 夜雨聆风
夜雨聆风





轻薄笔记本也能本地搭一套「CTF AI」助手
很多人一提到本地 AI,先想到的是大模型、显卡和高配置。但对大多数学生和参赛者来说,手里的设备往往就是一台轻薄笔记本。配置不高,显卡一般。如何搭一套能离线运行、能稳定辅助、能真正用于做题的工具链呢?
经过一些测试下来,轻薄本完全可以搭一套本地 AI 做题方案,核心思路很简单:
-
• 理论题:RapidOCR 负责识别图片题目,本地模型负责理解和回答 -
• CTF 题:Open WebUI 负责知识库检索,Ollama 负责本地模型推理 -
• 知识库:分成“解题经验库”和“工具使用库”两类,避免内容混杂
先看设备环境:

这类设备不适合一上来就追求很大的模型,更适合先从小模型起步。建议是先把本地链路跑通,再考虑往上加模型规模。能稳定回答、能结合知识库、能持续使用,比参数更重要。
使用 Ollama 拉取本地模型
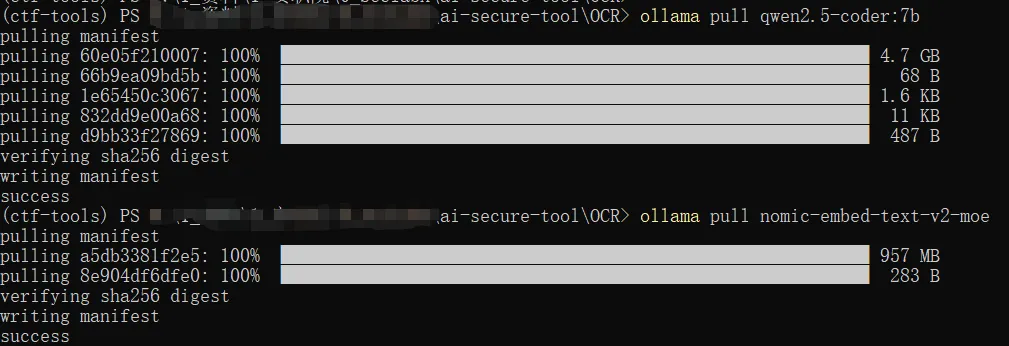
轻量方案里,小模型已经基本够用。像 qwen2.5-coder:3b 这种体量的编程模型,对轻薄本更友好,做代码理解、命令解释、思路提示、简单问答已经能覆盖很多场景。甚至可以继续上到 qwen2.5-coder:7b 这一类更大的模型。
