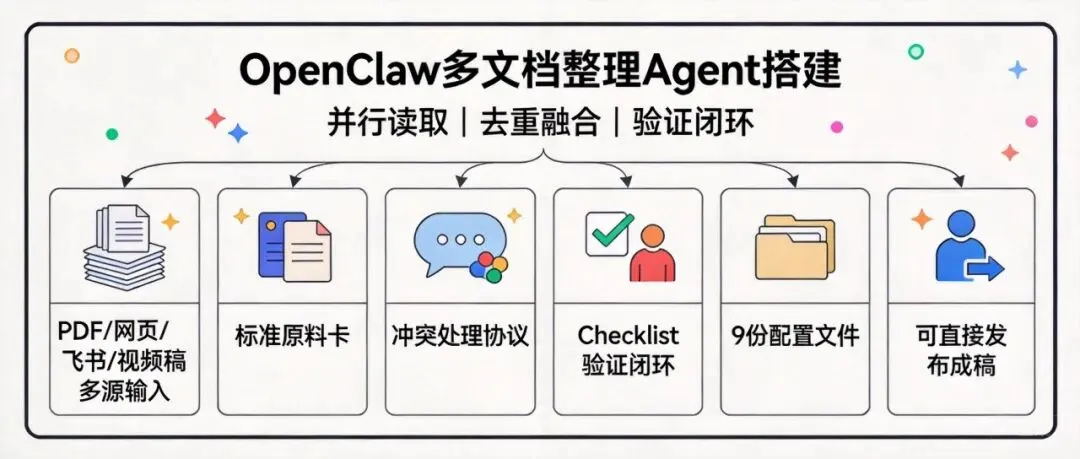
这个内容整理 Agent 到底是干嘛的
先给一句最直白的定义:
把杂乱资料,一键变成结构化、可信、可直接发布的内容。
这个 Agent 面向的,不是单篇小作文,而是多来源资料整合场景。你可以丢给它:
-
• PDF -
• 网页文章 -
• 飞书文档 -
• 视频转写稿 -
• 零散笔记 -
• 聊天记录
然后让它自动完成这些工作:
-
• 并行读取,避免长时间串行卡顿 -
• 提取核心论点与关键数据 -
• 去重、合并、处理内容冲突 -
• 按主题结构化输出 -
• 做完整性验证,避免漏段、截断、失真 -
• 最终交付一版可继续加工甚至可直接发布的成稿
做内容整理 Agent,最怕三件事:慢、乱、不稳定。
-
• 慢,通常是因为逐篇串行读取 -
• 乱,通常是因为边读边写,没做中间层 -
• 不稳定,通常是因为没有验证闭环
一、多数 Agent 跑不稳的核心原因
很多人以为多文档整理翻车,是模型不够强。我的实际感受是:聪明靠模型,稳定靠工程。
最常见的问题,大致可以归成下面这张表:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以真正缺的,往往不是更强大的模型,而是一条稳定的工程化生产线。
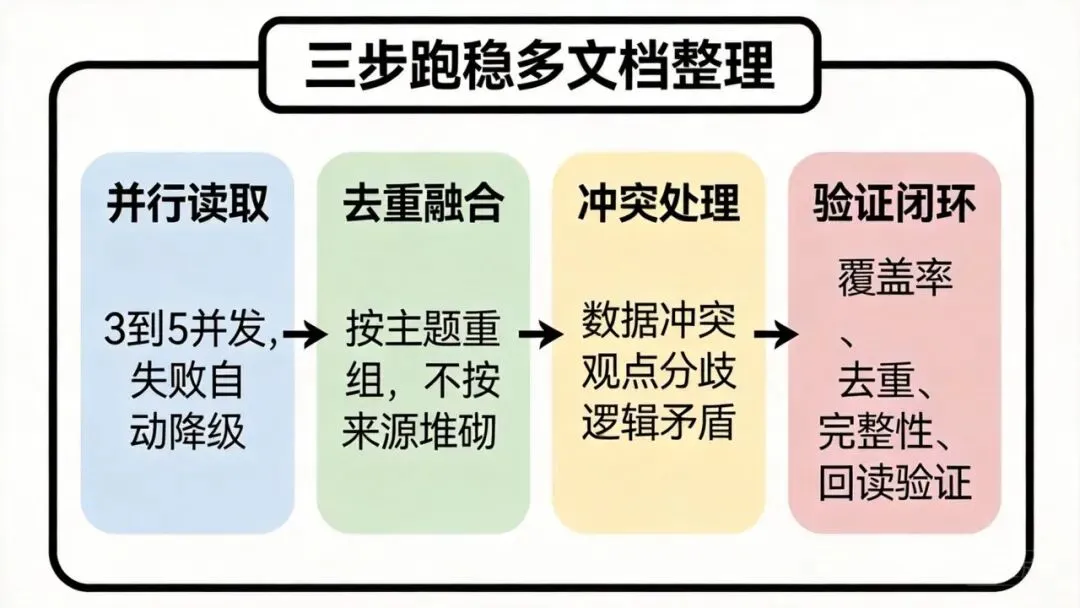
二、三步核心流水线
这套整理 Agent 的主干,我现在压缩成三步:
Step 1:并行读取
第一步不是立刻总结,而是先把不同来源的材料尽可能并行读取。
关键点:
-
• 不要一份一份串行读到底 -
• 并发数控制在 3 到 5 之间更稳 -
• 每个来源读完后先产出标准化中间结果,不直接写正文 -
• 失败就降级,不要把整个任务卡死
这一步的目标不是“写得漂亮”,而是“把所有原料都吃进去,而且尽量不漏”。
Step 2:去重融合
第二步才开始真正的整理。
这一步不要按“来源 A 说了什么、来源 B 又说了什么”去堆,而是按主题重新组织。
具体要做的事情包括:
-
• 把重复信息合并 -
• 把同类观点归到一起 -
• 把冲突内容单独标出来 -
• 把内容按主题重组,而不是按原顺序复述
如果没有这一步,最后出来的东西通常会非常像拼贴稿。
Step 3:验证闭环
这是最容易被忽略,但也是最决定稳定性的一步。
验证闭环至少要回答这些问题:
-
