 夜雨聆风
夜雨聆风





不想再为AI语音付费了,这个开源工具直接本地搞定!
大家好,我是Amy。
最近开始尝试做视频号了,发现比起单纯写文字来,剪辑视频的工作内容真的不是一个量级。
最基础的一步——口播,就已经把卡住了。
录音的时候经常这样: 刚开口就卡壳,说着说着开始重复,逻辑一乱,整段就只能推倒重来。

直到这几天,挖到一个宝藏工具—— Voicebox,才解决了这个难题。

它是一个开源的语音合成工作室,核心运用了阿里巴巴刚开源的 Qwen3-TTS 模型,不仅能几秒钟就克隆出很接近原生的声音,完美处理复杂的情绪和多语言切换。
而且从录制声音,生成语音,一直到后置效果,所有操作都可以在全部在本地电脑跑,不用上云、不用担心隐私外流。
就好比拥有了一个私人的录音棚。
传送门:https://github.com/jamiepine/voicebox
如何安装?
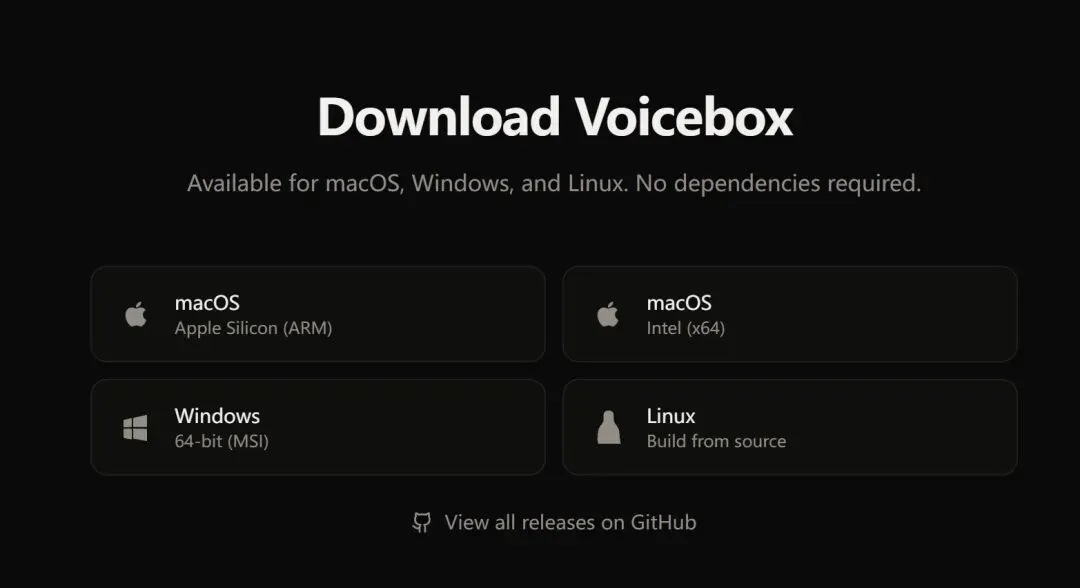
除了自己去部署外,官方提供了现成的安装包,macOS 和 Windows可以直接下载安装。
它的核心流程也很直接:
01
克隆声音
上传或者现场录制一段30s的音频,进行解析
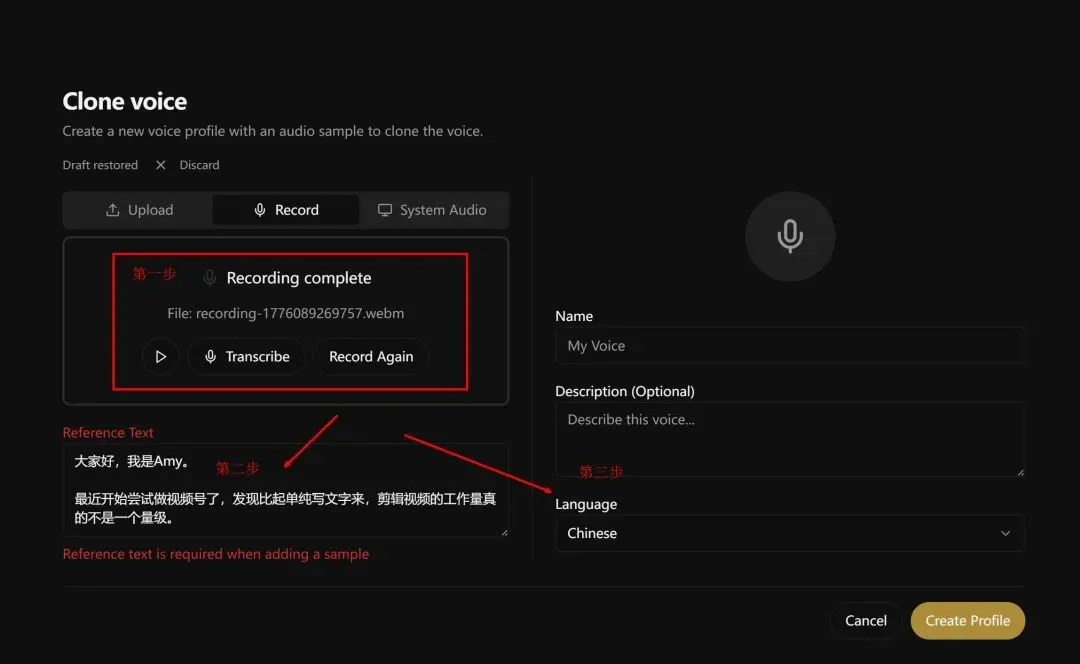
这里提醒一点,如果上传音频,一定要在第二张图的页面那里点击上传,如果是第一张图,它会一直提醒你 “无效的文件类型”。。。
02
TTS语音转音频
输入你想要生成音频的文本,点击魔法棒,程序开始下载模型。
