 夜雨聆风
夜雨聆风





LangChain文档加载|实现本地文档问答(PDF/Word/TXT) Day4
【开篇前言】
大家好,我是胖哥,前面3天咱们学会了LangChain的基础组件(提示词模板、链、记忆),能实现简单的AI交互和多轮对话,但这些都是基于“大模型自带知识”的交互——如果我们想让AI基于「自己的本地文档」(比如PDF、Word、TXT)回答问题,该怎么做?
这就是今天的核心内容:LangChain文档加载与处理,也是实战开发中最常用的功能之一(比如企业文档查询、论文解读、个人笔记问答等)。
今天咱们全程实战,手把手教你加载本地文档(以PDF为例,Word/TXT同理),搭建一个“本地文档问答机器人”,代码可直接复制运行,新手也能轻松上手,学会就能直接落地实用需求!
## 一、核心知识点:文档加载的核心逻辑
让AI基于本地文档回答问题,核心分为3步,这也是LangChain处理文档的标准流程:
1. 加载文档(Load):用LangChain的文档加载器,读取本地PDF/Word/TXT等文件,将其转化为LangChain可处理的格式
2. 分割文档(Split):将加载的文档分割成小块(因为大模型有上下文长度限制,无法处理过长文本)
3. 问答交互(Query):结合大模型和文档内容,让AI基于分割后的文档片段,回答用户的问题
【配图提示】:LangChain文档处理流程图,展示“加载文档 → 分割文档 → 问答交互”的完整流程,标注每个步骤的核心组件,配图放入C:\WorkBuddy\公众号,命名为Day4-1-文档处理流程图.png
## 二、实战准备:安装文档加载依赖
处理不同类型的文档,需要安装对应的依赖包,今天以最常用的PDF为例,安装相关依赖,复制代码即可完成安装。
【代码片段】(公众号排版用代码块,标注Python语言)
“`python
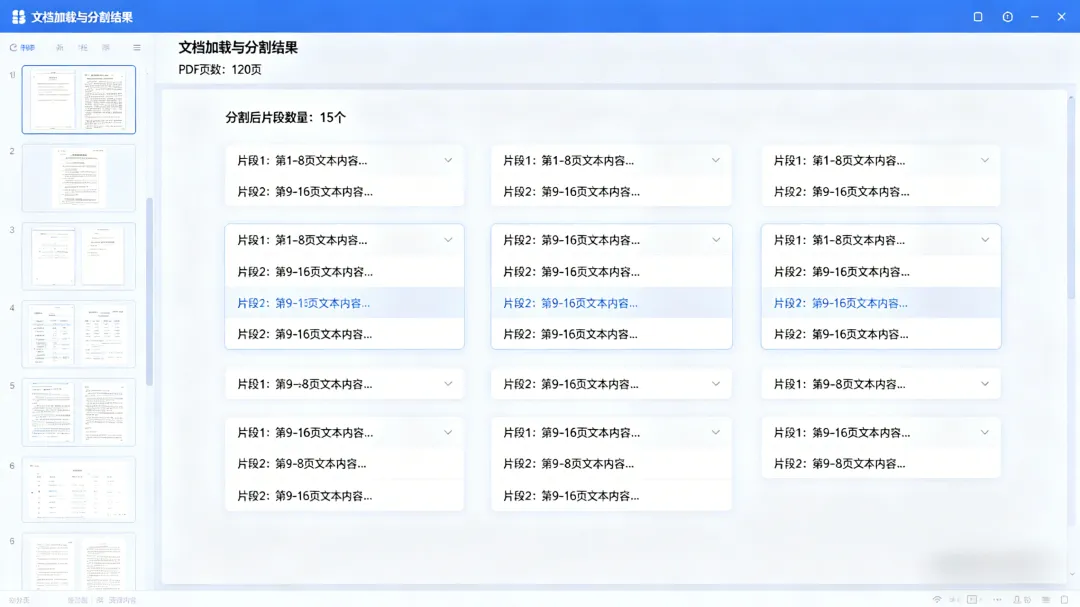
# 安装PDF加载依赖(核心依赖)pip install pypdf==4.2.0# 安装文档分割依赖(LangChain内置,需单独安装)pip install langchain-text-splitters==0.0.1# 安装可选依赖(处理Word/TXT文档,按需安装)# pip install python-docx # 处理Word文档# pip install python-multipart # 处理TXT文档```## 三、实战1:加载本地PDF文档并分割先实现“加载PDF文档 → 分割文档”的核心步骤,这里以本地一个PDF文件(比如“LangChain官方文档摘要.pdf”)为例,代码可直接复制,只需修改PDF文件路径。【代码片段】(公众号排版用代码块,标注Python语言)```pythonfromlangchain.document_loadersimportPyPDFLoader# PDF加载器fromlangchain.text_splitterimportRecursiveCharacterTextSplitter# 文档分割器# 1. 加载本地PDF文档(修改为你的PDF文件路径)pdf_path ="C:\\WorkBuddy\\公众号\\LangChain官方文档摘要.pdf"# 示例路径loader = PyPDFLoader(pdf_path)documents = loader.load()# 加载文档,返回文档列表(每一页为一个文档对象)print(f"PDF总页数:{len(documents)}")print(f"第一页内容预览:{documents[0].page_content[:200]}...")# 预览第一页前200字# 2. 