• 所有来源的核心论点有没有覆盖到? -
• 是否还有高重复段落没合并? -
• 有冲突的地方有没有明确标注? -
• 开头、结尾、关键步骤有没有缺失? -
• 输出后的字数和结构是否异常?
只要这一步没做,前面哪怕看起来写得很好,最后也很容易翻车。
三、标准原料卡格式
为了不让系统边读边乱写,我现在会让它先输出统一的原料卡。
一个简化版格式可以长这样:
source_card:id:S1title:文章标题source_type:PDF/网页/飞书/视频转写url:原始链接status:成功/降级/失败core_claims:-claim:论点描述evidence:支撑证据confidence:high/medium/lowkey_data:关键数据点boundary:适用边界conflicts:-with:S2description:冲突描述token_estimate:2400这张卡片的价值很大。
因为它把“读取”和“输出”之间,插入了一层标准化结构。这样后面做融合、去重、验证时,都有明确抓手,而不是靠模型临场发挥。
四、内容冲突三级处理协议
多来源整理最怕的一件事,就是不同资料之间互相矛盾。
我的经验是:不要硬调和,要先分类。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
这样做的好处是,整理结果会更诚实,也更适合后续继续加工。
五、输出验证 Checklist
这是我现在非常依赖的一张检查单。
在对外交付前,我至少会看下面几项:
-
• 所有来源核心论点已完整覆盖 -
• 重复段落(相似度高)已合并 -
• 所有内容冲突已标注处理 -
• 每段尽量包含:结论 + 证据 + 边界 + 建议 -
• 开头和结尾完整,没有中途截断 -
• 写入回读后的字数偏差在合理范围内
这张表看起来土,但非常有用。
很多所谓“AI 很不稳定”的问题,本质上不是模型不会写,而是没人做最后一道验证。
六、9 个配置文件说明
为了让这条链跑稳,我会把规则尽量拆到不同文件里,不让所有约束都堆在一个总提示词里。
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里面最关键的,不是文件数量,而是职责分离。
比如:
-
• SOUL.md决定“先执行再解释”这类核心行为 -
• TOOLS.md负责工具选择和降级策略 -
• MEMORY.md负责记录已经踩过的坑 -
• SCHEMA.md负责中间结构和输出契约