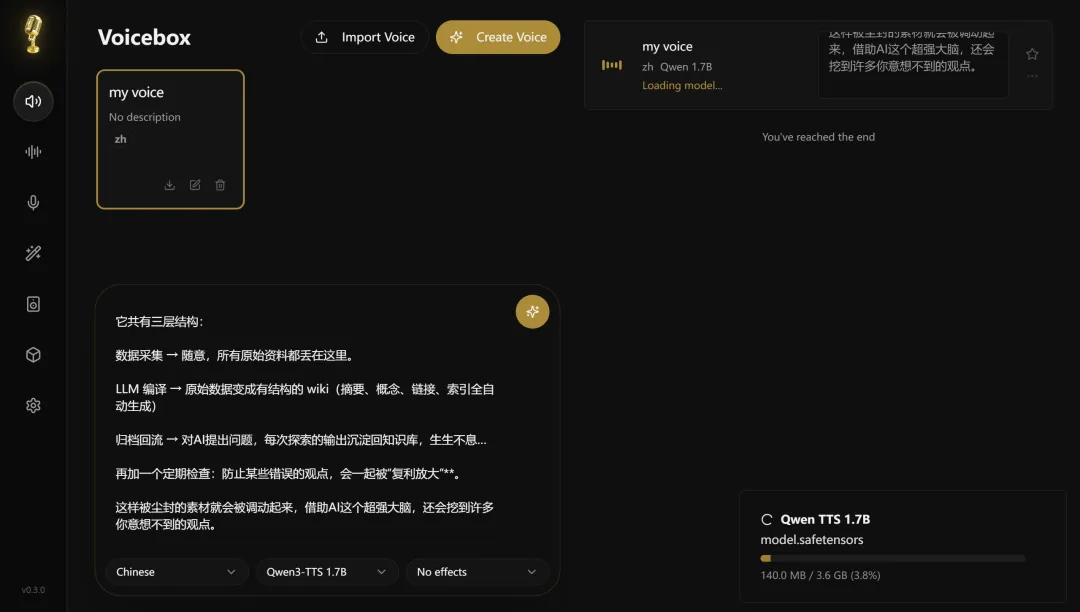
加载模型需要等一段时间(3.6G,好夸张)等待的时间,我又去克隆了不同语种的其他声音。
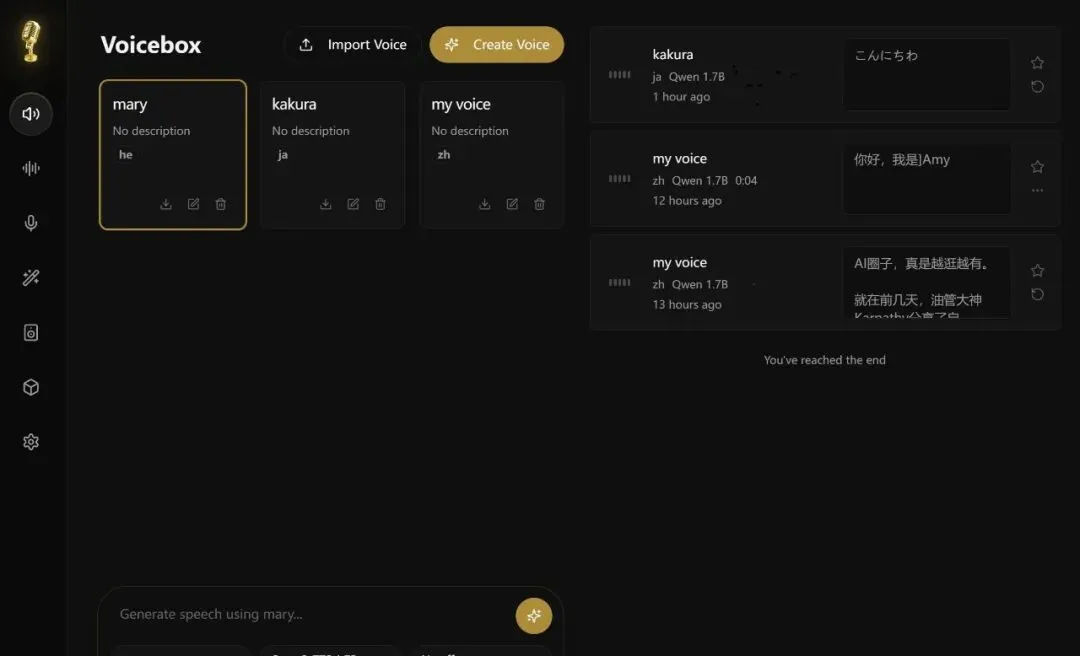
下载完成后,生成语音大概花了1分钟,播放试了下质量很不错,足以以假乱真的效果。
03
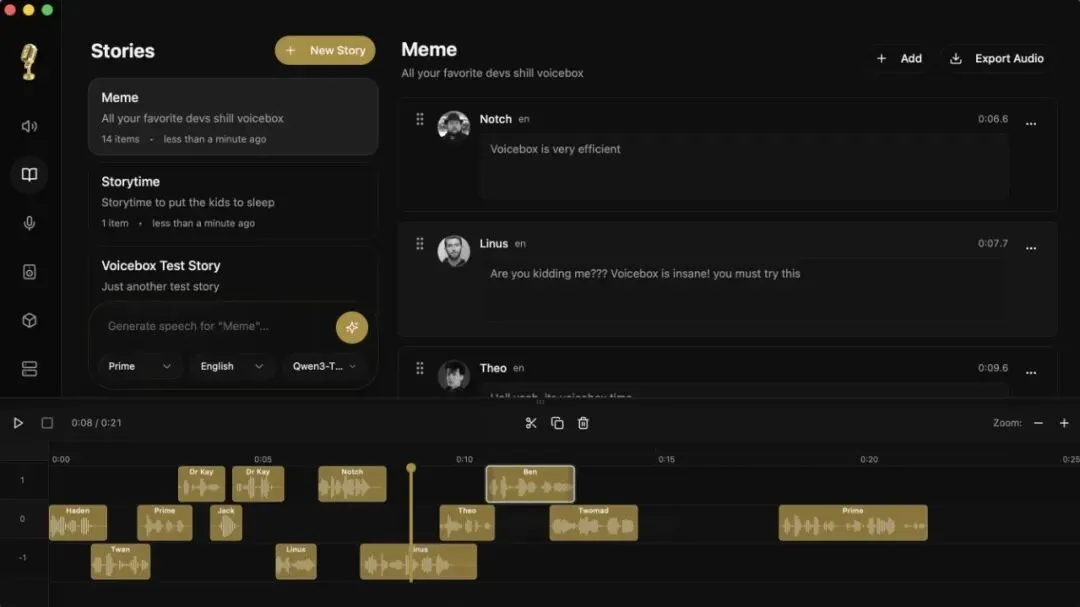
多轨时间线编辑器
除了单纯克隆声音,这里还有个 DAW 的介面:可以拉时间轴、多轨叠不同声音、做对话或 podcast脚本的东西。
04
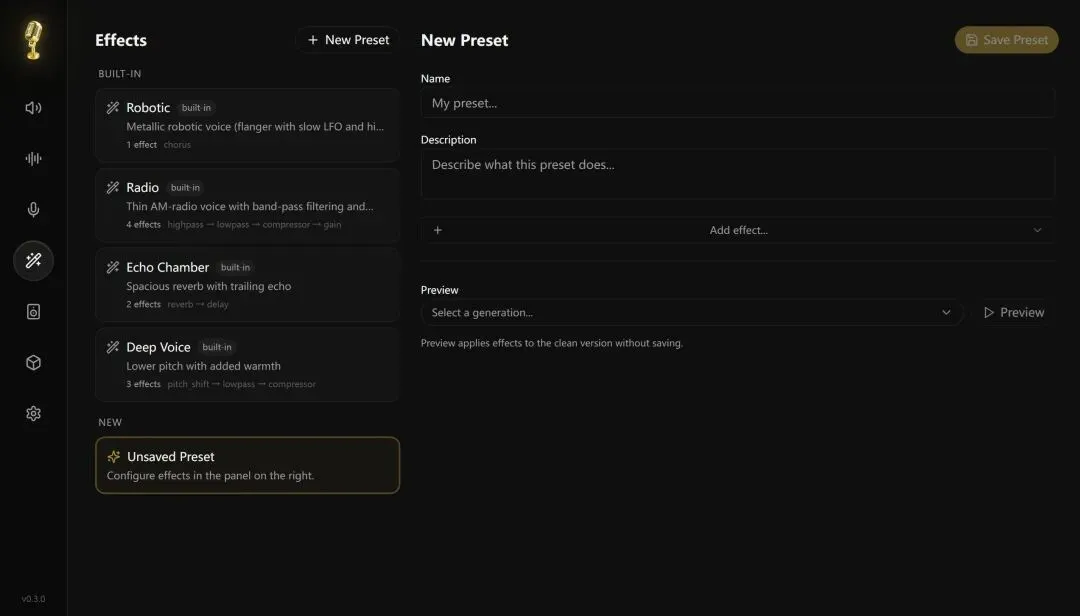
多音频效果
对声音效果不满意,Voicebox可以多种语音风格,情绪,所以做长内容也没问题。