拉取模型也很简单:ollama pull qwen2.5-coder:3b
Ollama 官网:https://ollama.com/
使用 Open WebUI 与模型对话
只有本地模型还不够。真正把它变成“做题助手”的,是 Open WebUI 这一层。
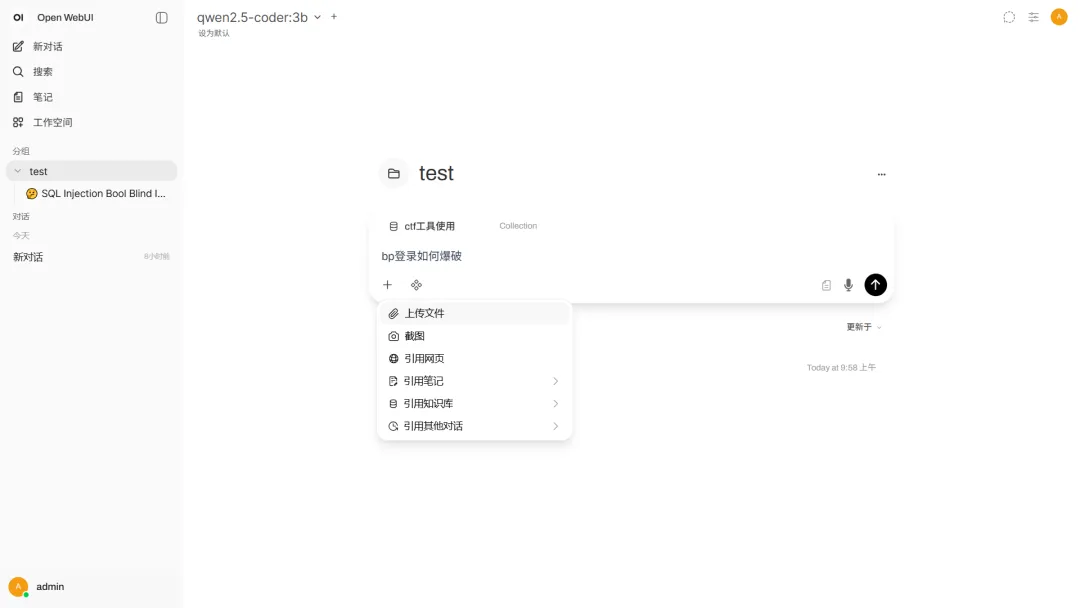
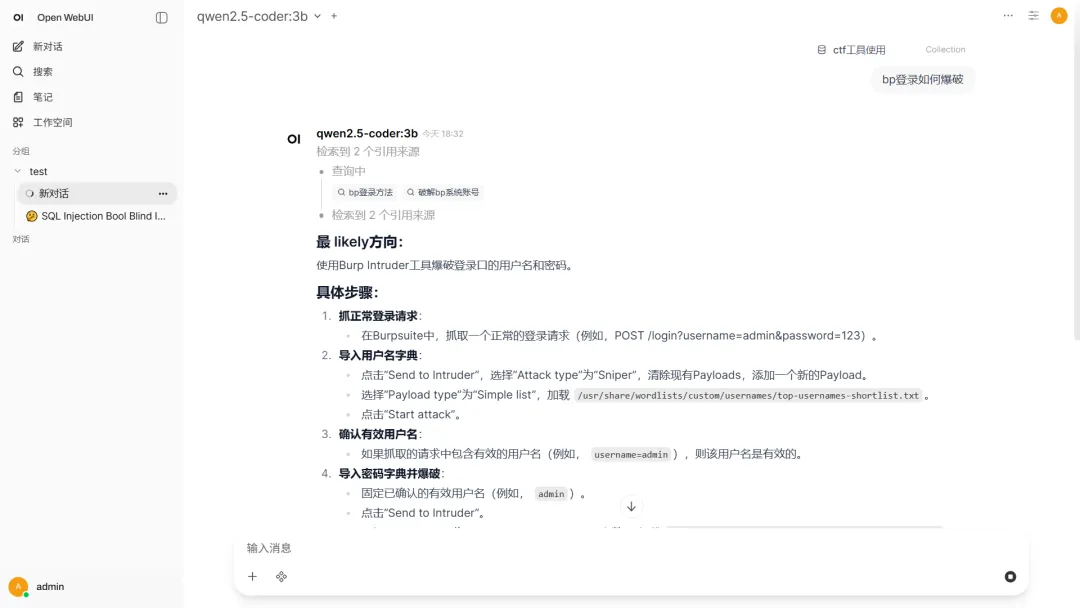
Open WebUI 负责两件事:
第一件事是把 Ollama 里的本地模型接起来,形成稳定的对话入口。第二件事是把知识库接进来,让模型回答时不只靠参数记忆,而是能先检索、再作答。
对 CTF 这类专业场景来说,这一步非常关键。因为小模型知识量很小,缺的不只是“一个万能答案”,而是:
-
• 某类题的入手经验 -
• 某个工具的具体用法 -
• 某条命令的参数含义 -
• 某种报错的定位思路
这些内容,靠知识库比单纯靠模型更稳。
Open WebUI 官网:https://openwebui.com/
使用 OCR 识别理论题
理论题最先卡住的,往往不是回答能力,而是题目如何识别?