这样任务一复杂起来,系统才不容易一会儿像助手、一会儿像脚本、一会儿又像失忆机器人。
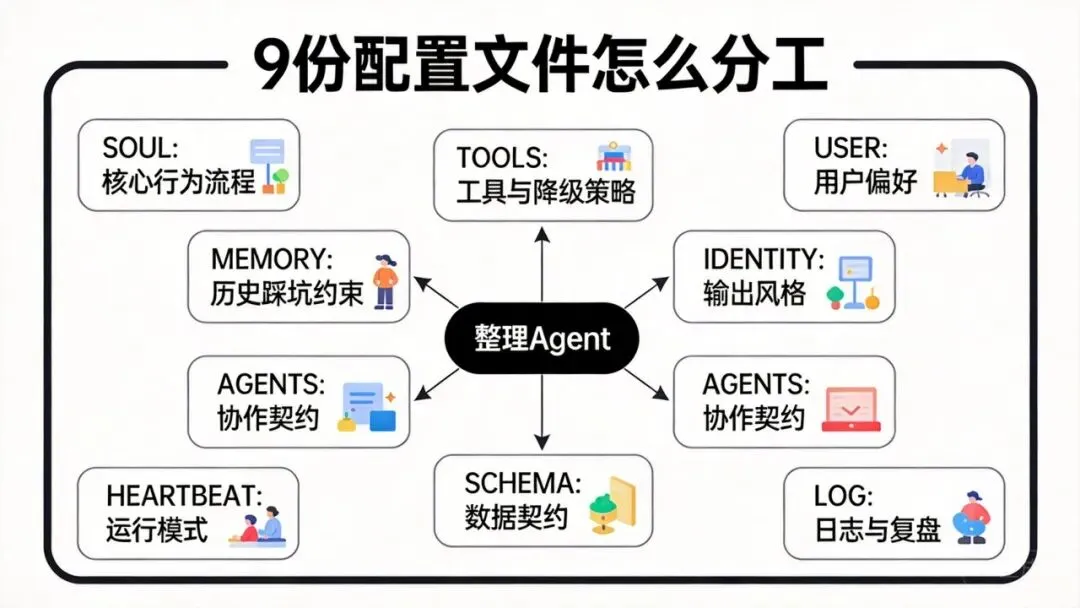
七、这 9 份配置文件怎么写
下面我把思路直接给出来,方便你照着改成自己的版本。
1/9 SOUL.md:核心行为流程
这一份的重点,不是文风,而是行为规则。
建议至少写清这些:
-
• Step 0:Token 预算评估 -
• Step 1:需求确认 -
• Step 2:并行读取 -
• Step 3:融合分析 -
• Step 4:验证闭环
同时把硬规则写死,比如:
-
1. 不确认需求不动手 -
2. 先读后生成,不凭记忆 -
3. 未验证不说完成 -
4. 冲突不强行调和 -
5. 不虚构证据
2/9 TOOLS.md:工具与降级策略
这份主要解决“哪个来源用什么工具、失败时怎么降级”。
例如:
-
• PDF:优先 read,必要时走 OCR -
• 网页:优先 web_fetch,失败再走浏览器渲染 -
• 飞书:优先官方读取链路,失败再导出 -
• 微信:优先抓正文,失败再走浏览器真实渲染
同时最好写清:
-
• 每种来源的超时阈值 -
• 是否允许重试 -
• 失败后如何标记但不阻塞全流程 -
• Token 预算怎么切分
3/9 MEMORY.md:历史踩坑约束
这份非常重要。
很多“今天修好、明天再犯”的问题,都是因为规则没有沉淀。
比如这类内容就适合写进来:
-
• 写入后必须回读验证 -
• 分批 blocks 不要过大 -
• 禁止 JSON 里塞超长正文 -
• 教程类内容尽量保留原顺序 -
• 引用必须带来源
4/9 IDENTITY.md:输出风格
这一份不是装人格,而是稳输出。
比如可以直接写:
-
• 结论先行 -
• 少空话 -
• 少寒暄 -
• 有边界 -
• 有可执行性
5/9 USER.md:用户偏好
如果 Agent 长期为你服务,这份最好明确:
-
• 用户喜欢什么风格 -
• 反感什么写法 -
• 哪些动作默认可以做 -
• 哪些动作必须确认
6/9 AGENTS.md:协作契约
如果你会用多 Agent,这份就负责:
-
• 输入格式怎么传 -
• 输出格式怎么收 -
• 每个 Agent 负责哪一段 -
• 怎样避免互相覆盖
7/9 SCHEMA.md:数据契约
这份最适合写:
-
• 原料卡字段 -
• 融合输出模板 -
