夜雨聆风
夜雨聆风





AAAI 2026 文档RAG终于会“边看边想”了:中科大提出LAT,用强化学习打通多模态推理链与视觉证据定位
在多模态大模型越来越擅长“读图”“看文档”“回答问题”的当下,一个关键问题也越来越突出:
模型即使答对了,用户也未必知道它到底是“看对了”还是“蒙对了”。
尤其是在文档场景中,这个问题更严重。论文截图、网页文档、报告页面、表格页面,往往都包含大量密集信息。模型如果只是给出一个答案,却不能明确指出它究竟看了哪一页、哪一块区域、沿着什么推理路径找到证据,那么这样的回答,仍然很难被真正信任。
Shuochen Liu 等作者这篇论文,正是在解决这个问题。作者提出了一种新的思路:不仅让模型给答案,还要让模型像人一样,一边思考,一边指出自己正在看什么证据。
这篇论文最核心的创新,可以概括为两点:
- 提出 Chain-of-Evidence(CoE)范式
:把“推理链”与“视觉证据定位”统一起来; - 提出 Look As You Think(LAT)框架
:用强化学习训练模型生成可验证的推理路径,而不仅仅是最终答案。
一、这篇论文到底在解决什么问题?
1.1 文档 RAG 已经很强,但“可验证性”还不够
作者关注的是 Visual Document Retrieval-Augmented Generation(VD-RAG),也就是视觉文档检索增强生成。简单来说,就是让视觉语言模型面对论文页面、网页截图、文档图片时,既能读取内容,又能回答问题。
这类任务的难点不只是“答出答案”,更在于:
-
文档页面信息密集,布局复杂; -
同一个答案可能跨越标题、正文、表格、图注等多个区域; -
多页场景下,模型还要先判断“哪一页相关”,再判断“页内哪一块相关”; -
如果模型出现幻觉,用户很难回溯它到底错在什么地方。
已有工作虽然已经开始关注 visual evidence attribution(视觉证据归因),也就是让模型把答案和文档中的证据区域对应起来,但作者指出,现有方法仍有一个明显不足:
它们往往只给“最后答案对应的证据”,却没有把“中间推理过程”展示出来。
换句话说,过去很多方法更像是在做“结果归因”,而不是“过程归因”。
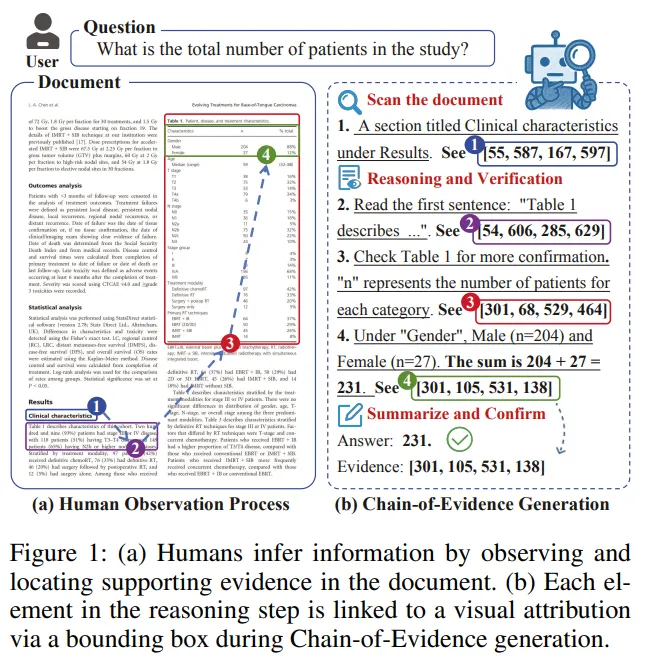
1.2 作者认为,真正可靠的文档问答,应该更像人类阅读
作者在论文中给出了一个非常直观的观察:人类在回答文档问题时,通常不是一下子就锁定最终答案,而是会经历一个逐步缩小范围的观察过程。
比如面对一个问题,人类可能会这样做:
-
先找到相关章节; -
再定位相关句子或表格; -
再确认具体数字或事实; -
最后给出答案,并能说明依据是什么。
这其实是一种 从粗到细(coarse-to-fine) 的证据定位过程。