05
建立自己的声音库
声音模型”还能快取,下次直接叫出来用,不用重新重克隆。
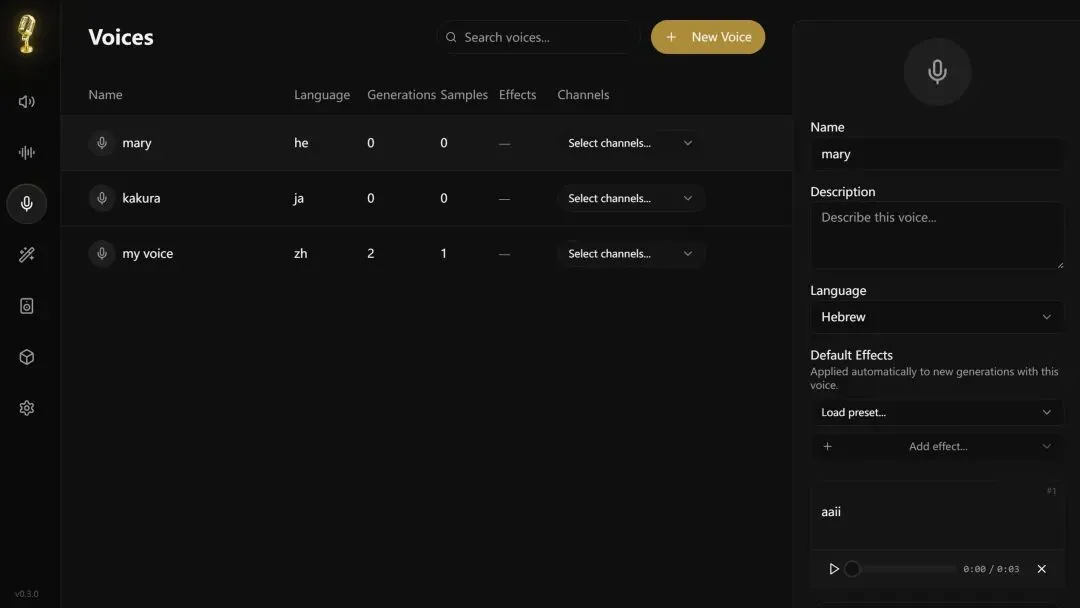
整个应用是用 Tauri + Rust 打包开发的,软件体积更小,所以不会有 Electron 常见的那种卡顿、臃肿的问题。
虽然如今AI 语音技术爆发,工具也越来越多,
但大多数方案还是依赖云端——
不仅要长期承担不低的订阅费用,
音频数据上传带来的隐私问题,也始终让人有点顾虑。
Voicebox 这样的本地化开源工具的出现,真的是福音。
无论是口播视频配音,还是做播客里的多角色对话、剧情类短视频,甚至游戏 NPC 语音、虚拟角色对话,都可以用它快速搭起来。
如果你对这些方向有兴趣,
一定值得下载试一试。