截图、扫描图、题库页面、比赛理论题界面,都会遇到这个问题。
这时候就先把 OCR 接进来。
RapidOCR → 提取题干 → 本地模型回答
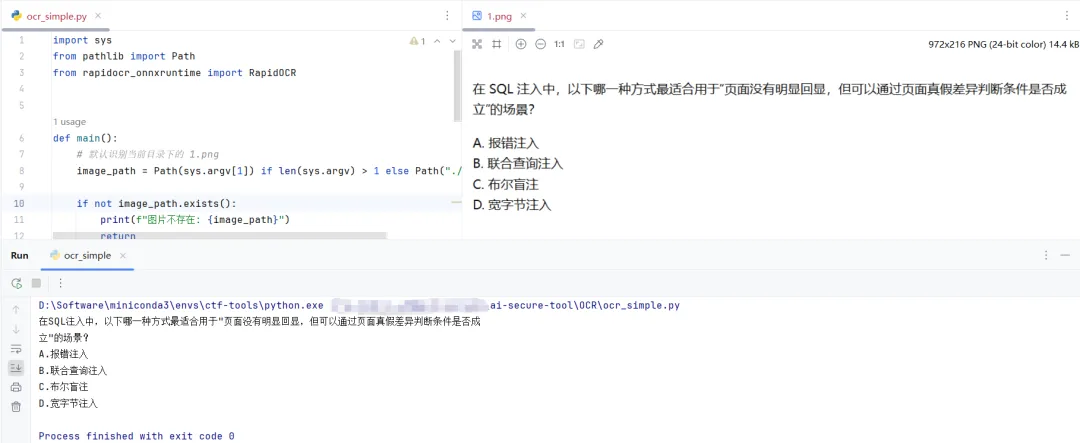
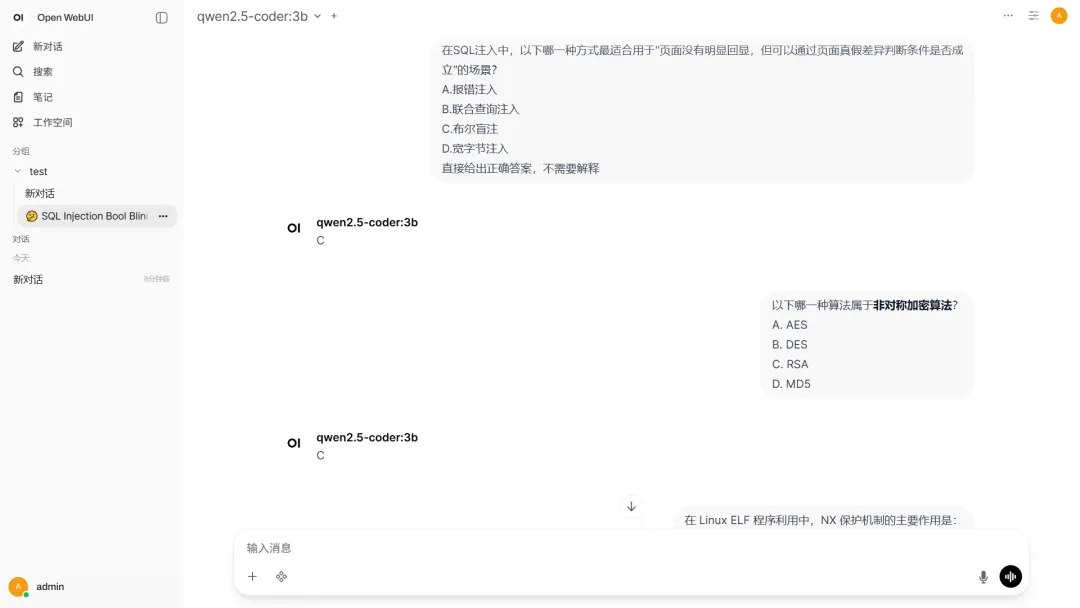
RapidOCR 的作用就是先把图片里的题干和选项提取出来,再交给本地模型处理。这样做有两个好处:
第一,输入更干净。第二,小模型不需要同时承担“识别图片”和“理解题目”两件事,压力会小很多。
这套方式很适合理论题、选择题、判断题和简答题的初步辅助。它不能代替人工复核,但能明显减少手动录入和来回切换的成本。
构建双知识库
CTF 场景里,更建议把知识库拆成两套,而不是全塞到一个库里。