分割文档(解决大模型上下文长度限制)text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,# 每个文档片段的长度(500字符)chunk_overlap=50,# 片段之间的重叠长度(50字符),避免分割丢失上下文length_function=len# 长度计算方式(按字符数))# 执行分割,得到分割后的文档片段列表split_documents = text_splitter.split_documents(documents)print(f"分割后的文档片段数量:{len(split_documents)}")print(f"第一个片段内容:{split_documents[0].page_content}")
“`
【代码说明】:
– PyPDFLoader:LangChain专门用于加载PDF文档的加载器,支持多页PDF,每一页会被视为一个独立的文档对象
– RecursiveCharacterTextSplitter:最常用的文档分割器,按字符数分割,chunk_size控制每个片段的长度,chunk_overlap控制片段重叠度(避免分割后上下文断裂)
– 文档路径:需修改为你本地PDF的实际路径,注意路径中的反斜杠用双反斜杠(\\)或单斜杠(/)
## 四、实战2:搭建本地PDF问答机器人
加载并分割文档后,结合大模型,实现“用户提问 → AI基于PDF内容回答”的功能,这是最核心的实战环节,代码可直接复制运行。
【代码片段】(公众号排版用代码块,标注Python语言)
“`python
fromlangchain.document_loadersimportPyPDFLoaderfromlangchain.text_splitterimportRecursiveCharacterTextSplitterfromlangchain.llmsimportOpenAIfromlangchain.chainsimportRetrievalQA# 检索式问答链fromlangchain.vectorstoresimportFAISS# 本地向量存储(用于存储文档片段)fromlangchain.embeddingsimportOpenAIEmbeddings# 嵌入模型(用于将文本转化为向量)importos# 1. 配置API密钥os.environ["OPENAI_API_KEY"] ="你的API密钥"# 2. 加载并分割PDF文档(复用上面的代码)pdf_path ="C:\\WorkBuddy\\公众号\\LangChain官方文档摘要.pdf"loader = PyPDFLoader(pdf_path)documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)split_documents = text_splitter.split_documents(documents)# 3. 将文档片段转化为向量,存储到本地FAISS向量库embeddings = OpenAIEmbeddings()# 嵌入模型,将文本转化为可检索的向量vector_store = FAISS.from_documents(split_documents, embeddings)# 构建向量库# 4. 初始化检索式问答链(串联向量库、大模型,实现问答)qa_chain = RetrievalQA.from_chain_type(llm=OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0.7),chain_type="stuff",# 最简单的问答类型,将相关文档片段传入大模型retriever=vector_store.as_retriever(k=2),# 检索最近的2个相关文档片段return_source_documents=True# 返回回答的来源文档(方便验证答案准确性))# 5. 