夜雨聆风
夜雨聆风





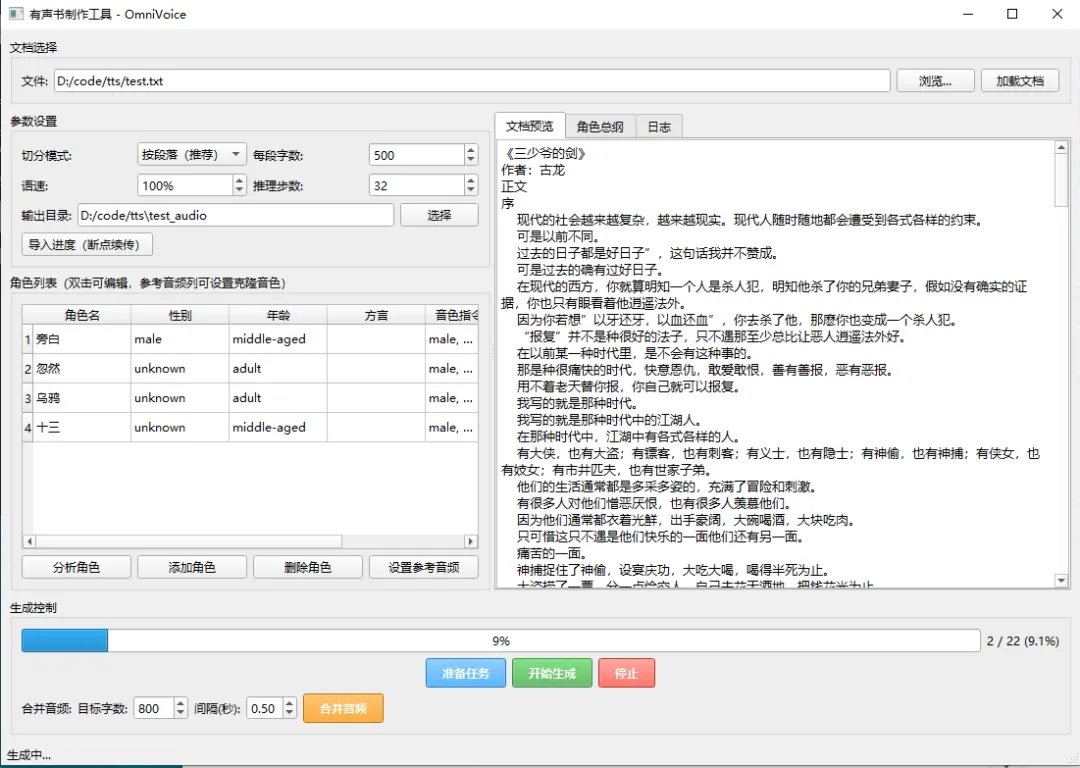
用AI做一个文本变有声书的软件
OmniVoice的主要功能
- 超大规模多语言合成
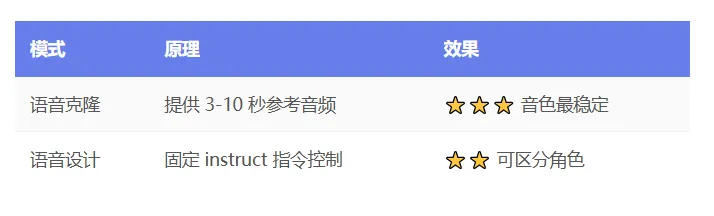
:支持 600+ 语种的零样本 TTS,覆盖从高频到低资源小语种,基于 58 万小时开源数据训练。 - 零样本语音克隆
:仅需 3-10 秒参考音频即可克隆任意说话人音色,支持自动转录(内置 Whisper)或手动提供文本。 - 属性化音色设计
:无需参考音频,通过自然语言描述(性别、年龄、音调、方言/口音、耳语风格等)直接生成定制声音。 - 参考音频去噪
:可处理带噪声或混响的参考音频,提取纯净说话人特征,避免合成语音携带环境杂音。 -
副语言控制:插入
[laughter]、[sigh]等标签添加笑声、叹气等情感 -
发音纠正:用拼音(如
ZHE2)或 CMU 音素(如[B EY1 S])纠正多音字和专有名词发音
核心功能

它是怎么工作的
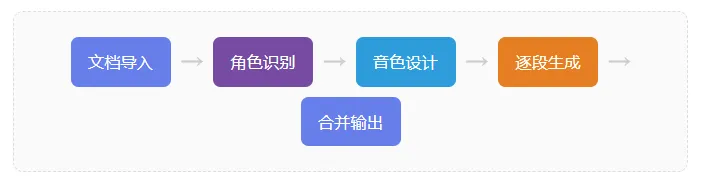
第一步:角色识别
工具会扫描全文,用正则匹配 “张三说:”“李四笑道:” 这样的模式,提取出说话人。然后根据上下文线索——比如附近出现了”奶奶””姑娘”这类词——自动推断角色的性别和年龄段,并分配对应的音色模板。
第二步:对话拆分
一段文字里可能既有旁白又有多个角色的对话。比如:
张三摇了摇头,道:「你总是这么悲观。」李四叹道:「我也没办法。」
工具会先把 “张三摇了摇头,道:” 标准化为 “张三道:”,然后拆成三个独立片段:旁白、张三对话、李四对话,各自用对应角色的音色生成。
第三步:音色一致性保证
这是最核心的难点。每个角色绑定一个 voice_key,由角色名 + 性别 + 年龄 + 音色指令组成。同角色在任何位置都走同一条音色路径:
第四步:生成与合并
每个片段独立调用 OmniVoice 生成 wav,支持断点续传——中途中断,下次接着来。生成完成后,点击”合并音频”,碎片文件按字数阈值自动合并,比如每 800 字一个大音频,片段间插入 0.5 秒静音,听感自然流畅。
技术栈
PythonPyQt6OmniVoice TTSCUDA GPUPyMuPDFsoundfileNumPy
整个工具基于 OmniVoice 本地 TTS 模型运行,调用 GPU 加速推理,不依赖任何云端 API,数据完全不出本机。界面用 PyQt6 构建,支持实时查看生成进度和日志。
开发中踩过的坑
做角色识别的时候,“李四笑道” 里的 “笑” 会被错误地吃进人名,变成角色 “李四笑”。解决方案是把人名匹配限定为恰好 2 个纯中文字符,而 “笑道” 作为一个整体动词来匹配。
还有 “张三摇了摇头,道:” 这种说话人 + 动作描述 + 说话动词的模式,最初整段都被归为旁白。后来加了一个预处理器,把逗号前的动作描述剥离,只保留 “张三道:”,问题才解决。