• 验证标准
它的作用是防止中间结构飘掉。
8/9 HEARTBEAT.md:运行模式
这份不是拿来装忙,而是定义:
-
• 什么情况下触发检查 -
• 什么属于轻量巡检 -
• 什么属于真正要提醒的变化 -
• 性能基线大概是多少
9/9 LOG.md:运行日志与复盘
最后一定要有日志。
至少记这些:
-
• 哪次任务处理了多少来源 -
• 哪些来源成功、哪些降级 -
• 哪一步失败 -
• 验证有没有通过 -
• 下次该避免什么
这样你才能真正把“偶尔能跑通”变成“以后都更稳”。
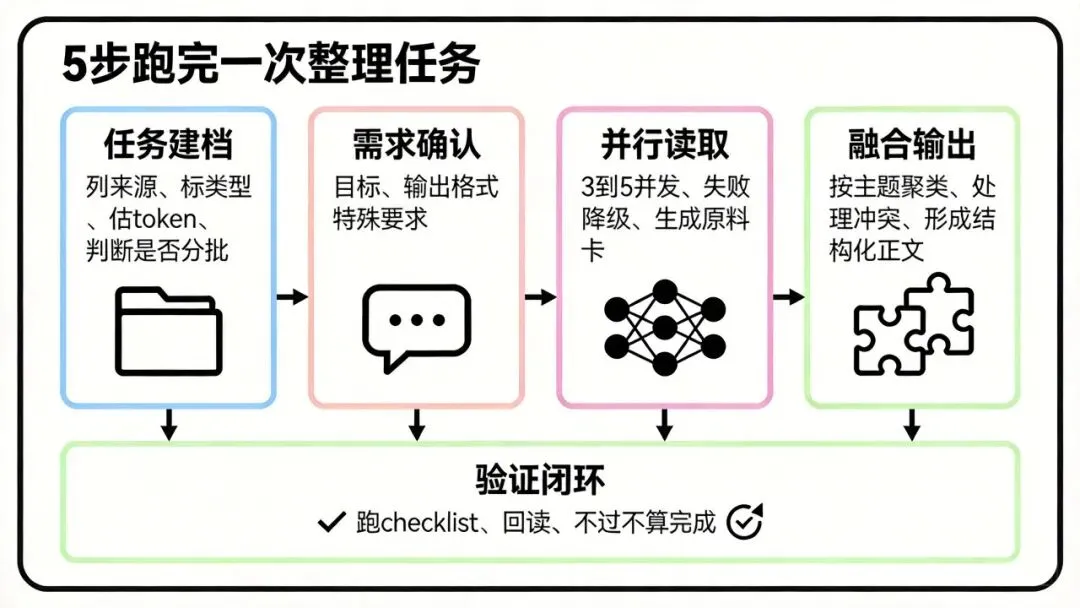
八、任务执行 5 步清单
如果你想快速照抄,我建议你把执行过程压缩成下面 5 步:
Step A:任务建档
-
• 列出来源 -
• 标类型 -
• 估算 Token -
• 判断是否需要分批
Step B:需求确认
-
• 确认目标是什么 -
• 确认输出格式是什么 -
• 确认有没有特殊要求
Step C:并行读取
-
• 并发控制在 3 到 5 -
• 失败自动降级 -
• 每个来源都生成原料卡
Step D:融合输出
-
• 按主题聚类 -
• 处理冲突 -
• 每段尽量包含结论、证据、边界、建议
Step E:验证闭环
-
• 跑 Checklist -
• 写入后回读 -
• 不通过就不能说完成
最后一句
这套方法我现在最看重的,不是它看起来多高级,而是它能把“资料整理”这件事,从碰运气,慢慢变成一个可重复、可验证、可交付的流程。
工程化不是把简单事情复杂化,而是把复杂事情变得更稳定。
如果你也经常在做 多文档、内容整理、资料整理 这类工作,我真心建议你别只盯着提示词本身,而是把整个链路搭起来。
当你把原料卡、冲突协议、验证闭环这些环节都补齐以后,OpenClaw 才会真正从“会聊天的 AI”变成一个能干活的整理系统。
能看到这里的都是凤毛麟角的存在!如果觉得不错,随手点个赞、在看、转发三连吧~如果想第一时间收到推送,也可以给我个星标⭐️谢谢你耐心看完我的文章~
会持续日更,聚焦AI、OpenClaw,Codex、AIGC、从龙虾塘到科技前沿,提供硬核干货与跨界视角。
欢迎加我微信“PPT69999”共同探讨!
“专属免费互助社群与知识库持续更新”,关注我,即刻入局,解锁AI跨界生存指南~
【还不会装龙虾的“关注公众号后 进入公众号点菜单栏一起交流→点联系我”,“免费领取全套教程及实战互助群”】