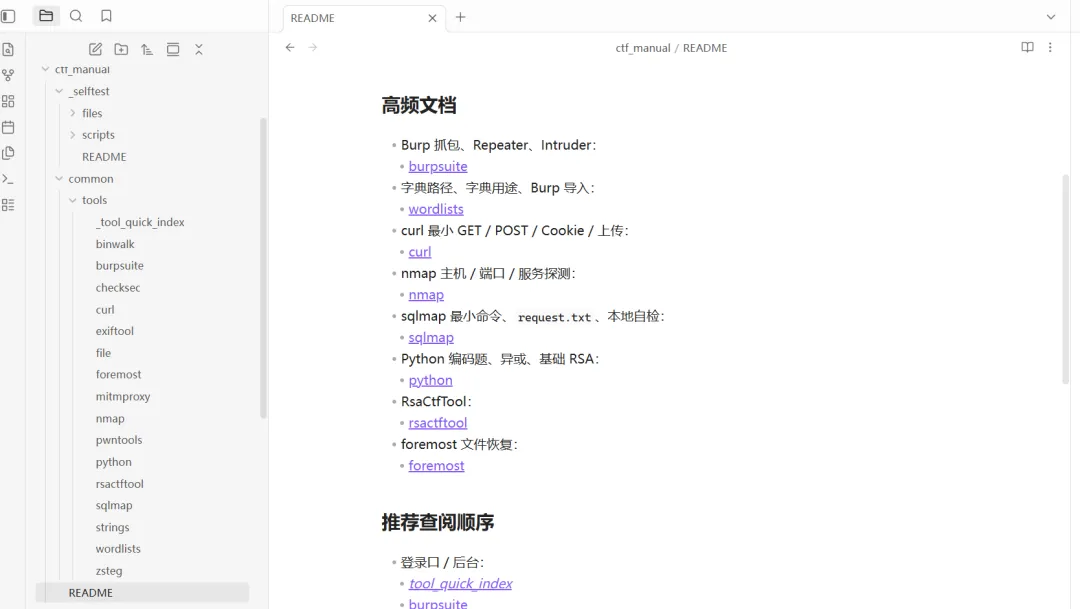
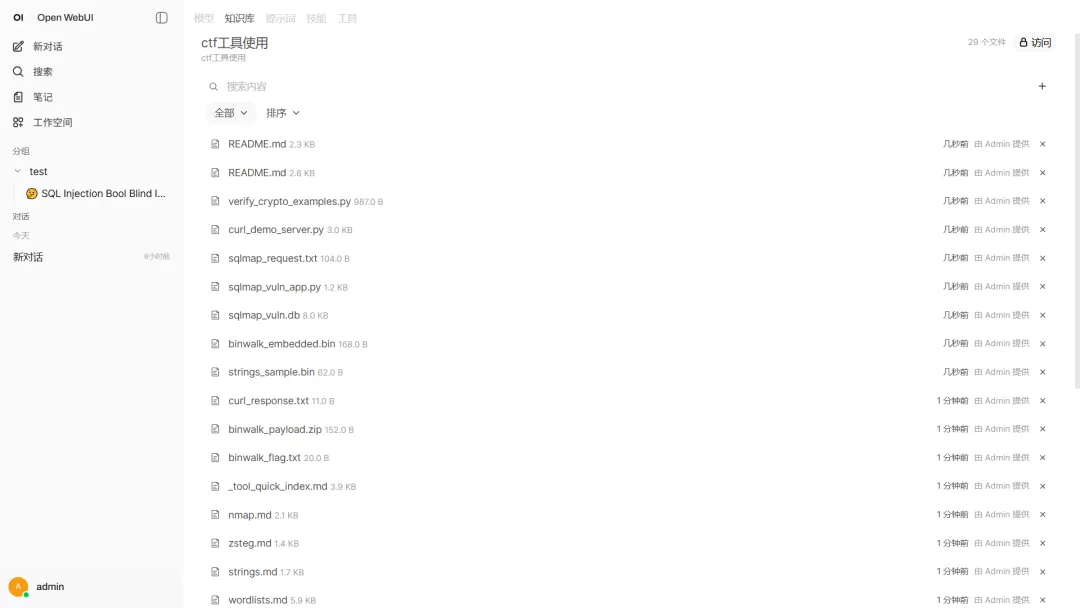
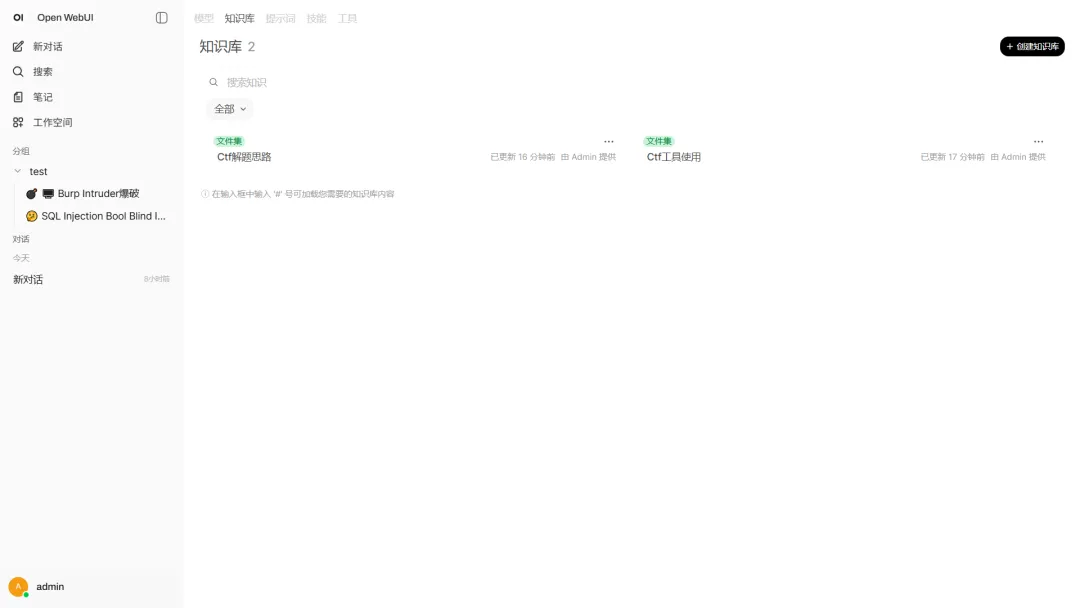
第一套叫解题经验库。这里放的是题型经验、常见入口、解题思路、典型复盘、易错点总结。它更像“思路脑”。
第二套叫工具使用库。这里放的是 Burp Suite、GDB、binwalk、CyberChef、Wireshark 这类工具的常用操作、参数说明和适用场景。它更像“工具脑”。
这样拆开以后,模型在回答时更容易聚焦。你问思路,它优先从经验库里找。你问工具,它优先从工具库里找。检索结果更干净,回答也更接近实战需要。
Open WebUI 里嵌入模型推荐用 nomic-embed-text-v2-moe。往往构建的知识库包含:中文、英文、代码等 多种语言,正确的嵌入模型可以让知识库里的资料能够被更准确地召回。
进阶方案
前面这套方案的重点是“轻薄本可用”。如果设备配置更高,内存更大,模型规模可以继续往上提,工作方式也可以继续升级。
这时候就不只是一套“本地问答 + 知识库”的结构了,而是可以进一步走向 Agent。
例如:
-
• opencode + 较大的本地模型 + kali MCP + bp MCP -
• 其他开源的安全类 Agent -
• 本地工具调用 + 多步骤任务分解 -
• 更长链路的自动化分析流程
👇扫码加入知识库,AI智能问答