二、作者提出了什么新概念?——Chain-of-Evidence(CoE)
2.1 CoE 不是普通的 CoT,而是“带证据定位的推理链”
过去很多模型会生成 Chain-of-Thought(CoT),也就是文字化的思维链。但作者认为,这对于文档场景还不够。
因为在文档问答里,推理的每一步都最好能落回到一个具体的视觉证据上。于是,作者提出了 Chain-of-Evidence(CoE)。
可以把 CoE 理解为:
每一个推理步骤,不只是写出“想了什么”,还要同时标注“这一步看的证据在哪一页、哪个框里”。
这意味着,CoE 包含三层信息:
- 问题与文档输入
; - 逐步推理文本
; - 每一步推理所对应的页码与边界框
。
最后,模型除了输出答案,还要给出支撑最终答案的那一个关键证据区域。
2.2 CoE 的价值,不只是解释,更是“可核验”
CoE 的价值在于,它把原本模糊的多模态推理过程,变成了一条可以检查的轨迹。
这样的设计至少带来三层意义:
第一,结果更透明。用户不仅知道答案是什么,还知道答案是从哪里来的。
第二,过程更可追踪。如果模型答错了,可以回看它在哪一步开始偏离了正确证据。
第三,训练目标更明确。模型不再只被要求“最后答对”,而是被要求“每一步都尽量对齐正确证据”。
从这个角度看,作者并不是在原有的证据归因任务上做一点小修补,而是在重新定义“什么叫可靠的文档问答”。
三、围绕 CoE,作者设计了什么方法?——Look As You Think(LAT)
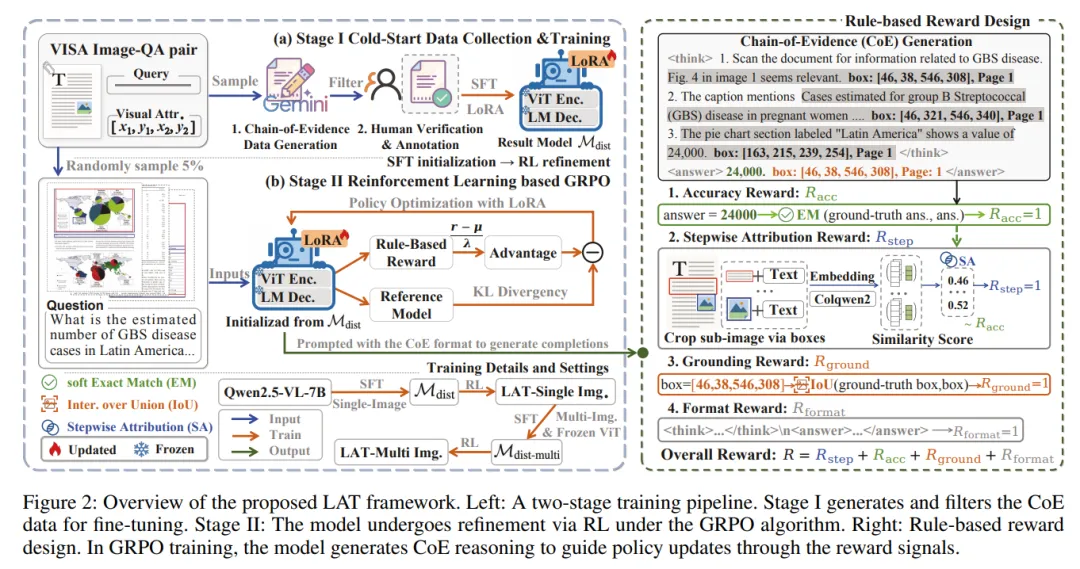
3.1 整体思路:先冷启动,再强化学习
为了让模型学会生成 CoE,作者提出了 Look As You Think(LAT) 框架。
这个框架分成两个阶段:
阶段一:冷启动数据构建与监督微调
作者先构建少量高质量 CoE 数据,让模型先学会“这种输出长什么样”。
阶段二:基于强化学习的细化优化
作者再让模型在奖励机制的引导下,进一步学习如何生成更可靠、更一致的证据化推理路径。
这个设计很重要,因为作者并不想依赖大规模人工标注的逐步证据数据。相反,作者希望:
用少量人工校验数据打底,再用强化学习把模型往“可验证推理”方向推上去。
四、阶段一做了什么?先把 CoE 数据“做出来”
4.1 冷启动数据不是人工全量标,而是“生成 + 过滤 + 人工校验”
作者没有一开始就依赖大规模人工构造 CoE 数据,而是采用了一种相对务实的路线:
-
从每个训练数据集中先采样 1000 个样本; -
使用更强的专有模型 Gemini 2.5 Pro; -
给它两个 CoE 示例作为 in-context demonstration; -
让它自动生成带边界框标注的逐步推理; -
再根据答案召回率过滤样本; -