问答测试(基于PDF内容回答问题)print("PDF问答机器人(输入'退出'结束):")whileTrue:user_question = input("你:")ifuser_question =="退出":print("AI:再见!有任何问题随时来问~")break# 调用问答链,获取回答和来源文档result = qa_chain({"query": user_question})print(f"AI:{result['result']}")# 打印回答的来源文档(可选,方便验证)print("\n回答来源:")fordocinresult["source_documents"]:print(f"- 第{doc.metadata['page']+1}页:{doc.page_content[:100]}...")print("-"*50)```
【代码说明】:
– FAISS:Facebook开源的本地向量存储库,用于存储文档片段的向量,支持快速检索相关文档,无需联网,本地即可运行
– OpenAIEmbeddings:将文本转化为向量的嵌入模型,只有将文本转化为向量,才能实现“检索相关文档”的功能
– RetrievalQA:检索式问答链,核心逻辑是“用户提问 → 检索向量库中最相关的文档片段 → 传入大模型 → 生成回答”
– return_source_documents=True:开启后,会返回回答对应的来源文档(页码、内容),方便验证答案是否来自PDF
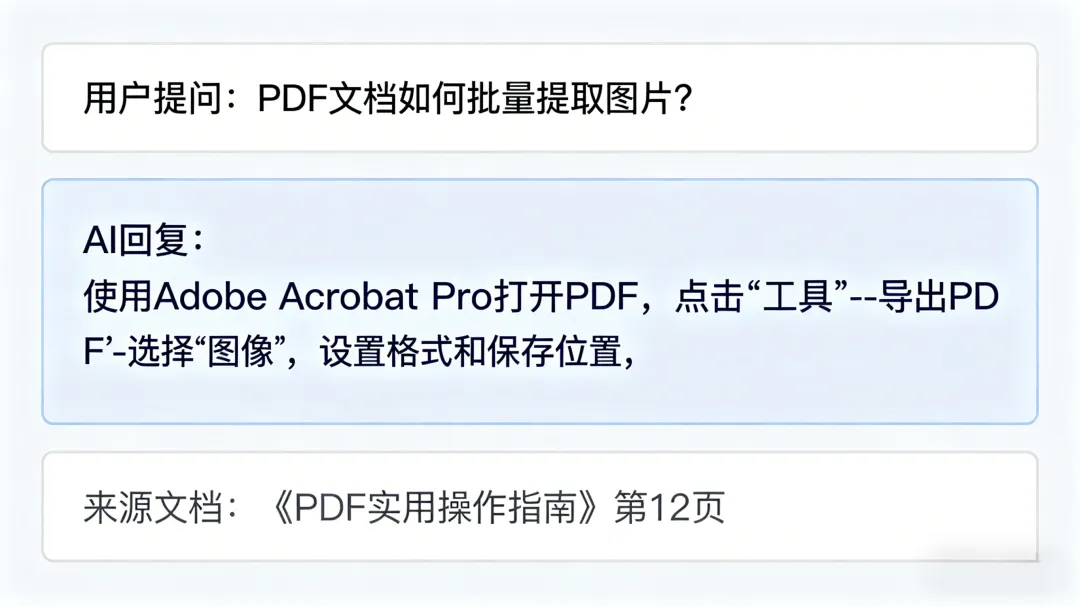
【测试示例】:
你:LangChain的核心组件有哪些?
AI:LangChain的核心组件包括提示词模板(PromptTemplate)、链(Chain)、记忆(Memory)、代理(Agent)、文档加载器(Document Loader)等,这些组件可以灵活组合,实现复杂的AI应用…
回答来源:
– 第2页:LangChain的核心组件包括提示词模板、链、记忆、代理、文档加载器等,每个组件都有其独特的作用,共同构成了LangChain的完整生态…
– 第3页:提示词模板用于标准化输入,链用于串联逻辑,记忆用于存储对话上下文,代理用于实现复杂的决策逻辑…
## 五、胖哥专属:实战技巧与避坑指南
1. 文档路径问题:务必确保PDF路径正确,Windows系统路径用双反斜杠(\\),Mac/Linux用单斜杠(/),避免路径错误导致加载失败
2. chunk_size调整:根据大模型的上下文长度调整,比如gpt-3.5-turbo-instruct的上下文长度是4096字符,chunk_size建议设为500-1000
3. 多文档支持:如果需要加载多个PDF/Word,可使用PyPDFDirectoryLoader(加载文件夹下所有PDF)、DocxLoader(加载Word),用法和PyPDFLoader类似
4. 国内模型适配:后续会讲用文心一言、通义千问替代OpenAI,无需科学上网,同样能实现文档问答
【结尾互动】
今天咱们实现了本地PDF问答机器人,这是LangChain实战开发中非常实用的功能,学会后可以直接用于处理自己的文档、论文、笔记等!
大家可以动手测试,替换成自己的PDF文件,提问相关问题,看看AI能否准确回答,有任何问题(比如路径错误、依赖安装失败),评论区留言,胖哥帮你排查!
明天咱们学习Day5:LangChain代理(Agent),让AI拥有“自主决策能力”,能自动调用工具、解决复杂问题,离独立开发完整AI应用又近一步!
—