最后再人工核验和修正边界框漂移问题。
作者最终保留了回答正确、边界框也经过核验的样本,用这些高质量样本去做监督微调。
这一阶段的目标不是追求数据规模,而是让模型先形成一个基本能力:
知道“什么样的输出才算 CoE”。
4.2 这一阶段解决的是“格式感”和“初始行为模式”
作者用 LoRA 对视觉语言模型做参数高效微调,让模型学习如下能力:
-
如何把推理写成分步形式; -
如何在步骤中插入证据框和页码; -
如何把最终答案与关键证据对应起来。
论文把这一阶段得到的模型记为 Mdist。从后续消融实验来看,仅仅这个阶段,就已经能明显提升模型的表现,说明:
高质量的 CoE 冷启动样本,确实能让模型初步学会“边想边看”的输出习惯。
五、阶段二怎么做?作者把“过程正确”写进奖励函数里
如果说阶段一是在教模型“怎么写”,那么阶段二就是在教模型:
什么样的推理过程,才算真正有价值。
作者在强化学习阶段采用了 GRPO,并围绕任务目标设计了四类奖励。
5.1 奖励一:答案准确奖励(Accuracy Reward)
这一奖励首先关注的是:答案是否正确。
但作者并没有只用硬性的 exact match,而是做了一个更柔和的设计:
-
如果预测答案和真实答案可以软匹配,则给高奖励; -
同时结合召回率,让部分语义相关但不完全一致的答案也能获得一定正向信号。
这样做的目的,是避免奖励过于稀疏,也避免模型因为表述形式略有差异就被完全否定。
这说明作者并没有把强化学习做成简单的“答对/答错”二分类,而是更注重训练信号的可持续性。
5.2 奖励二:步骤级证据归因奖励(Stepwise Attribution Reward)
这是整篇论文最核心的设计。
作者希望模型在每一步推理里,都能真正对齐对应的视觉证据,而不是随便给一个框。为此,作者做了两件事:
(1)衡量“这一步文字”和“这块图像区域”是否语义一致
作者把每一步推理文本,和它对应边界框裁出的图像区域,分别送入 ColQwen2 编码,再计算相似度。
也就是说,模型不能只写一句“我看到了表格中的数字”,还得让这句话和它框出来的区域在语义上匹配。
(2)限制不同步骤之间反复套用同一个大框
作者还额外计算不同边界框之间的重叠程度。如果多个步骤总是在重复使用高度相似的大区域,那么这种“看起来像在推理,实际上在偷懒”的行为,就会被抑制。
这一设计非常巧妙,因为它直接瞄准了一个常见漏洞:
模型可能会用一个又大又模糊的框,反复覆盖多个步骤,表面上像在做证据归因,实际上没有真正完成逐步定位。
作者通过重叠约束,鼓励模型形成真正的 粗到细定位路径,而不是机械重复。
更关键的是,这个步骤级奖励并不是独立发放的。作者要求:
-
只有当答案本身足够正确时, -
这些步骤级证据对齐奖励才真正起作用。
这意味着,作者希望奖励的不是“形式上像推理”的过程,而是:
那些既能导向正确答案、又在过程上证据一致的推理路径。
5.3 奖励三:最终答案证据定位奖励(Grounding Reward)
除了过程中的每一步,作者还要求模型必须把最终答案的支撑证据找准。
这一奖励的标准很明确:
-
预测的答案证据页码要正确; -
最终证据框与真实证据框的 IoU 要超过阈值。
这一步保证的是:模型不只是过程里“看过很多东西”,而且最后真的能把最关键的答案证据找出来。
5.4 奖励四:格式奖励(Format Reward)
作者还设计了格式奖励,要求模型严格输出:
<think> ... </think><answer> ... </answer>
格式对了就奖励,格式错了就惩罚。
这看起来像个小细节,其实并不小。因为在强化学习里,格式稳定本身就意味着训练目标更清晰,模型更容易收敛,也更利于后续评估。
六、实验是怎么做的?
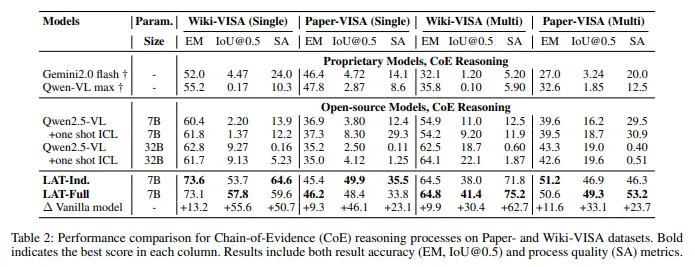
6.1 数据集:作者主要在 VISA 基准上验证方法
作者使用的是 VISA benchmark,这是一个面向视觉证据归因的文档 RAG 数据集。它包含三个子集:
- Wiki-VISA
- Paper-VISA
- FineWeb-VISA
论文的主要实验结果重点展示在 Wiki-VISA 和 Paper-VISA 上。
作者分别考察了两种设定:
单图设定(Single-image)
每个问题只给一页源文档,模型需要回答问题并定位证据。
多图设定(Multi-image)
每个问题会给多个候选文档页面,模型既要找对页面,又要在页面内找对证据。
后者显然更接近真实检索场景,也更能体现方法价值。
6.2 模型与训练细节
作者以 Qwen2.5-VL-7B-Instruct 为骨干模型,并采用 LoRA 进行参数高效训练。
训练流程上,作者先做 SFT,再做 RL。强化学习阶段只使用了 原始 QA 对中的 5% 样本,这一点非常值得注意,因为这意味着:
LAT 并不是依赖海量监督数据取胜,而是在有限监督下,通过奖励机制把模型能力“逼”出来。
多图设定下,作者还冻结了视觉编码器,只微调语言模型部分的 LoRA 参数,以减少显存开销。
6.3 评价指标:作者不只看答题准确率
作者用了三类指标评估模型:
- EM(soft Exact Match)
:看答案是否正确; - IoU@0.5
:看最终证据框是否准确; - SA(Stepwise Attribution)
:看步骤级证据归因是否合理。
这组指标很重要,因为它体现了这篇论文的真正目标:
不只是要“结果正确”,还要“过程可信”。
七、结果说明了什么?LAT 不只是能答题,更能把证据链走通
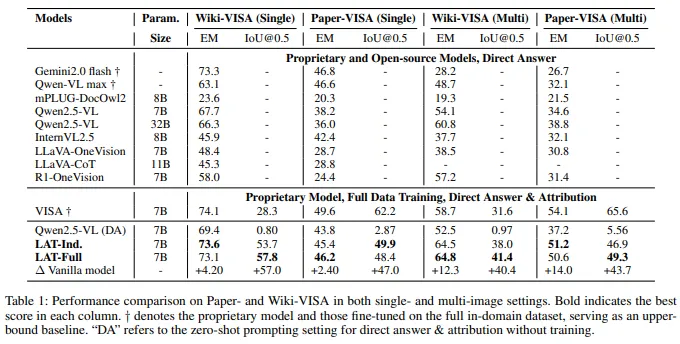
7.1 主结果:答案准确率和证据定位都显著提升
作者在论文中指出,相比原始基线模型,LAT 在单图和多图设置下,平均带来了:
- 8.23% 的 soft EM 提升
- 47.0% 的 IoU@0.5 提升
这组数字说明,LAT 并不是用“更长的推理过程”换来“更差的准确率”,而是在提升可验证性的同时,也提升了实际任务表现。
如果进一步看具体结果,LAT-Full 在多个设定下都取得了很强的表现,例如:
-
Wiki-VISA 单图:EM 73.1,IoU@0.5 57.8 -
Paper-VISA 单图:EM 46.2,IoU@0.5 48.4 -
Wiki-VISA 多图:EM 64.8,IoU@0.5 41.4 -
Paper-VISA 多图:EM 50.6,IoU@0.5 49.3
最值得注意的是,多图场景中的提升尤其明显。因为在这种情况下,模型不仅要“读懂页面”,还要“先找对页面再找对区域”,这恰好放大了 CoE 和 LAT 的优势。
7.2 过程质量也显著变好:这不是“会说推理话术”,而是真的会逐步找证据
论文进一步在 CoE 推理场景下比较了不同模型的过程质量。结果显示,LAT 在 SA(步骤级证据归因) 上有非常明显的提升。
这说明 LAT 的优势不只是“最后那个答案框更准”,还体现在:
-
每一步推理和对应证据之间的一致性更强; -
推理路径更像真实的阅读与检索过程; -
模型不太容易只靠模板化输出“伪思维链”。
换句话说,LAT 学到的不是一种表面形式,而是一种更贴近文档理解规律的行为模式。
八、消融和对比
8.1 先看与 SFT 的比较:强化学习并不是装饰,而是关键增益来源
作者专门设置了 SFT 基线,与 LAT 做对比。结果显示,LAT 在答案准确率和证据定位精度上都优于仅靠监督微调的方法,尤其在多图设置下优势更明显。
这说明一个事实:
仅仅把模型训练成“会输出 CoE 格式”,还不够;只有把“过程是否可信”纳入奖励机制,模型才会真正学会证据化推理。
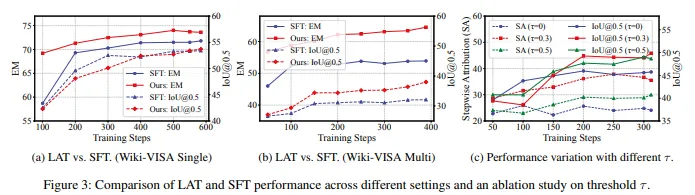
8.2 再看消融实验:四类奖励不是随便堆出来的
作者还做了非常关键的消融实验。实验结果表明:
-
仅有阶段一蒸馏得到的 Mdist,已经比原始模型好不少; -
去掉 步骤级奖励 Rstep 后,SA 明显下降,IoU 也会跟着变差; -
去掉 答案准确与最终 grounding 奖励 后,模型虽然还能维持部分过程一致性,但结果质量会明显受损; -
如果不再用答案正确性去约束步骤奖励,那么模型会越来越偏向“学格式”,而不是“学真实推理”。
这组实验特别有说服力,因为它回答了一个关键问题:
LAT 的增益,究竟来自强化学习本身,还是来自奖励设计?
作者给出的答案很清楚:来自二者结合,但奖励设计是决定性的。